
Prezentare generală a principalelor funcții Google BigQuery — exersați scrierea solicitărilor pentru analiza de marketing
Publicat: 2022-04-12Cu cât o afacere acumulează mai multe informații, cu atât mai acută este întrebarea unde să le depoziteze. Dacă nu aveți capacitatea sau dorința de a vă întreține propriile servere, Google BigQuery (GBQ) vă poate ajuta. BigQuery oferă stocare rapidă, rentabilă și scalabilă pentru lucrul cu date mari și vă permite să scrieți interogări folosind sintaxa SQL, precum și funcții standard și definite de utilizator.
În acest articol, analizăm principalele funcții ale BigQuery și arătăm posibilitățile acestora folosind exemple specifice. Veți învăța cum să scrieți interogări de bază și să le testați pe date demonstrative.
Creați rapoarte pe datele GBQ fără pregătire tehnică sau cunoștințe de SQL.
Aveți în mod regulat nevoie de rapoarte privind campaniile publicitare, dar nu aveți timp să studiați SQL sau să așteptați un răspuns de la analiștii dvs.? Cu OWOX BI, puteți crea rapoarte fără a fi nevoie să înțelegeți cum sunt structurate datele dvs. Doar selectați parametrii și valorile pe care doriți să le vedeți în raportul de date inteligente. OWOX BI Smart Data va vizualiza instantaneu datele dvs. într-un mod pe care îl puteți înțelege.
Cuprins
- Ce este SQL și ce dialecte acceptă BigQuery
- Unde să încep
- Funcții Google BigQuery
- Funcții agregate
- Funcții de dată
- Funcții șiruri
- Funcțiile ferestrei
- Concluzii
Ce este SQL și ce dialecte acceptă BigQuery
Structured Query Language (SQL) vă permite să preluați date din, să adăugați date și să modificați datele în matrice mari. Google BigQuery acceptă două dialecte SQL: SQL standard și SQL învechit.
Ce dialect să alegeți depinde de preferințele dvs., dar Google recomandă utilizarea standardului SQL pentru aceste beneficii:
- Flexibilitate și funcționalitate pentru câmpuri imbricate și repetate
- Suport pentru limbajele DML și DDL, permițându-vă să modificați datele din tabele, precum și să gestionați tabelele și vizualizările în GBQ
- Procesare mai rapidă a cantităților mari de date în comparație cu Legacy SQL
- Asistență pentru toate actualizările viitoare BigQuery
Puteți afla mai multe despre diferențele de dialect în documentația BigQuery.
Vezi și: Care sunt avantajele noului dialect SQL standard al Google BigQuery față de Legacy SQL și ce sarcini de afaceri poți rezolva cu acesta?
În mod implicit, interogările Google BigQuery rulează pe Legacy SQL.
Puteți trece la SQL standard în mai multe moduri:
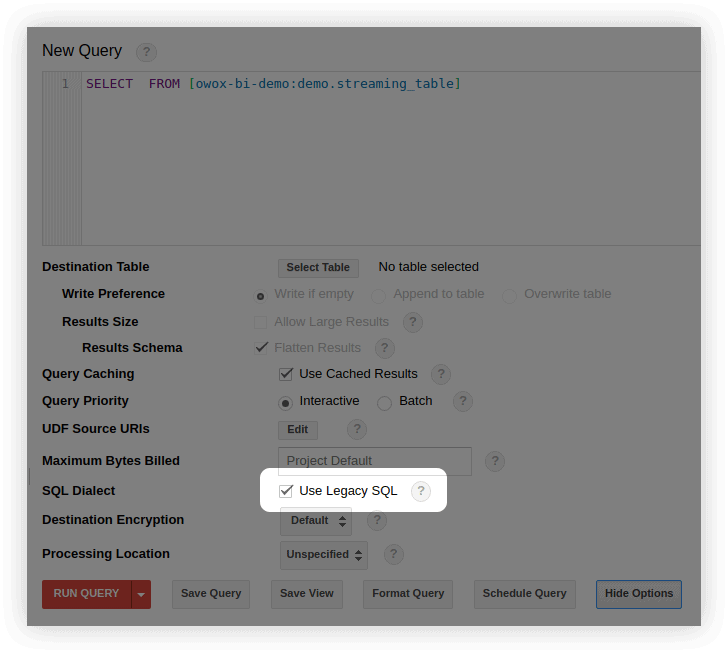
- În interfața BigQuery, în fereastra de editare a interogărilor, selectați Afișare opțiuni și eliminați bifa de lângă Utilizare SQL moștenit :
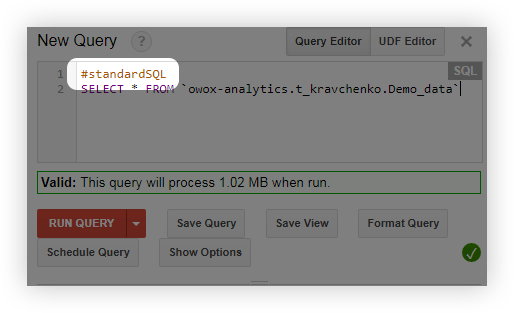
- Înainte de a interoga, adăugați linia #standardSQL și începeți interogarea cu o linie nouă:
Unde să încep
Pentru a putea exersa și a rula interogări cu noi, am pregătit un tabel cu date demonstrative. Completează formularul de mai jos și ți-l vom trimite prin e-mail.


Date demonstrative pentru practica interogărilor SQL
Descărcați Pentru a începe, descărcați tabelul de date demonstrativ și încărcați-l în proiectul dvs. Google BigQuery. Cel mai simplu mod de a face acest lucru este cu ajutorul suplimentului OWOX BI BigQuery Reports.
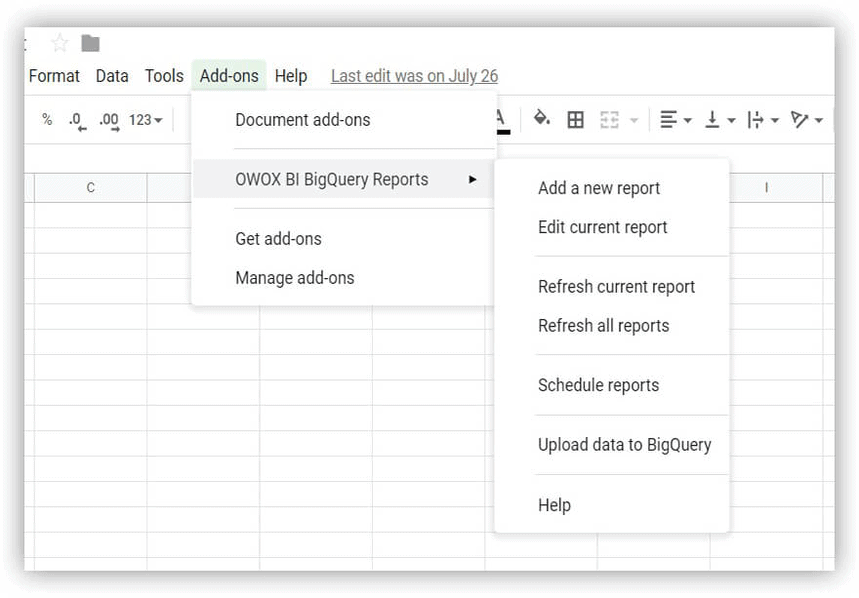
- Deschideți Google Sheets și instalați suplimentul OWOX BI BigQuery Reports.
- Deschideți tabelul pe care l-ați descărcat care conține date demonstrative și selectați Rapoarte OWOX BI BigQuery –> Încărcați date în BigQuery :
- În fereastra care se deschide, alegeți proiectul dvs. Google BigQuery, un set de date și gândiți-vă un nume pentru tabelul în care vor fi stocate datele încărcate.
- Specificați un format pentru datele încărcate (după cum se arată în captura de ecran):

Dacă nu aveți un proiect în Google BigQuery, creați unul. Pentru a face acest lucru, veți avea nevoie de un cont de facturare activ în Google Cloud Platform. Nu lăsați să vă sperie că trebuie să conectați un card bancar: nu veți fi taxat cu nimic fără să știți. În plus, atunci când vă înregistrați, veți primi 300 USD pentru 12 luni pe care îi puteți cheltui pe stocarea și procesarea datelor.
OWOX BI vă ajută să combinați datele din diferite sisteme în BigQuery: date despre acțiunile utilizatorilor pe site-ul dvs. web, apeluri, comenzi din CRM, e-mailuri, costuri de publicitate. Puteți utiliza OWOX BI pentru a personaliza analizele avansate și pentru a automatiza rapoartele de orice complexitate.
Înainte de a vorbi despre funcțiile Google BigQuery, să ne amintim cum arată interogările de bază atât în dialectele Legacy SQL, cât și în Standard SQL:
| Interogare | SQL moștenit | SQL standard |
|---|---|---|
| Selectați câmpuri din tabel | SELECTează câmpul 1, câmpul 2 | SELECTează câmpul 1, câmpul 2 |
| Selectați un tabel din care să alegeți câmpurile | DE LA [projectID:dataSet.tableName] | DIN `projectID.dataSet.tableName` |
| Selectați parametrul după care să filtrați valorile | WHERE câmp 1=valoare | WHERE câmp1=valoare |
| Selectați câmpurile după care să grupați rezultatele | GROUP BY câmpul 1, câmpul 2 | GROUP BY câmpul 1, câmpul 2 |
| Selectați cum să comandați rezultatele | ORDER BY câmpul 1 ASC (crescător) sau DESC (descrescător) | ORDER BY câmpul 1 ASC (crescător) sau DESC (descrescător) |
Funcții Google BigQuery
Când construiți interogări, veți folosi cel mai frecvent funcțiile de agregare, dată, șir și fereastră. Să aruncăm o privire mai atentă la fiecare dintre aceste grupuri de funcții.
Vedeți și: Cum să începeți să lucrați cu stocarea în cloud — creați un set de date și tabele și configurați importarea datelor în Google BigQuery.
Funcții agregate
Funcțiile agregate oferă valori rezumative pentru un întreg tabel. De exemplu, le puteți folosi pentru a calcula mărimea medie a cecului sau venitul total pe lună sau le puteți utiliza pentru a selecta segmentul de utilizatori care au făcut numărul maxim de achiziții.
Acestea sunt cele mai populare funcții agregate:
| SQL moștenit | SQL standard | Ce face funcția |
|---|---|---|
| AVG(câmp) | AVG([DIstinct] (câmp)) | Returnează valoarea medie a coloanei câmpului. În SQL standard, când adăugați o condiție DISTINCT, media este luată în considerare numai pentru rândurile cu valori unice (nerepetabile) în coloana câmpului. |
| MAX(câmp) | MAX(câmp) | Returnează valoarea maximă din coloana câmpului. |
| MIN(câmp) | MIN(câmp) | Returnează valoarea minimă din coloana câmpului. |
| SUM(câmp) | SUM(câmp) | Returnează suma valorilor din coloana câmpului. |
| COUNT(câmp) | COUNT(câmp) | Returnează numărul de rânduri din coloana câmpului. |
| EXACT_COUNT_DISTINCT(câmp) | COUNT([DIstinct] (câmp)) | Returnează numărul de rânduri unice din coloana câmpului. |
Pentru o listă a tuturor funcțiilor agregate, consultați documentația Legacy SQL și Standard SQL.
Să ne uităm la datele demonstrative pentru a vedea cum funcționează aceste funcții. Putem calcula venitul mediu pentru tranzacții, achizițiile pentru sumele cele mai mari și cele mai mici, venitul total, tranzacțiile totale și numărul de tranzacții unice (pentru a verifica dacă achizițiile au fost duplicate). Pentru a face acest lucru, vom scrie o interogare în care vom specifica numele proiectului nostru Google BigQuery, setul de date și tabelul.
#moștenire SQL
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]#SQL standard
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`Ca rezultat, vom obține următoarele:
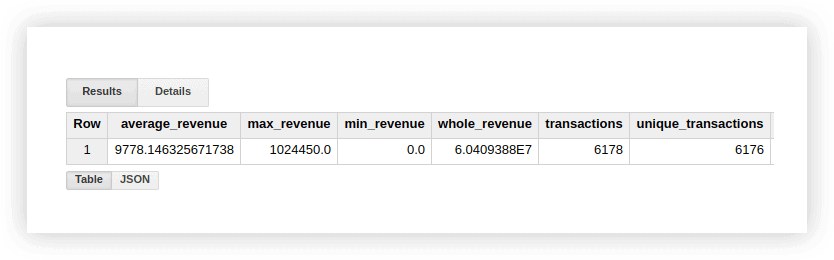
Puteți verifica rezultatele acestor calcule în tabelul inițial cu date demonstrative utilizând funcțiile standard Google Sheets (SUMA, AVG și altele) sau folosind tabele pivot.
După cum puteți vedea din captura de ecran de mai sus, numărul de tranzacții și tranzacții unice este diferit. Aceasta sugerează că există două tranzacții în tabelul nostru cu același ID tranzacție:

Dacă sunteți interesat de tranzacții unice, utilizați o funcție care numără șiruri unice. Alternativ, puteți grupa datele folosind funcția GROUP BY pentru a scăpa de duplicatele înainte de a aplica funcția de agregare.
Date demonstrative pentru practica interogărilor SQL
DescărcațiFuncții de dată
Aceste funcții vă permit să procesați datele: schimbați formatul acestora, selectați câmpul necesar (zi, lună sau an) sau schimbați data cu un anumit interval.
Ele pot fi utile atunci când:
- conversia datelor și orelor din surse diferite într-un singur format pentru a configura analize avansate
- crearea de rapoarte actualizate automat sau declanșarea e-mailurilor (de exemplu, când aveți nevoie de date pentru ultimele două ore, săptămână sau lună)
- crearea de rapoarte de cohortă în care este necesar să se obțină date pentru o perioadă de zile, săptămâni sau luni
Acestea sunt cele mai frecvent utilizate funcții de dată:
| SQL moștenit | SQL standard | Descrierea funcției |
|---|---|---|
| DATA CURENTA() | DATA CURENTA() | Returnează data curentă în formatul % AAAA -% LL-% ZZ. |
| DATE(marca temporală) | DATE(marca temporală) | Convertește data din formatul % AAAA -% LL-% ZZ% H:% M:% C. în formatul % AAAA -% LL-% ZZ. |
| DATE_ADD(marca temporală, interval, interval_units) | DATE_ADD(marca temporală, INTERVAL interval interval_units) | Returnează data marcajului de timp, crescând-o cu intervalul specificat interval.interval_units. În Legacy SQL, poate lua valorile YEAR, MONTH, DAY, HOUR, MINUTE și SECOND, iar în Standard SQL poate lua YEAR, QUARTER, MONTH, SĂPTĂMÂNĂ și ZI. |
| DATE_ADD(marca temporală, - interval, unități_interval) | DATE_SUB(marca temporală, INTERVAL interval interval_units) | Returnează data marcajului de timp, scăzând-o cu intervalul specificat. |
| DATEDIFF(timestamp1, timestamp2) | DATE_DIFF(timestamp1, timestamp2, data_part) | Returnează diferența dintre datele timestamp1 și timestamp2. În Legacy SQL, returnează diferența în zile, iar în Standard SQL, returnează diferența în funcție de valoarea specificată date_part (zi, săptămână, lună, trimestru, an). |
| DAY (marca temporală) | EXTRACT(DAY FROM marca temporală) | Returnează ziua de la data marcajului de timp. Ia valori de la 1 la 31 inclusiv. |
| MONTH(marca temporală) | EXTRACT(LUNA FROM marcaj temporal) | Returnează numărul de secvență al lunii de la data marcajului de timp. Ia valori de la 1 la 12 inclusiv. |
| AN (marca temporală) | EXTRACT(YEAR FROM marca temporală) | Returnează anul de la data marcajului de timp. |
Pentru o listă a tuturor funcțiilor de dată, consultați documentația Legacy SQL și Standard SQL.
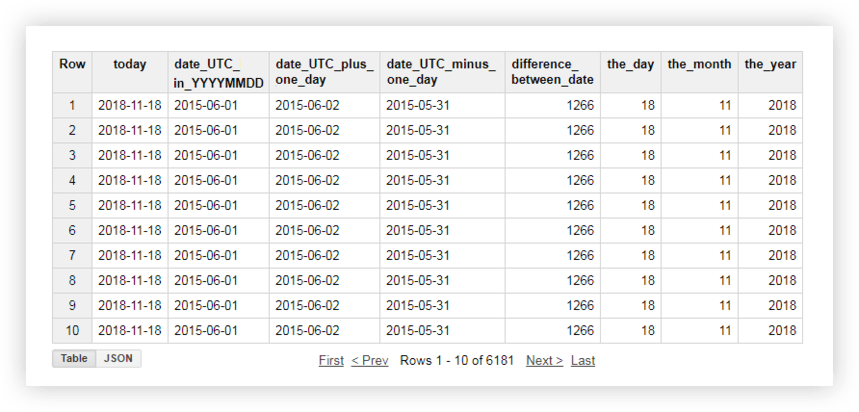
Să aruncăm o privire la datele noastre demonstrative pentru a vedea cum funcționează fiecare dintre aceste funcții. De exemplu, vom obține data curentă, vom transforma data din tabelul original în formatul % YYYY -% LL-% ZZ, o vom elimina și vom adăuga o zi. Apoi vom calcula diferența dintre data curentă și data din tabelul sursă și vom împărți data curentă în câmpuri separate pentru an, lună și zi. Pentru a face acest lucru, puteți copia exemplele de interogări de mai jos și puteți înlocui numele proiectului, setul de date și tabelul de date cu propriile dvs.
#moștenire SQL
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]#SQL standard
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)După rularea interogării, veți primi acest raport:
Vedeți și: Exemple de rapoarte care pot fi create folosind interogări SQL pe date din Google BigQuery și ce valori unice puteți completa datele Google Analytics cu OWOX BI.
Funcții șiruri
Funcțiile șir vă permit să generați un șir, să selectați și să înlocuiți subșiruri și să calculați lungimea unui șir și secvența de index a subșirului din șirul original. De exemplu, cu funcții șir, puteți:
- filtrați un raport cu etichete UTM care sunt transmise la adresa URL a paginii
- aduceți datele într-un singur format dacă numele sursei și campaniei sunt scrise în registre diferite
- înlocuiți datele incorecte dintr-un raport (de exemplu, dacă numele campaniei este tipărit greșit)
Acestea sunt cele mai populare funcții pentru lucrul cu șiruri:
| SQL moștenit | SQL standard | Descrierea funcției |
|---|---|---|
| CONCAT('str1', 'str2') sau 'str1'+ 'str2' | CONCAT('str1', 'str2') | Concatenează „str1” și „str2” într-un singur șir. |
| „str1” CONTINE „str2” | REGEXP_CONTAINS('str1', 'str2') sau 'str1' LIKE '%str2%' | Returnează adevărat dacă șirul „str1” conține șirul „str2”. În SQL standard, șirul „str2” poate fi scris ca o expresie obișnuită folosind biblioteca re2 . |
| LENGTH('str' ) | CHAR_LENGTH('str' )sau CHARACTER_LENGTH('str' ) | Returnează lungimea șirului „str” (număr de caractere). |
| SUBSTR('str', index [, max_len]) | SUBSTR('str', index [, max_len]) | Returnează un subșir de lungime max_len care începe cu un caracter index din șirul „str”. |
| LOWER('str') | LOWER('str') | Convertește toate caracterele din șirul „str în minuscule. |
| SUS (str) | SUS (str) | Convertește toate caracterele din șirul „str” în majuscule. |
| INSTR('str1', 'str2') | STRPOS('str1', 'str2') | Returnează indexul primei apariții a șirului „str2” la șirul „str1”; în caz contrar, returnează 0. |
| REPLACE('str1', 'str2', 'str3') | REPLACE('str1', 'str2', 'str3') | Înlocuiește „str1” cu „str2” cu „str3”. |
Puteți afla mai multe despre toate funcțiile șir în documentația Legacy SQL și Standard SQL.
Să ne uităm la datele demonstrative pentru a vedea cum să folosiți funcțiile descrise. Să presupunem că avem trei coloane separate care conțin valori ale zilei, lunii și anului:

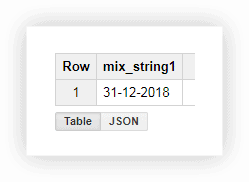
Lucrul cu o dată în acest format nu este foarte convenabil, așa că putem combina valorile într-o singură coloană. Pentru a face acest lucru, utilizați interogările SQL de mai jos și nu uitați să înlocuiți numele proiectului, al setului de date și al tabelului în Google BigQuery.
#moștenire SQL
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1#SQL standard
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1După rularea interogării, primim data într-o coloană:
Adesea, atunci când descărcați o pagină de pe un site web, adresa URL înregistrează valorile variabilelor alese de utilizator. Aceasta poate fi o metodă de plată sau de livrare, numărul tranzacției, indexul magazinului fizic în care cumpărătorul dorește să ridice articolul etc. Folosind o interogare SQL, puteți selecta acești parametri din adresa paginii. Luați în considerare două exemple despre cum și de ce ați putea face acest lucru.
Exemplul 1 . Să presupunem că vrem să știm numărul de achiziții în care utilizatorii ridică mărfuri din magazinele fizice. Pentru a face acest lucru, trebuie să calculăm numărul de tranzacții trimise de la paginile din adresa URL care conțin un subșir shop_id (un index pentru un magazin fizic). Putem face acest lucru cu următoarele interogări:
#moștenire SQL
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check#SQL standard

SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2
SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2Din tabelul rezultat, vedem că 5502 tranzacții (verificare = adevărat) au fost trimise din pagini care conțin shop_id:

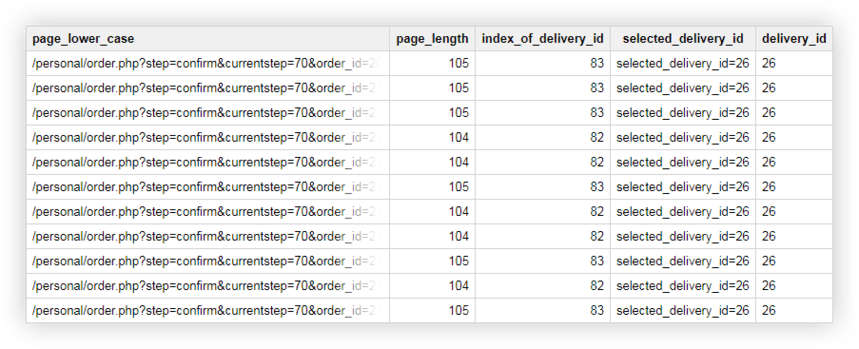
Exemplul 2 . Ați atribuit un delivery_id fiecărei metode de livrare și specificați valoarea acestui parametru în adresa URL a paginii. Pentru a afla ce metodă de livrare a ales utilizatorul, trebuie să selectați delivery_id într-o coloană separată.
Putem folosi următoarele interogări pentru aceasta:
#moștenire SQL
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC#SQL standard
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASCCa rezultat, obținem un tabel ca acesta în Google BigQuery:
Date demonstrative pentru practica interogărilor SQL
DescărcațiFuncțiile ferestrei
Aceste funcții sunt similare cu funcțiile agregate pe care le-am discutat mai sus. Principala diferență este că funcțiile ferestrei nu efectuează calcule pe întregul set de date selectat folosind interogarea, ci doar pe o parte a acestor date - un subset sau o fereastră .
Folosind funcțiile ferestre, puteți agrega date într-o secțiune de grup fără a utiliza funcția JOIN pentru a combina mai multe interogări. De exemplu, puteți calcula venitul mediu pe campanie publicitară sau numărul de tranzacții pe dispozitiv. Adăugând un alt câmp în raport, puteți afla cu ușurință, de exemplu, ponderea veniturilor dintr-o campanie publicitară de Black Friday sau ponderea tranzacțiilor efectuate dintr-o aplicație mobilă.
Împreună cu fiecare funcție din interogare, trebuie să scrieți expresia OVER care definește limitele ferestrei. OVER conține trei componente cu care puteți lucra:
- PARTITION BY — Definește caracteristica prin care împărțiți datele originale în subseturi, cum ar fi clientId sau DayTime
- ORDER BY — Definește ordinea rândurilor dintr-un subset, cum ar fi ora DESC
- WINDOW FRAME — Vă permite să procesați rânduri dintr-un subset al unei anumite caracteristici (de exemplu, numai cele cinci rânduri dinaintea rândului curent)
În acest tabel, am colectat cele mai frecvent utilizate funcții de fereastră:
| SQL moștenit | SQL standard | Descrierea funcției |
|---|---|---|
| AVG(câmp) COUNT(câmp) COUNT(câmp DISTINCT) MAX() MIN() SUMĂ() | AVG([DIstinct] (câmp)) COUNT(câmp) COUNT([DIstinct] (câmp)) MAX(câmp) MIN(câmp) SUM(câmp) | Returnează valoarea medie, număr, maxim, minim și total din coloana câmpului din subsetul selectat. DISTINCT este folosit pentru a calcula numai valori unice (nerepetabile). |
| DENSE_RANK() | DENSE_RANK() | Returnează numărul rândului dintr-un subset. |
| FIRST_VALUE(câmp) | FIRST_VALUE (câmp[{RESPECT | IGNORE} NULLS]) | Returnează valoarea primului rând din coloana câmpului dintr-un subset. În mod implicit, rândurile cu valori goale din coloana câmpului sunt incluse în calcul. RESPECT sau IGNORE NULLS specifică dacă să includă sau să ignore șirurile NULL. |
| LAST_VALUE(câmp) | LAST_VALUE (câmpul [{RESPECT | IGNORE} NULLS]) | Returnează valoarea ultimului rând dintr-un subset din coloana câmpului. În mod implicit, rândurile cu valori goale în coloana câmpului sunt incluse în calcul. RESPECT sau IGNORE NULLS specifică dacă să includă sau să ignore șirurile NULL. |
| LAG(câmp) | LAG (câmp[, offset [, expresie_default]]) | Returnează valoarea rândului anterior în raport cu coloana câmpului curent din subsetul. Decalajul este un număr întreg care specifică numărul de rânduri de compensat în jos față de rândul curent. Expresia_default este valoarea pe care funcția o va returna dacă nu este necesar. șir din submulțiune. |
| LEAD(câmp) | LEAD (câmp[, offset [, expresie_default]]) | Returnează valoarea rândului următor în raport cu coloana câmpului curent din subsetul. Offset este un număr întreg care definește numărul de rânduri pe care doriți să le mutați în sus față de rândul curent. Default_expression este valoarea pe care funcția o va returna dacă nu există un șir necesar în subsetul curent. |
Puteți vedea o listă cu toate funcțiile analitice agregate și funcțiile de navigare în documentația pentru Legacy SQL și Standard SQL.
Exemplul 1 . Să presupunem că vrem să analizăm activitatea clienților în timpul orelor de lucru și non-lucrătoare. Pentru a face acest lucru, trebuie să împărțim tranzacțiile în două grupuri și să calculăm valorile de interes:
- Grupa 1 — Achiziții în timpul programului de lucru de la 9:00 la 18:00
- Grupa 2 — Achiziții în afara orelor de program de la 00:00 la 9:00 și de la 18:00 la 23:59
Pe lângă orele de lucru și non-lucrătoare, o altă variabilă pentru formarea unei ferestre este clientId. Adică, pentru fiecare utilizator, vom avea două ferestre:
| fereastră | clientId | Ziua |
|---|---|---|
| fereastra 1 | clientId 1 | ore de lucru |
| fereastra 2 | clientId 2 | orele nelucrătoare |
| fereastra 3 | clientId 3 | ore de lucru |
| fereastra 4 | ID client 4 | orele nelucrătoare |
| fereastra N | ID client N | ore de lucru |
| fereastra N+1 | clientId N+1 | orele nelucrătoare |
Să folosim datele demonstrative pentru a calcula venitul mediu, maxim, minim și total, numărul total de tranzacții și numărul de tranzacții unice per utilizator în timpul orelor de lucru și în afara orelor de lucru. Solicitările de mai jos ne vor ajuta să facem acest lucru.
#moștenire SQL
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC#SQL standard
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESCSă vedem ce se întâmplă ca rezultat folosind exemplul utilizatorului cu clientId 102041117.1428132012. În tabelul original pentru acest utilizator, avem următoarele date:

Prin rularea interogării, primim un raport care conține venitul mediu, minim, maxim și total de la acest utilizator, precum și numărul total de tranzacții al utilizatorului. După cum puteți vedea în captura de ecran de mai jos, ambele tranzacții au fost efectuate de utilizator în timpul programului de lucru:

Exemplul 2 . Acum pentru o sarcină mai complicată:
- Pune numerele de ordine pentru toate tranzacțiile în fereastră în funcție de momentul executării lor. Amintiți-vă că definim fereastra după utilizator și intervalele de timp de lucru/nefuncțional.
- Raportați veniturile tranzacției următoare/anterioare (față de cea curentă) în fereastră.
- Afișați veniturile primei și ultimelor tranzacții în fereastră.
Pentru a face acest lucru, vom folosi următoarele interogări:
#moștenire SQL
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour#SQL standard
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hourPutem verifica rezultatele calculelor folosind exemplul unui utilizator pe care îl cunoaștem deja: clientId 102041117.1428132012:

Din captura de ecran de mai sus, putem vedea că:
- prima tranzacție a fost la 15:00 și a doua tranzacție a fost la 16:00
- după tranzacție la ora 15:00, a existat o tranzacție la ora 16:00 cu un venit de 25066 (coloana lead_revenue)
- înainte de tranzacție la ora 16:00, a existat o tranzacție la ora 15:00 cu un venit de 3699 (coloana lag_revenue)
- prima tranzacție din fereastră a fost la 15:00, iar venitul pentru această tranzacție a fost 3699 (coloana first_revenue_by_hour)
- interogarea procesează datele rând cu linie, deci pentru tranzacția în cauză, ultima tranzacție din fereastră va fi însăși și valorile din coloanele last_revenue_by_hour și veniturile vor fi aceleași
Articole utile despre Google BigQuery:
- Top 6 instrumente de vizualizare BigQuery
- Cum să încărcați date în Google BigQuery
- Cum să încărcați date brute din Google Ads în Google BigQuery
- Conector Google BigQuery Foi de calcul Google
- Automatizați rapoartele în Foi de calcul Google utilizând datele din Google BigQuery
- Automatizați rapoartele în Google Data Studio pe baza datelor din Google BigQuery
Dacă doriți să colectați date neeșantionate de pe site-ul dvs. în Google BigQuery, dar nu știți de unde să începeți, rezervați o demonstrație. Vă vom spune despre toate posibilitățile pe care le aveți cu BigQuery și OWOX BI.
Clienții noștri
crește cu 22% mai rapid
Creșteți mai repede, măsurând ceea ce funcționează cel mai bine în marketingul dvs
Analizați-vă eficiența de marketing, găsiți zonele de creștere, creșteți rentabilitatea investiției
Obțineți o demonstrațieConcluzii
În acest articol, ne-am uitat la cele mai populare grupuri de funcții: agregat, dată, șir și fereastră. Cu toate acestea, Google BigQuery are multe mai multe funcții utile, inclusiv:
- funcții de casting care vă permit să convertiți datele într-un anumit format
- Funcții wildcard de tabel care vă permit să accesați mai multe tabele dintr-un set de date
- funcții de expresie regulată care vă permit să descrieți modelul unei interogări de căutare și nu valoarea sa exactă
Cu siguranță vom scrie despre aceste funcții pe blogul nostru. Între timp, puteți încerca toate funcțiile descrise în acest articol folosind datele noastre demonstrative.
Date demonstrative pentru practica interogărilor SQL
Descărcați