
Google BigQuery 主要功能概覽——練習編寫營銷分析請求
已發表: 2022-04-12企業積累的信息越多,存儲在哪裡的問題就越尖銳。 如果您沒有能力或不想維護自己的服務器,Google BigQuery (GBQ) 可以提供幫助。 BigQuery 為處理大數據提供了快速、經濟高效且可擴展的存儲,它允許您使用類似 SQL 的語法以及標準和用戶定義的函數來編寫查詢。
在本文中,我們將了解 BigQuery 的主要功能,並通過具體示例展示它們的可能性。 您將學習如何編寫基本查詢並在演示數據上對其進行測試。
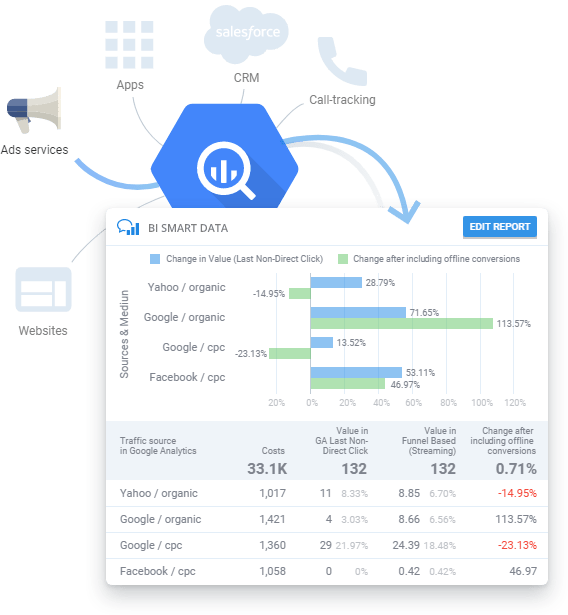
無需技術培訓或 SQL 知識即可構建 GBQ 數據報告。
您是否經常需要有關廣告活動的報告,但沒有時間研究 SQL 或等待分析師的回复? 使用 OWOX BI,您無需了解數據的結構即可創建報告。 只需選擇您想在智能數據報告中看到的參數和指標。 OWOX BI Smart Data 將以您可以理解的方式立即可視化您的數據。
目錄
- 什麼是 SQL,BigQuery 支持哪些方言
- 從哪兒開始
- 谷歌 BigQuery 功能
- 聚合函數
- 日期函數
- 字符串函數
- 窗口函數
- 結論
什麼是 SQL,BigQuery 支持哪些方言
結構化查詢語言 (SQL) 允許您從大型數組中檢索數據、添加數據和修改數據。 Google BigQuery 支持兩種 SQL 方言:標準 SQL 和過時的舊版 SQL。
選擇哪種方言取決於您的偏好,但 Google 建議使用標準 SQL 以獲得以下好處:
- 嵌套和重複字段的靈活性和功能
- 支持 DML 和 DDL 語言,允許您更改表中的數據以及管理 GBQ 中的表和視圖
- 與舊版 SQL 相比,處理大量數據的速度更快
- 支持所有未來的 BigQuery 更新
您可以在 BigQuery 文檔中詳細了解方言差異。
另請參閱:Google BigQuery 的新標準 SQL 方言與舊版 SQL 相比有哪些優勢,您可以使用它解決哪些業務任務?
默認情況下,Google BigQuery 查詢在舊版 SQL 上運行。
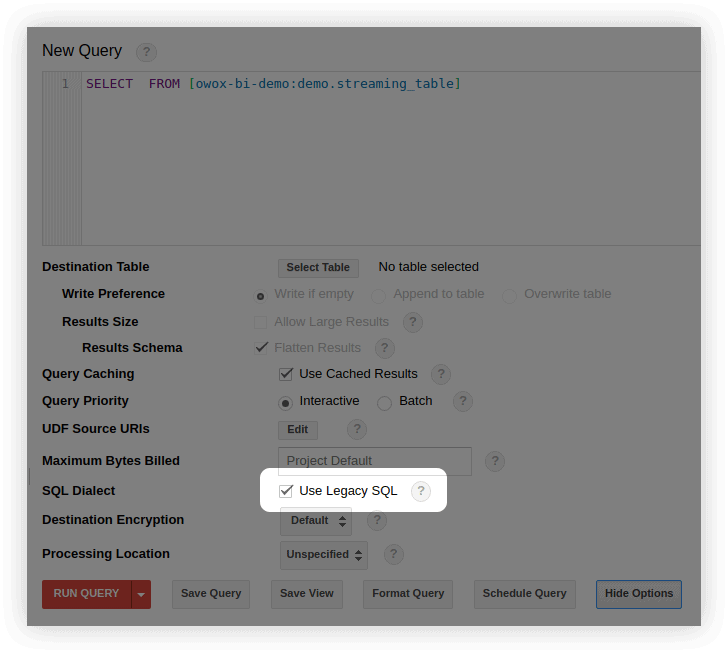
您可以通過多種方式切換到標準 SQL:
- 在 BigQuery 界面的查詢編輯窗口中,選擇Show Options並刪除Use Legacy SQL旁邊的複選標記:
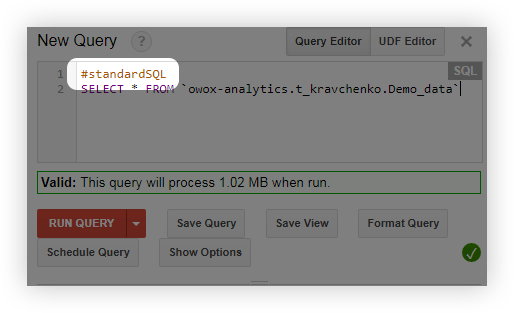
- 在查詢之前,添加 #standardSQL 行並使用新行開始查詢:
從哪兒開始
因此,您可以與我們一起練習和運行查詢,我們準備了一個包含演示數據的表。 填寫下面的表格,我們將通過電子郵件將其發送給您。


SQL 查詢練習的演示數據
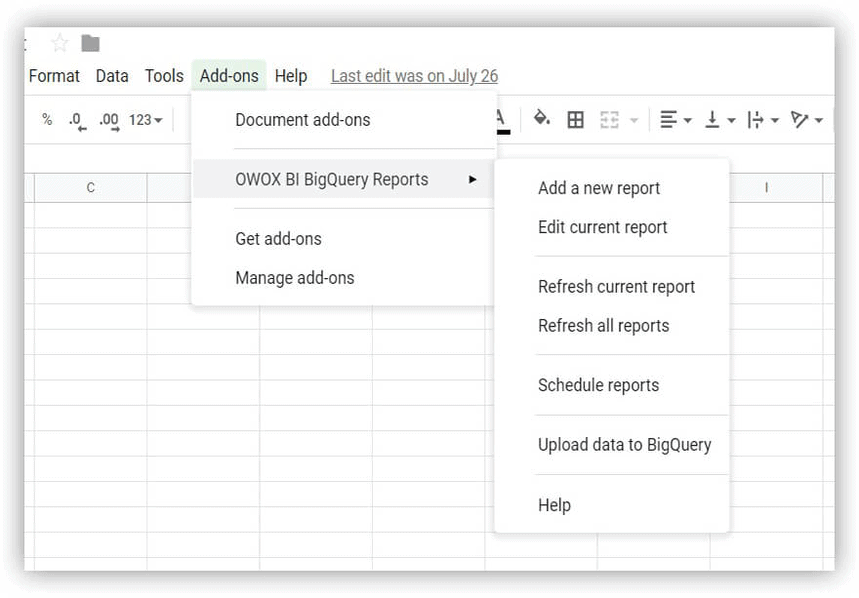
下載要開始使用,請下載您的演示數據表並將其上傳到您的 Google BigQuery 項目。 最簡單的方法是使用 OWOX BI BigQuery Reports 插件。
- 打開 Google 表格並安裝 OWOX BI BigQuery Reports 插件。
- 打開您下載的包含演示數據的表,然後選擇OWOX BI BigQuery Reports –> Upload Data to BigQuery :
- 在打開的窗口中,選擇您的 Google BigQuery 項目、一個數據集,然後為將存儲加載數據的表命名。
- 指定加載數據的格式(如屏幕截圖所示):

如果您在 Google BigQuery 中沒有項目,請創建一個。 為此,您需要在 Google Cloud Platform 中有一個有效的結算帳戶。 不要害怕您需要關聯銀行卡:在您不知情的情況下不會向您收取任何費用。 此外,當您註冊時,您將在 12 個月內收到 300 美元,可用於數據存儲和處理。
OWOX BI 可幫助您將來自不同系統的數據合併到 BigQuery 中:關於您網站上的用戶操作、電話、來自 CRM 的訂單、電子郵件、廣告費用的數據。 您可以使用 OWOX BI 自定義高級分析並自動生成任何復雜性的報告。
在談論 Google BigQuery 功能之前,讓我們記住舊 SQL 和標準 SQL 方言中的基本查詢是什麼樣的:
| 詢問 | 舊版 SQL | 標準 SQL |
|---|---|---|
| 從表中選擇字段 | 選擇字段1,字段2 | 選擇字段1,字段2 |
| 選擇要從中選擇字段的表 | FROM [projectID:dataSet.tableName] | FROM `projectID.dataSet.tableName` |
| 選擇過濾值所依據的參數 | WHERE 字段1=值 | WHERE 字段1=值 |
| 選擇用於對結果進行分組的字段 | GROUP BY 字段1,字段2 | GROUP BY 字段1,字段2 |
| 選擇如何訂購結果 | ORDER BY field1 ASC(升序)或 DESC(降序) | ORDER BY field1 ASC(升序)或 DESC(降序) |
谷歌 BigQuery 功能
在構建查詢時,您最常使用聚合、日期、字符串和窗口函數。 讓我們仔細看看這些函數組中的每一個。
另請參閱:如何開始使用雲存儲 - 創建數據集和表並配置將數據導入 Google BigQuery。
聚合函數
聚合函數為整個表提供匯總值。 例如,您可以使用它們來計算平均支票大小或每月總收入,或者您可以使用它們來選擇購買次數最多的用戶細分。
這些是最流行的聚合函數:
| 舊版 SQL | 標準 SQL | 函數的作用 |
|---|---|---|
| 平均(場) | AVG([DISTINCT] (字段)) | 返回字段列的平均值。 在標準 SQL 中,當您添加 DISTINCT 條件時,僅考慮字段列中具有唯一(非重複)值的行的平均值。 |
| 最大值(字段) | 最大值(字段) | 返回字段列的最大值。 |
| 最小值(字段) | 最小值(字段) | 返回字段列的最小值。 |
| 總和(字段) | 總和(字段) | 從字段列返回值的總和。 |
| 計數(字段) | 計數(字段) | 返回字段列中的行數。 |
| EXACT_COUNT_DISTINCT(字段) | 計數([DISTINCT](字段)) | 返回字段列中的唯一行數。 |
有關所有聚合函數的列表,請參閱 Legacy SQL 和 Standard SQL 文檔。
讓我們看一下演示數據,看看這些函數是如何工作的。 我們可以計算交易的平均收入、最高和最低金額的購買、總收入、總交易以及唯一交易的數量(以檢查是否重複購買)。 為此,我們將編寫一個查詢,在其中指定 Google BigQuery 項目、數據集和表的名稱。
#舊版 SQL
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]#標準 SQL
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`結果,我們將得到以下信息:
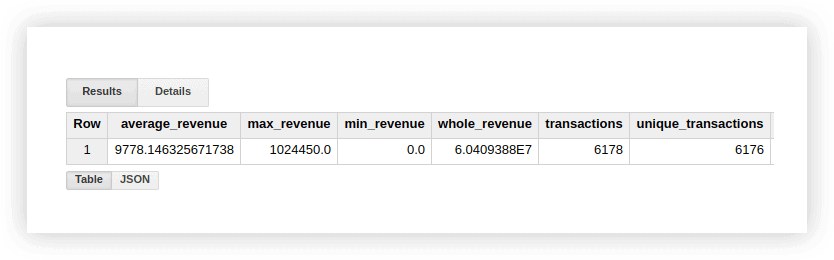
您可以使用標準 Google 表格函數(SUM、AVG 等)或使用數據透視表在原始表中使用演示數據檢查這些計算的結果。
從上面的截圖可以看出,交易數量和唯一交易數量是不同的。 這表明我們的表中有兩個事務具有相同的 transactionId:

如果您對唯一交易感興趣,請使用計算唯一字符串的函數。 或者,您可以使用 GROUP BY 函數對數據進行分組,以在應用聚合函數之前消除重複項。
SQL 查詢練習的演示數據
下載日期函數
這些功能允許您處理日期:更改其格式、選擇必要的字段(日、月或年),或將日期移動特定間隔。
它們在以下情況下可能有用:
- 將不同來源的日期和時間轉換為單一格式以設置高級分析
- 創建自動更新的報告或觸發郵件(例如,當您需要過去兩個小時、一周或一個月的數據時)
- 創建需要在幾天、幾週或幾個月內獲取數據的同類群組報告
這些是最常用的日期函數:
| 舊版 SQL | 標準 SQL | 功能說明 |
|---|---|---|
| 當前日期() | 當前日期() | 以 % YYYY -% MM-% DD 格式返回當前日期。 |
| 日期(時間戳) | 日期(時間戳) | 將日期從 % YYYY -% MM-% DD% H:% M:% C. 轉換為 % YYYY -% MM-% DD 格式。 |
| DATE_ADD(時間戳,間隔,interval_units) | DATE_ADD(時間戳,INTERVAL 間隔interval_units) | 返回時間戳日期,將其增加指定的時間間隔 interval.interval_units。在舊版 SQL 中,它可以採用 YEAR、MONTH、DAY、HOUR、MINUTE 和 SECOND 值,而在標準 SQL 中,它可以採用 YEAR、QUARTER、MONTH、周和日。 |
| DATE_ADD(時間戳,- 間隔,interval_units) | DATE_SUB(時間戳,INTERVAL 間隔interval_units) | 返回時間戳日期,按指定的時間間隔遞減。 |
| DATEDIFF(時間戳 1,時間戳 2) | DATE_DIFF(timestamp1, timestamp2, date_part) | 返回 timestamp1 和 timestamp2 日期之間的差異。 在舊版 SQL 中,以天為單位返回差值,而在標準 SQL 中,根據指定的 date_part 值(日、週、月、季度、年)返回差值。 |
| DAY(時間戳) | 提取(日期從時間戳) | 返回時間戳日期的日期。 取值從 1 到 31(包括 1 到 31)。 |
| 月(時間戳) | 提取(從時間戳開始的月份) | 從時間戳日期返回月份序列號。 取值從 1 到 12(包括 1 到 12)。 |
| 年(時間戳) | EXTRACT(來自時間戳的年份) | 從時間戳日期返回年份。 |
有關所有日期函數的列表,請參閱 Legacy SQL 和 Standard SQL 文檔。
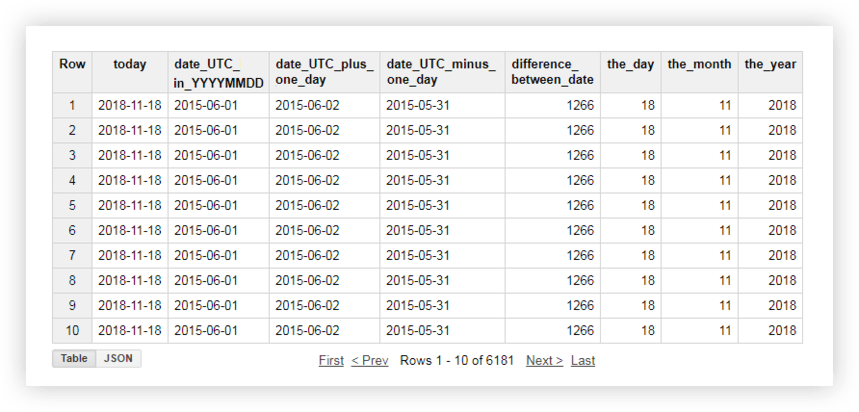
讓我們看一下我們的演示數據,看看這些函數是如何工作的。 例如,我們將獲取當前日期,將原始表格中的日期轉換為 %YYYY -% MM-% DD 格式,將其取出,並在其上添加一天。 然後我們將計算當前日期與源表中的日期之間的差異,並將當前日期分解為單獨的年、月和日字段。 為此,您可以復制下面的示例查詢並將項目名稱、數據集和數據表替換為您自己的。
#舊版 SQL
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]#標準 SQL
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)運行查詢後,您將收到此報告:
另請參閱:可以使用 SQL 查詢對 Google BigQuery 中的數據構建的報告示例,以及您可以使用 OWOX BI 補充 Google Analytics 數據的獨特指標。
字符串函數
字符串函數允許您生成字符串、選擇和替換子字符串,以及計算字符串的長度和子字符串在原始字符串中的索引序列。 例如,使用字符串函數,您可以:
- 過濾帶有傳遞到頁面 URL 的 UTM 標記的報告
- 如果源名稱和活動名稱寫在不同的寄存器中,則將數據轉換為單一格式
- 替換報告中的錯誤數據(例如,如果活動名稱打印錯誤)
這些是處理字符串的最流行的函數:
| 舊版 SQL | 標準 SQL | 功能說明 |
|---|---|---|
| CONCAT('str1', 'str2') 或 'str1'+ 'str2' | 連接('str1','str2') | 將“str1”和“str2”連接成一個字符串。 |
| “str1”包含“str2” | REGEXP_CONTAINS('str1', 'str2') 或 'str1' LIKE '%str2%' | 如果字符串“str1”包含字符串“str2”,則返回 true。在標準 SQL 中,可以使用re2 庫將字符串“str2”寫為正則表達式。 |
| 長度('str') | CHAR_LENGTH('str') 或 CHARACTER_LENGTH('str') | 返回字符串 'str' 的長度(字符數)。 |
| SUBSTR('str', 索引 [, max_len]) | SUBSTR('str', 索引 [, max_len]) | 返回長度為 max_len 的子字符串,該子字符串以字符串 'str' 中的索引字符開頭。 |
| 降低('str') | 降低('str') | 將字符串 'str 中的所有字符轉換為小寫。 |
| 上(字符串) | 上(字符串) | 將字符串 'str' 中的所有字符轉換為大寫。 |
| INSTR('str1', 'str2') | STRPOS('str1', 'str2') | 將字符串“str2”第一次出現的索引返回到字符串“str1”; 否則,返回 0。 |
| 替換('str1','str2','str3') | 替換('str1','str2','str3') | 將 'str1' 替換為 'str2' 和 'str3'。 |
您可以在 Legacy SQL 和 Standard SQL 文檔中了解有關所有字符串函數的更多信息。
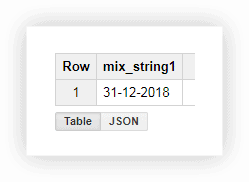
讓我們看一下演示數據,看看如何使用所描述的功能。 假設我們有三個單獨的列,分別包含日、月和年值:

使用這種格式的日期不是很方便,因此我們可以將這些值合併到一列中。 為此,請使用下面的 SQL 查詢,並記住在 Google BigQuery 中替換您的項目、數據集和表的名稱。
#舊版 SQL
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1#標準 SQL
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1運行查詢後,我們在一列中收到日期:
通常,當您在網站上下載頁面時,URL 會記錄用戶選擇的變量的值。 這可以是付款或送貨方式、交易編號、買家想要取貨的實體店的索引等。使用 SQL 查詢,您可以從頁面地址中選擇這些參數。 考慮兩個例子,說明你如何以及為什麼這樣做。
示例 1 。 假設我們想知道用戶從實體店取貨的購買次數。 為此,我們需要計算從 URL 中包含子字符串 shop_id(實體店索引)的頁面發送的交易數量。 我們可以通過以下查詢來做到這一點:
#舊版 SQL
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check#標準 SQL
SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2
SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2從結果表中,我們看到從包含 shop_id 的頁面發送了 5502 筆交易(check = true):

示例 2 。 您已為每種交付方式分配了一個 delivery_id,並在頁面 URL 中指定了此參數的值。 要了解用戶選擇了哪種交付方式,您需要在單獨的列中選擇 delivery_id。
我們可以為此使用以下查詢:
#舊版 SQL
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC#標準 SQL

SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASC結果,我們在 Google BigQuery 中得到了一個這樣的表:
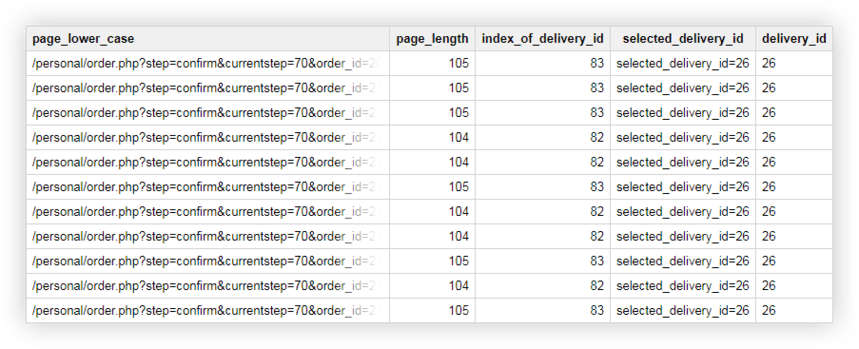
SQL 查詢練習的演示數據
下載窗口函數
這些函數類似於我們上面討論的聚合函數。 主要區別在於窗口函數不會對使用查詢選擇的整個數據集進行計算,而只會對部分數據(子集或窗口)進行計算。
使用窗口函數,您可以在組部分中聚合數據,而無需使用 JOIN 函數來組合多個查詢。 例如,您可以計算每個廣告活動的平均收入或每台設備的交易次數。 通過在報告中添加另一個字段,您可以輕鬆找出黑色星期五廣告活動的收入份額或移動應用程序進行的交易的份額。
連同查詢中的每個函數,您必須拼出定義窗口邊界的 OVER 表達式。 OVER 包含三個可以使用的組件:
- PARTITION BY — 定義將原始數據劃分為子集的特徵,例如 clientId 或 DayTime
- ORDER BY — 定義子集中行的順序,例如小時 DESC
- WINDOW FRAME - 允許您處理特定特徵子集中的行(例如,僅當前行之前的五行)
在此表中,我們收集了最常用的窗口函數:
| 舊版 SQL | 標準 SQL | 功能說明 |
|---|---|---|
| 平均(場) 計數(字段) 計數(DISTINCT 字段) 最大限度() 最小() 和() | AVG([DISTINCT] (字段)) 計數(字段) 計數([DISTINCT](字段)) 最大值(字段) 最小值(字段) 總和(字段) | 從所選子集中的字段列返回平均值、數字、最大值、最小值和總值。DISTINCT 僅用於計算唯一(非重複)值。 |
| DENSE_RANK() | DENSE_RANK() | 返回子集中的行號。 |
| FIRST_VALUE(字段) | FIRST_VALUE(字段[{RESPECT | IGNORE} NULLS]) | 返回子集中字段列的第一行的值。 默認情況下,計算中包括字段列中具有空值的行。 RESPECT 或 IGNORE NULLS 指定是包含還是忽略 NULL 字符串。 |
| LAST_VALUE(字段) | LAST_VALUE(字段 [{RESPECT | IGNORE} NULLS]) | 從字段列返回子集中最後一行的值。默認情況下,字段列中具有空值的行包含在計算中。 RESPECT 或 IGNORE NULLS 指定是包含還是忽略 NULL 字符串。 |
| 滯後(場) | LAG (field[, offset [, default_expression]]) | 返回相對於子集中當前字段列的前一行的值。Offset 是一個整數,指定從當前行向下偏移的行數。Default_expression 是函數在不需要時返回的值子集中的字符串。 |
| 領導(領域) | LEAD (field[, offset [, default_expression]]) | 返回相對於子集中當前字段列的下一行的值。 偏移量是一個整數,它定義了要相對於當前行向上移動的行數。Default_expression 是如果當前子集中沒有必需的字符串,函數將返回的值。 |
您可以在 Legacy SQL 和 Standard SQL 的文檔中查看所有聚合分析函數和導航函數的列表。
示例 1 。 假設我們要分析客戶在工作時間和非工作時間的活動。 為此,我們需要將交易分為兩組併計算感興趣的指標:
- 第 1 組 — 工作時間 9:00 至 18:00 購買
- 第 2 組 — 00:00 至 9:00 和 18:00 至 23:59 下班後購買
除了工作時間和非工作時間,另一個形成窗口的變量是clientId。 也就是說,對於每個用戶,我們將有兩個窗口:
| 窗戶 | 客戶 ID | 白天 |
|---|---|---|
| 窗口 1 | 客戶編號 1 | 工作時間 |
| 窗口 2 | 客戶 ID 2 | 非工作時間 |
| 窗口 3 | 客戶 ID 3 | 工作時間 |
| 窗口 4 | 客戶 ID 4 | 非工作時間 |
| 窗口 N | 客戶編號 N | 工作時間 |
| 窗口 N+1 | 客戶編號 N+1 | 非工作時間 |
讓我們使用演示數據來計算平均、最大、最小和總收入、交易總數以及每個用戶在工作和非工作時間的唯一交易數。 下面的請求將幫助我們做到這一點。
#舊版 SQL
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC#標準 SQL
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC讓我們以 clientId 為 102041117.1428132012 的用戶為例來看看結果如何。 在這個用戶的原始表中,我們有以下數據:

通過運行查詢,我們會收到一份報告,其中包含來自該用戶的平均、最低、最高和總收入以及用戶的交易總數。 正如您在下面的屏幕截圖中看到的,這兩項交易都是用戶在工作時間進行的:

示例 2 。 現在執行更複雜的任務:
- 根據執行時間將所有事務的序列號放在窗口中。 回想一下,我們按用戶和工作/非工作時間段定義窗口。
- 報告窗口內下一個/上一個交易(相對於當前)的收入。
- 在窗口中顯示第一筆和最後一筆交易的收入。
為此,我們將使用以下查詢:
#舊版 SQL
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour#標準 SQL
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour我們可以使用我們已經知道的用戶示例來檢查計算結果:clientId 102041117.1428132012:

從上面的截圖中,我們可以看到:
- 第一筆交易是在 15:00,第二筆交易是在 16:00
- 15:00交易後,16:00有一筆交易,收益為25066(列lead_revenue)
- 16:00交易前,15:00有一筆交易,收益為3699(列lag_revenue)
- 窗口內的第一筆交易是在 15:00,此筆交易的收入為 3699(first_revenue_by_hour 列)
- 查詢逐行處理數據,因此對於有問題的交易,窗口中的最後一筆交易將是其本身,並且 last_revenue_by_hour 和收入列中的值將相同
關於 Google BigQuery 的有用文章:
- 6 大 BigQuery 可視化工具
- 如何將數據上傳到 Google BigQuery
- 如何將原始數據從 Google Ads 上傳到 Google BigQuery
- Google BigQuery Google 表格連接器
- 使用來自 Google BigQuery 的數據自動生成 Google 表格中的報告
- 根據來自 Google BigQuery 的數據在 Google Data Studio 中自動生成報告
如果您想在 Google BigQuery 中從您的網站收集非抽樣數據,但不知道從哪裡開始,請預訂演示。 我們將告訴您使用 BigQuery 和 OWOX BI 獲得的所有可能性。
我們的客戶
生長 快22%
通過衡量在您的營銷中最有效的方法來更快地增長
分析您的營銷效率,找到增長領域,提高投資回報率
獲取演示結論
在本文中,我們研究了最流行的函數組:聚合、日期、字符串和窗口。 但是,Google BigQuery 有更多有用的功能,包括:
- 允許您將數據轉換為特定格式的轉換函數
- 表通配符函數,允許您訪問數據集中的多個表
- 允許您描述搜索查詢模型而不是其確切值的正則表達式函數
我們一定會在我們的博客上寫下這些功能。 同時,您可以使用我們的演示數據試用本文中描述的所有功能。
SQL 查詢練習的演示數據
下載