
Descripción general de las funciones principales de Google BigQuery: practique la redacción de solicitudes para análisis de marketing
Publicado: 2022-04-12Cuanta más información acumula una empresa, más aguda es la cuestión de dónde almacenarla. Si no tiene la capacidad o el deseo de mantener sus propios servidores, Google BigQuery (GBQ) puede ayudarlo. BigQuery proporciona almacenamiento rápido, rentable y escalable para trabajar con macrodatos, y le permite escribir consultas con una sintaxis similar a la de SQL, así como funciones estándar y definidas por el usuario.
En este artículo, analizamos las principales funciones de BigQuery y mostramos sus posibilidades mediante ejemplos específicos. Aprenderá a escribir consultas básicas y probarlas en datos de demostración.
Cree informes sobre datos de GBQ sin formación técnica ni conocimientos de SQL.
¿Necesita regularmente informes sobre campañas publicitarias pero no tiene tiempo para estudiar SQL o esperar una respuesta de sus analistas? Con OWOX BI, puede crear informes sin necesidad de comprender cómo se estructuran sus datos. Simplemente seleccione los parámetros y las métricas que desea ver en su informe de Smart Data. OWOX BI Smart Data visualizará instantáneamente sus datos de una manera que pueda entender.
Tabla de contenido
- Qué es SQL y qué dialectos admite BigQuery
- Donde empezar
- Funciones de Google BigQuery
- Funciones agregadas
- Funciones de fecha
- Funciones de cadena
- Funciones de ventana
- Conclusiones
Qué es SQL y qué dialectos admite BigQuery
El lenguaje de consulta estructurado (SQL) le permite recuperar datos, agregar datos y modificar datos en matrices grandes. Google BigQuery admite dos dialectos de SQL: SQL estándar y SQL heredado obsoleto.
El dialecto que elija depende de sus preferencias, pero Google recomienda usar SQL estándar para obtener estos beneficios:
- Flexibilidad y funcionalidad para campos anidados y repetitivos
- Compatibilidad con los lenguajes DML y DDL, lo que le permite cambiar datos en tablas, así como administrar tablas y vistas en GBQ
- Procesamiento más rápido de grandes cantidades de datos en comparación con Legacy SQL
- Compatibilidad con todas las futuras actualizaciones de BigQuery
Puede obtener más información sobre las diferencias de dialecto en la documentación de BigQuery.
Consulte también: ¿Cuáles son las ventajas del nuevo dialecto SQL estándar de Google BigQuery sobre SQL heredado y qué tareas comerciales puede resolver con él?
De forma predeterminada, las consultas de Google BigQuery se ejecutan en SQL heredado.
Puede cambiar a SQL estándar de varias maneras:
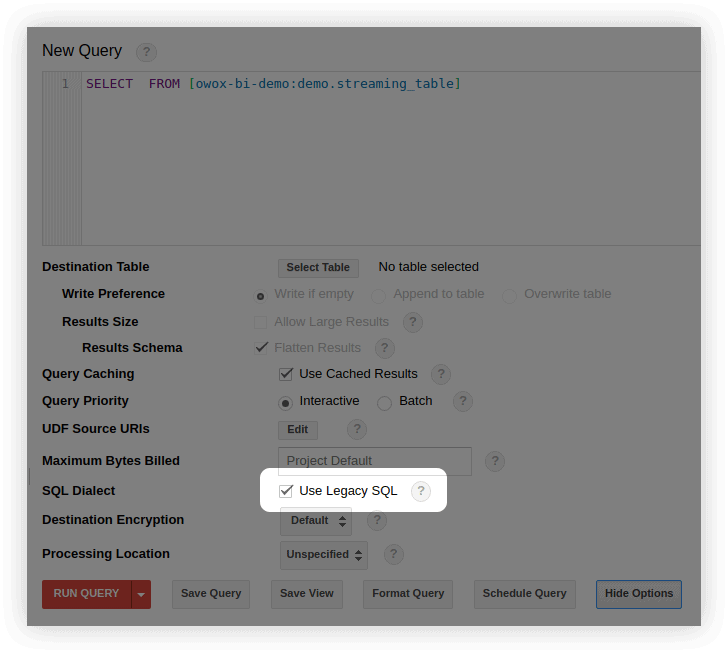
- En la interfaz de BigQuery, en la ventana de edición de consultas, seleccione Mostrar opciones y elimine la marca de verificación junto a Usar SQL heredado :
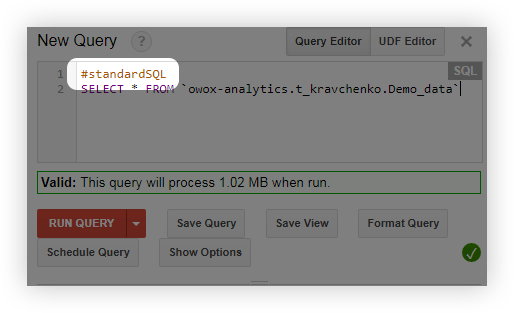
- Antes de consultar, agregue la línea #standardSQL y comience su consulta con una nueva línea:
Donde empezar
Para que puedas practicar y realizar consultas con nosotros, hemos preparado una tabla con datos de demostración. Rellena el siguiente formulario y te lo enviaremos por correo electrónico.


Datos de demostración para la práctica de consultas SQL
Descargar Para comenzar, descargue su tabla de datos de demostración y cárguela en su proyecto de Google BigQuery. La forma más sencilla de hacerlo es con el complemento OWOX BI BigQuery Reports.
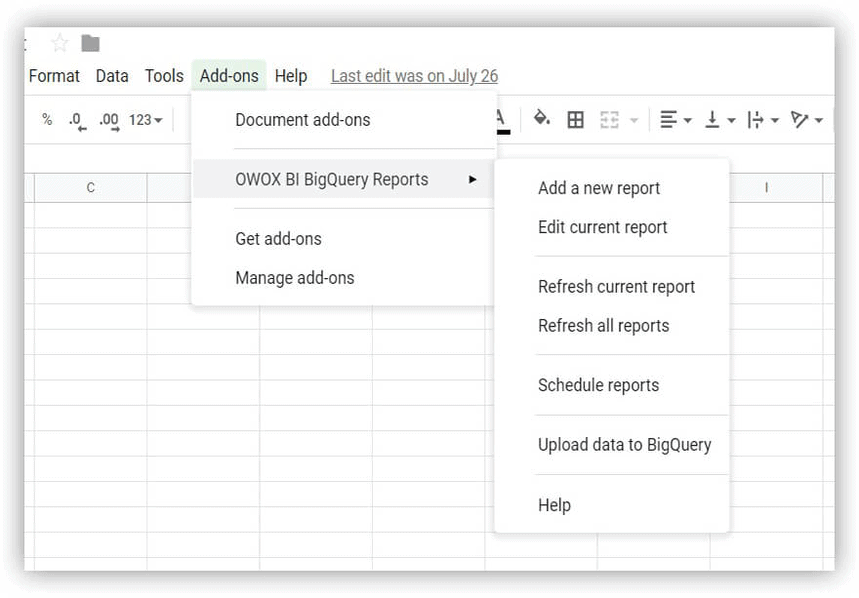
- Abra Hojas de cálculo de Google e instale el complemento OWOX BI BigQuery Reports.
- Abra la tabla que descargó que contiene datos de demostración y seleccione OWOX BI BigQuery Reports -> Cargar datos en BigQuery :
- En la ventana que se abre, elija su proyecto de Google BigQuery, un conjunto de datos, y piense en un nombre para la tabla en la que se almacenarán los datos cargados.
- Especifique un formato para los datos cargados (como se muestra en la captura de pantalla):

Si no tiene un proyecto en Google BigQuery, cree uno. Para hacer esto, necesitará una cuenta de facturación activa en Google Cloud Platform. Que no te asuste la necesidad de vincular una tarjeta bancaria: no se te cobrará nada sin tu conocimiento. Además, cuando se registre, recibirá $300 por 12 meses que podrá gastar en almacenamiento y procesamiento de datos.
OWOX BI lo ayuda a combinar datos de diferentes sistemas en BigQuery: datos sobre las acciones de los usuarios en su sitio web, llamadas, pedidos de su CRM, correos electrónicos, costos publicitarios. Puede usar OWOX BI para personalizar análisis avanzados y automatizar informes de cualquier complejidad.
Antes de hablar sobre las funciones de Google BigQuery, recordemos cómo se ven las consultas básicas en los dialectos SQL heredado y SQL estándar:
| Consulta | SQL heredado | SQL estándar |
|---|---|---|
| Seleccionar campos de la tabla | SELECCIONA campo 1, campo 2 | SELECCIONA campo 1, campo 2 |
| Seleccione una tabla de la que elegir campos | DESDE [ID del proyecto: conjunto de datos. nombre de la tabla] | DESDE `projectID.dataSet.tableName` |
| Seleccionar parámetro por el cual filtrar valores | DONDE campo1=valor | DONDE campo1=valor |
| Seleccionar campos por los que agrupar los resultados | AGRUPAR POR campo 1, campo 2 | AGRUPAR POR campo 1, campo 2 |
| Seleccione cómo ordenar los resultados | ORDENAR POR campo1 ASC (ascendente) o DESC (descendente) | ORDENAR POR campo1 ASC (ascendente) o DESC (descendente) |
Funciones de Google BigQuery
Al crear consultas, utilizará con mayor frecuencia las funciones de agregación, fecha, cadena y ventana. Echemos un vistazo más de cerca a cada uno de estos grupos de funciones.
Consulte también: Cómo comenzar a trabajar con el almacenamiento en la nube: cree un conjunto de datos y tablas y configure la importación de datos a Google BigQuery.
Funciones agregadas
Las funciones agregadas proporcionan valores de resumen para una tabla completa. Por ejemplo, puede usarlos para calcular el tamaño promedio del cheque o el ingreso total por mes, o puede usarlos para seleccionar el segmento de usuarios que realizó la cantidad máxima de compras.
Estas son las funciones agregadas más populares:
| SQL heredado | SQL estándar | que hace la funcion |
|---|---|---|
| PROMEDIO(campo) | PROMEDIO([DISTINTO] (campo)) | Devuelve el valor promedio de la columna de campo. En SQL estándar, cuando agrega una condición DISTINCT, el promedio se considera solo para filas con valores únicos (no repetidos) en la columna de campo. |
| MAX(campo) | MAX(campo) | Devuelve el valor máximo de la columna de campo. |
| MIN(campo) | MIN(campo) | Devuelve el valor mínimo de la columna de campo. |
| SUMA(campo) | SUMA(campo) | Devuelve la suma de los valores de la columna de campo. |
| CONTAR(campo) | CONTAR(campo) | Devuelve el número de filas en la columna de campo. |
| EXACT_COUNT_DISTINCT(campo) | COUNT([DISTINCT] (campo)) | Devuelve el número de filas únicas en la columna de campo. |
Para obtener una lista de todas las funciones agregadas, consulte la documentación de SQL heredado y SQL estándar.
Veamos los datos de demostración para ver cómo funcionan estas funciones. Podemos calcular el ingreso promedio por transacciones, las compras por los montos más altos y más bajos, los ingresos totales, las transacciones totales y la cantidad de transacciones únicas (para verificar si las compras se duplicaron). Para ello, escribiremos una consulta en la que especificaremos el nombre de nuestro proyecto Google BigQuery, el conjunto de datos y la tabla.
#SQL heredado
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]#SQL estándar
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`Como resultado, obtendremos lo siguiente:
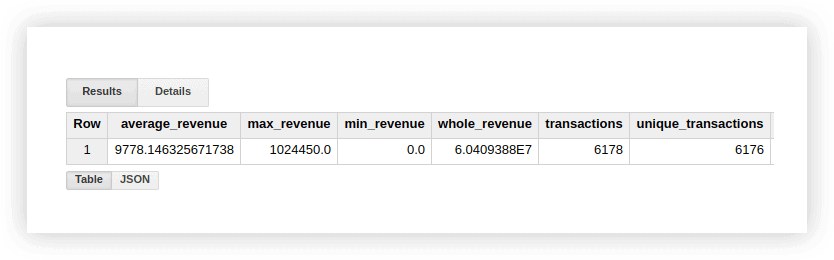
Puede verificar los resultados de estos cálculos en la tabla original con datos de demostración usando las funciones estándar de Google Sheets (SUM, AVG y otras) o usando tablas dinámicas.
Como puede ver en la captura de pantalla anterior, la cantidad de transacciones y transacciones únicas es diferente. Esto sugiere que hay dos transacciones en nuestra tabla con el mismo ID de transacción:

Si está interesado en transacciones únicas, use una función que cuente cadenas únicas. Alternativamente, puede agrupar datos usando la función GROUP BY para deshacerse de los duplicados antes de aplicar la función agregada.
Datos de demostración para la práctica de consultas SQL
DescargarFunciones de fecha
Estas funciones le permiten procesar fechas: cambie su formato, seleccione el campo necesario (día, mes o año) o cambie la fecha en un cierto intervalo.
Pueden ser útiles cuando:
- convertir fechas y horas de diferentes fuentes a un solo formato para configurar análisis avanzados
- crear informes actualizados automáticamente o enviar correos electrónicos (por ejemplo, cuando necesite datos de las últimas dos horas, semana o mes)
- crear informes de cohortes en los que es necesario obtener datos para un período de días, semanas o meses
Estas son las funciones de fecha más utilizadas:
| SQL heredado | SQL estándar | Función descriptiva |
|---|---|---|
| FECHA ACTUAL() | FECHA ACTUAL() | Devuelve la fecha actual en el formato % AAAA -% MM-% DD. |
| FECHA (marca de tiempo) | FECHA (marca de tiempo) | Convierte la fecha del formato % AAAA -% MM-% DD% H:% M:% C. al formato % AAAA -% MM-% DD. |
| DATE_ADD(marca de tiempo, intervalo, unidades_intervalo) | FECHA_AÑADIR(marca de tiempo, INTERVALO intervalo unidades_intervalo) | Devuelve la fecha de la marca de tiempo, aumentándola en el intervalo especificado interval.interval_units. En Legacy SQL, puede tomar los valores AÑO, MES, DÍA, HORA, MINUTO y SEGUNDO, y en SQL estándar puede tomar AÑO, TRIMESTRE, MES, SEMANA y DÍA. |
| DATE_ADD(marca de tiempo, - intervalo, unidades_intervalo) | DATE_SUB(marca de tiempo, INTERVALO intervalo intervalo_unidades) | Devuelve la fecha de la marca de tiempo, disminuyéndola según el intervalo especificado. |
| DATEDIFF(timestamp1, timestamp2) | DATE_DIFF(timestamp1, timestamp2, date_part) | Devuelve la diferencia entre las fechas timestamp1 y timestamp2. En Legacy SQL, devuelve la diferencia en días, y en Standard SQL, devuelve la diferencia según el valor de date_part especificado (día, semana, mes, trimestre, año). |
| DÍA (marca de tiempo) | EXTRACTO (DÍA DESDE la marca de tiempo) | Devuelve el día a partir de la fecha de marca de tiempo. Toma valores del 1 al 31 inclusive. |
| MES(marca de tiempo) | EXTRACTO (MES DESDE la marca de tiempo) | Devuelve el número de secuencia del mes a partir de la fecha de marca de tiempo. Toma valores del 1 al 12 inclusive. |
| AÑO (marca de tiempo) | EXTRACTO (AÑO DESDE la marca de tiempo) | Devuelve el año a partir de la fecha de la marca de tiempo. |
Para obtener una lista de todas las funciones de fecha, consulte la documentación de SQL heredado y SQL estándar.
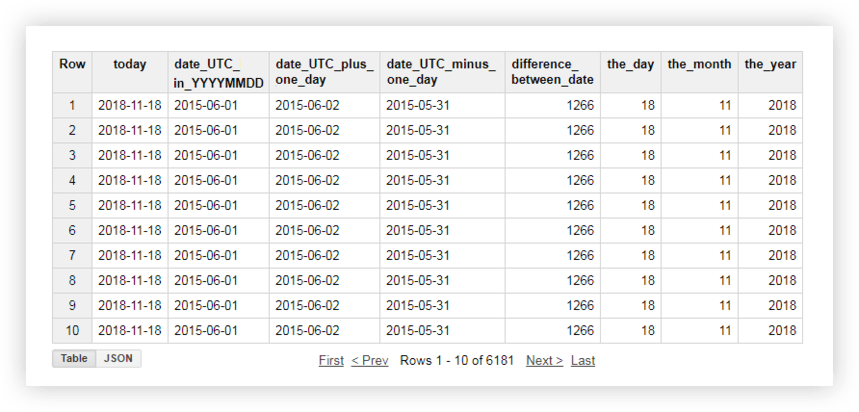
Echemos un vistazo a nuestros datos de demostración para ver cómo funciona cada una de estas funciones. Por ejemplo, obtendremos la fecha actual, convertiremos la fecha de la tabla original al formato % AAAA -% MM-% DD, la quitaremos y le agregaremos un día. Luego, calcularemos la diferencia entre la fecha actual y la fecha de la tabla de origen y dividiremos la fecha actual en campos separados de año, mes y día. Para hacer esto, puede copiar las consultas de muestra a continuación y reemplazar el nombre del proyecto, el conjunto de datos y la tabla de datos con los suyos propios.
#SQL heredado
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]#SQL estándar
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)Después de ejecutar la consulta, recibirá este informe:
Consulte también: Ejemplos de informes que se pueden crear mediante consultas SQL sobre datos en Google BigQuery y qué métricas únicas puede complementar los datos de Google Analytics con OWOX BI.
Funciones de cadena
Las funciones de cadena le permiten generar una cadena, seleccionar y reemplazar subcadenas y calcular la longitud de una cadena y la secuencia de índice de la subcadena en la cadena original. Por ejemplo, con funciones de cadena, puede:
- filtrar un informe con etiquetas UTM que se pasan a la URL de la página
- llevar los datos a un solo formato si los nombres de la fuente y la campaña están escritos en registros diferentes
- reemplazar datos incorrectos en un informe (por ejemplo, si el nombre de la campaña está mal impreso)
Estas son las funciones más populares para trabajar con cadenas:
| SQL heredado | SQL estándar | Función descriptiva |
|---|---|---|
| CONCAT('str1', 'str2') o 'str1'+ 'str2' | CONCAT('str1', 'str2') | Concatena 'str1' y 'str2' en una cadena. |
| 'str1' CONTIENE 'str2' | REGEXP_CONTAINS('str1', 'str2') o 'str1' COMO '%str2%' | Devuelve verdadero si la cadena 'str1' contiene la cadena 'str2'. En SQL estándar, la cadena 'str2' se puede escribir como una expresión regular utilizando la biblioteca re2 . |
| LONGITUD('str' ) | CHAR_LENGTH('str' )o CHARACTER_LENGTH('str' ) | Devuelve la longitud de la cadena 'str' (número de caracteres). |
| SUBSTR('str', índice [, max_len]) | SUBSTR('str', índice [, max_len]) | Devuelve una subcadena de longitud max_len que comienza con un carácter de índice de la cadena 'str'. |
| INFERIOR('str') | INFERIOR('str') | Convierte todos los caracteres de la cadena 'str a minúsculas. |
| SUPERIOR (str) | SUPERIOR (str) | Convierte todos los caracteres de la cadena 'str' a mayúsculas. |
| INSTR('str1', 'str2') | STRPOS('str1', 'str2') | Devuelve el índice de la primera aparición de la cadena 'str2' en la cadena 'str1'; de lo contrario, devuelve 0. |
| REEMPLAZAR('str1', 'str2', 'str3') | REEMPLAZAR('str1', 'str2', 'str3') | Reemplaza 'str1' con 'str2' con 'str3'. |
Puede obtener más información sobre todas las funciones de cadena en la documentación de SQL heredado y SQL estándar.
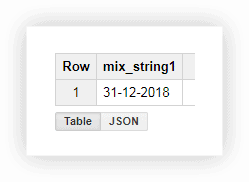
Veamos los datos de demostración para ver cómo usar las funciones descritas. Supongamos que tenemos tres columnas separadas que contienen valores de día, mes y año:

Trabajar con una fecha en este formato no es muy conveniente, por lo que podemos combinar los valores en una columna. Para hacer esto, use las consultas SQL a continuación y recuerde sustituir el nombre de su proyecto, conjunto de datos y tabla en Google BigQuery.
#SQL heredado
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1#SQL estándar
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1Después de ejecutar la consulta, recibimos la fecha en una columna:
A menudo, cuando descarga una página en un sitio web, la URL registra los valores de las variables que el usuario ha elegido. Este puede ser un método de pago o entrega, número de transacción, índice de la tienda física en la que el comprador quiere recoger el artículo, etc. Mediante una consulta SQL, puede seleccionar estos parámetros desde la dirección de la página. Considere dos ejemplos de cómo y por qué podría hacer esto.
Ejemplo 1 . Supongamos que queremos saber el número de compras en las que los usuarios recogen mercancías en tiendas físicas. Para hacer esto, necesitamos calcular la cantidad de transacciones enviadas desde páginas en la URL que contienen una subcadena shop_id (un índice para una tienda física). Esto lo podemos hacer con las siguientes consultas:

#SQL heredado
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check#SQL estándar
SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2
SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2De la tabla resultante, vemos que se enviaron 5502 transacciones (verificar = verdadero) desde páginas que contienen shop_id:

Ejemplo 2 . Ha asignado un ID de entrega a cada método de entrega y especifica el valor de este parámetro en la URL de la página. Para saber qué método de entrega ha elegido el usuario, debe seleccionar delivery_id en una columna separada.
Podemos usar las siguientes consultas para esto:
#SQL heredado
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC#SQL estándar
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASCComo resultado, obtenemos una tabla como esta en Google BigQuery:
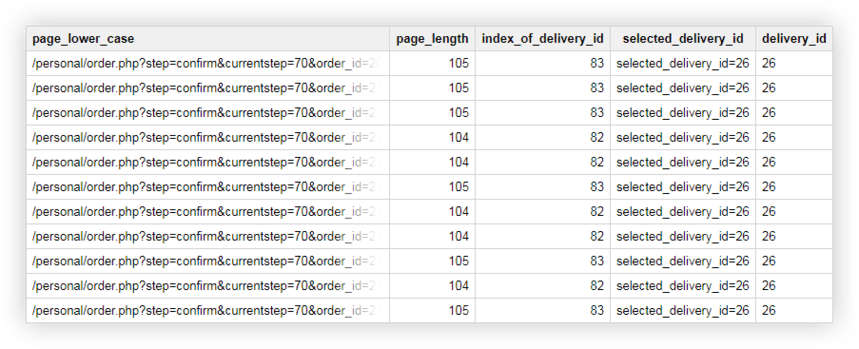
Datos de demostración para la práctica de consultas SQL
DescargarFunciones de ventana
Estas funciones son similares a las funciones agregadas que discutimos anteriormente. La principal diferencia es que las funciones de ventana no realizan cálculos sobre el conjunto completo de datos seleccionados mediante la consulta, sino solo sobre una parte de esos datos: un subconjunto o ventana .
Usando funciones de ventana, puede agregar datos en una sección de grupo sin usar la función JOIN para combinar múltiples consultas. Por ejemplo, puede calcular el ingreso promedio por campaña publicitaria o la cantidad de transacciones por dispositivo. Al agregar otro campo al informe, puede averiguar fácilmente, por ejemplo, el porcentaje de ingresos de una campaña publicitaria en Black Friday o el porcentaje de transacciones realizadas desde una aplicación móvil.
Junto con cada función de la consulta, debe deletrear la expresión OVER que define los límites de la ventana. OVER contiene tres componentes con los que puede trabajar:
- PARTICIÓN POR: define la característica por la que divide los datos originales en subconjuntos, como clientId o DayTime
- ORDENAR POR: define el orden de las filas en un subconjunto, como la hora DESC
- MARCO DE VENTANA: le permite procesar filas dentro de un subconjunto de una característica específica (por ejemplo, solo las cinco filas antes de la fila actual)
En esta tabla, hemos recopilado las funciones de ventana más utilizadas:
| SQL heredado | SQL estándar | Función descriptiva |
|---|---|---|
| PROMEDIO(campo) CONTAR(campo) CONTAR (campo DISTINTO) MÁX.() MIN() SUMA() | PROMEDIO([DISTINTO] (campo)) CONTAR(campo) COUNT([DISTINCT] (campo)) MAX(campo) MIN(campo) SUMA(campo) | Devuelve el valor promedio, numérico, máximo, mínimo y total de la columna de campo dentro del subconjunto seleccionado. DISTINCT se usa para calcular solo valores únicos (no repetitivos). |
| DENSO_RANGO() | DENSO_RANGO() | Devuelve el número de fila dentro de un subconjunto. |
| PRIMER_VALOR(campo) | PRIMER_VALOR (campo [{RESPETO | IGNORAR} NULOS]) | Devuelve el valor de la primera fila de la columna de campo dentro de un subconjunto. De forma predeterminada, las filas con valores vacíos de la columna de campo se incluyen en el cálculo. RESPECT o IGNORE NULLS especifica si incluir o ignorar cadenas NULL. |
| LAST_VALUE(campo) | LAST_VALUE (campo [{RESPETO | IGNORAR} NULOS]) | Devuelve el valor de la última fila dentro de un subconjunto de la columna de campo. De forma predeterminada, las filas con valores vacíos en la columna de campo se incluyen en el cálculo. RESPECT o IGNORE NULLS especifica si incluir o ignorar cadenas NULL. |
| RETRASO (campo) | LAG (campo[, desplazamiento [, expresión_predeterminada]]) | Devuelve el valor de la fila anterior con respecto a la columna del campo actual dentro del subconjunto. Offset es un número entero que especifica el número de filas para compensar hacia abajo desde la fila actual. Default_expression es el valor que devolverá la función si no se requiere cadena dentro del subconjunto. |
| PLOMO (campo) | LEAD (campo[, desplazamiento [, expresión_predeterminada]]) | Devuelve el valor de la fila siguiente en relación con la columna del campo actual dentro del subconjunto. Offset es un número entero que define el número de filas que desea mover hacia arriba con respecto a la fila actual. Default_expression es el valor que devolverá la función si no hay una cadena requerida dentro del subconjunto actual. |
Puede ver una lista de todas las funciones analíticas agregadas y funciones de navegación en la documentación de Legacy SQL y Standard SQL.
Ejemplo 1 . Digamos que queremos analizar la actividad de los clientes en horario laboral y no laboral. Para hacer esto, necesitamos dividir las transacciones en dos grupos y calcular las métricas de interés:
- Grupo 1 — Compras en horario laboral de 9:00 a 18:00
- Grupo 2 — Compras fuera del horario de 00:00 a 9:00 y de 18:00 a 23:59
Además de las horas laborables y no laborables, otra variable para formar una ventana es clientId. Es decir, para cada usuario tendremos dos ventanas:
| ventana | Identificación del cliente | Tiempo de día |
|---|---|---|
| ventana 1 | ID de cliente 1 | Horas Laborales |
| ventana 2 | ID de cliente 2 | horas no laborables |
| ventana 3 | ID de cliente 3 | Horas Laborales |
| ventana 4 | ID de cliente 4 | horas no laborables |
| ventana norte | ID de cliente N | Horas Laborales |
| ventana N+1 | ID de cliente N+1 | horas no laborables |
Usemos datos de demostración para calcular el ingreso promedio, máximo, mínimo y total, el número total de transacciones y el número de transacciones únicas por usuario durante las horas laborales y no laborales. Las solicitudes a continuación nos ayudarán a hacer esto.
#SQL heredado
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC#SQL estándar
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESCVeamos qué sucede como resultado usando el ejemplo del usuario con clientId 102041117.1428132012. En la tabla original para este usuario, tenemos los siguientes datos:

Al ejecutar la consulta, recibimos un informe que contiene los ingresos promedio, mínimo, máximo y total de este usuario, así como el número total de transacciones del usuario. Como puede ver en la captura de pantalla a continuación, ambas transacciones fueron realizadas por el usuario durante el horario laboral:

Ejemplo 2 . Ahora para una tarea más complicada:
- Coloque números de secuencia para todas las transacciones en la ventana según el momento de su ejecución. Recordemos que definimos la ventana por usuario y franjas horarias laborables/no laborables.
- Informe los ingresos de la transacción siguiente/anterior (en relación con la actual) dentro de la ventana.
- Muestre los ingresos de la primera y la última transacción en la ventana.
Para hacer esto, usaremos las siguientes consultas:
#SQL heredado
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour#SQL estándar
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hourPodemos comprobar los resultados de los cálculos utilizando el ejemplo de un usuario que ya conocemos: clientId 102041117.1428132012:

En la captura de pantalla anterior, podemos ver que:
- la primera transacción fue a las 15:00 y la segunda transacción fue a las 16:00
- después de la transacción a las 15:00, hubo una transacción a las 16:00 con ingresos de 25066 (columna lead_revenue)
- antes de la transacción a las 16:00, hubo una transacción a las 15:00 con ingresos de 3699 (columna lag_revenue)
- la primera transacción dentro de la ventana fue a las 15:00, y los ingresos de esta transacción fueron 3699 (columna first_revenue_by_hour)
- la consulta procesa los datos línea por línea, por lo que para la transacción en cuestión, la última transacción en la ventana será ella misma y los valores en las columnas último_ingreso_por_hora e ingresos serán los mismos
Artículos útiles sobre Google BigQuery:
- Las 6 principales herramientas de visualización de BigQuery
- Cómo subir datos a Google BigQuery
- Cómo cargar datos sin procesar de Google Ads a Google BigQuery
- Conector de Hojas de cálculo de Google BigQuery
- Automatice los informes en hojas de cálculo de Google utilizando datos de Google BigQuery
- Automatice los informes en Google Data Studio en función de los datos de Google BigQuery
Si desea recopilar datos sin muestrear de su sitio web en Google BigQuery pero no sabe por dónde empezar, reserve una demostración. Te contamos todas las posibilidades que obtienes con BigQuery y OWOX BI.
Nuestros clientes
crecer 22% más rápido
Crezca más rápido midiendo lo que funciona mejor en su marketing
Analice su eficiencia de marketing, encuentre las áreas de crecimiento, aumente el ROI
Obtener demostraciónConclusiones
En este artículo, hemos analizado los grupos de funciones más populares: agregado, fecha, cadena y ventana. Sin embargo, Google BigQuery tiene muchas más funciones útiles, que incluyen:
- funciones de conversión que le permiten convertir datos a un formato específico
- funciones comodín de tabla que le permiten acceder a varias tablas en un conjunto de datos
- funciones de expresiones regulares que le permiten describir el modelo de una consulta de búsqueda y no su valor exacto
Definitivamente escribiremos sobre estas funciones en nuestro blog. Mientras tanto, puede probar todas las funciones descritas en este artículo utilizando nuestros datos de demostración.
Datos de demostración para la práctica de consultas SQL
Descargar