
نظرة عامة على ميزات Google BigQuery الرئيسية - تدرب على كتابة طلبات لتحليل التسويق
نشرت: 2022-04-12كلما زادت المعلومات التي يجمعها العمل التجاري ، زادت حدة السؤال عن مكان تخزينه. إذا لم تكن لديك القدرة أو الرغبة في الحفاظ على الخوادم الخاصة بك ، فيمكن أن يساعدك Google BigQuery (GBQ). يوفر BigQuery سعة تخزينية سريعة وفعالة من حيث التكلفة وقابلة للتطوير للعمل مع البيانات الضخمة ، كما يسمح لك بكتابة استعلامات باستخدام بناء جملة يشبه SQL بالإضافة إلى الوظائف القياسية والمحددة من قبل المستخدم.
في هذه المقالة ، نلقي نظرة على الوظائف الرئيسية لأداة BigQuery ونعرض إمكانياتها باستخدام أمثلة محددة. ستتعلم كيفية كتابة الاستفسارات الأساسية واختبارها على البيانات التجريبية.
بناء تقارير عن بيانات GBQ دون تدريب تقني أو معرفة بـ SQL.
هل تحتاج بانتظام إلى تقارير عن الحملات الإعلانية ولكن ليس لديك وقت لدراسة SQL أو انتظار الرد من المحللين؟ باستخدام OWOX BI ، يمكنك إنشاء تقارير دون الحاجة إلى فهم كيفية تنظيم بياناتك. ما عليك سوى تحديد المعلمات والمقاييس التي تريد رؤيتها في تقرير البيانات الذكية الخاص بك. سوف تقوم OWOX BI Smart Data بتصور بياناتك على الفور بطريقة يمكنك فهمها.
جدول المحتويات
- ما هو SQL وما هي اللهجات التي يدعمها BigQuery
- من اين نبدأ
- ميزات Google BigQuery
- وظائف مجمعة
- وظائف التاريخ
- وظائف السلسلة
- وظائف النافذة
- الاستنتاجات
ما هو SQL وما هي اللهجات التي يدعمها BigQuery
تتيح لك لغة الاستعلام الهيكلية (SQL) استرداد البيانات من البيانات وإضافتها إليها وتعديلها في المصفوفات الكبيرة. يدعم Google BigQuery لهجتي SQL: معيار SQL ولغة SQL القديمة.
تعتمد اللغة التي تختارها على تفضيلاتك ، ولكن توصي Google باستخدام لغة SQL القياسية لهذه الفوائد:
- المرونة والوظائف للحقول المتداخلة والمتكررة
- دعم لغتي DML و DDL ، مما يسمح لك بتغيير البيانات في الجداول وكذلك إدارة الجداول وطرق العرض في GBQ
- معالجة أسرع لكميات كبيرة من البيانات مقارنة بـ Legacy SQL
- دعم لجميع تحديثات BigQuery المستقبلية
يمكنك معرفة المزيد حول الاختلافات في اللهجات في وثائق BigQuery.
راجع أيضًا: ما هي مزايا لغة SQL القياسية الجديدة في Google BigQuery مقارنة بـ Legacy SQL ، وما هي مهام العمل التي يمكنك حلها باستخدامها؟
بشكل افتراضي ، تعمل طلبات بحث Google BigQuery على لغة SQL القديمة.
يمكنك التبديل إلى Standard SQL بعدة طرق:
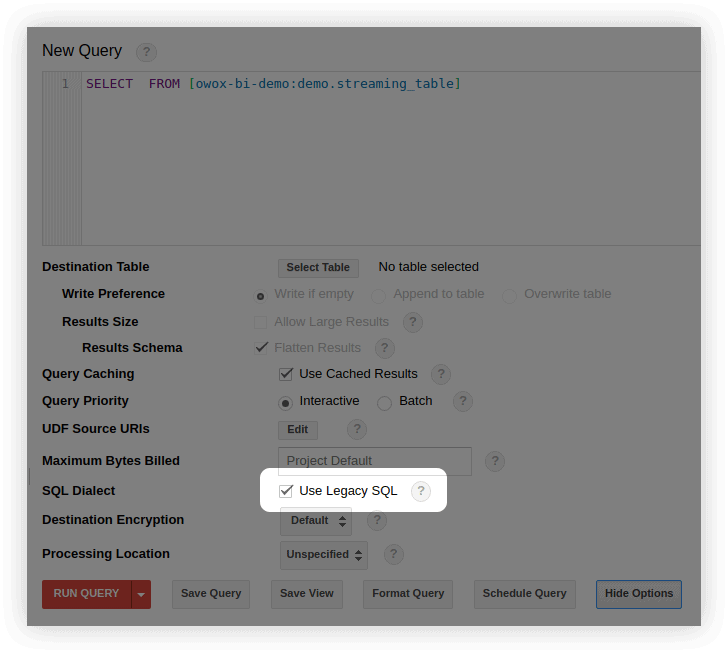
- في واجهة BigQuery ، في نافذة تحرير الاستعلام ، حدد إظهار الخيارات وقم بإزالة علامة الاختيار الموجودة بجوار Use Legacy SQL :
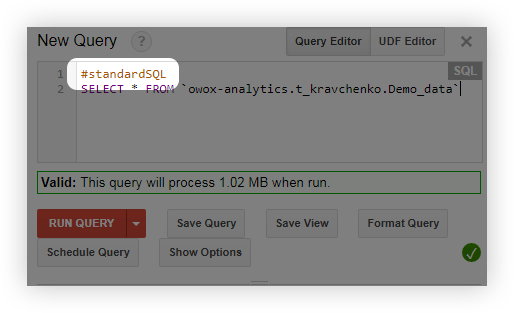
- قبل الاستعلام ، أضف السطر #standardSQL وابدأ الاستعلام بسطر جديد:
من اين نبدأ
حتى تتمكن من ممارسة الاستعلامات وتشغيلها معنا ، فقد أعددنا جدولًا يحتوي على بيانات توضيحية. املأ النموذج أدناه وسنرسله إليك بالبريد الإلكتروني.


البيانات التجريبية لممارسة استعلامات SQL
تحميل للبدء ، نزّل جدول البيانات التجريبية وحمّله إلى مشروع Google BigQuery. أسهل طريقة للقيام بذلك هي باستخدام الوظيفة الإضافية OWOX BI BigQuery Reports.
- افتح جداول بيانات Google وثبّت الوظيفة الإضافية OWOX BI BigQuery Reports.
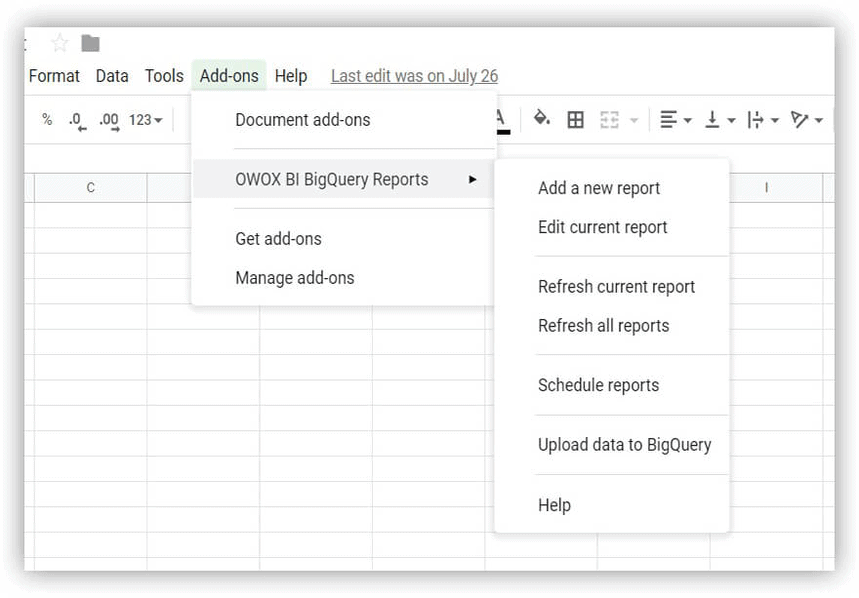
- افتح الجدول الذي نزّلته والذي يحتوي على بيانات توضيحية وحدد OWOX BI BigQuery Reports -> تحميل البيانات إلى BigQuery :
- في النافذة التي تفتح ، اختر مشروع Google BigQuery ، ومجموعة بيانات ، وفكر في اسم للجدول الذي سيتم تخزين البيانات المحملة فيه.
- حدد تنسيقًا للبيانات المحملة (كما هو موضح في لقطة الشاشة):

إذا لم يكن لديك مشروع في Google BigQuery ، فأنشئ مشروعًا. للقيام بذلك ، ستحتاج إلى حساب فوترة نشط في Google Cloud Platform. لا تدع الأمر يخيفك أنك بحاجة إلى ربط بطاقة مصرفية: لن يتم تحصيل أي رسوم منك دون علمك. بالإضافة إلى ذلك ، عند التسجيل ، ستتلقى 300 دولار لمدة 12 شهرًا يمكنك إنفاقها على تخزين البيانات ومعالجتها.
يساعدك OWOX BI على دمج البيانات من أنظمة مختلفة في BigQuery: بيانات حول إجراءات المستخدم على موقع الويب الخاص بك والمكالمات والطلبات من CRM ورسائل البريد الإلكتروني وتكاليف الإعلان. يمكنك استخدام OWOX BI لتخصيص التحليلات المتقدمة وأتمتة التقارير بأي تعقيد.
قبل الحديث عن ميزات Google BigQuery ، دعنا نتذكر شكل الاستعلامات الأساسية في كل من لهجات SQL القديمة ولهجة SQL القياسية:
| استفسار | لغة SQL القديمة | معيار SQL |
|---|---|---|
| حدد الحقول من الجدول | حدد الحقل 1 ، الحقل 2 | حدد الحقل 1 ، الحقل 2 |
| حدد الجدول الذي تختار الحقول منه | من [معرف المشروع: dataSet.tableName] | من `projectID.dataSet.tableName` |
| حدد المعلمة التي يتم من خلالها تصفية القيم | حيث الحقل 1 = القيمة | حيث الحقل 1 = القيمة |
| حدد الحقول التي يتم من خلالها تجميع النتائج | تجميع حسب الحقل 1 ، الحقل 2 | تجميع حسب الحقل 1 ، الحقل 2 |
| حدد كيفية ترتيب النتائج | ترتيب حسب الحقل 1 ASC (تصاعدي) أو تنازلي (تنازلي) | ترتيب حسب الحقل 1 ASC (تصاعدي) أو تنازلي (تنازلي) |
ميزات Google BigQuery
عند إنشاء الاستعلامات ، ستستخدم في أغلب الأحيان الدالات التجميعية والتاريخية والسلسلة والنافذة. دعونا نلقي نظرة فاحصة على كل مجموعة من هذه الوظائف.
راجع أيضًا: كيفية بدء العمل مع التخزين السحابي - إنشاء مجموعة بيانات وجداول وتهيئة استيراد البيانات إلى Google BigQuery.
وظائف مجمعة
توفر الدالات التجميعية قيمًا موجزة لجدول بأكمله. على سبيل المثال ، يمكنك استخدامها لحساب متوسط حجم الشيك أو إجمالي الإيرادات شهريًا ، أو يمكنك استخدامها لتحديد شريحة المستخدمين الذين أجروا أقصى عدد من عمليات الشراء.
هذه هي الوظائف التجميعية الأكثر شيوعًا:
| لغة SQL القديمة | معيار SQL | ماذا تفعل الوظيفة |
|---|---|---|
| AVG (حقل) | AVG ([DISTINCT] (حقل)) | تُرجع متوسط قيمة عمود الحقل. في معيار SQL ، عند إضافة شرط DISTINCT ، يتم اعتبار المتوسط فقط للصفوف ذات القيم الفريدة (غير المتكررة) في عمود الحقل. |
| MAX (حقل) | MAX (حقل) | تُرجع القيمة القصوى من عمود الحقل. |
| MIN (حقل) | MIN (حقل) | تُرجع الحد الأدنى للقيمة من عمود الحقل. |
| SUM (حقل) | SUM (حقل) | تُرجع مجموع القيم من عمود الحقل. |
| COUNT (حقل) | COUNT (حقل) | تُرجع عدد الصفوف في عمود الحقل. |
| EXACT_COUNT_DISTINCT (حقل) | COUNT ([DISTINCT] (حقل)) | تُرجع هذه الدالة عدد الصفوف الفريدة في عمود الحقل. |
للحصول على قائمة بجميع الوظائف المجمعة ، راجع وثائق Legacy SQL و Standard SQL.
لنلقِ نظرة على البيانات التجريبية لنرى كيف تعمل هذه الوظائف. يمكننا حساب متوسط الإيرادات للمعاملات ، والمشتريات لأعلى وأقل المبالغ ، وإجمالي الإيرادات ، وإجمالي المعاملات ، وعدد المعاملات الفريدة (للتحقق مما إذا كانت المشتريات مكررة). للقيام بذلك ، سنكتب استعلامًا نحدد فيه اسم مشروع Google BigQuery ومجموعة البيانات والجدول.
#legacy SQL
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]# معيار SQL
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`نتيجة لذلك ، سوف نحصل على ما يلي:
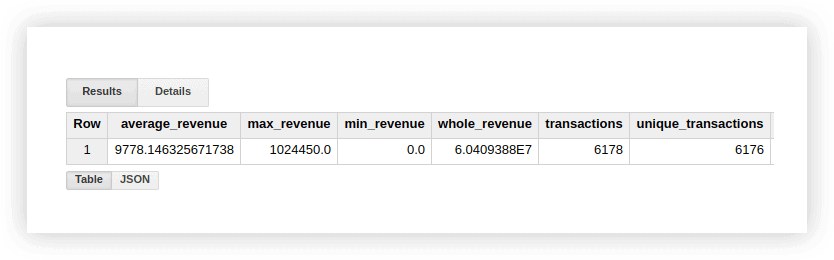
يمكنك التحقق من نتائج هذه الحسابات في الجدول الأصلي باستخدام البيانات التوضيحية باستخدام وظائف جداول بيانات Google القياسية (SUM و AVG وغيرها) أو باستخدام الجداول المحورية.
كما ترى من لقطة الشاشة أعلاه ، يختلف عدد المعاملات والمعاملات الفريدة. يشير هذا إلى وجود معاملتين في جدولنا لهما نفس المعاملة ID:

إذا كنت مهتمًا بالمعاملات الفريدة ، فاستخدم دالة تحسب سلاسل فريدة. بدلاً من ذلك ، يمكنك تجميع البيانات باستخدام الدالة GROUP BY للتخلص من التكرارات قبل تطبيق الوظيفة التجميعية.
البيانات التجريبية لممارسة استعلامات SQL
تحميلوظائف التاريخ
تتيح لك هذه الوظائف معالجة التواريخ: تغيير تنسيقها ، أو تحديد الحقل الضروري (اليوم ، أو الشهر ، أو السنة) ، أو تغيير التاريخ بفاصل زمني معين.
قد تكون مفيدة عندما:
- تحويل التواريخ والأوقات من مصادر مختلفة إلى تنسيق واحد لإعداد تحليلات متقدمة
- إنشاء تقارير محدثة تلقائيًا أو تشغيل المراسلات (على سبيل المثال ، عندما تحتاج إلى بيانات لآخر ساعتين أو أسبوع أو شهر)
- إنشاء تقارير جماعية يكون من الضروري فيها الحصول على بيانات لفترة أيام أو أسابيع أو شهور
هذه هي وظائف التاريخ الأكثر استخدامًا:
| لغة SQL القديمة | معيار SQL | وصف الوظيفة |
|---|---|---|
| التاريخ الحالي() | التاريخ الحالي() | إرجاع التاريخ الحالي بالتنسيق٪ YYYY -٪ MM-٪ DD. |
| DATE (الطابع الزمني) | DATE (الطابع الزمني) | تحويل التاريخ من تنسيق٪ YYYY -٪ MM-٪ DD٪ H:٪ M:٪ C. إلى تنسيق٪ YYYY -٪ MM-٪ DD. |
| DATE_ADD (الطابع الزمني ، الفاصل الزمني ، الفاصل_الوحدات) | DATE_ADD (الطابع الزمني ، الفاصل الزمني INTERVAL الفاصل_وحدات) | يُرجع تاريخ الطابع الزمني ، ويزيده بالفاصل الزمني المحدد. interval_units. في Legacy SQL ، يمكن أن يأخذ القيم YEAR و MONTH و DAY و HOUR و MINUTE و SECOND ، وفي SQL القياسي يمكن أن يستغرق الأمر YEAR و QUARTER و MONTH و أسبوع ويوم. |
| DATE_ADD (الطابع الزمني ، - الفاصل الزمني ، الفاصل_الوحدات) | DATE_SUB (الطابع الزمني ، الفاصل الزمني INTERVAL الفاصل_وحدات) | تُرجع تاريخ الطابع الزمني ، وتقليله بمقدار الفاصل الزمني المحدد. |
| DATEDIFF (الطابع الزمني 1 ، الطابع الزمني 2) | DATE_DIFF (الطابع الزمني 1 ، الطابع الزمني 2 ، جزء التاريخ) | تُرجع الفرق بين تواريخ الطابع الزمني 1 والطابع الزمني 2. في Legacy SQL ، تُرجع الفرق بالأيام ، وفي Standard SQL ، تُرجع الفرق بناءً على قيمة جزء_التاريخ المحددة (اليوم ، الأسبوع ، الشهر ، ربع السنة ، السنة). |
| DAY (الطابع الزمني) | مستخرج (يوم من الطابع الزمني) | إرجاع اليوم من تاريخ الطابع الزمني. تأخذ القيم من 1 إلى 31 ضمناً. |
| MONTH (الطابع الزمني) | مستخرج (شهر من الطابع الزمني) | تُرجع رقم تسلسل الشهر من تاريخ الطابع الزمني. يأخذ القيم من 1 إلى 12 ضمناً. |
| YEAR (الطابع الزمني) | مستخرج (سنة من الطابع الزمني) | ترجع السنة من تاريخ الطابع الزمني. |
للحصول على قائمة بجميع وظائف التاريخ ، راجع وثائق Legacy SQL و Standard SQL.
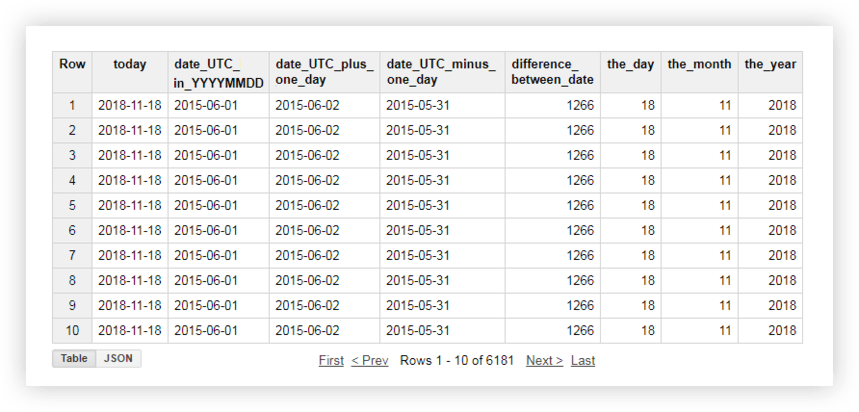
دعنا نلقي نظرة على بياناتنا التجريبية لنرى كيف تعمل كل من هذه الوظائف. على سبيل المثال ، سنحصل على التاريخ الحالي ، ونحول التاريخ من الجدول الأصلي إلى التنسيق٪ YYYY -٪ MM-٪ DD ، ونحذفه ونضيف إليه يومًا واحدًا. ثم سنحسب الفرق بين التاريخ الحالي والتاريخ من الجدول المصدر ونقسم التاريخ الحالي إلى حقول منفصلة للسنة والشهر واليوم. للقيام بذلك ، يمكنك نسخ نماذج الاستعلامات أدناه واستبدال اسم المشروع ومجموعة البيانات وجدول البيانات باسمك.
#legacy SQL
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]# معيار SQL
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)بعد تشغيل الاستعلام ، ستتلقى هذا التقرير:
راجع أيضًا: أمثلة على التقارير التي يمكن إنشاؤها باستخدام استعلامات SQL حول البيانات في Google BigQuery والمقاييس الفريدة التي يمكنك استكمال بيانات Google Analytics بها باستخدام OWOX BI.
وظائف السلسلة
تتيح لك وظائف السلسلة إنشاء سلسلة وتحديد واستبدال السلاسل الفرعية وحساب طول السلسلة وتسلسل الفهرس للسلسلة الفرعية في السلسلة الأصلية. على سبيل المثال ، مع وظائف السلسلة ، يمكنك:
- قم بتصفية تقرير بعلامات UTM التي تم تمريرها إلى عنوان URL للصفحة
- إحضار البيانات في تنسيق واحد إذا تمت كتابة اسمي المصدر والحملة في سجلات مختلفة
- استبدال البيانات غير الصحيحة في تقرير (على سبيل المثال ، إذا تمت طباعة اسم الحملة بشكل خاطئ)
هذه هي الوظائف الأكثر شيوعًا للعمل مع السلاسل:
| لغة SQL القديمة | معيار SQL | وصف الوظيفة |
|---|---|---|
| CONCAT ("str1" ، "str2") أو "str1" + "str2" | CONCAT ('str1'، 'str2') | يربط 'str1' و 'str2' في سلسلة واحدة. |
| "str1" يحتوي على "str2" | REGEXP_CONTAINS ('str1' ، 'str2') أو 'str1' مثل '٪ str2٪' | لإرجاع صحيح إذا كانت السلسلة 'str1' تحتوي على سلسلة 'str2.' في معيار SQL ، يمكن كتابة السلسلة 'str2' كتعبير عادي باستخدام مكتبة re2 . |
| الطول ("ستر") | CHAR_LENGTH ('str') أو CHARACTER_LENGTH ('str') | لعرض طول السلسلة "str" (عدد الأحرف). |
| SUBSTR ('str'، index [، max_len]) | SUBSTR ('str'، index [، max_len]) | تُرجع سلسلة فرعية بطول max_len تبدأ بحرف فهرس من سلسلة 'str'. |
| LOWER ("str") | LOWER ("str") | يحول جميع الأحرف في السلسلة 'str إلى أحرف صغيرة. |
| أعلى (شارع) | أعلى (شارع) | يحول جميع الأحرف في السلسلة "str" إلى أحرف كبيرة. |
| INSTR ('str1'، 'str2') | STRPOS ('str1'، 'str2') | إرجاع فهرس التواجد الأول للسلسلة 'str2' إلى السلسلة 'str1' ؛ وإلا ، يتم إرجاع 0. |
| استبدال ('str1'، 'str2'، 'str3') | استبدال ('str1'، 'str2'، 'str3') | يستبدل "str1" بـ "str2" بـ "str3". |
يمكنك معرفة المزيد حول جميع وظائف السلسلة في وثائق Legacy SQL و Standard SQL.
لنلقِ نظرة على البيانات التوضيحية لمعرفة كيفية استخدام الوظائف الموصوفة. افترض أن لدينا ثلاثة أعمدة منفصلة تحتوي على قيم اليوم والشهر والسنة:

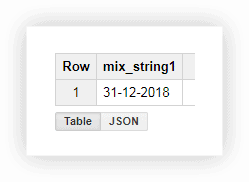
العمل مع تاريخ بهذا التنسيق ليس ملائمًا للغاية ، لذا يمكننا دمج القيم في عمود واحد. للقيام بذلك ، استخدم استعلامات SQL أدناه وتذكر استبدال اسم المشروع ومجموعة البيانات والجدول في Google BigQuery.
#legacy SQL
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1# معيار SQL
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1بعد إجراء الاستعلام ، نتلقى التاريخ في عمود واحد:
في كثير من الأحيان ، عند تنزيل صفحة على موقع ويب ، يسجل عنوان URL قيم المتغيرات التي اختارها المستخدم. يمكن أن تكون طريقة الدفع أو التسليم ، أو رقم المعاملة ، أو فهرس المتجر الفعلي الذي يريد المشتري استلام العنصر فيه ، وما إلى ذلك. باستخدام استعلام SQL ، يمكنك تحديد هذه المعلمات من عنوان الصفحة. ضع في اعتبارك مثالين لكيفية ولماذا يمكنك القيام بذلك.

مثال 1 . لنفترض أننا نريد معرفة عدد عمليات الشراء التي يلتقط فيها المستخدمون البضائع من المتاجر الفعلية. للقيام بذلك ، نحتاج إلى حساب عدد المعاملات المرسلة من الصفحات الموجودة في عنوان URL التي تحتوي على سلسلة فرعية shop_id (فهرس لمتجر فعلي). يمكننا القيام بذلك من خلال الاستفسارات التالية:
#legacy SQL
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check# معيار SQL
SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2
SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2من الجدول الناتج ، نرى أنه تم إرسال 5502 معاملة (تحقق = صحيح) من الصفحات التي تحتوي على معرّف_المحل:

مثال 2 . لقد قمت بتعيين delivery_id لكل طريقة تسليم ، وتحدد قيمة هذه المعلمة في عنوان URL للصفحة. لمعرفة طريقة التسليم التي اختارها المستخدم ، تحتاج إلى تحديد معرّف التسليم في عمود منفصل.
يمكننا استخدام الاستعلامات التالية لهذا:
#legacy SQL
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC# معيار SQL
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASCنتيجة لذلك ، حصلنا على جدول مثل هذا في Google BigQuery:
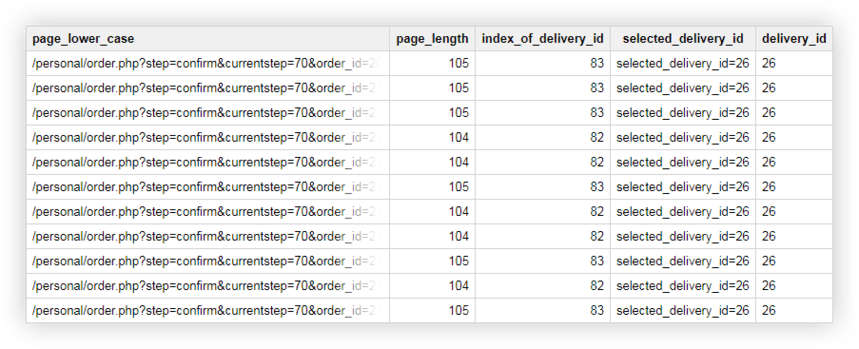
البيانات التجريبية لممارسة استعلامات SQL
تحميلوظائف النافذة
تشبه هذه الوظائف الوظائف الإجمالية التي ناقشناها أعلاه. يتمثل الاختلاف الرئيسي في أن وظائف النافذة لا تنفذ عمليات حسابية على المجموعة الكاملة من البيانات المحددة باستخدام الاستعلام ولكن فقط على جزء من تلك البيانات - مجموعة فرعية أو نافذة .
باستخدام وظائف النافذة ، يمكنك تجميع البيانات في قسم مجموعة دون استخدام وظيفة JOIN لدمج استعلامات متعددة. على سبيل المثال ، يمكنك حساب متوسط الإيرادات لكل حملة إعلانية أو عدد المعاملات لكل جهاز. من خلال إضافة حقل آخر إلى التقرير ، يمكنك بسهولة معرفة ، على سبيل المثال ، حصة الإيرادات من حملة إعلانية في يوم الجمعة الأسود أو حصة المعاملات التي تمت من تطبيق الهاتف المحمول.
جنبًا إلى جنب مع كل دالة في الاستعلام ، يجب عليك كتابة تعبير OVER الذي يحدد حدود النافذة. يحتوي OVER على ثلاثة مكونات يمكنك العمل معها:
- PARTITION BY - تحدد الخاصية التي تقسم بها البيانات الأصلية إلى مجموعات فرعية ، مثل clientId أو DayTime
- ORDER BY - يحدد ترتيب الصفوف في مجموعة فرعية ، مثل الساعة DESC
- إطار WINDOW - يسمح لك بمعالجة الصفوف ضمن مجموعة فرعية من ميزة معينة (على سبيل المثال ، الصفوف الخمسة فقط قبل الصف الحالي)
في هذا الجدول ، قمنا بتجميع وظائف النوافذ الأكثر استخدامًا:
| لغة SQL القديمة | معيار SQL | وصف الوظيفة |
|---|---|---|
| AVG (حقل) COUNT (حقل) COUNT (حقل DISTINCT) الأعلى() دقيقة () مجموع() | AVG ([DISTINCT] (حقل)) COUNT (حقل) COUNT ([DISTINCT] (حقل)) MAX (حقل) MIN (حقل) SUM (حقل) | تُرجع القيمة المتوسطة والرقم والحد الأقصى والحد الأدنى والإجمالي من عمود الحقل ضمن المجموعة الفرعية المحددة. تُستخدم DISTINCT لحساب القيم الفريدة (غير المتكررة) فقط. |
| DENSE_RANK () | DENSE_RANK () | إرجاع رقم الصف ضمن مجموعة فرعية. |
| FIRST_VALUE (حقل) | FIRST_VALUE (الحقل [{RESPECT | IGNORE} فارغ]) | تُرجع قيمة الصف الأول من عمود الحقل ضمن مجموعة فرعية. بشكل افتراضي ، يتم تضمين الصفوف ذات القيم الفارغة من عمود الحقل في الحساب. تحدد RESPECT أو IGNORE NULLS ما إذا كان سيتم تضمين أو تجاهل سلاسل NULL. |
| LAST_VALUE (حقل) | LAST_VALUE (الحقل [{RESPECT | IGNORE} NULLS]) | تُرجع قيمة الصف الأخير داخل مجموعة فرعية من عمود الحقل. افتراضيًا ، يتم تضمين الصفوف ذات القيم الفارغة في عمود الحقل في الحساب. تحدد RESPECT أو IGNORE NULLS ما إذا كان سيتم تضمين أو تجاهل سلاسل NULL. |
| LAG (حقل) | LAG (حقل [، offset [، default_expression]]) | تُرجع قيمة الصف السابق فيما يتعلق بعمود الحقل الحالي داخل المجموعة الفرعية. الإزاحة هي عدد صحيح يحدد عدد الصفوف المراد تعويضها لأسفل من الصف الحالي. Default_expression هو القيمة التي ستعيدها الدالة إذا لم يكن هناك حاجة سلسلة ضمن المجموعة الفرعية. |
| LEAD (حقل) | LEAD (حقل [، offset [، default_expression]]) | تُرجع قيمة الصف التالي بالنسبة إلى عمود الحقل الحالي ضمن المجموعة الفرعية. الإزاحة هي عدد صحيح يحدد عدد الصفوف التي تريد نقلها لأعلى فيما يتعلق بالصف الحالي. التعبير_ الافتراضي هو القيمة التي ستعيدها الدالة إذا لم يكن هناك سلسلة مطلوبة ضمن المجموعة الفرعية الحالية. |
يمكنك الاطلاع على قائمة بجميع الوظائف التحليلية المجمعة ووظائف التنقل في وثائق Legacy SQL و Standard SQL.
مثال 1 . لنفترض أننا نريد تحليل نشاط العملاء أثناء ساعات العمل وغير ساعات العمل. للقيام بذلك ، نحتاج إلى تقسيم المعاملات إلى مجموعتين وحساب مقاييس الفائدة:
- المجموعة 1 - المشتريات خلال ساعات العمل من 9:00 حتي 18:00
- المجموعة 2 - المشتريات بعد ساعات العمل من 00:00 إلى 9:00 ومن 18:00 إلى 23:59
بالإضافة إلى ساعات العمل وغير ساعات العمل ، هناك متغير آخر لتشكيل النافذة هو معرف العميل. أي ، لكل مستخدم ، لدينا نافذتان:
| نافذة او شباك | معرف العميل | النهار |
|---|---|---|
| نافذة 1 | معرف العميل 1 | ساعات العمل |
| النافذة 2 | معرف العميل 2 | خارج ساعات العمل |
| نافذة 3 | معرف العميل 3 | ساعات العمل |
| نافذة 4 | معرف العميل 4 | خارج ساعات العمل |
| نافذة N | معرف العميل N | ساعات العمل |
| نافذة N + 1 | معرف العميل N + 1 | خارج ساعات العمل |
دعنا نستخدم البيانات التجريبية لحساب متوسط ، الحد الأقصى ، الحد الأدنى ، وإجمالي الإيرادات ، إجمالي عدد المعاملات ، وعدد المعاملات الفريدة لكل مستخدم أثناء ساعات العمل وغير ساعات العمل. الطلبات أدناه ستساعدنا على القيام بذلك.
#legacy SQL
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC# معيار SQL
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESCدعونا نرى ما سيحدث نتيجة استخدام مثال المستخدم مع معرف العميل clientId 102041117.1428132012. في الجدول الأصلي لهذا المستخدم ، لدينا البيانات التالية:

من خلال تشغيل الاستعلام ، نتلقى تقريرًا يحتوي على متوسط وأدنى وأقصى وإجمالي الإيرادات من هذا المستخدم بالإضافة إلى إجمالي عدد معاملات المستخدم. كما ترى في لقطة الشاشة أدناه ، فقد أجرى المستخدم كلا المعاملتين خلال ساعات العمل:

مثال 2 . الآن لمهمة أكثر تعقيدًا:
- ضع أرقامًا متسلسلة لجميع المعاملات في النافذة اعتمادًا على وقت تنفيذها. تذكر أننا نحدد النافذة حسب المستخدم وفترات العمل / غير العاملة.
- تقرير الإيرادات من المعاملة التالية / السابقة (بالنسبة للحالية) داخل النافذة.
- اعرض إيرادات المعاملات الأولى والأخيرة في النافذة.
للقيام بذلك ، سنستخدم الاستعلامات التالية:
#legacy SQL
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour# معيار SQL
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hourيمكننا التحقق من نتائج الحسابات باستخدام مثال مستخدم نعرفه بالفعل: معرف العميل 102041117.1428132012:

من لقطة الشاشة أعلاه ، يمكننا أن نرى ما يلي:
- كانت المعاملة الأولى الساعة 15:00 والمعاملة الثانية كانت الساعة 16:00
- بعد المعاملة الساعة 15:00 ، كانت هناك معاملة في الساعة 16:00 بإيرادات 25066 (عمود الرصاص_الإيرادات)
- قبل المعاملة في الساعة 16:00 ، كانت هناك معاملة في الساعة 15:00 بإيرادات 3699 (عمود lag_revenue)
- كانت أول معاملة داخل النافذة في الساعة 15:00 ، وكانت إيرادات هذه المعاملة 3699 (العمود first_revenue_by_hour)
- يقوم الاستعلام بمعالجة البيانات سطرًا بسطر ، لذلك بالنسبة للمعاملة المعنية ، ستكون آخر معاملة في النافذة هي نفسها والقيم في الأعمدة last_revenue_by_hour وستكون الإيرادات هي نفسها
مقالات مفيدة حول Google BigQuery:
- أفضل 6 أدوات لمرئيات BigQuery
- كيفية تحميل البيانات إلى Google BigQuery
- كيفية تحميل البيانات الأولية من إعلانات Google إلى Google BigQuery
- Google BigQuery Google Sheets Connector
- أتمتة التقارير في جداول بيانات Google باستخدام البيانات من Google BigQuery
- أتمتة التقارير في Google Data Studio استنادًا إلى البيانات من Google BigQuery
إذا كنت ترغب في جمع بيانات غير مستندة إلى عينات من موقع الويب الخاص بك في Google BigQuery ولكنك لا تعرف من أين تبدأ ، فقم بحجز عرض توضيحي. سنخبرك بجميع الاحتمالات التي تحصل عليها مع BigQuery و OWOX BI.
عملائنا
تنمو 22٪ أسرع
حقق نموًا أسرع عن طريق قياس أفضل أداء في التسويق
تحليل كفاءتك التسويقية ، والعثور على مجالات النمو ، وزيادة عائد الاستثمار
احصل على نسخة تجريبيةالاستنتاجات
في هذه المقالة ، ألقينا نظرة على أكثر مجموعات الوظائف شيوعًا: التجميع والتاريخ والسلسلة والنافذة. ومع ذلك ، يحتوي Google BigQuery على العديد من الوظائف المفيدة ، بما في ذلك:
- وظائف الصب التي تسمح لك بتحويل البيانات إلى تنسيق معين
- وظائف أحرف البدل للجدول التي تتيح لك الوصول إلى جداول متعددة في مجموعة بيانات
- دالات التعبير العادي التي تتيح لك وصف نموذج استعلام البحث وليس قيمته بالضبط
سنكتب بالتأكيد عن هذه الوظائف على مدونتنا. في غضون ذلك ، يمكنك تجربة جميع الوظائف الموضحة في هذه المقالة باستخدام بيانات العرض التوضيحي الخاصة بنا.
البيانات التجريبية لممارسة استعلامات SQL
تحميل