
ภาพรวมของฟีเจอร์หลักของ Google BigQuery — ฝึกเขียนคำขอสำหรับการวิเคราะห์การตลาด
เผยแพร่แล้ว: 2022-04-12ยิ่งข้อมูลของธุรกิจสะสมมากเท่าไร ก็ยิ่งมีคำถามมากขึ้นว่าจะเก็บไว้ที่ใด หากคุณไม่มีความสามารถหรือต้องการบำรุงรักษาเซิร์ฟเวอร์ของคุณเอง Google BigQuery (GBQ) สามารถช่วยคุณได้ BigQuery ให้พื้นที่เก็บข้อมูลที่รวดเร็ว คุ้มค่า และปรับขนาดได้สำหรับการทำงานกับข้อมูลขนาดใหญ่ และช่วยให้คุณเขียนการสืบค้นโดยใช้ไวยากรณ์ที่เหมือน SQL รวมถึงฟังก์ชันมาตรฐานและฟังก์ชันที่ผู้ใช้กำหนดเอง
ในบทความนี้ เราจะพิจารณาฟังก์ชันหลักของ BigQuery และแสดงความเป็นไปได้โดยใช้ตัวอย่างเฉพาะ คุณจะได้เรียนรู้วิธีเขียนข้อความค้นหาพื้นฐานและทดสอบกับข้อมูลสาธิต
สร้างรายงานเกี่ยวกับข้อมูล GBQ โดยไม่ต้องมีการฝึกอบรมด้านเทคนิคหรือความรู้เกี่ยวกับ SQL
คุณต้องการรายงานเกี่ยวกับแคมเปญโฆษณาเป็นประจำแต่ไม่มีเวลาศึกษา SQL หรือรอคำตอบจากนักวิเคราะห์ของคุณหรือไม่? ด้วย OWOX BI คุณสามารถสร้างรายงานโดยไม่จำเป็นต้องเข้าใจว่าข้อมูลของคุณมีโครงสร้างอย่างไร เพียงเลือกพารามิเตอร์และเมตริกที่คุณต้องการดูในรายงาน Smart Data OWOX BI Smart Data จะแสดงภาพข้อมูลของคุณทันทีในแบบที่คุณเข้าใจ
สารบัญ
- SQL คืออะไรและ BigQuery รองรับภาษาใดบ้าง
- จะเริ่มต้นที่ไหน
- คุณสมบัติของ Google BigQuery
- ฟังก์ชันรวม
- ฟังก์ชั่นวันที่
- ฟังก์ชันสตริง
- ฟังก์ชั่นหน้าต่าง
- บทสรุป
SQL คืออะไรและ BigQuery รองรับภาษาใดบ้าง
Structured Query Language (SQL) ช่วยให้คุณดึงข้อมูลจาก เพิ่มข้อมูล และแก้ไขข้อมูลในอาร์เรย์ขนาดใหญ่ Google BigQuery รองรับภาษาถิ่นของ SQL สองภาษา: Standard SQL และ Legacy SQL ที่ล้าสมัย
ภาษาที่จะเลือกขึ้นอยู่กับความชอบของคุณ แต่ Google แนะนำให้ใช้ Standard SQL เพื่อประโยชน์เหล่านี้:
- ความยืดหยุ่นและการทำงานสำหรับช่องที่ซ้อนกันและทำซ้ำ
- รองรับภาษา DML และ DDL ช่วยให้คุณเปลี่ยนข้อมูลในตารางรวมถึงจัดการตารางและมุมมองใน GBQ
- การประมวลผลข้อมูลจำนวนมากเร็วขึ้นเมื่อเทียบกับ Legacy SQL
- รองรับการอัปเดต BigQuery ในอนาคตทั้งหมด
ดูข้อมูลเพิ่มเติมเกี่ยวกับความแตกต่างของภาษาได้ในเอกสาร BigQuery
ดูเพิ่มเติม: อะไรคือข้อดีของภาษา Standard SQL ใหม่ของ Google BigQuery เหนือ Legacy SQL และงานทางธุรกิจใดบ้างที่คุณสามารถแก้ไขได้
โดยค่าเริ่มต้น การสืบค้นข้อมูล Google BigQuery จะทำงานบน SQL เดิม
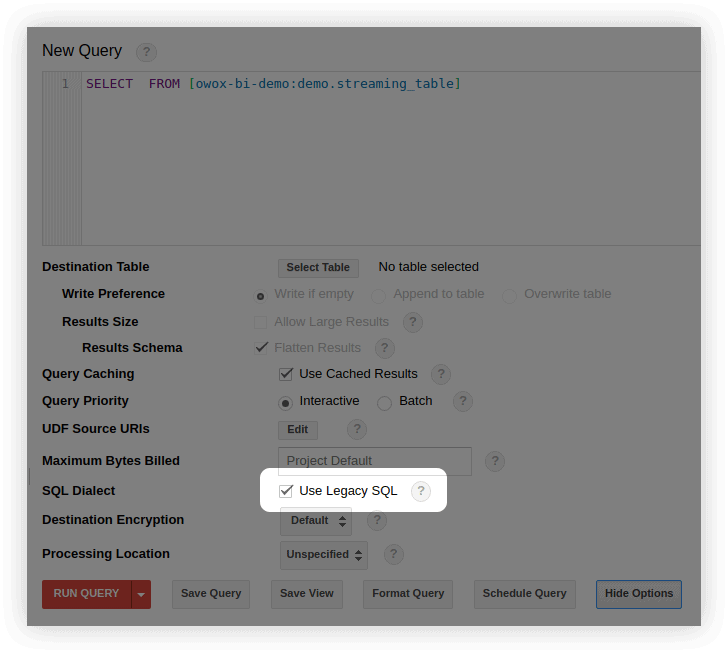
คุณสามารถเปลี่ยนเป็น Standard SQL ได้หลายวิธี:
- ในอินเทอร์เฟซ BigQuery ในหน้าต่างแก้ไขการสืบค้น ให้เลือก Show Options และเอาเครื่องหมายถูกที่อยู่ถัดจาก Use Legacy SQL ออก:
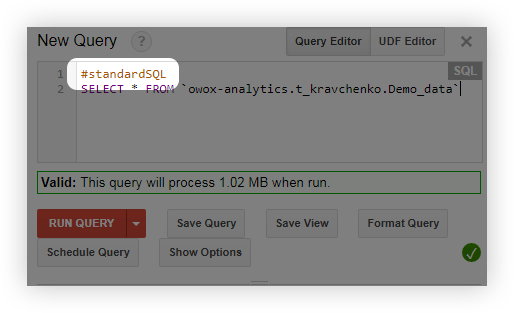
- ก่อนทำการสืบค้น ให้เพิ่มบรรทัด #standardSQL แล้วเริ่มการสืบค้นด้วยบรรทัดใหม่:
จะเริ่มต้นที่ไหน
เพื่อให้คุณสามารถฝึกฝนและเรียกใช้แบบสอบถามกับเรา เราได้เตรียมตารางที่มีข้อมูลสาธิต กรอกแบบฟอร์มด้านล่าง แล้วเราจะส่งอีเมลถึงคุณ


ข้อมูลสาธิตสำหรับการปฏิบัติแบบสอบถาม SQL
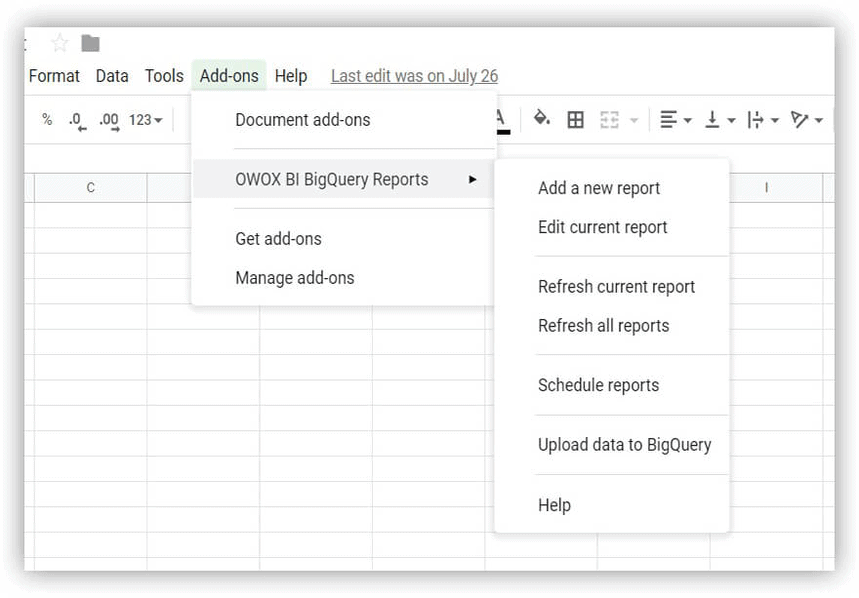
ดาวน์โหลด ในการเริ่มต้น ให้ดาวน์โหลดตารางข้อมูลสาธิตแล้วอัปโหลดไปยังโครงการ Google BigQuery วิธีที่ง่ายที่สุดในการทำเช่นนี้คือการใช้โปรแกรมเสริม OWOX BI BigQuery Reports
- เปิด Google ชีตและติดตั้งโปรแกรมเสริม OWOX BI BigQuery Reports
- เปิดตารางที่คุณดาวน์โหลดซึ่งมีข้อมูลสาธิตและเลือก OWOX BI BigQuery Reports –> อัปโหลดข้อมูลไปยัง BigQuery :
- ในหน้าต่างที่เปิดขึ้น ให้เลือกโปรเจ็กต์ Google BigQuery ชุดข้อมูล และคิดชื่อสำหรับตารางที่จะจัดเก็บข้อมูลที่โหลดไว้
- ระบุรูปแบบสำหรับข้อมูลที่โหลด (ตามที่แสดงในภาพหน้าจอ):

หากคุณไม่มีโครงการใน Google BigQuery ให้สร้างโครงการ ในการดำเนินการนี้ คุณจะต้องมีบัญชีสำหรับการเรียกเก็บเงินที่ใช้งานอยู่ใน Google Cloud Platform อย่าปล่อยให้คุณต้องกลัวว่าคุณต้องผูกบัตรธนาคาร: คุณจะไม่ถูกเรียกเก็บเงินโดยที่คุณไม่รู้ตัว นอกจากนี้ เมื่อคุณลงทะเบียน คุณจะได้รับ $300 เป็นเวลา 12 เดือน ซึ่งคุณสามารถใช้จ่ายในการจัดเก็บและประมวลผลข้อมูล
OWOX BI ช่วยให้คุณรวมข้อมูลจากระบบต่างๆ ลงใน BigQuery: ข้อมูลเกี่ยวกับการดำเนินการของผู้ใช้บนเว็บไซต์ การโทร คำสั่งซื้อจาก CRM อีเมล ค่าโฆษณา คุณสามารถใช้ OWOX BI เพื่อปรับแต่งการวิเคราะห์ขั้นสูงและรายงานความซับซ้อนโดยอัตโนมัติ
ก่อนที่จะพูดถึงคุณลักษณะของ Google BigQuery ให้จำไว้ว่าการสืบค้นข้อมูลพื้นฐานมีลักษณะอย่างไรในภาษาถิ่นของ SQL และ Standard SQL:
| แบบสอบถาม | SQL . ดั้งเดิม | มาตรฐานSQL |
|---|---|---|
| เลือกฟิลด์จากตาราง | เลือกฟิลด์ 1,field2 | เลือกฟิลด์ 1,field2 |
| เลือกตารางที่จะเลือกเขตข้อมูล | จาก [projectID:dataSet.tableName] | จาก `projectID.dataSet.tableName` |
| เลือกพารามิเตอร์ที่ต้องการกรองค่า | โดยที่ field1=value | โดยที่ field1=value |
| เลือกช่องที่จะจัดกลุ่มผลลัพธ์ | จัดกลุ่มตามฟิลด์ 1, field2 | จัดกลุ่มตามฟิลด์ 1, field2 |
| เลือกวิธีการสั่งผล | เรียงตามฟิลด์ 1 ASC (จากน้อยไปมาก) หรือ DESC (จากมากไปน้อย) | เรียงตามฟิลด์ 1 ASC (จากน้อยไปมาก) หรือ DESC (จากมากไปน้อย) |
คุณสมบัติของ Google BigQuery
เมื่อสร้างคำค้นหา คุณจะใช้ฟังก์ชันการรวม วันที่ สตริง และหน้าต่างบ่อยที่สุด มาดูฟังก์ชันแต่ละกลุ่มกันอย่างละเอียดยิ่งขึ้น
ดูเพิ่มเติม: วิธีเริ่มทำงานกับที่เก็บข้อมูลบนคลาวด์ — สร้างชุดข้อมูลและตาราง และกำหนดค่าการนำเข้าข้อมูลไปยัง Google BigQuery
ฟังก์ชันรวม
ฟังก์ชันการรวมจะให้ค่าสรุปสำหรับทั้งตาราง ตัวอย่างเช่น คุณสามารถใช้เพื่อคำนวณขนาดเช็คเฉลี่ยหรือรายได้รวมต่อเดือน หรือคุณสามารถใช้เพื่อเลือกกลุ่มผู้ใช้ที่ทำการซื้อได้สูงสุด
เหล่านี้เป็นฟังก์ชันรวมที่ได้รับความนิยมมากที่สุด:
| SQL . ดั้งเดิม | มาตรฐานSQL | ฟังก์ชั่นทำอะไร |
|---|---|---|
| AVG(ฟิลด์) | AVG([DISTINCT] (ฟิลด์)) | ส่งกลับค่าเฉลี่ยของคอลัมน์เขตข้อมูล ใน Standard SQL เมื่อคุณเพิ่มเงื่อนไข DISTINCT ค่าเฉลี่ยจะถูกพิจารณาเฉพาะสำหรับแถวที่มีค่าไม่ซ้ำกัน (ไม่ซ้ำ) ในคอลัมน์ฟิลด์ |
| MAX(ฟิลด์) | MAX(ฟิลด์) | ส่งกลับค่าสูงสุดจากคอลัมน์ฟิลด์ |
| MIN(ฟิลด์) | MIN(ฟิลด์) | ส่งคืนค่าต่ำสุดจากคอลัมน์ฟิลด์ |
| SUM(ฟิลด์) | SUM(ฟิลด์) | ส่งกลับผลรวมของค่าจากคอลัมน์ฟิลด์ |
| COUNT(ฟิลด์) | COUNT(ฟิลด์) | ส่งกลับจำนวนแถวในคอลัมน์เขตข้อมูล |
| EXACT_COUNT_DISTINCT(ฟิลด์) | COUNT([DISTINCT] (ฟิลด์)) | ส่งกลับจำนวนแถวที่ไม่ซ้ำในคอลัมน์ฟิลด์ |
สำหรับรายการฟังก์ชันการรวมทั้งหมด โปรดดูเอกสาร Legacy SQL และ Standard SQL
ลองดูข้อมูลสาธิตเพื่อดูว่าฟังก์ชันเหล่านี้ทำงานอย่างไร เราสามารถคำนวณรายได้เฉลี่ยสำหรับธุรกรรม การซื้อสำหรับจำนวนเงินสูงสุดและต่ำสุด รายได้รวม ธุรกรรมทั้งหมด และจำนวนธุรกรรมที่ไม่ซ้ำ (เพื่อตรวจสอบว่ามีการซื้อซ้ำหรือไม่) ในการดำเนินการนี้ เราจะเขียนข้อความค้นหาที่เราระบุชื่อโครงการ Google BigQuery ชุดข้อมูล และตาราง
#legacySQL
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]#มาตรฐานSQL
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`เป็นผลให้เราได้รับสิ่งต่อไปนี้:
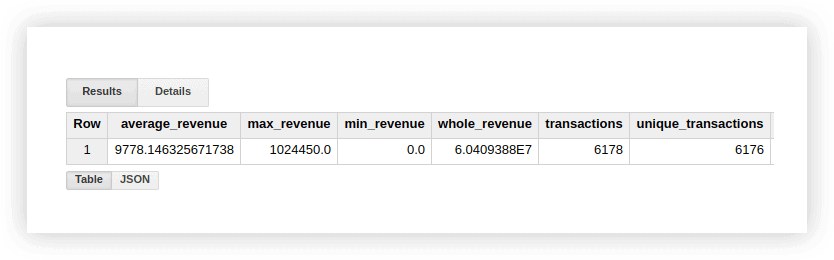
คุณสามารถตรวจสอบผลลัพธ์ของการคำนวณเหล่านี้ได้ในตารางต้นฉบับพร้อมข้อมูลสาธิตโดยใช้ฟังก์ชันมาตรฐานของ Google ชีต (SUM, AVG และอื่นๆ) หรือใช้ตารางสรุปผล
ดังที่คุณเห็นจากภาพหน้าจอด้านบน จำนวนธุรกรรมและธุรกรรมที่ไม่ซ้ำนั้นแตกต่างกัน นี่แสดงให้เห็นว่ามีธุรกรรมสองรายการในตารางของเราที่มีรหัสธุรกรรมเดียวกัน:

หากคุณสนใจธุรกรรมที่ไม่ซ้ำ ให้ใช้ฟังก์ชันที่นับสตริงที่ไม่ซ้ำ อีกวิธีหนึ่ง คุณสามารถจัดกลุ่มข้อมูลโดยใช้ฟังก์ชัน GROUP BY เพื่อกำจัดข้อมูลที่ซ้ำกันก่อนที่จะใช้ฟังก์ชันการรวม
ข้อมูลสาธิตสำหรับการปฏิบัติแบบสอบถาม SQL
ดาวน์โหลดฟังก์ชั่นวันที่
ฟังก์ชันเหล่านี้ช่วยให้คุณประมวลผลวันที่: เปลี่ยนรูปแบบ เลือกฟิลด์ที่จำเป็น (วัน เดือน หรือปี) หรือเปลี่ยนวันที่ตามช่วงเวลา
อาจมีประโยชน์เมื่อ:
- แปลงวันที่และเวลาจากแหล่งต่างๆ ให้เป็นรูปแบบเดียวเพื่อตั้งค่าการวิเคราะห์ขั้นสูง
- การสร้างรายงานที่อัปเดตโดยอัตโนมัติหรือทริกเกอร์การส่งจดหมาย (เช่น เมื่อคุณต้องการข้อมูลในช่วงสองชั่วโมง สัปดาห์ หรือเดือนล่าสุด)
- การสร้างรายงานกลุ่มประชากรตามรุ่นซึ่งจำเป็นต้องได้รับข้อมูลเป็นระยะเวลาวัน สัปดาห์ หรือเดือน
เหล่านี้เป็นฟังก์ชันวันที่ที่ใช้บ่อยที่สุด:
| SQL . ดั้งเดิม | มาตรฐานSQL | คำอธิบายฟังก์ชัน |
|---|---|---|
| วันที่ปัจจุบัน() | วันที่ปัจจุบัน() | ส่งกลับวันที่ปัจจุบันในรูปแบบ % YYYY -% MM-% DD |
| วันที่(ประทับเวลา) | วันที่(ประทับเวลา) | แปลงวันที่จาก % YYYY -% MM-% DD% H:% M:% C. เป็น % YYYY -% MM-% DD รูปแบบ |
| DATE_ADD(การประทับเวลา, ช่วงเวลา, ช่วง_หน่วย) | DATE_ADD(การประทับเวลา ช่วงเวลา INTERVAL interval_units) | ส่งกลับวันที่ประทับเวลา โดยเพิ่มขึ้นตามช่วงเวลาที่ระบุ Interval_units ใน Legacy SQL สามารถรับค่า YEAR, MONTH, DAY, HOUR, MINUTE และ SECOND ใน Standard SQL อาจใช้เวลา YEAR, QUARTER, MONTH, สัปดาห์และวัน |
| DATE_ADD(การประทับเวลา - ช่วงเวลา, ช่วง_หน่วย) | DATE_SUB (การประทับเวลา ช่วงเวลา INTERVAL interval_units) | ส่งกลับวันที่ประทับเวลา โดยลดลงตามช่วงเวลาที่ระบุ |
| DATEDIFF(การประทับเวลา1, การประทับเวลา2) | DATE_DIFF(ประทับเวลา1, ประทับเวลา2, date_part) | ส่งกลับค่าความแตกต่างระหว่างวันที่ประทับเวลา1และประทับเวลา2 ใน Legacy SQL จะส่งคืนค่าส่วนต่างเป็นวัน และใน Standard SQL จะส่งคืนค่าส่วนต่างโดยขึ้นอยู่กับค่า date_part ที่ระบุ (วัน สัปดาห์ เดือน ไตรมาส ปี) |
| วัน(ประทับเวลา) | EXTRACT (วันจากเวลาประทับ) | ส่งกลับวันจากวันที่ประทับเวลา รับค่าตั้งแต่ 1 ถึง 31 |
| เดือน(ประทับเวลา) | EXTRACT (เดือนจากการประทับเวลา) | ส่งกลับหมายเลขลำดับเดือนจากวันที่ประทับเวลา รับค่าตั้งแต่ 1 ถึง 12 |
| ปี(ประทับเวลา) | EXTRACT (ปีจากการประทับเวลา) | ส่งกลับปีจากวันที่ประทับเวลา |
สำหรับรายการฟังก์ชันวันที่ทั้งหมด โปรดดูเอกสาร Legacy SQL และ Standard SQL
ลองดูข้อมูลสาธิตของเราเพื่อดูว่าแต่ละฟังก์ชันทำงานอย่างไร ตัวอย่างเช่น เราจะได้วันที่ปัจจุบัน เปลี่ยนวันที่จากตารางต้นฉบับให้อยู่ในรูปแบบ % YYYY -% MM-% DD นำออกไป และเพิ่มวันเข้าไป จากนั้น เราจะคำนวณความแตกต่างระหว่างวันที่ปัจจุบันและวันที่จากตารางต้นทาง และแบ่งวันที่ปัจจุบันออกเป็นช่องปี เดือน และวันที่แยกจากกัน ในการทำเช่นนี้ คุณสามารถคัดลอกแบบสอบถามตัวอย่างด้านล่างและแทนที่ชื่อโครงการ ชุดข้อมูล และตารางข้อมูลด้วยของคุณเอง
#legacySQL
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]#มาตรฐานSQL
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)
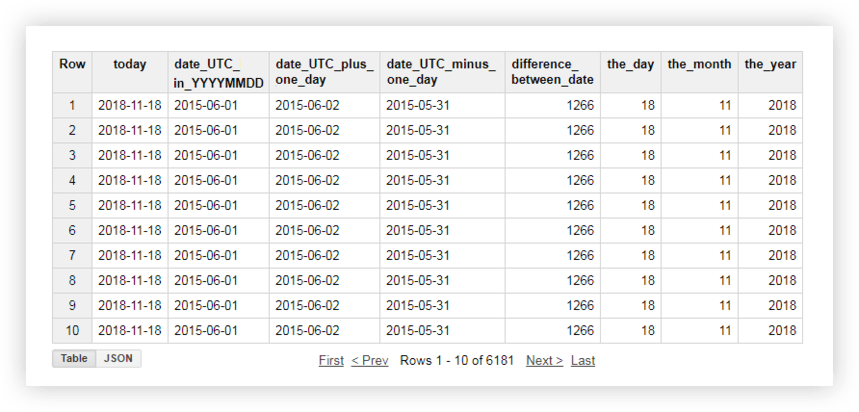
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)หลังจากเรียกใช้แบบสอบถาม คุณจะได้รับรายงานนี้:
ดูเพิ่มเติม: ตัวอย่างรายงานที่สามารถสร้างโดยใช้การสืบค้น SQL กับข้อมูลใน Google BigQuery และตัวชี้วัดเฉพาะใดบ้างที่คุณสามารถเสริมข้อมูล Google Analytics ด้วย OWOX BI
ฟังก์ชันสตริง
ฟังก์ชันสตริงช่วยให้คุณสร้างสตริง เลือกและแทนที่สตริงย่อย และคำนวณความยาวของสตริงและลำดับดัชนีของสตริงย่อยในสตริงดั้งเดิม ตัวอย่างเช่น ด้วยฟังก์ชันสตริง คุณสามารถ:
- กรองรายงานด้วยแท็ก UTM ที่ส่งผ่านไปยัง URL ของหน้า
- นำข้อมูลมาเป็นรูปแบบเดียวหากชื่อแหล่งที่มาและแคมเปญเขียนด้วยการลงทะเบียนต่างกัน
- แทนที่ข้อมูลที่ไม่ถูกต้องในรายงาน (เช่น หากพิมพ์ชื่อแคมเปญผิด)
ฟังก์ชันเหล่านี้เป็นฟังก์ชันยอดนิยมสำหรับการทำงานกับสตริง:
| SQL . ดั้งเดิม | มาตรฐานSQL | คำอธิบายฟังก์ชัน |
|---|---|---|
| CONCAT('str1', 'str2') หรือ 'str1'+ 'str2' | CONCAT('str1', 'str2') | เชื่อม 'str1' และ 'str2' เป็นสตริงเดียว |
| 'str1' ประกอบด้วย 'str2' | REGEXP_CONTAINS('str1', 'str2') หรือ 'str1' เช่น '%str2%' | คืนค่า true หากสตริง 'str1' มีสตริง 'str2' ใน Standard SQL สตริง 'str2' สามารถเขียนเป็นนิพจน์ทั่วไปได้โดยใช้ ไลบรารี re2 |
| LENGTH('str' ) | CHAR_LENGTH('str' )หรือ CHARACTER_LENGTH('str' ) | ส่งกลับความยาวของสตริง 'str' (จำนวนอักขระ) |
| SUBSTR('str', ดัชนี [, max_len]) | SUBSTR('str', ดัชนี [, max_len]) | ส่งกลับสตริงย่อยของความยาว max_len ที่เริ่มต้นด้วยอักขระดัชนีจากสตริง 'str' |
| ล่าง('str') | ล่าง('str') | แปลงอักขระทั้งหมดในสตริง 'str เป็นตัวพิมพ์เล็ก |
| บน(str) | บน(str) | แปลงอักขระทั้งหมดในสตริง 'str' เป็นตัวพิมพ์ใหญ่ |
| INSTR('str1', 'str2') | STRPOS('str1', 'str2') | ส่งกลับดัชนีของสตริงที่เกิดขึ้นครั้งแรก 'str2' เป็นสตริง 'str1'; มิฉะนั้นจะคืนค่า 0 |
| แทนที่ ('str1', 'str2', 'str3') | แทนที่ ('str1', 'str2', 'str3') | แทนที่ 'str1' ด้วย 'str2' ด้วย 'str3' |
คุณสามารถเรียนรู้เพิ่มเติมเกี่ยวกับฟังก์ชันสตริงทั้งหมดในเอกสารคู่มือ Legacy SQL และ Standard SQL
ลองดูข้อมูลสาธิตเพื่อดูวิธีใช้ฟังก์ชันที่อธิบายไว้ สมมติว่าเรามีสามคอลัมน์แยกกันที่มีค่าวัน เดือน และปี:

การทำงานกับวันที่ในรูปแบบนี้ไม่สะดวกนัก เราจึงสามารถรวมค่าต่างๆ ไว้ในคอลัมน์เดียวได้ ในการดำเนินการนี้ ให้ใช้คำสั่ง SQL ด้านล่าง และอย่าลืมแทนที่ชื่อโปรเจ็กต์ ชุดข้อมูล และตารางใน Google BigQuery
#legacySQL
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1#มาตรฐานSQL
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1
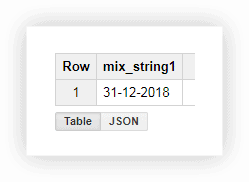
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1หลังจากเรียกใช้แบบสอบถาม เราได้รับวันที่ในหนึ่งคอลัมน์:
บ่อยครั้งเมื่อคุณดาวน์โหลดหน้าเว็บบนเว็บไซต์ URL จะบันทึกค่าของตัวแปรที่ผู้ใช้เลือก ซึ่งอาจเป็นวิธีการชำระเงินหรือการจัดส่ง หมายเลขธุรกรรม ดัชนีของร้านค้าจริงที่ผู้ซื้อต้องการรับสินค้า ฯลฯ การใช้แบบสอบถาม SQL คุณสามารถเลือกพารามิเตอร์เหล่านี้จากที่อยู่เพจได้ ลองพิจารณาสองตัวอย่างว่าคุณจะทำสิ่งนี้ได้อย่างไรและเพราะเหตุใด
ตัวอย่างที่ 1 . สมมติว่าเราต้องการทราบจำนวนการซื้อที่ผู้ใช้ไปรับสินค้าจากหน้าร้านจริง ในการดำเนินการนี้ เราจำเป็นต้องคำนวณจำนวนธุรกรรมที่ส่งจากหน้าใน URL ที่มีสตริงย่อย shop_id (ดัชนีสำหรับร้านค้าจริง) เราสามารถทำได้ด้วยแบบสอบถามต่อไปนี้:
#legacySQL
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check#มาตรฐานSQL

SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2
SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2จากตารางผลลัพธ์ เราจะเห็นว่า 5502 ธุรกรรม (check = true) ถูกส่งจากเพจที่มี shop_id:

ตัวอย่างที่ 2 . คุณได้กำหนด delivery_id ให้กับวิธีการจัดส่งแต่ละวิธี และคุณระบุค่าของพารามิเตอร์นี้ใน URL ของหน้า หากต้องการทราบวิธีการจัดส่งที่ผู้ใช้เลือก คุณต้องเลือก delivery_id ในคอลัมน์แยกต่างหาก
เราสามารถใช้แบบสอบถามต่อไปนี้สำหรับสิ่งนี้:
#legacySQL
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC#มาตรฐานSQL
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASCเป็นผลให้เราได้รับตารางเช่นนี้ใน Google BigQuery:
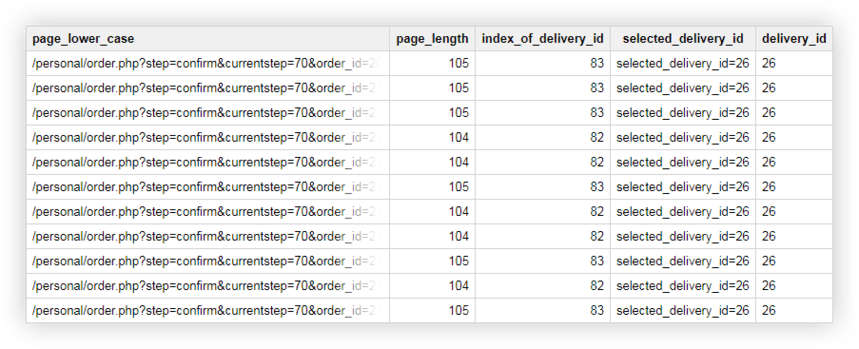
ข้อมูลสาธิตสำหรับการปฏิบัติแบบสอบถาม SQL
ดาวน์โหลดฟังก์ชั่นหน้าต่าง
ฟังก์ชันเหล่านี้คล้ายกับฟังก์ชันรวมที่เรากล่าวถึงข้างต้น ความแตกต่างหลัก ๆ คือ ฟังก์ชันของหน้าต่างไม่ทำการคำนวณกับชุดข้อมูลทั้งหมดที่เลือกโดยใช้คิวรี แต่จะคำนวณเฉพาะส่วนหนึ่งของข้อมูลนั้นเท่านั้น — เซตย่อยหรือ หน้าต่าง
เมื่อใช้ฟังก์ชันหน้าต่าง คุณสามารถรวมข้อมูลในส่วนกลุ่มโดยไม่ต้องใช้ฟังก์ชัน JOIN เพื่อรวมการสืบค้นหลายรายการ ตัวอย่างเช่น คุณสามารถคำนวณรายได้เฉลี่ยต่อแคมเปญโฆษณาหรือจำนวนธุรกรรมต่ออุปกรณ์ ด้วยการเพิ่มฟิลด์อื่นในรายงาน คุณสามารถค้นหาได้อย่างง่ายดาย เช่น ส่วนแบ่งของรายได้จากแคมเปญโฆษณาในวัน Black Friday หรือส่วนแบ่งของธุรกรรมที่เกิดจากแอปพลิเคชันมือถือ
คุณต้องสะกดนิพจน์ OVER ที่กำหนดขอบเขตหน้าต่างร่วมกับแต่ละฟังก์ชันในคิวรี OVER มีสามองค์ประกอบที่คุณสามารถใช้งานได้:
- PARTITION BY — กำหนดคุณลักษณะที่คุณแบ่งข้อมูลต้นฉบับออกเป็นชุดย่อย เช่น clientId หรือ DayTime
- ORDER BY — กำหนดลำดับของแถวในชุดย่อย เช่น DESC . ชั่วโมง
- กรอบหน้าต่าง — ให้คุณประมวลผลแถวภายในชุดย่อยของคุณสมบัติเฉพาะ (เช่น เฉพาะห้าแถวก่อนแถวปัจจุบัน)
ในตารางนี้ เราได้รวบรวมฟังก์ชันหน้าต่างที่ใช้บ่อยที่สุด:
| SQL . ดั้งเดิม | มาตรฐานSQL | คำอธิบายฟังก์ชัน |
|---|---|---|
| AVG(ฟิลด์) COUNT(ฟิลด์) COUNT(ฟิลด์ DISTINCT) แม็กซ์() นาที() ผลรวม() | AVG([DISTINCT] (ฟิลด์)) COUNT(ฟิลด์) COUNT([DISTINCT] (ฟิลด์)) MAX(ฟิลด์) MIN(ฟิลด์) SUM(ฟิลด์) | ส่งคืนค่าเฉลี่ย ตัวเลข สูงสุด ต่ำสุด และรวมจากคอลัมน์ฟิลด์ภายในชุดย่อยที่เลือก DISTINCT ใช้ในการคำนวณเฉพาะค่าที่ไม่ซ้ำ (ไม่ซ้ำ) |
| DENSE_RANK() | DENSE_RANK() | ส่งกลับหมายเลขแถวภายในเซตย่อย |
| FIRST_VALUE(ฟิลด์) | FIRST_VALUE (ฟิลด์[{RESPECT | IGNORE} NULLS]) | ส่งคืนค่าของแถวแรกจากคอลัมน์เขตข้อมูลภายในชุดย่อย โดยค่าเริ่มต้น แถวที่มีค่าว่างจากคอลัมน์ฟิลด์จะรวมอยู่ในการคำนวณ RESPECT หรือ IGNORE NULLS ระบุว่าจะรวมหรือละเว้นสตริง NULL หรือไม่ |
| LAST_VALUE(ฟิลด์) | LAST_VALUE (ฟิลด์ [{RESPECT | IGNORE} NULLS]) | ส่งคืนค่าของแถวสุดท้ายภายในชุดย่อยจากคอลัมน์ของฟิลด์ โดยค่าเริ่มต้น แถวที่มีค่าว่างในคอลัมน์ฟิลด์จะรวมอยู่ในการคำนวณ RESPECT หรือ IGNORE NULLS ระบุว่าจะรวมหรือละเว้นสตริง NULL หรือไม่ |
| LAG(ฟิลด์) | LAG (ฟิลด์[, ออฟเซ็ต [, default_expression]]) | ส่งคืนค่าของแถวก่อนหน้าโดยสัมพันธ์กับคอลัมน์ฟิลด์ปัจจุบันภายในเซตย่อย Offset เป็นจำนวนเต็มที่ระบุจำนวนแถวที่จะออฟเซ็ตจากแถวปัจจุบัน Default_expression คือค่าที่ฟังก์ชันจะคืนค่าหากไม่ต้องการ สตริงภายในเซตย่อย |
| ตะกั่ว(ฟิลด์) | LEAD (ฟิลด์[, ออฟเซ็ต [, default_expression]]) | ส่งคืนค่าของแถวถัดไปที่สัมพันธ์กับคอลัมน์ฟิลด์ปัจจุบันภายในเซตย่อย ออฟเซ็ตเป็นจำนวนเต็มที่กำหนดจำนวนแถวที่คุณต้องการย้ายขึ้นไปเทียบกับแถวปัจจุบัน Default_expression คือค่าที่ฟังก์ชันจะคืนค่าหากไม่มีสตริงที่จำเป็นภายในเซตย่อยปัจจุบัน |
คุณสามารถดูรายการฟังก์ชันการวิเคราะห์รวมและฟังก์ชันการนำทางในเอกสารประกอบสำหรับ Legacy SQL และ Standard SQL
ตัวอย่างที่ 1 . สมมติว่าเราต้องการวิเคราะห์กิจกรรมของลูกค้าในช่วงเวลาทำงานและนอกเวลางาน ในการทำเช่นนี้ เราจำเป็นต้องแบ่งธุรกรรมออกเป็นสองกลุ่มและคำนวณเมตริกที่น่าสนใจ:
- กลุ่มที่ 1 — การซื้อในช่วงเวลาทำการ 9:00 ถึง 18:00
- กลุ่มที่ 2 — ซื้อหลังเวลา 00:00 น. ถึง 9:00 น. และ 18:00 น. ถึง 23:59 น
นอกเหนือจากชั่วโมงทำงานและนอกเวลาทำงาน ตัวแปรอื่นสำหรับการสร้างหน้าต่างคือ clientId นั่นคือ สำหรับผู้ใช้แต่ละคน เราจะมีสองหน้าต่าง:
| หน้าต่าง | รหัสลูกค้า | เวลากลางวัน |
|---|---|---|
| หน้าต่าง 1 | รหัสลูกค้า 1 | ชั่วโมงทำงาน |
| หน้าต่าง2 | รหัสลูกค้า 2 | นอกเวลางาน |
| หน้าต่าง3 | รหัสลูกค้า 3 | ชั่วโมงทำงาน |
| หน้าต่าง4 | รหัสลูกค้า 4 | นอกเวลางาน |
| หน้าต่าง N | รหัสลูกค้า N | ชั่วโมงทำงาน |
| หน้าต่าง N+1 | รหัสลูกค้า N+1 | นอกเวลางาน |
ลองใช้ข้อมูลสาธิตเพื่อคำนวณรายได้เฉลี่ย สูงสุด ต่ำสุด และรวม จำนวนธุรกรรมทั้งหมด และจำนวนธุรกรรมที่ไม่ซ้ำต่อผู้ใช้ระหว่างชั่วโมงทำงานและนอกเวลาทำงาน คำขอด้านล่างจะช่วยให้เราทำสิ่งนี้ได้
#legacySQL
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC#มาตรฐานSQL
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESCลองดูสิ่งที่เกิดขึ้นโดยใช้ตัวอย่างของผู้ใช้ที่มี clientId 102041117.1428132012 ในตารางเดิมสำหรับผู้ใช้รายนี้ เรามีข้อมูลต่อไปนี้:

โดยการเรียกใช้แบบสอบถาม เราได้รับรายงานที่ประกอบด้วยรายได้เฉลี่ย ต่ำสุด สูงสุด และรวมจากผู้ใช้รายนี้ ตลอดจนจำนวนธุรกรรมทั้งหมดของผู้ใช้ ดังที่คุณเห็นในภาพหน้าจอด้านล่าง ธุรกรรมทั้งสองถูกสร้างขึ้นโดยผู้ใช้ในช่วงเวลาทำงาน:

ตัวอย่างที่ 2 . ตอนนี้สำหรับงานที่ซับซ้อนมากขึ้น:
- ใส่หมายเลขลำดับสำหรับธุรกรรมทั้งหมดในหน้าต่างขึ้นอยู่กับเวลาของการดำเนินการ จำได้ว่าเรากำหนดหน้าต่างโดยผู้ใช้และช่วงเวลาทำงาน/ไม่ทำงาน
- รายงานรายได้ของธุรกรรมถัดไป/ก่อนหน้า (เทียบกับปัจจุบัน) ภายในหน้าต่าง
- แสดงรายได้ของการทำธุรกรรมครั้งแรกและครั้งสุดท้ายในหน้าต่าง
ในการดำเนินการนี้ เราจะใช้แบบสอบถามต่อไปนี้:
#legacySQL
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour#มาตรฐานSQL
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hourเราสามารถตรวจสอบผลลัพธ์ของการคำนวณโดยใช้ตัวอย่างของผู้ใช้ที่เราทราบอยู่แล้ว: clientId 102041117.1428132012:

จากภาพหน้าจอด้านบน เราจะเห็นว่า:
- รายการแรกคือเวลา 15:00 น. และธุรกรรมที่สองคือเวลา 16:00 น.
- หลังจากทำรายการเวลา 15:00 น. มีการทำธุรกรรมเวลา 16:00 น. โดยมีรายได้ 25066 (column lead_revenue)
- ก่อนทำรายการเวลา 16:00 น. มีธุรกรรมเวลา 15:00 น. โดยมีรายได้ 3699 (คอลัมน์ lag_revenue)
- ธุรกรรมแรกภายในหน้าต่างคือเวลา 15:00 น. และรายได้สำหรับธุรกรรมนี้คือ 3699 (คอลัมน์ first_revenue_by_hour)
- คิวรีประมวลผลข้อมูลทีละบรรทัด ดังนั้นสำหรับธุรกรรมที่เป็นปัญหา ธุรกรรมสุดท้ายในหน้าต่างจะเป็นตัวมันเอง และค่าในคอลัมน์ last_revenue_by_hour และรายได้จะเท่ากัน
บทความที่เป็นประโยชน์เกี่ยวกับ Google BigQuery:
- เครื่องมือสร้างภาพ BigQuery 6 อันดับแรก
- วิธีอัปโหลดข้อมูลไปยัง Google BigQuery
- วิธีอัปโหลดข้อมูลดิบจากโฆษณา Google ไปยัง Google BigQuery
- Google BigQuery Google ชีต Connector
- รายงานอัตโนมัติใน Google ชีตโดยใช้ข้อมูลจาก Google BigQuery
- รายงานอัตโนมัติใน Google Data Studio ตามข้อมูลจาก Google BigQuery
หากคุณต้องการรวบรวมข้อมูลที่ไม่ได้เก็บตัวอย่างจากเว็บไซต์ของคุณใน Google BigQuery แต่ไม่รู้ว่าจะเริ่มต้นจากที่ใด ให้จองการสาธิต เราจะบอกคุณเกี่ยวกับความเป็นไปได้ทั้งหมดที่คุณได้รับจาก BigQuery และ OWOX BI
ลูกค้าของเรา
เติบโต เร็วขึ้น 22%
เติบโตเร็วขึ้นด้วยการวัดว่าอะไรทำงานได้ดีที่สุดในการทำการตลาดของคุณ
วิเคราะห์ประสิทธิภาพทางการตลาดของคุณ ค้นหาพื้นที่การเติบโต เพิ่ม ROI
รับการสาธิตบทสรุป
ในบทความนี้ เราได้พิจารณากลุ่มฟังก์ชันที่ได้รับความนิยมมากที่สุด ได้แก่ การรวม วันที่ สตริง และหน้าต่าง อย่างไรก็ตาม Google BigQuery มีฟังก์ชันที่มีประโยชน์อีกมากมาย เช่น:
- ฟังก์ชันการหล่อที่ให้คุณแปลงข้อมูลเป็นรูปแบบเฉพาะได้
- ฟังก์ชันสัญลักษณ์แทนตารางที่ให้คุณเข้าถึงหลายตารางในชุดข้อมูล
- ฟังก์ชันนิพจน์ทั่วไปที่ให้คุณอธิบายรูปแบบของคำค้นหา ไม่ใช่ค่าที่แน่นอน
แน่นอนเราจะเขียนเกี่ยวกับฟังก์ชันเหล่านี้ในบล็อกของเรา ในระหว่างนี้ คุณสามารถลองใช้ฟังก์ชันทั้งหมดที่อธิบายไว้ในบทความนี้โดยใช้ข้อมูลสาธิตของเรา
ข้อมูลสาธิตสำหรับการปฏิบัติแบบสอบถาม SQL
ดาวน์โหลด