
Panoramica delle principali funzionalità di Google BigQuery: esercitati a scrivere richieste per analisi di marketing
Pubblicato: 2022-04-12Più informazioni accumula un'azienda, più acuta è la domanda su dove archiviarle. Se non hai la capacità o desideri mantenere i tuoi server, Google BigQuery (GBQ) può aiutarti. BigQuery fornisce uno storage veloce, conveniente e scalabile per lavorare con i big data e ti consente di scrivere query utilizzando una sintassi simile a SQL, nonché funzioni standard e definite dall'utente.
In questo articolo, esaminiamo le principali funzioni di BigQuery e mostriamo le loro possibilità utilizzando esempi specifici. Imparerai come scrivere query di base e testarle su dati demo.
Crea report sui dati GBQ senza formazione tecnica o conoscenza di SQL.
Hai regolarmente bisogno di report sulle campagne pubblicitarie ma non hai tempo per studiare SQL o aspettare una risposta dai tuoi analisti? Con OWOX BI puoi creare report senza dover capire come sono strutturati i tuoi dati. Seleziona semplicemente i parametri e le metriche che desideri visualizzare nel tuo rapporto Smart Data. OWOX BI Smart Data visualizzerà istantaneamente i tuoi dati in un modo che puoi capire.
Sommario
- Che cos'è SQL e quali dialetti supporta BigQuery
- Dove iniziare
- Funzionalità di Google BigQuery
- Funzioni aggregate
- Funzioni di data
- Funzioni di stringa
- Funzioni della finestra
- Conclusioni
Che cos'è SQL e quali dialetti supporta BigQuery
Structured Query Language (SQL) consente di recuperare dati, aggiungere dati e modificare dati in matrici di grandi dimensioni. Google BigQuery supporta due dialetti SQL: SQL standard e SQL legacy obsoleto.
Quale dialetto scegliere dipende dalle tue preferenze, ma Google consiglia di utilizzare Standard SQL per questi vantaggi:
- Flessibilità e funzionalità per campi nidificati e ripetuti
- Supporto per i linguaggi DML e DDL, che consente di modificare i dati nelle tabelle e di gestire tabelle e viste in GBQ
- Elaborazione più rapida di grandi quantità di dati rispetto a Legacy SQL
- Supporto per tutti i futuri aggiornamenti di BigQuery
Puoi saperne di più sulle differenze dialettali nella documentazione di BigQuery.
Vedi anche: quali sono i vantaggi del nuovo dialetto SQL standard di Google BigQuery rispetto a Legacy SQL e quali attività aziendali puoi risolvere con esso?
Per impostazione predefinita, le query di Google BigQuery vengono eseguite su Legacy SQL.
Puoi passare a SQL standard in diversi modi:
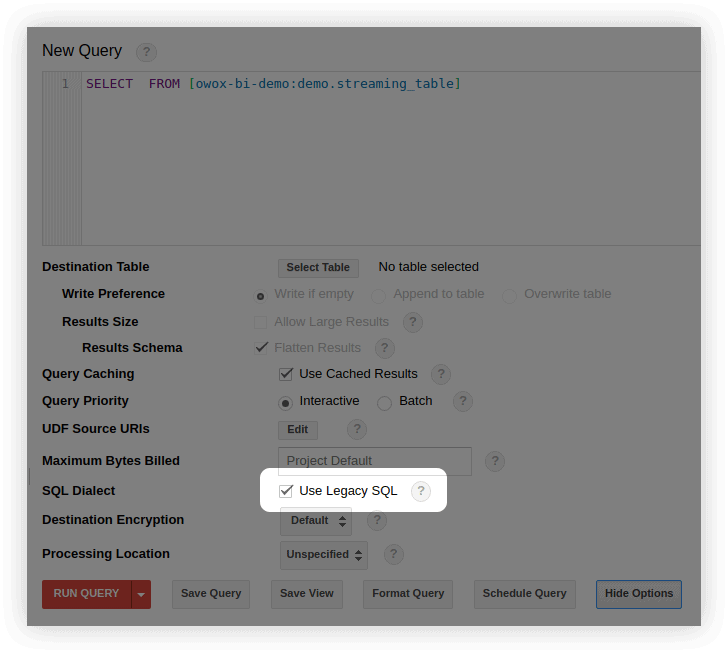
- Nell'interfaccia di BigQuery, nella finestra di modifica della query, seleziona Mostra opzioni e rimuovi il segno di spunta accanto a Usa SQL legacy :
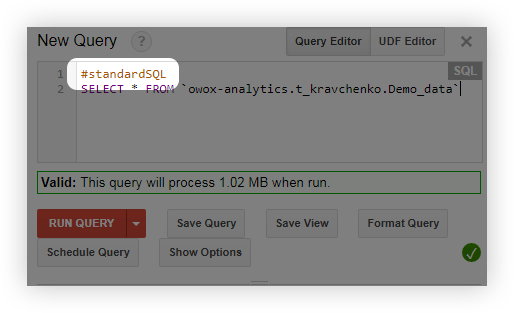
- Prima di eseguire una query, aggiungi la riga #standardSQL e inizia la query con una nuova riga:
Dove iniziare
Per esercitarti ed eseguire query con noi, abbiamo preparato una tabella con dati demo. Compila il modulo sottostante e te lo invieremo via email.


Dati demo per la pratica delle query SQL
Scarica Per iniziare, scarica la tabella dei dati demo e caricala nel tuo progetto Google BigQuery. Il modo più semplice per farlo è con il componente aggiuntivo OWOX BI BigQuery Reports.
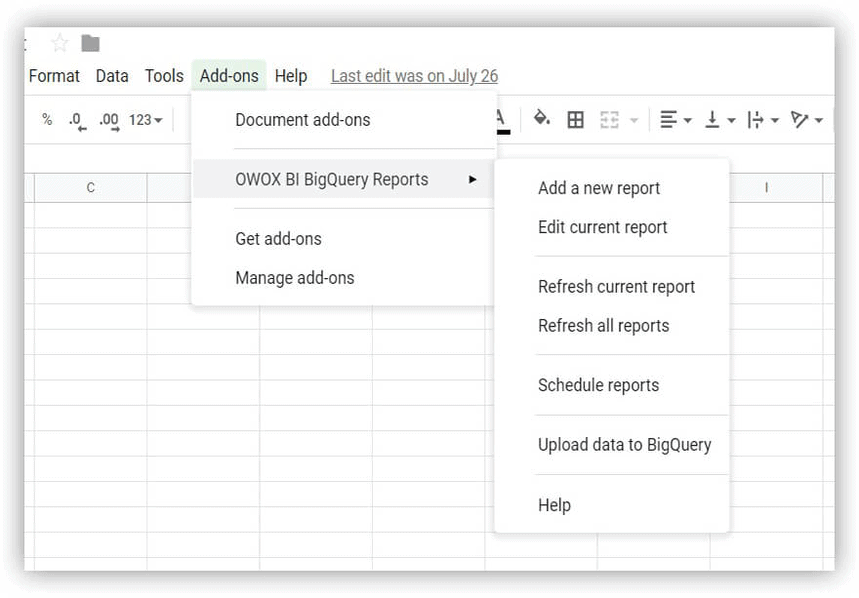
- Apri Fogli Google e installa il componente aggiuntivo OWOX BI BigQuery Reports.
- Apri la tabella che hai scaricato che contiene i dati demo e seleziona OWOX BI BigQuery Reports -> Carica dati su BigQuery :
- Nella finestra che si apre, scegli il tuo progetto Google BigQuery, un set di dati e pensa a un nome per la tabella in cui verranno archiviati i dati caricati.
- Specificare un formato per i dati caricati (come mostrato nello screenshot):

Se non hai un progetto in Google BigQuery, creane uno. Per fare ciò, avrai bisogno di un account di fatturazione attivo in Google Cloud Platform. Non farti spaventare dalla necessità di collegare una carta di credito: non ti verrà addebitato nulla a tua insaputa. Inoltre, quando ti registri, riceverai $ 300 per 12 mesi che puoi spendere per l'archiviazione e l'elaborazione dei dati.
OWOX BI ti aiuta a combinare i dati di diversi sistemi in BigQuery: dati sulle azioni degli utenti sul tuo sito web, chiamate, ordini dal tuo CRM, e-mail, costi pubblicitari. Puoi utilizzare OWOX BI per personalizzare analisi avanzate e automatizzare report di qualsiasi complessità.
Prima di parlare delle funzionalità di Google BigQuery, ricordiamo che aspetto hanno le query di base nei dialetti Legacy SQL e Standard SQL:
| Domanda | SQL legacy | SQL standard |
|---|---|---|
| Seleziona i campi dalla tabella | SELEZIONA campo1,campo2 | SELEZIONA campo1,campo2 |
| Seleziona una tabella da cui scegliere i campi | DA [IDprogetto:dataSet.nometabella] | DA `projectID.dataSet.tableName` |
| Selezionare il parametro in base al quale filtrare i valori | WHERE campo1=valore | WHERE campo1=valore |
| Seleziona i campi in base ai quali raggruppare i risultati | GRUPPO PER campo1, campo2 | GRUPPO PER campo1, campo2 |
| Seleziona come ordinare i risultati | ORDINA PER campo1 ASC (crescente) o DESC (decrescente) | ORDINA PER campo1 ASC (crescente) o DESC (decrescente) |
Funzionalità di Google BigQuery
Durante la creazione di query, utilizzerai più frequentemente le funzioni aggregate , date, string e window. Diamo un'occhiata più da vicino a ciascuno di questi gruppi di funzioni.
Vedi anche: Come iniziare a lavorare con il cloud storage: crea un set di dati e tabelle e configura l'importazione dei dati in Google BigQuery.
Funzioni aggregate
Le funzioni di aggregazione forniscono valori di riepilogo per un'intera tabella. Ad esempio, puoi utilizzarli per calcolare la dimensione media dell'assegno o le entrate totali al mese oppure puoi utilizzarli per selezionare il segmento di utenti che ha effettuato il numero massimo di acquisti.
Queste sono le funzioni aggregate più popolari:
| SQL legacy | SQL standard | Cosa fa la funzione |
|---|---|---|
| MEDIA (campo) | MEDIA([DISTINTA] (campo)) | Restituisce il valore medio della colonna del campo. In SQL standard, quando si aggiunge una condizione DISTINCT, la media viene considerata solo per le righe con valori univoci (non ripetuti) nella colonna del campo. |
| MAX(campo) | MAX(campo) | Restituisce il valore massimo dalla colonna del campo. |
| MIN(campo) | MIN(campo) | Restituisce il valore minimo dalla colonna del campo. |
| SOMMA(campo) | SOMMA(campo) | Restituisce la somma dei valori dalla colonna del campo. |
| COUNT(campo) | COUNT(campo) | Restituisce il numero di righe nella colonna del campo. |
| EXACT_COUNT_DISTINCT(campo) | COUNT([DISTINCT] (campo)) | Restituisce il numero di righe univoche nella colonna del campo. |
Per un elenco di tutte le funzioni aggregate, vedere la documentazione di Legacy SQL e Standard SQL.
Diamo un'occhiata ai dati demo per vedere come funzionano queste funzioni. Possiamo calcolare le entrate medie per le transazioni, gli acquisti per gli importi più alti e più bassi, le entrate totali, le transazioni totali e il numero di transazioni uniche (per verificare se gli acquisti sono stati duplicati). Per fare ciò, scriveremo una query in cui specifichiamo il nome del nostro progetto Google BigQuery, il set di dati e la tabella.
#SQL legacy
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]#SQL standard
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`Di conseguenza, otterremo quanto segue:
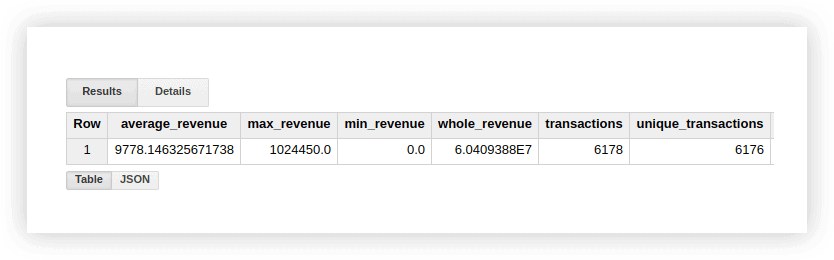
Puoi controllare i risultati di questi calcoli nella tabella originale con i dati demo utilizzando le funzioni standard di Fogli Google (SOMMA, AVG e altre) o utilizzando le tabelle pivot.
Come puoi vedere dallo screenshot sopra, il numero di transazioni e transazioni uniche è diverso. Questo suggerisce che ci sono due transazioni nella nostra tabella con lo stesso transactionId:

Se sei interessato a transazioni uniche, usa una funzione che conta le stringhe univoche. In alternativa, puoi raggruppare i dati utilizzando la funzione GROUP BY per eliminare i duplicati prima di applicare la funzione di aggregazione.
Dati demo per la pratica delle query SQL
ScaricaFunzioni di data
Queste funzioni consentono di elaborare le date: modificarne il formato, selezionare il campo necessario (giorno, mese o anno) oppure spostare la data di un determinato intervallo.
Possono essere utili quando:
- conversione di date e orari da diverse fonti in un unico formato per impostare analisi avanzate
- creazione di report aggiornati automaticamente o attivazione di mailing (ad esempio, quando sono necessari i dati delle ultime due ore, settimane o mesi)
- creando report di coorte in cui è necessario ottenere dati per un periodo di giorni, settimane o mesi
Queste sono le funzioni di data più comunemente utilizzate:
| SQL legacy | SQL standard | Descrizione della funzione |
|---|---|---|
| DATA ODIERNA() | DATA ODIERNA() | Restituisce la data corrente nel formato % AAAA -% MM-% GG. |
| DATA (marcatura oraria) | DATA (marcatura oraria) | Converte la data dal formato % AAAA -% MM-% GG% H:% M:% C. al formato % AAAA -% MM-% GG. |
| DATE_ADD(timestamp, intervallo, intervallo_unità) | DATE_ADD(timestamp, INTERVAL interval interval_units) | Restituisce la data del timestamp, aumentandola dell'intervallo specificato interval.interval_units. In SQL legacy, può assumere i valori ANNO, MESE, GIORNO, ORA, MINUTO e SECONDO, e in SQL standard può richiedere ANNO, TRIMESTRE, MESE, SETTIMANA e GIORNO. |
| DATE_ADD(timestamp, - intervallo, intervallo_unità) | DATE_SUB(timestamp, INTERVAL interval interval_units) | Restituisce la data del timestamp, diminuendola dell'intervallo specificato. |
| DATEDIFF(timestamp1, timestamp2) | DATE_DIFF(timestamp1, timestamp2, data_parte) | Restituisce la differenza tra le date timestamp1 e timestamp2. In Legacy SQL, restituisce la differenza in giorni e in Standard SQL, restituisce la differenza in base al valore date_part specificato (giorno, settimana, mese, trimestre, anno). |
| GIORNO (marcatura oraria) | ESTRATTO (GIORNO DA timestamp) | Restituisce il giorno dalla data del timestamp. Accetta valori da 1 a 31 inclusi. |
| MESE (marcatura temporale) | ESTRATTO (MESE DAL timestamp) | Restituisce il numero di sequenza del mese dalla data del timestamp. Accetta valori da 1 a 12 inclusi. |
| ANNO (marcatura temporale) | ESTRATTO (ANNO DA timestamp) | Restituisce l'anno dalla data del timestamp. |
Per un elenco di tutte le funzioni di data, vedere la documentazione di Legacy SQL e Standard SQL.
Diamo un'occhiata ai nostri dati demo per vedere come funziona ciascuna di queste funzioni. Ad esempio, otterremo la data corrente, trasformeremo la data dalla tabella originale nel formato % AAAA -% MM-% GG, la porteremo via e vi aggiungeremo un giorno. Quindi calcoleremo la differenza tra la data corrente e la data dalla tabella di origine e suddivideremo la data corrente in campi anno, mese e giorno separati. Per fare ciò, puoi copiare le query di esempio seguenti e sostituire il nome del progetto, il set di dati e la tabella di dati con le tue.
#SQL legacy
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]#SQL standard
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)Dopo aver eseguito la query, riceverai questo rapporto:
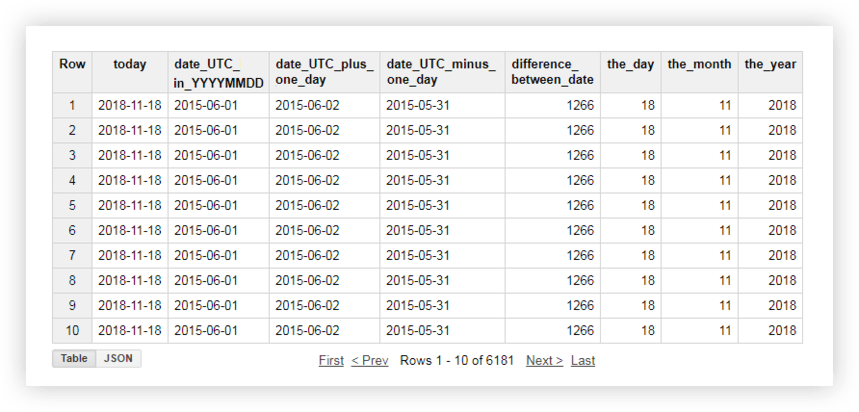
Vedi anche: Esempi di rapporti che possono essere creati utilizzando query SQL sui dati in Google BigQuery e quali metriche uniche puoi integrare i dati di Google Analytics con OWOX BI.
Funzioni di stringa
Le funzioni di stringa consentono di generare una stringa, selezionare e sostituire sottostringhe e calcolare la lunghezza di una stringa e la sequenza di indice della sottostringa nella stringa originale. Ad esempio, con le funzioni di stringa, puoi:
- filtrare un report con tag UTM che vengono passati all'URL della pagina
- portare i dati in un unico formato se i nomi di origine e campagna sono scritti in registri diversi
- sostituire i dati errati in un rapporto (ad esempio, se il nome della campagna è stampato in modo errato)
Queste sono le funzioni più popolari per lavorare con le stringhe:
| SQL legacy | SQL standard | Descrizione della funzione |
|---|---|---|
| CONCAT('str1', 'str2') o 'str1'+ 'str2' | CONCAT('str1', 'str2') | Concatena 'str1' e 'str2' in una stringa. |
| 'str1' CONTIENE 'str2' | REGEXP_CONTAINS('str1', 'str2') o 'str1' COME '%str2%' | Restituisce true se la stringa 'str1' contiene la stringa 'str2.'In Standard SQL, la stringa 'str2' può essere scritta come un'espressione regolare utilizzando la libreria re2 . |
| LUNGHEZZA('str' ) | CHAR_LENGTH('str' ) o CHARACTER_LENGTH('str' ) | Restituisce la lunghezza della stringa 'str' (numero di caratteri). |
| SUBSTR('str', indice [, max_len]) | SUBSTR('str', indice [, max_len]) | Restituisce una sottostringa di lunghezza max_len che inizia con un carattere di indice dalla stringa 'str'. |
| LOWER('str') | LOWER('str') | Converte tutti i caratteri nella stringa 'str in minuscolo. |
| SUPERIORE(str) | SUPERIORE(str) | Converte tutti i caratteri nella stringa 'str' in maiuscolo. |
| INSTR('str1', 'str2') | STRPOS('str1', 'str2') | Restituisce l'indice della prima occorrenza della stringa 'str2' nella stringa 'str1'; in caso contrario, restituisce 0. |
| REPLACE('str1', 'str2', 'str3') | REPLACE('str1', 'str2', 'str3') | Sostituisce 'str1' con 'str2' con 'str3'. |
Puoi saperne di più su tutte le funzioni di stringa nella documentazione di Legacy SQL e Standard SQL.
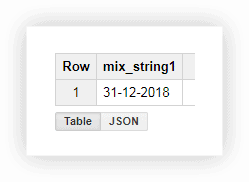
Diamo un'occhiata ai dati demo per vedere come utilizzare le funzioni descritte. Supponiamo di avere tre colonne separate che contengono i valori di giorno, mese e anno:

Lavorare con una data in questo formato non è molto conveniente, quindi possiamo combinare i valori in una colonna. Per fare ciò, utilizza le query SQL seguenti e ricorda di sostituire il nome del tuo progetto, set di dati e tabella in Google BigQuery.
#SQL legacy
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1#SQL standard
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1Dopo aver eseguito la query, riceviamo la data in una colonna:
Spesso, quando scarichi una pagina su un sito web, l'URL registra i valori delle variabili che l'utente ha scelto. Può essere un metodo di pagamento o consegna, numero di transazione, indice del negozio fisico in cui l'acquirente desidera ritirare l'articolo, ecc. Utilizzando una query SQL, puoi selezionare questi parametri dall'indirizzo della pagina. Considera due esempi di come e perché potresti farlo.
Esempio 1 . Supponiamo di voler conoscere il numero di acquisti in cui gli utenti ritirano le merci dai negozi fisici. Per fare ciò, dobbiamo calcolare il numero di transazioni inviate dalle pagine nell'URL che contengono una sottostringa shop_id (un indice per un negozio fisico). Possiamo farlo con le seguenti domande:
#SQL legacy
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check#SQL standard

SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2
SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2Dalla tabella risultante, vediamo che 5502 transazioni (check = true) sono state inviate da pagine contenenti shop_id:

Esempio 2 . Hai assegnato un delivery_id a ciascun metodo di consegna e specifichi il valore di questo parametro nell'URL della pagina. Per scoprire quale metodo di consegna ha scelto l'utente, devi selezionare delivery_id in una colonna separata.
Possiamo usare le seguenti query per questo:
#SQL legacy
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC#SQL standard
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASCDi conseguenza, otteniamo una tabella come questa in Google BigQuery:
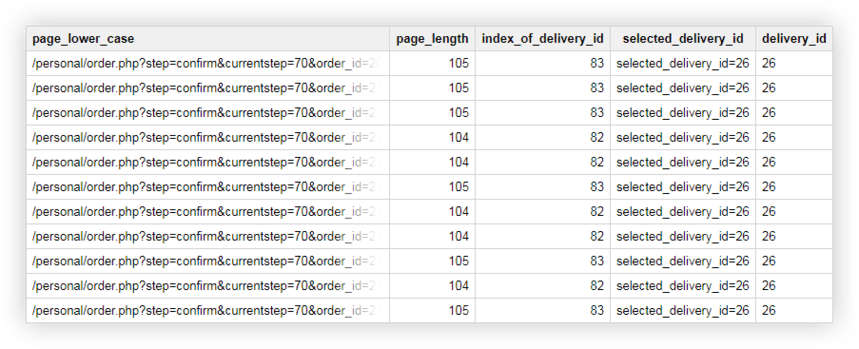
Dati demo per la pratica delle query SQL
ScaricaFunzioni della finestra
Queste funzioni sono simili alle funzioni aggregate discusse sopra. La differenza principale è che le funzioni della finestra non eseguono calcoli sull'intero insieme di dati selezionato utilizzando la query, ma solo su una parte di quei dati, un sottoinsieme o una finestra .
Utilizzando le funzioni della finestra, è possibile aggregare i dati in una sezione di gruppo senza utilizzare la funzione UNISCI per combinare più query. Ad esempio, puoi calcolare le entrate medie per campagna pubblicitaria o il numero di transazioni per dispositivo. Aggiungendo un altro campo al rapporto, puoi facilmente scoprire, ad esempio, la quota di entrate di una campagna pubblicitaria del Black Friday o la quota di transazioni effettuate da un'applicazione mobile.
Insieme a ciascuna funzione nella query, è necessario compitare l'espressione OVER che definisce i limiti della finestra. OVER contiene tre componenti con cui puoi lavorare:
- PARTITION BY: definisce la caratteristica in base alla quale si dividono i dati originali in sottoinsiemi, come clientId o DayTime
- ORDER BY — Definisce l'ordine delle righe in un sottoinsieme, come l'ora DESC
- CORNICE FINESTRA — Consente di elaborare le righe all'interno di un sottoinsieme di una caratteristica specifica (ad esempio, solo le cinque righe prima della riga corrente)
In questa tabella abbiamo raccolto le funzioni della finestra più utilizzate:
| SQL legacy | SQL standard | Descrizione della funzione |
|---|---|---|
| MEDIA (campo) COUNT(campo) COUNT(campo DISTINCT) MASSIMO() MIN() SOMMA() | MEDIA([DISTINTA] (campo)) COUNT(campo) COUNT([DISTINCT] (campo)) MAX(campo) MIN(campo) SOMMA(campo) | Restituisce il valore medio, numerico, massimo, minimo e totale dalla colonna del campo all'interno del sottoinsieme selezionato. DISTINCT viene utilizzato per calcolare solo valori univoci (non ripetuti). |
| DENSE_RANK() | DENSE_RANK() | Restituisce il numero di riga all'interno di un sottoinsieme. |
| FIRST_VALUE(campo) | FIRST_VALUE (campo[{RISPECT | IGNORE} NULLS]) | Restituisce il valore della prima riga dalla colonna del campo all'interno di un sottoinsieme. Per impostazione predefinita, nel calcolo vengono incluse le righe con valori vuoti della colonna del campo. RESPECT o IGNORE NULLS specifica se includere o ignorare le stringhe NULL. |
| LAST_VALUE(campo) | LAST_VALUE (campo [{RESPECT | IGNORE} NULLS]) | Restituisce il valore dell'ultima riga all'interno di un sottoinsieme dalla colonna del campo. Per impostazione predefinita, le righe con valori vuoti nella colonna del campo vengono incluse nel calcolo. RESPECT o IGNORE NULLS specifica se includere o ignorare le stringhe NULL. |
| GAL(campo) | LAG (campo[, offset [, espressione_predefinita]]) | Restituisce il valore della riga precedente rispetto alla colonna del campo corrente all'interno del sottoinsieme.Offset è un numero intero che specifica il numero di righe di cui eseguire l'offset rispetto alla riga corrente.Default_expression è il valore che la funzione restituirà se non è richiesto stringa all'interno del sottoinsieme. |
| LEAD(campo) | LEAD (campo[, offset [, espressione_predefinita]]) | Restituisce il valore della riga successiva rispetto alla colonna del campo corrente all'interno del sottoinsieme. Offset è un numero intero che definisce il numero di righe che si desidera spostare in alto rispetto alla riga corrente. Default_expression è il valore che la funzione restituirà se non è presente alcuna stringa richiesta all'interno del sottoinsieme corrente. |
È possibile visualizzare un elenco di tutte le funzioni analitiche aggregate e le funzioni di navigazione nella documentazione per Legacy SQL e Standard SQL.
Esempio 1 . Diciamo di voler analizzare l'attività dei clienti durante l'orario lavorativo e non. Per fare ciò, dobbiamo dividere le transazioni in due gruppi e calcolare le metriche di interesse:
- Gruppo 1 — Acquisti durante l'orario di lavoro dalle 9:00 alle 18:00
- Gruppo 2 — Acquisti fuori orario dalle 00:00 alle 9:00 e dalle 18:00 alle 23:59
Oltre alle ore lavorative e non lavorative, un'altra variabile per formare una finestra è clientId. Cioè, per ogni utente, avremo due finestre:
| finestra | Identificativo cliente | Giorno |
|---|---|---|
| finestra 1 | ID cliente 1 | ore lavorative |
| finestra 2 | ID cliente 2 | orario non lavorativo |
| finestra 3 | ID cliente 3 | ore lavorative |
| finestra 4 | ID cliente 4 | orario non lavorativo |
| finestra n | ID cliente N | ore lavorative |
| finestra N+1 | ID cliente N+1 | orario non lavorativo |
Usiamo i dati demo per calcolare le entrate medie, massime, minime e totali, il numero totale di transazioni e il numero di transazioni uniche per utente durante l'orario lavorativo e non lavorativo. Le richieste seguenti ci aiuteranno a farlo.
#SQL legacy
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC#SQL standard
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESCVediamo cosa succede di conseguenza usando l'esempio dell'utente con clientId 102041117.1428132012. Nella tabella originale per questo utente, abbiamo i seguenti dati:

Eseguendo la query, riceviamo un rapporto che contiene le entrate medie, minime, massime e totali di questo utente, nonché il numero totale di transazioni dell'utente. Come puoi vedere nello screenshot qui sotto, entrambe le transazioni sono state effettuate dall'utente durante l'orario di lavoro:

Esempio 2 . Ora per un compito più complicato:
- Inserisci i numeri di sequenza per tutte le transazioni nella finestra a seconda del momento della loro esecuzione. Ricordiamo che definiamo la finestra per utente e fasce orarie lavorative/non lavorative.
- Segnalare i ricavi della transazione successiva/precedente (relativa a quella corrente) all'interno della finestra.
- Visualizza i ricavi della prima e dell'ultima transazione nella finestra.
Per fare ciò, utilizzeremo le seguenti query:
#SQL legacy
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour#SQL standard
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hourPossiamo verificare i risultati dei calcoli utilizzando l'esempio di un utente che già conosciamo: clientId 102041117.1428132012:

Dallo screenshot sopra, possiamo vedere che:
- la prima transazione è stata alle 15:00 e la seconda alle 16:00
- dopo la transazione alle 15:00, c'è stata una transazione alle 16:00 con un ricavo di 25066 (colonna lead_revenue)
- prima della transazione alle 16:00, c'era una transazione alle 15:00 con un ricavo di 3699 (colonna lag_revenue)
- la prima transazione all'interno della finestra è stata alle 15:00 e le entrate per questa transazione sono state 3699 (colonna first_revenue_by_hour)
- la query elabora i dati riga per riga, quindi per la transazione in questione, l'ultima transazione nella finestra sarà essa stessa e i valori nelle colonne last_revenue_by_hour e revenue saranno gli stessi
Articoli utili su Google BigQuery:
- I 6 migliori strumenti di visualizzazione BigQuery
- Come caricare i dati su Google BigQuery
- Come caricare dati grezzi da Google Ads su Google BigQuery
- Connettore per fogli Google BigQuery di Google
- Automatizza i rapporti in Fogli Google utilizzando i dati di Google BigQuery
- Automatizza i rapporti in Google Data Studio in base ai dati di Google BigQuery
Se desideri raccogliere dati non campionati dal tuo sito web in Google BigQuery ma non sai da dove iniziare, prenota una demo. Ti parleremo di tutte le possibilità che hai con BigQuery e OWOX BI.
I nostri clienti
crescere 22% più veloce
Cresci più velocemente misurando ciò che funziona meglio nel tuo marketing
Analizza la tua efficienza di marketing, trova le aree di crescita, aumenta il ROI
Ottieni una demoConclusioni
In questo articolo, abbiamo esaminato i gruppi di funzioni più popolari: aggregato, data, stringa e finestra. Tuttavia, Google BigQuery ha molte altre funzioni utili, tra cui:
- funzioni di casting che consentono di convertire i dati in un formato specifico
- funzioni jolly della tabella che consentono di accedere a più tabelle in un set di dati
- funzioni di espressione regolare che consentono di descrivere il modello di una query di ricerca e non il suo valore esatto
Scriveremo sicuramente di queste funzioni sul nostro blog. Nel frattempo, puoi provare tutte le funzioni descritte in questo articolo utilizzando i nostri dati demo.
Dati demo per la pratica delle query SQL
Scarica