
Как создать файл robots.txt (и зачем это нужно)
Опубликовано: 2022-06-07Объяснение SEO людям может быть трудным, потому что есть много маленьких шагов, которые могут показаться не очень важными на первый взгляд, но при правильном выполнении они приводят к большим выигрышам в поисковом рейтинге.
Один важный шаг, который легко упустить из виду, — это сообщить роботам поисковых систем, какие страницы индексировать, а какие нет. Это можно сделать с помощью файла robots.txt.
В сегодняшней статье я собираюсь объяснить, как именно создать файл robots.txt, чтобы вы могли привести в порядок эту фундаментальную часть своего сайта и убедиться, что поисковые роботы взаимодействуют с вашим сайтом так, как вы хотите.
Что такое файл robots.txt?
Файл robots.txt представляет собой простую директиву, сообщающую поисковым роботам, какие страницы вашего сайта следует сканировать и индексировать.
Это часть протокола исключения роботов (REP), семейства стандартных процедур, которые определяют, как роботы поисковых систем сканируют Интернет, оценивают и индексируют контент сайта, а затем предоставляют этот контент пользователям. В этом файле указывается, где сканерам разрешено сканировать, а где нет. Он также может содержать информацию, которая может помочь поисковым роботам более эффективно сканировать веб-сайт.
REP также включает «мета-теги роботов», которые представляют собой директивы, включенные в HTML-код страницы и содержащие конкретные инструкции о том, как поисковые роботы должны сканировать и индексировать определенные веб-страницы и изображения или файлы, которые они содержат.
В чем разница между Robots.txt и тегом Meta Robots?
Как я уже упоминал, протокол исключения роботов также включает «мета-теги роботов», которые представляют собой фрагменты кода, включенные в HTML-код страницы. Они отличаются от файлов robots.txt тем, что указывают поисковым роботам направление на определенные веб-страницы , запрещая доступ либо ко всей странице, либо к определенным файлам, содержащимся на странице, таким как фотографии и видео.
Напротив, файлы robots.txt предназначены для предотвращения индексации целых сегментов веб-сайта, например подкаталогов, предназначенных только для внутреннего использования. Файл robots.txt находится в корневом домене вашего сайта, а не на конкретной странице, а директивы структурированы таким образом, что они влияют на все страницы, содержащиеся в каталогах или подкаталогах, на которые они ссылаются.
Зачем мне нужен файл robots.txt?
Файл robots.txt — это обманчиво простой текстовый файл, который имеет большое значение. Без него поисковые роботы будут просто индексировать каждую найденную страницу.
Почему это важно?
Во-первых, сканирование всего сайта требует времени и ресурсов. Все это стоит денег, поэтому Google ограничивает объем сканирования сайта, особенно если этот сайт очень большой. Это известно как «краулинговый бюджет». Бюджет сканирования ограничен несколькими техническими факторами, включая время отклика, малоценные URL-адреса и количество обнаруженных ошибок.
Кроме того, если вы разрешите поисковым системам беспрепятственный доступ ко всем вашим страницам и позволите их поисковым роботам индексировать их, вы можете столкнуться с раздуванием индекса. Это означает, что Google может ранжировать неважные страницы, которые вы не хотите показывать в результатах поиска. Эти результаты могут вызвать у посетителей плохой опыт, и они могут даже конкурировать со страницами, для которых вы хотите ранжироваться.
Когда вы добавляете файл robots.txt на свой сайт или обновляете существующий файл, вы можете уменьшить траты краулингового бюджета и ограничить раздувание индекса.
Рекомендуемое чтение
- Руководство по техническому SEO: что такое техническое SEO?
- Что такое раздувание индекса? (И как это исправить)
Где я могу найти файл robots.txt?
Есть простой способ узнать, есть ли на вашем сайте файл robots.txt: найдите его в Интернете.
Просто введите URL-адрес любого сайта и добавьте в конец «/robots.txt». Например: victoriousseo.com/robots.txt показывает вам нашу.
Попробуйте сами, введя URL своего сайта и добавив «/robots.txt» в конец. Вы должны увидеть одну из трех вещей:
- Пара строк текста, указывающих на действительный файл robots.txt.
- Совершенно пустая страница, указывающая на отсутствие файла robots.txt.
- Ошибка 404
Если вы проверяете свой сайт и получаете один из двух вторых результатов, вам нужно создать файл robots.txt, чтобы помочь поисковым системам лучше понять, на чем им следует сосредоточить свои усилия.
Как создать файл robots.txt
Файл robots.txt включает в себя определенные команды, которые роботы поисковых систем могут читать и выполнять. Вот некоторые из терминов, которые вы будете использовать при создании файла robots.txt.
Общие термины robots.txt, которые следует знать
Пользовательский агент : Пользовательский агент — это любое программное обеспечение, которому поручено извлекать и представлять веб-контент конечным пользователям. В то время как веб-браузеры, медиаплееры и подключаемые модули могут считаться примерами пользовательских агентов, в контексте файлов robot.txt пользовательский агент — это поисковый робот или паук (например, Googlebot), который сканирует и индексирует Ваш сайт.
Разрешить: если эта команда содержится в файле robots.txt, она разрешает агентам пользователя сканировать любые страницы, следующие за ней. Например, если команда гласит «Разрешить: /», это означает, что любой поисковый робот может получить доступ к любой странице, которая следует за косой чертой в «http://www.example.com/». Вам не нужно добавлять это для всего, что вы хотите сканировать, так как все, что не запрещено в robots.txt, неявно разрешено. Вместо этого используйте его, чтобы разрешить доступ к подкаталогу, находящемуся на запрещенном пути. Например, на сайтах WordPress часто есть директива disallow для папки /wp-admin/, которая, в свою очередь, требует от них добавления директивы allow, позволяющей сканерам получать доступ к /wp-admin/admin-ajax.php, не обращаясь ни к чему другому в папке. основная папка.
Disallow: эта команда запрещает определенным пользовательским агентам сканировать страницы, следующие за указанной папкой. Например, если команда гласит «Запретить: /blog/», это означает, что пользовательский агент не может сканировать любые URL-адреса, содержащие подкаталог /blog/, что исключит весь блог из поиска. Вы, вероятно, никогда не хотели бы этого делать, но вы могли бы. Вот почему очень важно учитывать последствия использования директивы disallow каждый раз, когда вы думаете о внесении изменений в файл robots.txt.
Crawl-delay: Хотя эта команда считается неофициальной, она предназначена для того, чтобы поисковые роботы не перегружали серверы запросами. Обычно это реализуется на веб-сайтах, где слишком много запросов могут вызвать проблемы с сервером. Некоторые поисковые системы поддерживают его, но Google — нет. Вы можете настроить скорость сканирования для Google, открыв Google Search Console, перейдя на страницу настроек скорости сканирования вашего ресурса и отрегулировав там ползунок. Это работает только в том случае, если Google считает, что это не оптимально. Если вы считаете, что это неоптимально, и Google с этим не согласен, вам может потребоваться отправить специальный запрос на его корректировку. Это потому, что Google предпочитает, чтобы вы позволяли им оптимизировать скорость сканирования вашего веб-сайта.

XML Sitemap: эта директива делает именно то, что вы и предполагали: сообщает поисковым роботам, где находится ваша XML-карта сайта. Он должен выглядеть примерно так: «Карта сайта: http://www.example.com/sitemap.xml». Вы можете узнать больше о лучших методах работы с картами сайта здесь.
Пошаговые инструкции по созданию robots.txt
Чтобы создать собственный файл robots.txt, вам потребуется доступ к простому текстовому редактору, такому как Блокнот или TextEdit. Важно не использовать текстовый процессор, так как он обычно сохраняет файлы в проприетарных формах и может добавлять в файл специальные символы.
Для простоты мы будем использовать «www.example.com».
Мы начнем с установки параметров пользовательского агента. В первой строке введите:
Пользовательский агент: *
Звездочка означает, что всем поисковым роботам разрешено посещать ваш сайт.
Некоторые веб-сайты будут использовать разрешающую директиву, чтобы сказать, что ботам разрешено сканировать, но в этом нет необходимости. Любые части сайта, которые вы не запретили, неявно разрешены.
Далее мы введем параметр запрета. Дважды нажмите «возврат», чтобы вставить разрыв после строки пользовательского агента, затем введите:
Запретить: /
Поскольку после него мы не вводим никаких команд, это означает, что поисковые роботы могут посещать каждую страницу вашего сайта.
Если вы хотите заблокировать доступ к определенному контенту, вы можете добавить каталог после команды disallow. В нашем файле robots.txt есть две следующие команды запрета:
Запретить: /wp/wp-admin/
Запретить: /*?*
Первый гарантирует, что наши страницы администратора WordPress (где мы редактируем такие вещи, как эта статья) не будут сканироваться. Это страницы, которые мы не хотели бы ранжировать в поиске, и Google также будет пустой тратой времени, пытаясь их просканировать, потому что они защищены паролем. Второй предотвращает сканирование URL-адресов, содержащих вопросительный знак, таких как страницы результатов поиска по блогам.
После того, как вы выполнили свои команды, создайте ссылку на карту сайта. Хотя этот шаг не является обязательным с технической точки зрения, он является рекомендуемой практикой, поскольку он указывает веб-паукам на наиболее важные страницы вашего сайта и делает архитектуру вашего сайта понятной. После вставки другого разрыва строки введите:
Карта сайта: http://www.example.com/sitemap.xml
Теперь ваш веб-разработчик может загрузить ваш файл на ваш сайт.
Создание файла Robots.txt в WordPress
Если у вас есть доступ администратора к вашему WordPress, вы можете изменить файл robots.txt с помощью плагина Yoast SEO или AIOSEO. Кроме того, ваш веб-разработчик может использовать клиент FTP или SFTP для подключения к вашему сайту WordPress и доступа к корневому каталогу.
Не перемещайте файл robots.txt куда-либо, кроме корневого каталога. Хотя некоторые источники предлагают разместить его в подкаталоге или поддомене, в идеале он должен находиться в корневом домене: www.example.com/robots.txt.
Как проверить файл robots.txt
Теперь, когда вы создали файл robots.txt, пришло время протестировать его. К счастью, Google упрощает это, предоставляя тестер robots.txt как часть Google Search Console.
После того, как вы откроете тестер для своего сайта, вы увидите все синтаксические предупреждения и выделенные логические ошибки.
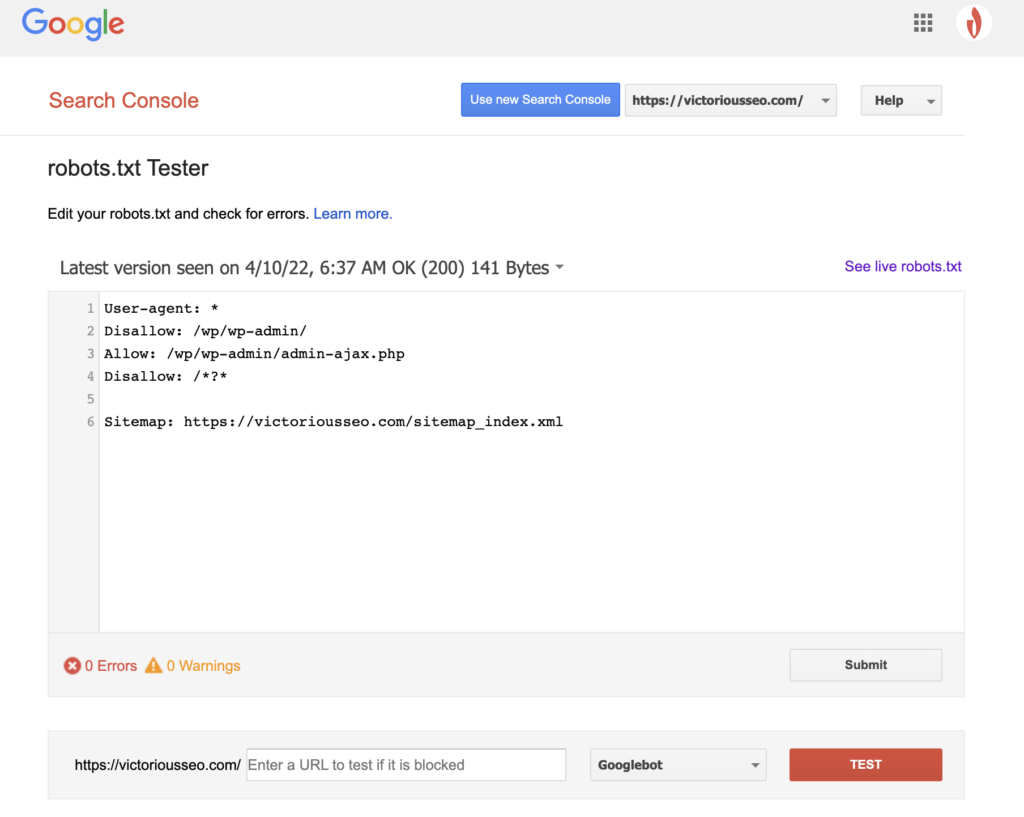
Чтобы проверить, как конкретный робот Google «видит» вашу страницу, введите URL-адрес вашего сайта в текстовое поле внизу страницы, а затем выберите один из различных роботов Google в раскрывающемся списке справа. Нажатие «TEST» смоделирует поведение выбранного вами бота и покажет, не запрещают ли роботу Googlebot доступ к странице какие-либо директивы.

Недостатки robots.txt
Файлы robots.txt очень полезны, но у них есть свои ограничения.
Файлы robots.txt не должны использоваться для защиты или сокрытия частей вашего веб-сайта (это может привести к нарушению Закона о защите данных). Помните, я предлагал вам найти собственный файл robots.txt? Это означает, что любой может получить к нему доступ, а не только вы. Если есть информация, которую необходимо защитить, лучше всего защитить паролем определенные страницы или документы.
Кроме того, директивы вашего файла robots.txt — это просто запросы. Вы можете ожидать, что Googlebot и другие законные поисковые роботы будут подчиняться вашим указаниям, но другие боты могут просто их игнорировать.
Наконец, даже если вы попросите сканеры не индексировать определенные URL-адреса, они не станут невидимыми. Другие веб-сайты могут ссылаться на них. Если вы не хотите, чтобы определенная информация на вашем веб-сайте была доступна для всеобщего обозрения, вам следует защитить ее паролем. Если вы хотите убедиться, что он не будет проиндексирован, рассмотрите возможность добавления на страницу тега noindex.
Узнайте больше о техническом SEO: загрузите наш контрольный список
Хотите узнать больше о SEO, включая пошаговые инструкции о том, как взять SEO вашего сайта в свои руки? Загрузите наш Контрольный список SEO на 2022 год, чтобы получить исчерпывающий список дел, включая ценные ресурсы, которые помогут вам повысить рейтинг в поисковых системах и привлечь больше органического трафика на ваш сайт.

Контрольный список SEO и инструменты планирования
Готовы ли вы двинуть иглу на вашем SEO? Получите интерактивный контрольный список и инструменты планирования и приступайте к работе!