
Jak utworzyć plik Robots.txt (i dlaczego trzeba)
Opublikowany: 2022-06-07Wyjaśnienie ludziom SEO może być trudne, ponieważ istnieje wiele małych kroków, które na początku mogą wydawać się mało ważne, ale gdy zostaną wykonane prawidłowo, przyczyniają się do dużych wzrostów w rankingu wyszukiwania.
Jednym z ważnych kroków, które można łatwo przeoczyć, jest poinformowanie robotów wyszukiwarek, które strony mają indeksować, a które nie. Możesz to zrobić za pomocą pliku robots.txt.
W dzisiejszym poście wyjaśnię dokładnie, jak utworzyć plik robots.txt, aby uporządkować tę podstawową część witryny i upewnić się, że roboty indeksujące wchodzą w interakcję z witryną w sposób, w jaki chcesz.
Co to jest plik robots.txt?
Plik robots.txt to prosta dyrektywa, która informuje roboty wyszukiwarek, które strony w Twojej witrynie mają przeszukiwać i indeksować.
Jest to część protokołu wykluczania robotów (REP), rodziny standardowych procedur, które regulują sposób, w jaki roboty wyszukiwarek przemierzają sieć, oceniają i indeksują zawartość witryny, a następnie udostępniają tę zawartość użytkownikom. Ten plik określa, gdzie roboty indeksujące mogą indeksować, a gdzie nie. Może również zawierać informacje, które mogą pomóc robotom indeksującym w bardziej efektywnym indeksowaniu witryny.
REP zawiera również „meta tagi robotów”, które są dyrektywami zawartymi w kodzie HTML strony, które zawierają szczegółowe instrukcje dotyczące sposobu, w jaki roboty indeksujące powinny przeszukiwać i indeksować określone strony internetowe oraz zawarte w nich obrazy lub pliki.
Jaka jest różnica między plikiem Robots.txt a tagiem Meta Robots?
Jak wspomniałem, protokół wykluczania robotów obejmuje również „meta tagi robotów”, które są fragmentami kodu zawartymi w kodzie HTML strony. Różnią się one od plików robots.txt tym, że dostarczają wskazówek robotom indeksującym na określonych stronach internetowych , uniemożliwiając dostęp do całej strony lub do określonych plików na niej zawartych, takich jak zdjęcia i filmy.
Natomiast pliki robots.txt mają zapobiegać indeksowaniu całych segmentów witryny, na przykład podkatalogu przeznaczonego wyłącznie do użytku wewnętrznego. Plik robots.txt znajduje się w domenie głównej witryny, a nie na określonej stronie, a dyrektywy mają taką strukturę, że wpływają na wszystkie strony zawarte w katalogach lub podkatalogach, do których się odnoszą.
Dlaczego potrzebuję pliku Robots.txt?
Plik robots.txt to zwodniczo prosty plik tekstowy o wielkim znaczeniu. Bez tego roboty sieciowe po prostu zindeksują każdą znalezioną stronę.
Dlaczego to ma znaczenie?
Po pierwsze, indeksowanie całej witryny wymaga czasu i zasobów. Wszystko to kosztuje, więc Google ogranicza zakres indeksowania witryny, zwłaszcza jeśli ta witryna jest bardzo duża. Jest to znane jako „budżet indeksowania”. Budżet indeksowania jest ograniczony przez kilka czynników technicznych, w tym czas odpowiedzi, adresy URL o niskiej wartości i liczbę napotkanych błędów.
Dodatkowo, jeśli zezwolisz wyszukiwarkom na nieograniczony dostęp do wszystkich swoich stron i indeksowaniu ich robotom indeksującym, możesz skończyć z rozdęciem indeksu. Oznacza to, że Google może pozycjonować nieistotne strony, których nie chcesz wyświetlać w wynikach wyszukiwania. Te wyniki mogą zapewnić odwiedzającym złe wrażenia, a nawet mogą konkurować ze stronami, dla których chcesz się pozycjonować.
Po dodaniu pliku robots.txt do witryny lub zaktualizowaniu istniejącego pliku można zmniejszyć marnotrawstwo budżetu na indeksowanie i ograniczyć rozrost indeksu.
rekomendowane lektury
- Przewodnik techniczny SEO: Co to jest Tech SEO?
- Co to jest wzdęcie indeksu? (I jak to naprawić)
Gdzie mogę znaleźć mój plik Robots.txt?
Istnieje prosty sposób sprawdzenia, czy Twoja witryna zawiera plik robots.txt: poszukaj go w Internecie.
Wystarczy wpisać adres URL dowolnej witryny i dodać na końcu „/robots.txt”. Na przykład: victoriousseo.com/robots.txt pokazuje nasz.
Spróbuj sam, wpisując adres URL swojej witryny i dodając na końcu „/robots.txt”. Powinieneś zobaczyć jedną z trzech rzeczy:
- Kilka wierszy tekstu wskazujących na prawidłowy plik robots.txt
- Całkowicie pusta strona oznaczająca brak rzeczywistego pliku robots.txt
- Błąd 404
Jeśli sprawdzasz swoją witrynę i otrzymujesz jeden z dwóch drugich wyników, warto utworzyć plik robots.txt, aby pomóc wyszukiwarkom lepiej zrozumieć, na czym powinny skoncentrować swoje wysiłki.
Jak utworzyć plik Robots.txt
Plik robots.txt zawiera określone polecenia, które roboty wyszukiwarek mogą odczytać i wykonać. Oto niektóre terminy, których będziesz używać podczas tworzenia pliku robots.txt.
Popularne warunki dotyczące pliku Robots.txt, które należy znać
User-Agent : User-Agent to dowolne oprogramowanie, którego zadaniem jest pobieranie i prezentowanie treści internetowych użytkownikom końcowym. Chociaż przeglądarki internetowe, odtwarzacze multimedialne i wtyczki można uznać za przykłady klientów użytkownika, w kontekście plików robot.txt klient użytkownika to robot indeksujący wyszukiwarki (taki jak Googlebot), który przeszukuje i indeksuje Twoja strona internetowa.
Zezwól: jeśli jest zawarte w pliku robots.txt, to polecenie umożliwia agentom użytkownika indeksowanie wszystkich stron, które po nim następują. Na przykład, jeśli polecenie brzmi „Allow: /”, oznacza to, że każdy robot internetowy może uzyskać dostęp do dowolnej strony, która znajduje się po ukośniku w „http://www.example.com/”. Nie musisz dodawać tego dla wszystkiego, co chcesz zindeksować, ponieważ wszystko, co nie jest zabronione w pliku robots.txt, jest domyślnie dozwolone. Zamiast tego użyj go, aby zezwolić na dostęp do podkatalogu, który znajduje się w niedozwolonej ścieżce. Na przykład witryny WordPress często mają dyrektywę disallow dla folderu /wp-admin/, która z kolei wymaga dodania dyrektywy allow, aby umożliwić robotom indeksującym dostęp do /wp-admin/admin-ajax.php bez dotarcia do czegokolwiek innego w główny folder.
Disallow: To polecenie uniemożliwia określonym klientom użytkownika indeksowanie stron znajdujących się w określonym folderze. Na przykład, jeśli polecenie brzmi „Disallow: /blog/”, oznacza to, że klient użytkownika nie może indeksować żadnych adresów URL zawierających podkatalog /blog/, co wykluczyłoby całego bloga z wyszukiwania. Prawdopodobnie nigdy nie chciałbyś tego zrobić, ale możesz. Dlatego bardzo ważne jest, aby za każdym razem, gdy myślisz o wprowadzeniu zmian w pliku robots.txt, rozważyć konsekwencje użycia dyrektywy disallow.
Opóźnienie indeksowania: chociaż to polecenie jest uważane za nieoficjalne, ma na celu powstrzymanie robotów indeksujących przed potencjalnie przytłaczającymi serwerami żądaniami. Jest zwykle wdrażany na stronach internetowych, w których zbyt wiele żądań może powodować problemy z serwerem. Niektóre wyszukiwarki obsługują to, ale Google nie. Możesz dostosować szybkość indeksowania dla Google, otwierając Google Search Console, przechodząc do strony Ustawienia szybkości indeksowania swojej usługi i dostosowując tam suwak. Działa to tylko wtedy, gdy Google uważa, że nie jest optymalny. Jeśli uważasz, że jest nieoptymalne, a Google się z tym nie zgadza, może być konieczne złożenie specjalnej prośby o dostosowanie. Dzieje się tak, ponieważ Google woli, abyś pozwolił im zoptymalizować szybkość indeksowania Twojej witryny.

Mapa witryny XML: ta dyrektywa robi dokładnie to, co można przypuszczać: informuje roboty indeksujące, gdzie znajduje się mapa witryny XML. Powinien wyglądać mniej więcej tak: „Mapa witryny: http://www.example.com/sitemap.xml”. Więcej informacji o sprawdzonych metodach tworzenia map witryn znajdziesz tutaj.
Instrukcje krok po kroku dotyczące tworzenia pliku Robots.txt
Aby utworzyć własny plik robots.txt, potrzebujesz dostępu do prostego edytora tekstu, takiego jak Notatnik lub TextEdit. Ważne jest, aby nie używać edytora tekstu, ponieważ zazwyczaj zapisuje on pliki w zastrzeżonych formach i może dodawać do pliku znaki specjalne.
Dla uproszczenia użyjemy „www.example.com”.
Zaczniemy od ustawienia parametrów klienta użytkownika. W pierwszym wierszu wpisz:
Agent użytkownika: *
Gwiazdka oznacza, że wszystkie roboty sieciowe mogą odwiedzać Twoją witrynę.
Niektóre witryny używają dyrektywy zezwalającej, aby powiedzieć, że boty mogą się indeksować, ale nie jest to konieczne. Wszelkie części witryny, których nie zabroniłeś, są domyślnie dozwolone.
Następnie wprowadzimy parametr disallow. Naciśnij dwukrotnie „return”, aby wstawić przerwę po wierszu klienta użytkownika, a następnie wpisz:
Uniemożliwić: /
Ponieważ nie wpisujemy po nim żadnych poleceń, oznacza to, że roboty indeksujące mogą odwiedzać każdą stronę w Twojej witrynie.
Jeśli chcesz zablokować dostęp do określonej zawartości, możesz dodać katalog po poleceniu disallow. Nasz plik robots.txt zawiera następujące dwa polecenia zakazu:
Nie zezwalaj: /wp/wp-admin/
Uniemożliwić: /*?*
Pierwszy zapewnia, że nasze strony administracyjne WordPressa (gdzie edytujemy rzeczy takie jak ten artykuł) nie zostaną zindeksowane. Są to strony, których nie chcemy umieszczać w rankingu w wynikach wyszukiwania, a próba ich indeksowania byłaby również stratą czasu Google, ponieważ są one chronione hasłem. Drugi zapobiega indeksowaniu adresów URL zawierających znak zapytania, takich jak strony wyników wyszukiwania blogów.
Po wykonaniu poleceń połącz się z mapą witryny. Chociaż ten krok nie jest technicznie wymagany, jest to zalecana sprawdzona metoda, ponieważ kieruje ona roboty-pająki internetowe do najważniejszych stron w Twojej witrynie i zapewnia przejrzystą architekturę witryny. Po wstawieniu kolejnego łamania wiersza wpisz:
Mapa witryny: http://www.example.com/sitemap.xml
Teraz Twój programista może przesłać Twój plik do Twojej witryny.
Tworzenie pliku Robots.txt w WordPress
Jeśli masz dostęp administracyjny do swojego WordPressa, możesz zmodyfikować plik robots.txt za pomocą wtyczki Yoast SEO lub AIOSEO. Alternatywnie, Twój programista może użyć klienta FTP lub SFTP, aby połączyć się z Twoją witryną WordPress i uzyskać dostęp do katalogu głównego.
Nie przenoś pliku robots.txt w inne miejsce niż katalog główny. Chociaż niektóre źródła sugerują umieszczenie go w podkatalogu lub subdomenie, najlepiej, aby znajdował się on w Twojej domenie głównej: www.example.com/robots.txt.
Jak przetestować plik Robots.txt
Po utworzeniu pliku robots.txt nadszedł czas, aby go przetestować. Na szczęście Google ułatwia to, udostępniając Tester pliku robots.txt w ramach Google Search Console.
Po otwarciu testera dla swojej witryny zobaczysz podświetlone ostrzeżenia dotyczące składni i błędy logiczne.
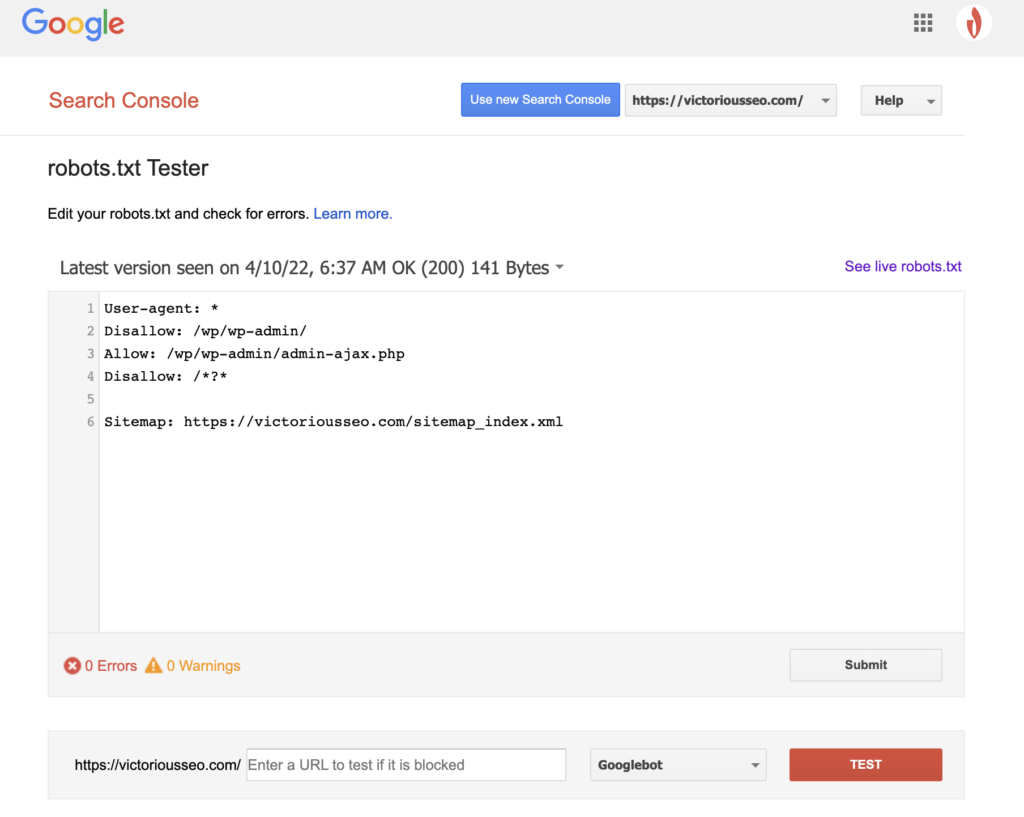
Aby sprawdzić, jak dany Googlebot „widzi” Twoją stronę, wprowadź adres URL swojej witryny w polu tekstowym u dołu strony, a następnie wybierz spośród różnych Googlebotów z menu rozwijanego po prawej stronie. Naciśnięcie „TEST” zasymuluje zachowanie wybranego bota i pokaże, czy jakieś dyrektywy uniemożliwiają Googlebotowi dostęp do strony.

Niedociągnięcia robots.txt
Pliki robots.txt są bardzo przydatne, ale mają swoje ograniczenia.
Pliki robots.txt nie powinny być używane do ochrony lub ukrywania części witryny (może to naruszyć ustawę o ochronie danych). Pamiętasz, kiedy sugerowałem Ci wyszukanie własnego pliku robots.txt? Oznacza to, że każdy może uzyskać do niego dostęp, nie tylko Ty. Jeśli istnieją informacje, które musisz chronić, najlepszym rozwiązaniem jest zabezpieczenie określonych stron lub dokumentów hasłem.
Ponadto dyrektywy w pliku robots.txt to po prostu żądania. Możesz oczekiwać, że Googlebot i inne legalne roboty będą przestrzegać Twoich poleceń, ale inne boty mogą je po prostu zignorować.
Wreszcie, nawet jeśli zażądasz od robotów indeksujących określonych adresów URL, nie będą one niewidoczne. Inne strony internetowe mogą zawierać do nich linki. Jeśli nie chcesz, aby pewne informacje na Twojej stronie były dostępne do publicznego wglądu, powinieneś zabezpieczyć je hasłem. Jeśli chcesz mieć pewność, że nie zostanie zindeksowany, rozważ umieszczenie na stronie tagu noindex.
Dowiedz się więcej o SEO technicznym: Pobierz naszą listę kontrolną
Chcesz dowiedzieć się więcej o SEO, w tym instrukcje krok po kroku, jak wziąć pozycjonowanie swojej witryny w swoje ręce? Pobierz naszą listę kontrolną SEO 2022, aby uzyskać pełną listę rzeczy do zrobienia, w tym cenne zasoby, które pomogą Ci poprawić rankingi wyszukiwania i przyciągnąć więcej ruchu organicznego do Twojej witryny.

Lista kontrolna SEO i narzędzia planowania
Czy jesteś gotowy, aby przenieść igłę na SEO? Pobierz interaktywną listę kontrolną i narzędzia do planowania i zacznij!