
Cum să creați un fișier Robots.txt (și de ce trebuie)
Publicat: 2022-06-07Explicarea SEO oamenilor poate fi dificilă, deoarece există o mulțime de pași mici care ar putea să nu pară foarte importanți la început, dar se adună la câștiguri mari în clasamentele de căutare atunci când sunt făcute corect.
Un pas important, care este ușor de trecut cu vederea, este acela de a permite crawlerilor motoarelor de căutare să știe ce pagini să indexeze - și care nu. Puteți face acest lucru cu un fișier robots.txt.
În postarea de astăzi, voi explica exact cum să creați un fișier robots.txt, astfel încât să puteți obține această parte fundamentală a site-ului dvs. și să vă asigurați că crawlerele interacționează cu site-ul dvs. în modul dorit.
Ce este un fișier robots.txt?
Fișierul robots.txt este o directivă simplă care le spune crawlerilor motoarelor de căutare ce pagini de pe site-ul dvs. să acceseze cu crawlere și să indexeze.
Face parte din protocolul de excludere a roboților (REP), o familie de proceduri standard care guvernează modul în care roboții motoarelor de căutare accesează cu crawlere web, evaluează și indexează conținutul site-ului și apoi furnizează acel conținut utilizatorilor. Acest fișier specifică unde crawlerelor li se permite să acceseze cu crawlere și unde nu le este permis. De asemenea, poate conține informații care ar putea ajuta crawlerii să acceseze cu crawlere mai eficient site-ul web.
REP include, de asemenea, „etichete meta roboți”, care sunt directive incluse în HTML-ul unei pagini care conțin instrucțiuni specifice despre cum ar trebui să acceseze cu crawlere web și să indexeze anumite pagini web și imaginile sau fișierele pe care le conțin.
Care este diferența dintre Robots.txt și Meta Robots Tag?
După cum am menționat, protocolul de excludere a roboților include și „etichete meta roboți”, care sunt bucăți de cod incluse în HTML-ul unei pagini. Acestea sunt diferite de fișierele robots.txt prin faptul că oferă direcții către crawlerele web pe anumite pagini web , interzicând accesul fie la pagina completă, fie la anumite fișiere conținute în pagină, cum ar fi fotografii și videoclipuri.
În schimb, fișierele robots.txt au scopul de a împiedica indexarea unor segmente întregi ale unui site web, cum ar fi un subdirector destinat doar uzului intern. Un fișier robots.txt se află mai degrabă pe domeniul rădăcină al site-ului dvs. decât pe o anumită pagină, iar directivele sunt structurate astfel încât să afecteze toate paginile conținute în directoarele sau subdirectoarele la care se referă.
De ce am nevoie de un fișier Robots.txt?
Fișierul robots.txt este un fișier text înșelător de simplu de mare importanță. Fără aceasta, crawlerele web vor indexa pur și simplu fiecare pagină pe care o găsesc.
De ce contează asta?
Pentru început, accesarea cu crawlere a unui întreg site necesită timp și resurse. Toate acestea costă bani, așa că Google limitează cât de mult va accesa cu crawlere un site, mai ales dacă acel site este foarte mare. Acest lucru este cunoscut sub numele de „buget de accesare cu crawlere”. Bugetul de accesare cu crawlere este limitat de mai mulți factori tehnici, inclusiv timpul de răspuns, adresele URL cu valoare redusă și numărul de erori întâlnite.
În plus, dacă permiteți motoarelor de căutare acces neîngrădit la toate paginile dvs. și lăsați crawlerele lor să le indexeze, este posibil să ajungeți să aveți indexare. Aceasta înseamnă că Google poate clasa pagini neimportante pe care nu doriți să apară în rezultatele căutării. Aceste rezultate ar putea oferi vizitatorilor o experiență slabă și ar putea chiar să concureze cu paginile pentru care doriți să vă clasați.
Când adăugați un fișier robots.txt pe site-ul dvs. sau actualizați fișierul existent, puteți reduce risipa de buget de accesare cu crawlere și puteți limita creșterea indexului.
Lectură recomandată
- Ghid tehnic SEO: Ce este SEO tehnic?
- Ce este Index Bloat? (Și cum să o rezolvi)
Unde îmi pot găsi fișierul Robots.txt?
Există o modalitate simplă de a vedea dacă site-ul dvs. are un fișier robots.txt: căutați-l pe internet.
Doar introduceți adresa URL a oricărui site și adăugați „/robots.txt” la sfârșit. De exemplu: victoriousseo.com/robots.txt vă arată pe al nostru.
Încercați-l singur introducând adresa URL a site-ului dvs. și adăugând „/robots.txt” la sfârșit. Ar trebui să vedeți unul dintre cele trei lucruri:
- Câteva rânduri de text care indică un fișier robots.txt valid
- O pagină complet goală, care indică că nu există un fișier robots.txt real
- O eroare 404
Dacă vă verificați site-ul și obțineți oricare dintre următoarele două rezultate, veți dori să creați un fișier robots.txt pentru a ajuta motoarele de căutare să înțeleagă mai bine unde ar trebui să-și concentreze eforturile.
Cum se creează un fișier Robots.txt
Un fișier robots.txt include anumite comenzi pe care roboții motoarelor de căutare le pot citi și urma. Iată câțiva dintre termenii pe care îi veți folosi atunci când creați un fișier robots.txt.
Termeni obișnuiți pentru Robots.txt de cunoscut
User-Agent : un user-agent este orice program care are sarcina de a prelua și prezenta conținut web pentru utilizatorii finali. În timp ce browserele web, playerele media și pluginurile pot fi considerate exemple de agenți de utilizator, în contextul fișierelor robot.txt, un agent de utilizator este un crawler sau un spider pentru motor de căutare (cum ar fi Googlebot) care accesează cu crawlere și indexează. site-ul tau.
Permite: când este conținută într-un fișier robots.txt, această comandă le permite agenților de utilizator să acceseze cu crawlere toate paginile care o urmează. De exemplu, dacă comanda scrie „Permite: /” înseamnă că orice crawler web poate accesa orice pagină care urmează bara oblică din „http://www.example.com/”. Nu trebuie să adăugați acest lucru pentru tot ceea ce doriți să fie accesat cu crawlere, deoarece orice lucru care nu este interzis de robots.txt este permis implicit. În schimb, utilizați-l pentru a permite accesul la un subdirector care se află într-o cale interzisă. De exemplu, site-urile WordPress au adesea o directivă disallow pentru folderul /wp-admin/, care, la rândul său, le cere să adauge o directivă de autorizare pentru a permite crawlerilor să ajungă la /wp-admin/admin-ajax.php fără a ajunge la nimic altceva în folderul principal.
Disallow: Această comandă interzice anumitor user-agents să acceseze cu crawlere paginile care urmează folderului specificat. De exemplu, dacă comanda arată „Disallow: /blog/” înseamnă că agentul utilizator nu poate accesa cu crawlere nicio adresă URL care conține subdirectorul /blog/, ceea ce ar exclude întregul blog de la căutare. Probabil că nu ai vrea niciodată să faci asta, dar ai putea. De aceea, este foarte important să luați în considerare implicațiile utilizării directivei disallow de fiecare dată când vă gândiți să faceți modificări fișierului robots.txt.
Întârzierea accesului cu crawlere: deși această comandă este considerată neoficială, este concepută pentru a împiedica crawlerele web de la serverele potențial copleșitoare cu solicitări. De obicei, este implementat pe site-uri web unde prea multe solicitări ar putea cauza probleme cu serverul. Unele motoare de căutare îl acceptă, dar Google nu. Puteți ajusta rata de accesare cu crawlere pentru Google deschizând Google Search Console, navigând la pagina Setări pentru rata de accesare cu crawlere a proprietății dvs. și ajustând glisorul de acolo. Acest lucru funcționează numai dacă Google consideră că nu este optim. Dacă credeți că este suboptim și Google nu este de acord, poate fi necesar să faceți o solicitare specială pentru a o ajusta. Asta pentru că Google preferă să le permiteți să optimizeze rata de accesare cu crawlere pentru site-ul dvs.

Sitemap XML: această directivă face exact ceea ce ați ghici că face: spuneți crawlerilor web unde este harta dvs. XML sitemap. Ar trebui să arate ceva de genul: „Sitemap: http://www.example.com/sitemap.xml”. Puteți afla mai multe despre cele mai bune practici pentru sitemap aici.
Instrucțiuni pas cu pas pentru crearea Robots.txt
Pentru a vă crea propriul fișier robots.txt, veți avea nevoie de acces la un editor de text simplu, cum ar fi Notepad sau TextEdit. Este important să nu folosiți un procesor de text, deoarece acestea salvează de obicei fișierele în forme proprietare și pot adăuga caractere speciale fișierului.
Din motive de simplitate, vom folosi „www.example.com”.
Vom începe prin a seta parametrii user-agent. Pe prima linie, tastați:
Agent utilizator: *
Asteriscul înseamnă că toți crawlerele web au permisiunea de a vă vizita site-ul web.
Unele site-uri web vor folosi o directivă de autorizare pentru a spune că roboții au voie să se acceseze cu crawlere, dar acest lucru nu este necesar. Orice părți ale site-ului pe care nu le-ați interzis sunt implicit permise.
În continuare, vom introduce parametrul disallow. Apăsați „întoarcere” de două ori pentru a introduce o pauză după linia user-agent, apoi tastați:
Nu permite: /
Deoarece nu introducem nicio comandă după aceasta, înseamnă că crawlerele web pot vizita fiecare pagină de pe site-ul dvs.
Dacă doriți să blocați accesul la un anumit conținut, puteți adăuga directorul după comanda disallow. Fișierul nostru robots.txt are următoarele două comenzi de respingere:
Nu permiteți: /wp/wp-admin/
Nu permite: /*?*
Prima se asigură că paginile noastre de administrare WordPress (unde edităm lucruri precum acest articol) nu sunt accesate cu crawlere. Acestea sunt pagini pe care nu le-am dori să fie clasate în căutare și, de asemenea, ar fi o pierdere de timp pentru Google să încerce să le acceseze cu crawlere, deoarece sunt protejate cu parolă. Al doilea împiedică accesarea cu crawlere a adreselor URL care conțin un semn de întrebare, cum ar fi paginile cu rezultatele căutării pe blog.
După ce ați finalizat comenzile, faceți un link către harta site-ului. Deși acest pas nu este necesar din punct de vedere tehnic, este o practică recomandată, deoarece indică paianjenii web către cele mai importante pagini de pe site-ul dvs. și clarifică arhitectura site-ului. După ce ați inserat o altă întrerupere de linie, tastați:
Harta site-ului: http://www.example.com/sitemap.xml
Acum, dezvoltatorul dvs. web vă poate încărca fișierul pe site-ul dvs. web.
Crearea unui fișier Robots.txt în WordPress
Dacă aveți acces de administrator la WordPress, puteți modifica fișierul robots.txt cu pluginul Yoast SEO sau AIOSEO. Alternativ, dezvoltatorul dvs. web poate folosi un client FTP sau SFTP pentru a se conecta la site-ul dvs. WordPress și a accesa directorul rădăcină.
Nu mutați fișierul robots.txt în altă parte decât în directorul rădăcină. În timp ce unele surse sugerează plasarea acestuia într-un subdirector sau subdomeniu, în mod ideal, ar trebui să locuiască pe domeniul dvs. rădăcină: www.example.com/robots.txt.
Cum să vă testați fișierul Robots.txt
Acum că ați creat un fișier robots.txt, este timpul să îl testați. Din fericire, Google ușurează, oferind un tester robots.txt ca parte a Google Search Console.
După ce deschideți testerul pentru site-ul dvs., veți vedea toate avertismentele de sintaxă și erorile de logică evidențiate.
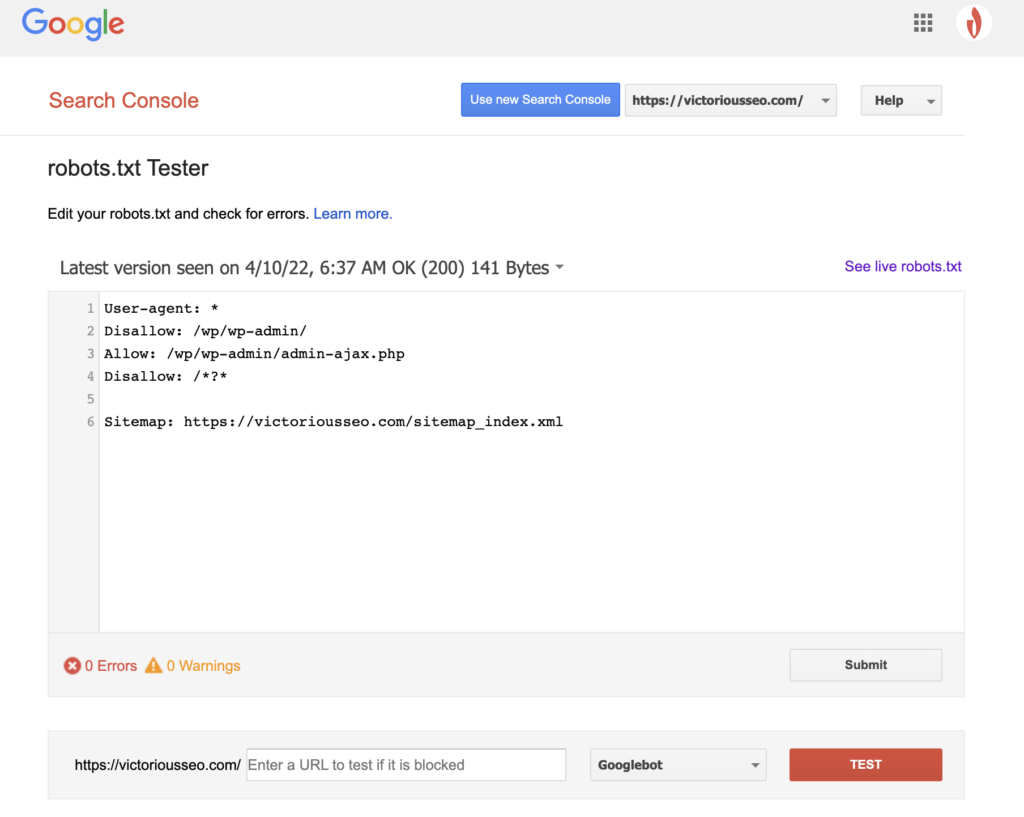
Pentru a testa modul în care un anumit Googlebot „văd” pagina dvs., introduceți o adresă URL de pe site-ul dvs. în caseta de text din partea de jos a paginii și apoi alegeți dintre diferiții Googlebot din meniul drop-down din dreapta. Atingerea „TEST” va simula comportamentul botului pe care l-ați selectat și va arăta dacă vreo directivă împiedică Googlebot să acceseze pagina.

Deficiențele Robots.txt
Fișierele Robots.txt sunt foarte utile, dar au limitările lor.
Fișierele Robots.txt nu trebuie utilizate pentru a proteja sau a ascunde părți ale site-ului dvs. web (în acest fel ar putea încălca Legea privind protecția datelor). Vă amintiți când v-am sugerat să căutați propriul fișier robots.txt? Asta înseamnă că oricine îl poate accesa, nu doar tu. Dacă există informații pe care trebuie să le protejați, cea mai bună abordare este protejarea cu parolă a anumitor pagini sau documente.
În plus, directivele fișierului robots.txt sunt pur și simplu solicitări. Vă puteți aștepta ca Googlebot și alți crawler-uri legitimi să respecte directivele dvs., dar alți roboți le pot ignora pur și simplu.
În cele din urmă, chiar dacă solicitați crawlerelor să nu indexeze anumite adrese URL, acestea nu sunt invizibile. Alte site-uri web pot trimite către ele. Dacă nu doriți ca anumite informații de pe site-ul dvs. să fie disponibile pentru vizualizare publică, ar trebui să le protejați cu parolă. Dacă doriți să vă asigurați că nu va fi indexat, luați în considerare includerea unei etichete noindex pe pagină.
Aflați mai multe despre SEO tehnic: descărcați lista noastră de verificare
Doriți să aflați mai multe despre SEO, inclusiv instrucțiuni pas cu pas despre cum să luați SEO site-ului dvs. în propriile mâini? Descărcați Lista noastră de verificare SEO 2022 pentru a obține o listă cuprinzătoare de activități, inclusiv resurse valoroase care vă vor ajuta să vă îmbunătățiți clasamentul în căutare și să generați mai mult trafic organic către site-ul dvs.

Lista de verificare SEO și instrumente de planificare
Ești gata să muți acul pe SEO? Obțineți lista de verificare interactivă și instrumente de planificare și începeți!