
Como criar um arquivo Robots.txt (e por que você precisa)
Publicados: 2022-06-07Explicar o SEO para as pessoas pode ser difícil porque há muitos pequenos passos que podem não parecer muito importantes no início, mas eles somam grandes ganhos nos rankings de pesquisa quando feitos corretamente.
Um passo importante que é fácil de ignorar é permitir que os rastreadores de mecanismos de pesquisa saibam quais páginas indexar – e quais não indexar. Você pode fazer isso com um arquivo robots.txt.
No post de hoje, vou explicar exatamente como criar um arquivo robots.txt para que você possa obter essa parte fundamental do seu site e garantir que os rastreadores estejam interagindo com seu site da maneira que você deseja.
O que é um arquivo robots.txt?
O arquivo robots.txt é uma diretiva simples que informa aos rastreadores do mecanismo de pesquisa quais páginas do seu site devem ser rastreadas e indexadas.
Faz parte do protocolo de exclusão de robôs (REP), uma família de procedimentos padrão que governam como os robôs dos mecanismos de pesquisa rastreiam a Web, avaliam e indexam o conteúdo do site e, em seguida, fornecem esse conteúdo aos usuários. Este arquivo especifica onde os rastreadores têm permissão para rastrear e onde eles não têm permissão. Ele também pode conter informações que podem ajudar os rastreadores a rastrear o site com mais eficiência.
O REP também inclui "meta tags de robôs", que são diretivas incluídas no HTML de uma página que contêm instruções específicas sobre como os rastreadores da Web devem rastrear e indexar determinadas páginas da Web e as imagens ou arquivos que elas contêm.
Qual é a diferença entre Robots.txt e Meta Robots Tag?
Como mencionei, o protocolo de exclusão de robôs também inclui “meta tags de robôs”, que são pedaços de código incluídos no HTML de uma página. Eles são diferentes dos arquivos robots.txt, pois fornecem orientação para rastreadores da Web em páginas da Web específicas , impedindo o acesso à página completa ou a arquivos específicos contidos na página, como fotos e vídeos.
Por outro lado, os arquivos robots.txt destinam-se a impedir que segmentos inteiros de um site sejam indexados, como um subdiretório destinado apenas ao uso interno. Um arquivo robots.txt reside no domínio raiz do seu site e não em uma página específica, e as diretivas são estruturadas de forma que afetam todas as páginas contidas nos diretórios ou subdiretórios aos quais se referem.
Por que preciso de um arquivo Robots.txt?
O arquivo robots.txt é um arquivo de texto enganosamente simples de grande importância. Sem ele, os rastreadores da web simplesmente indexarão cada página que encontrarem.
Por que isso importa?
Para começar, rastrear um site inteiro leva tempo e recursos. Tudo isso custa dinheiro, então o Google limita o quanto ele rastreará um site, especialmente se esse site for muito grande. Isso é conhecido como “orçamento de rastreamento”. O orçamento de rastreamento é limitado por vários fatores técnicos, incluindo tempo de resposta, URLs de baixo valor e o número de erros encontrados.
Além disso, se você permitir aos mecanismos de pesquisa acesso irrestrito a todas as suas páginas e permitir que seus rastreadores as indexem, você pode acabar com o índice inchado. Isso significa que o Google pode classificar páginas sem importância que você não deseja que apareçam nos resultados de pesquisa. Esses resultados podem fornecer aos visitantes uma experiência ruim e podem até acabar competindo com as páginas para as quais você deseja classificar.
Ao adicionar um arquivo robots.txt ao seu site ou atualizar o arquivo existente, você pode reduzir o desperdício do orçamento de rastreamento e limitar o inchaço do índice.
Leitura recomendada
- Guia técnico de SEO: O que é SEO técnico?
- O que é o inchaço do índice? (E como consertar isso)
Onde posso encontrar meu arquivo Robots.txt?
Há uma maneira simples de ver se o seu site tem um arquivo robots.txt: procure na internet.
Basta digitar a URL de qualquer site e adicionar “/robots.txt” ao final. Por exemplo: victoriousseo.com/robots.txt mostra o nosso.
Experimente você mesmo digitando a URL do seu site e adicionando “/robots.txt” no final. Você deve ver uma das três coisas:
- Algumas linhas de texto indicando um arquivo robots.txt válido
- Uma página completamente em branco, indicando que não há um arquivo robots.txt real
- Um erro 404
Se você estiver verificando seu site e obtendo um dos dois segundos resultados, convém criar um arquivo robots.txt para ajudar os mecanismos de pesquisa a entender melhor onde devem concentrar seus esforços.
Como criar um arquivo Robots.txt
Um arquivo robots.txt inclui determinados comandos que os robôs do mecanismo de pesquisa podem ler e seguir. Aqui estão alguns dos termos que você usará ao criar um arquivo robots.txt.
Termos comuns do Robots.txt para saber
User-Agent : Um user-agent é qualquer software encarregado de recuperar e apresentar conteúdo da Web para usuários finais. Embora navegadores da Web, players de mídia e plug-ins possam ser considerados exemplos de user-agents, no contexto de arquivos robot.txt, um user-agent é um rastreador ou spider de mecanismo de pesquisa (como o Googlebot) que rastreia e indexa seu site.
Permitir: quando contido em um arquivo robots.txt, esse comando permite que os agentes do usuário rastreiem todas as páginas que o seguem. Por exemplo, se o comando for "Permitir: /", isso significa que qualquer rastreador da Web pode acessar qualquer página que siga a barra em "http://www.example.com/". Você não precisa adicioná-lo para tudo o que deseja rastreado, pois tudo o que não é proibido pelo robots.txt é permitido implicitamente. Em vez disso, use-o para permitir o acesso a um subdiretório que esteja em um caminho não permitido. Por exemplo, os sites do WordPress geralmente têm uma diretiva disallow para a pasta /wp-admin/, o que, por sua vez, exige que eles adicionem uma diretiva allow para permitir que os rastreadores acessem /wp-admin/admin-ajax.php sem alcançar qualquer outra coisa no diretório pasta principal.
Disallow: Este comando proíbe que agentes de usuário específicos rastreiem as páginas que seguem a pasta especificada. Por exemplo, se o comando ler “Disallow: /blog/”, isso significa que o agente do usuário não pode rastrear URLs que contenham o subdiretório /blog/, o que excluiria todo o blog da pesquisa. Você provavelmente nunca iria querer fazer isso, mas você poderia. É por isso que é muito importante considerar as implicações de usar a diretiva disallow sempre que você pensar em fazer alterações em seu arquivo robots.txt.
Atraso no rastreamento: embora esse comando seja considerado não oficial, ele foi projetado para impedir que os rastreadores da Web possam sobrecarregar os servidores com solicitações. Normalmente, é implementado em sites em que muitas solicitações podem causar problemas no servidor. Alguns mecanismos de pesquisa oferecem suporte, mas o Google não. Você pode ajustar a taxa de rastreamento do Google abrindo o Google Search Console, navegando até a página Configurações da taxa de rastreamento da sua propriedade e ajustando o controle deslizante lá. Isso só funciona se o Google achar que não é o ideal. Se você achar que está abaixo do ideal e o Google discordar, talvez seja necessário fazer uma solicitação especial para ajustá-lo. Isso porque o Google prefere que você permita que eles otimizem a taxa de rastreamento do seu site.

XML Sitemap: Esta diretiva faz exatamente o que você imagina: informa aos rastreadores da web onde está seu sitemap XML. Deve ser algo como: “Sitemap: http://www.example.com/sitemap.xml.” Você pode saber mais sobre as práticas recomendadas do sitemap aqui.
Instruções passo a passo para criar Robots.txt
Para criar seu próprio arquivo robots.txt, você precisará acessar um editor de texto simples, como o Bloco de Notas ou o TextEdit. É importante não usar um processador de texto, pois eles normalmente salvam arquivos em formatos proprietários e podem adicionar caracteres especiais ao arquivo.
Para simplificar, usaremos "www.example.com".
Começaremos definindo os parâmetros do agente do usuário. Na primeira linha, digite:
Agente de usuário: *
O asterisco significa que todos os rastreadores da Web têm permissão para visitar seu site.
Alguns sites usarão uma diretiva de permissão para dizer que os bots podem rastrear, mas isso é desnecessário. Quaisquer partes do site que você não desautorizou são implicitamente permitidas.
Em seguida, inseriremos o parâmetro disallow. Pressione “return” duas vezes para inserir uma quebra após a linha do agente do usuário e digite:
Não permitir: /
Como não estamos inserindo nenhum comando depois, isso significa que os rastreadores da Web podem visitar todas as páginas do seu site.
Se você deseja bloquear o acesso a determinado conteúdo, pode adicionar o diretório após o comando disallow. Nosso arquivo robots.txt tem os dois comandos de não permissão a seguir:
Não permitir: /wp/wp-admin/
Não permitir: /*?*
O primeiro garante que nossas páginas de administração do WordPress (onde editamos coisas como este artigo) não sejam rastreadas. Essas são páginas que não gostaríamos de ranquear na pesquisa, e também seria uma perda de tempo do Google tentar rastreá-las porque são protegidas por senha. A segunda impede que URLs que contenham um ponto de interrogação, como páginas de resultados de pesquisa de blog, sejam rastreados.
Depois de concluir seus comandos, crie um link para o mapa do site. Embora essa etapa não seja tecnicamente necessária, é uma prática recomendada, pois aponta os web spiders para as páginas mais importantes do seu site e deixa a arquitetura do seu site clara. Após inserir outra quebra de linha, digite:
Mapa do site: http://www.example.com/sitemap.xml
Agora, seu desenvolvedor da Web pode enviar seu arquivo para seu site.
Criando um arquivo Robots.txt no WordPress
Se você tiver acesso de administrador ao seu WordPress, poderá modificar seu arquivo robots.txt com o plug-in Yoast SEO ou AIOSEO. Alternativamente, seu desenvolvedor web pode usar um cliente FTP ou SFTP para se conectar ao seu site WordPress e acessar o diretório raiz.
Não mova o arquivo robots.txt para outro lugar que não seja o diretório raiz. Embora algumas fontes sugiram colocá-lo em um subdiretório ou subdomínio, o ideal é que ele resida em seu domínio raiz: www.example.com/robots.txt.
Como testar seu arquivo Robots.txt
Agora que você criou um arquivo robots.txt, é hora de testá-lo. Felizmente, o Google facilita isso fornecendo um testador de robots.txt como parte do Google Search Console.
Depois de abrir o testador do seu site, você verá os avisos de sintaxe e os erros de lógica destacados.
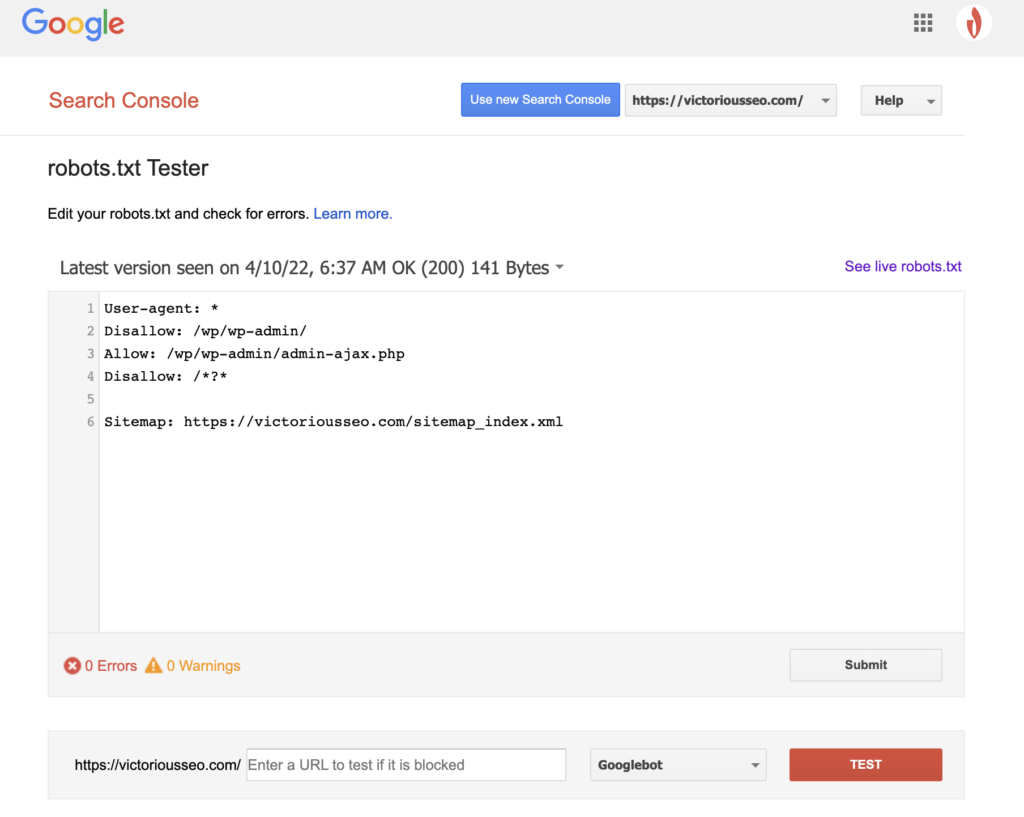
Para testar como um determinado Googlebot “vê” sua página, insira um URL do seu site na caixa de texto na parte inferior da página e escolha entre os vários Googlebots no menu suspenso à direita. Clicar em “TEST” simulará o comportamento do bot que você selecionou e mostrará se alguma diretiva está impedindo o Googlebot de acessar a página.

Defeitos do Robots.txt
Os arquivos Robots.txt são muito úteis, mas têm suas limitações.
Os arquivos Robots.txt não devem ser usados para proteger ou ocultar partes do seu site (isso pode violar a Lei de Proteção de Dados). Lembra quando sugeri que você procurasse seu próprio arquivo robots.txt? Isso significa que qualquer pessoa pode acessá-lo, não apenas você. Se houver informações que você precisa proteger, a melhor abordagem é proteger páginas ou documentos específicos com senha.
Além disso, suas diretivas de arquivo robots.txt são simplesmente solicitações. Você pode esperar que o Googlebot e outros rastreadores legítimos obedeçam às suas diretivas, mas outros bots podem simplesmente ignorá-los.
Por fim, mesmo que você solicite que os rastreadores não indexem URLs específicos, eles não ficarão invisíveis. Outros sites podem ter links para eles. Se você não quiser que certas informações em seu site estejam disponíveis para visualização pública, você deve protegê-las com senha. Se você quiser ter certeza de que não será indexado, considere incluir uma tag noindex na página.
Saiba mais sobre SEO técnico: baixe nossa lista de verificação
Quer saber mais sobre SEO, incluindo instruções passo a passo sobre como fazer o SEO do seu site em suas próprias mãos? Baixe nossa Lista de Verificação de SEO 2022 para obter uma lista abrangente de tarefas, incluindo recursos valiosos que ajudarão você a melhorar seus rankings de pesquisa e direcionar mais tráfego orgânico para seu site.

Lista de verificação de SEO e ferramentas de planejamento
Você está pronto para mover a agulha em seu SEO? Obtenha a lista de verificação interativa e as ferramentas de planejamento e comece!