
Come creare un file Robots.txt (e perché è necessario)
Pubblicato: 2022-06-07Spiegare la SEO alle persone può essere difficile perché ci sono molti piccoli passaggi che potrebbero non sembrare molto importanti all'inizio, ma si sommano a grandi guadagni nelle classifiche di ricerca se fatti bene.
Un passaggio importante che è facile trascurare è consentire ai crawler dei motori di ricerca di sapere quali pagine indicizzare e quali no. Puoi farlo con un file robots.txt.
Nel post di oggi, spiegherò esattamente come creare un file robots.txt in modo da poter mettere a posto questa parte fondamentale del tuo sito e assicurarti che i crawler interagiscano con il tuo sito nel modo desiderato.
Che cos'è un file robots.txt?
Il file robots.txt è una semplice direttiva che indica ai crawler dei motori di ricerca quali pagine del tuo sito scansionare e indicizzare.
Fa parte del protocollo di esclusione dei robot (REP), una famiglia di procedure standard che regolano il modo in cui i robot dei motori di ricerca eseguono la scansione del Web, valutano e indicizzano i contenuti del sito e quindi forniscono tali contenuti agli utenti. Questo file specifica dove i crawler possono eseguire la scansione e dove non possono farlo. Può anche contenere informazioni che potrebbero aiutare i crawler a eseguire la scansione del sito Web in modo più efficiente.
Il REP include anche "meta tag robots", che sono direttive incluse nell'HTML di una pagina che contengono istruzioni specifiche su come i web crawler dovrebbero eseguire la scansione e indicizzare determinate pagine web e le immagini oi file in esse contenuti.
Qual è la differenza tra Robots.txt e Meta Robots Tag?
Come ho già detto, il protocollo di esclusione dei robot include anche "meta tag robots", che sono parti di codice incluse nell'HTML di una pagina. Sono diversi dai file robots.txt in quanto forniscono indicazioni ai crawler web su pagine web specifiche , impedendo l'accesso alla pagina completa oa file particolari contenuti nella pagina, come foto e video.
Al contrario, i file robots.txt hanno lo scopo di impedire l'indicizzazione di interi segmenti di un sito Web, ad esempio una sottodirectory destinata esclusivamente all'uso interno. Un file robots.txt risiede nel dominio principale del tuo sito anziché in una pagina particolare e le direttive sono strutturate in modo tale da interessare tutte le pagine contenute nelle directory o sottodirectory a cui fanno riferimento.
Perché ho bisogno di un file Robots.txt?
Il file robots.txt è un file di testo ingannevolmente semplice di grande importanza. Senza di essa, i web crawler indicizzeranno semplicemente ogni singola pagina che trovano.
Perché è importante?
Per cominciare, la scansione di un intero sito richiede tempo e risorse. Tutto ciò costa denaro, quindi Google limita la quantità di scansione di un sito, soprattutto se quel sito è molto grande. Questo è noto come "crawl budget". Il budget di scansione è limitato da diversi fattori tecnici, tra cui il tempo di risposta, gli URL di basso valore e il numero di errori riscontrati.
Inoltre, se consenti ai motori di ricerca l'accesso illimitato a tutte le tue pagine e consenti ai loro crawler di indicizzarle, potresti finire con un indice gonfio. Ciò significa che Google potrebbe classificare le pagine non importanti che non desideri vengano visualizzate nei risultati di ricerca. Questi risultati potrebbero fornire ai visitatori un'esperienza scadente e potrebbero persino finire per competere con le pagine per le quali desideri classificarti.
Quando aggiungi un file robots.txt al tuo sito o aggiorni il tuo file esistente, puoi ridurre lo spreco di budget di scansione e limitare l'aumento dell'indice.
Lettura consigliata
- Guida SEO tecnica: cos'è la SEO tecnica?
- Cos'è il rigonfiamento dell'indice? (E come risolverlo)
Dove posso trovare il mio file Robots.txt?
C'è un modo semplice per vedere se il tuo sito ha un file robots.txt: cercalo su Internet.
Basta digitare l'URL di qualsiasi sito e aggiungere "/robots.txt" alla fine. Ad esempio: victoriousseo.com/robots.txt ti mostra il nostro.
Prova tu stesso digitando l'URL del tuo sito e aggiungendo "/robots.txt" alla fine. Dovresti vedere una delle tre cose:
- Un paio di righe di testo che indicano un file robots.txt valido
- Una pagina completamente vuota, che indica che non esiste un file robots.txt effettivo
- Un errore 404
Se stai controllando il tuo sito e ottieni uno dei secondi due risultati, ti consigliamo di creare un file robots.txt per aiutare i motori di ricerca a capire meglio dove dovrebbero concentrare i loro sforzi.
Come creare un file Robots.txt
Un file robots.txt include alcuni comandi che i robot dei motori di ricerca possono leggere e seguire. Ecco alcuni dei termini che utilizzerai quando crei un file robots.txt.
Termini comuni di Robots.txt da conoscere
User-Agent : uno user-agent è qualsiasi pezzo di software incaricato di recuperare e presentare contenuti web per gli utenti finali. Mentre browser web, lettori multimediali e plug-in possono essere tutti considerati esempi di user-agent, nel contesto dei file robot.txt, uno user-agent è un crawler o spider dei motori di ricerca (come Googlebot) che esegue la scansione e l'indicizzazione il tuo sito web.
Consenti: se contenuto in un file robots.txt, questo comando consente agli agenti utente di eseguire la scansione di tutte le pagine che lo seguono. Ad esempio, se il comando dice "Consenti: /" significa che qualsiasi web crawler può accedere a qualsiasi pagina che segue la barra in "http://www.example.com/". Non è necessario aggiungerlo per tutto ciò di cui desideri eseguire la scansione, poiché tutto ciò che non è consentito dal robots.txt è implicitamente consentito. Usalo invece per consentire l'accesso a una sottodirectory che si trova in un percorso non consentito. Ad esempio, i siti WordPress hanno spesso una direttiva disallow per la cartella /wp-admin/, che a sua volta richiede loro di aggiungere una direttiva allow per consentire ai crawler di raggiungere /wp-admin/admin-ajax.php senza raggiungere nient'altro nella cartella principale.
Disallow: questo comando impedisce agli agenti utente specifici di eseguire la scansione delle pagine che seguono la cartella specificata. Ad esempio, se il comando dice "Disallow: /blog/", significa che l'agente utente non può eseguire la scansione degli URL che contengono la sottodirectory /blog/, il che escluderebbe l'intero blog dalla ricerca. Probabilmente non vorresti mai farlo, ma potresti. Ecco perché è molto importante considerare le implicazioni dell'utilizzo della direttiva disallow ogni volta che pensi di apportare modifiche al tuo file robots.txt.
Crawl-delay: sebbene questo comando sia considerato non ufficiale, è progettato per impedire ai crawler Web di sovraccaricare i server potenzialmente con richieste. In genere viene implementato su siti Web in cui troppe richieste potrebbero causare problemi al server. Alcuni motori di ricerca lo supportano, ma Google no. Puoi regolare la velocità di scansione per Google aprendo Google Search Console, accedendo alla pagina Impostazioni velocità di scansione della tua struttura e regolando il dispositivo di scorrimento lì. Funziona solo se Google ritiene che non sia ottimale. Se ritieni che non sia ottimale e Google non è d'accordo, potrebbe essere necessario inviare una richiesta speciale per modificarlo. Questo perché Google preferisce che tu consenta loro di ottimizzare la velocità di scansione per il tuo sito web.

XML Sitemap: questa direttiva fa esattamente quello che potresti immaginare: indica ai web crawler dove si trova la tua Sitemap XML. Dovrebbe essere simile a: "Mappa del sito: http://www.example.com/sitemap.xml". Puoi saperne di più sulle best practice per le mappe del sito qui.
Istruzioni dettagliate per la creazione di Robots.txt
Per creare il tuo file robots.txt, devi accedere a un semplice editor di testo come Blocco note o TextEdit. È importante non utilizzare un elaboratore di testi, poiché in genere salva i file in moduli proprietari e può aggiungere caratteri speciali al file.
Per semplicità, utilizzeremo "www.example.com".
Inizieremo impostando i parametri dell'agente utente. Nella prima riga, digita:
User-agent: *
L'asterisco significa che tutti i web crawler sono autorizzati a visitare il tuo sito web.
Alcuni siti Web utilizzeranno una direttiva di autorizzazione per dire che i bot possono eseguire la scansione, ma ciò non è necessario. Qualsiasi parte del sito che non hai disabilitato è implicitamente consentita.
Successivamente, inseriremo il parametro disallow. Premi "return" due volte per inserire un'interruzione dopo la riga user-agent, quindi digita:
Non consentire: /
Poiché non inseriamo alcun comando dopo di esso, significa che i web crawler possono visitare ogni pagina del tuo sito.
Se desideri bloccare l'accesso a determinati contenuti, puoi aggiungere la directory dopo il comando disallow. Il nostro file robots.txt ha i seguenti due comandi di disabilitazione:
Non consentire: /wp/wp-admin/
Non consentire: /*?*
Il primo assicura che le nostre pagine di amministrazione di WordPress (dove modifichiamo cose come questo articolo) non vengano scansionate. Queste sono pagine che non vorremmo classificare nei risultati di ricerca e sarebbe anche una perdita di tempo per Google provare a scansionarle perché sono protette da password. Il secondo impedisce la scansione degli URL che contengono un punto interrogativo, come le pagine dei risultati di ricerca del blog.
Una volta completati i comandi, collegarsi alla mappa del sito. Sebbene questo passaggio non sia tecnicamente richiesto, è una procedura consigliata poiché indirizza gli spider web alle pagine più importanti del tuo sito e rende chiara l'architettura del tuo sito. Dopo aver inserito un'altra interruzione di riga, digitare:
Mappa del sito: http://www.example.com/sitemap.xml
Ora il tuo sviluppatore web può caricare il tuo file sul tuo sito web.
Creazione di un file Robots.txt in WordPress
Se hai accesso come amministratore al tuo WordPress, puoi modificare il tuo file robots.txt con Yoast SEO Plugin o AOSEO. In alternativa, il tuo sviluppatore web può utilizzare un client FTP o SFTP per connettersi al tuo sito WordPress e accedere alla directory principale.
Non spostare il file robots.txt in un punto diverso dalla directory principale. Sebbene alcune fonti suggeriscano di inserirlo in una sottodirectory o sottodominio, idealmente dovrebbe risiedere nel tuo dominio principale: www.example.com/robots.txt.
Come testare il tuo file Robots.txt
Ora che hai creato un file robots.txt, è il momento di provarlo. Fortunatamente, Google semplifica le cose fornendo un tester robots.txt come parte di Google Search Console.
Dopo aver aperto il tester per il tuo sito, vedrai evidenziati tutti gli avvisi di sintassi e gli errori logici.
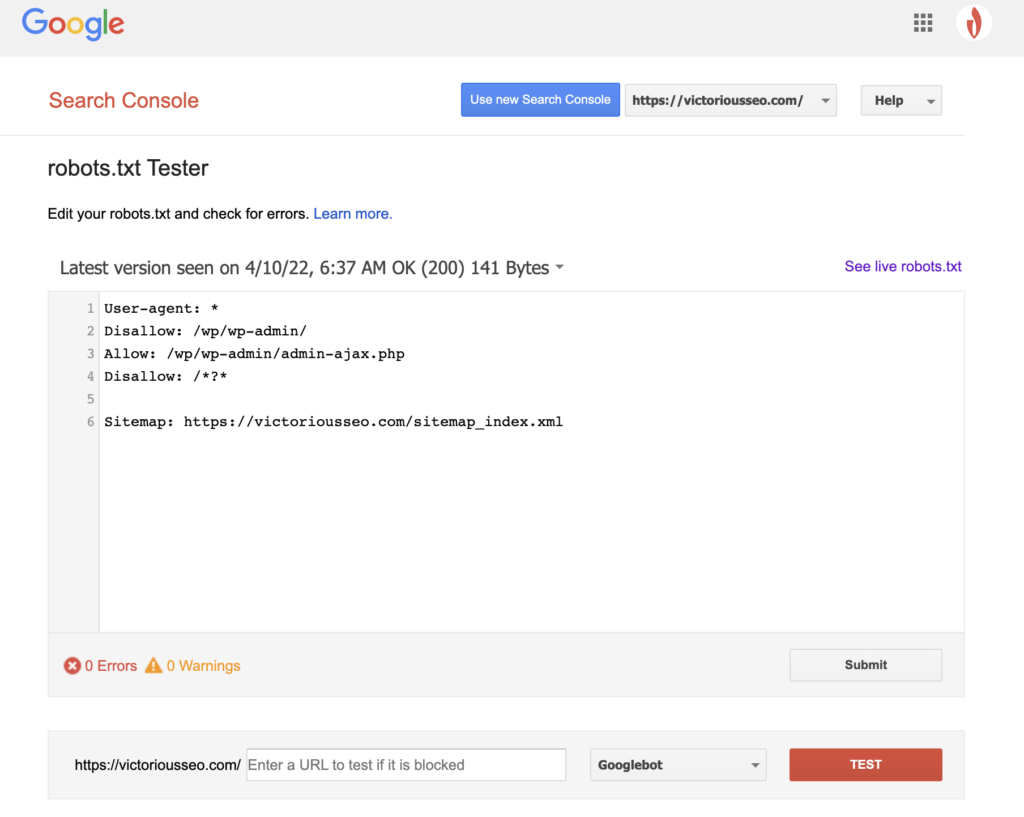
Per testare come un determinato Googlebot “vede” la tua pagina, inserisci un URL del tuo sito nella casella di testo in fondo alla pagina e poi scegli tra i vari Googlebot nel menu a tendina a destra. Premendo "TEST" si simulerà il comportamento del bot selezionato e si mostrerà se eventuali direttive impediscono a Googlebot di accedere alla pagina.

I difetti di Robots.txt
I file Robots.txt sono molto utili, ma hanno i loro limiti.
I file Robots.txt non devono essere utilizzati per proteggere o nascondere parti del tuo sito web (ciò potrebbe violare il Data Protection Act). Ricordi quando ti ho suggerito di cercare il tuo file robots.txt? Ciò significa che chiunque può accedervi, non solo tu. Se ci sono informazioni che devi proteggere, l'approccio migliore è proteggere con password pagine o documenti specifici.
Inoltre, le direttive del tuo file robots.txt sono semplicemente richieste. Puoi aspettarti che Googlebot e altri crawler legittimi obbediscano alle tue direttive, ma altri bot potrebbero semplicemente ignorarle.
Infine, anche se richiedi ai crawler di non indicizzare URL specifici, questi non sono invisibili. Altri siti Web potrebbero collegarsi ad essi. Se non desideri che determinate informazioni sul tuo sito Web siano disponibili per la visualizzazione pubblica, dovresti proteggerle con una password. Se vuoi assicurarti che non venga indicizzato, considera di includere un tag noindex nella pagina.
Ulteriori informazioni sulla SEO tecnica: scarica la nostra lista di controllo
Vuoi saperne di più sulla SEO, comprese le istruzioni dettagliate su come prendere in mano la SEO del tuo sito web? Scarica la nostra Checklist SEO 2022 per ottenere un elenco completo di cose da fare, incluse preziose risorse che ti aiuteranno a migliorare le tue classifiche di ricerca e indirizzare più traffico organico al tuo sito web.

Lista di controllo SEO e strumenti di pianificazione
Sei pronto a muovere l'ago della tua SEO? Ottieni la checklist interattiva e gli strumenti di pianificazione e inizia!