
Cómo crear un archivo Robots.txt (y por qué es necesario)
Publicado: 2022-06-07Explicar el SEO a las personas puede ser difícil porque hay muchos pequeños pasos que pueden no parecer muy importantes al principio, sin embargo, se suman a grandes ganancias en las clasificaciones de búsqueda cuando se hacen correctamente.
Un paso importante que es fácil pasar por alto es permitir que los rastreadores de los motores de búsqueda sepan qué páginas indexar y cuáles no. Puede hacer esto con un archivo robots.txt.
En la publicación de hoy, explicaré exactamente cómo crear un archivo robots.txt para que pueda ajustar esta parte fundamental de su sitio y asegurarse de que los rastreadores interactúen con su sitio de la manera que desea.
¿Qué es un archivo robots.txt?
El archivo robots.txt es una directiva simple que les dice a los rastreadores de motores de búsqueda qué páginas de su sitio deben rastrear e indexar.
Es parte del protocolo de exclusión de robots (REP), una familia de procedimientos estándar que rigen cómo los robots de los motores de búsqueda rastrean la web, evalúan e indexan el contenido del sitio y luego entregan ese contenido a los usuarios. Este archivo especifica dónde pueden rastrear los rastreadores y dónde no. También puede contener información que podría ayudar a los rastreadores a rastrear el sitio web de manera más eficiente.
El REP también incluye "etiquetas de meta robots", que son directivas incluidas en el HTML de una página que contienen instrucciones específicas sobre cómo los rastreadores web deben rastrear e indexar páginas web particulares y las imágenes o archivos que contienen.
¿Cuál es la diferencia entre Robots.txt y Meta Robots Tag?
Como mencioné, el protocolo de exclusión de robots también incluye "etiquetas de meta robots", que son fragmentos de código incluidos en el HTML de una página. Se diferencian de los archivos robots.txt en que brindan orientación a los rastreadores web en páginas web específicas , impidiendo el acceso a la página completa o a archivos específicos contenidos en la página, como fotos y videos.
Por el contrario, los archivos robots.txt están destinados a evitar que se indexen segmentos completos de un sitio web, como un subdirectorio solo para uso interno. Un archivo robots.txt vive en el dominio raíz de su sitio en lugar de en una página en particular, y las directivas están estructuradas de manera que afectan a todas las páginas contenidas dentro de los directorios o subdirectorios a los que se refieren.
¿Por qué necesito un archivo Robots.txt?
El archivo robots.txt es un archivo de texto engañosamente simple de gran importancia. Sin él, los rastreadores web simplemente indexarán cada página que encuentren.
¿Por qué importa esto?
Para empezar, rastrear un sitio completo requiere tiempo y recursos. Todo eso cuesta dinero, por lo que Google limita cuánto rastreará un sitio, especialmente si ese sitio es muy grande. Esto se conoce como "presupuesto de rastreo". El presupuesto de rastreo está limitado por varios factores técnicos, incluido el tiempo de respuesta, las URL de bajo valor y la cantidad de errores encontrados.
Además, si permite que los motores de búsqueda accedan sin restricciones a todas sus páginas y deja que sus rastreadores las indexen, puede terminar con un índice inflado. Esto significa que Google puede clasificar páginas sin importancia que no desea que aparezcan en los resultados de búsqueda. Estos resultados podrían proporcionar a los visitantes una mala experiencia e incluso podrían terminar compitiendo con las páginas para las que desea clasificar.
Cuando agrega un archivo robots.txt a su sitio o actualiza su archivo existente, puede reducir el desperdicio de presupuesto de rastreo y limitar la hinchazón del índice.
Lectura recomendada
- Guía técnica de SEO: ¿Qué es Tech SEO?
- ¿Qué es la hinchazón del índice? (Y como arreglarlo)
¿Dónde puedo encontrar mi archivo Robots.txt?
Hay una forma sencilla de ver si su sitio tiene un archivo robots.txt: búsquelo en Internet.
Simplemente escriba la URL de cualquier sitio y agregue "/robots.txt" al final. Por ejemplo: victoriousseo.com/robots.txt te muestra el nuestro.
Pruébelo usted mismo escribiendo la URL de su sitio y agregando "/robots.txt" al final. Deberías ver una de estas tres cosas:
- Un par de líneas de texto que indican un archivo robots.txt válido
- Una página completamente en blanco, lo que indica que no hay un archivo robots.txt real
- un error 404
Si está revisando su sitio y obteniendo cualquiera de los dos segundos resultados, querrá crear un archivo robots.txt para ayudar a los motores de búsqueda a comprender mejor dónde deben enfocar sus esfuerzos.
Cómo crear un archivo Robots.txt
Un archivo robots.txt incluye ciertos comandos que los robots de los motores de búsqueda pueden leer y seguir. Estos son algunos de los términos que usará cuando cree un archivo robots.txt.
Términos comunes de Robots.txt que debe conocer
Agente de usuario : un agente de usuario es cualquier pieza de software encargada de recuperar y presentar contenido web para los usuarios finales. Si bien los navegadores web, los reproductores multimedia y los complementos pueden considerarse ejemplos de agentes de usuario, en el contexto de los archivos robot.txt, un agente de usuario es un rastreador o araña de un motor de búsqueda (como Googlebot) que rastrea e indexa su página web.
Permitir: cuando está contenido en un archivo robots.txt, este comando permite a los agentes de usuario rastrear cualquier página que lo siga. Por ejemplo, si el comando dice "Permitir: /", significa que cualquier rastreador web puede acceder a cualquier página que siga a la barra inclinada en "http://www.example.com/". No necesita agregar esto para todo lo que desea rastrear, ya que todo lo que no está prohibido por robots.txt está permitido implícitamente. En su lugar, utilícelo para permitir el acceso a un subdirectorio que se encuentra en una ruta no permitida. Por ejemplo, los sitios de WordPress a menudo tienen una directiva de rechazo para la carpeta /wp-admin/, que a su vez requiere que agreguen una directiva de permiso para permitir que los rastreadores lleguen a /wp-admin/admin-ajax.php sin llegar a nada más en el carpeta principal.
Disallow: este comando prohíbe que agentes de usuario específicos rastreen las páginas que siguen a la carpeta especificada. Por ejemplo, si el comando dice "No permitir: /blog/", esto significa que el agente de usuario no puede rastrear ninguna URL que contenga el subdirectorio /blog/, lo que excluiría todo el blog de la búsqueda. Probablemente nunca querrías hacer eso, pero podrías. Por eso es muy importante tener en cuenta las implicaciones de usar la directiva disallow cada vez que piense en realizar cambios en su archivo robots.txt.
Crawl-delay: si bien este comando se considera no oficial, está diseñado para evitar que los rastreadores web abrumen los servidores con solicitudes. Por lo general, se implementa en sitios web donde demasiadas solicitudes podrían causar problemas con el servidor. Algunos motores de búsqueda lo admiten, pero Google no. Puede ajustar la frecuencia de rastreo de Google abriendo Google Search Console, navegando a la página Configuración de la frecuencia de rastreo de su propiedad y ajustando el control deslizante allí. Esto solo funciona si Google cree que no es óptimo. Si cree que no es óptimo y Google no está de acuerdo, es posible que deba presentar una solicitud especial para ajustarlo. Esto se debe a que Google prefiere que les permita optimizar la frecuencia de rastreo de su sitio web.

Mapa del sitio XML: esta directiva hace exactamente lo que crees que hace: decirle a los rastreadores web dónde está tu mapa del sitio XML. Debería tener un aspecto similar a: "Mapa del sitio: http://www.example.com/sitemap.xml". Puede obtener más información sobre las mejores prácticas del mapa del sitio aquí.
Instrucciones paso a paso para crear Robots.txt
Para crear su propio archivo robots.txt, necesitará acceso a un editor de texto simple como Notepad o TextEdit. Es importante no utilizar un procesador de textos, ya que estos suelen guardar archivos en formularios propietarios y pueden agregar caracteres especiales al archivo.
En aras de la simplicidad, usaremos "www.example.com".
Comenzaremos configurando los parámetros del agente de usuario. En la primera línea, escriba:
Agente de usuario: *
El asterisco significa que todos los rastreadores web pueden visitar su sitio web.
Algunos sitios web usarán una directiva de permiso para decir que los bots pueden rastrear, pero esto no es necesario. Cualquier parte del sitio que no haya rechazado está implícitamente permitida.
A continuación, ingresaremos el parámetro de rechazo. Presione "retorno" dos veces para insertar un salto después de la línea de agente de usuario, luego escriba:
No permitir: /
Debido a que no estamos ingresando ningún comando después, significa que los rastreadores web pueden visitar todas las páginas de su sitio.
Si desea bloquear el acceso a cierto contenido, puede agregar el directorio después del comando de rechazo. Nuestro archivo robots.txt tiene los siguientes dos comandos de rechazo:
No permitir: /wp/wp-admin/
No permitir: /*?*
El primero asegura que nuestras páginas de administración de WordPress (donde editamos cosas como este artículo) no sean rastreadas. Estas son páginas que no nos gustaría clasificar en la búsqueda, y también sería una pérdida de tiempo para Google tratar de rastrearlas porque están protegidas con contraseña. El segundo evita que se rastreen las URL que contienen un signo de interrogación, como las páginas de resultados de búsqueda de blogs.
Una vez que haya completado sus comandos, enlace a su mapa del sitio. Si bien este paso no es técnicamente necesario, es una mejor práctica recomendada, ya que dirige a las arañas web a las páginas más importantes de su sitio y aclara la arquitectura de su sitio. Después de insertar otro salto de línea, escriba:
Mapa del sitio: http://www.example.com/sitemap.xml
Ahora su desarrollador web puede cargar su archivo en su sitio web.
Crear un archivo Robots.txt en WordPress
Si tiene acceso de administrador a su WordPress, puede modificar su archivo robots.txt con el complemento Yoast SEO o AIOSEO. Alternativamente, su desarrollador web puede usar un cliente FTP o SFTP para conectarse a su sitio de WordPress y acceder al directorio raíz.
No mueva el archivo robots.txt a ningún otro lugar que no sea el directorio raíz. Si bien algunas fuentes sugieren colocarlo en un subdirectorio o subdominio, idealmente debería vivir en su dominio raíz: www.example.com/robots.txt.
Cómo probar su archivo Robots.txt
Ahora que ha creado un archivo robots.txt, es hora de probarlo. Afortunadamente, Google lo facilita al proporcionar un Probador de robots.txt como parte de Google Search Console.
Después de abrir el probador de su sitio, verá las advertencias de sintaxis y los errores lógicos resaltados.
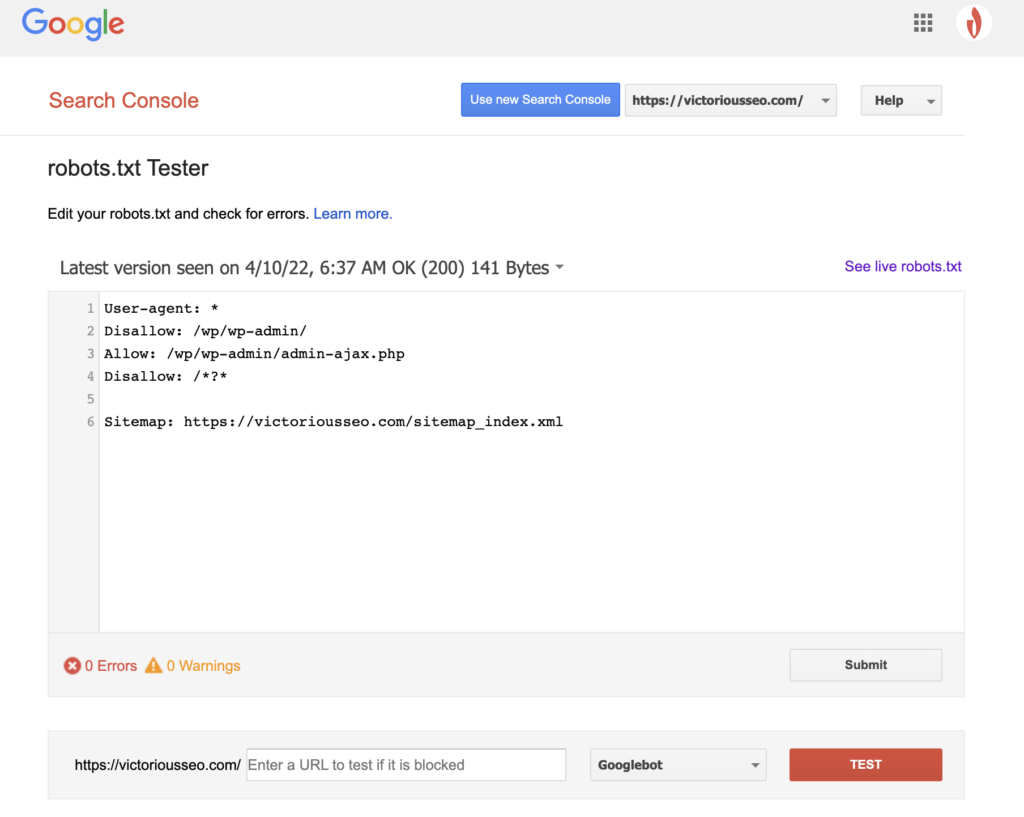
Para probar cómo un Googlebot en particular "ve" su página, ingrese una URL de su sitio en el cuadro de texto en la parte inferior de la página y luego elija entre varios Googlebots en el menú desplegable a la derecha. Presionar "PROBAR" simulará el comportamiento del bot que seleccionó y mostrará si alguna directiva impide que Googlebot acceda a la página.

Deficiencias de Robots.txt
Los archivos Robots.txt son muy útiles, pero tienen sus limitaciones.
Los archivos Robots.txt no deben usarse para proteger u ocultar partes de su sitio web (si lo hace, podría infringir la Ley de Protección de Datos). ¿Recuerdas cuando te sugerí que buscaras tu propio archivo robots.txt? Eso significa que cualquiera puede acceder a él, no solo tú. Si hay información que necesita proteger, el mejor enfoque es proteger con contraseña páginas o documentos específicos.
Además, las directivas de su archivo robots.txt son simplemente solicitudes. Puede esperar que Googlebot y otros rastreadores legítimos obedezcan sus directivas, pero otros bots pueden simplemente ignorarlos.
Finalmente, incluso si solicita a los rastreadores que no indexen URL específicas, no son invisibles. Otros sitios web pueden tener enlaces a ellos. Si no desea que cierta información de su sitio web esté disponible para el público, debe protegerla con una contraseña. Si desea asegurarse de que no se indexará, considere incluir una etiqueta noindex en la página.
Obtenga más información sobre SEO técnico: descargue nuestra lista de verificación
¿Quiere aprender más sobre SEO, incluidas instrucciones paso a paso sobre cómo tomar el SEO de su sitio web en sus propias manos? Descargue nuestra lista de verificación de SEO 2022 para obtener una lista completa de tareas pendientes, que incluye recursos valiosos que lo ayudarán a mejorar sus clasificaciones de búsqueda y generar más tráfico orgánico a su sitio web.

Lista de verificación de SEO y herramientas de planificación
¿Estás listo para mover la aguja en tu SEO? ¡Obtenga la lista de verificación interactiva y las herramientas de planificación y comience!