
Robots.txtファイルを作成する方法(およびその必要性)
公開: 2022-06-07最初はあまり重要ではないように思われるかもしれない小さなステップがたくさんあるので、人々にSEOを説明するのは難しいかもしれませんが、正しく行われると検索ランキングが大幅に向上します。
見落としがちな重要なステップの1つは、検索エンジンのクローラーに、インデックスを作成するページとインデックスを作成しないページを知らせることです。 これは、robots.txtファイルを使用して行うことができます。
今日の投稿では、robots.txtファイルを作成する方法を正確に説明します。これにより、サイトのこの基本的な部分を二乗し、クローラーが希望どおりにサイトと対話していることを確認できます。
robots.txtファイルとは何ですか?
robots.txtファイルは、検索エンジンのクローラーにサイトのどのページをクロールしてインデックスを作成するかを指示する単純なディレクティブです。
これは、検索エンジンロボットがWebをクロールし、サイトコンテンツを評価してインデックスを作成し、そのコンテンツをユーザーに提供する方法を管理する一連の標準手順であるロボット除外プロトコル(REP)の一部です。 このファイルは、クローラーがクロールできる場所と許可されていない場所を指定します。 また、クローラーがWebサイトをより効率的にクロールするのに役立つ情報を含めることもできます。
REPには、「メタロボットタグ」も含まれています。これは、ページのHTMLに含まれるディレクティブであり、Webクローラーが特定のWebページとそれに含まれる画像またはファイルをクロールしてインデックスを作成する方法に関する特定の指示が含まれています。
Robots.txtとMetaRobotsタグの違いは何ですか?
前述したように、ロボット除外プロトコルには、ページのHTMLに含まれるコードの一部である「メタロボットタグ」も含まれています。 これらはrobots.txtファイルとは異なり、特定のWebページ上のWebクローラーに方向を提供し、ページ全体またはページに含まれる写真やビデオなどの特定のファイルへのアクセスを禁止します。
対照的に、robots.txtファイルは、内部使用のみを目的としたサブディレクトリなど、Webサイトのセグメント全体がインデックスに登録されないようにすることを目的としています。 robots.txtファイルは、特定のページではなくサイトのルートドメインに存在し、ディレクティブは、参照するディレクトリまたはサブディレクトリに含まれるすべてのページに影響を与えるように構成されています。
Robots.txtファイルが必要なのはなぜですか?
robots.txtファイルは、一見シンプルなテキストファイルであり、非常に重要です。 これがないと、Webクローラーは見つけたすべてのページにインデックスを付けるだけです。
なぜこれが重要なのですか?
手始めに、サイト全体のクロールには時間とリソースがかかります。 それはすべてお金がかかるので、特にそのサイトが非常に大きい場合、Googleはサイトをクロールする量を制限します。 これは「クロール予算」として知られています。 クロールの予算は、応答時間、価値の低いURL、発生したエラーの数など、いくつかの技術的要因によって制限されます。
さらに、検索エンジンにすべてのページへの無制限のアクセスを許可し、クローラーにインデックスを作成させると、インデックスが肥大化する可能性があります。 これは、検索結果に表示したくない重要でないページをGoogleがランク付けする可能性があることを意味します。 これらの結果は、訪問者に貧弱な体験を提供する可能性があり、ランク付けしたいページと競合する可能性さえあります。
robots.txtファイルをサイトに追加したり、既存のファイルを更新したりすると、クロールの予算の無駄を減らし、インデックスの肥大化を抑えることができます。
おすすめの読み物
- テクニカルSEOガイド:テックSEOとは何ですか?
- インデックスブロートとは何ですか? (そしてそれを修正する方法)
Robots.txtファイルはどこにありますか?
サイトにrobots.txtファイルがあるかどうかを確認する簡単な方法があります。インターネットで調べてください。
任意のサイトのURLを入力し、最後に「/robots.txt」を追加するだけです。 例: victoriousseo.com/robots.txtは私たちのものを示しています。
サイトのURLを入力し、最後に「/robots.txt」を追加して、自分で試してみてください。 次の3つのうちの1つが表示されます。
- 有効なrobots.txtファイルを示す数行のテキスト
- 実際のrobots.txtファイルがないことを示す完全に空白のページ
- 404エラー
サイトをチェックして、次の2つの結果のいずれかを取得している場合は、robots.txtファイルを作成して、検索エンジンがどこに注力すべきかをよりよく理解できるようにする必要があります。
Robots.txtファイルを作成する方法
robots.txtファイルには、検索エンジンのロボットが読み取って追跡できる特定のコマンドが含まれています。 robots.txtファイルを作成するときに使用する用語の一部を次に示します。
知っておくべき一般的なRobots.txtの用語
ユーザーエージェント:ユーザーエージェントは、エンドユーザー向けにWebコンテンツを取得して表示することを目的としたソフトウェアです。 Webブラウザー、メディアプレーヤー、プラグインはすべてユーザーエージェントの例と見なすことができますが、robot.txtファイルのコンテキストでは、ユーザーエージェントは、クロールしてインデックスを作成する検索エンジンのクローラーまたはスパイダー(Googlebotなど)です。あなたのウェブサイト。
許可: robots.txtファイルに含まれている場合、このコマンドは、ユーザーエージェントがそれに続くすべてのページをクロールすることを許可します。 たとえば、コマンドに「Allow:/」と表示されている場合、これは、すべてのWebクローラーが「http://www.example.com/」のスラッシュに続くすべてのページにアクセスできることを意味します。 robots.txtで許可されていないものは暗黙的に許可されるため、クロールするすべてのものにこれを追加する必要はありません。 代わりに、これを使用して、許可されていないパスにあるサブディレクトリへのアクセスを許可します。 たとえば、WordPressサイトには、/ wp-admin /フォルダーに対するdisallowディレクティブが含まれていることがよくあります。これにより、クローラーが/wp-admin/admin-ajax.phpに到達できるように、allowディレクティブを追加する必要があります。メインフォルダ。
Disallow:このコマンドは、特定のユーザーエージェントが指定されたフォルダーに続くページをクロールすることを禁止します。 たとえば、コマンドに「Disallow:/ blog /」と表示されている場合、これは、ユーザーエージェントが/ blog /サブディレクトリを含むURLをクロールできないことを意味します。これにより、ブログ全体が検索から除外されます。 あなたはおそらくそれをしたくないでしょうが、あなたはそうすることができます。 そのため、robots.txtファイルに変更を加えることを検討するときはいつでも、disallowディレクティブを使用することの影響を考慮することが非常に重要です。
クロール遅延:このコマンドは非公式と見なされますが、Webクローラーがリクエストでサーバーを圧倒する可能性を防ぐように設計されています。 これは通常、リクエストが多すぎるとサーバーの問題が発生する可能性があるWebサイトに実装されます。 一部の検索エンジンはそれをサポートしていますが、Googleはサポートしていません。 Googleのクロール速度を調整するには、Google検索コンソールを開き、プロパティの[クロール速度の設定]ページに移動して、そこでスライダーを調整します。 これは、Googleが最適ではないと判断した場合にのみ機能します。 それが最適ではないと思われ、Googleが同意しない場合は、調整するために特別なリクエストを送信する必要があります。 これは、Googleが、Webサイトのクロール速度を最適化できるようにすることを望んでいるためです。

XMLサイトマップ:このディレクティブは、あなたが推測するとおりに実行します。つまり、XMLサイトマップがどこにあるかをWebクローラーに通知します。 「サイトマップ:http://www.example.com/sitemap.xml」のようになります。 サイトマップのベストプラクティスについて詳しくは、こちらをご覧ください。
Robots.txtを作成するためのステップバイステップの説明
独自のrobots.txtファイルを作成するには、メモ帳やテキストエディットなどのシンプルなテキストエディタにアクセスする必要があります。 ワードプロセッサは通常、独自の形式でファイルを保存し、ファイルに特殊文字を追加する可能性があるため、ワードプロセッサを使用しないことが重要です。
わかりやすくするために、「www.example.com」を使用します。
まず、ユーザーエージェントパラメータを設定します。 最初の行に次のように入力します。
ユーザーエージェント: *
アスタリスクは、すべてのWebクローラーがWebサイトにアクセスできることを意味します。
一部のWebサイトは、ボットがクロールを許可されていることを示すためにallowディレクティブを使用しますが、これは不要です。 許可されていないサイトの部分は、暗黙的に許可されます。
次に、disallowパラメーターを入力します。 「return」を2回押して、user-agent行の後にブレークを挿入し、次のように入力します。
禁止:/
その後はコマンドを入力しないため、Webクローラーはサイトのすべてのページにアクセスできます。
特定のコンテンツへのアクセスをブロックする場合は、disallowコマンドの後にディレクトリを追加できます。 robots.txtファイルには次の2つの禁止コマンドがあります。
禁止:/ wp / wp-admin /
禁止:/ *?*
1つ目は、WordPress管理ページ(この記事のようなものを編集する場所)がクロールされないようにします。 これらは検索でのランク付けを望まないページであり、パスワードで保護されているため、Googleがクロールしようとする時間の無駄にもなります。 2つ目は、ブログの検索結果ページなど、疑問符を含むURLがクロールされないようにします。
コマンドを完了したら、サイトマップにリンクします。 この手順は技術的には必須ではありませんが、Webスパイダーがサイトの最も重要なページを指し示し、サイトアーキテクチャが明確になるため、推奨されるベストプラクティスです。 別の改行を挿入した後、次のように入力します。
サイトマップ:http://www.example.com/sitemap.xml
これで、Web開発者はファイルをWebサイトにアップロードできます。
WordPressでRobots.txtファイルを作成する
WordPressへの管理者アクセス権がある場合は、YoastSEOプラグインまたはAIOSEOを使用してrobots.txtファイルを変更できます。 または、Web開発者はFTPまたはSFTPクライアントを使用してWordPressサイトに接続し、ルートディレクトリにアクセスできます。
robots.txtファイルをルートディレクトリ以外の場所に移動しないでください。 一部のソースでは、サブディレクトリまたはサブドメインに配置することを提案していますが、理想的には、ルートドメイン( www.example.com/robots.txt)に存在する必要があります。
Robots.txtファイルをテストする方法
robots.txtファイルを作成したので、次はそれをテストします。 幸い、Googleは、Google検索コンソールの一部としてrobots.txtテスターを提供することで簡単にできます。
サイトのテスターを開くと、構文の警告と論理エラーが強調表示されます。
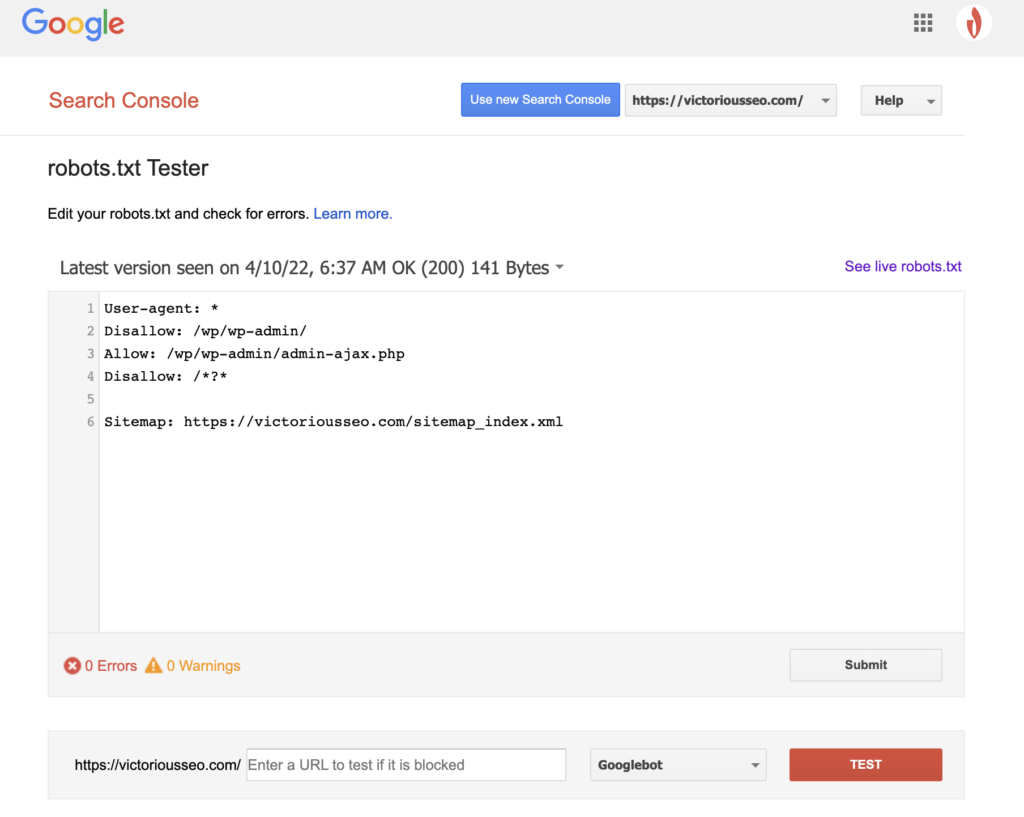
特定のGooglebotがページをどのように「認識する」かをテストするには、ページ下部のテキストボックスにサイトのURLを入力し、右側のドロップダウンでさまざまなGooglebotから選択します。 「TEST」を押すと、選択したボットの動作がシミュレートされ、ディレクティブがGooglebotによるページへのアクセスを妨げているかどうかが示されます。

Robots.txtの欠点
Robots.txtファイルは非常に便利ですが、制限があります。
Robots.txtファイルを使用してWebサイトの一部を保護または非表示にしないでください(データ保護法に違反する可能性があります)。 自分のrobots.txtファイルを検索することを提案したときのことを覚えていますか? つまり、あなただけでなく、誰でもアクセスできるということです。 保護する必要のある情報がある場合、最善のアプローチは、特定のページまたはドキュメントをパスワードで保護することです。
さらに、robots.txtファイルディレクティブは単なるリクエストです。 Googlebotやその他の正当なクローラーがあなたの指示に従うことを期待できますが、他のボットは単にそれらを無視する可能性があります。
最後に、クローラーに特定のURLのインデックスを作成しないように要求しても、それらは非表示になりません。 他のウェブサイトがそれらにリンクしている可能性があります。 Webサイトの特定の情報を公開したくない場合は、パスワードで保護する必要があります。 インデックスが作成されないようにする場合は、ページにnoindexタグを含めることを検討してください。
テクニカルSEOの詳細:チェックリストをダウンロード
あなたのウェブサイトのSEOをあなた自身の手に持っていく方法のステップバイステップの説明を含むSEOについてもっと知りたいですか? 2022年のSEOチェックリストをダウンロードして、検索ランキングを向上させ、ウェブサイトへのオーガニックトラフィックを増やすのに役立つ貴重なリソースを含む、包括的なToDoリストを入手してください。

SEOチェックリストと計画ツール
SEOの針を動かす準備はできていますか? インタラクティブなチェックリストと計画ツールを入手して、始めましょう!