
Comment créer un fichier Robots.txt (et pourquoi vous en avez besoin)
Publié: 2022-06-07Expliquer le référencement aux gens peut être difficile car il y a beaucoup de petites étapes qui peuvent ne pas sembler très importantes au début, mais elles s'ajoutent à de gros gains dans les classements de recherche lorsqu'elles sont bien faites.
Une étape importante facile à ignorer consiste à informer les robots des moteurs de recherche des pages à indexer et de celles à ne pas indexer. Vous pouvez le faire avec un fichier robots.txt.
Dans l'article d'aujourd'hui, je vais vous expliquer exactement comment créer un fichier robots.txt afin que vous puissiez mettre cette partie fondamentale de votre site au carré et vous assurer que les robots d'exploration interagissent avec votre site comme vous le souhaitez.
Qu'est-ce qu'un fichier robots.txt ?
Le fichier robots.txt est une simple directive qui indique aux robots des moteurs de recherche quelles pages de votre site explorer et indexer.
Cela fait partie du protocole d'exclusion des robots (REP), une famille de procédures standard qui régissent la façon dont les robots des moteurs de recherche parcourent le Web, évaluent et indexent le contenu du site, puis diffusent ce contenu aux utilisateurs. Ce fichier spécifie où les robots sont autorisés à explorer et où ils ne sont pas autorisés à le faire. Il peut également contenir des informations susceptibles d'aider les robots d'exploration à explorer plus efficacement le site Web.
Le REP comprend également des «balises méta-robots», qui sont des directives incluses dans le code HTML d'une page contenant des instructions spécifiques sur la manière dont les robots d'exploration Web doivent explorer et indexer des pages Web particulières et les images ou fichiers qu'elles contiennent.
Quelle est la différence entre Robots.txt et la balise Meta Robots ?
Comme je l'ai mentionné, le protocole d'exclusion des robots comprend également des «balises méta-robots», qui sont des morceaux de code inclus dans le code HTML d'une page. Ils sont différents des fichiers robots.txt en ce sens qu'ils orientent les robots d'exploration sur des pages Web spécifiques , en interdisant l'accès à la page complète ou à des fichiers particuliers contenus sur la page, tels que des photos et des vidéos.
En revanche, les fichiers robots.txt sont destinés à empêcher l'indexation de segments entiers d'un site Web, comme un sous-répertoire uniquement destiné à un usage interne. Un fichier robots.txt réside sur le domaine racine de votre site plutôt que sur une page particulière, et les directives sont structurées de manière à affecter toutes les pages contenues dans les répertoires ou sous-répertoires auxquels elles se réfèrent.
Pourquoi ai-je besoin d'un fichier Robots.txt ?
Le fichier robots.txt est un fichier texte trompeusement simple d'une grande importance. Sans cela, les robots d'indexation indexeront simplement chaque page qu'ils trouveront.
Pourquoi est-ce important ?
Pour commencer, l'exploration d'un site entier prend du temps et des ressources. Tout cela coûte de l'argent, donc Google limite la quantité d'exploration d'un site, surtout si ce site est très volumineux. C'est ce qu'on appelle le "budget de crawl". Le budget de crawl est limité par plusieurs facteurs techniques, notamment le temps de réponse, les URL de faible valeur et le nombre d'erreurs rencontrées.
De plus, si vous autorisez les moteurs de recherche à accéder sans entrave à toutes vos pages et laissez leurs robots les indexer, vous risquez de vous retrouver avec un gonflement de l'index. Cela signifie que Google peut classer les pages sans importance que vous ne souhaitez pas voir apparaître dans les résultats de recherche. Ces résultats pourraient offrir aux visiteurs une mauvaise expérience, et ils pourraient même finir par entrer en concurrence avec les pages pour lesquelles vous souhaitez vous classer.
Lorsque vous ajoutez un fichier robots.txt à votre site ou mettez à jour votre fichier existant, vous pouvez réduire le gaspillage du budget de crawl et limiter le gonflement de l'index.
lecture recommandée
- Guide SEO technique : Qu'est-ce que le SEO technique ?
- Qu'est-ce que le gonflement de l'index ? (Et comment y remédier)
Où puis-je trouver mon fichier Robots.txt ?
Il existe un moyen simple de voir si votre site contient un fichier robots.txt : recherchez-le sur Internet.
Tapez simplement l'URL de n'importe quel site et ajoutez "/robots.txt" à la fin. Par exemple : victoriousseo.com/robots.txt vous montre le nôtre.
Essayez-le vous-même en tapant l'URL de votre site et en ajoutant "/robots.txt" à la fin. Vous devriez voir l'une des trois choses suivantes :
- Quelques lignes de texte indiquant un fichier robots.txt valide
- Une page complètement vierge, indiquant qu'il n'y a pas de fichier robots.txt réel
- Une erreur 404
Si vous consultez votre site et obtenez l'un des deux seconds résultats, vous souhaiterez créer un fichier robots.txt pour aider les moteurs de recherche à mieux comprendre où ils doivent concentrer leurs efforts.
Comment créer un fichier Robots.txt
Un fichier robots.txt comprend certaines commandes que les robots des moteurs de recherche peuvent lire et suivre. Voici quelques-uns des termes que vous utiliserez lorsque vous créerez un fichier robots.txt.
Termes Robots.txt courants à connaître
User-Agent : Un user-agent est tout logiciel chargé de récupérer et de présenter du contenu Web aux utilisateurs finaux. Alors que les navigateurs Web, les lecteurs multimédias et les plug-ins peuvent tous être considérés comme des exemples d'agents utilisateurs, dans le contexte des fichiers robot.txt, un agent utilisateur est un moteur de recherche ou une araignée (comme Googlebot) qui explore et indexe votre site web.
Autoriser : lorsqu'elle est contenue dans un fichier robots.txt, cette commande permet aux agents utilisateurs d'explorer toutes les pages qui la suivent. Par exemple, si la commande indique "Autoriser : /", cela signifie que tout robot d'exploration Web peut accéder à n'importe quelle page qui suit la barre oblique dans "http://www.example.com/". Vous n'avez pas besoin de l'ajouter pour tout ce que vous voulez explorer, car tout ce qui n'est pas interdit par le fichier robots.txt est implicitement autorisé. Utilisez-le plutôt pour autoriser l'accès à un sous-répertoire qui se trouve dans un chemin non autorisé. Par exemple, les sites WordPress ont souvent une directive d'interdiction pour le dossier /wp-admin/, ce qui les oblige à ajouter une directive d'autorisation pour permettre aux robots d'atteindre /wp-admin/admin-ajax.php sans atteindre quoi que ce soit d'autre dans le dossier. dossier principal.
Interdire : cette commande interdit à des agents utilisateurs spécifiques d'explorer les pages qui suivent le dossier spécifié. Par exemple, si la commande indique « Disallow: /blog/ », cela signifie que l'agent utilisateur ne peut explorer aucune URL contenant le sous-répertoire /blog/, ce qui exclurait tout le blog de la recherche. Vous ne voudriez probablement jamais faire cela, mais vous le pourriez. C'est pourquoi il est très important de prendre en compte les implications de l'utilisation de la directive disallow chaque fois que vous envisagez d'apporter des modifications à votre fichier robots.txt.
Crawl-delay : bien que cette commande soit considérée comme non officielle, elle est conçue pour empêcher les robots d'exploration Web de submerger potentiellement les serveurs de requêtes. Il est généralement mis en œuvre sur des sites Web où un trop grand nombre de requêtes peut entraîner des problèmes de serveur. Certains moteurs de recherche le supportent, mais pas Google. Vous pouvez ajuster la vitesse d'exploration de Google en ouvrant la console de recherche Google, en accédant à la page Paramètres de vitesse d'exploration de votre propriété et en y ajustant le curseur. Cela ne fonctionne que si Google pense que ce n'est pas optimal. Si vous pensez qu'il n'est pas optimal et que Google n'est pas d'accord, vous devrez peut-être faire une demande spéciale pour le faire ajuster. En effet, Google préfère que vous leur permettiez d'optimiser le taux d'exploration de votre site Web.

Sitemap XML : cette directive fait exactement ce que vous imaginez : indiquer aux robots d'exploration Web où se trouve votre sitemap XML. Il devrait ressembler à : "Sitemap : http://www.example.com/sitemap.xml". Vous pouvez en savoir plus sur les meilleures pratiques de sitemap ici.
Instructions pas à pas pour créer Robots.txt
Pour créer votre propre fichier robots.txt, vous aurez besoin d'accéder à un simple éditeur de texte tel que le Bloc-notes ou TextEdit. Il est important de ne pas utiliser de traitement de texte, car ceux-ci enregistrent généralement les fichiers sous des formes propriétaires et peuvent ajouter des caractères spéciaux au fichier.
Par souci de simplicité, nous utiliserons "www.example.com".
Nous allons commencer par définir les paramètres de l'agent utilisateur. Sur la première ligne, tapez :
Agent utilisateur: *
L'astérisque signifie que tous les robots d'indexation sont autorisés à visiter votre site Web.
Certains sites Web utiliseront une directive allow pour indiquer que les bots sont autorisés à explorer, mais cela n'est pas nécessaire. Toutes les parties du site que vous n'avez pas interdites sont implicitement autorisées.
Ensuite, nous entrerons le paramètre d'interdiction. Appuyez deux fois sur "retour" pour insérer une pause après la ligne de l'agent utilisateur, puis tapez :
Interdire : /
Étant donné que nous n'entrons aucune commande après cela, cela signifie que les robots d'exploration Web peuvent visiter chaque page de votre site.
Si vous souhaitez bloquer l'accès à certains contenus, vous pouvez ajouter le répertoire après la commande Disallow. Notre fichier robots.txt contient les deux commandes d'interdiction suivantes :
Interdire : /wp/wp-admin/
Interdire : /*?*
Le premier garantit que nos pages d'administration WordPress (où nous éditons des choses comme cet article) ne sont pas explorées. Ce sont des pages que nous ne voudrions pas classer dans la recherche, et ce serait également une perte de temps pour Google d'essayer de les explorer car elles sont protégées par un mot de passe. La seconde empêche les URL contenant un point d'interrogation, comme les pages de résultats de recherche de blog, d'être explorées.
Une fois que vous avez terminé vos commandes, créez un lien vers votre sitemap. Bien que cette étape ne soit pas techniquement requise, il s'agit d'une bonne pratique recommandée car elle dirige les robots d'indexation vers les pages les plus importantes de votre site et rend l'architecture de votre site claire. Après avoir inséré un autre saut de ligne, tapez :
Plan du site : http://www.example.com/sitemap.xml
Votre développeur Web peut maintenant télécharger votre fichier sur votre site Web.
Créer un fichier Robots.txt dans WordPress
Si vous avez un accès administrateur à votre WordPress, vous pouvez modifier votre fichier robots.txt avec le plugin Yoast SEO ou AIOSEO. Alternativement, votre développeur Web peut utiliser un client FTP ou SFTP pour se connecter à votre site WordPress et accéder au répertoire racine.
Ne déplacez pas le fichier robots.txt ailleurs que dans le répertoire racine. Bien que certaines sources suggèrent de le placer dans un sous-répertoire ou un sous-domaine, idéalement, il devrait résider sur votre domaine racine : www.example.com/robots.txt.
Comment tester votre fichier Robots.txt
Maintenant que vous avez créé un fichier robots.txt, il est temps de le tester. Heureusement, Google facilite les choses en fournissant un testeur robots.txt dans le cadre de Google Search Console.
Après avoir ouvert le testeur pour votre site, vous verrez tous les avertissements de syntaxe et les erreurs de logique mis en surbrillance.
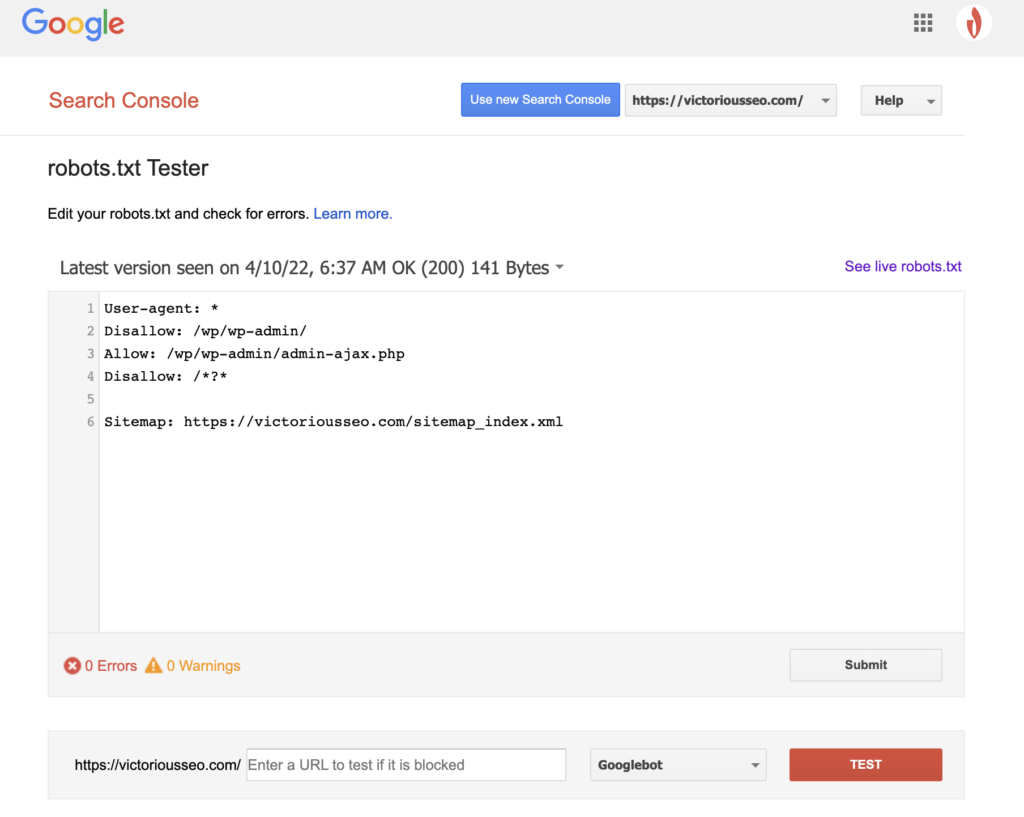
Pour tester comment un Googlebot particulier "voit" votre page, entrez une URL de votre site dans la zone de texte en bas de la page, puis choisissez parmi les différents Googlebots dans le menu déroulant à droite. Appuyer sur "TEST" simulera le comportement du bot que vous avez sélectionné et montrera si des directives empêchent Googlebot d'accéder à la page.

Les lacunes de Robots.txt
Les fichiers robots.txt sont très utiles, mais ils ont leurs limites.
Les fichiers robots.txt ne doivent pas être utilisés pour protéger ou masquer des parties de votre site Web (cela pourrait enfreindre la loi sur la protection des données). Vous vous souvenez quand je vous ai suggéré de rechercher votre propre fichier robots.txt ? Cela signifie que tout le monde peut y accéder, pas seulement vous. S'il y a des informations que vous devez protéger, la meilleure approche consiste à protéger par mot de passe des pages ou des documents spécifiques.
De plus, vos directives de fichier robots.txt sont simplement des requêtes. Vous pouvez vous attendre à ce que Googlebot et d'autres robots d'exploration légitimes obéissent à vos directives, mais d'autres robots peuvent simplement les ignorer.
Enfin, même si vous demandez aux robots de ne pas indexer des URL spécifiques, ils ne sont pas invisibles. D'autres sites Web peuvent être liés à ceux-ci. Si vous ne souhaitez pas que certaines informations de votre site Web soient accessibles au public, vous devez les protéger par mot de passe. Si vous voulez vous assurer qu'il ne sera pas indexé, envisagez d'inclure une balise noindex sur la page.
En savoir plus sur le référencement technique : téléchargez notre liste de contrôle
Vous voulez en savoir plus sur le référencement, y compris des instructions étape par étape sur la façon de prendre en main le référencement de votre site Web ? Téléchargez notre liste de contrôle SEO 2022 pour obtenir une liste complète de choses à faire, y compris des ressources précieuses qui vous aideront à améliorer votre classement de recherche et à générer plus de trafic organique vers votre site Web.

Liste de contrôle et outils de planification SEO
Êtes-vous prêt à bouger l'aiguille sur votre référencement ? Obtenez la liste de contrôle interactive et les outils de planification et lancez-vous !