
So erstellen Sie eine Robots.txt-Datei (und warum müssen Sie das tun)
Veröffentlicht: 2022-06-07Es kann schwierig sein, Leuten SEO zu erklären, weil es viele kleine Schritte gibt, die auf den ersten Blick nicht sehr wichtig erscheinen, aber wenn sie richtig gemacht werden, summieren sie sich zu großen Gewinnen in den Suchrankings.
Ein wichtiger Schritt, der leicht übersehen wird, besteht darin, den Crawlern von Suchmaschinen mitzuteilen, welche Seiten indexiert werden sollen – und welche nicht. Sie können dies mit einer robots.txt-Datei tun.
Im heutigen Beitrag werde ich genau erklären, wie man eine robots.txt-Datei erstellt, damit Sie diesen grundlegenden Teil Ihrer Website in Ordnung bringen und sicherstellen können, dass Crawler mit Ihrer Website so interagieren, wie Sie es möchten.
Was ist eine robots.txt-Datei?
Die robots.txt-Datei ist eine einfache Anweisung, die Suchmaschinen-Crawlern mitteilt, welche Seiten Ihrer Website gecrawlt und indexiert werden sollen.
Es ist Teil des Robots Exclusion Protocol (REP), einer Familie von Standardverfahren, die regeln, wie Suchmaschinen-Roboter das Web durchsuchen, Website-Inhalte bewerten und indizieren und diese Inhalte dann den Benutzern bereitstellen. Diese Datei gibt an, wo Crawler kriechen dürfen und wo nicht. Es kann auch Informationen enthalten, die Crawlern helfen könnten, die Website effizienter zu crawlen.
Der REP enthält auch „Meta-Roboter-Tags“, das sind Anweisungen, die im HTML einer Seite enthalten sind und spezifische Anweisungen dazu enthalten, wie Webcrawler bestimmte Webseiten und die darin enthaltenen Bilder oder Dateien crawlen und indizieren sollen.
Was ist der Unterschied zwischen Robots.txt und Meta Robots Tag?
Wie ich bereits erwähnt habe, enthält das Robots-Ausschlussprotokoll auch „Meta-Roboter-Tags“, bei denen es sich um Codeteile handelt, die im HTML einer Seite enthalten sind. Sie unterscheiden sich von robots.txt-Dateien darin, dass sie Webcrawlern auf bestimmten Webseiten Anweisungen geben und den Zugriff entweder auf die vollständige Seite oder auf bestimmte auf der Seite enthaltene Dateien wie Fotos und Videos verbieten.
Im Gegensatz dazu sollen robots.txt-Dateien verhindern, dass ganze Segmente einer Website indexiert werden, beispielsweise ein Unterverzeichnis, das nur für den internen Gebrauch bestimmt ist. Eine robots.txt-Datei befindet sich auf der Root-Domain Ihrer Website und nicht auf einer bestimmten Seite, und die Anweisungen sind so strukturiert, dass sie alle Seiten betreffen, die in den Verzeichnissen oder Unterverzeichnissen enthalten sind, auf die sie verweisen.
Warum brauche ich eine Robots.txt-Datei?
Die robots.txt-Datei ist eine täuschend einfache Textdatei von großer Bedeutung. Ohne sie indizieren Webcrawler einfach jede einzelne Seite, die sie finden.
Warum ist das wichtig?
Zunächst einmal kostet das Crawlen einer ganzen Website Zeit und Ressourcen. All das kostet Geld, daher begrenzt Google, wie viel eine Website gecrawlt wird, insbesondere wenn diese Website sehr groß ist. Dies wird als „Crawl-Budget“ bezeichnet. Das Crawling-Budget wird durch mehrere technische Faktoren begrenzt, darunter die Antwortzeit, URLs mit geringem Wert und die Anzahl der aufgetretenen Fehler.
Außerdem, wenn Sie Suchmaschinen uneingeschränkten Zugriff auf alle Ihre Seiten erlauben und ihre Crawler sie indizieren lassen, kann es sein, dass Sie am Ende einen aufgeblähten Index haben. Dies bedeutet, dass Google unwichtige Seiten einstufen kann, die Sie nicht in den Suchergebnissen erscheinen lassen möchten. Diese Ergebnisse könnten Besuchern ein schlechtes Erlebnis bereiten, und sie könnten sogar mit Seiten konkurrieren, für die Sie einen Rang einnehmen möchten.
Wenn Sie Ihrer Website eine robots.txt-Datei hinzufügen oder Ihre vorhandene Datei aktualisieren, können Sie die Verschwendung von Crawl-Budget reduzieren und das Aufblähen des Index begrenzen.
Literatur-Empfehlungen
- Technischer SEO-Leitfaden: Was ist Tech-SEO?
- Was ist Indexaufblähung? (Und wie man es repariert)
Wo finde ich meine Robots.txt-Datei?
Es gibt eine einfache Methode, um festzustellen, ob Ihre Website über eine robots.txt-Datei verfügt: Suchen Sie im Internet danach.
Geben Sie einfach die URL einer beliebigen Website ein und fügen Sie am Ende „/robots.txt“ hinzu. Zum Beispiel: victoriousseo.com/robots.txt zeigt Ihnen unsere.
Probieren Sie es selbst aus, indem Sie Ihre Website-URL eingeben und am Ende „/robots.txt“ hinzufügen. Sie sollten eines von drei Dingen sehen:
- Ein paar Textzeilen, die auf eine gültige robots.txt-Datei hinweisen
- Eine völlig leere Seite, die darauf hinweist, dass es keine eigentliche robots.txt-Datei gibt
- Ein 404-Fehler
Wenn Sie Ihre Website überprüfen und eines der beiden zweiten Ergebnisse erhalten, sollten Sie eine robots.txt-Datei erstellen, damit Suchmaschinen besser verstehen, worauf sie ihre Bemühungen konzentrieren sollten.
So erstellen Sie eine Robots.txt-Datei
Eine robots.txt-Datei enthält bestimmte Befehle, die Suchmaschinen-Roboter lesen und befolgen können. Hier sind einige der Begriffe, die Sie verwenden werden, wenn Sie eine robots.txt-Datei erstellen.
Allgemeine Robots.txt-Begriffe, die Sie kennen sollten
User-Agent : Ein User-Agent ist eine beliebige Software, die mit dem Abrufen und Präsentieren von Webinhalten für Endbenutzer beauftragt ist. Während Webbrowser, Mediaplayer und Plug-Ins alle als Beispiele für User-Agents angesehen werden können, ist ein User-Agent im Zusammenhang mit robot.txt-Dateien ein Suchmaschinen-Crawler oder -Spider (wie Googlebot), der crawlt und indexiert deine Website.
Zulassen: Wenn dieser Befehl in einer robots.txt-Datei enthalten ist, erlaubt er Benutzeragenten, alle darauf folgenden Seiten zu crawlen. Wenn der Befehl beispielsweise „Allow: /“ lautet, bedeutet dies, dass jeder Webcrawler auf jede Seite zugreifen kann, die auf den Schrägstrich in „http://www.example.com/“ folgt. Sie müssen dies nicht für alles hinzufügen, was gecrawlt werden soll, da alles, was nicht durch die robots.txt verboten ist, implizit erlaubt ist. Verwenden Sie es stattdessen, um den Zugriff auf ein Unterverzeichnis zuzulassen, das sich in einem unzulässigen Pfad befindet. Zum Beispiel haben WordPress-Sites oft eine disallow-Anweisung für den Ordner /wp-admin/, was wiederum erfordert, dass sie eine allow-Anweisung hinzufügen, damit Crawler /wp-admin/admin-ajax.php erreichen können, ohne irgendetwas anderes im Ordner zu erreichen Hauptordner.
Disallow: Dieser Befehl verbietet bestimmten User-Agents das Crawlen der Seiten, die auf den angegebenen Ordner folgen. Wenn der Befehl beispielsweise „Disallow: /blog/“ lautet, bedeutet dies, dass der Benutzeragent keine URLs crawlen darf, die das Unterverzeichnis /blog/ enthalten, wodurch der gesamte Blog von der Suche ausgeschlossen würde. Das würdest du wahrscheinlich nie wollen, aber du könntest. Aus diesem Grund ist es sehr wichtig, die Auswirkungen der Verwendung der disallow-Direktive zu berücksichtigen, wenn Sie daran denken, Änderungen an Ihrer robots.txt-Datei vorzunehmen.
Crawl-Verzögerung: Obwohl dieser Befehl als inoffiziell gilt, soll er Web-Crawler davon abhalten, Server möglicherweise mit Anfragen zu überfordern. Es wird normalerweise auf Websites implementiert, auf denen zu viele Anfragen Serverprobleme verursachen könnten. Einige Suchmaschinen unterstützen dies, Google jedoch nicht. Sie können die Crawling-Rate für Google anpassen, indem Sie die Google Search Console öffnen, zur Seite Crawling-Rate-Einstellungen Ihrer Property navigieren und dort den Schieberegler anpassen. Das funktioniert nur, wenn Google es für nicht optimal hält. Wenn Sie der Meinung sind, dass es suboptimal ist und Google anderer Meinung ist, müssen Sie möglicherweise eine spezielle Anfrage stellen, um es anzupassen. Das liegt daran, dass Google es vorzieht, dass Sie ihnen erlauben, die Crawling-Rate für Ihre Website zu optimieren.

XML-Sitemap: Diese Direktive macht genau das, was Sie vermuten: Sie teilt Webcrawlern mit, wo sich Ihre XML-Sitemap befindet. Es sollte in etwa so aussehen: „Sitemap: http://www.example.com/sitemap.xml.“ Hier erfahren Sie mehr über Best Practices für Sitemaps.
Schritt-für-Schritt-Anleitung zum Erstellen von Robots.txt
Um Ihre eigene robots.txt-Datei zu erstellen, benötigen Sie Zugriff auf einen einfachen Texteditor wie Notepad oder TextEdit. Es ist wichtig, kein Textverarbeitungsprogramm zu verwenden, da diese Dateien normalerweise in proprietären Formaten speichern und der Datei möglicherweise Sonderzeichen hinzufügen.
Der Einfachheit halber verwenden wir „www.example.com“.
Wir beginnen mit dem Festlegen der User-Agent-Parameter. Geben Sie in der ersten Zeile Folgendes ein:
User-Agent: *
Das Sternchen bedeutet, dass alle Webcrawler Ihre Website besuchen dürfen.
Einige Websites verwenden eine Allow-Direktive, um zu sagen, dass Bots crawlen dürfen, aber das ist unnötig. Alle Teile der Website, die Sie nicht verboten haben, sind implizit erlaubt.
Als Nächstes geben wir den Disallow-Parameter ein. Drücken Sie zweimal „Return“, um nach der User-Agent-Zeile einen Umbruch einzufügen, und geben Sie dann Folgendes ein:
Nicht zulassen: /
Da wir danach keine Befehle eingeben, bedeutet dies, dass Webcrawler jede Seite Ihrer Website besuchen können.
Wenn Sie den Zugriff auf bestimmte Inhalte blockieren möchten, können Sie das Verzeichnis nach dem disallow-Befehl hinzufügen. Unsere robots.txt-Datei enthält die folgenden zwei Disallow-Befehle:
Nicht zulassen: /wp/wp-admin/
Nicht zulassen: /*?*
Die erste stellt sicher, dass unsere WordPress-Admin-Seiten (auf denen wir Dinge wie diesen Artikel bearbeiten) nicht gecrawlt werden. Dies sind Seiten, die wir nicht in der Suche platzieren möchten, und es wäre auch Zeitverschwendung, zu versuchen, sie zu crawlen, da sie passwortgeschützt sind. Die zweite verhindert, dass URLs gecrawlt werden, die ein Fragezeichen enthalten, z. B. Blog-Suchergebnisseiten.
Wenn Sie Ihre Befehle ausgeführt haben, verlinken Sie zu Ihrer Sitemap. Obwohl dieser Schritt technisch nicht erforderlich ist, wird er als bewährte Vorgehensweise empfohlen, da er Webspider auf die wichtigsten Seiten Ihrer Website verweist und die Architektur Ihrer Website klar macht. Geben Sie nach dem Einfügen eines weiteren Zeilenumbruchs Folgendes ein:
Sitemap: http://www.example.com/sitemap.xml
Jetzt kann Ihr Webentwickler Ihre Datei auf Ihre Website hochladen.
Erstellen einer Robots.txt-Datei in WordPress
Wenn Sie Administratorzugriff auf Ihr WordPress haben, können Sie Ihre robots.txt-Datei mit dem Yoast SEO Plugin oder AIOSEO ändern. Alternativ kann Ihr Webentwickler einen FTP- oder SFTP-Client verwenden, um eine Verbindung zu Ihrer WordPress-Site herzustellen und auf das Stammverzeichnis zuzugreifen.
Verschieben Sie die robots.txt-Datei nur in das Stammverzeichnis. Während einige Quellen vorschlagen, es in einem Unterverzeichnis oder einer Subdomain zu platzieren, sollte es idealerweise auf Ihrer Root-Domain liegen: www.example.com/robots.txt.
So testen Sie Ihre Robots.txt-Datei
Nachdem Sie nun eine robots.txt-Datei erstellt haben, ist es an der Zeit, sie zu testen. Glücklicherweise macht es Google einfach, indem es einen robots.txt-Tester als Teil der Google Search Console bereitstellt.
Nachdem Sie den Tester für Ihre Website geöffnet haben, werden alle Syntaxwarnungen und Logikfehler hervorgehoben angezeigt.
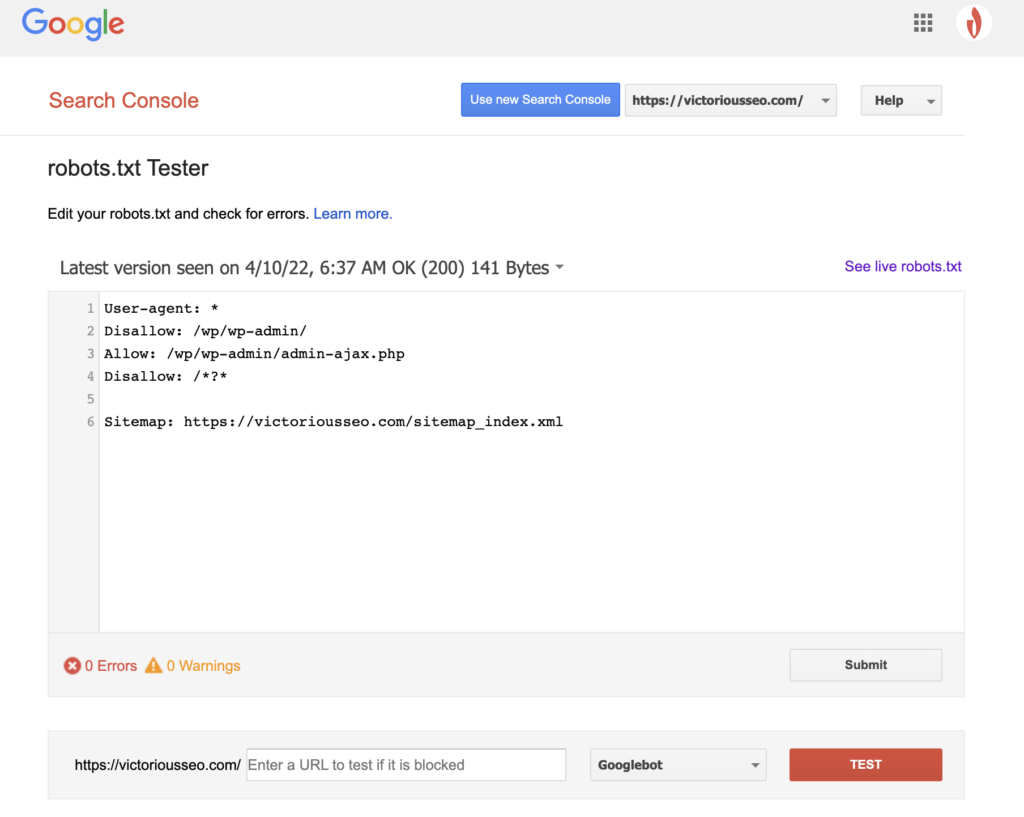
Um zu testen, wie ein bestimmter Googlebot Ihre Seite „sieht“, geben Sie eine URL von Ihrer Website in das Textfeld unten auf der Seite ein und wählen Sie dann im Dropdown-Menü rechts einen der verschiedenen Googlebots aus. Wenn Sie auf „TEST“ klicken, wird das Verhalten des von Ihnen ausgewählten Bots simuliert und angezeigt, ob irgendwelche Anweisungen den Googlebot daran hindern, auf die Seite zuzugreifen.

Die Mängel von robots.txt
Robots.txt-Dateien sind sehr nützlich, aber sie haben ihre Grenzen.
Robots.txt-Dateien sollten nicht verwendet werden, um Teile Ihrer Website zu schützen oder zu verbergen (dies könnte gegen das Datenschutzgesetz verstoßen). Erinnerst du dich, als ich dir vorgeschlagen habe, nach deiner eigenen robots.txt-Datei zu suchen? Das bedeutet, dass jeder darauf zugreifen kann, nicht nur Sie. Wenn Sie Informationen schützen müssen, ist es am besten, bestimmte Seiten oder Dokumente mit einem Kennwort zu schützen.
Darüber hinaus sind Ihre Anweisungen in der robots.txt-Datei einfach Anfragen. Sie können davon ausgehen, dass der Googlebot und andere legitime Crawler Ihre Anweisungen befolgen, aber andere Bots ignorieren sie möglicherweise einfach.
Selbst wenn Sie Crawler anfordern, bestimmte URLs nicht zu indizieren, sind diese schließlich nicht unsichtbar. Andere Websites können auf sie verlinken. Wenn Sie nicht möchten, dass bestimmte Informationen auf Ihrer Website öffentlich zugänglich sind, sollten Sie sie mit einem Passwort schützen. Wenn Sie sicherstellen möchten, dass sie nicht indexiert wird, ziehen Sie in Erwägung, ein noindex-Tag auf der Seite einzufügen.
Erfahren Sie mehr über technisches SEO: Laden Sie unsere Checkliste herunter
Möchten Sie mehr über SEO erfahren, einschließlich Schritt-für-Schritt-Anleitungen, wie Sie die SEO Ihrer Website selbst in die Hand nehmen können? Laden Sie unsere SEO-Checkliste 2022 herunter, um eine umfassende To-do-Liste zu erhalten, einschließlich wertvoller Ressourcen, die Ihnen helfen, Ihre Suchrankings zu verbessern und mehr organischen Traffic auf Ihre Website zu lenken.

SEO-Checkliste und Planungstools
Sind Sie bereit, die Nadel in Ihrem SEO zu bewegen? Holen Sie sich die interaktive Checkliste und Planungstools und legen Sie los!