
エンティティ属性の関係の識別
公開: 2022-03-022022年3月1日に付与されたこの特許は、本文中のエンティティと属性の関係を特定することを目的としています。
検索エンジンやナレッジベースなどの検索アプリケーションは、検索者の情報ニーズを満たし、検索者に最も有利なリソースを表示しようとします。
構造化データは、属性の関係をより適切に識別するのに役立つ場合があります
属性エンティティの関係の識別は、構造化された検索結果で行われます。
構造化された検索結果には、クエリなどのユーザーリクエストで指定されたエンティティに対する回答を含む属性のリストが表示されます。
したがって、「Kevin Durant」の構造化された検索結果には、給与、チーム、生年月日、家族などの属性と、これらの属性に関する情報を提供する回答が含まれる場合があります。
このような構造化された検索結果を作成するには、エンティティと属性の関係を特定する必要があります。
エンティティ属性関係は、用語のペア間のテキスト関係の特定のケースです。
用語のペアの最初の用語は、エンティティ、人、場所、組織、または概念です。
2番目の用語は、エンティティの側面を説明する属性または文字列です。
例は次のとおりです。
- 人の「生年月日」
- 国の「人口」
- アスリートの「給料」
- 組織の「CEO」
エンティティに関するコンテンツとスキーマ(および構造化データ)でより多くの情報を提供することで、検索エンジンは特定のエンティティに関するより良い情報を探索し、データをテストおよび収集し、知っていることを明確にし、エンティティについてより多くの信頼を得ることができます。認識しています。
エンティティと属性の候補のペア
この特許は、エンティティと属性を定義するためのエンティティと属性の候補ペアを取得します。ここで、属性はエンティティの候補属性です。 構造化データ内のエンティティに関する事実から学習することに加えて、Googleはその情報のコンテキストを調べて情報を使用し、それらのエンティティに関する他の単語や事実のベクトルや共起からも学習できます。
単語ベクトルの特許を見て、検索エンジンが単語の意味と文脈、およびエンティティに関する情報をよりよく理解する方法を理解してください。 (これは、Googleが現在行っていることのいくつかをどのように行っているかについて、特許調査から学ぶチャンスです。)Googleは、インデックスを作成することに関する事実とデータを収集し、インデックスに含まれるエンティティについて学習する場合があります。それがそれらについて知っている属性。
これは次の場所で行われます。
- エンティティと属性を含む文を使用して、属性がエンティティと属性の候補ペア内のエンティティの実際の属性であるかどうかを判断します。
- エンティティと属性を含む一連の文の単語の埋め込みを生成する
- 既知のエンティティと属性のペアを使用して、エンティティの分散属性の埋め込みを作成します。エンティティの分散属性の埋め込みは、既知のエンティティと属性のペアからエンティティに関連付けられている他の属性に基づいて、エンティティの埋め込みを指定します。
- 文中の単語の埋め込み、エンティティの分布属性の埋め込み、および属性の場合、エンティティと属性の候補ペアがエンティティと属性の候補ペアのエンティティの必須属性であるかどうかに基づいています。
単語の埋め込みは、エンティティと属性を含む文で構成されます
文のセット内のエンティティとポイントの間の単語の最初の埋め込みを指定する最初のベクトル表現を構築する
- 文のセットに基づいてエンティティの二重埋め込みを定義する2番目のベクトル表現を作成する
- 文のセットに基づいて、属性の3番目の埋め込みの3番目のベクトル表現を構築する
- ピッキングは、既知のエンティティ属性を使用して、エンティティの分布属性の埋め込みを組み合わせます。つまり、使用可能なエンティティと属性のペアを使用して、エンティティの分布属性の埋め込みを指定し、4番目のベクトル表現を作成します。
- これらの既知のエンティティ属性ペアを使用して分散属性埋め込みを構築することは、使用可能なエンティティ属性チームと属性の分散属性埋め込みを使用して5番目のベクトル表現を開発することを意味します。
- 文のセット内の単語の埋め込み、エンティティの分布属性の埋め込み、および属性の分布属性の埋め込みに基づいて、エンティティと属性の候補ペアの属性がエンティティの必須属性であるかどうかを判断します。エンティティと属性の候補ペア
- 第1のベクトル表現、第2のベクトル表現、第3のベクトル表現、第4のベクトル表現、および第5のベクトル表現に基づいて、エンティティと属性の候補ペアの属性がエンティティのエンティティの必須属性であるかどうかを判断します。 -属性候補ペア
- 第1のベクトル表現、第2のベクトル表現、第3のベクトル表現、第4のベクトル表現、および第5のベクトル表現から、エンティティと属性の候補ペアの属性がエンティティのエンティティの必須属性であるかどうかを選択します。属性候補ペア、フィードフォワードネットワークを使用して実行されます。
- 第1のベクトル表現、第2のベクトル表現、第3のベクトル表現、第4のベクトル表現、および第5のベクトル表現に基づいて、エンティティと属性の候補ペアの属性がエンティティのエンティティの必須属性であるかどうかを選択します。 -属性候補ペア、構成:
- 第1のベクトル表現、第2のベクトル表現、第3のベクトル表現、第4のベクトル表現、および第5のベクトル表現を連結することによって単一のベクトル表現を生成する。 フィードフォワードネットワークへの単一ベクトル表現の入力
- フィードフォワードネットワークによって、単一のベクトル表現を使用して、エンティティと属性の候補ペアの属性が、エンティティと属性の候補ペアのエンティティの必須属性であるかどうかを判断します。
既知のエンティティと属性のペアを使用して、エンティティの分布属性の埋め込みを指定する4番目のベクトル表現を作成するには、次の要素が含まれます。
- 既知のエンティティ属性チーム内のエンティティに関連付けられている属性のセットを識別します。ここで、属性のセットは属性を省略します
- 属性のセット内の特性の加重和を計算することにより、エンティティの分布属性埋め込みを生成します
既知のエンティティと属性のペアを使用して、属性の分布属性の埋め込みを指定する5番目のベクトル表現を選択すると、次のようになります。
- 属性を使用して、既知のエンティティと属性のカップルの中からエンティティのセットを識別します。 エンティティのコレクション内のエンティティごとに
- 属性の場所に属性が含まれていない、エンティティに関連付けられた一連の機能の決定
- 属性のコレクション内の特性の加重和を計算することにより、エンティティの分布属性埋め込みを生成します
従来技術のモデルベースのエンティティ属性識別に対するより正確なエンティティ属性関係の利点
初期のアートエンティティ属性識別技術は、自然言語処理(NLP)機能、遠隔監視、およびデータ文に基づいてエンティティと属性を表すことによってエンティティ属性関係を識別する従来の機械学習モデルなどのモデルベースのアプローチを使用していました。 これらの用語が表示されます。
対照的に、この仕様で説明されているイノベーションは、エンティティと属性がこれらの用語が表示されるデータでどのように表現されるかに関する情報を使用し、関連付けられることがわかっている他の機能を使用してエンティティと属性を表すことにより、データセット内のエンティティと属性の関係を識別しますこれらの用語。 これにより、類似したエンティティによって共有される詳細でエンティティと属性を表すことができ、これらの用語が含まれる文を考慮することによって識別できないエンティティと属性の関係を識別する精度が向上します。
たとえば、データセットに「ロナウド」と「メッシ」の2つのエンティティがあり、「レコード」属性を使用して記述されている文と、エンティティ「メッシ」が「目標」を使用して記述されているペナルティが含まれているシナリオを考えてみます。属性。 そのようなシナリオでは、従来技術の技術は、以下のエンティティ属性ペアを識別することができる:(ロナウド、記録)、(メッシ、ログ)、および(メッシ、ゴール) 。 この仕様で説明されている革新は、これらの用語がデータセットでどのように使用されるかによって識別されない可能性のあるエンティティと属性の関係を識別することにより、これらの従来技術のアプローチを超えています。
上記の例を使用して、この仕様で説明されているイノベーションは、「Ronaldo」と「Messi」が「record」属性を共有し、「goals」属性を使用して「record」属性を表すため、類似したエンティティであると判断します。 このようにして、たとえば、この仕様で説明されているイノベーションにより、データセットからそのような関係を識別できない場合でも、エンティティと属性の関係(Cristiano、Goalsなど)を識別できるようになります。
属性関係の識別特許
エンティティ属性関係の識別
発明者:Dan Iter、Xiao Yu、Fangtao Li
譲受人:Google LLC
米国特許:11,263,400
付与:2022年3月1日
提出日:2019年7月5日
概要
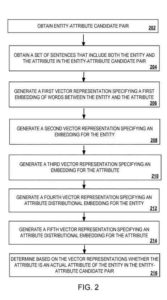
テキストコーパス内のエンティティと属性の関係を簡単に識別できる、コンピュータストレージメディアにエンコードされたコンピュータプログラムを含む、方法、システム、および装置。メソッドには、候補エンティティと属性のペアの属性が、エンティティと属性の候補ペアのエンティティの実際の属性であるかどうかを判断することが含まれます。これには、エンティティと属性を含む文のセット内の単語の埋め込みの生成と、既知のエンティティと属性のペアを使用した生成が含まれます。これには、既知のエンティティと属性のペアからエンティティに関連付けられた他の属性に基づいてエンティティの属性分散埋め込みを生成すること、および既知の属性の既知のエンティティに関連付けられた既知の属性に基づいて属性の属性分散埋め込みを生成することも含まれます。エンティティと属性のペア。これらの埋め込みに基づいて、フィードフォワードネットワークは、エンティティと属性の候補ペアの属性が、エンティティと属性の候補ペアのエンティティの実際の属性であるかどうかを判断します。
テキスト内のエンティティ属性の関係の識別
候補エンティティと属性のペア(属性はエンティティの候補属性)は、分類モデルに入力されます。 分類モデルは、パス埋め込みエンジン、分布表現エンジン、属性エンジン、およびフィードフォワードネットワークを使用します。 候補エンティティと属性のペアの属性が、候補エンティティと属性のペアの必須エンティティであるかどうかを判別します。
パス埋め込みエンジンは、データセットの一連の文(たとえば、30以上の文)内のエンティティと属性の日常的な出現を接続するパスまたは単語の埋め込みを表すベクトルを生成します。 分布表現エンジンは、エンティティの埋め込みを表すベクトルを生成し、これらの用語が文のセットに現れるコンテキストに基づいて用語を属性付けます。 分散属性エンジンは、エンティティの埋め込みを表すベクトルと、属性の埋め込みを表す別のベクトルを生成します。
エンティティの属性分散エンジンの埋め込みは、データセット内のエンティティに関連付けられることがわかっている他の機能(つまり、候補属性以外の属性)に基づいて取得されます。 品質に対する詳細な分散エンジンの埋め込みは、候補属性の既知のエンティティに関連付けられたさまざまな機能に基づいています。
分類モデルは、p ath埋め込みエンジン、分布表現エンジン、および分布属性エンジンからのベクトル表現を単一のベクトル表現に連結します。 次に、分類モデルは、単一のベクトル表現をフィードフォワードネットワークに入力します。フィードフォワードネットワークは、単一のベクトル表現を使用して、候補のエンティティと属性のペアの属性が候補のエンティティと属性のペアのエンティティの必須属性であるかどうかを判断します。
フィードフォワードネットワークが、候補エンティティ属性ペアのポイントが候補エンティティ属性ペアのエンティティに必要であると判断したとします。 その場合、候補のエンティティと属性のペアは、他の既知の/実際のエンティティと属性のペアとともにナレッジベースに保存されます。
エンティティ属性関係の抽出
この環境には、ナレッジベース内の候補エンティティと属性のペアについて、候補エンティティと属性のペアの属性が候補ペアのエンティティの必須属性であるかどうかを判断する分類モデルが含まれています。 分類モデルはニューラルネットワークモデルであり、コンポーネントについて以下に説明します。 分類モデルは、他の教師なしおよび教師なし機械学習モデルを使用して使用することもできます。
非一時的なデータストレージメディア(たとえば、ハードドライブ、フラッシュメモリなど)に格納されたデータベース(または他の適切なデータストレージ構造)を含むことができるナレッジベースは、候補エンティティと属性のペアのセットを保持します。 候補となるエンティティと属性のペアは、データソースから取得したWebページやニュース記事などのテキストドキュメントのコンテンツのセットを使用して取得されます。 データソースには、ニュースWebサイト、データアグリゲータープラットフォーム、ソーシャルメディアプラットフォームなど、あらゆるコンテンツソースを含めることができます。
データソースは、データアグリゲータープラットフォームからニュース記事を取得します。 データソースはモデルを使用できます。 教師なしまたは教師なし機械学習モデル(自然言語処理モデル)は、品詞を使用して、記事から文を抽出し、抽出された文をエンティティや属性としてトークン化してラベル付けすることにより、エンティティと属性のペアの候補のセットを生成しますおよび依存関係はツリータグを解析します。
データソースは、抽出された文を機械学習モデルに入力できます。 たとえば、一連のトレーニングセンテンスとそれに関連するエンティティと属性のペアを使用してトレーニングを受けることができます。 このような機械学習モデルは、入力された抽出された文の候補エンティティ属性チームを出力できます。
ナレッジベースでは、データソースは、候補エンティティと属性のペア、および候補エンティティと属性のペアの単語を含むデータソースによって抽出された文を格納します。 候補エンティティと属性のペアは、エンティティと属性が存在する文の数がしきい値の文数(たとえば、30文)を満たす(たとえば、満たす、または超える)場合にのみ、ナレッジベースに格納されます。
分類モデルは、(ナレッジベースに格納されている)候補エンティティ-属性ペアの属性が、候補エンティティ-属性ペアのエンティティの実際の属性であるかどうかを判別します。 分類モデルは、パス埋め込みエンジン106、分布表現ソース、属性エンジン、およびフィードフォワードネットワークを含む。 本明細書で使用される場合、エンジンという用語は、一連のタスクを実行するデータ処理装置を指す。 候補エンティティと属性のペアの属性がエンティティの必須属性であるかどうかを判断する際の、分類モデルのこれらのエンジンの操作。
エンティティ属性の関係を識別するためのプロセス例
プロセスの操作は、システムのコンポーネントによって実行されるものとして以下に説明されており、プロセスの機能は、説明のみを目的として以下に説明されています。 プロセスの操作は、任意の適切なデバイスまたはシステム、例えば、任意の適用可能なデータ処理装置によって達成することができる。 プロセスの機能は、一時的ではないコンピューター可読媒体に保存された命令として実装することもできます。 命令の実行により、データ処理装置はプロセスの操作を実行する。
ナレッジベースは、データソースからエンティティと属性の候補ペアを取得します。
ナレッジベースは、エンティティの単語と候補エンティティと属性のペアの属性を含む一連の文をデータソースから取得します。
文のセットと候補エンティティと属性のペアに基づいて、分類モデルは、候補属性が候補エンティティの実際の属性であるかどうかを判断します。 ペナルティのセットは、多数の文、たとえば30以上の文である可能性があります。
次の操作を実行する分類モデル
- エンティティと属性を含む一連の文の単語の埋め込みについては、以下のプロセスに関して以下で詳しく説明します。
- 既知のエンティティと属性のペアを使用して作成されます。これは、エンティティに埋め込まれた分布属性であり、操作に関して以下で詳しく説明します。
- 既知のエンティティと属性のペアを使用して構築し、属性に分散属性を埋め込みます。これについては、操作に関して以下で詳しく説明します。
- 文のセット内の単語の埋め込み、エンティティの分布属性の埋め込み、および属性の分布属性の埋め込みに基づいて、エンティティと属性の候補ペアの属性がエンティティの必須属性であるかどうかを選択します。エンティティと属性の候補のペア。これについては、操作に関して以下で詳しく説明します。
パス埋め込みエンジンは、文のエンティティと属性の間に埋め込まれる最初の単語を指定する最初のベクトル表現を生成します。 パス埋め込みエンジンは、一連の文にこれらの用語の日常的な出現を接続するパスまたは単語を埋め込むことにより、候補エンティティ属性用語間の関係を検出します。
「ヘビは爬虫類です」というフレーズの場合、パス埋め込みエンジンはトラック「is a」の埋め込みを生成します。これは、たとえば属と種の関係を検出するために使用でき、他のエンティティ属性の識別に使用できます。ペア。
エンティティと属性の間の単語の生成
パス埋め込みエンジンは、エンティティと文の属性の間に単語を生成するために次のことを行います。 一連の文の各文について、パス埋め込みエンジンは最初に、エンティティと属性の間の依存関係パス(単語のグループを指定する)を抽出します。 パス埋め込みエンジンは、文を文字列からリストに変換します。最初の用語はエンティティであり、最後の用語は属性です(または、最初の用語が属性で、前の用語がエンティティです) 。
依存関係パスの各用語(エッジとも呼ばれる)は、次の機能を使用して表されます:用語の補題、品詞タグ、依存関係ラベル、および依存関係パスの方向(左、右またはルート) 。 これらの機能のそれぞれが埋め込まれ、連結されて、一連のベクトル(V 1、V pos、V dep)を含む用語またはエッジ(V e)のベクトル表現が生成されます。 、V dir)、次の式で示されます。{右矢印(v)} e = [{右矢印(v)} l、{右矢印(v)} pos、{右矢印(v)} dep、{右矢印(v)} dir]
次に、パス埋め込みエンジンは、各パスの項またはエッジのベクトルのシーケンスを長短期記憶(LSTM)ネットワークに入力します。これにより、次のように、文(V s)の単一のベクトル表現が生成されます。以下の式:{右矢印オーバー(v)} s = LSTM({右矢印オーバー(v)} e(1)..。 {右矢印オーバー(v)}。sub e(k))
最後に、パス埋め込みエンジンは、文のセット内のすべての文の単一のベクトル表現を注意メカニズムに入力します。これにより、次のように、文表現の加重平均(Vsents(e、a))が決定されます。以下の式:{右矢印(v)} sents(e、a)= ATTN({右矢印(v)} s(1)..。 {右矢印(v ) )} s(n))
分布表現モデルは、文に基づいて、エンティティの2番目のベクトル表現と属性の3番目のベクトル表現を生成します。 分布表現エンジンは、文のセット内でポイントと候補エンティティ属性ペアのエンティティが発生するコンテキストに基づいて、候補エンティティ属性用語間の関係を検出します。 たとえば、分布表現エンジンは、エンティティ「ニューヨーク」が米国の都市または州を参照していることを示唆する方法で、エンティティ「ニューヨーク」が文のコレクションで使用されることを決定する場合があります。
別の例として、分布表現エンジンは、属性「capital」が州または国内の重要な都市を参照していることを示唆する方法で、一連の文で使用されることを決定する場合があります。 したがって、分布表現エンジンは、エンティティが現れるコンテキスト(すなわち、文のセット)を使用して、エンティティ(V e)の埋め込みを指定するベクトル表現を生成します。 分布表現エンジンは、特徴が現れる文のセットを使用して、属性の埋め込みを指定するベクトル表現(V a)を生成します。
分布属性エンジンは、既知のエンティティと属性のペアを使用して、エンティティの分布属性の埋め込みを指定する4番目のベクトル表現を生成します。 知識ベースに格納される既知のエンティティ属性ペアは、エンティティ内の各属性がエンティティ内の各属性であることが確認されたエンティティ属性ペアです(たとえば、分類モデルによる事前処理を使用して、または人間の評価に基づいて)。属性ペアは、エンティティと属性のカップルのエンティティの重要な属性です。
分散属性エンジンは、次の操作を実行して、エンティティが関連付けられる既知のエンティティと属性のペアの一部(たとえば、最も一般的な)または他のすべての既知の属性を使用してエンティティの埋め込みを指定する分散属性の埋め込みを決定します。
エンティティの他の属性の識別
エンティティ属性候補ペアのエンティティの場合、分散属性エンジンは、既知のエンティティ属性チームのエンティティに関連付けられているエンティティ属性候補ペアに含まれている属性以外の属性を識別します。
候補エンティティ-属性ペア(マイケルジョーダン、有名)のエンティティ「マイケルジョーダン」の場合、属性分散エンジンは、(マイケルジョーダン、裕福な)や(マイケルジョーダン、レコード)、富裕層や説明などの属性を識別します。
次に、属性分散エンジンは、識別された既知の属性の加重和を計算することによってエンティティの埋め込みを生成します(前の段落で説明)。ここで、次の式に示すように、注意メカニズムを使用して加重が学習されます。矢印(v)} e = ATTN(α1) ..。epsilon(αm))
分布属性エンジンは、既知のエンティティと属性のペアを使用して、属性に埋め込まれた分布属性を指定する5番目のベクトル表現を生成します。 分散属性エンジンは、次の操作を実行して、候補属性の既知のエンティティに関連付けられた既知の属性の一部(最も一般的かどうか)またはすべてに基づいてモデルを決定します。
エンティティ属性候補ペアのポイントについて、分散属性エンジンは、品質を持つ既知のエンティティ属性カップルの中から既知のエンティティを識別します。
識別された既知のエンティティごとに、分散属性エンジンは、既知のエンティティ属性チーム内のエンティティに関連付けられている他の属性(つまり、エンティティ属性候補のペアに含まれている属性以外の属性)を識別します。 分散属性エンジンは、次の方法で、識別された属性の中から属性のサブセットを識別できます。
(1)各エンティティに関連付けられている既知のエンティティの数に基づいて属性をランク付けします。たとえば、少数のエンティティに関連付けられている属性よりも多数のエンティティに関連付けられている属性に高いランクを割り当てます)
受信トレイに直接ニュースを検索
*必須