
SQL standard în Google BigQuery: avantaje și exemple de utilizare în marketing
Publicat: 2022-04-12În 2016, Google BigQuery a introdus o nouă modalitate de a comunica cu tabelele: SQL standard. Până atunci, BigQuery avea propriul său limbaj de interogare structurat, numit BigQuery SQL (denumit acum Legacy SQL).
La prima vedere, nu există mare diferență între Legacy și Standard SQL: numele tabelelor sunt scrise puțin diferit; Standard are cerințe gramaticale puțin mai stricte (de exemplu, nu puteți pune o virgulă înainte de FROM) și mai multe tipuri de date. Dar dacă te uiți cu atenție, există câteva modificări minore de sintaxă care oferă marketerilor multe avantaje.
În acest articol, veți obține răspunsuri la următoarele întrebări:
- Care sunt avantajele SQL standard față de SQL moștenit?
- Care sunt capabilitățile SQL standard și cum este utilizat?
- Cum pot trece de la Legacy la Standard SQL?
- Cu ce alte servicii, caracteristici de sintaxă, operatori și funcții este compatibil SQL standard?
- Cum pot folosi interogări SQL pentru rapoartele de marketing?
Care sunt avantajele SQL standard față de SQL moștenit?
Noi tipuri de date: matrice și câmpuri imbricate
SQL standard acceptă noi tipuri de date: ARRAY și STRUCT (matrice și câmpuri imbricate). Aceasta înseamnă că în BigQuery, a devenit mai ușor să lucrați cu tabele încărcate din fișiere JSON/Avro, care conțin adesea atașamente pe mai multe niveluri.
Un câmp imbricat este un mini tabel în interiorul unuia mai mare:
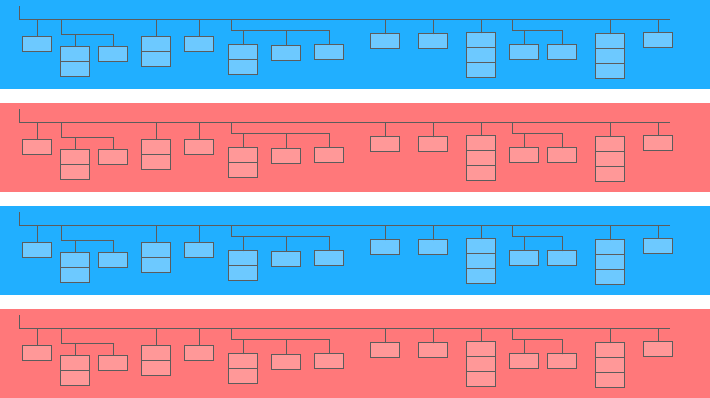
În diagrama de mai sus, barele albastre și galbene sunt liniile în care sunt încorporate mini-mesele. Fiecare linie este o sesiune. Sesiunile au parametri comuni: data, numărul ID, categoria dispozitivului utilizatorului, browserul, sistemul de operare etc. Pe lângă parametrii generali pentru fiecare sesiune, tabelul de accesări este atașat liniei.

Tabelul de accesări conține informații despre acțiunile utilizatorului pe site. De exemplu, dacă un utilizator dă clic pe un banner, răsfoiește catalogul, deschide o pagină de produs, pune un produs în coș sau plasează o comandă, aceste acțiuni vor fi înregistrate în tabelul de accesări.
Dacă un utilizator plasează o comandă pe site, informațiile despre comandă vor fi, de asemenea, introduse în tabelul de accesări:
- transactionId (numărul care identifică tranzacția)
- Venitul tranzacției (valoarea totală a comenzii)
- tranzacțieExpediere (costuri de transport)
Tabelele de date de sesiune colectate folosind OWOX BI au o structură similară.
Să presupunem că doriți să aflați numărul de comenzi de la utilizatorii din New York City în ultima lună. Pentru a afla, trebuie să vă referiți la tabelul de accesări și să numărați numărul de ID-uri unice de tranzacție. Pentru a extrage date din astfel de tabele, Standard SQL are o funcție UNNEST:
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City Dacă informațiile despre comandă au fost înregistrate într-un tabel separat și nu într-un tabel imbricat, ar trebui să utilizați JOIN pentru a combina tabelul cu informațiile despre comandă și tabelul cu datele sesiunii pentru a afla în ce sesiuni au fost făcute comenzi.
Mai multe opțiuni de interogare
Dacă trebuie să extrageți date din câmpuri imbricate pe mai multe niveluri, puteți adăuga subinterogări cu SELECT și WHERE. De exemplu, în tabelele de streaming de sesiuni OWOX BI, un alt subtabel, produs, este scris în subtabelul de accesări. Subtabelul de produse colectează date despre produse care sunt transmise cu o matrice de comerț electronic îmbunătățit. Dacă pe site este configurat comerțul electronic îmbunătățit și un utilizator a privit o pagină de produs, caracteristicile acestui produs vor fi înregistrate în subtabelul de produse.
Pentru a obține aceste caracteristici ale produsului, veți avea nevoie de o subinterogare în interogarea principală. Pentru fiecare caracteristică de produs, o subinterogare SELECT separată este creată în paranteze:
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD`
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` Datorită capabilităților SQL standard, este mai ușor să construiți o logică de interogare și să scrieți cod. Pentru comparație, în Legacy SQL, ar trebui să scrieți acest tip de scară:
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )Solicitari catre surse externe
Folosind SQL standard, puteți accesa tabelele BigQuery direct din Google Bigtable, Google Cloud Storage, Google Drive și Google Sheets.
Adică, în loc să încărcați întregul tabel în BigQuery, puteți șterge datele cu o singură interogare, puteți selecta parametrii de care aveți nevoie și îi puteți încărca în stocarea în cloud.
Mai multe funcții de utilizator (UDF)
Dacă trebuie să utilizați o formulă care nu este documentată, funcțiile definite de utilizator (UDF) vă vor ajuta. În practica noastră, acest lucru se întâmplă rar, deoarece documentația SQL standard acoperă aproape toate sarcinile de analiză digitală.
În SQL Standard, funcțiile definite de utilizator pot fi scrise în SQL sau JavaScript; Legacy SQL acceptă numai JavaScript. Argumentele acestor funcții sunt coloane, iar valorile pe care le iau sunt rezultatul manipulării coloanelor. În SQL standard, funcțiile pot fi scrise în aceeași fereastră ca interogările.
Mai multe condiții JOIN
În Legacy SQL, condițiile JOIN se pot baza pe egalitate sau pe nume de coloane. În plus față de aceste opțiuni, dialectul SQL standard acceptă JOIN prin inegalitate și prin expresie arbitrară.
De exemplu, pentru a identifica partenerii CPA neloiali, putem selecta sesiuni în care sursa a fost înlocuită în 60 de secunde de la tranzacție. Pentru a face acest lucru în SQL standard, putem adăuga o inegalitate la condiția JOIN:
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime Singura limitare a SQL standard în ceea ce privește JOIN este că nu permite semi-uniunea cu subinterogări de forma WHERE column IN (SELECT ...):
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESC
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESCMai puține șanse de greșeli
Unele funcții din Legacy SQL returnează NULL dacă condiția este incorectă. De exemplu, dacă împărțirea cu zero s-a strecurat în calculele dvs., interogarea va fi executată și intrările NULL vor apărea în rândurile rezultate ale tabelului. Acest lucru poate masca probleme în interogare sau în date.
Logica standardului SQL este mai simplă. Dacă o condiție sau datele de intrare sunt incorecte, interogarea va genera o eroare, de exemplu „diviziunea la zero”, astfel încât să puteți corecta rapid interogarea. Următoarele verificări sunt încorporate în SQL standard:
- Valori valide pentru +, -, ×, SUM, AVG, STDEV
- Impartirea cu zero
Solicitările rulează mai repede
Interogările JOIN scrise în Standard SQL sunt mai rapide decât cele scrise în Legacy SQL datorită filtrării preliminare a datelor primite. Mai întâi, interogarea selectează rândurile care corespund condițiilor JOIN, apoi le procesează.
În viitor, Google BigQuery va lucra la îmbunătățirea vitezei și a performanței interogărilor numai pentru SQL standard.
Tabelele pot fi editate: inserați și ștergeți rânduri, actualizați
Funcțiile DML (Data Manipulation Language) sunt disponibile în SQL standard. Aceasta înseamnă că puteți actualiza tabelele și puteți adăuga sau elimina rânduri din ele prin aceeași fereastră în care scrieți interogări. De exemplu, folosind DML, puteți combina datele din două tabele într-unul singur:
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)Codul este mai ușor de citit și editat
Cu SQL standard, interogările complexe pot fi pornite nu numai cu SELECT, ci și cu WITH, făcând codul mai ușor de citit, comentat și înțeles. Acest lucru înseamnă, de asemenea, că este mai ușor să preveniți propriile greșeli și să corectați greșelile altora.
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2 Este convenabil să lucrezi cu operatorul WITH dacă ai calcule care se fac în mai multe etape. În primul rând, puteți colecta valori intermediare în subinterogări, apoi puteți face calculele finale.
Google Cloud Platform (GCP), care include BigQuery, este o platformă cu ciclu complet pentru lucrul cu date mari, de la organizarea unui depozit de date sau a unui cloud de date până la derularea de experimente științifice și analize predictive și prescriptive. Odată cu introducerea standardului SQL, BigQuery își extinde publicul. Lucrul cu GCP devine din ce în ce mai interesant pentru analiștii de marketing, analiștii de produse, cercetătorii de date și echipele de alți specialiști.
Capabilități de SQL standard și exemple de cazuri de utilizare
La OWOX BI, lucrăm adesea cu tabele compilate folosind exportul standard Google Analytics 360 către Google BigQuery sau OWOX BI Pipeline. În exemplele de mai jos, ne vom uita la specificul interogărilor SQL pentru astfel de date.
Dacă nu colectați deja date de pe site-ul dvs. în BigQuery, puteți încerca să faceți acest lucru gratuit cu versiunea de probă a OWOX BI.
1. Selectați datele pentru un interval de timp
În Google BigQuery, datele despre comportamentul utilizatorilor pentru site-ul dvs. sunt stocate în tabele cu metacaractere (tabele cu un asterisc); se formează un tabel separat pentru fiecare zi. Aceste tabele au același nume: doar sufixul este diferit. Sufixul este data în formatul AAAAMMZZ. De exemplu, tabelul owoxbi_sessions_20190301 conține date despre sesiunile din 1 martie 2019.
Ne putem referi direct la un grup de astfel de tabele într-o singură solicitare pentru a obține date, de exemplu, de la 1 februarie până la 28 februarie 2019. Pentru a face acest lucru, trebuie să înlocuim AAAAMMZZ cu un * în FROM și în WHERE, trebuie să specificăm sufixele de tabel pentru începutul și sfârșitul intervalului de timp:
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �'
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �' Datele specifice pentru care dorim să colectăm date nu ne sunt întotdeauna cunoscute. De exemplu, în fiecare săptămână ar putea fi nevoie să analizăm datele din ultimele trei luni. Pentru a face acest lucru, putem folosi funcția FORMAT_DATE:
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) După BETWEEN, înregistrăm sufixul primului tabel. Expresia CURRENT_DATE (), INTERVAL 3 MONTHS înseamnă „selectați datele pentru ultimele 3 luni de la data curentă”. Al doilea sufix de tabel este formatat după AND. Este necesar să se marcheze sfârșitul intervalului ca ieri: CURRENT_DATE (), INTERVAL 1 DAY.
2. Preluați parametrii și indicatorii utilizatorului
Parametrii și valorile utilizatorului din tabelele de export Google Analytics sunt scrise în tabelul de accesări imbricate și în subtabelele customDimensions și customMetrics. Toate dimensiunile personalizate sunt înregistrate în două coloane: una pentru numărul de parametri colectați pe site, a doua pentru valorile acestora. Iată cum arată toți parametrii transmiși cu o singură lovitură:
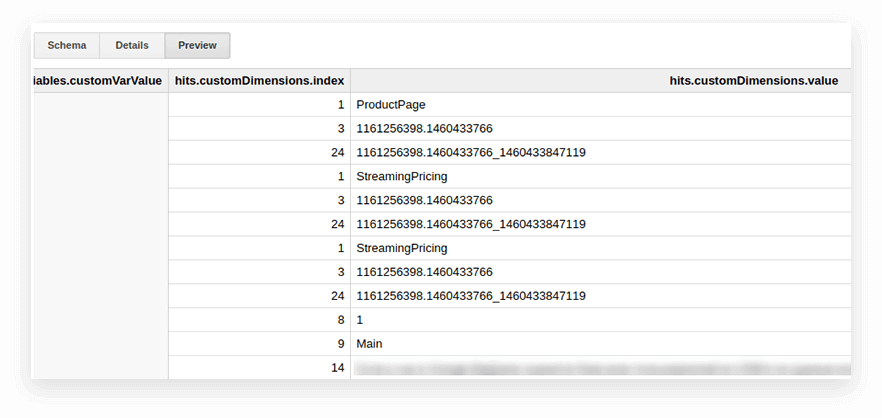
Pentru a le despacheta și a scrie parametrii necesari în coloane separate, folosim următoarea interogare SQL:
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 Iată cum arată în cerere:
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201` În captura de ecran de mai jos, am selectat parametrii 1 și 2 din datele demonstrative Google Analytics 360 din Google BigQuery și le-am numit page_type și client_id. Fiecare parametru este înregistrat într-o coloană separată:

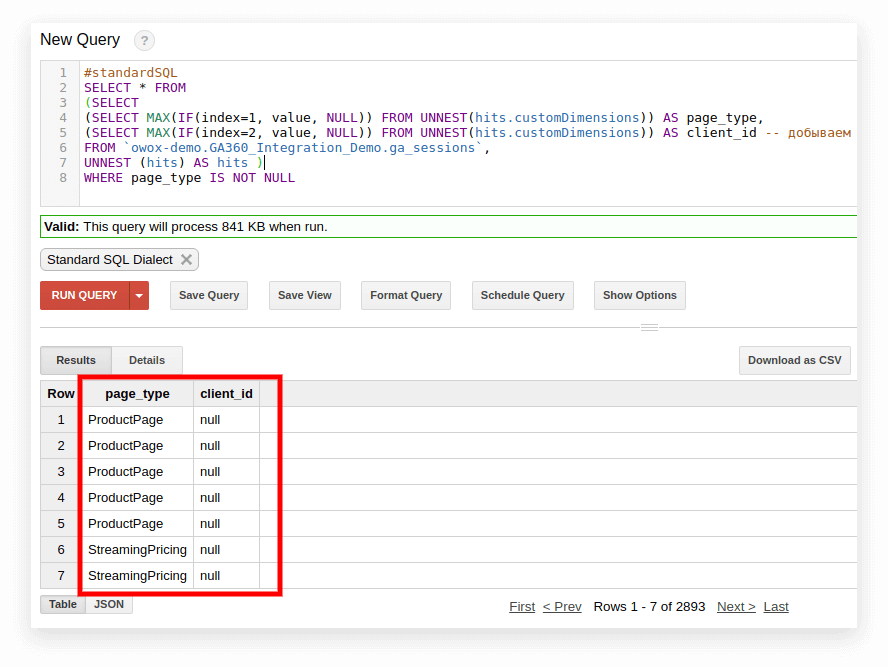
3. Calculați numărul de sesiuni în funcție de sursa de trafic, canal, campanie, oraș și categorie de dispozitiv
Astfel de calcule sunt utile dacă intenționați să vizualizați date în Google Data Studio și să filtrați după oraș și categoria de dispozitiv. Acest lucru este ușor de făcut cu funcția ferestrei COUNT:
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`4. Combină aceleași date din mai multe tabele
Să presupunem că colectați date despre comenzile finalizate în mai multe tabele BigQuery: unul colectează toate comenzile din Magazinul A, celălalt colectează comenzile din Magazinul B. Doriți să le combinați într-un singur tabel cu aceste coloane:
- client_id — un număr care identifică un cumpărător unic
- transaction_created — ora de creare a comenzii în format TIMESTAMP
- transaction_id — numărul comenzii
- is_approved — dacă comanda a fost confirmată
- transaction_revenue — valoarea comenzii
În exemplul nostru, comenzile de la 1 ianuarie 2018 până ieri trebuie să fie în tabel. Pentru a face acest lucru, selectați coloanele corespunzătoare din fiecare grup de tabele, atribuiți-le același nume și combinați rezultatele cu UNION ALL:
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC5. Creați un dicționar de grupuri de canale de trafic
Când datele intră în Google Analytics, sistemul determină automat grupul căruia îi aparține o anumită tranziție: Căutare directă, Căutare organică, Căutare plătită și așa mai departe. Pentru a identifica un grup de canale, Google Analytics analizează etichetele UTM ale tranzițiilor, și anume utm_source și utm_medium. Puteți citi mai multe despre grupurile de canale și regulile de definire în Ajutorul Google Analytics.
Dacă clienții OWOX BI doresc să-și atribuie propriile nume unor grupuri de canale, creăm un dicționar, a cărui tranziție aparține unui anumit canal. Pentru a face acest lucru, folosim operatorul CASE condiționat și funcția REGEXP_CONTAINS. Această funcție selectează valorile în care apare expresia regulată specificată.
Vă recomandăm să luați nume din lista dvs. de surse din Google Analytics. Iată un exemplu despre cum să adăugați astfel de condiții la corpul solicitării:
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201` Cum se trece la SQL standard
Dacă nu ați trecut încă la SQL standard, o puteți face oricând. Principalul lucru este să evitați amestecarea dialectelor într-o singură cerere.
Opțiunea 1. Comutați în interfața Google BigQuery
SQL moștenit este utilizat în mod prestabilit în vechea interfață BigQuery. Pentru a comuta între dialecte, faceți clic pe Afișare opțiuni sub câmpul de introducere a interogării și debifați caseta Utilizare SQL moștenit de lângă Dialectul SQL.
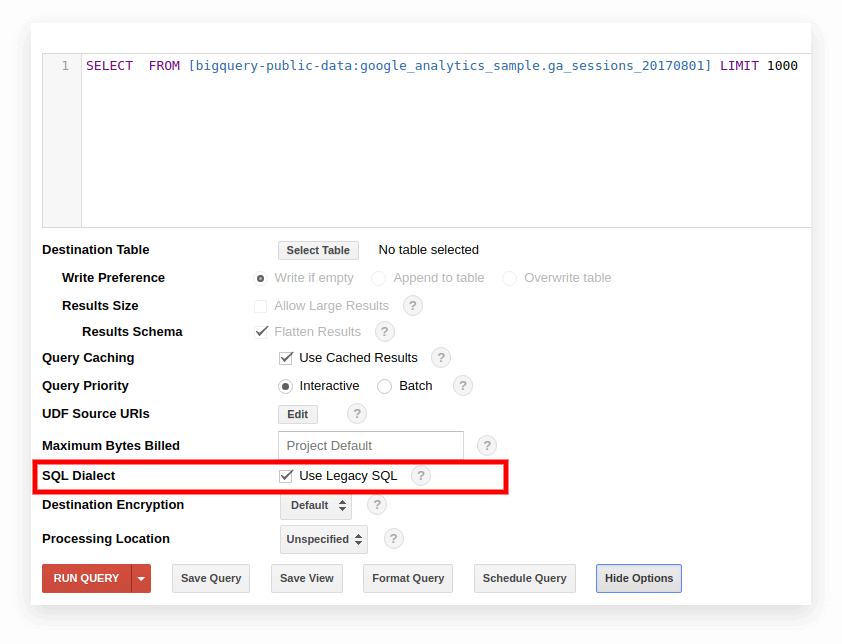
Noua interfață folosește standard SQL în mod implicit. Aici, trebuie să accesați fila Mai multe pentru a schimba dialectele:
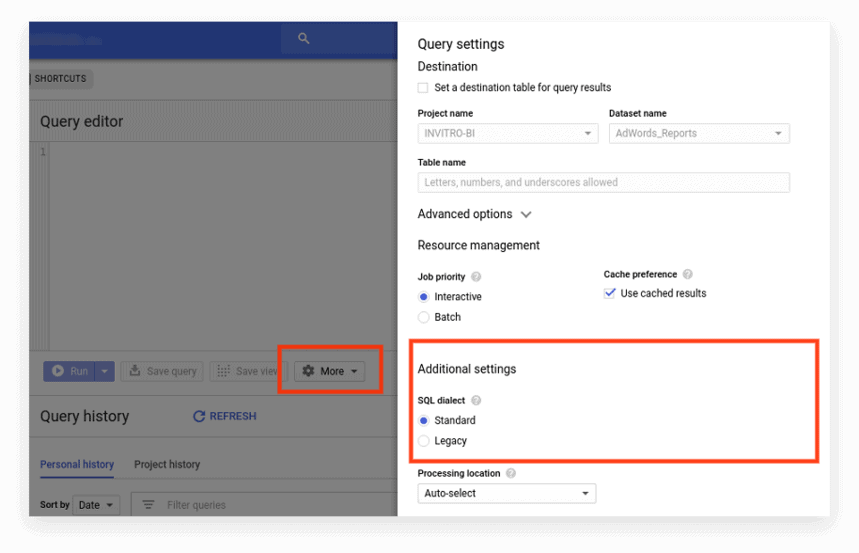
Opțiunea 2. Scrieți prefixul la începutul cererii
Dacă nu ați bifat setările de solicitare, puteți începe cu prefixul dorit (#standardSQL sau #legacySQL):
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10;
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10; În acest caz, Google BigQuery va ignora setările din interfață și va rula interogarea folosind dialectul specificat în prefix.
Dacă aveți vizualizări sau interogări salvate care sunt lansate într-un program folosind Apps Script, nu uitați să schimbați valoarea useLegacySql la false în script:
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }Opțiunea 3. Tranziție la SQL standard pentru vizualizări
Dacă lucrați cu Google BigQuery nu cu tabele, ci cu vizualizări, acele vizualizări nu pot fi accesate în dialectul SQL standard. Adică, dacă prezentarea dvs. este scrisă în Legacy SQL, nu puteți scrie cereri în ea în Standard SQL.
Pentru a transfera o vizualizare la SQL standard, trebuie să rescrieți manual interogarea prin care a fost creată. Cel mai simplu mod de a face acest lucru este prin interfața BigQuery.
1. Deschideți vizualizarea:
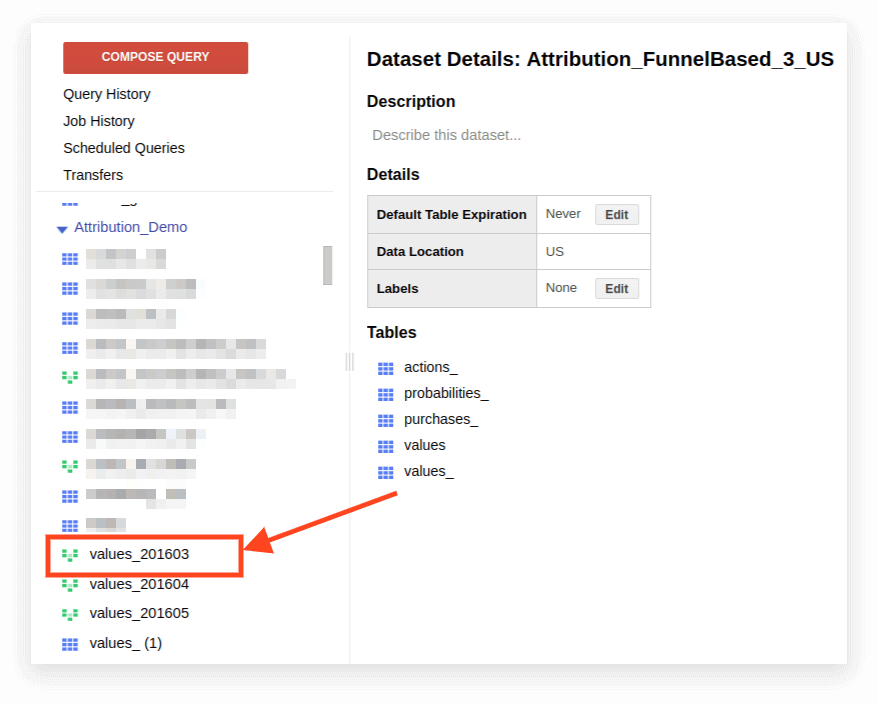
2. Faceți clic pe Detalii. Textul interogării ar trebui să se deschidă, iar butonul Editare interogare va apărea mai jos:
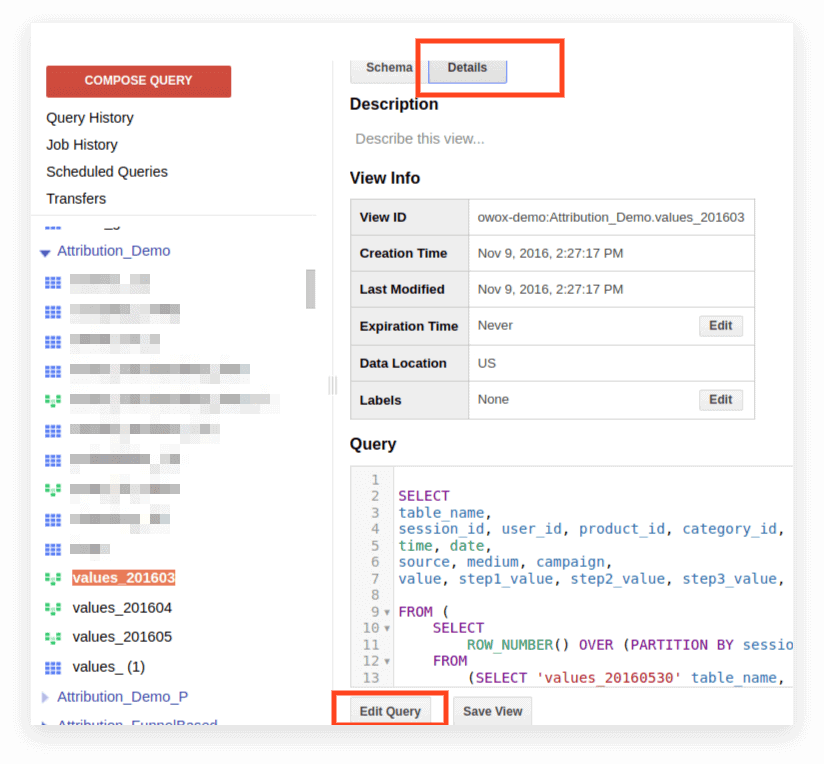
Acum puteți edita cererea conform regulilor Standard SQL.
Dacă intenționați să continuați să utilizați cererea ca prezentare, faceți clic pe Salvare vizualizare după ce ați terminat editarea.
Compatibilitate, caracteristici de sintaxă, operatori, funcții
Compatibilitate
Datorită implementării standardului SQL, puteți accesa direct datele stocate în alte servicii direct din BigQuery:
- Fișierele jurnal Google Cloud Storage
- Înregistrări tranzacționale în Google Bigtable
- Date din alte surse
Acest lucru vă permite să utilizați produsele Google Cloud Platform pentru orice sarcini analitice, inclusiv analize predictive și prescriptive bazate pe algoritmi de învățare automată.
Sintaxa interogării
Structura de interogare în dialectul standard este aproape aceeași ca în Legacy:
Numele tabelelor și vizualizării sunt separate printr-un punct (punct), iar întreaga interogare este închisă cu accente grave: `project_name.data_name_name.table_name``bigquery-public-data.samples.natality`
Sintaxa completă a interogării, cu explicații despre ceea ce poate fi inclus în fiecare operator, este compilată ca o schemă în documentația BigQuery.
Caracteristicile sintaxei SQL standard:
- Sunt necesare virgule pentru a lista câmpurile din instrucțiunea SELECT.
- Dacă utilizați operatorul UNNEST după FROM , înainte de UNNEST este plasată o virgulă sau JOIN.
- Nu poți pune o virgulă înainte de FROM.
- O virgulă între două interogări este egală cu un CROSS JOIN, așa că aveți grijă cu ea.
- JOIN se poate face nu numai prin coloană sau egalitate, ci și prin expresii arbitrare și inegalitate.
- Este posibil să scrieți subinterogări complexe în orice parte a expresiei SQL (în SELECT, FROM, WHERE etc.). În practică, nu este încă posibil să utilizați expresii precum WHERE column_name IN (SELECT ...) așa cum puteți în alte baze de date.
Operatori
În SQL standard, operatorii definesc tipul de date. De exemplu, o matrice este întotdeauna scrisă între paranteze []. Operatorii sunt utilizați pentru comparație, potrivirea expresiei logice (NU, SAU, ȘI) și în calcule aritmetice.
Funcții
SQL standard acceptă mai multe caracteristici decât Legacy: agregare tradițională (sumă, număr, minim, maxim); funcții matematice, șiruri și statistice; și formate rare, cum ar fi HyperLogLog ++.
În dialectul standard, există mai multe funcții pentru a lucra cu date și TIMESTAMP. O listă completă a funcțiilor este furnizată în documentația Google. Cele mai frecvent utilizate funcții sunt pentru lucrul cu date, șiruri, agregare și fereastră.
1. Funcții de agregare
COUNT (DISTINCT nume_coloană) numără numărul de valori unice dintr-o coloană. De exemplu, să presupunem că trebuie să numărăm numărul de sesiuni de pe dispozitivele mobile pe 1 martie 2019. Deoarece un număr de sesiune poate fi repetat pe linii diferite, dorim să numărăm numai valorile unice ale numărului de sesiuni:
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile' SUM (nume_coloană) — suma valorilor din coloană
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile' MIN (nume_coloană) | MAX (nume_coloană) — valoarea minimă și maximă din coloană. Aceste funcții sunt convenabile pentru verificarea răspândirii datelor într-un tabel.
2. Funcții ferestre (analitice).
Funcțiile analitice iau în considerare valorile nu pentru întregul tabel, ci pentru o anumită fereastră - un set de rânduri care vă interesează. Adică, puteți defini segmente într-un tabel. De exemplu, puteți calcula SUM (venitul) nu pentru toate liniile, ci pentru orașe, categorii de dispozitive și așa mai departe. Puteți transforma funcțiile analitice SUM, COUNT și AVG, precum și alte funcții de agregare, adăugând la acestea condiția OVER (PARTITION BY column_name).
De exemplu, trebuie să numărați numărul de sesiuni în funcție de sursa de trafic, canal, campanie, oraș și categorie de dispozitiv. În acest caz, putem folosi următoarea expresie:
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t OVER determină fereastra pentru care vor fi făcute calculele. PARTITION BY indică ce rânduri trebuie grupate pentru calcul. În unele funcții, este necesar să specificați ordinea grupării cu ORDER BY.
Pentru o listă completă a funcțiilor ferestrei, consultați documentația BigQuery.
3. Funcții șiruri
Acestea sunt utile atunci când trebuie să modificați textul, să formatați textul într-o linie sau să lipiți valorile coloanelor. De exemplu, funcțiile șir sunt grozave dacă doriți să generați un identificator unic de sesiune din datele standard de export Google Analytics 360. Să luăm în considerare cele mai populare funcții șir.
SUBSTR taie o parte din șir. În cerere, această funcție este scrisă ca SUBSTR (string_name, 0.4). Primul număr indică câte caractere trebuie săriți de la începutul rândului, iar al doilea număr indică câte cifre să tăiați. De exemplu, să presupunem că aveți o coloană de dată care conține date în formatul STRING. În acest caz, datele arată astfel: 20190103. Dacă doriți să extrageți un an din această linie, SUBSTR vă va ajuta:
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301` CONCAT (nume_coloană etc.) lipește valori. Să folosim coloana de dată din exemplul anterior. Să presupunem că doriți ca toate datele să fie înregistrate astfel: 2019-03-01. Pentru a converti datele din formatul actual în acest format, pot fi utilizate două funcții de șir: mai întâi, tăiați bucățile necesare din șir cu SUBSTR, apoi lipiți-le prin cratima:
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301` REGEXP_CONTAINS returnează valorile coloanelor în care apare expresia regulată:
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301` Această funcție poate fi utilizată atât în SELECT, cât și în WHERE. De exemplu, în WHERE, puteți selecta anumite pagini cu acesta:
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order')
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order') 4. Funcții de dată
Adesea, datele din tabele sunt înregistrate în format STRING. Dacă intenționați să vizualizați rezultatele în Google Data Studio, datele din tabel trebuie convertite în format DATE folosind funcția PARSE_DATE.
PARSE_DATE convertește un STRING din formatul 1900-01-01 în formatul DATE.
Dacă datele din tabelele dvs. arată diferit (de exemplu, 19000101 sau 01_01_1900), trebuie mai întâi să le convertiți în formatul specificat.
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301` DATE_DIFF calculează cât timp a trecut între două date în zile, săptămâni, luni sau ani. Este util dacă trebuie să determinați intervalul dintre momentul în care un utilizator a văzut reclamă și a plasat o comandă. Iată cum arată funcția într-o solicitare:
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301` Dacă doriți să aflați mai multe despre funcțiile enumerate, citiți Funcțiile Google BigQuery — O revizuire detaliată.
Interogări SQL pentru rapoarte de marketing
Dialectul SQL standard permite companiilor să extragă informații maxime din date cu segmentare profundă, audituri tehnice, analiză KPI de marketing și identificarea contractanților incorecți în rețelele CPA. Iată exemple de probleme de afaceri în care interogările SQL privind datele colectate în Google BigQuery vă vor ajuta.
1. Analiza ROPO: evaluați contribuția campaniilor online la vânzările offline. Pentru a efectua analiza ROPO, trebuie să combinați datele despre comportamentul utilizatorilor online cu datele din CRM, sistemul de urmărire a apelurilor și aplicația mobilă.
Dacă există o cheie în una și a doua bază - un parametru comun care este unic pentru fiecare utilizator (de exemplu, User ID) - puteți urmări:
pe care utilizatorii au vizitat site-ul înainte de a cumpăra bunuri din magazin
cum s-au comportat utilizatorii pe site
cât timp au luat utilizatorii pentru a lua o decizie de cumpărare
ce campanii au avut cea mai mare creștere a achizițiilor offline.
2. Segmentează clienții după orice combinație de parametri, de la comportamentul pe site (pagini vizitate, produse vizualizate, numărul de vizite pe site înainte de cumpărare) până la numărul cardului de fidelitate și articolele achiziționate.
3. Aflați ce parteneri CPA lucrează cu rea-credință și înlocuiesc etichetele UTM.
4. Analizați progresul utilizatorilor prin intermediul pâlniei de vânzări.
Am pregătit o selecție de interogări în dialectul SQL standard. Dacă colectați deja date de pe site-ul dvs., din surse de publicitate și din sistemul dvs. CRM în Google BigQuery, puteți utiliza aceste șabloane pentru a vă rezolva problemele de afaceri. Pur și simplu înlocuiți numele proiectului, setul de date și tabelul din BigQuery cu propriile dvs. În colecție, veți primi 11 interogări SQL.
Pentru datele colectate folosind exportul standard din Google Analytics 360 în Google BigQuery:
- Acțiuni ale utilizatorului în contextul oricăror parametri
- Statistici privind acțiunile cheie ale utilizatorilor
- Utilizatori care au vizualizat anumite pagini de produse
- Acțiunile utilizatorilor care au cumpărat un anumit produs
- Configurați pâlnia cu pașii necesari
- Eficacitatea site-ului intern de căutare
Pentru datele colectate în Google BigQuery folosind OWOX BI:
- Consum atribuit pe sursă și canal
- Costul mediu de atragere a unui vizitator în funcție de oraș
- Rentabilitatea cheltuielilor publicitare pentru profitul brut pe sursă și canal
- Numărul de comenzi în CRM după metoda de plată și modalitatea de livrare
- Timp mediu de livrare pe oraș
Dacă aveți întrebări despre interogarea datelor Google BigQuery la care nu ați găsit răspunsuri în acest articol, întrebați în comentarii. Vom încerca să vă ajutăm.