
SQL estándar en Google BigQuery: ventajas y ejemplos de uso en marketing
Publicado: 2022-04-12En 2016, Google BigQuery introdujo una nueva forma de comunicarse con tablas: SQL estándar. Hasta entonces, BigQuery tenía su propio lenguaje de consulta estructurado llamado BigQuery SQL (ahora llamado Legacy SQL).
A primera vista, no hay mucha diferencia entre Legacy y Standard SQL: los nombres de las tablas se escriben un poco diferente; Estándar tiene requisitos gramaticales ligeramente más estrictos (por ejemplo, no puede poner una coma antes de DE) y más tipos de datos. Pero si observa detenidamente, hay algunos cambios de sintaxis menores que brindan muchas ventajas a los especialistas en marketing.
En este artículo, obtendrá respuestas a las siguientes preguntas:
- ¿Cuáles son las ventajas de SQL estándar sobre SQL heredado?
- ¿Cuáles son las capacidades de SQL estándar y cómo se utiliza?
- ¿Cómo puedo pasar de Legacy a Standard SQL?
- ¿Con qué otros servicios, características de sintaxis, operadores y funciones es compatible SQL estándar?
- ¿Cómo puedo usar consultas SQL para informes de marketing?
¿Cuáles son las ventajas de SQL estándar sobre SQL heredado?
Nuevos tipos de datos: matrices y campos anidados
SQL estándar admite nuevos tipos de datos: ARRAY y STRUCT (matrices y campos anidados). Esto significa que en BigQuery ahora es más fácil trabajar con tablas cargadas desde archivos JSON/Avro, que a menudo contienen archivos adjuntos de varios niveles.
Un campo anidado es una mini tabla dentro de una más grande:
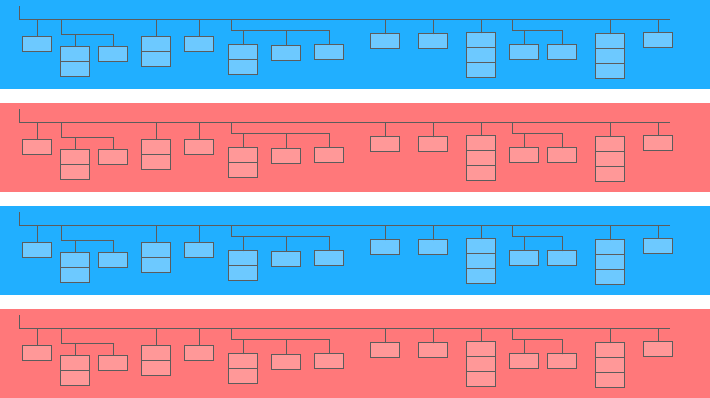
En el diagrama anterior, las barras azules y amarillas son las líneas en las que están incrustadas las minimesas. Cada línea es una sesión. Las sesiones tienen parámetros comunes: fecha, número de cédula, categoría de dispositivo del usuario, navegador, sistema operativo, etc. Además de los parámetros generales de cada sesión, se adjunta a la línea la tabla de aciertos.

La tabla de resultados contiene información sobre las acciones del usuario en el sitio. Por ejemplo, si un usuario hace clic en un banner, hojea el catálogo, abre una página de producto, coloca un producto en la cesta o realiza un pedido, estas acciones se registrarán en la tabla de aciertos.
Si un usuario realiza un pedido en el sitio, la información sobre el pedido también se ingresará en la tabla de resultados:
- transaccionId (número que identifica la transacción)
- transactionRevenue (valor total del pedido)
- transacciónEnvío (gastos de envío)
Las tablas de datos de sesión recopiladas con OWOX BI tienen una estructura similar.
Suponga que desea saber el número de pedidos de los usuarios de la ciudad de Nueva York durante el último mes. Para averiguarlo, debe consultar la tabla de aciertos y contar la cantidad de ID de transacción únicos. Para extraer datos de tales tablas, Standard SQL tiene una función UNNEST:
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City Si la información del pedido se registró en una tabla separada y no en una tabla anidada, tendría que usar JOIN para combinar la tabla con la información del pedido y la tabla con los datos de la sesión para averiguar en qué sesiones se realizaron los pedidos.
Más opciones de subconsulta
Si necesita extraer datos de campos anidados de varios niveles, puede agregar subconsultas con SELECT y WHERE. Por ejemplo, en las tablas de transmisión de sesiones de BI de OWOX, otra subtabla, producto, se escribe en la subtabla de visitas. La subtabla de productos recopila datos de productos que se transmiten con una matriz de comercio electrónico mejorado. Si se configura un comercio electrónico mejorado en el sitio y un usuario ha mirado la página de un producto, las características de este producto se registrarán en la subtabla del producto.
Para obtener estas características del producto, necesitará una subconsulta dentro de la consulta principal. Para cada característica del producto, se crea una subconsulta SELECT separada entre paréntesis:
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD`
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` Gracias a las capacidades de SQL estándar, es más fácil crear lógica de consulta y escribir código. A modo de comparación, en Legacy SQL, necesitaría escribir este tipo de escalera:
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )Solicitudes a fuentes externas
Con SQL estándar, puede acceder a las tablas de BigQuery directamente desde Google Bigtable, Google Cloud Storage, Google Drive y Google Sheets.
Es decir, en lugar de cargar toda la tabla en BigQuery, puede eliminar los datos con una sola consulta, seleccionar los parámetros que necesita y cargarlos en el almacenamiento en la nube.
Más funciones de usuario (UDF)
Si necesita usar una fórmula que no está documentada, las funciones definidas por el usuario (UDF) lo ayudarán. En nuestra práctica, esto sucede rara vez, ya que la documentación de SQL estándar cubre casi todas las tareas de análisis digital.
En SQL estándar, las funciones definidas por el usuario se pueden escribir en SQL o JavaScript; SQL heredado solo admite JavaScript. Los argumentos de estas funciones son columnas, y los valores que toman son el resultado de manipular columnas. En SQL estándar, las funciones se pueden escribir en la misma ventana que las consultas.
Más condiciones de ÚNETE
En Legacy SQL, las condiciones de JOIN se pueden basar en igualdad o nombres de columna. Además de estas opciones, el dialecto SQL estándar admite JOIN por desigualdad y por expresión arbitraria.
Por ejemplo, para identificar socios de CPA desleales, podemos seleccionar sesiones en las que la fuente se reemplazó dentro de los 60 segundos posteriores a la transacción. Para hacer esto en SQL estándar, podemos agregar una desigualdad a la condición JOIN:
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime La única limitación de Standard SQL con respecto a JOIN es que no permite semi-join con subconsultas de la forma WHERE column IN (SELECT...):
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESC
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESCMenos posibilidades de errores
Algunas funciones en Legacy SQL devuelven NULL si la condición es incorrecta. Por ejemplo, si la división por cero se ha infiltrado en sus cálculos, la consulta se ejecutará y aparecerán entradas NULL en las filas resultantes de la tabla. Esto puede enmascarar problemas en la consulta o en los datos.
La lógica de SQL estándar es más sencilla. Si una condición o dato de entrada es incorrecto, la consulta generará un error, por ejemplo “división por cero”, para que puedas corregir rápidamente la consulta. Las siguientes comprobaciones están integradas en SQL estándar:
- Valores válidos para +, -, ×, SUM, AVG, STDEV
- División por cero
Las solicitudes se ejecutan más rápido
Las consultas JOIN escritas en SQL estándar son más rápidas que las escritas en SQL heredado gracias al filtrado preliminar de los datos entrantes. Primero, la consulta selecciona las filas que coinciden con las condiciones de JOIN y luego las procesa.
En el futuro, Google BigQuery trabajará para mejorar la velocidad y el rendimiento de las consultas solo para SQL estándar.
Las tablas se pueden editar: insertar y eliminar filas, actualizar
Las funciones del lenguaje de manipulación de datos (DML) están disponibles en SQL estándar. Esto significa que puede actualizar tablas y agregar o eliminar filas de ellas a través de la misma ventana en la que escribe consultas. Por ejemplo, al usar DML, puede combinar datos de dos tablas en una sola:
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)El código es más fácil de leer y editar.
Con SQL estándar, las consultas complejas se pueden iniciar no solo con SELECT sino también con WITH, lo que hace que el código sea más fácil de leer, comentar y comprender. Esto también significa que es más fácil prevenir los propios y corregir los errores de los demás.
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2 Es conveniente trabajar con el operador CON si tiene cálculos que se realizan en varias etapas. Primero, puede recopilar métricas intermedias en subconsultas y luego hacer los cálculos finales.
Google Cloud Platform (GCP), que incluye BigQuery, es una plataforma de ciclo completo para trabajar con big data, desde organizar un almacén de datos o una nube de datos hasta ejecutar experimentos científicos y análisis predictivos y prescriptivos. Con la introducción de SQL estándar, BigQuery amplía su audiencia. Trabajar con GCP es cada vez más interesante para los analistas de marketing, los analistas de productos, los científicos de datos y los equipos de otros especialistas.
Capacidades de SQL estándar y ejemplos de casos de uso
En OWOX BI, a menudo trabajamos con tablas compiladas utilizando la exportación estándar de Google Analytics 360 a Google BigQuery o OWOX BI Pipeline. En los ejemplos a continuación, veremos los detalles de las consultas SQL para dichos datos.
Si aún no recopila datos de su sitio en BigQuery, puede intentar hacerlo de forma gratuita con la versión de prueba de OWOX BI.
1. Seleccionar datos para un intervalo de tiempo
En Google BigQuery, los datos de comportamiento de los usuarios de su sitio se almacenan en tablas comodín (tablas con un asterisco); se forma una tabla separada para cada día. Estas tablas tienen el mismo nombre: solo el sufijo es diferente. El sufijo es la fecha en el formato AAAAMMDD. Por ejemplo, la tabla owoxbi_sessions_20190301 contiene datos sobre las sesiones del 1 de marzo de 2019.
Podemos referirnos directamente a un grupo de dichas tablas en una solicitud para obtener datos, por ejemplo, del 1 de febrero al 28 de febrero de 2019. Para hacer esto, necesitamos reemplazar AAAAMMDD con un * en DESDE, y en DONDE, necesitamos especificar los sufijos de la tabla para el inicio y el final del intervalo de tiempo:
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �'
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �' No siempre conocemos las fechas específicas para las que queremos recopilar datos. Por ejemplo, cada semana podríamos necesitar analizar los datos de los últimos tres meses. Para hacer esto, podemos usar la función FORMAT_DATE:
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) Después de BETWEEN, registramos el sufijo de la primera tabla. La frase FECHA_ACTUAL(), INTERVALO 3 MESES significa «seleccionar datos de los últimos 3 meses a partir de la fecha actual». El sufijo de la segunda tabla se formatea después de AND. Es necesario marcar el final del intervalo como ayer: CURRENT_DATE (), INTERVALO 1 DÍA.
2. Recuperar parámetros e indicadores de usuario
Los parámetros de usuario y las métricas en las tablas de exportación de Google Analytics se escriben en la tabla de resultados anidados y en las subtablas customDimensions y customMetrics. Todas las dimensiones personalizadas se registran en dos columnas: una para la cantidad de parámetros recopilados en el sitio, la segunda para sus valores. Así es como se ven todos los parámetros transmitidos con un solo golpe:
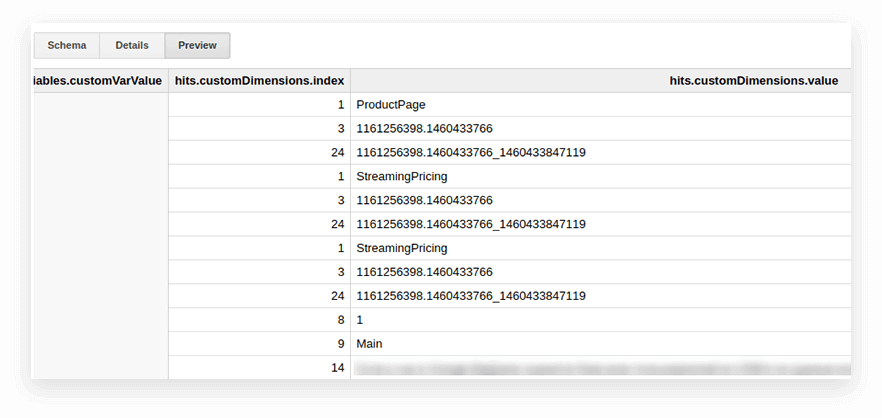
Para desempaquetarlos y escribir los parámetros necesarios en columnas separadas, usamos la siguiente consulta SQL:
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 Así es como se ve en la solicitud:
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201` En la siguiente captura de pantalla, seleccionamos los parámetros 1 y 2 de los datos de demostración de Google Analytics 360 en Google BigQuery y los llamamos page_type y client_id. Cada parámetro se registra en una columna separada:

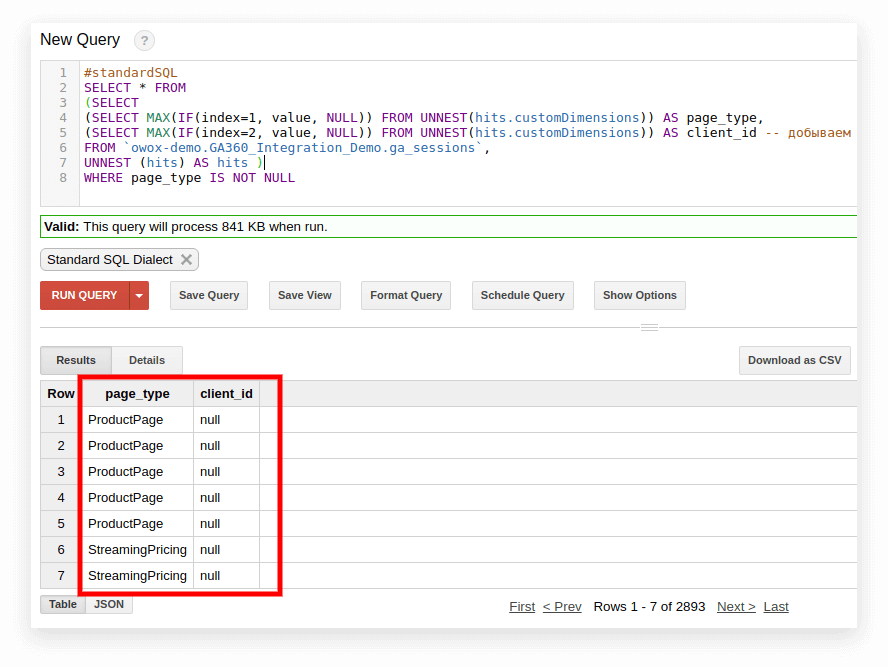
3. Calcule el número de sesiones por fuente de tráfico, canal, campaña, ciudad y categoría de dispositivo
Dichos cálculos son útiles si planea visualizar datos en Google Data Studio y filtrar por ciudad y categoría de dispositivo. Esto es fácil de hacer con la función de ventana COUNT:
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`4. Combinar los mismos datos de varias tablas
Suponga que recopila datos sobre pedidos completados en varias tablas de BigQuery: una recopila todos los pedidos de la tienda A y la otra recopila los pedidos de la tienda B. Desea combinarlos en una tabla con estas columnas:
- client_id: un número que identifica a un comprador único
- transaction_created — hora de creación del pedido en formato TIMESTAMP
- id_transacción — número de pedido
- is_approved — si el pedido fue confirmado
- transaction_revenue — monto del pedido
En nuestro ejemplo, los pedidos desde el 1 de enero de 2018 hasta ayer deben estar en la tabla. Para hacer esto, seleccione las columnas apropiadas de cada grupo de tablas, asígneles el mismo nombre y combine los resultados con UNION ALL:
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC5. Cree un diccionario de grupos de canales de tráfico
Cuando los datos ingresan a Google Analytics, el sistema determina automáticamente el grupo al que pertenece una transición en particular: Directa, Búsqueda orgánica, Búsqueda paga, etc. Para identificar un grupo de canales, Google Analytics analiza las etiquetas UTM de las transiciones, a saber, utm_source y utm_medium. Puede obtener más información sobre los grupos de canales y las reglas de definición en la Ayuda de Google Analytics.
Si los clientes de OWOX BI quieren asignar sus propios nombres a grupos de canales, creamos un diccionario, cuya transición pertenece a un canal específico. Para hacer esto, usamos el operador CASE condicional y la función REGEXP_CONTAINS. Esta función selecciona los valores en los que se produce la expresión regular especificada.
Recomendamos tomar nombres de su lista de fuentes en Google Analytics. Aquí hay un ejemplo de cómo agregar tales condiciones al cuerpo de la solicitud:
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201` Cómo cambiar a SQL estándar
Si aún no ha cambiado a SQL estándar, puede hacerlo en cualquier momento. Lo principal es evitar mezclar dialectos en una sola solicitud.
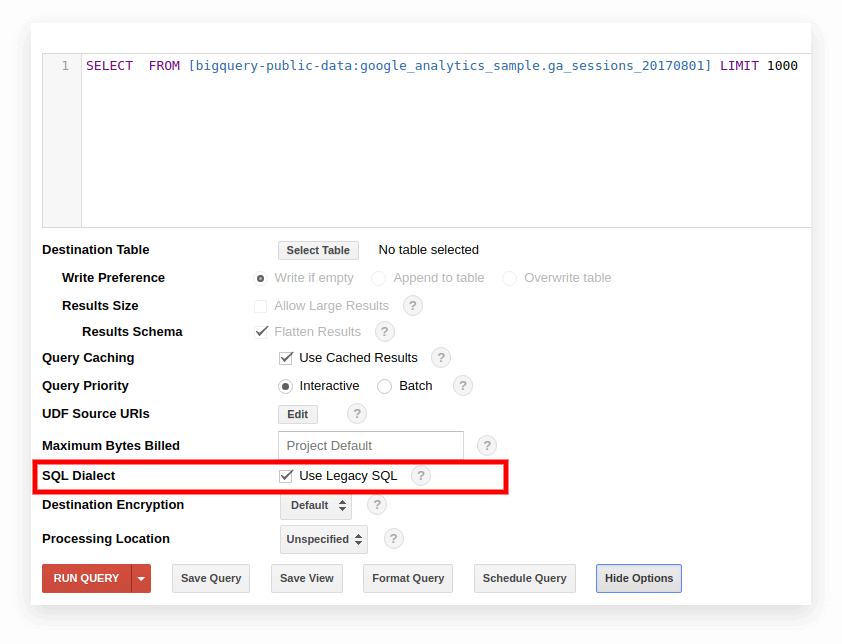
Opción 1. Cambiar en la interfaz de Google BigQuery
El SQL heredado se usa de forma predeterminada en la antigua interfaz de BigQuery. Para cambiar entre dialectos, haga clic en Mostrar opciones debajo del campo de entrada de consulta y desactive la casilla Usar SQL heredado junto a Dialecto SQL.
La nueva interfaz utiliza SQL estándar de forma predeterminada. Aquí, debe ir a la pestaña Más para cambiar de dialecto:
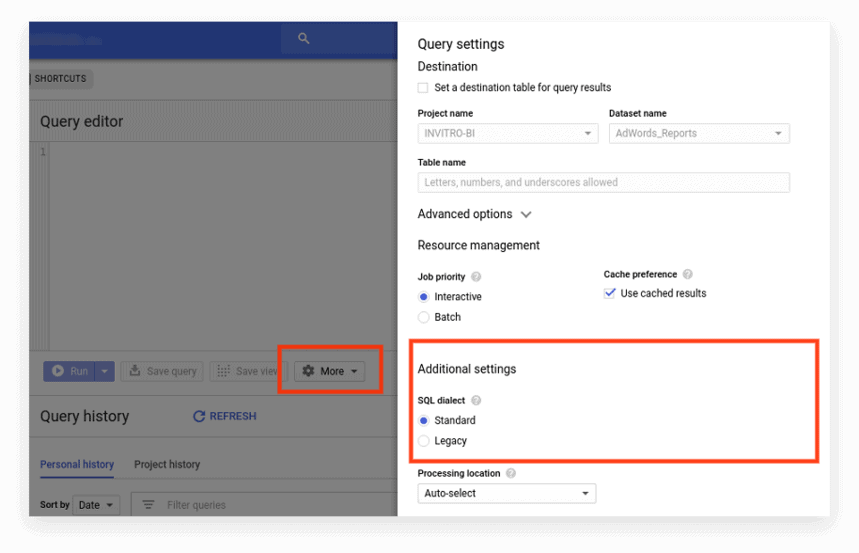
Opción 2. Escribir el prefijo al inicio de la solicitud
Si no ha marcado la configuración de la solicitud, puede comenzar con el prefijo deseado (#standardSQL o #legacySQL):
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10;
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10; En este caso, Google BigQuery ignorará la configuración de la interfaz y ejecutará la consulta con el dialecto especificado en el prefijo.
Si tiene vistas o consultas guardadas que se inician de forma programada con Apps Script, no olvide cambiar el valor de useLegacySql a false en el script:
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }Opción 3. Transición a SQL estándar para vistas
Si trabaja con Google BigQuery no con tablas sino con vistas, no se puede acceder a esas vistas en el dialecto SQL estándar. Es decir, si su presentación está escrita en SQL heredado, no puede escribirle solicitudes en SQL estándar.
Para transferir una vista a SQL estándar, debe volver a escribir manualmente la consulta por la que se creó. La forma más fácil de hacerlo es a través de la interfaz de BigQuery.
1. Abra la vista:
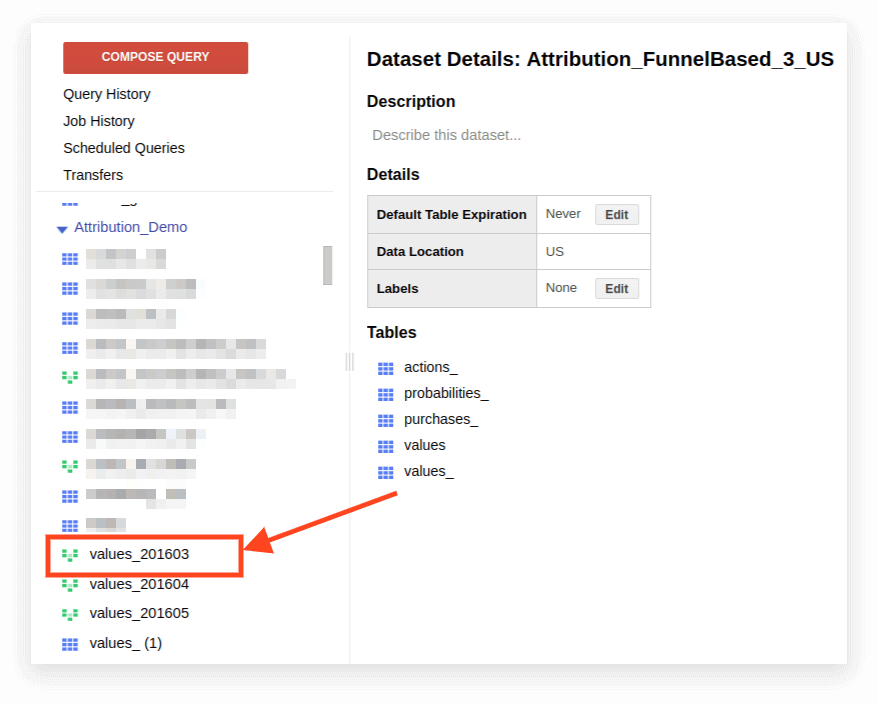
2. Haga clic en Detalles. El texto de la consulta debería abrirse y el botón Editar consulta aparecerá a continuación:
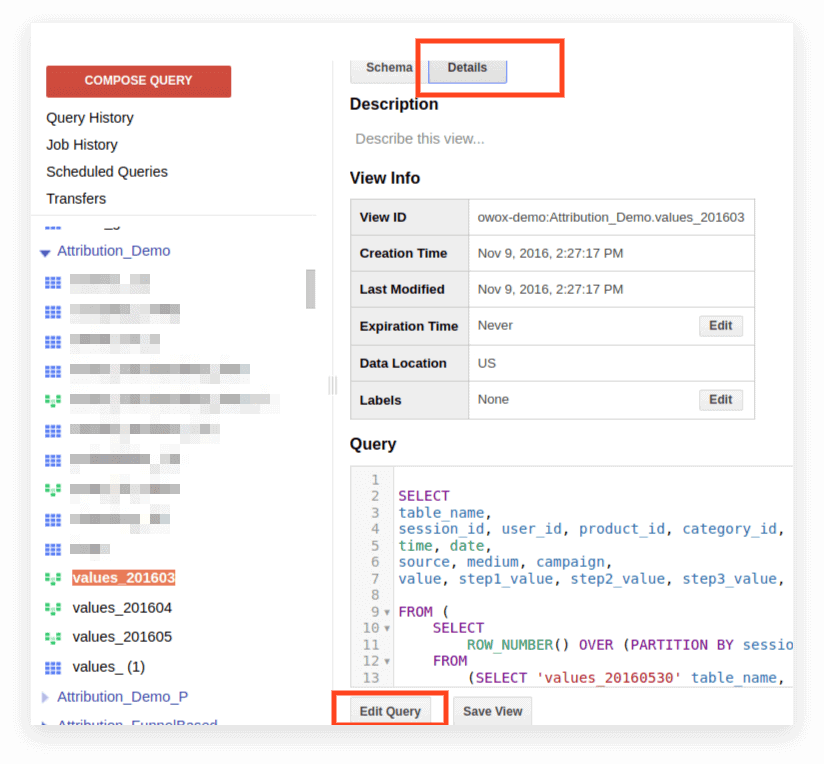
Ahora puede editar la solicitud de acuerdo con las reglas de SQL estándar.
Si planea continuar usando la solicitud como una presentación, haga clic en Guardar vista después de que haya terminado de editar.
Compatibilidad, características de sintaxis, operadores, funciones
Compatibilidad
Gracias a la implementación de SQL estándar, puedes acceder directamente a los datos almacenados en otros servicios directamente desde BigQuery:
- Archivos de registro de almacenamiento en la nube de Google
- Registros de transacciones en Google Bigtable
- Datos de otras fuentes
Esto le permite usar los productos de Google Cloud Platform para cualquier tarea analítica, incluidos los análisis predictivos y prescriptivos basados en algoritmos de aprendizaje automático.
Sintaxis de consulta
La estructura de consulta en el dialecto estándar es casi la misma que en Legacy:
Los nombres de las tablas y la vista están separados por un punto (punto) y toda la consulta está encerrada en acentos graves: `nombre_proyecto.nombre_datos_nombre.nombre_tabla``bigquery-public-data.samples.natality`
La sintaxis completa de la consulta, con explicaciones de lo que se puede incluir en cada operador, se compila como un esquema en la documentación de BigQuery.
Características de la sintaxis SQL estándar:
- Se necesitan comas para listar campos en la instrucción SELECT.
- Si usa el operador UNNEST después de FROM , se coloca una coma o JOIN antes de UNNEST.
- No puedes poner una coma antes de FROM.
- Una coma entre dos consultas equivale a CROSS JOIN, así que ten cuidado con eso.
- JOIN se puede hacer no solo por columna o igualdad sino por expresiones arbitrarias y desigualdad.
- Es posible escribir subconsultas complejas en cualquier parte de la expresión SQL (en SELECT, FROM, WHERE, etc.). En la práctica, aún no es posible usar expresiones como WHERE column_name IN (SELECT ...) como en otras bases de datos.
Operadores
En SQL estándar, los operadores definen el tipo de datos. Por ejemplo, una matriz siempre se escribe entre corchetes []. Los operadores se utilizan para la comparación, haciendo coincidir la expresión lógica (NOT, OR, AND) y en cálculos aritméticos.
Funciones
SQL estándar admite más funciones que Legacy: agregación tradicional (suma, número, mínimo, máximo); funciones matemáticas, de cadenas y estadísticas; y formatos raros como HyperLogLog ++.
En el dialecto estándar, hay más funciones para trabajar con fechas y TIMESTAMP. Se proporciona una lista completa de características en la documentación de Google. Las funciones más utilizadas son para trabajar con fechas, cadenas, agregación y ventana.
1. Funciones de agregación
COUNT (DISTINCT column_name) cuenta el número de valores únicos en una columna. Por ejemplo, supongamos que necesitamos contar la cantidad de sesiones desde dispositivos móviles el 1 de marzo de 2019. Dado que un número de sesión se puede repetir en diferentes líneas, queremos contar solo los valores de número de sesión únicos:
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile' SUM (column_name) — la suma de los valores en la columna
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile' MIN (nombre_columna) | MAX (column_name) — el valor mínimo y máximo en la columna. Estas funciones son convenientes para verificar la distribución de datos en una tabla.
2. Funciones de ventana (analíticas)
Las funciones analíticas consideran valores no para toda la tabla sino para una determinada ventana, un conjunto de filas que le interesan. Es decir, puede definir segmentos dentro de una tabla. Por ejemplo, puede calcular SUM (ingresos) no para todas las líneas sino para ciudades, categorías de dispositivos, etc. Puede convertir las funciones analíticas SUM, COUNT y AVG, así como otras funciones de agregación, agregándoles la condición OVER (PARTITION BY column_name).
Por ejemplo, debe contar la cantidad de sesiones por fuente de tráfico, canal, campaña, ciudad y categoría de dispositivo. En este caso, podemos utilizar la siguiente expresión:
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t OVER determina la ventana para la cual se realizarán los cálculos. PARTITION BY indica qué filas deben agruparse para el cálculo. En algunas funciones, es necesario especificar el orden de agrupación con ORDER BY.
Para obtener una lista completa de las funciones de la ventana, consulta la documentación de BigQuery.
3. Funciones de cadena
Estos son útiles cuando necesita cambiar texto, formatear el texto en una línea o pegar los valores de las columnas. Por ejemplo, las funciones de cadena son excelentes si desea generar un identificador de sesión único a partir de los datos de exportación estándar de Google Analytics 360. Consideremos las funciones de cadena más populares.
SUBSTR corta parte de la cadena. En la solicitud, esta función se escribe como SUBSTR (string_name, 0.4). El primer número indica cuántos caracteres saltar desde el principio de la línea y el segundo número indica cuántos dígitos cortar. Por ejemplo, supongamos que tiene una columna de fecha que contiene fechas en el formato STRING. En este caso, las fechas se ven así: 20190103. Si desea extraer un año de esta línea, SUBSTR lo ayudará a:
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301` CONCAT (column_name, etc.) pega valores. Usemos la columna de fecha del ejemplo anterior. Suponga que desea que todas las fechas se registren así: 2019-03-01. Para convertir fechas de su formato actual a este formato, se pueden usar dos funciones de cadena: primero, corte las partes necesarias de la cadena con SUBSTR, luego péguelas a través del guión:
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301` REGEXP_CONTAINS devuelve los valores de las columnas en las que aparece la expresión regular:
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301` Esta función se puede utilizar tanto en SELECT como en WHERE. Por ejemplo, en DONDE, puede seleccionar páginas específicas con él:
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order')
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order') 4. Funciones de fecha
A menudo, las fechas en las tablas se registran en formato STRING. Si planea visualizar los resultados en Google Data Studio, las fechas en la tabla deben convertirse al formato de FECHA usando la función PARSE_DATE.
PARSE_DATE convierte una STRING del formato 1900-01-01 al formato DATE.
Si las fechas en sus tablas se ven diferentes (por ejemplo, 19000101 o 01_01_1900), primero debe convertirlas al formato especificado.
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301` DATE_DIFF calcula cuánto tiempo ha pasado entre dos fechas en días, semanas, meses o años. Es útil si necesita determinar el intervalo entre el momento en que un usuario vio publicidad y realizó un pedido. Así es como se ve la función en una solicitud:
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301` Si desea obtener más información sobre las funciones enumeradas, lea Funciones de Google de BigQuery: una revisión detallada.
Consultas SQL para informes de marketing
El dialecto SQL estándar permite a las empresas extraer la máxima información de los datos con una segmentación profunda, auditorías técnicas, análisis de KPI de marketing e identificación de contratistas desleales en las redes de CPA. Estos son ejemplos de problemas comerciales en los que las consultas SQL sobre los datos recopilados en Google BigQuery lo ayudarán.
1. Análisis ROPO: evaluar la contribución de las campañas online a las ventas offline. Para realizar un análisis de ROPO, debe combinar datos sobre el comportamiento de los usuarios en línea con datos de su CRM, sistema de seguimiento de llamadas y aplicación móvil.
Si hay una clave en una y la segunda base, un parámetro común que es único para cada usuario (por ejemplo, ID de usuario), puede realizar un seguimiento:
qué usuarios visitaron el sitio antes de comprar productos en la tienda
cómo se comportaron los usuarios en el sitio
cuánto tiempo tardaron los usuarios en tomar una decisión de compra
qué campañas tuvieron el mayor aumento en las compras fuera de línea.
2. Segmente a los clientes por cualquier combinación de parámetros, desde el comportamiento en el sitio (páginas visitadas, productos vistos, número de visitas al sitio antes de comprar) hasta el número de tarjeta de fidelización y los artículos comprados.
3. Averigüe qué socios de CPA están trabajando de mala fe y reemplazando las etiquetas UTM.
4. Analizar el progreso de los usuarios a través del embudo de ventas.
Hemos preparado una selección de consultas en dialecto SQL estándar. Si ya recopila datos de su sitio, de fuentes publicitarias y de su sistema CRM en Google BigQuery, puede usar estas plantillas para resolver sus problemas comerciales. Simplemente reemplaza el nombre del proyecto, el conjunto de datos y la tabla en BigQuery por los tuyos. En la colección, recibirá 11 consultas SQL.
Para los datos recopilados mediante la exportación estándar de Google Analytics 360 a Google BigQuery:
- Acciones del usuario en el contexto de cualquier parámetro
- Estadísticas sobre acciones clave de los usuarios
- Usuarios que vieron páginas de productos específicos
- Acciones de los usuarios que compraron un producto en particular
- Configurar el embudo con los pasos necesarios
- Eficacia del sitio de búsqueda interna
Para los datos recopilados en Google BigQuery mediante OWOX BI:
- Consumo atribuido por fuente y canal
- Coste medio de atraer a un visitante por ciudad
- ROAS de beneficio bruto por fuente y canal
- Número de pedidos en el CRM por forma de pago y forma de entrega
- Tiempo medio de entrega por ciudad
Si tiene preguntas sobre la consulta de datos de Google BigQuery para las que no encontró respuestas en este artículo, pregunte en los comentarios. Intentaremos ayudarte.