
SQL standard in Google BigQuery: vantaggi ed esempi di utilizzo nel marketing
Pubblicato: 2022-04-12Nel 2016 Google BigQuery ha introdotto un nuovo modo di comunicare con le tabelle: SQL standard. Fino ad allora, BigQuery aveva un proprio linguaggio di query strutturato chiamato BigQuery SQL (ora chiamato Legacy SQL).
A prima vista, non c'è molta differenza tra Legacy e Standard SQL: i nomi delle tabelle sono scritti in modo leggermente diverso; Standard ha requisiti grammaticali leggermente più rigidi (ad esempio, non è possibile inserire una virgola prima di FROM) e più tipi di dati. Ma se guardi da vicino, ci sono alcune piccole modifiche alla sintassi che offrono molti vantaggi agli esperti di marketing.
In questo articolo, riceverai le risposte alle seguenti domande:
- Quali sono i vantaggi di Standard SQL rispetto a Legacy SQL?
- Quali sono le funzionalità di Standard SQL e come viene utilizzato?
- Come posso passare da Legacy a SQL standard?
- Con quali altri servizi, caratteristiche della sintassi, operatori e funzioni è compatibile SQL standard?
- Come posso utilizzare le query SQL per i rapporti di marketing?
Quali sono i vantaggi di Standard SQL rispetto a Legacy SQL?
Nuovi tipi di dati: array e campi nidificati
L'SQL standard supporta nuovi tipi di dati: ARRAY e STRUCT (array e campi nidificati). Ciò significa che in BigQuery è diventato più facile lavorare con tabelle caricate da file JSON/Avro, che spesso contengono allegati multilivello.
Un campo annidato è una mini tabella all'interno di una più grande:
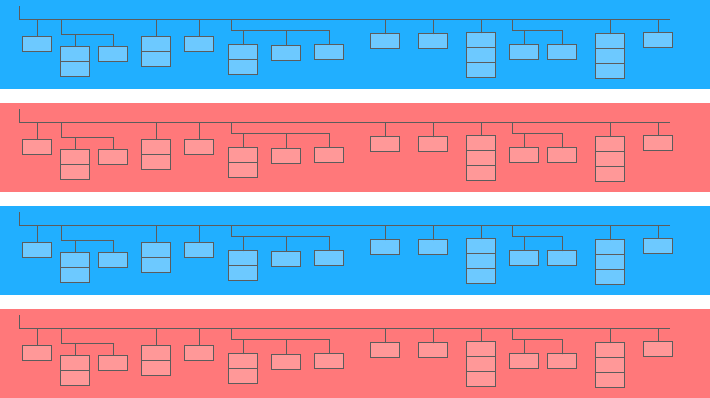
Nel diagramma sopra, le barre blu e gialle sono le linee in cui sono incorporate le mini tabelle. Ogni riga è una sessione. Le sessioni hanno parametri comuni: data, numero ID, categoria del dispositivo utente, browser, sistema operativo, ecc. Oltre ai parametri generali di ciascuna sessione, alla riga è allegata la tabella degli accessi.

La tabella dei risultati contiene informazioni sulle azioni degli utenti sul sito. Ad esempio, se un utente fa clic su un banner, sfoglia il catalogo, apre la pagina di un prodotto, inserisce un prodotto nel carrello o effettua un ordine, queste azioni verranno registrate nella tabella dei risultati.
Se un utente effettua un ordine sul sito, le informazioni sull'ordine verranno inserite anche nella tabella dei risultati:
- TransactionId (numero identificativo della transazione)
- TransactionRevenue (valore totale dell'ordine)
- transazioneSpedizione (costi di spedizione)
Le tabelle dei dati di sessione raccolte utilizzando OWOX BI hanno una struttura simile.
Si supponga di voler conoscere il numero di ordini degli utenti a New York nell'ultimo mese. Per scoprirlo, devi fare riferimento alla tabella dei risultati e contare il numero di ID transazione univoci. Per estrarre i dati da tali tabelle, Standard SQL ha una funzione UNNEST:
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City Se le informazioni sull'ordine sono state registrate in una tabella separata e non in una tabella nidificata, è necessario utilizzare JOIN per combinare la tabella con le informazioni sull'ordine e la tabella con i dati della sessione per scoprire in quali sessioni sono stati effettuati gli ordini.
Altre opzioni di sottoquery
Se devi estrarre dati da campi nidificati multilivello, puoi aggiungere sottoquery con SELECT e WHERE. Ad esempio, nelle tabelle di streaming della sessione OWOX BI, un'altra sottotabella, prodotto, viene scritta nella sottotabella hits. La sottotabella del prodotto raccoglie i dati del prodotto che vengono trasmessi con un array di e-commerce avanzato. Se sul sito è impostato un e-commerce avanzato e un utente ha visualizzato la pagina di un prodotto, le caratteristiche di questo prodotto verranno registrate nella sottotabella del prodotto.
Per ottenere queste caratteristiche del prodotto, avrai bisogno di una sottoquery all'interno della query principale. Per ciascuna caratteristica del prodotto, tra parentesi viene creata una sottoquery SELECT separata:
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD`
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` Grazie alle funzionalità di Standard SQL, è più facile creare una logica di query e scrivere codice. Per fare un confronto, in Legacy SQL, dovresti scrivere questo tipo di ladder:
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )Richieste a fonti esterne
Utilizzando l'SQL standard, puoi accedere alle tabelle BigQuery direttamente da Google Bigtable, Google Cloud Storage, Google Drive e Fogli Google.
Cioè, invece di caricare l'intera tabella in BigQuery, puoi eliminare i dati con una singola query, selezionare i parametri che ti servono e caricarli nel cloud storage.
Altre funzioni utente (UDF)
Se devi utilizzare una formula che non è documentata, le funzioni definite dall'utente (UDF) ti aiuteranno. Nella nostra pratica, ciò accade raramente, poiché la documentazione SQL standard copre quasi tutte le attività dell'analisi digitale.
In Standard SQL, le funzioni definite dall'utente possono essere scritte in SQL o JavaScript; L'SQL legacy supporta solo JavaScript. Gli argomenti di queste funzioni sono colonne e i valori che assumono sono il risultato della manipolazione delle colonne. In Standard SQL, le funzioni possono essere scritte nella stessa finestra delle query.
Altre condizioni UNISCITI
In Legacy SQL, le condizioni JOIN possono essere basate sull'uguaglianza o sui nomi delle colonne. Oltre a queste opzioni, il dialetto SQL standard supporta JOIN per disuguaglianza e per espressione arbitraria.
Ad esempio, per identificare i partner CPA sleali, possiamo selezionare sessioni in cui l'origine è stata sostituita entro 60 secondi dalla transazione. Per fare ciò in Standard SQL, possiamo aggiungere una disuguaglianza alla condizione JOIN:
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime L'unica limitazione di Standard SQL rispetto a JOIN è che non consente il semi-join con sottoquery della colonna WHERE IN (SELECT ...):
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESC
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESCMeno possibilità di errori
Alcune funzioni in Legacy SQL restituiscono NULL se la condizione non è corretta. Ad esempio, se la divisione per zero si è insinuata nei calcoli, la query verrà eseguita e le voci NULL verranno visualizzate nelle righe risultanti della tabella. Ciò potrebbe mascherare problemi nella query o nei dati.
La logica di Standard SQL è più semplice. Se una condizione o un dato di input non è corretto, la query genererà un errore, ad esempio «divisione per zero», in modo da poter correggere rapidamente la query. I seguenti controlli sono incorporati in Standard SQL:
- Valori validi per +, -, ×, SUM, AVG, DEV.ST
- Divisione per zero
Le richieste vengono eseguite più velocemente
Le query JOIN scritte in Standard SQL sono più veloci di quelle scritte in Legacy SQL grazie al filtraggio preliminare dei dati in entrata. Innanzitutto, la query seleziona le righe che soddisfano le condizioni JOIN, quindi le elabora.
In futuro, Google BigQuery lavorerà per migliorare la velocità e le prestazioni delle query solo per SQL standard.
Le tabelle possono essere modificate: inserisci e cancella righe, aggiorna
Le funzioni di Data Manipulation Language (DML) sono disponibili in SQL standard. Ciò significa che puoi aggiornare le tabelle e aggiungere o rimuovere righe da esse attraverso la stessa finestra in cui scrivi le query. Ad esempio, utilizzando DML, puoi combinare i dati di due tabelle in una:
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)Il codice è più facile da leggere e modificare
Con Standard SQL, è possibile avviare query complesse non solo con SELECT ma anche con WITH, rendendo il codice più facile da leggere, commentare e comprendere. Ciò significa anche che è più facile prevenire i propri errori e correggere gli errori degli altri.
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2 È conveniente lavorare con l'operatore WITH se si dispone di calcoli eseguiti in più fasi. Innanzitutto, puoi raccogliere le metriche intermedie nelle sottoquery, quindi eseguire i calcoli finali.
La Google Cloud Platform (GCP), che include BigQuery, è una piattaforma a ciclo completo per lavorare con i big data, dall'organizzazione di un data warehouse o di un data cloud all'esecuzione di esperimenti scientifici e analisi predittive e prescrittive. Con l'introduzione dell'SQL standard, BigQuery sta ampliando il suo pubblico. Lavorare con GCP sta diventando sempre più interessante per analisti di marketing, analisti di prodotto, data scientist e team di altri specialisti.
Capacità di Standard SQL ed esempi di casi d'uso
In OWOX BI, lavoriamo spesso con tabelle compilate utilizzando l'esportazione standard di Google Analytics 360 su Google BigQuery o OWOX BI Pipeline. Negli esempi seguenti, esamineremo le specifiche delle query SQL per tali dati.
Se non stai già raccogliendo dati dal tuo sito in BigQuery, puoi provare a farlo gratuitamente con la versione di prova di OWOX BI.
1. Selezionare i dati per un intervallo di tempo
In Google BigQuery, i dati sul comportamento degli utenti per il tuo sito sono archiviati in tabelle con caratteri jolly (tabelle con un asterisco); per ogni giorno viene formata una tabella separata. Queste tabelle hanno lo stesso nome: solo il suffisso è diverso. Il suffisso è la data nel formato AAAAMMGG. Ad esempio, la tabella owoxbi_sessions_20190301 contiene i dati sulle sessioni del 1 marzo 2019.
Possiamo fare riferimento direttamente a un gruppo di tali tabelle in una richiesta per ottenere dati, ad esempio, dal 1 febbraio al 28 febbraio 2019. Per fare ciò, è necessario sostituire AAAAMMGG con un * in FROM e in WHERE, dobbiamo specificare i suffissi della tabella per l'inizio e la fine dell'intervallo di tempo:
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �'
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �' Le date specifiche per le quali desideriamo raccogliere i dati non ci sono sempre note. Ad esempio, ogni settimana potrebbe essere necessario analizzare i dati degli ultimi tre mesi. Per fare ciò, possiamo utilizzare la funzione FORMAT_DATE:
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) Dopo BETWEEN, registriamo il suffisso della prima tabella. La frase CURRENT_DATE (), INTERVAL 3 MONTHS significa "selezionare i dati degli ultimi 3 mesi dalla data corrente." Il secondo suffisso della tabella è formattato dopo AND. È necessario contrassegnare la fine dell'intervallo come ieri: CURRENT_DATE (), INTERVAL 1 DAY.
2. Recuperare parametri e indicatori utente
I parametri utente e le metriche nelle tabelle di esportazione di Google Analytics vengono scritti nella tabella dei risultati nidificati e nelle sottotabelle customDimensions e customMetrics. Tutte le dimensioni personalizzate sono registrate in due colonne: una per il numero di parametri raccolti sul sito, la seconda per i loro valori. Ecco come appaiono tutti i parametri trasmessi con un colpo:
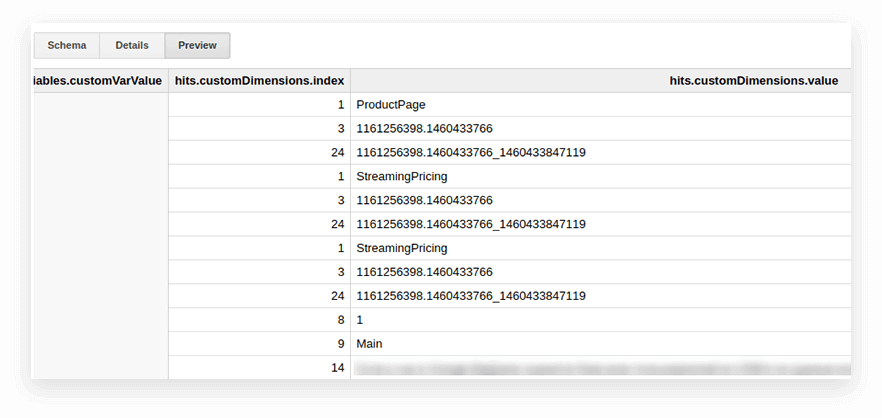
Per decomprimerli e scrivere i parametri necessari in colonne separate, utilizziamo la seguente query SQL:
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 Ecco come appare nella richiesta:
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201` Nello screenshot seguente, abbiamo selezionato i parametri 1 e 2 dai dati demo di Google Analytics 360 in Google BigQuery e li abbiamo chiamati page_type e client_id. Ogni parametro è registrato in una colonna separata:

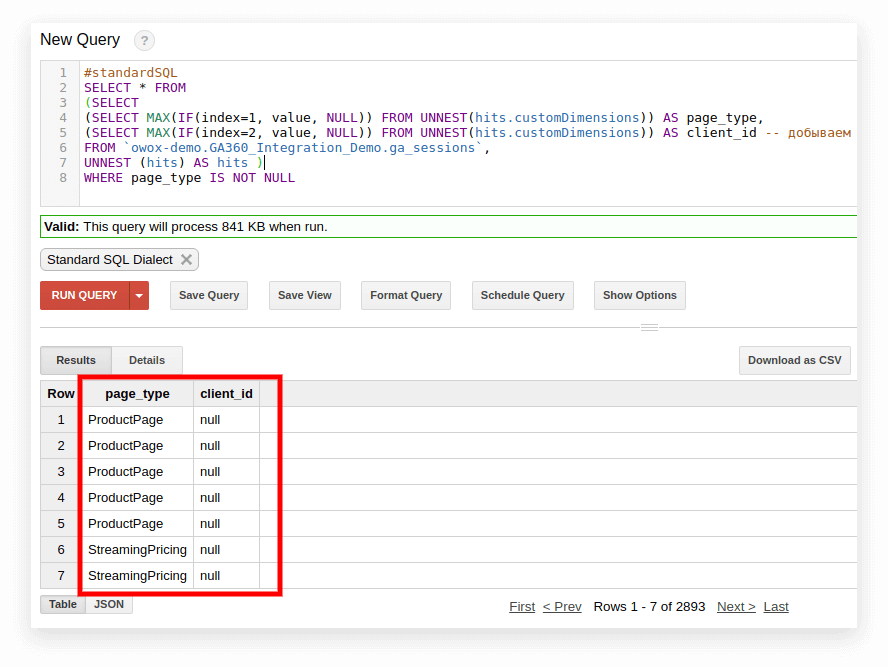
3. Calcola il numero di sessioni per fonte di traffico, canale, campagna, città e categoria di dispositivo
Tali calcoli sono utili se prevedi di visualizzare i dati in Google Data Studio e filtrare per città e categoria di dispositivo. Questo è facile da fare con la funzione della finestra COUNT:
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`4. Combina gli stessi dati da più tabelle
Supponiamo di raccogliere dati sugli ordini completati in diverse tabelle BigQuery: una raccoglie tutti gli ordini dal negozio A, l'altra raccoglie gli ordini dal negozio B. Vuoi combinarli in una tabella con queste colonne:
- client_id — un numero che identifica un acquirente univoco
- transazione_creata: ora di creazione dell'ordine in formato TIMESTAMP
- Transaction_id — numero dell'ordine
- is_approved — se l'ordine è stato confermato
- Transaction_revenue — importo dell'ordine
Nel nostro esempio gli ordini dal 1 gennaio 2018 a ieri devono essere nella tabella. Per fare ciò, seleziona le colonne appropriate da ciascun gruppo di tabelle, assegna loro lo stesso nome e combina i risultati con UNION ALL:
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC5. Creare un dizionario di gruppi di canali di traffico
Quando i dati entrano in Google Analytics, il sistema determina automaticamente il gruppo a cui appartiene una particolare transizione: diretta, ricerca organica, ricerca a pagamento e così via. Per identificare un gruppo di canali, Google Analytics esamina i tag UTM delle transizioni, ovvero utm_source e utm_medium. Puoi leggere ulteriori informazioni sui gruppi di canali e sulle regole di definizione nella Guida di Google Analytics.
Se i clienti OWOX BI vogliono assegnare i propri nomi a gruppi di canali, creiamo un dizionario, la cui transizione appartiene a un canale specifico. Per fare ciò, utilizziamo l'operatore CASE condizionale e la funzione REGEXP_CONTAINS. Questa funzione seleziona i valori in cui si verifica l'espressione regolare specificata.
Ti consigliamo di prendere i nomi dal tuo elenco di fonti in Google Analytics. Ecco un esempio di come aggiungere tali condizioni al corpo della richiesta:
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201` Come passare all'SQL standard
Se non sei ancora passato a Standard SQL, puoi farlo in qualsiasi momento. La cosa principale è evitare di mescolare i dialetti in una richiesta.
Opzione 1. Passa nell'interfaccia di Google BigQuery
L'SQL legacy viene utilizzato per impostazione predefinita nella vecchia interfaccia di BigQuery. Per passare da un dialetto all'altro, fai clic su Mostra opzioni nel campo di input della query e deseleziona la casella Usa SQL legacy accanto a Dialetto SQL.
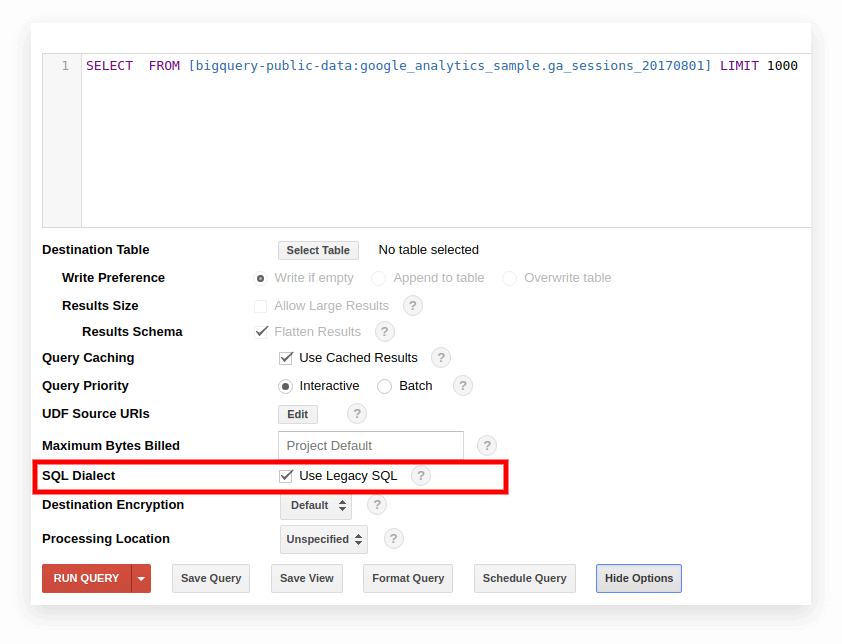
La nuova interfaccia utilizza Standard SQL per impostazione predefinita. Qui, devi andare alla scheda Altro per cambiare dialetto:
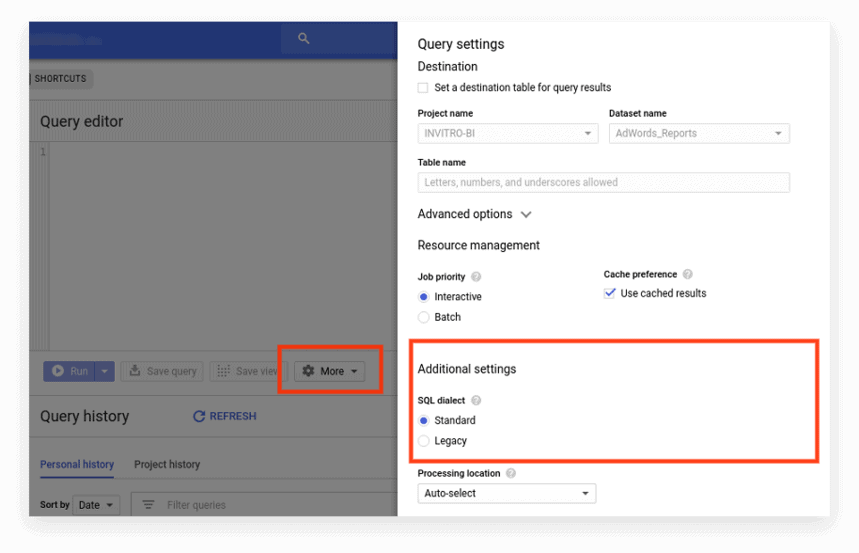
Opzione 2. Scrivi il prefisso all'inizio della richiesta
Se non hai spuntato le impostazioni della richiesta, puoi iniziare con il prefisso desiderato (#standardSQL o #legacySQL):
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10;
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10; In questo caso, Google BigQuery ignorerà le impostazioni nell'interfaccia ed eseguirà la query utilizzando il dialetto specificato nel prefisso.
Se hai visualizzazioni o query salvate che vengono avviate in base a una pianificazione utilizzando Apps Script, non dimenticare di modificare il valore di useLegacySql su false nello script:
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }Opzione 3. Transizione a SQL standard per le viste
Se lavori con Google BigQuery non con le tabelle ma con le viste, non è possibile accedere a tali viste nel dialetto SQL standard. Cioè, se la tua presentazione è scritta in Legacy SQL, non puoi scrivervi richieste in Standard SQL.
Per trasferire una vista in SQL standard, è necessario riscrivere manualmente la query con cui è stata creata. Il modo più semplice per farlo è tramite l'interfaccia di BigQuery.
1. Apri la vista:
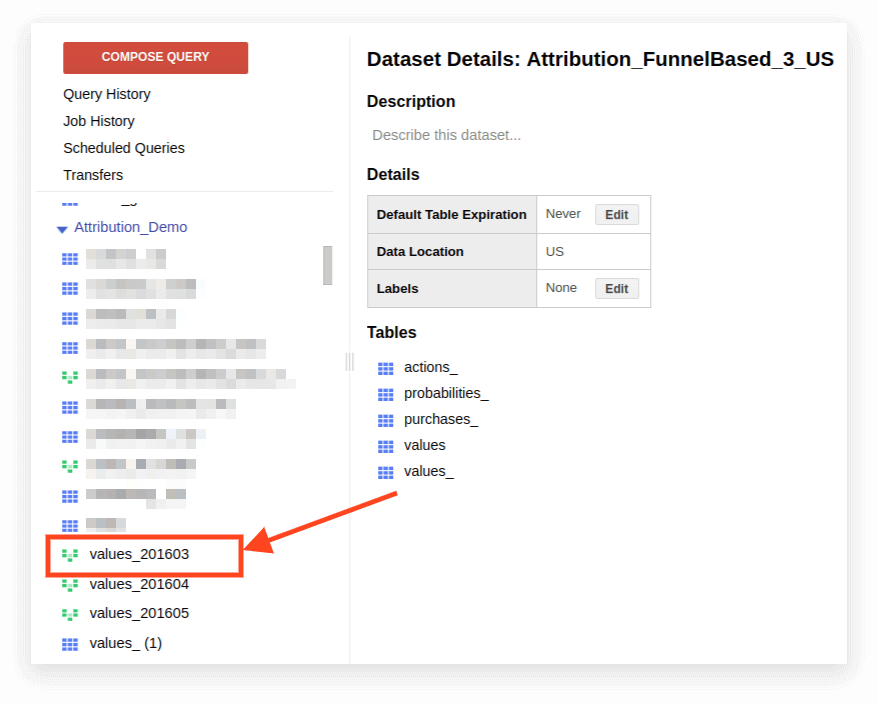
2. Fare clic su Dettagli. Il testo della query dovrebbe aprirsi e il pulsante Modifica query apparirà di seguito:
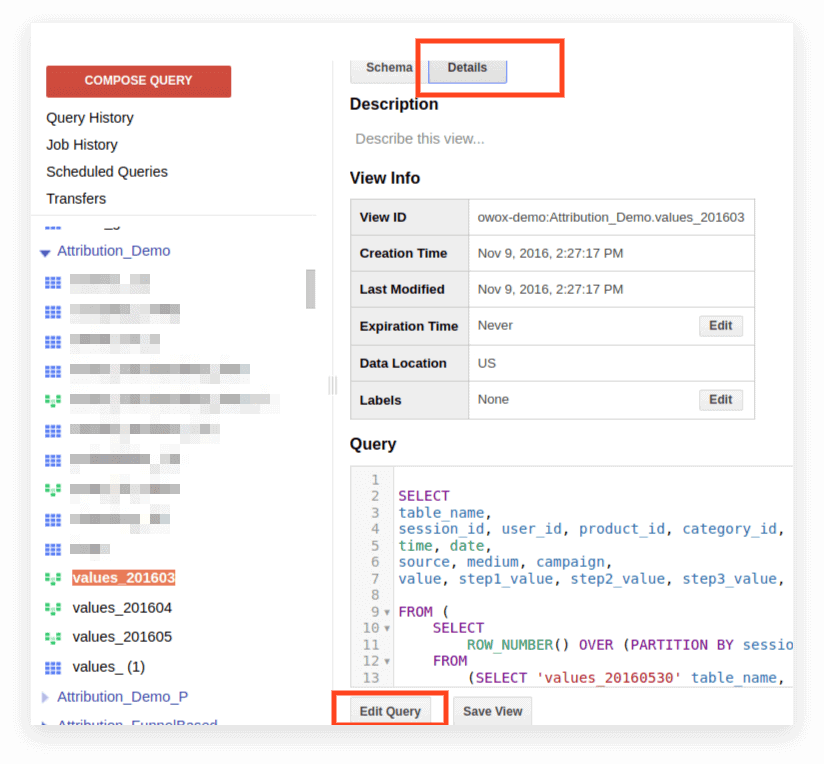
Ora puoi modificare la richiesta secondo le regole di Standard SQL.
Se intendi continuare a utilizzare la richiesta come presentazione, fai clic su Salva vista al termine della modifica.
Compatibilità, caratteristiche sintattiche, operatori, funzioni
Compatibilità
Grazie all'implementazione di Standard SQL, puoi accedere direttamente ai dati archiviati in altri servizi direttamente da BigQuery:
- File di registro di Google Cloud Storage
- Record transazionali in Google Bigtable
- Dati da altre fonti
Ciò ti consente di utilizzare i prodotti Google Cloud Platform per qualsiasi attività analitica, inclusa l'analisi predittiva e prescrittiva basata su algoritmi di apprendimento automatico.
Sintassi della query
La struttura della query nel dialetto Standard è quasi la stessa di Legacy:
I nomi delle tabelle e della vista sono separati da un punto (punto) e l'intera query è racchiusa in accenti gravi: `project_name.data_name_name.table_name``bigquery-public-data.samples.natality`
La sintassi completa della query, con le spiegazioni di cosa può essere incluso in ciascun operatore, viene compilata come schema nella documentazione di BigQuery.
Caratteristiche della sintassi SQL standard:
- Le virgole sono necessarie per elencare i campi nell'istruzione SELECT.
- Se si utilizza l'operatore UNNEST dopo FROM , viene inserita una virgola o JOIN prima di UNNEST.
- Non puoi mettere una virgola prima di FROM.
- Una virgola tra due query equivale a un CROSS JOIN, quindi fai attenzione.
- JOIN può essere fatto non solo per colonna o uguaglianza, ma anche per espressioni arbitrarie e disuguaglianza.
- È possibile scrivere sottoquery complesse in qualsiasi parte dell'espressione SQL (in SELECT, FROM, WHERE, ecc.). In pratica, non è ancora possibile utilizzare espressioni come WHERE nome_colonna IN (SELECT ...) come invece è possibile in altri database.
Operatori
In Standard SQL, gli operatori definiscono il tipo di dati. Ad esempio, un array viene sempre scritto tra parentesi quadre []. Gli operatori vengono utilizzati per il confronto, la corrispondenza dell'espressione logica (NOT, OR, AND) e nei calcoli aritmetici.
Funzioni
Standard SQL supporta più funzionalità rispetto a Legacy: aggregazione tradizionale (somma, numero, minimo, massimo); funzioni matematiche, di stringa e statistiche; e formati rari come HyperLogLog ++.
Nel dialetto Standard, ci sono più funzioni per lavorare con date e TIMESTAMP. Un elenco completo delle funzioni è fornito nella documentazione di Google. Le funzioni più comunemente utilizzate sono per lavorare con date, stringhe, aggregazione e finestra.
1. Funzioni di aggregazione
COUNT (DISTINCT column_name) conta il numero di valori univoci in una colonna. Ad esempio, supponiamo di dover contare il numero di sessioni da dispositivi mobili il 1 marzo 2019. Poiché un numero di sessione può essere ripetuto su righe diverse, vogliamo contare solo i valori del numero di sessione univoci:
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile' SUM (nome_colonna) — la somma dei valori nella colonna
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile' MIN (nome_colonna) | MAX (nome_colonna) — il valore minimo e massimo nella colonna. Queste funzioni sono utili per controllare la diffusione dei dati in una tabella.
2. Funzioni della finestra (analitiche).
Le funzioni analitiche considerano i valori non per l'intera tabella ma per una determinata finestra, un insieme di righe che ti interessa. Cioè, puoi definire segmenti all'interno di una tabella. Ad esempio, puoi calcolare SUM (ricavi) non per tutte le linee ma per città, categorie di dispositivi e così via. È possibile attivare le funzioni analitiche SUM, COUNT e AVG nonché altre funzioni di aggregazione aggiungendo la condizione OVER (PARTITION BY nome_colonna).
Ad esempio, devi contare il numero di sessioni per fonte di traffico, canale, campagna, città e categoria di dispositivo. In questo caso, possiamo usare la seguente espressione:
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t OVER determina la finestra per la quale verranno effettuati i calcoli. PARTITION BY indica quali righe devono essere raggruppate per il calcolo. In alcune funzioni è necessario specificare l'ordine di raggruppamento con ORDER BY.
Per un elenco completo delle funzioni della finestra, consulta la documentazione di BigQuery.
3. Funzioni di stringa
Questi sono utili quando è necessario modificare il testo, formattare il testo in una riga o incollare i valori delle colonne. Ad esempio, le funzioni di stringa sono ottime se desideri generare un identificatore di sessione univoco dai dati di esportazione standard di Google Analytics 360. Consideriamo le funzioni di stringa più popolari.
SUBSTR taglia parte della corda. Nella richiesta, questa funzione è scritta come SUBSTR (nome_stringa, 0.4). Il primo numero indica quanti caratteri saltare dall'inizio della riga e il secondo numero indica quante cifre tagliare. Ad esempio, supponiamo di avere una colonna di data che contiene date nel formato STRING. In questo caso, le date si presentano così: 20190103. Se vuoi estrarre un anno da questa riga, SUBSTR ti aiuterà:
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301` CONCAT (nome_colonna, ecc.) incolla i valori. Usiamo la colonna della data dell'esempio precedente. Supponiamo di voler registrare tutte le date in questo modo: 01-03-2019. Per convertire le date dal formato corrente in questo formato, è possibile utilizzare due funzioni di stringa: prima, taglia i pezzi necessari della stringa con SUBSTR, quindi incollali tramite il trattino:
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301` REGEXP_CONTAINS restituisce i valori delle colonne in cui si verifica l'espressione regolare:
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301` Questa funzione può essere utilizzata sia in SELECT che in WHERE. Ad esempio, in DOVE, puoi selezionare pagine specifiche con esso:
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order')
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order') 4. Funzioni di data
Spesso le date nelle tabelle sono registrate in formato STRING. Se prevedi di visualizzare i risultati in Google Data Studio, le date nella tabella devono essere convertite nel formato DATE utilizzando la funzione PARSE_DATE.
PARSE_DATE converte una STRING dal formato 1900-01-01 nel formato DATE.
Se le date nelle tabelle hanno un aspetto diverso (ad esempio, 19000101 o 01_01_1900), devi prima convertirle nel formato specificato.
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301` DATE_DIFF calcola quanto tempo è trascorso tra due date in giorni, settimane, mesi o anni. È utile se è necessario determinare l'intervallo tra il momento in cui un utente ha visto la pubblicità e ha effettuato un ordine. Ecco come appare la funzione in una richiesta:
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301` Se vuoi saperne di più sulle funzioni elencate, leggi BigQuery Google Features: A Detailed Review.
Query SQL per report di marketing
Il dialetto SQL standard consente alle aziende di estrarre il massimo delle informazioni dai dati con una segmentazione approfondita, audit tecnici, analisi KPI di marketing e identificazione di appaltatori sleali nelle reti CPA. Ecco alcuni esempi di problemi aziendali in cui le query SQL sui dati raccolti in Google BigQuery ti aiuteranno.
1. Analisi ROPO: valutare il contributo delle campagne online alle vendite offline. Per eseguire l'analisi ROPO, devi combinare i dati sul comportamento degli utenti online con i dati del tuo CRM, del sistema di tracciamento delle chiamate e dell'applicazione mobile.
Se è presente una chiave in una e nella seconda base, un parametro comune univoco per ogni utente (ad esempio, ID utente), puoi tenere traccia di:
quali utenti hanno visitato il sito prima di acquistare la merce in negozio
come si sono comportati gli utenti sul sito
quanto tempo hanno impiegato gli utenti per prendere una decisione di acquisto
quali campagne hanno avuto il maggiore aumento sugli acquisti offline.
2. Segmentare i clienti in base a qualsiasi combinazione di parametri, dal comportamento sul sito (pagine visitate, prodotti visualizzati, numero di visite al sito prima dell'acquisto) al numero di carta fedeltà e agli articoli acquistati.
3. Scopri quali partner CPA stanno lavorando in malafede e stanno sostituendo i tag UTM.
4. Analizza i progressi degli utenti attraverso il funnel di vendita.
Abbiamo preparato una selezione di query nel dialetto SQL standard. Se raccogli già dati dal tuo sito, da fonti pubblicitarie e dal tuo sistema CRM in Google BigQuery, puoi utilizzare questi modelli per risolvere i tuoi problemi aziendali. Sostituisci semplicemente il nome del progetto, il set di dati e la tabella in BigQuery con i tuoi. Nella raccolta riceverai 11 query SQL.
Per i dati raccolti utilizzando l'esportazione standard da Google Analytics 360 a Google BigQuery:
- Azioni dell'utente nel contesto di qualsiasi parametro
- Statistiche sulle azioni chiave dell'utente
- Utenti che hanno visualizzato pagine di prodotti specifici
- Azioni degli utenti che hanno acquistato un determinato prodotto
- Configura la canalizzazione con tutti i passaggi necessari
- Efficacia del sito di ricerca interno
Per i dati raccolti in Google BigQuery utilizzando OWOX BI:
- Consumo attribuito per fonte e canale
- Costo medio per attirare un visitatore per città
- ROAS per l'utile lordo per fonte e canale
- Numero di ordini nel CRM per metodo di pagamento e metodo di consegna
- Tempi di consegna medi per città
Se hai domande sull'interrogazione dei dati di Google BigQuery a cui non hai trovato risposte in questo articolo, chiedi nei commenti. Cercheremo di aiutarti.