
Стандартный SQL в Google BigQuery: преимущества и примеры использования в маркетинге
Опубликовано: 2022-04-12В 2016 году Google BigQuery представил новый способ взаимодействия с таблицами: стандартный SQL. До этого у BigQuery был собственный язык структурированных запросов под названием BigQuery SQL (сейчас он называется Legacy SQL).
На первый взгляд особой разницы между Legacy и Standard SQL нет: имена таблиц пишутся немного по-разному; Стандарт имеет несколько более строгие требования к грамматике (например, нельзя ставить запятую перед FROM) и больше типов данных. Но если присмотреться, есть небольшие изменения синтаксиса, которые дают маркетологам много преимуществ.
В этой статье вы получите ответы на следующие вопросы:
- Каковы преимущества стандартного SQL по сравнению с устаревшим SQL?
- Каковы возможности стандартного SQL и как он используется?
- Как перейти с Legacy на Standard SQL?
- С какими другими службами, функциями синтаксиса, операторами и функциями совместим стандартный SQL?
- Как я могу использовать SQL-запросы для маркетинговых отчетов?
Каковы преимущества стандартного SQL по сравнению с устаревшим SQL?
Новые типы данных: массивы и вложенные поля
Стандартный SQL поддерживает новые типы данных: ARRAY и STRUCT (массивы и вложенные поля). Это означает, что в BigQuery стало проще работать с таблицами, загружаемыми из файлов JSON/Avro, которые часто содержат многоуровневые вложения.
Вложенное поле представляет собой мини-таблицу внутри более крупной:
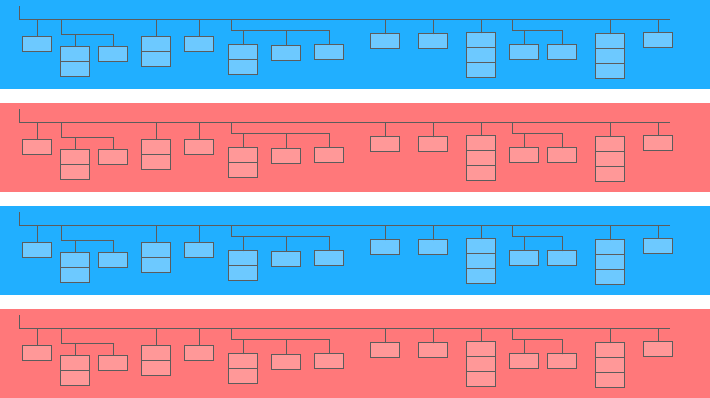
На диаграмме выше синие и желтые полосы — это строки, в которые встроены мини-таблицы. Каждая строка — это один сеанс. Сессии имеют общие параметры: дата, идентификационный номер, категория пользовательского устройства, браузер, операционная система и т.д. Помимо общих параметров для каждой сессии, к строке прилагается таблица хитов.

Таблица посещений содержит информацию о действиях пользователей на сайте. Например, если пользователь нажимает на баннер, пролистывает каталог, открывает страницу товара, кладет товар в корзину или оформляет заказ, эти действия будут зафиксированы в таблице обращений.
Если пользователь размещает заказ на сайте, информация о заказе также будет занесена в таблицу обращений:
- transactionId (номер, идентифицирующий транзакцию)
- transactionRevenue (общая стоимость заказа)
- сделкаДоставка (стоимость доставки)
Таблицы данных сеанса, собранные с помощью OWOX BI, имеют схожую структуру.
Предположим, вы хотите узнать количество заказов от пользователей из Нью-Йорка за последний месяц. Чтобы это узнать, нужно обратиться к таблице совпадений и подсчитать количество уникальных идентификаторов транзакций. Для извлечения данных из таких таблиц в Standard SQL есть функция UNNEST:
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City Если бы информация о заказе была записана в отдельную таблицу, а не во вложенную таблицу, вам пришлось бы использовать JOIN для объединения таблицы с информацией о заказе и таблицы с данными сеанса, чтобы узнать, в каких сеансах заказы были сделаны.
Дополнительные параметры подзапроса
Если вам нужно извлечь данные из многоуровневых вложенных полей, вы можете добавить подзапросы с помощью SELECT и WHERE. Например, в таблицах стриминга сессий OWOX BI в подтаблицу hits записывается другая подтаблица product. Подтаблица product собирает данные о товарах, которые передаются с помощью массива расширенной электронной торговли. Если на сайте настроена расширенная электронная коммерция и пользователь просмотрел страницу товара, характеристики этого товара будут записаны в подтаблицу товаров.
Чтобы получить эти характеристики продукта, вам понадобится подзапрос внутри основного запроса. Для каждой характеристики товара создается отдельный подзапрос SELECT в скобках:
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD`
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` Благодаря возможностям стандартного SQL проще создавать логику запросов и писать код. Для сравнения, в Legacy SQL вам нужно было бы написать лестницу такого типа:
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )Запросы к внешним источникам
Используя стандартный SQL, вы можете получить доступ к таблицам BigQuery напрямую из Google Bigtable, Google Cloud Storage, Google Диска и Google Таблиц.
То есть вместо того, чтобы загружать всю таблицу в BigQuery, вы можете удалить данные одним единственным запросом, выбрать нужные вам параметры и загрузить их в облачное хранилище.
Дополнительные пользовательские функции (UDF)
Если вам нужно использовать формулу, которая не задокументирована, вам помогут пользовательские функции (UDF). В нашей практике такое случается редко, так как документация Standard SQL охватывает практически все задачи цифровой аналитики.
В стандартном SQL пользовательские функции могут быть написаны на SQL или JavaScript; Устаревший SQL поддерживает только JavaScript. Аргументами этих функций являются столбцы, а значения, которые они принимают, — результат манипулирования столбцами. В стандартном SQL функции можно писать в том же окне, что и запросы.
Дополнительные условия ПРИСОЕДИНЯЙТЕСЬ
В Legacy SQL условия JOIN могут быть основаны на равенстве или именах столбцов. В дополнение к этим параметрам диалект Standard SQL поддерживает JOIN по неравенству и по произвольному выражению.
Например, для выявления недобросовестных CPA-партнеров мы можем выбрать сеансы, в которых источник был заменен в течение 60 секунд после транзакции. Чтобы сделать это в стандартном SQL, мы можем добавить неравенство к условию JOIN:
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime Единственное ограничение стандартного SQL в отношении JOIN заключается в том, что он не допускает полусоединения с подзапросами формы WHERE column IN (SELECT...):
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESC
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESCМеньше шансов на ошибку
Некоторые функции в устаревшем SQL возвращают NULL, если условие неверно. Например, если в ваши расчеты закралось деление на ноль, запрос будет выполнен и в результирующих строках таблицы появятся записи NULL. Это может маскировать проблемы в запросе или данных.
Логика стандартного SQL более проста. Если условие или входные данные неверны, запрос выдаст ошибку, например «деление на ноль», чтобы можно было быстро исправить запрос. В стандартный SQL встроены следующие проверки:
- Допустимые значения для +, -, ×, SUM, AVG, STDEV
- Деление на ноль
Запросы выполняются быстрее
Запросы JOIN, написанные на Standard SQL, быстрее, чем на Legacy SQL, благодаря предварительной фильтрации входящих данных. Сначала запрос выбирает строки, соответствующие условиям JOIN, а затем обрабатывает их.
В дальнейшем Google BigQuery будет работать над улучшением скорости и производительности запросов только для Standard SQL.
Таблицы можно редактировать: вставлять и удалять строки, обновлять
Функции языка манипулирования данными (DML) доступны в стандартном SQL. Это означает, что вы можете обновлять таблицы и добавлять или удалять из них строки через то же окно, в котором пишете запросы. Например, с помощью DML можно объединить данные из двух таблиц в одну:
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)Код легче читать и редактировать
В стандартном SQL сложные запросы можно запускать не только с помощью SELECT, но и с помощью WITH, что упрощает чтение, комментирование и понимание кода. Это также означает, что легче предотвращать свои ошибки и исправлять чужие.
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2 С оператором WITH удобно работать, если у вас есть расчеты, которые выполняются в несколько этапов. Сначала можно собирать промежуточные метрики в подзапросах, потом делать окончательные расчеты.
Облачная платформа Google (GCP), в состав которой входит BigQuery, представляет собой платформу полного цикла для работы с большими данными, от организации хранилища данных или облака данных до проведения научных экспериментов и предиктивной и предписывающей аналитики. С появлением стандартного SQL BigQuery расширяет свою аудиторию. Работа с GCP становится все более интересной для маркетологов, продуктовых аналитиков, специалистов по данным и команд других специалистов.
Возможности Standard SQL и примеры использования
В OWOX BI мы часто работаем с таблицами, составленными с помощью стандартного экспорта Google Analytics 360 в Google BigQuery или OWOX BI Pipeline. В приведенных ниже примерах мы рассмотрим особенности SQL-запросов для таких данных.
Если вы еще не собираете данные со своего сайта в BigQuery, вы можете попробовать сделать это бесплатно с помощью пробной версии OWOX BI.
1. Выберите данные за временной интервал
В Google BigQuery данные о поведении пользователей для вашего сайта хранятся в таблицах с подстановочными знаками (таблицы со звездочкой); на каждый день формируется отдельная таблица. Эти таблицы имеют одинаковое имя: отличается только суффикс. Суффикс представляет собой дату в формате ГГГГММДД. Например, таблица owoxbi_sessions_20190301 содержит данные о сессиях на 1 марта 2019 года.
Мы можем обратиться сразу к группе таких таблиц в одном запросе, чтобы получить данные, например, с 1 февраля по 28 февраля 2019 года. Для этого нам нужно заменить ГГГГММДД на * в FROM, а в WHERE, нам нужно указать суффиксы таблицы для начала и конца временного интервала:
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �'
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �' Конкретные даты, за которые мы хотим собрать данные, нам не всегда известны. Например, каждую неделю нам может понадобиться анализировать данные за последние три месяца. Для этого мы можем использовать функцию FORMAT_DATE:
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) После BETWEEN записываем суффикс первой таблицы. Фраза CURRENT_DATE(), INTERVAL 3 MONTHS означает «выбрать данные за последние 3 месяца с текущей даты». Второй суффикс таблицы форматируется после AND. Нужно отметить конец интервала как вчера: CURRENT_DATE(), INTERVAL 1 DAY.
2. Получить пользовательские параметры и индикаторы
Пользовательские параметры и показатели в таблицах экспорта Google Analytics записываются во вложенную таблицу обращений и в подтаблицы customDimensions и customMetrics. Все специальные параметры записываются в две колонки: одна для количества параметров, собранных на сайте, вторая для их значений. Вот как выглядят все параметры, передаваемые одним хитом:
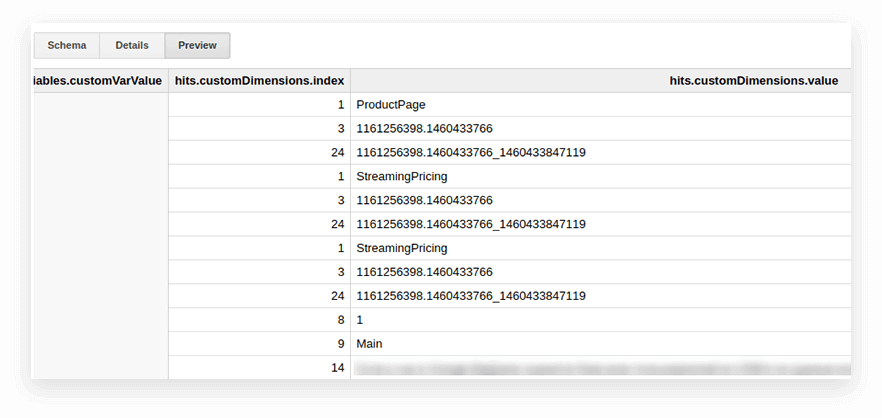
Для того, чтобы распаковать их и записать нужные параметры в отдельные столбцы, используем следующий SQL-запрос:
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 Вот как это выглядит в запросе:
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201` На скриншоте ниже мы выбрали параметры 1 и 2 из демонстрационных данных Google Analytics 360 в Google BigQuery и назвали их page_type и client_id. Каждый параметр записывается в отдельный столбец:

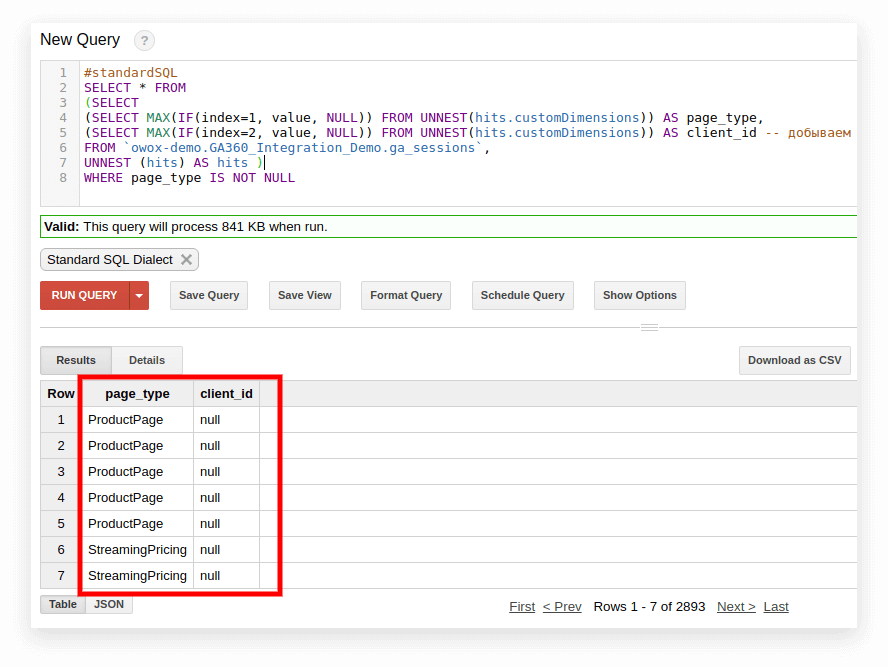
3. Подсчитайте количество сеансов по источнику трафика, каналу, кампании, городу и категории устройства.
Такие расчеты полезны, если вы планируете визуализировать данные в Google Data Studio и фильтровать по городам и категориям устройств. Это легко сделать с помощью оконной функции COUNT:
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`4. Объедините одинаковые данные из нескольких таблиц
Предположим, вы собираете данные о выполненных заказах в нескольких таблицах BigQuery: в одной собираются все заказы из Магазина А, в другой — заказы из Магазина Б. Вы хотите объединить их в одну таблицу с такими столбцами:
- client_id — номер, который идентифицирует уникального покупателя
- transaction_created — время создания ордера в формате TIMESTAMP
- transaction_id — номер заказа
- is_approved — был ли подтвержден заказ
- transaction_revenue — сумма заказа
В нашем примере в таблице должны быть заказы с 1 января 2018 года по вчерашний день. Для этого выберите соответствующие столбцы из каждой группы таблиц, присвойте им одинаковое имя и объедините результаты с помощью UNION ALL:
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC5. Создайте словарь групп каналов трафика
Когда данные поступают в Google Analytics, система автоматически определяет группу, к которой относится тот или иной переход: Прямой, Органический поиск, Платный поиск и так далее. Чтобы определить группу каналов, Google Analytics просматривает теги UTM переходов, а именно utm_source и utm_medium. Подробнее о группах каналов и правилах определения можно прочитать в справке Google Analytics.
Если клиенты OWOX BI хотят присвоить группам каналов свои имена, мы создаем словарь, переход которого относится к конкретному каналу. Для этого мы используем условный оператор CASE и функцию REGEXP_CONTAINS. Эта функция выбирает значения, в которых встречается указанное регулярное выражение.
Мы рекомендуем брать имена из вашего списка источников в Google Analytics. Вот пример того, как добавить такие условия в тело запроса:
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201` Как перейти на стандартный SQL
Если вы еще не перешли на стандартный SQL, вы можете сделать это в любое время. Главное не смешивать диалекты в одном запросе.
Вариант 1. Переключиться в интерфейсе Google BigQuery
Устаревший SQL по умолчанию используется в старом интерфейсе BigQuery. Чтобы переключиться между диалектами, нажмите « Показать параметры» под полем ввода запроса и снимите флажок « Использовать устаревший SQL » рядом с «Диалект SQL».
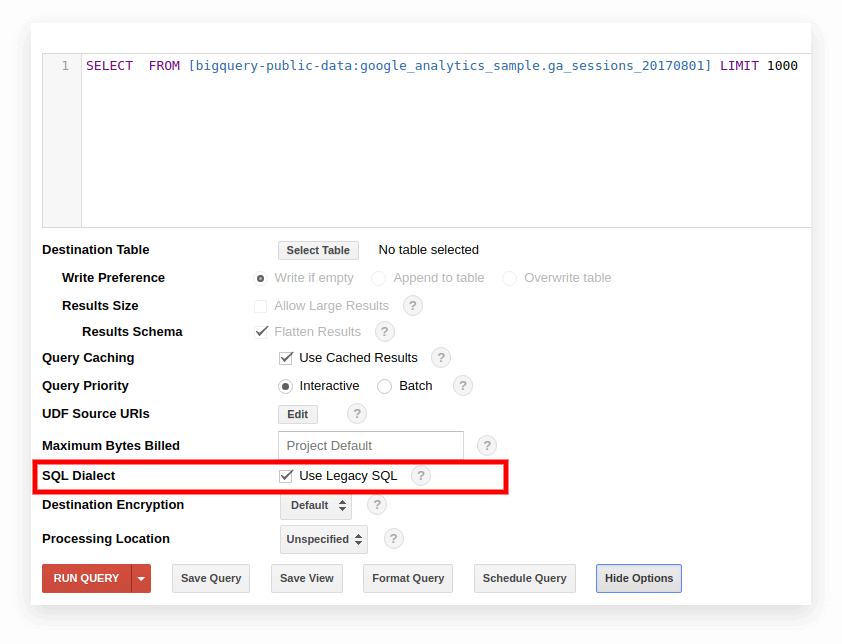
Новый интерфейс по умолчанию использует стандартный SQL. Здесь вам нужно перейти на вкладку «Дополнительно», чтобы переключить диалекты:
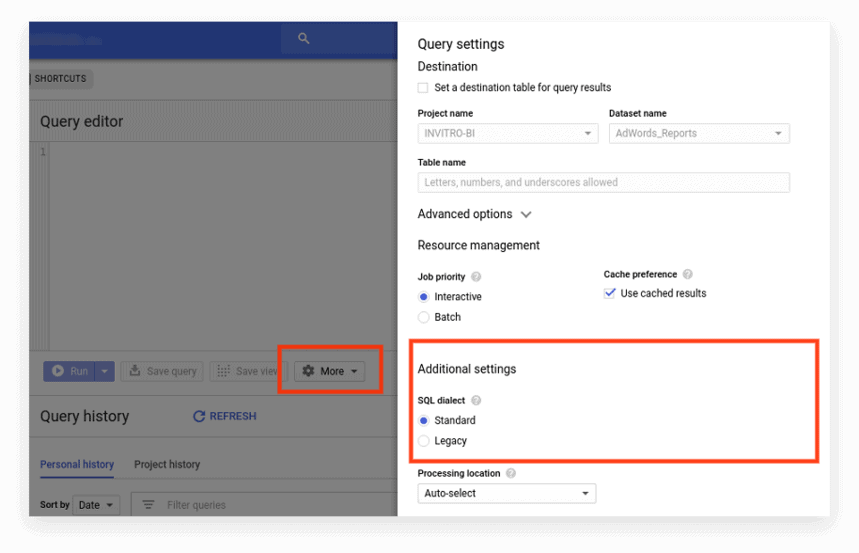
Вариант 2. Пишем префикс в начале запроса
Если вы не отметили настройки запроса, вы можете начать с нужного префикса (#standardSQL или #legacySQL):
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10;
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10; В этом случае Google BigQuery проигнорирует настройки в интерфейсе и выполнит запрос на диалекте, указанном в префиксе.
Если у вас есть представления или сохраненные запросы, которые запускаются по расписанию с помощью Apps Script, не забудьте изменить в скрипте значение useLegacySql на false:
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }Вариант 3. Переход на стандартный SQL для представлений
Если вы работаете с Google BigQuery не с таблицами, а с представлениями, эти представления не будут доступны на диалекте Standard SQL. То есть, если ваша презентация написана на Legacy SQL, вы не сможете писать к ней запросы на Standard SQL.
Чтобы перевести представление на стандартный SQL, нужно вручную переписать запрос, по которому оно было создано. Проще всего это сделать через интерфейс BigQuery.
1. Откройте вид:
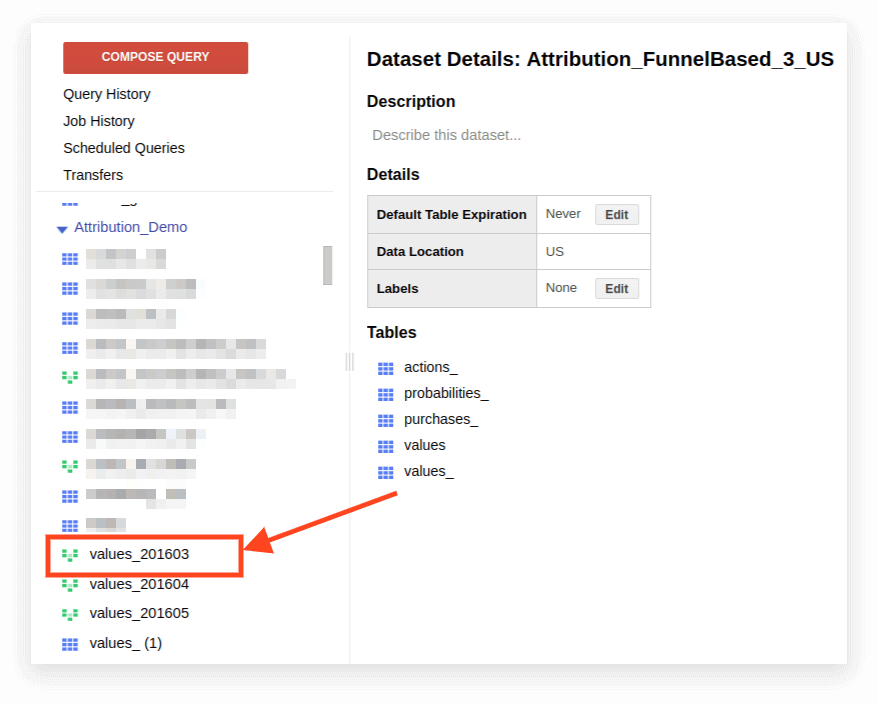
2. Щелкните Детали. Должен открыться текст запроса, а внизу появится кнопка «Редактировать запрос»:
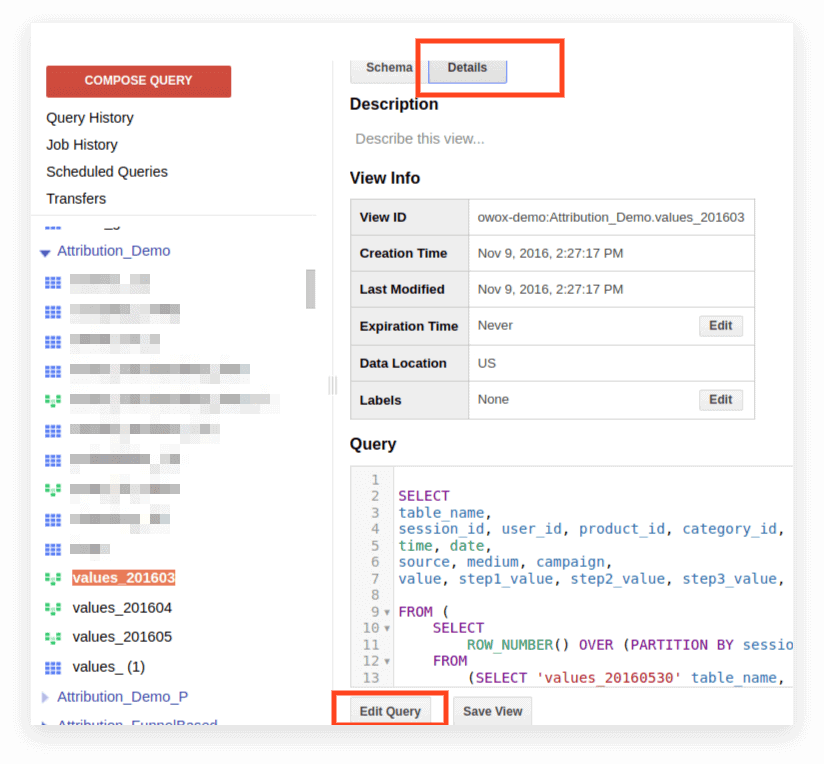
Теперь вы можете редактировать запрос по правилам Standard SQL.
Если вы планируете и дальше использовать запрос в качестве презентации, нажмите «Сохранить представление» после завершения редактирования.
Совместимость, особенности синтаксиса, операторы, функции
Совместимость
Благодаря реализации Standard SQL вы можете напрямую обращаться к данным, хранящимся в других сервисах, прямо из BigQuery:
- Файлы журнала Google Cloud Storage
- Транзакционные записи в Google Bigtable
- Данные из других источников
Это позволяет использовать продукты Google Cloud Platform для любых аналитических задач, включая предиктивную и предписывающую аналитику на основе алгоритмов машинного обучения.
Синтаксис запроса
Структура запроса на стандартном диалекте почти такая же, как и в Legacy:
Имена таблиц и представления разделены точкой (точкой), а весь запрос заключен в гравюры: `project_name.data_name_name.table_name``bigquery-public-data.samples.natality`
Полный синтаксис запроса с пояснениями того, что может быть включено в каждый оператор, скомпилирован в виде схемы в документации BigQuery.
Особенности стандартного синтаксиса SQL:
- Запятые необходимы для перечисления полей в операторе SELECT.
- Если вы используете оператор UNNEST после FROM, запятая или JOIN ставится перед UNNEST.
- Нельзя ставить запятую перед ОТ.
- Запятая между двумя запросами равно CROSS JOIN, поэтому будьте осторожны с ней.
- JOIN может быть выполнен не только по столбцу или равенству, но и по произвольным выражениям и неравенству.
- Сложные подзапросы можно писать в любой части SQL-выражения (в SELECT, FROM, WHERE и т. д.). На практике пока невозможно использовать такие выражения, как WHERE имя_столбца IN (SELECT...), как в других базах данных.
Операторы
В стандартном SQL операторы определяют тип данных. Например, массив всегда записывается в квадратных скобках []. Операторы используются для сравнения, сопоставления логических выражений (НЕ, ИЛИ, И) и в арифметических вычислениях.
Функции
Стандартный SQL поддерживает больше возможностей, чем Legacy: традиционная агрегация (сумма, число, минимум, максимум); математические, строковые и статистические функции; и редкие форматы, такие как HyperLogLog++.
В стандартном диалекте больше функций для работы с датами и TIMESTAMP. Полный список функций приведен в документации Google. Наиболее часто используемые функции предназначены для работы с датами, строками, агрегацией и окном.
1. Агрегирующие функции
COUNT (DISTINCT имя_столбца) подсчитывает количество уникальных значений в столбце. Например, нам нужно подсчитать количество сеансов с мобильных устройств на 1 марта 2019 года. Поскольку номер сеанса может повторяться в разных строках, мы хотим подсчитывать только уникальные значения номера сеанса:
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile' SUM (column_name) — сумма значений в столбце
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile' МИН (имя_столбца) | MAX (column_name) — минимальное и максимальное значение в столбце. Эти функции удобны для проверки разброса данных в таблице.
2. Оконные (аналитические) функции
Аналитические функции считают значения не для всей таблицы, а для определенного окна — набора строк, которые вас интересуют. То есть вы можете определять сегменты внутри таблицы. Например, можно рассчитать SUM (доход) не по всем линиям, а по городам, категориям устройств и так далее. Вы можете включить аналитические функции SUM, COUNT и AVG, а также другие функции агрегирования, добавив к ним условие OVER (PARTITION BY column_name).
Например, вам нужно подсчитать количество сеансов по источникам трафика, каналам, кампаниям, городам и категориям устройств. В этом случае мы можем использовать следующее выражение:
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t OVER определяет окно, для которого будут производиться расчеты. PARTITION BY указывает, какие строки должны быть сгруппированы для расчета. В некоторых функциях необходимо указывать порядок группировки с помощью ORDER BY.
Полный список оконных функций см. в документации BigQuery.
3. Строковые функции
Это полезно, когда вам нужно изменить текст, отформатировать текст в строке или склеить значения столбцов. Например, строковые функции отлично подходят, если вы хотите создать уникальный идентификатор сеанса из стандартных экспортных данных Google Analytics 360. Рассмотрим самые популярные строковые функции.
SUBSTR отсекает часть строки. В запросе эта функция записывается как SUBSTR(string_name, 0.4). Первое число указывает, сколько символов нужно пропустить с начала строки, а второе число указывает, сколько цифр нужно вырезать. Например, предположим, что у вас есть столбец дат, содержащий даты в формате STRING. В этом случае даты выглядят так: 20190103. Если вы хотите извлечь год из этой строки, вам поможет SUBSTR:
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301` CONCAT (имя_столбца и т. д.) объединяет значения. Давайте воспользуемся столбцом даты из предыдущего примера. Предположим, вы хотите, чтобы все даты записывались так: 2019-03-01. Чтобы преобразовать даты из их текущего формата в этот формат, можно использовать две строковые функции: сначала вырезать нужные куски строки с помощью SUBSTR, затем склеить их через дефис:
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301` REGEXP_CONTAINS возвращает значения столбцов, в которых встречается регулярное выражение:
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301` Эту функцию можно использовать как в SELECT, так и в WHERE. Например, в WHERE вы можете выбрать с его помощью определенные страницы:
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order')
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order') 4. Функции даты
Часто даты в таблицах записываются в формате STRING. Если вы планируете визуализировать результаты в Google Data Studio, даты в таблице необходимо преобразовать в формат DATE с помощью функции PARSE_DATE.
PARSE_DATE преобразует STRING формата 1900-01-01 в формат DATE.
Если даты в ваших таблицах выглядят по-разному (например, 19000101 или 01_01_1900), их необходимо предварительно преобразовать в указанный формат.
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301` DATE_DIFF вычисляет, сколько времени прошло между двумя датами в днях, неделях, месяцах или годах. Это полезно, если вам нужно определить интервал между тем, когда пользователь увидел рекламу и сделал заказ. Вот как функция выглядит в запросе:
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301` Если вы хотите узнать больше о перечисленных функциях, прочтите BigQuery Google Features — A Detailed Review.
SQL-запросы для маркетинговых отчетов
Диалект Standard SQL позволяет бизнесу извлекать максимум информации из данных с помощью глубокой сегментации, технических аудитов, маркетингового анализа KPI и выявления недобросовестных контрагентов в CPA-сетях. Вот примеры бизнес-задач, в которых вам помогут SQL-запросы к данным, собранным в Google BigQuery.
1. ROPO-анализ: оценить вклад онлайн-кампаний в офлайн-продажи. Для проведения ROPO-анализа вам необходимо объединить данные о поведении пользователей в сети с данными из вашей CRM, системы коллтрекинга и мобильного приложения.
Если в одной и во второй базе есть ключ — общий параметр, уникальный для каждого пользователя (например, User ID) — можно отследить:
какие пользователи посещали сайт перед покупкой товаров в магазине
как пользователи вели себя на сайте
сколько времени потребовалось пользователям, чтобы принять решение о покупке
какие кампании показали наибольший рост офлайн-покупок.
2. Сегментировать клиентов по любой комбинации параметров, от поведения на сайте (посещенные страницы, просмотренные товары, количество посещений сайта перед покупкой) до номера карты лояльности и купленных товаров.
3. Узнайте, какие CPA-партнеры работают недобросовестно и подменяют UTM-метки.
4. Анализируйте продвижение пользователей по воронке продаж.
Мы подготовили подборку запросов на стандартном диалекте SQL. Если вы уже собираете данные со своего сайта, из рекламных источников и из вашей CRM-системы в Google BigQuery, вы можете использовать эти шаблоны для решения своих бизнес-задач. Просто замените название проекта, набор данных и таблицу в BigQuery на свои собственные. В коллекции вы получите 11 запросов SQL.
Для данных, собранных с помощью стандартного экспорта из Google Analytics 360 в Google BigQuery:
- Действия пользователя в разрезе любых параметров
- Статистика по ключевым действиям пользователей
- Пользователи, которые просматривали определенные страницы продукта
- Действия пользователей, купивших тот или иной товар
- Настройте воронку с любыми необходимыми шагами
- Эффективность внутреннего поиска сайта
Для данных, собранных в Google BigQuery с помощью OWOX BI:
- Атрибутивное потребление по источникам и каналам
- Средняя стоимость привлечения посетителя по городам
- ROAS для валовой прибыли по источникам и каналам
- Количество заказов в CRM по способу оплаты и способу доставки
- Среднее время доставки по городу
Если у вас есть вопросы о запросе данных Google BigQuery, на которые вы не нашли ответов в этой статье, задавайте их в комментариях. Мы постараемся вам помочь.