
Standardowy SQL w Google BigQuery: zalety i przykłady użycia w marketingu
Opublikowany: 2022-04-12W 2016 r. Google BigQuery wprowadził nowy sposób komunikacji z tabelami: Standardowy SQL. Do tego czasu BigQuery miał własny ustrukturyzowany język zapytań o nazwie BigQuery SQL (obecnie nazywany Legacy SQL).
Na pierwszy rzut oka nie ma dużej różnicy między Legacy a Standard SQL: nazwy tabel są pisane nieco inaczej; Standard ma nieco bardziej rygorystyczne wymagania gramatyczne (na przykład nie można wstawić przecinka przed FROM) i więcej typów danych. Ale jeśli przyjrzysz się uważnie, zauważysz kilka drobnych zmian składni, które dają marketerom wiele korzyści.
W tym artykule uzyskasz odpowiedzi na następujące pytania:
- Jakie są zalety standardowego SQL nad starszym SQL?
- Jakie są możliwości standardowego SQL i jak jest używany?
- Jak mogę przejść ze starszej wersji na standardowy SQL?
- Z jakimi innymi usługami, funkcjami składni, operatorami i funkcjami jest zgodny Standard SQL?
- Jak używać zapytań SQL do raportów marketingowych?
Jakie są zalety standardowego SQL nad starszym SQL?
Nowe typy danych: tablice i pola zagnieżdżone
Standardowy SQL obsługuje nowe typy danych: ARRAY i STRUCT (tablice i pola zagnieżdżone). Oznacza to, że w BigQuery łatwiej jest pracować z tabelami ładowanymi z plików JSON/Avro, które często zawierają wielopoziomowe załączniki.
Pole zagnieżdżone to mini tabela w większym:
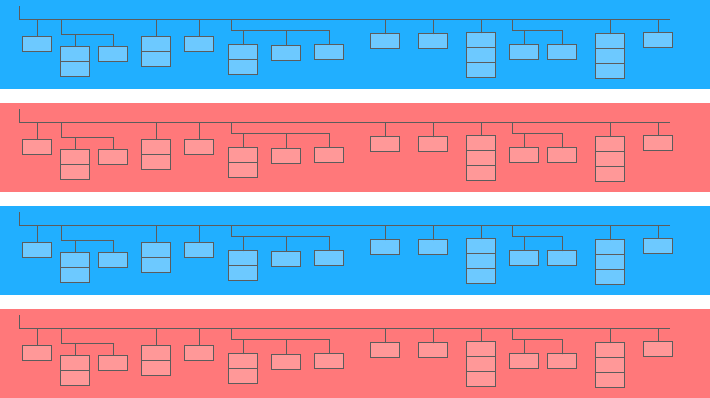
Na powyższym schemacie niebieskie i żółte paski to linie, w których osadzone są minitabele. Każda linia to jedna sesja. Sesje mają wspólne parametry: datę, numer ID, kategorię urządzenia użytkownika, przeglądarkę, system operacyjny itp. Oprócz ogólnych parametrów dla każdej sesji do wiersza dołączona jest tabela trafień.

Tabela odsłon zawiera informacje o działaniach użytkownika w serwisie. Na przykład, jeśli użytkownik kliknie w baner, przejrzy katalog, otworzy stronę produktu, umieści produkt w koszyku lub złoży zamówienie, działania te zostaną zapisane w tabeli trafień.
Jeżeli użytkownik złoży zamówienie w serwisie, informacja o zamówieniu zostanie również umieszczona w tabeli odsłon:
- transactionId (numer identyfikujący transakcję)
- transactionRevenue (całkowita wartość zamówienia)
- TransactionSshipping (koszty wysyłki)
Podobną strukturę mają tablice danych sesji zebrane za pomocą OWOX BI.
Załóżmy, że chcesz poznać liczbę zamówień od użytkowników w Nowym Jorku w ciągu ostatniego miesiąca. Aby się tego dowiedzieć, musisz odwołać się do tabeli trafień i policzyć liczbę unikalnych identyfikatorów transakcji. Aby wyodrębnić dane z takich tabel, Standardowy SQL ma funkcję UNNEST:
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City Jeśli informacje o zamówieniach zostały zapisane w osobnej tabeli, a nie w zagnieżdżonej tabeli, musiałbyś użyć JOIN, aby połączyć tabelę z informacjami o zamówieniach i tabelę z danymi sesji, aby dowiedzieć się, w których sesjach zostały złożone zamówienia.
Więcej opcji podzapytania
Jeśli chcesz wyodrębnić dane z wielopoziomowych pól zagnieżdżonych, możesz dodać podzapytania za pomocą SELECT i WHERE. Na przykład w tabelach przesyłania strumieniowego sesji OWOX BI inna podtabela, produkt, jest zapisywana w podtabeli hits. Podtabela produktów zbiera dane produktów, które są przesyłane za pomocą tablicy ulepszonego e-commerce. Jeśli w witrynie skonfigurowano rozszerzony e-commerce, a użytkownik spojrzał na stronę produktu, cechy tego produktu zostaną zapisane w podtabeli produktów.
Aby uzyskać te cechy produktu, potrzebujesz podzapytania w zapytaniu głównym. Dla każdej cechy produktu tworzone jest osobne podzapytanie SELECT w nawiasach:
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD`
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` Dzięki możliwościom standardowego SQL łatwiej jest budować logikę zapytań i pisać kod. Dla porównania, w Legacy SQL musiałbyś napisać taki rodzaj drabiny:
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )Żądania do źródeł zewnętrznych
Używając standardowego SQL, możesz uzyskać dostęp do tabel BigQuery bezpośrednio z Google Bigtable, Google Cloud Storage, Dysku Google i Arkuszy Google.
Oznacza to, że zamiast wczytywać całą tabelę do BigQuery, możesz usunąć dane za pomocą jednego zapytania, wybrać potrzebne parametry i przesłać je do pamięci w chmurze.
Więcej funkcji użytkownika (UDF)
Jeśli potrzebujesz użyć formuły, która nie jest udokumentowana, pomogą Ci funkcje zdefiniowane przez użytkownika (UDF). W naszej praktyce zdarza się to rzadko, ponieważ dokumentacja Standard SQL obejmuje prawie wszystkie zadania analityki cyfrowej.
W standardowym SQL funkcje zdefiniowane przez użytkownika mogą być napisane w SQL lub JavaScript; Starszy SQL obsługuje tylko JavaScript. Argumentami tych funkcji są kolumny, a przyjmowane przez nie wartości są wynikiem manipulowania kolumnami. W standardowym SQL funkcje można pisać w tym samym oknie co zapytania.
Więcej warunków DOŁĄCZ
W Legacy SQL warunki JOIN mogą być oparte na równości lub nazwach kolumn. Oprócz tych opcji, dialekt Standardowy SQL obsługuje JOIN przez nierówność i dowolne wyrażenie.
Na przykład, aby zidentyfikować nieuczciwych partnerów CPA, możemy wybrać sesje, w których źródło zostało zastąpione w ciągu 60 sekund od transakcji. Aby to zrobić w standardowym SQL, możemy dodać nierówność do warunku JOIN:
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime Jedynym ograniczeniem standardowego SQL w odniesieniu do JOIN jest to, że nie pozwala on na częściowe łączenie z podzapytaniami postaci WHERE column IN (SELECT ...):
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESC
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESCMniejsza szansa na błędy
Niektóre funkcje w Legacy SQL zwracają NULL, jeśli warunek jest niepoprawny. Na przykład, jeśli do obliczeń wkradło się dzielenie przez zero, zapytanie zostanie wykonane i w wynikowych wierszach tabeli pojawią się wpisy NULL. Może to maskować problemy w zapytaniu lub w danych.
Logika standardowego SQL jest prostsza. Jeśli warunek lub dane wejściowe są nieprawidłowe, zapytanie wygeneruje błąd, na przykład „dzielenie przez zero”, dzięki czemu możesz szybko poprawić zapytanie. Następujące kontrole są osadzone w standardowym języku SQL:
- Prawidłowe wartości dla +, -, ×, SUM, AVG, STDEV
- Dzielenie przez zero
Żądania przebiegają szybciej
Zapytania JOIN napisane w Standard SQL są szybsze niż te napisane w Legacy SQL dzięki wstępnemu filtrowaniu przychodzących danych. Najpierw zapytanie wybiera wiersze, które spełniają warunki JOIN, a następnie je przetwarza.
W przyszłości Google BigQuery będzie pracować nad poprawą szybkości i wydajności zapytań tylko dla standardowego SQL.
Tabele można edytować: wstawiać i usuwać wiersze, aktualizować
Funkcje języka manipulacji danymi (DML) są dostępne w standardowym języku SQL. Oznacza to, że możesz aktualizować tabele i dodawać lub usuwać z nich wiersze za pomocą tego samego okna, w którym piszesz zapytania. Na przykład, używając DML, możesz połączyć dane z dwóch tabel w jedną:
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)Kod jest łatwiejszy do odczytania i edycji
W przypadku standardowego SQL złożone zapytania można uruchamiać nie tylko za pomocą SELECT, ale także za pomocą funkcji WITH, dzięki czemu kod jest łatwiejszy do odczytania, komentowania i zrozumienia. Oznacza to również, że łatwiej jest zapobiegać własnym błędom i poprawiać błędy innych.
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2 Wygodnie jest pracować z operatorem WITH, jeśli masz obliczenia wykonywane w kilku etapach. Najpierw możesz zebrać metryki pośrednie w podzapytaniach, a następnie wykonać obliczenia końcowe.
Platforma Google Cloud (GCP), która obejmuje BigQuery, to platforma umożliwiająca pełny cykl pracy z dużymi zbiorami danych, od organizowania hurtowni danych lub chmury danych po przeprowadzanie eksperymentów naukowych oraz analitykę predykcyjną i preskrypcyjną. Wraz z wprowadzeniem standardowego SQL BigQuery poszerza grono swoich odbiorców. Współpraca z GCP staje się coraz bardziej interesująca dla analityków marketingowych, analityków produktów, data sciences i zespołów innych specjalistów.
Możliwości Standardowego SQL i przykłady zastosowań
W OWOX BI często pracujemy z tabelami skompilowanymi przy użyciu standardowego eksportu Google Analytics 360 do Google BigQuery lub OWOX BI Pipeline. W poniższych przykładach przyjrzymy się specyfice zapytań SQL dla takich danych.
Jeśli nie zbierasz jeszcze danych ze swojej witryny w BigQuery, możesz spróbować to zrobić bezpłatnie, korzystając z wersji próbnej OWOX BI.
1. Wybierz dane dla przedziału czasu
W Google BigQuery dane dotyczące zachowań użytkowników w Twojej witrynie są przechowywane w tabelach z symbolami wieloznacznymi (tabelami z gwiazdką). Dla każdego dnia tworzona jest osobna tabela. Te tabele mają tę samą nazwę: tylko przyrostek jest inny. Sufiks to data w formacie RRRRMMDD. Na przykład tabela owoxbi_sessions_20190301 zawiera dane o sesjach z 1 marca 2019 r.
Możemy odnieść się bezpośrednio do grupy takich tabel w jednym żądaniu w celu uzyskania danych np. od 1 lutego do 28 lutego 2019 roku. W tym celu musimy zamienić YYYYMMDD na * w FROM, a w GDZIE, musimy określić przyrostki tabeli dla początku i końca przedziału czasu:
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �'
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �' Konkretne daty, dla których chcemy zbierać dane, nie zawsze są nam znane. Na przykład co tydzień możemy potrzebować analizować dane z ostatnich trzech miesięcy. W tym celu możemy użyć funkcji FORMAT_DATE:
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) Po BETWEEN zapisujemy sufiks pierwszej tabeli. Wyrażenie CURRENT_DATE (), INTERWAŁ 3 MIESIĄCE oznacza „wybierz dane z ostatnich 3 miesięcy od bieżącej daty”. Drugi przyrostek tabeli jest sformatowany po AND. Należy oznaczyć koniec interwału jako wczoraj: CURRENT_DATE (), INTERVAL 1 DAY.
2. Pobierz parametry i wskaźniki użytkownika
Parametry i dane użytkownika w tabelach eksportu Google Analytics są zapisywane w zagnieżdżonej tabeli działań oraz w podtablicach customDimensions i customMetrics. Wszystkie niestandardowe wymiary są zapisywane w dwóch kolumnach: jedna dla liczby parametrów zebranych na stronie, druga dla ich wartości. Oto jak wyglądają wszystkie parametry przekazywane jednym trafieniem:
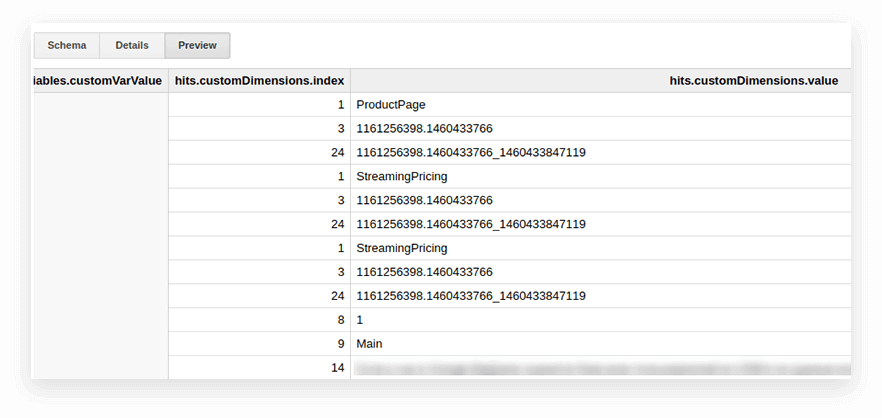
W celu ich rozpakowania i zapisania niezbędnych parametrów w osobnych kolumnach używamy następującego zapytania SQL:
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 Oto jak to wygląda w żądaniu:
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201` Na poniższym zrzucie ekranu wybraliśmy parametry 1 i 2 z danych demonstracyjnych Google Analytics 360 w Google BigQuery i nazwaliśmy je page_type i client_id. Każdy parametr jest zapisywany w osobnej kolumnie:

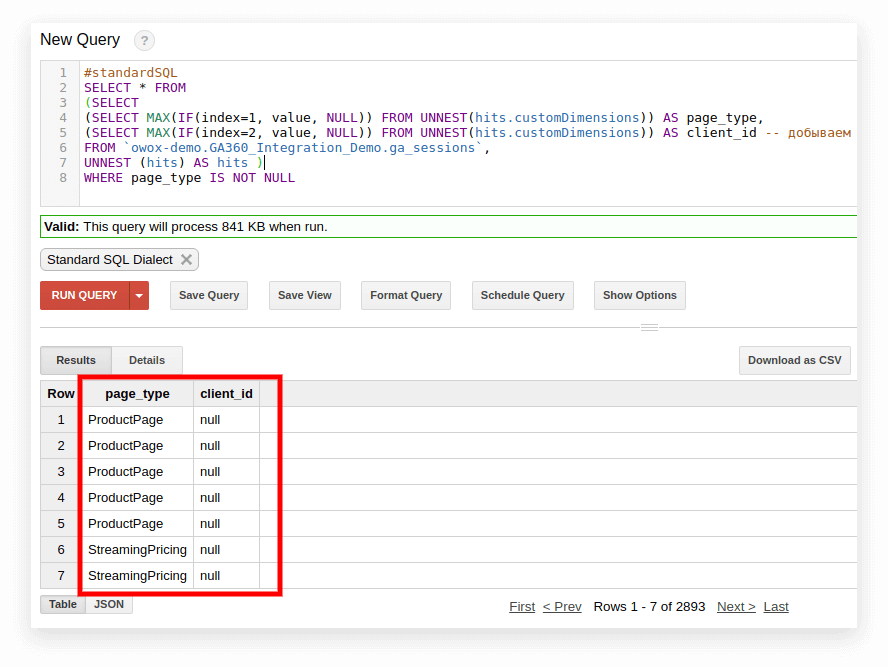
3. Oblicz liczbę sesji według źródła ruchu, kanału, kampanii, miasta i kategorii urządzenia
Takie obliczenia są przydatne, jeśli planujesz wizualizować dane w Google Data Studio i filtrować według miasta i kategorii urządzenia. Jest to łatwe dzięki funkcji okna COUNT:
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`4. Połącz te same dane z kilku tabel
Załóżmy, że zbierasz dane o zrealizowanych zamówieniach w kilku tabelach BigQuery: jedna zbiera wszystkie zamówienia ze Sklepu A, a druga ze Sklepu B. Chcesz połączyć je w jedną tabelę z tymi kolumnami:
- client_id — liczba identyfikująca unikalnego kupującego
- transaction_created — czas utworzenia zamówienia w formacie TIMESTAMP
- id_transakcji — numer zamówienia
- is_approved — czy zamówienie zostało potwierdzone
- transaction_revenue — kwota zamówienia
W naszym przykładzie w tabeli muszą znajdować się zamówienia od 1 stycznia 2018 do wczoraj. Aby to zrobić, wybierz odpowiednie kolumny z każdej grupy tabel, nadaj im tę samą nazwę i połącz wyniki z UNION ALL:
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC5. Stwórz słownik grup kanałów ruchu
Kiedy dane trafiają do Google Analytics, system automatycznie określa grupę, do której należy dane przejście: Direct, Organic Search, Paid Search i tak dalej. Aby zidentyfikować grupę kanałów, Google Analytics analizuje tagi przejść UTM, a mianowicie utm_source i utm_medium. Więcej informacji o grupach kanałów i regułach definicji znajdziesz w pomocy Google Analytics.
Jeżeli klienci OWOX BI chcą przypisać własne nazwy do grup kanałów, tworzymy słownik, którego przejście należy do konkretnego kanału. W tym celu używamy warunkowego operatora CASE oraz funkcji REGEXP_CONTAINS. Ta funkcja wybiera wartości, w których występuje określone wyrażenie regularne.
Zalecamy pobranie nazw z listy źródeł w Google Analytics. Oto przykład, jak dodać takie warunki do treści żądania:
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201` Jak przejść na standardowy SQL
Jeśli nie przełączyłeś się jeszcze na Standard SQL, możesz to zrobić w dowolnym momencie. Najważniejsze jest, aby uniknąć mieszania dialektów w jednej prośbie.
Opcja 1. Przełącz się w interfejsie Google BigQuery
Starszy język SQL jest domyślnie używany w starym interfejsie BigQuery. Aby przełączać się między dialektami, kliknij opcję Pokaż opcje pod polem wprowadzania zapytania i usuń zaznaczenie pola Użyj starszego języka SQL obok opcji Dialekt SQL.
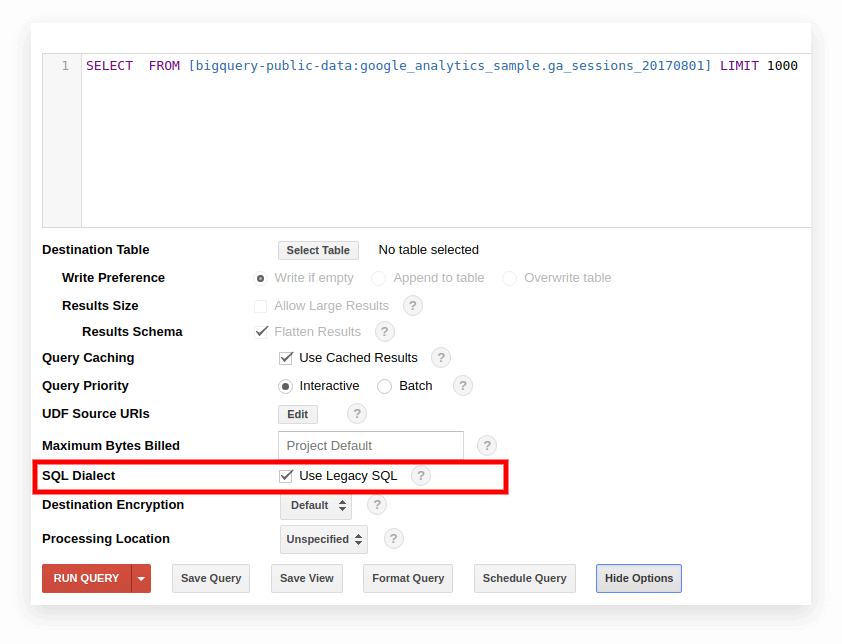
Nowy interfejs domyślnie używa standardowego SQL. Tutaj musisz przejść do zakładki Więcej, aby przełączyć dialekty:
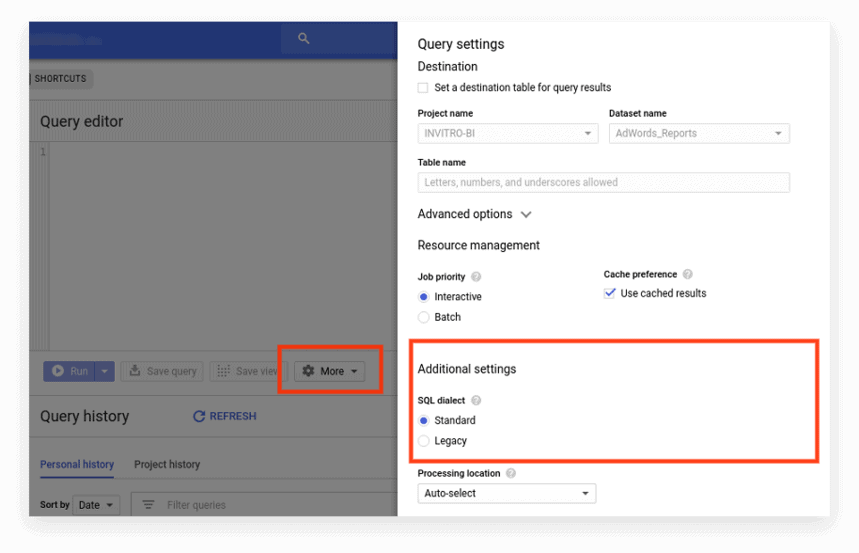
Opcja 2. Wpisz prefiks na początku żądania
Jeśli nie zaznaczyłeś ustawień żądania, możesz zacząć od żądanego prefiksu (#standardSQL lub #legacySQL):
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10;
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10; W takim przypadku Google BigQuery zignoruje ustawienia w interfejsie i uruchomi zapytanie przy użyciu dialektu określonego w prefiksie.
Jeśli masz widoki lub zapisane zapytania uruchamiane zgodnie z harmonogramem za pomocą Apps Script, nie zapomnij zmienić w skrypcie wartości useLegacySql na false:
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }Opcja 3. Przejście do standardowego SQL dla widoków
Jeśli pracujesz z Google BigQuery nie z tabelami, ale z widokami, te widoki nie są dostępne w dialekcie Standard SQL. Oznacza to, że jeśli Twoja prezentacja jest napisana w Legacy SQL, nie możesz pisać do niej żądań w Standard SQL.
Aby przenieść widok do standardowego SQL, należy ręcznie przepisać zapytanie, według którego został utworzony. Najłatwiej to zrobić za pomocą interfejsu BigQuery.
1. Otwórz widok:
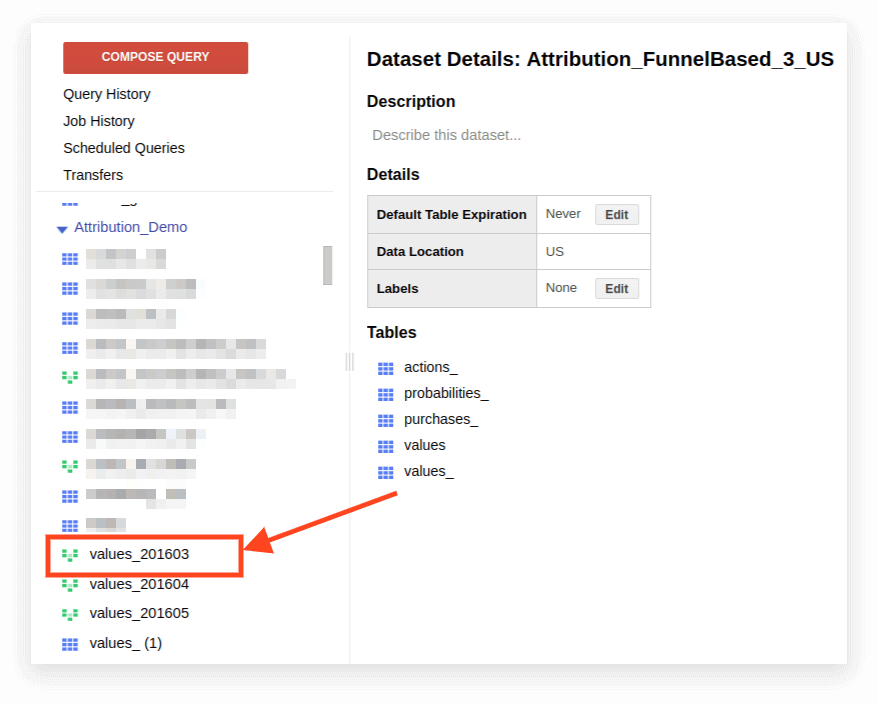
2. Kliknij Szczegóły. Tekst zapytania powinien się otworzyć, a poniżej pojawi się przycisk Edytuj zapytanie:
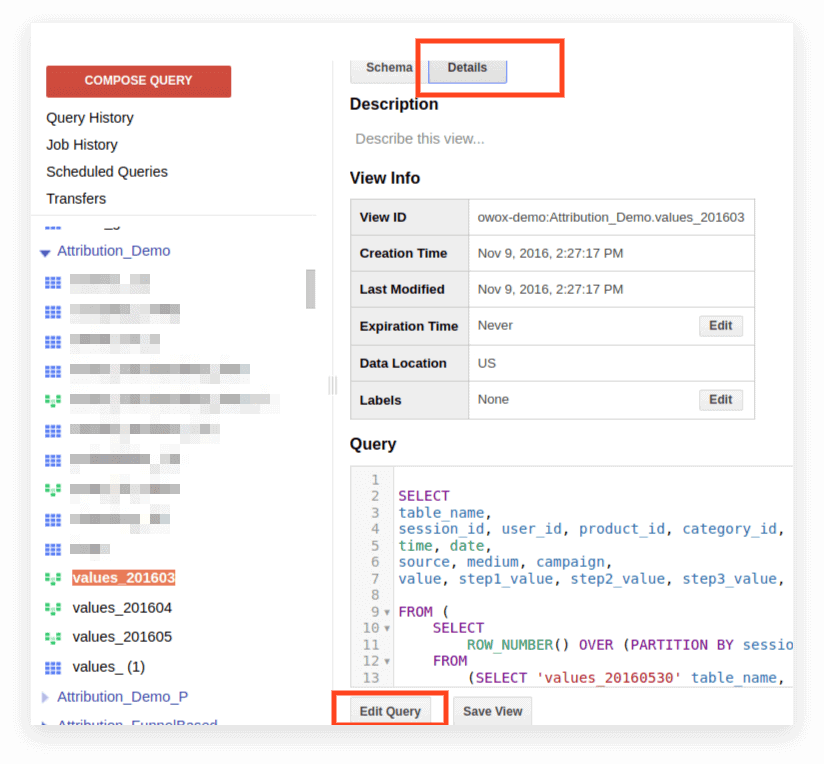
Teraz możesz edytować żądanie zgodnie z zasadami Standard SQL.
Jeśli planujesz nadal używać żądania jako prezentacji, kliknij Zapisz widok po zakończeniu edycji.
Kompatybilność, cechy składni, operatory, funkcje
Zgodność
Dzięki wdrożeniu Standard SQL masz bezpośredni dostęp do danych przechowywanych w innych usługach bezpośrednio z BigQuery:
- Pliki dziennika Google Cloud Storage
- Rekordy transakcyjne w Google Bigtable
- Dane z innych źródeł
Dzięki temu możesz używać produktów Google Cloud Platform do dowolnych zadań analitycznych, w tym analiz predykcyjnych i preskryptywnych opartych na algorytmach uczenia maszynowego.
Składnia zapytania
Struktura zapytań w dialekcie Standard jest prawie taka sama jak w Legacy:
Nazwy tabel i widoków oddzielone są kropką (kropką), a całe zapytanie ujęto akcentami: `nazwa_projektu.nazwa_danych.nazwa_tabeli``bigquery-public-data.samples.natality`
Pełna składnia zapytania wraz z objaśnieniami, co może zawierać każdy operator, jest kompilowana jako schemat w dokumentacji BigQuery.
Funkcje składni standardowej SQL:
- Do wyświetlenia pól w instrukcji SELECT potrzebne są przecinki.
- Jeśli używasz operatora UNNEST po FROM , przecinek lub JOIN są umieszczane przed UNNEST.
- Nie możesz umieścić przecinka przed FROM.
- Przecinek między dwoma zapytaniami to CROSS JOIN, więc bądź ostrożny.
- JOIN można wykonać nie tylko za pomocą kolumny lub równości, ale także za pomocą arbitralnych wyrażeń i nierówności.
- Możliwe jest pisanie złożonych podzapytań w dowolnej części wyrażenia SQL (w SELECT, FROM, WHERE itp.). W praktyce nie jest jeszcze możliwe użycie wyrażeń typu WHERE nazwa_kolumny IN (SELECT ...), jak to ma miejsce w innych bazach danych.
Operatorzy
W standardowym SQL operatory definiują typ danych. Na przykład tablica jest zawsze zapisywana w nawiasach kwadratowych []. Operatory służą do porównywania, dopasowywania wyrażenia logicznego (NOT, OR, AND) oraz do obliczeń arytmetycznych.
Funkcje
Standardowy SQL obsługuje więcej funkcji niż Legacy: agregacja tradycyjna (suma, liczba, minimum, maksimum); funkcje matematyczne, łańcuchowe i statystyczne; i rzadkie formaty, takie jak HyperLogLog ++.
W dialekcie Standard jest więcej funkcji do pracy z datami i ZNACZNIKIEM CZASU. Pełna lista funkcji znajduje się w dokumentacji Google. Najczęściej używane funkcje służą do pracy z datami, ciągami, agregacją i oknem.
1. Funkcje agregacji
COUNT (DISTINCT nazwa_kolumny) zlicza liczbę unikalnych wartości w kolumnie. Załóżmy na przykład, że musimy policzyć liczbę sesji z urządzeń mobilnych w dniu 1 marca 2019 r. Ponieważ numer sesji może się powtarzać w różnych wierszach, chcemy policzyć tylko unikalne wartości numeru sesji:
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile' SUM (nazwa_kolumny) — suma wartości w kolumnie
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile' MIN (nazwa kolumny) | MAX (nazwa_kolumny) — minimalna i maksymalna wartość w kolumnie. Te funkcje są wygodne do sprawdzania rozkładu danych w tabeli.
2. Funkcje okna (analityczne)
Funkcje analityczne uwzględniają wartości nie dla całej tabeli, ale dla określonego okna — zbioru wierszy, którymi jesteś zainteresowany. To znaczy, możesz zdefiniować segmenty w tabeli. Na przykład możesz obliczyć SUMA (przychód) nie dla wszystkich linii, ale dla miast, kategorii urządzeń itd. Funkcje analityczne SUM, COUNT i AVG, a także inne funkcje agregacji można zmienić, dodając do nich warunek OVER (PARTITION BY nazwa_kolumny).
Na przykład musisz policzyć liczbę sesji według źródła ruchu, kanału, kampanii, miasta i kategorii urządzenia. W takim przypadku możemy użyć następującego wyrażenia:
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t OVER określa okno, dla którego będą wykonywane obliczenia. PARTITION BY wskazuje, które wiersze należy pogrupować do obliczeń. W niektórych funkcjach konieczne jest określenie kolejności grupowania za pomocą ORDER BY.
Pełną listę funkcji okien znajdziesz w dokumentacji BigQuery.
3. Funkcje ciągów
Są przydatne, gdy trzeba zmienić tekst, sformatować tekst w linii lub skleić wartości kolumn. Na przykład funkcje ciągów znakomicie się sprawdzają, jeśli chcesz wygenerować unikalny identyfikator sesji ze standardowych danych eksportu Google Analytics 360. Rozważmy najpopularniejsze funkcje łańcuchowe.
SUBSTR przecina część sznurka. W żądaniu ta funkcja jest zapisana jako SUBSTR (string_name, 0.4). Pierwsza liczba wskazuje, ile znaków należy pominąć od początku wiersza, a druga liczba wskazuje, ile cyfr należy wyciąć. Załóżmy na przykład, że masz kolumnę daty zawierającą daty w formacie STRING. W tym przypadku daty wyglądają tak: 20190103. Jeśli chcesz wydobyć rok z tej linii, SUBSTR pomoże Ci:
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301` CONCAT (nazwa_kolumny itp.) skleja wartości. Użyjmy kolumny daty z poprzedniego przykładu. Załóżmy, że chcesz, aby wszystkie daty były zapisywane w następujący sposób: 2019-03-01. Aby przekonwertować daty z ich obecnego formatu na ten format, można użyć dwóch funkcji ciągu: najpierw wytnij potrzebne fragmenty ciągu za pomocą SUBSTR, a następnie sklej je przez myślnik:
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301` REGEXP_CONTAINS zwraca wartości kolumn, w których występuje wyrażenie regularne:
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301` Ta funkcja może być używana zarówno w WYBIERZ, jak i WHERE. Na przykład w WHERE możesz wybrać za jego pomocą określone strony:
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order')
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order') 4. Funkcje daty
Często daty w tabelach zapisywane są w formacie STRING. Jeśli planujesz wizualizować wyniki w Google Data Studio, daty w tabeli należy przekonwertować na format DATE za pomocą funkcji PARSE_DATE.
PARSE_DATE konwertuje STRING formatu 1900-01-01 na format DATE.
Jeśli daty w tabelach wyglądają inaczej (na przykład 19000101 lub 01_01_1900), należy je najpierw przekonwertować na określony format.
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301` DATE_DIFF oblicza, ile czasu minęło między dwiema datami w dniach, tygodniach, miesiącach lub latach. Jest to przydatne, jeśli chcesz określić odstęp czasu między wyświetleniem reklamy przez użytkownika a złożeniem zamówienia. Oto jak funkcja wygląda w żądaniu:
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301` Jeśli chcesz dowiedzieć się więcej o wymienionych funkcjach, przeczytaj BigQuery Google Features — szczegółowa recenzja.
Zapytania SQL do raportów marketingowych
Dialekt Standardowy SQL pozwala firmom wydobyć maksimum informacji z danych dzięki głębokiej segmentacji, audytom technicznym, marketingowej analizie KPI i identyfikacji nieuczciwych kontrahentów w sieciach CPA. Oto przykłady problemów biznesowych, w których pomogą Ci zapytania SQL dotyczące danych zebranych w Google BigQuery.
1. Analiza ROPO: oceń wkład kampanii online w sprzedaż offline. Aby przeprowadzić analizę ROPO, musisz połączyć dane dotyczące zachowań użytkowników online z danymi z Twojego CRM, systemu śledzenia połączeń i aplikacji mobilnej.
Jeśli w jednej i drugiej podstawie znajduje się klucz — wspólny parametr, który jest unikalny dla każdego użytkownika (na przykład identyfikator użytkownika) — możesz śledzić:
którzy użytkownicy odwiedzili witrynę przed zakupem towarów w sklepie
jak użytkownicy zachowywali się na stronie
ile czasu zajęło użytkownikom podjęcie decyzji o zakupie
jakie kampanie odnotowały największy wzrost zakupów offline.
2. Segmentuj klientów według dowolnej kombinacji parametrów, od zachowania na stronie (odwiedzane strony, przeglądane produkty, liczba wizyt na stronie przed zakupem) po numer karty lojalnościowej i zakupione produkty.
3. Dowiedz się, którzy partnerzy CPA działają w złej wierze i zastępują tagi UTM.
4. Analizuj postępy użytkowników przez lejek sprzedażowy.
Przygotowaliśmy zestaw zapytań w dialekcie Standard SQL. Jeśli zbierasz już dane ze swojej witryny, ze źródeł reklamowych oraz z systemu CRM w Google BigQuery, możesz użyć tych szablonów do rozwiązywania problemów biznesowych. Po prostu zastąp nazwę projektu, zbiór danych i tabelę w BigQuery własną nazwą. W kolekcji otrzymasz 11 zapytań SQL.
W przypadku danych zebranych przy użyciu standardowego eksportu z Google Analytics 360 do Google BigQuery:
- Działania użytkownika w kontekście dowolnych parametrów
- Statystyki dotyczące kluczowych działań użytkowników
- Użytkownicy, którzy oglądali strony konkretnych produktów
- Działania użytkowników, którzy kupili dany produkt
- Skonfiguruj lejek z niezbędnymi krokami
- Skuteczność wewnętrznej strony wyszukiwania
W przypadku danych zebranych w Google BigQuery przy użyciu OWOX BI:
- Przypisane zużycie według źródła i kanału
- Średni koszt przyciągnięcia gościa według miasta
- ROAS dla zysku brutto według źródła i kanału
- Ilość zamówień w CRM według metody płatności i metody dostawy
- Średni czas dostawy według miasta
Jeśli masz pytania dotyczące przeszukiwania danych Google BigQuery, na które nie znalazłeś odpowiedzi w tym artykule, zadaj je w komentarzach. Postaramy się Ci pomóc.