
Google BigQuery 中的標準 SQL:營銷中使用的優勢和示例
已發表: 2022-04-122016 年,Google BigQuery 引入了一種與表通信的新方式:標準 SQL。 在那之前,BigQuery 擁有自己的結構化查詢語言,稱為 BigQuery SQL(現在稱為 Legacy SQL)。
乍一看,Legacy SQL 和 Standard SQL 並沒有太大區別:表名的寫法略有不同; 標準有稍微嚴格的語法要求(例如,您不能在 FROM 之前放置逗號)和更多的數據類型。 但是,如果您仔細觀察,就會發現一些細微的語法變化給營銷人員帶來了許多優勢。
在本文中,您將獲得以下問題的答案:
- 與傳統 SQL 相比,標準 SQL 有哪些優勢?
- 標準 SQL 有哪些功能以及如何使用它?
- 如何從舊版 SQL 遷移到標準 SQL?
- 標準 SQL 還兼容哪些其他服務、語法特性、運算符和函數?
- 如何將 SQL 查詢用於營銷報告?
與傳統 SQL 相比,標準 SQL 有哪些優勢?
新數據類型:數組和嵌套字段
標準 SQL 支持新的數據類型:ARRAY 和 STRUCT(數組和嵌套字段)。 這意味著在 BigQuery 中,處理從 JSON/Avro 文件加載的表變得更加容易,這些文件通常包含多級附件。
嵌套字段是一個更大的表中的一個迷你表:
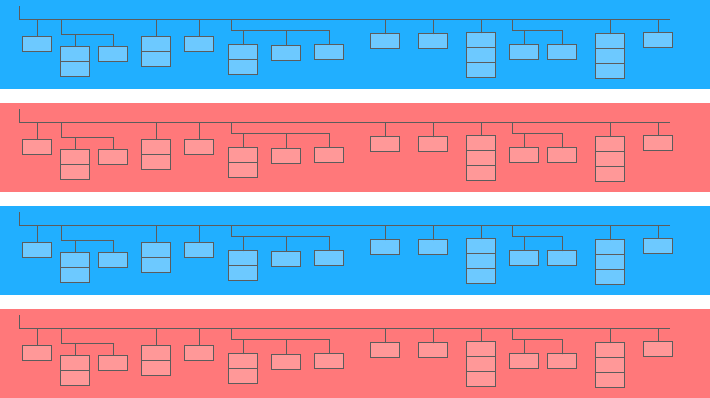
在上圖中,藍色和黃色條是嵌入迷你表格的線條。 每行是一個會話。 會話具有通用參數:日期、ID 號、用戶設備類別、瀏覽器、操作系統等。除了每個會話的通用參數外,還附有命中表。

hits 表包含有關用戶在站點上的操作的信息。 例如,如果用戶點擊橫幅、翻閱目錄、打開產品頁面、將產品放入購物籃或下訂單,這些操作將記錄在命中表中。
如果用戶在網站上下訂單,訂單的相關信息也將輸入到命中表中:
- transactionId(標識交易的編號)
- transactionRevenue(訂單總價值)
- transactionShipping(運費)
使用 OWOX BI 收集的會話數據表具有類似的結構。
假設您想知道過去一個月紐約市用戶的訂單數量。 要找出答案,您需要參考 hits 表併計算唯一事務 ID 的數量。 為了從這些表中提取數據,標準 SQL 有一個 UNNEST 函數:
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City 如果訂單信息記錄在單獨的表中而不是嵌套表中,則必須使用 JOIN 將包含訂單信息的表和包含會話數據的表結合起來,以便找出在哪些會話中下訂單。
更多子查詢選項
如果需要從多級嵌套字段中提取數據,可以使用 SELECT 和 WHERE 添加子查詢。 例如,在 OWOX BI 會話流表中,另一個子表 product 被寫入 hits 子表。 產品子表收集通過增強型電子商務數組傳輸的產品數據。 如果在網站上設置了增強型電子商務,並且用戶查看了產品頁面,則該產品的特徵將記錄在產品子表中。
要獲得這些產品特徵,您需要在主查詢中添加一個子查詢。 對於每個產品特性,在括號中創建一個單獨的 SELECT 子查詢:
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD`
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` 由於標準 SQL 的功能,構建查詢邏輯和編寫代碼變得更加容易。 作為比較,在 Legacy SQL 中,您需要編寫這種類型的階梯:
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )對外部資源的請求
使用標準 SQL,您可以直接從 Google Bigtable、Google Cloud Storage、Google Drive 和 Google Sheets 訪問 BigQuery 表。
也就是說,無需將整個表加載到 BigQuery 中,您可以通過一次查詢刪除數據,選擇您需要的參數,然後將它們上傳到雲存儲。
更多用戶功能 (UDF)
如果您需要使用未記錄的公式,用戶定義函數 (UDF) 將為您提供幫助。 在我們的實踐中,這種情況很少發生,因為標準 SQL 文檔幾乎涵蓋了數字分析的所有任務。
在標準 SQL 中,用戶定義的函數可以用 SQL 或 JavaScript 編寫; 舊版 SQL 僅支持 JavaScript。 這些函數的參數是列,它們取的值是操作列的結果。 在標準 SQL 中,可以在與查詢相同的窗口中編寫函數。
更多JOIN條件
在舊版 SQL 中,JOIN 條件可以基於相等或列名。 除了這些選項之外,標準 SQL 方言還支持通過不等式和任意表達式進行 JOIN。
例如,為了識別不公平的 CPA 合作夥伴,我們可以選擇在交易後 60 秒內更換來源的會話。 要在標準 SQL 中做到這一點,我們可以在 JOIN 條件中添加一個不等式:
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime 標準 SQL 關於 JOIN 的唯一限制是它不允許半連接形式為 WHERE column IN (SELECT ...) 的子查詢:
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESC
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESC犯錯的機會更小
如果條件不正確,舊版 SQL 中的某些函數會返回 NULL。 例如,如果除以零已經悄悄進入您的計算,則將執行查詢,並且 NULL 條目將出現在表的結果行中。 這可能會掩蓋查詢或數據中的問題。
標準 SQL 的邏輯更直接。 如果條件或輸入數據不正確,查詢將生成錯誤,例如“除以零”,因此您可以快速更正查詢。 標準 SQL 中嵌入了以下檢查:
- +、-、×、SUM、AVG、STDEV 的有效值
- 被零除
請求運行得更快
由於對傳入數據進行了初步過濾,用標準 SQL 編寫的 JOIN 查詢比用傳統 SQL 編寫的查詢要快。 首先,查詢選擇匹配 JOIN 條件的行,然後處理它們。
將來,Google BigQuery 將致力於提高僅針對標準 SQL 的查詢的速度和性能。
可以編輯表格:插入和刪除行、更新
標準 SQL 中提供了數據操作語言 (DML) 函數。 這意味著您可以通過編寫查詢的同一窗口更新表並在其中添加或刪除行。 例如,使用 DML,您可以將兩個表中的數據合併為一個:
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)代碼更易於閱讀和編輯
使用標準 SQL,不僅可以使用 SELECT 還可以使用 WITH 啟動複雜的查詢,從而使代碼更易於閱讀、註釋和理解。 這也意味著更容易防止自己的錯誤和糾正他人的錯誤。
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2 如果您的計算是分幾個階段完成的,那麼使用 WITH 運算符會很方便。 首先,您可以在子查詢中收集中間指標,然後進行最終計算。
包含 BigQuery 的 Google Cloud Platform (GCP) 是一個用於處理大數據的全週期平台,從組織數據倉庫或數據云到運行科學實驗以及預測性和規範性分析。 隨著標準 SQL 的推出,BigQuery 正在擴大其受眾。 對於營銷分析師、產品分析師、數據科學家和其他專家團隊來說,與 GCP 合作變得越來越有趣。
標準 SQL 的功能和用例示例
在 OWOX BI,我們經常處理使用標準 Google Analytics 360 導出到 Google BigQuery 或 OWOX BI Pipeline 編譯的表。 在下面的示例中,我們將查看針對此類數據的 SQL 查詢的細節。
如果您還沒有在 BigQuery 中從您的站點收集數據,您可以嘗試使用 OWOX BI 的試用版免費這樣做。
1.選擇時間間隔的數據
在 Google BigQuery 中,您網站的用戶行為數據存儲在通配符表(帶有星號的表)中; 每天形成一個單獨的表格。 這些表具有相同的名稱:僅後綴不同。 後綴是格式為 YYYYMMDD 的日期。 例如,表 owoxbi_sessions_20190301 包含 2019 年 3 月 1 日的會話數據。
我們可以在一個請求中直接引用一組這樣的表來獲取數據,例如從 2019 年 2 月 1 日到 2 月 28 日。為此,我們需要在 FROM 中將 YYYYMMDD 替換為 *,在 WHERE 中,我們需要為時間間隔的開始和結束指定表後綴:
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �'
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �' 我們並不總是知道我們想要收集數據的具體日期。 例如,我們可能每週都需要分析過去三個月的數據。 為此,我們可以使用 FORMAT_DATE 函數:
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) 在 BETWEEN 之後,我們記錄第一個表的後綴。 CURRENT_DATE (), INTERVAL 3 MONTHS 表示«選擇從當前日期開始的最後 3 個月的數據。» 第二個表後綴在 AND 之後格式化。 需要將間隔結束標記為昨天:CURRENT_DATE (), INTERVAL 1 DAY。
2.檢索用戶參數和指標
Google Analytics(分析)導出表中的用戶參數和指標被寫入嵌套匹配表以及 customDimensions 和 customMetrics 子表。 所有自定義維度都記錄在兩列中:一列是網站上收集的參數數量,第二列是它們的值。 這是一擊傳輸的所有參數的樣子:
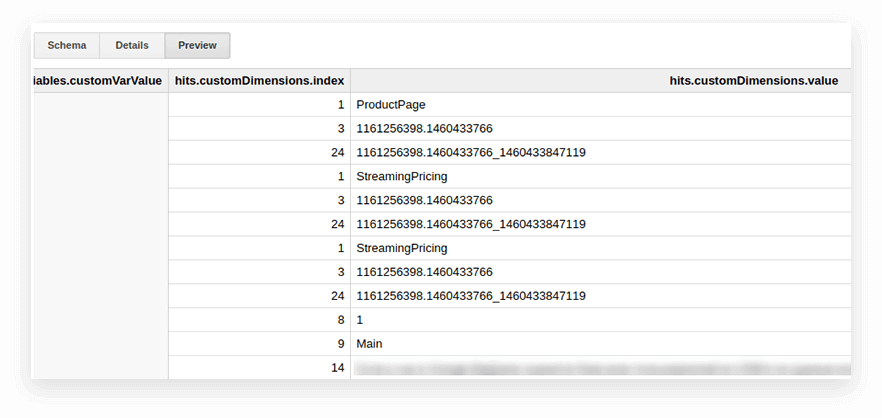
為了解壓它們並將必要的參數寫入單獨的列,我們使用以下 SQL 查詢:
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 這是請求中的樣子:
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201`
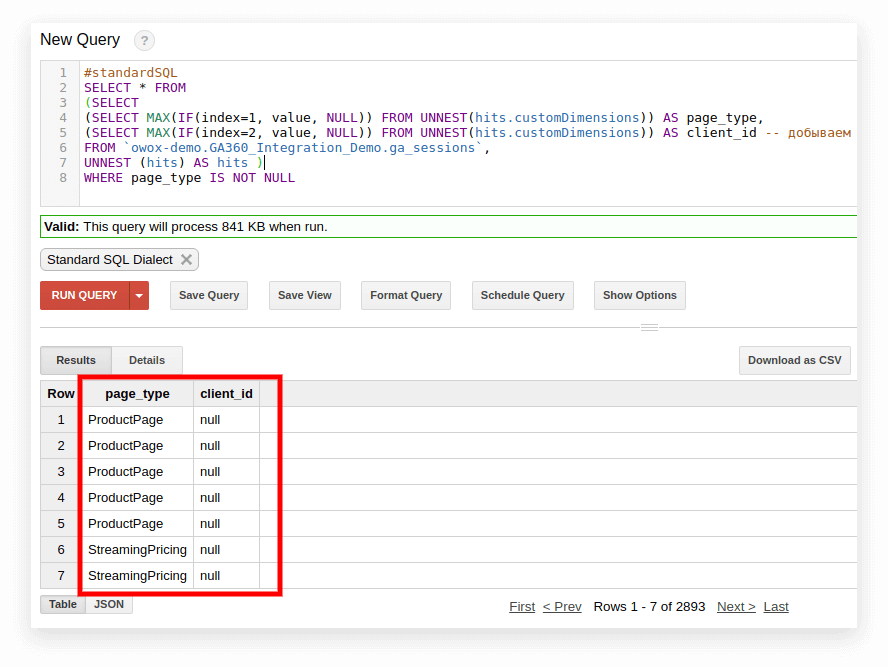
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201` 在下面的屏幕截圖中,我們從 Google BigQuery 中的 Google Analytics 360 演示數據中選擇了參數 1 和 2,並將它們命名為 page_type 和 client_id。 每個參數都記錄在單獨的列中:

3. 按流量來源、渠道、活動、城市、設備類別計算會話數
如果您計劃在 Google Data Studio 中可視化數據並按城市和設備類別進行過濾,此類計算非常有用。 使用 COUNT 窗口函數很容易做到這一點:
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`4. 合併多張表的相同數據
假設您在多個 BigQuery 表中收集已完成訂單的數據:一個收集來自商店 A 的所有訂單,另一個收集來自商店 B 的訂單。您希望將它們合併到一個包含以下列的表中:
- client_id — 標識唯一買家的數字
- transaction_created — TIMESTAMP 格式的訂單創建時間
- transaction_id — 訂單號
- is_approved — 訂單是否被確認
- transaction_revenue — 訂單金額
在我們的示例中,從 2018 年 1 月 1 日到昨天的訂單必須在表中。 為此,請從每組表中選擇適當的列,為它們分配相同的名稱,然後將結果與 UNION ALL 結合起來:
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC5.創建流量渠道組字典
當數據進入 Google Analytics 時,系統會自動確定特定轉換所屬的組:直接、自然搜索、付費搜索等。 為了識別一組渠道,Google Analytics 會查看轉換的 UTM 標籤,即 utm_source 和 utm_medium。 您可以在 Google Analytics(分析)幫助中閱讀有關渠道組和定義規則的更多信息。
如果 OWOX BI 客戶端想要將自己的名稱分配給通道組,我們創建一個字典,該轉換屬於特定通道。 為此,我們使用條件 CASE 運算符和 REGEXP_CONTAINS 函數。 該函數選擇出現指定正則表達式的值。
我們建議您從 Google Analytics 中的來源列表中獲取名稱。 以下是如何將此類條件添加到請求正文的示例:
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201` 如何切換到標準 SQL
如果您還沒有切換到標準 SQL,您可以隨時切換。 主要是避免在一個請求中混合方言。
選項 1. 切換到 Google BigQuery 界面
舊版 BigQuery 界面默認使用舊版 SQL。 要在方言之間切換,請單擊查詢輸入字段下的Show Options並取消選中 SQL Dialect 旁邊的Use Legacy SQL框。
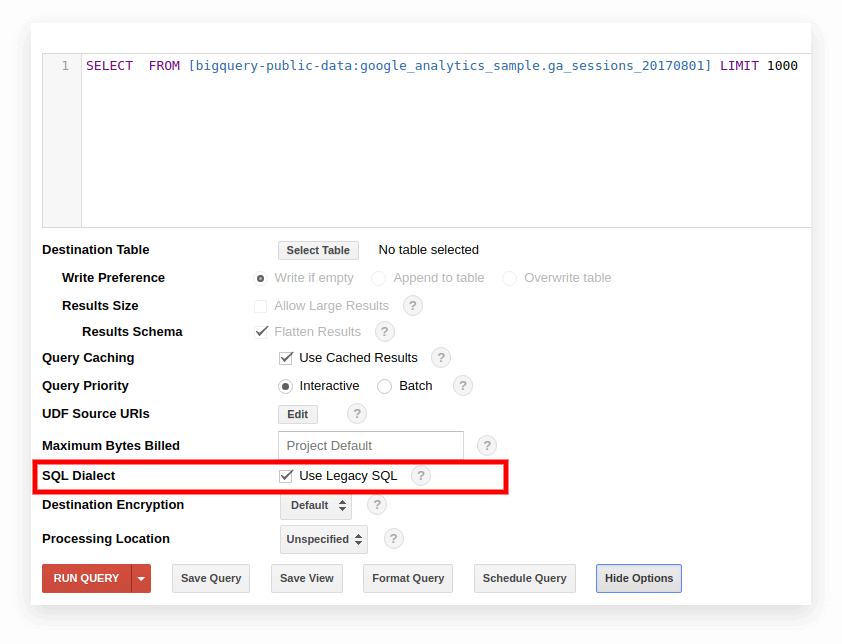
新接口默認使用標準 SQL。 在這裡,您需要轉到更多選項卡來切換方言:
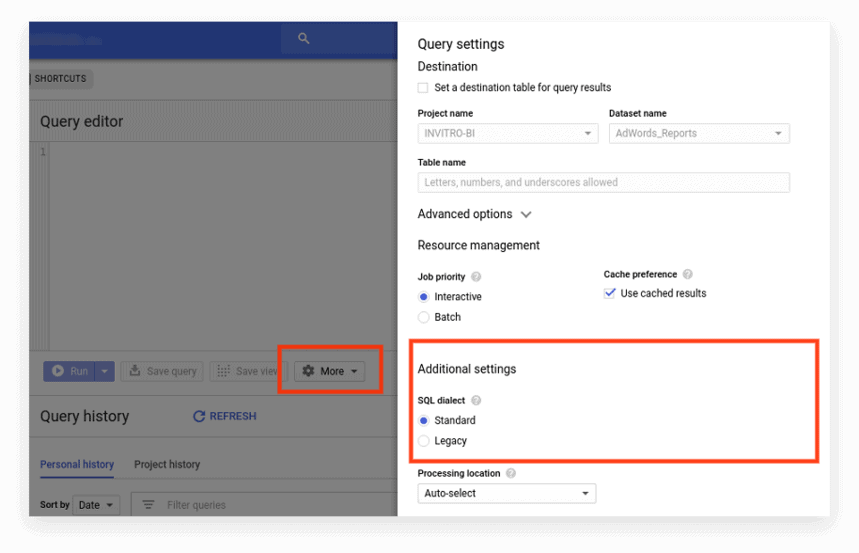
選項 2. 在請求的開頭寫前綴
如果您沒有勾選請求設置,您可以從所需的前綴(#standardSQL 或 #legacySQL)開始:
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10;
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10; 在這種情況下,Google BigQuery 將忽略界面中的設置,並使用前綴中指定的方言運行查詢。
如果您有使用 Apps 腳本按計劃啟動的視圖或保存的查詢,請不要忘記在腳本中將 useLegacySql 的值更改為 false:
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }選項 3. 轉換為視圖的標準 SQL
如果您使用 Google BigQuery 而不是表而是視圖,則無法在標準 SQL 方言中訪問這些視圖。 也就是說,如果您的演示文稿是用 Legacy SQL 編寫的,那麼您就不能在 Standard SQL 中向它編寫請求。
要將視圖傳輸到標準 SQL,您需要手動重寫創建它的查詢。 最簡單的方法是通過 BigQuery 界面。
1. 打開視圖:
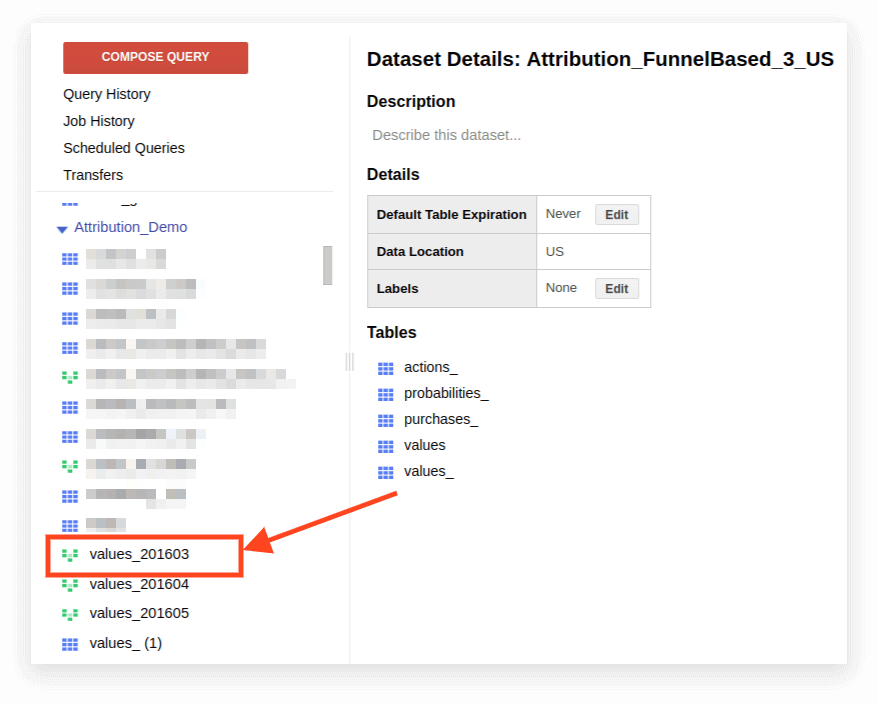
2. 單擊詳細信息。 查詢文本應打開,編輯查詢按鈕將出現在下方:
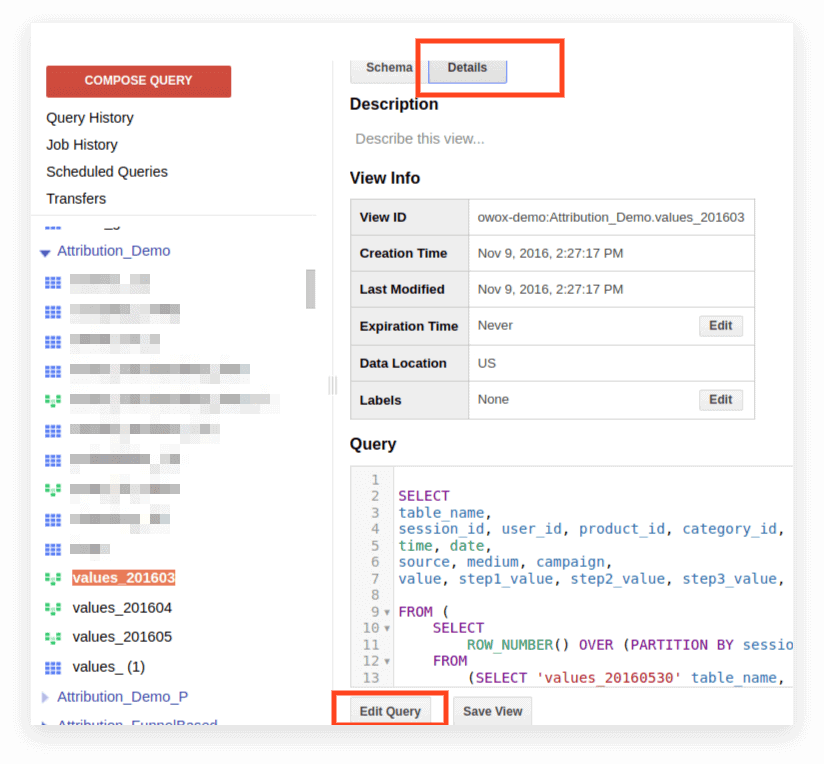
現在您可以根據標準 SQL 的規則編輯請求。
如果您打算繼續將請求用作演示文稿,請在完成編輯後單擊保存視圖。
兼容性、語法特性、運算符、函數
兼容性
由於標準 SQL 的實施,您可以直接從 BigQuery 直接訪問存儲在其他服務中的數據:
- 谷歌云存儲日誌文件
- Google Bigtable 中的交易記錄
- 其他來源的數據
這使您可以將 Google Cloud Platform 產品用於任何分析任務,包括基於機器學習算法的預測性和規範性分析。
查詢語法
Standard 方言中的查詢結構與 Legacy 中的幾乎相同:
表和視圖的名稱用句點(句號)分隔,整個查詢用重音括起來:`project_name.data_name_name.table_name``bigquery-public-data.samples.natality`
查詢的完整語法以及每個運算符中可以包含的內容的說明在 BigQuery 文檔中編譯為架構。
標準 SQL 語法的特點:
- 需要逗號來列出 SELECT 語句中的字段。
- 如果在 FROM 之後使用 UNNEST 運算符,則在 UNNEST 之前放置一個逗號或 JOIN。
- FROM 前不能加逗號。
- 兩個查詢之間的逗號等於 CROSS JOIN,所以要小心。
- JOIN 不僅可以通過列或相等來完成,還可以通過任意表達式和不等式來完成。
- 可以在 SQL 表達式的任何部分(在 SELECT、FROM、WHERE 等中)編寫複雜的子查詢。 實際上,還不能像在其他數據庫中那樣使用 WHERE column_name IN (SELECT ...) 這樣的表達式。
運營商
在標準 SQL 中,運算符定義數據的類型。 例如,數組總是寫在方括號 [] 中。 運算符用於比較、匹配邏輯表達式(NOT、OR、AND)和算術計算。
職能
標準 SQL 支持比 Legacy 更多的特性:傳統聚合(sum、number、minimum、maximum); 數學、字符串和統計函數; 以及 HyperLogLog ++ 等稀有格式。
在標準方言中,有更多用於處理日期和 TIMESTAMP 的功能。 Google 的文檔中提供了完整的功能列表。 最常用的函數用於處理日期、字符串、聚合和窗口。
1.聚合函數
COUNT (DISTINCT column_name) 計算列中唯一值的數量。 例如,假設我們需要計算 2019 年 3 月 1 日來自移動設備的會話數。由於會話編號可以在不同的行上重複,我們只想計算唯一的會話編號值:
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile' SUM (column_name) — 列中值的總和
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile' 最小(列名)| MAX (column_name) — 列中的最小值和最大值。 這些函數便於檢查表中數據的分佈情況。
2.窗口(分析)函數
分析函數考慮的不是整個表的值,而是某個窗口的值——您感興趣的一組行。也就是說,您可以在表中定義段。 例如,您可以計算 SUM(收入),而不是針對所有線路,而是針對城市、設備類別等。 您可以通過向分析函數 SUM、COUNT 和 AVG 以及其他聚合函數添加 OVER 條件 (PARTITION BY column_name) 來對其進行轉換。
例如,您需要按流量來源、渠道、活動、城市和設備類別統計會話數。 在這種情況下,我們可以使用以下表達式:
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t OVER 確定將進行計算的窗口。 PARTITION BY 指示應將哪些行分組以進行計算。 在某些函數中,需要用 ORDER BY 指定分組的順序。
有關窗口函數的完整列表,請參閱 BigQuery 文檔。
3.字符串函數
當您需要更改文本、格式化一行文本或粘合列的值時,這些非常有用。 例如,如果您想從標準的 Google Analytics 360 導出數據中生成唯一的會話標識符,則字符串函數非常有用。 讓我們考慮最流行的字符串函數。
SUBSTR 剪切部分字符串。 在請求中,這個函數寫為 SUBSTR (string_name, 0.4)。 第一個數字表示從行首跳過多少個字符,第二個數字表示要剪切多少位。 例如,假設您有一個包含 STRING 格式日期的日期列。 在這種情況下,日期如下所示:20190103。如果您想從該行中提取年份,SUBSTR 將幫助您:
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301` CONCAT(column_name 等)粘合值。 讓我們使用上一個示例中的日期列。 假設您希望像這樣記錄所有日期:2019-03-01。 要將日期從當前格式轉換為這種格式,可以使用兩個字符串函數:首先,使用 SUBSTR 剪切字符串的必要部分,然後通過連字符將它們粘合:
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301` REGEXP_CONTAINS 返回出現正則表達式的列的值:
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301` 此函數可用於 SELECT 和 WHERE。 例如,在 WHERE 中,您可以使用它選擇特定頁面:
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order')
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order') 4.日期功能
通常,表格中的日期以 STRING 格式記錄。 如果您計劃在 Google Data Studio 中可視化結果,則需要使用 PARSE_DATE 函數將表中的日期轉換為 DATE 格式。
PARSE_DATE 將 1900-01-01 格式的 STRING 轉換為 DATE 格式。
如果表中的日期看起來不同(例如,19000101 或 01_01_1900),則必須首先將它們轉換為指定的格式。
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301` DATE_DIFF 以天、週、月或年計算兩個日期之間經過的時間。 如果您需要確定用戶看到廣告和下訂單之間的時間間隔,這很有用。 下面是函數在請求中的樣子:
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301` 如果您想了解有關所列功能的更多信息,請閱讀 BigQuery Google 功能 - 詳細回顧。
營銷報告的 SQL 查詢
標準 SQL 方言允許企業通過深度細分、技術審計、營銷 KPI 分析和識別 CPA 網絡中的不公平承包商從數據中提取最大信息。 以下是一些業務問題示例,在這些問題中,對 Google BigQuery 中收集的數據的 SQL 查詢將對您有所幫助。
1. ROPO分析:評估線上活動對線下銷售的貢獻。 要執行 ROPO 分析,您需要將在線用戶行為數據與來自 CRM、呼叫跟踪系統和移動應用程序的數據相結合。
如果在一個和第二個鹼基中有一個鍵——對於每個用戶來說都是唯一的公共參數(例如,用戶 ID)——你可以跟踪:
哪些用戶在商店購買商品之前訪問了該網站
用戶在網站上的行為方式
用戶做出購買決定需要多長時間
哪些廣告系列在線下購買方面的增幅最大。
2. 通過任何參數組合對客戶進行細分,從網站上的行為(訪問的頁面、查看的產品、購買前訪問網站的次數)到會員卡號和購買的物品。
3. 找出哪些 CPA 合作夥伴在惡意工作並替換 UTM 標籤。
4、通過銷售漏斗分析用戶的進度。
我們準備了一系列標準 SQL 方言的查詢。 如果您已經從您的網站、廣告來源和 Google BigQuery 中的 CRM 系統收集數據,則可以使用這些模板來解決您的業務問題。 只需將 BigQuery 中的項目名稱、數據集和表替換為您自己的。 在集合中,您將收到 11 個 SQL 查詢。
對於使用從 Google Analytics 360 到 Google BigQuery 的標準導出收集的數據:
- 任何參數上下文中的用戶操作
- 關鍵用戶操作統計
- 查看特定產品頁面的用戶
- 購買特定產品的用戶的操作
- 使用任何必要的步驟設置漏斗
- 內部搜索網站的有效性
對於使用 OWOX BI 在 Google BigQuery 中收集的數據:
- 按來源和渠道劃分的消費
- 城市吸引遊客的平均成本
- ROAS 按來源和渠道劃分的毛利潤
- 按付款方式和交付方式在 CRM 中的訂單數量
- 各城市的平均交貨時間
如果您有關於查詢 Google BigQuery 數據的問題,但在本文中沒有找到答案,請在評論中提問。 我們會盡力幫助您。