
Standard-SQL in Google BigQuery: Vorteile und Anwendungsbeispiele im Marketing
Veröffentlicht: 2022-04-12Im Jahr 2016 führte Google BigQuery eine neue Art der Kommunikation mit Tabellen ein: Standard-SQL. Bis dahin hatte BigQuery seine eigene strukturierte Abfragesprache namens BigQuery SQL (heute Legacy SQL genannt).
Auf den ersten Blick gibt es keinen großen Unterschied zwischen Legacy- und Standard-SQL: Die Namen von Tabellen werden etwas anders geschrieben; Standard hat etwas strengere Grammatikanforderungen (z. B. darf vor FROM kein Komma gesetzt werden) und mehr Datentypen. Aber wenn Sie genau hinsehen, gibt es einige geringfügige Syntaxänderungen, die Marketingfachleuten viele Vorteile verschaffen.
In diesem Artikel erhalten Sie Antworten auf die folgenden Fragen:
- Was sind die Vorteile von Standard-SQL gegenüber Legacy-SQL?
- Was sind die Fähigkeiten von Standard-SQL und wie wird es verwendet?
- Wie kann ich von Legacy zu Standard-SQL wechseln?
- Mit welchen anderen Diensten, Syntaxfeatures, Operatoren und Funktionen ist Standard-SQL kompatibel?
- Wie kann ich SQL-Abfragen für Marketingberichte verwenden?
Was sind die Vorteile von Standard-SQL gegenüber Legacy-SQL?
Neue Datentypen: Arrays und verschachtelte Felder
Standard-SQL unterstützt neue Datentypen: ARRAY und STRUCT (Arrays und verschachtelte Felder). Das bedeutet, dass es in BigQuery einfacher geworden ist, mit Tabellen zu arbeiten, die aus JSON/Avro-Dateien geladen wurden, die oft mehrstufige Anhänge enthalten.
Ein verschachteltes Feld ist eine Minitabelle in einer größeren:
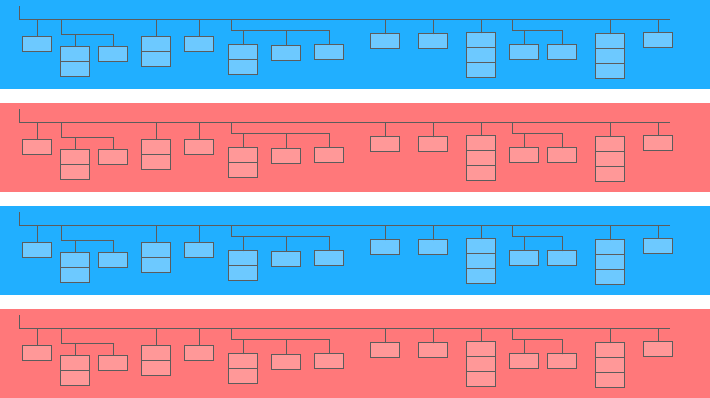
Im obigen Diagramm sind die blauen und gelben Balken die Linien, in die Minitabellen eingebettet sind. Jede Zeile ist eine Sitzung. Sitzungen haben gemeinsame Parameter: Datum, ID-Nummer, Kategorie des Benutzergeräts, Browser, Betriebssystem usw. Zusätzlich zu den allgemeinen Parametern für jede Sitzung ist die Treffertabelle an die Zeile angehängt.

Die Treffertabelle enthält Informationen über Benutzeraktionen auf der Website. Klickt ein Nutzer beispielsweise auf ein Banner, blättert im Katalog, öffnet eine Produktseite, legt ein Produkt in den Warenkorb oder gibt eine Bestellung auf, werden diese Aktionen in der Treffertabelle erfasst.
Wenn ein Benutzer eine Bestellung auf der Seite aufgibt, werden auch Informationen über die Bestellung in die Treffertabelle eingetragen:
- TransactionId (Nummer, die die Transaktion identifiziert)
- TransactionRevenue (Gesamtwert der Bestellung)
- TransaktionVersand (Versandkosten)
Mit OWOX BI gesammelte Sitzungsdatentabellen haben eine ähnliche Struktur.
Angenommen, Sie möchten die Anzahl der Bestellungen von Benutzern in New York City im letzten Monat wissen. Um dies herauszufinden, müssen Sie sich auf die Treffertabelle beziehen und die Anzahl der eindeutigen Transaktions-IDs zählen. Um Daten aus solchen Tabellen zu extrahieren, hat Standard-SQL eine UNNEST-Funktion:
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City Wenn die Bestellinformationen in einer separaten Tabelle und nicht in einer verschachtelten Tabelle aufgezeichnet wurden, müssten Sie die Tabelle mit Bestellinformationen und die Tabelle mit Sitzungsdaten mit JOIN kombinieren, um herauszufinden, in welchen Sitzungen Bestellungen getätigt wurden.
Weitere Unterabfrageoptionen
Wenn Sie Daten aus verschachtelten Feldern mit mehreren Ebenen extrahieren müssen, können Sie Unterabfragen mit SELECT und WHERE hinzufügen. Beispielsweise wird in OWOX BI-Sitzungsstreamingtabellen eine andere Untertabelle, Produkt, in die Untertabelle für Treffer geschrieben. Die Produktuntertabelle sammelt Produktdaten, die mit einem erweiterten E-Commerce-Array übertragen werden. Wenn auf der Website erweiterter E-Commerce eingerichtet ist und ein Benutzer sich eine Produktseite angesehen hat, werden Merkmale dieses Produkts in der Produktuntertabelle aufgezeichnet.
Um diese Produkteigenschaften zu erhalten, benötigen Sie eine Unterabfrage innerhalb der Hauptabfrage. Für jedes Produktmerkmal wird in Klammern eine eigene SELECT-Unterabfrage erstellt:
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD`
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` Dank der Funktionen von Standard-SQL ist es einfacher, Abfragelogik zu erstellen und Code zu schreiben. Zum Vergleich müssten Sie in Legacy-SQL diese Art von Ladder schreiben:
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )Anfragen an externe Quellen
Mit Standard-SQL können Sie direkt von Google Bigtable, Google Cloud Storage, Google Drive und Google Sheets auf BigQuery-Tabellen zugreifen.
Das heißt, anstatt die gesamte Tabelle in BigQuery zu laden, können Sie die Daten mit einer einzigen Abfrage löschen, die benötigten Parameter auswählen und in den Cloud-Speicher hochladen.
Weitere Benutzerfunktionen (UDF)
Wenn Sie eine Formel verwenden müssen, die nicht dokumentiert ist, helfen Ihnen benutzerdefinierte Funktionen (UDF). In unserer Praxis kommt das selten vor, da die Standard-SQL-Dokumentation fast alle Aufgaben der Digital Analytics abdeckt.
In Standard-SQL können benutzerdefinierte Funktionen in SQL oder JavaScript geschrieben werden; Legacy-SQL unterstützt nur JavaScript. Die Argumente dieser Funktionen sind Spalten, und die Werte, die sie annehmen, sind das Ergebnis der Manipulation von Spalten. In Standard-SQL können Funktionen im selben Fenster wie Abfragen geschrieben werden.
Weitere JOIN-Bedingungen
In Legacy-SQL können JOIN-Bedingungen auf Gleichheit oder Spaltennamen basieren. Zusätzlich zu diesen Optionen unterstützt der Standard-SQL-Dialekt JOIN durch Ungleichheit und durch beliebigen Ausdruck.
Um beispielsweise unfaire CPA-Partner zu identifizieren, können wir Sitzungen auswählen, in denen die Quelle innerhalb von 60 Sekunden nach der Transaktion ersetzt wurde. Um dies in Standard-SQL zu tun, können wir der JOIN-Bedingung eine Ungleichung hinzufügen:
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime Die einzige Einschränkung von Standard-SQL in Bezug auf JOIN besteht darin, dass es keine Semi-Joins mit Unterabfragen der Form WHERE column IN (SELECT ...) zulässt:
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESC
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESCWeniger Fehlerwahrscheinlichkeit
Einige Funktionen in Legacy-SQL geben NULL zurück, wenn die Bedingung falsch ist. Wenn sich beispielsweise eine Division durch Null in Ihre Berechnungen eingeschlichen hat, wird die Abfrage ausgeführt und in den resultierenden Zeilen der Tabelle erscheinen NULL-Einträge. Dadurch können Probleme in der Abfrage oder in den Daten verdeckt werden.
Die Logik von Standard-SQL ist einfacher. Wenn eine Bedingung oder Eingabedaten falsch sind, generiert die Abfrage einen Fehler, zum Beispiel «Division durch Null», damit Sie die Abfrage schnell korrigieren können. Die folgenden Prüfungen sind in Standard-SQL eingebettet:
- Gültige Werte für +, -, ×, SUM, AVG, STDEV
- Durch Null teilen
Anfragen werden schneller ausgeführt
In Standard-SQL geschriebene JOIN-Abfragen sind schneller als in Legacy-SQL geschriebene, dank der vorläufigen Filterung eingehender Daten. Zuerst wählt die Abfrage die Zeilen aus, die den JOIN-Bedingungen entsprechen, und verarbeitet sie dann.
In Zukunft wird Google BigQuery daran arbeiten, die Geschwindigkeit und Leistung von Abfragen nur für Standard-SQL zu verbessern.
Tabellen können bearbeitet werden: Zeilen einfügen und löschen, aktualisieren
Data Manipulation Language (DML)-Funktionen sind in Standard-SQL verfügbar. Das bedeutet, dass Sie in demselben Fenster, in dem Sie Abfragen schreiben, Tabellen aktualisieren und Zeilen hinzufügen oder entfernen können. Beispielsweise können Sie mit DML Daten aus zwei Tabellen zu einer kombinieren:
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)Code ist einfacher zu lesen und zu bearbeiten
Mit Standard-SQL können komplexe Abfragen nicht nur mit SELECT, sondern auch mit WITH gestartet werden, wodurch Code einfacher zu lesen, zu kommentieren und zu verstehen ist. Das bedeutet auch, dass es einfacher ist, eigene Fehler zu vermeiden und Fehler anderer zu korrigieren.
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2 Es ist praktisch, mit dem WITH-Operator zu arbeiten, wenn Sie Berechnungen haben, die in mehreren Schritten durchgeführt werden. Zuerst können Sie Zwischenmetriken in Unterabfragen sammeln und dann die endgültigen Berechnungen durchführen.
Die Google Cloud Platform (GCP), die BigQuery enthält, ist eine Plattform für den gesamten Zyklus für die Arbeit mit Big Data, von der Organisation eines Data Warehouse oder einer Datencloud bis hin zur Durchführung wissenschaftlicher Experimente und prädiktiver und präskriptiver Analysen. Mit der Einführung von Standard-SQL erweitert BigQuery seine Zielgruppe. Die Arbeit mit GCP wird für Marketinganalysten, Produktanalysten, Data Scientists und Teams anderer Spezialisten immer interessanter.
Fähigkeiten von Standard-SQL und Beispiele für Anwendungsfälle
Bei OWOX BI arbeiten wir oft mit Tabellen, die mit dem standardmäßigen Google Analytics 360-Export nach Google BigQuery oder der OWOX BI-Pipeline erstellt wurden. In den folgenden Beispielen sehen wir uns die Besonderheiten von SQL-Abfragen für solche Daten an.
Wenn Sie noch keine Daten von Ihrer Website in BigQuery erfassen, können Sie dies kostenlos mit der Testversion von OWOX BI versuchen.
1. Wählen Sie Daten für ein Zeitintervall aus
In Google BigQuery werden Nutzerverhaltensdaten für Ihre Website in Wildcard-Tabellen (Tabellen mit einem Sternchen) gespeichert; Für jeden Tag wird eine separate Tabelle gebildet. Diese Tabellen haben denselben Namen, nur das Suffix ist unterschiedlich. Das Suffix ist das Datum im Format YYYYMMDD. Beispielsweise enthält die Tabelle owoxbi_sessions_20190301 Daten zu Sitzungen für den 1. März 2019.
Wir können in einer Anfrage direkt auf eine Gruppe solcher Tabellen verweisen, um beispielsweise Daten vom 1. bis 28. Februar 2019 zu erhalten. Dazu müssen wir YYYYMMDD durch ein * in FROM und in WHERE ersetzen. wir müssen die Tabellensuffixe für den Beginn und das Ende des Zeitintervalls angeben:
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �'
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �' Die konkreten Daten, zu denen wir Daten erheben wollen, sind uns nicht immer bekannt. Zum Beispiel müssen wir möglicherweise jede Woche Daten für die letzten drei Monate analysieren. Dazu können wir die Funktion FORMAT_DATE verwenden:
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) Nach BETWEEN erfassen wir das Suffix der ersten Tabelle. Der Ausdruck CURRENT_DATE (), INTERVAL 3 MONTHS bedeutet «Daten für die letzten 3 Monate ab dem aktuellen Datum auswählen». Das zweite Tabellensuffix ist nach AND formatiert. Es wird benötigt, um das Ende des Intervalls als gestern zu markieren: CURRENT_DATE (), INTERVAL 1 DAY.
2. Abrufen von Benutzerparametern und Indikatoren
Benutzerparameter und Messwerte in Google Analytics-Exporttabellen werden in die verschachtelte Treffertabelle und in die untergeordneten Tabellen „customDimensions“ und „customMetrics“ geschrieben. Alle benutzerdefinierten Dimensionen werden in zwei Spalten aufgezeichnet: eine für die Anzahl der auf der Website gesammelten Parameter, die zweite für ihre Werte. So sehen alle Parameter aus, die mit einem Schlag übertragen werden:
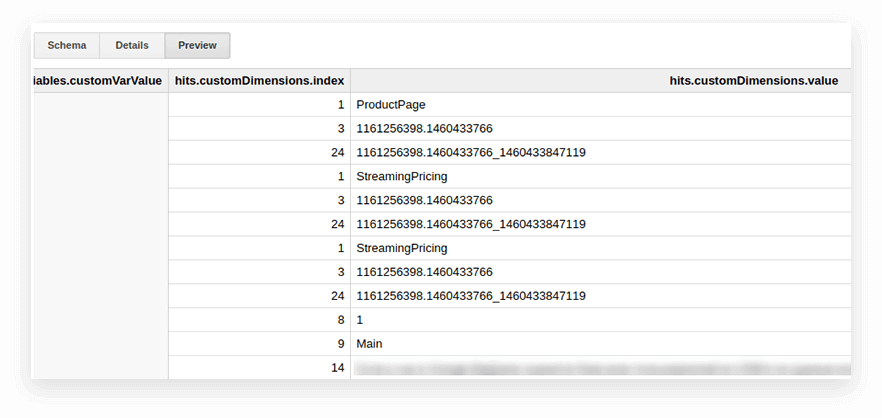
Um sie zu entpacken und die notwendigen Parameter in separate Spalten zu schreiben, verwenden wir die folgende SQL-Abfrage:
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 So sieht es in der Anfrage aus:
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201` Im Screenshot unten haben wir die Parameter 1 und 2 aus Google Analytics 360-Demodaten in Google BigQuery ausgewählt und sie page_type und client_id genannt. Jeder Parameter wird in einer separaten Spalte aufgezeichnet:

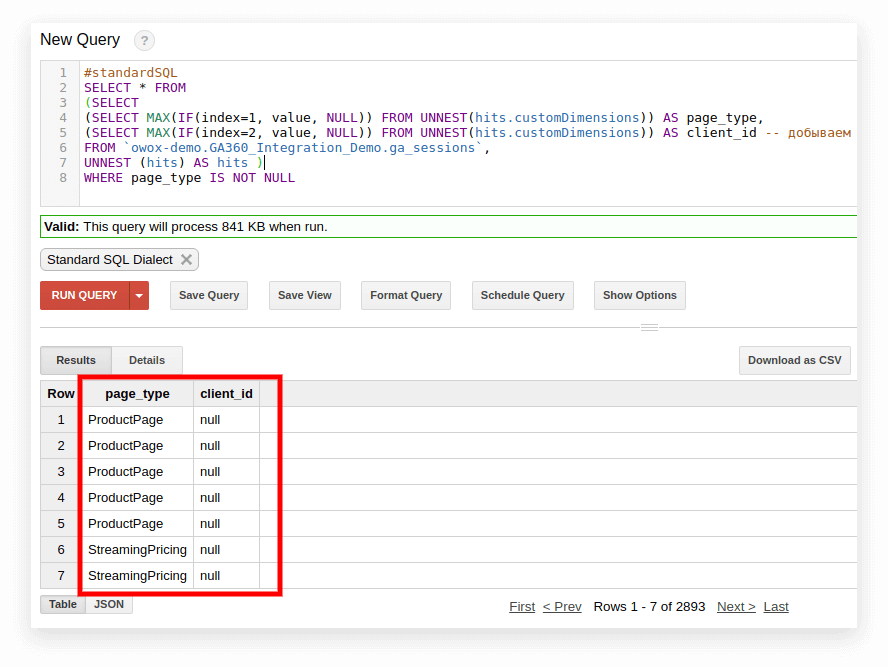
3. Berechnen Sie die Anzahl der Sitzungen nach Verkehrsquelle, Kanal, Kampagne, Stadt und Gerätekategorie
Solche Berechnungen sind nützlich, wenn Sie planen, Daten in Google Data Studio zu visualisieren und nach Stadt und Gerätekategorie zu filtern. Das geht ganz einfach mit der Fensterfunktion COUNT:
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`4. Kombinieren Sie dieselben Daten aus mehreren Tabellen
Angenommen, Sie erfassen Daten zu abgeschlossenen Bestellungen in mehreren BigQuery-Tabellen: Eine erfasst alle Bestellungen von Geschäft A, die andere erfasst Bestellungen von Geschäft B. Sie möchten sie in einer Tabelle mit diesen Spalten kombinieren:
- client_id — eine Zahl, die einen eindeutigen Käufer identifiziert
- transaction_created – Auftragserstellungszeit im TIMESTAMP-Format
- transaction_id — Bestellnummer
- is_approved — ob die Bestellung bestätigt wurde
- transaction_revenue — Bestellbetrag
In unserem Beispiel müssen Bestellungen vom 1. Januar 2018 bis gestern in der Tabelle stehen. Wählen Sie dazu die entsprechenden Spalten aus jeder Tabellengruppe aus, weisen Sie ihnen denselben Namen zu und kombinieren Sie die Ergebnisse mit UNION ALL:
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC5. Erstellen Sie ein Wörterbuch von Verkehrskanalgruppen
Wenn Daten in Google Analytics eingehen, bestimmt das System automatisch die Gruppe, zu der ein bestimmter Übergang gehört: Direkt, organische Suche, bezahlte Suche und so weiter. Um eine Gruppe von Kanälen zu identifizieren, betrachtet Google Analytics die UTM-Tags von Übergängen, nämlich utm_source und utm_medium. Weitere Informationen zu Kanalgruppen und Definitionsregeln finden Sie in der Google Analytics-Hilfe.
Wenn OWOX BI-Kunden Gruppen von Kanälen eigene Namen zuweisen möchten, erstellen wir ein Wörterbuch, welcher Übergang zu einem bestimmten Kanal gehört. Dazu verwenden wir den bedingten CASE-Operator und die Funktion REGEXP_CONTAINS. Diese Funktion wählt die Werte aus, in denen der angegebene reguläre Ausdruck vorkommt.
Wir empfehlen, Namen aus Ihrer Quellenliste in Google Analytics zu übernehmen. Hier ist ein Beispiel dafür, wie Sie solche Bedingungen zum Anfragetext hinzufügen:
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201` So wechseln Sie zu Standard-SQL
Wenn Sie noch nicht auf Standard-SQL umgestiegen sind, können Sie dies jederzeit tun. Die Hauptsache ist, das Mischen von Dialekten in einer Anfrage zu vermeiden.
Option 1. Schalten Sie die Google BigQuery-Oberfläche ein
Legacy-SQL wird standardmäßig in der alten BigQuery-Oberfläche verwendet. Um zwischen den Dialekten zu wechseln, klicken Sie unter dem Abfrageeingabefeld auf Optionen anzeigen und deaktivieren Sie das Kontrollkästchen Legacy-SQL verwenden neben SQL-Dialekt.
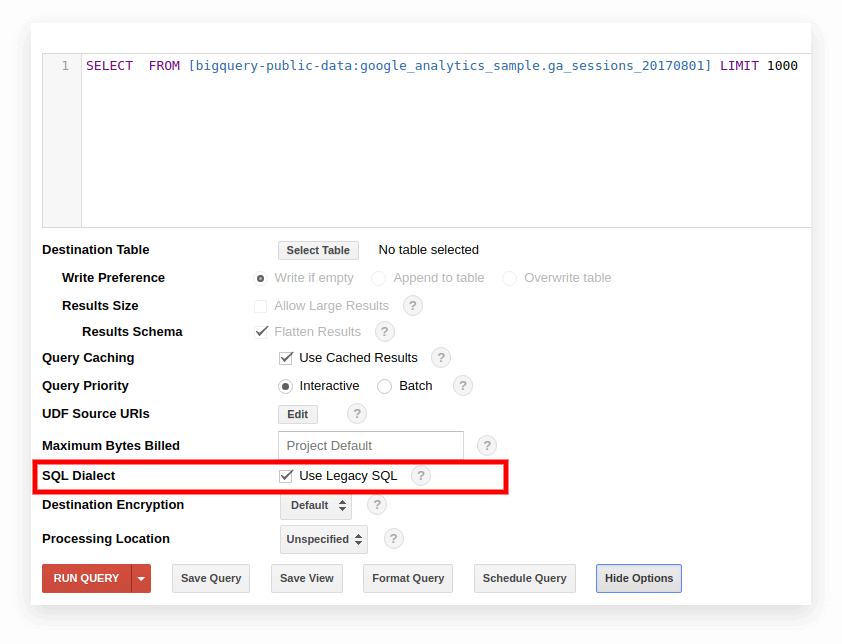
Die neue Schnittstelle verwendet standardmäßig Standard-SQL. Hier müssen Sie zur Registerkarte Mehr gehen, um die Dialekte zu wechseln:
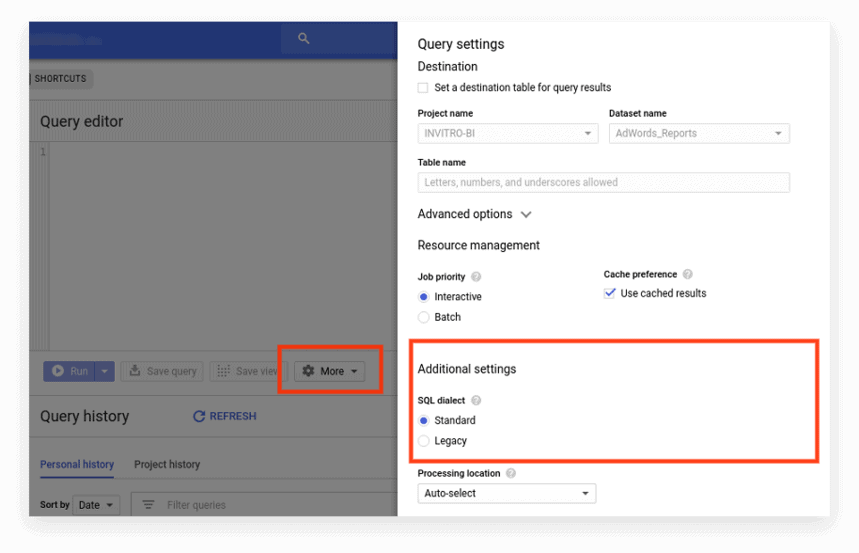
Option 2. Schreiben Sie das Präfix an den Anfang der Anfrage
Wenn Sie die Abfrageeinstellungen nicht angekreuzt haben, können Sie mit dem gewünschten Präfix beginnen (#standardSQL oder #legacySQL):
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10;
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10; In diesem Fall ignoriert Google BigQuery die Einstellungen in der Benutzeroberfläche und führt die Abfrage mit dem im Präfix angegebenen Dialekt aus.
Wenn Sie Ansichten oder gespeicherte Abfragen haben, die nach einem Zeitplan mit Apps Script gestartet werden, vergessen Sie nicht, den Wert von useLegacySql im Skript auf false zu ändern:
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }Option 3. Übergang zu Standard-SQL für Ansichten
Wenn Sie mit Google BigQuery nicht mit Tabellen, sondern mit Ansichten arbeiten, können diese Ansichten nicht im Standard-SQL-Dialekt aufgerufen werden. Das heißt, wenn Ihre Präsentation in Legacy-SQL geschrieben ist, können Sie in Standard-SQL keine Anforderungen an sie schreiben.
Um eine Ansicht in Standard-SQL zu übertragen, müssen Sie die Abfrage, mit der sie erstellt wurde, manuell umschreiben. Am einfachsten geht das über die BigQuery-Oberfläche.
1. Ansicht öffnen:
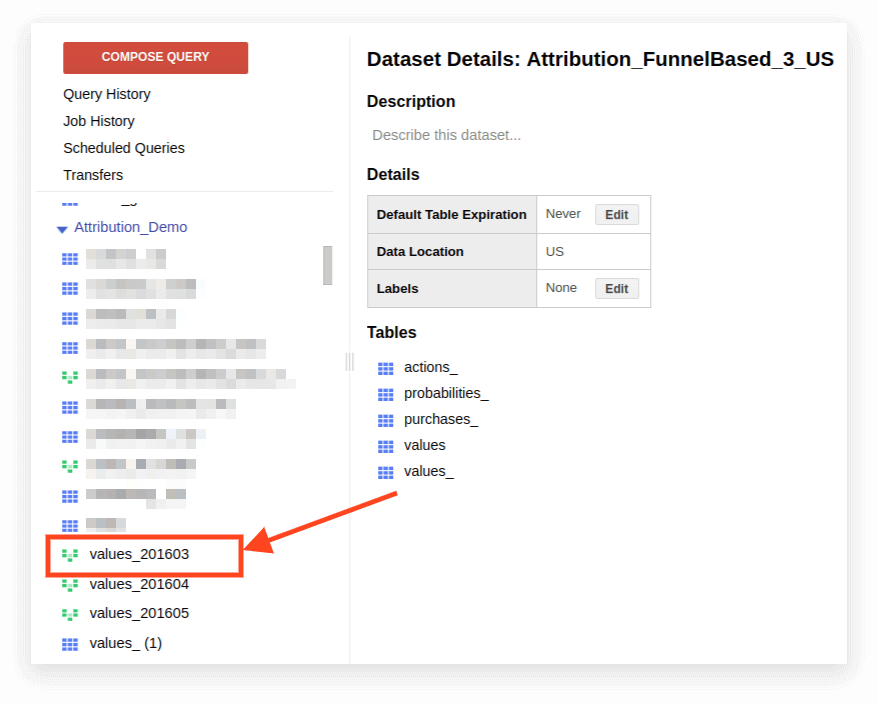
2. Klicken Sie auf Details. Der Abfragetext sollte sich öffnen und die Schaltfläche „Abfrage bearbeiten“ wird unten angezeigt:
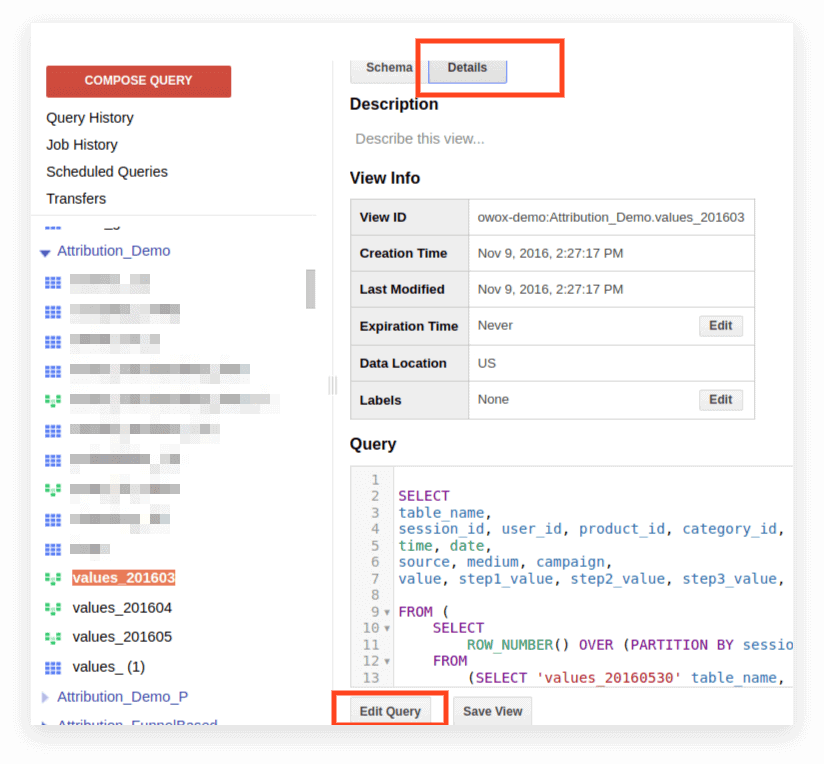
Nun können Sie die Anfrage nach den Regeln von Standard SQL bearbeiten.
Wenn Sie die Anfrage weiterhin als Präsentation verwenden möchten, klicken Sie nach Abschluss der Bearbeitung auf Ansicht speichern.
Kompatibilität, Syntaxmerkmale, Operatoren, Funktionen
Kompatibilität
Dank der Implementierung von Standard-SQL können Sie direkt aus BigQuery auf Daten zugreifen, die in anderen Diensten gespeichert sind:
- Google Cloud Storage-Protokolldateien
- Transaktionsaufzeichnungen in Google Bigtable
- Daten aus anderen Quellen
Auf diese Weise können Sie Google Cloud Platform-Produkte für beliebige Analyseaufgaben verwenden, einschließlich prädiktiver und präskriptiver Analysen auf der Grundlage von Algorithmen für maschinelles Lernen.
Abfragesyntax
Die Abfragestruktur im Standarddialekt ist fast dieselbe wie in Legacy:
Die Namen der Tabellen und Ansichten werden durch einen Punkt (Punkt) getrennt, und die gesamte Abfrage wird in gravierende Akzente eingeschlossen: `Projektname.Datenname_Name.Tabellenname``bigquery-public-data.samples.natality`
Die vollständige Syntax der Abfrage mit Erläuterungen dazu, was in jedem Operator enthalten sein kann, ist als Schema in der BigQuery-Dokumentation zusammengestellt.
Merkmale der Standard-SQL-Syntax:
- Kommas werden benötigt, um Felder in der SELECT-Anweisung aufzulisten.
- Wenn Sie den UNNEST-Operator nach FROM verwenden, wird ein Komma oder JOIN vor UNNEST gesetzt.
- Sie können kein Komma vor FROM setzen.
- Ein Komma zwischen zwei Abfragen entspricht einem CROSS JOIN, seien Sie also vorsichtig damit.
- JOIN kann nicht nur nach Spalte oder Gleichheit erfolgen, sondern auch nach beliebigen Ausdrücken und Ungleichheiten.
- Es ist möglich, komplexe Unterabfragen in jeden Teil des SQL-Ausdrucks zu schreiben (in SELECT, FROM, WHERE usw.). In der Praxis ist es noch nicht möglich, Ausdrücke wie WHERE Spaltenname IN (SELECT ...) wie in anderen Datenbanken zu verwenden.
Betreiber
In Standard-SQL definieren Operatoren den Datentyp. Beispielsweise wird ein Array immer in Klammern [] geschrieben. Operatoren werden für Vergleiche, Übereinstimmungen mit dem logischen Ausdruck (NOT, OR, AND) und in arithmetischen Berechnungen verwendet.
Funktionen
Standard-SQL unterstützt mehr Funktionen als Legacy: traditionelle Aggregation (Summe, Zahl, Minimum, Maximum); mathematische, String- und statistische Funktionen; und seltene Formate wie HyperLogLog ++.
Im Standarddialekt gibt es mehr Funktionen zum Arbeiten mit Datum und TIMESTAMP. Eine vollständige Liste der Funktionen finden Sie in der Google-Dokumentation. Die am häufigsten verwendeten Funktionen sind für die Arbeit mit Datumsangaben, Zeichenfolgen, Aggregation und Fenster.
1. Aggregationsfunktionen
COUNT (DISTINCT Spaltenname) zählt die Anzahl der eindeutigen Werte in einer Spalte. Angenommen, wir müssen die Anzahl der Sitzungen von Mobilgeräten am 1. März 2019 zählen. Da eine Sitzungsnummer in verschiedenen Zeilen wiederholt werden kann, möchten wir nur die eindeutigen Werte der Sitzungsnummer zählen:
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile' SUM (column_name) — die Summe der Werte in der Spalte
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile' MIN (Spaltenname) | MAX (column_name) — der minimale und maximale Wert in der Spalte. Diese Funktionen sind praktisch, um die Verteilung von Daten in einer Tabelle zu überprüfen.
2. Window (analytische) Funktionen
Analytische Funktionen berücksichtigen Werte nicht für die gesamte Tabelle, sondern für ein bestimmtes Fenster – eine Reihe von Zeilen, die Sie interessieren. Das heißt, Sie können Segmente innerhalb einer Tabelle definieren. Beispielsweise können Sie SUM (Umsatz) nicht für alle Linien, sondern für Städte, Gerätekategorien usw. berechnen. Sie können die Analysefunktionen SUM, COUNT und AVG sowie andere Aggregationsfunktionen umwandeln, indem Sie ihnen die OVER-Bedingung (PARTITION BY Spaltenname) hinzufügen.
Beispielsweise müssen Sie die Anzahl der Sitzungen nach Verkehrsquelle, Kanal, Kampagne, Stadt und Gerätekategorie zählen. In diesem Fall können wir den folgenden Ausdruck verwenden:
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t OVER bestimmt das Fenster, für das Berechnungen durchgeführt werden. PARTITION BY gibt an, welche Zeilen für die Berechnung gruppiert werden sollen. Bei einigen Funktionen ist es notwendig, die Reihenfolge der Gruppierung mit ORDER BY anzugeben.
Eine vollständige Liste der Fensterfunktionen finden Sie in der BigQuery-Dokumentation.
3. String-Funktionen
Diese sind nützlich, wenn Sie Text ändern, den Text in einer Zeile formatieren oder die Werte von Spalten zusammenfügen müssen. Zeichenfolgenfunktionen eignen sich beispielsweise hervorragend, wenn Sie eine eindeutige Sitzungskennung aus den standardmäßigen Google Analytics 360-Exportdaten generieren möchten. Betrachten wir die beliebtesten String-Funktionen.
SUBSTR schneidet einen Teil der Zeichenfolge ab. In der Anfrage wird diese Funktion als SUBSTR (string_name, 0.4) geschrieben. Die erste Zahl gibt an, wie viele Zeichen vom Anfang der Zeile aus übersprungen werden sollen, und die zweite Zahl gibt an, wie viele Stellen abgeschnitten werden müssen. Angenommen, Sie haben eine Datumsspalte, die Datumsangaben im STRING-Format enthält. In diesem Fall sehen die Daten so aus: 20190103. Wenn Sie aus dieser Zeile ein Jahr extrahieren möchten, hilft Ihnen SUBSTR:
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301` CONCAT (column_name usw.) klebt Werte. Verwenden wir die Datumsspalte aus dem vorherigen Beispiel. Angenommen, Sie möchten, dass alle Daten wie folgt aufgezeichnet werden: 2019-03-01. Um Datumsangaben aus ihrem aktuellen Format in dieses Format zu konvertieren, können zwei String-Funktionen verwendet werden: Schneiden Sie zuerst die erforderlichen Teile des Strings mit SUBSTR ab und kleben Sie sie dann durch den Bindestrich:
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301` REGEXP_CONTAINS gibt die Werte der Spalten zurück, in denen der reguläre Ausdruck vorkommt:
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301` Diese Funktion kann sowohl in SELECT als auch in WHERE verwendet werden. In WHERE können Sie beispielsweise bestimmte Seiten damit auswählen:
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order')
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order') 4. Datumsfunktionen
Häufig werden Daten in Tabellen im STRING-Format aufgezeichnet. Wenn Sie Ergebnisse in Google Data Studio visualisieren möchten, müssen die Daten in der Tabelle mithilfe der Funktion PARSE_DATE in das DATE-Format konvertiert werden.
PARSE_DATE konvertiert einen STRING des Formats 1900-01-01 in das DATE-Format.
Wenn die Daten in Ihren Tabellen anders aussehen (z. B. 19000101 oder 01_01_1900), müssen Sie sie zuerst in das angegebene Format konvertieren.
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301` DATE_DIFF berechnet, wie viel Zeit zwischen zwei Daten in Tagen, Wochen, Monaten oder Jahren vergangen ist. Dies ist nützlich, wenn Sie das Intervall zwischen dem Anzeigen von Werbung und dem Aufgeben einer Bestellung durch einen Benutzer ermitteln müssen. So sieht die Funktion in einer Anfrage aus:
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301` Wenn Sie mehr über die aufgeführten Funktionen erfahren möchten, lesen Sie BigQuery Google Features – A Detailed Review.
SQL-Abfragen für Marketingberichte
Der Standard-SQL-Dialekt ermöglicht es Unternehmen, maximale Informationen aus Daten mit tiefer Segmentierung, technischen Audits, Marketing-KPI-Analysen und der Identifizierung unlauterer Auftragnehmer in CPA-Netzwerken zu extrahieren. Hier sind Beispiele für Geschäftsprobleme, bei denen Ihnen SQL-Abfragen zu in Google BigQuery gesammelten Daten helfen werden.
1. ROPO-Analyse: Bewerten Sie den Beitrag von Online-Kampagnen zum Offline-Umsatz. Um eine ROPO-Analyse durchzuführen, müssen Sie Daten zum Online-Benutzerverhalten mit Daten aus Ihrem CRM, Anrufverfolgungssystem und Ihrer mobilen Anwendung kombinieren.
Wenn in der einen und der zweiten Basis ein Schlüssel vorhanden ist – ein gemeinsamer Parameter, der für jeden Benutzer eindeutig ist (z. B. die Benutzer-ID) – können Sie Folgendes nachverfolgen:
welche Benutzer die Website besucht haben, bevor sie Waren im Geschäft gekauft haben
wie sich Benutzer auf der Website verhalten haben
wie lange die Nutzer brauchten, um eine Kaufentscheidung zu treffen
welche Kampagnen den größten Anstieg bei Offlinekäufen erzielten.
2. Segmentieren Sie Kunden nach einer beliebigen Kombination von Parametern, vom Verhalten auf der Website (besuchte Seiten, angesehene Produkte, Anzahl der Besuche auf der Website vor dem Kauf) bis zur Kundenkartennummer und den gekauften Artikeln.
3. Finden Sie heraus, welche CPA-Partner in böser Absicht arbeiten und UTM-Tags ersetzen.
4. Analysieren Sie den Fortschritt der Benutzer durch den Verkaufstrichter.
Wir haben eine Auswahl von Abfragen im Standard-SQL-Dialekt vorbereitet. Wenn Sie bereits Daten von Ihrer Website, von Werbequellen und von Ihrem CRM-System in Google BigQuery sammeln, können Sie diese Vorlagen verwenden, um Ihre geschäftlichen Probleme zu lösen. Ersetzen Sie einfach den Projektnamen, das Dataset und die Tabelle in BigQuery durch Ihre eigenen. In der Sammlung erhalten Sie 11 SQL-Abfragen.
Für Daten, die mit dem Standardexport von Google Analytics 360 nach Google BigQuery erfasst wurden:
- Benutzeraktionen im Zusammenhang mit beliebigen Parametern
- Statistiken zu Key-User-Aktionen
- Benutzer, die bestimmte Produktseiten angesehen haben
- Aktionen von Benutzern, die ein bestimmtes Produkt gekauft haben
- Richten Sie den Trichter mit allen erforderlichen Schritten ein
- Effektivität der internen Suchseite
Für Daten, die in Google BigQuery mit OWOX BI erfasst wurden:
- Zugeordneter Verbrauch nach Quelle und Kanal
- Durchschnittliche Kosten, um einen Besucher anzuziehen, nach Stadt
- ROAS für den Bruttogewinn nach Quelle und Kanal
- Anzahl der Bestellungen im CRM nach Zahlungsmethode und Liefermethode
- Durchschnittliche Lieferzeit nach Stadt
Wenn Sie Fragen zum Abfragen von Google BigQuery-Daten haben, auf die Sie in diesem Artikel keine Antworten gefunden haben, stellen Sie diese in den Kommentaren. Wir werden versuchen, Ihnen zu helfen.