
Google BigQuery의 표준 SQL: 마케팅에서의 이점 및 사용 예
게시 됨: 2022-04-122016년에 Google BigQuery는 테이블과 통신하는 새로운 방법인 표준 SQL을 도입했습니다. 그때까지 BigQuery에는 BigQuery SQL(지금은 Legacy SQL이라고 함)이라는 자체 구조화된 쿼리 언어가 있었습니다.
언뜻 보기에 Legacy와 Standard SQL 사이에는 큰 차이가 없습니다. 테이블 이름은 약간 다르게 작성됩니다. 표준에는 약간 더 엄격한 문법 요구 사항(예: FROM 앞에 쉼표를 넣을 수 없음)과 더 많은 데이터 유형이 있습니다. 그러나 자세히 살펴보면 마케터에게 많은 이점을 제공하는 약간의 구문 변경이 있습니다.
이 문서에서는 다음 질문에 대한 답변을 얻을 수 있습니다.
- Legacy SQL에 비해 Standard SQL의 장점은 무엇입니까?
- 표준 SQL의 기능은 무엇이며 어떻게 사용됩니까?
- Legacy에서 Standard SQL로 어떻게 이동할 수 있습니까?
- 표준 SQL과 호환되는 다른 서비스, 구문 기능, 연산자 및 기능은 무엇입니까?
- 마케팅 보고서에 SQL 쿼리를 사용하려면 어떻게 해야 합니까?
Legacy SQL에 비해 Standard SQL의 장점은 무엇입니까?
새로운 데이터 유형: 배열 및 중첩 필드
표준 SQL은 새로운 데이터 유형인 ARRAY 및 STRUCT(배열 및 중첩 필드)를 지원합니다. 즉, BigQuery에서는 다단계 첨부 파일을 포함하는 경우가 많은 JSON/Avro 파일에서 로드된 테이블로 작업하기가 더 쉬워졌습니다.
중첩 필드는 더 큰 테이블 안에 있는 미니 테이블입니다.
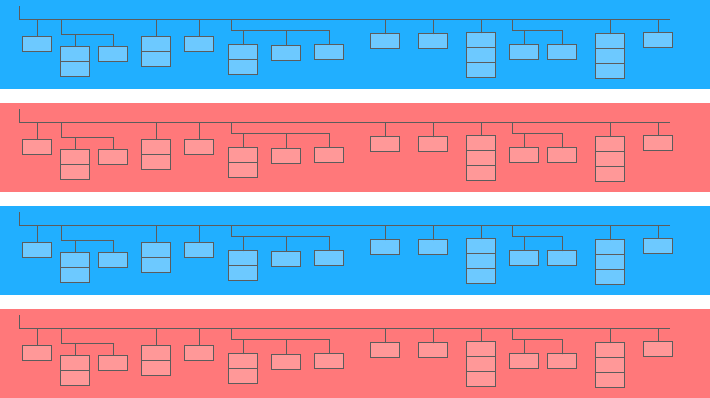
위의 다이어그램에서 파란색과 노란색 막대는 미니 테이블이 포함된 라인입니다. 각 라인은 하나의 세션입니다. 세션에는 날짜, ID 번호, 사용자 장치 범주, 브라우저, 운영 체제 등의 공통 매개변수가 있습니다. 각 세션에 대한 일반 매개변수 외에도 히트 테이블이 행에 첨부됩니다.

조회수 테이블에는 사이트에서의 사용자 작업에 대한 정보가 포함됩니다. 예를 들어 사용자가 배너를 클릭하거나 카탈로그를 넘기거나 제품 페이지를 열거나 제품을 장바구니에 담거나 주문하면 이러한 작업이 조회수 테이블에 기록됩니다.
사용자가 사이트에서 주문하면 주문에 대한 정보도 조회수 테이블에 입력됩니다.
- transactionId(트랜잭션을 식별하는 번호)
- transactionRevenue(주문의 총액)
- transaction배송비(배송비)
OWOX BI를 사용하여 수집한 세션 데이터 테이블은 유사한 구조를 가지고 있습니다.
지난 한 달 동안 뉴욕시 사용자의 주문 수를 알고 싶다고 가정합니다. 알아내려면 조회수 테이블을 참조하고 고유한 트랜잭션 ID의 수를 계산해야 합니다. 이러한 테이블에서 데이터를 추출하기 위해 표준 SQL에는 UNNEST 함수가 있습니다.
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City 주문 정보가 중첩된 테이블이 아닌 별도의 테이블에 기록된 경우 JOIN을 사용하여 주문 정보가 있는 테이블과 세션 데이터가 있는 테이블을 결합하여 어느 세션에서 주문이 이루어졌는지 알아내야 합니다.
추가 하위 쿼리 옵션
다단계 중첩 필드에서 데이터를 추출해야 하는 경우 SELECT 및 WHERE를 사용하여 하위 쿼리를 추가할 수 있습니다. 예를 들어, OWOX BI 세션 스트리밍 테이블에서 다른 하위 테이블인 product가 hit 하위 테이블에 기록됩니다. 제품 하위 테이블은 향상된 전자상거래 어레이와 함께 전송되는 제품 데이터를 수집합니다. 향상된 전자 상거래가 사이트에 설정되어 있고 사용자가 제품 페이지를 본 경우 이 제품의 특성이 제품 하위 테이블에 기록됩니다.
이러한 제품 특성을 얻으려면 기본 쿼리 내부에 하위 쿼리가 필요합니다. 각 제품 특성에 대해 별도의 SELECT 하위 쿼리가 괄호 안에 생성됩니다.
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD`
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` 표준 SQL의 기능 덕분에 쿼리 논리를 구축하고 코드를 작성하는 것이 더 쉽습니다. 비교를 위해 Legacy SQL에서는 다음 유형의 래더를 작성해야 합니다.
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )외부 소스에 대한 요청
표준 SQL을 사용하면 Google Bigtable, Google Cloud Storage, Google 드라이브 및 Google 스프레드시트에서 직접 BigQuery 테이블에 액세스할 수 있습니다.
즉, 전체 테이블을 BigQuery에 로드하는 대신 단일 쿼리로 데이터를 삭제하고 필요한 매개변수를 선택하여 클라우드 스토리지에 업로드할 수 있습니다.
더 많은 사용자 기능(UDF)
문서화되지 않은 수식을 사용해야 하는 경우 사용자 정의 함수(UDF)가 도움이 될 것입니다. 표준 SQL 문서가 디지털 분석의 거의 모든 작업을 다루기 때문에 실제로 이런 일은 거의 발생하지 않습니다.
표준 SQL에서 사용자 정의 함수는 SQL 또는 JavaScript로 작성할 수 있습니다. Legacy SQL은 JavaScript만 지원합니다. 이러한 함수의 인수는 열이며 취하는 값은 열을 조작한 결과입니다. 표준 SQL에서는 쿼리와 동일한 창에서 함수를 작성할 수 있습니다.
더 많은 JOIN 조건
Legacy SQL에서 JOIN 조건은 같음 또는 열 이름을 기반으로 할 수 있습니다. 이러한 옵션 외에도 표준 SQL 언어는 부등식 및 임의 표현식에 의한 JOIN을 지원합니다.
예를 들어 불공정한 CPA 파트너를 식별하기 위해 거래 후 60초 이내에 소스가 교체된 세션을 선택할 수 있습니다. 표준 SQL에서 이를 수행하기 위해 JOIN 조건에 부등식을 추가할 수 있습니다.
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime JOIN과 관련된 표준 SQL의 유일한 제한 사항은 WHERE column IN (SELECT ...) 형식의 하위 쿼리로 semi-join을 허용하지 않는다는 것입니다.
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESC
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESC실수의 가능성이 적음
Legacy SQL의 일부 함수는 조건이 잘못된 경우 NULL을 반환합니다. 예를 들어, 0으로 나누기가 계산에 들어간 경우 쿼리가 실행되고 테이블의 결과 행에 NULL 항목이 나타납니다. 이것은 쿼리 또는 데이터의 문제를 마스킹할 수 있습니다.
표준 SQL의 논리는 더 간단합니다. 조건 또는 입력 데이터가 잘못된 경우 쿼리는 «0으로 나누기»와 같은 오류를 생성하므로 쿼리를 빠르게 수정할 수 있습니다. 표준 SQL에는 다음 검사가 포함되어 있습니다.
- +, -, ×, SUM, AVG, STDEV에 대한 유효한 값
- 0으로 나누기
요청이 더 빠르게 실행됩니다.
표준 SQL로 작성된 JOIN 쿼리는 들어오는 데이터의 사전 필터링 덕분에 Legacy SQL로 작성된 쿼리보다 빠릅니다. 먼저 쿼리는 JOIN 조건과 일치하는 행을 선택한 다음 처리합니다.
앞으로 Google BigQuery는 표준 SQL에 대해서만 쿼리의 속도와 성능을 개선하기 위해 노력할 것입니다.
테이블 편집 가능: 행 삽입 및 삭제, 업데이트
DML(데이터 조작 언어) 기능은 표준 SQL에서 사용할 수 있습니다. 즉, 쿼리를 작성하는 동일한 창을 통해 테이블을 업데이트하고 테이블에서 행을 추가하거나 제거할 수 있습니다. 예를 들어 DML을 사용하여 두 테이블의 데이터를 하나로 결합할 수 있습니다.
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)코드를 읽고 편집하기가 더 쉽습니다.
표준 SQL을 사용하면 SELECT뿐만 아니라 WITH로도 복잡한 쿼리를 시작할 수 있으므로 코드를 더 쉽게 읽고, 주석을 달고, 이해할 수 있습니다. 이것은 또한 자신의 실수를 방지하고 다른 사람의 실수를 수정하는 것이 더 쉽다는 것을 의미합니다.
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2 여러 단계로 수행되는 계산이 있는 경우 WITH 연산자로 작업하는 것이 편리합니다. 먼저 하위 쿼리에서 중간 메트릭을 수집한 다음 최종 계산을 수행할 수 있습니다.
BigQuery가 포함된 GCP(Google Cloud Platform)는 데이터 웨어하우스 또는 데이터 클라우드 구성에서 과학 실험 및 예측 및 처방 분석 실행에 이르기까지 빅 데이터 작업을 위한 전체 주기 플랫폼입니다. 표준 SQL의 도입으로 BigQuery는 대상을 확장하고 있습니다. GCP와의 작업은 마케팅 분석가, 제품 분석가, 데이터 과학자 및 기타 전문가 팀에게 점점 더 흥미로워지고 있습니다.
표준 SQL의 기능 및 사용 사례의 예
OWOX BI에서는 Google BigQuery 또는 OWOX BI 파이프라인으로 표준 Google Analytics 360 내보내기를 사용하여 컴파일된 테이블을 사용하는 경우가 많습니다. 아래 예에서 이러한 데이터에 대한 SQL 쿼리의 세부 사항을 살펴보겠습니다.
BigQuery의 사이트에서 데이터를 아직 수집하고 있지 않다면 OWOX BI 평가판을 사용하여 무료로 데이터를 수집할 수 있습니다.
1. 시간 간격에 대한 데이터 선택
Google BigQuery에서 사이트의 사용자 행동 데이터는 와일드카드 테이블(별표가 있는 테이블)에 저장됩니다. 매일 별도의 테이블이 구성됩니다. 이 테이블은 이름이 같습니다. 접미사만 다릅니다. 접미사는 YYYYMMDD 형식의 날짜입니다. 예를 들어 owoxbi_sessions_20190301 테이블에는 2019년 3월 1일 세션에 대한 데이터가 포함되어 있습니다.
예를 들어 2019년 2월 1일부터 2월 28일까지의 데이터를 얻기 위해 하나의 요청에서 이러한 테이블 그룹을 직접 참조할 수 있습니다. 이렇게 하려면 FROM에서 YYYYMMDD를 *로 바꾸고 WHERE에서 시간 간격의 시작과 끝을 위한 테이블 접미사를 지정해야 합니다.
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �'
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �' 데이터를 수집하려는 특정 날짜가 항상 알려진 것은 아닙니다. 예를 들어 매주 지난 3개월 동안의 데이터를 분석해야 할 수 있습니다. 이를 위해 FORMAT_DATE 함수를 사용할 수 있습니다.
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) BETWEEN 이후에는 첫 번째 테이블의 접미사를 기록합니다. CURRENT_DATE(), INTERVAL 3 MONTHS라는 구문은 «현재 날짜로부터 지난 3개월 동안의 데이터 선택»을 의미합니다. 두 번째 테이블 접미사는 AND 다음에 형식이 지정됩니다. 간격의 끝을 어제로 표시하는 데 필요합니다. CURRENT_DATE(), INTERVAL 1 DAY.
2. 사용자 매개변수 및 표시기 검색
Google Analytics 내보내기 테이블의 사용자 매개변수 및 측정항목은 중첩된 조회수 테이블과 customDimensions 및 customMetrics 하위 테이블에 기록됩니다. 모든 맞춤 측정기준은 두 개의 열에 기록됩니다. 하나는 사이트에서 수집된 매개변수 수이고 다른 하나는 해당 값입니다. 한 번의 히트로 전송된 모든 매개변수는 다음과 같습니다.
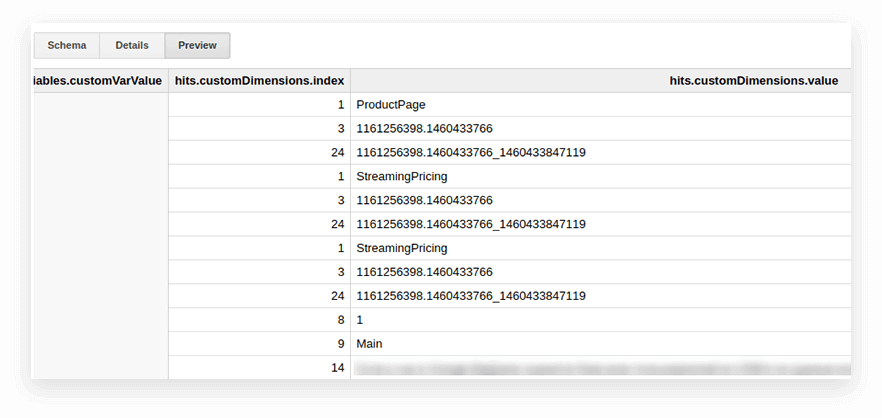
압축을 풀고 필요한 매개변수를 별도의 열에 쓰기 위해 다음 SQL 쿼리를 사용합니다.
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 요청에 다음과 같이 표시됩니다.
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201` 아래 스크린샷에서는 Google BigQuery의 Google Analytics 360 데모 데이터에서 매개변수 1과 2를 선택하고 이를 page_type 및 client_id라고 합니다. 각 매개변수는 별도의 열에 기록됩니다.

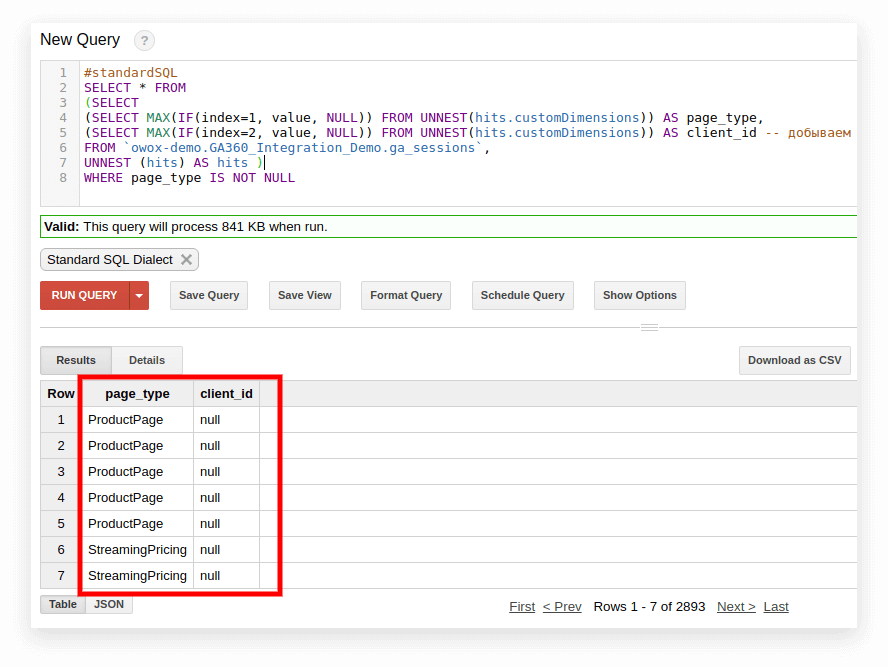
3. 트래픽 소스, 채널, 캠페인, 도시 및 기기 카테고리별로 세션 수를 계산합니다.
이러한 계산은 Google 데이터 스튜디오에서 데이터를 시각화하고 도시 및 기기 카테고리별로 필터링하려는 경우에 유용합니다. 이것은 COUNT 창 기능으로 쉽게 수행할 수 있습니다.
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`4. 여러 테이블의 동일한 데이터 결합
여러 BigQuery 테이블에서 완료된 주문에 대한 데이터를 수집한다고 가정합니다. 하나는 Store A에서 모든 주문을 수집하고 다른 하나는 Store B에서 주문을 수집합니다. 다음 열이 있는 하나의 테이블로 결합하려고 합니다.
- client_id — 고유한 구매자를 식별하는 숫자
- transaction_created — TIMESTAMP 형식의 주문 생성 시간
- transaction_id — 주문 번호
- is_approved — 주문이 확인되었는지 여부
- transaction_revenue — 주문 금액
이 예제에서는 2018년 1월 1일부터 어제까지의 주문이 테이블에 있어야 합니다. 이렇게 하려면 각 테이블 그룹에서 적절한 열을 선택하고 동일한 이름을 할당한 다음 결과를 UNION ALL과 결합합니다.
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC5. 트래픽 채널 그룹 사전 생성
데이터가 Google Analytics에 입력되면 시스템은 특정 전환이 속하는 그룹(직접, 자연 검색, 유료 검색 등)을 자동으로 결정합니다. 채널 그룹을 식별하기 위해 Google Analytics는 전환의 UTM 태그, 즉 utm_source 및 utm_medium을 확인합니다. Google Analytics 도움말에서 채널 그룹 및 정의 규칙에 대해 자세히 알아볼 수 있습니다.
OWOX BI 클라이언트가 채널 그룹에 고유한 이름을 할당하려는 경우 특정 채널에 속하는 전환이 사전을 생성합니다. 이를 위해 조건부 CASE 연산자와 REGEXP_CONTAINS 함수를 사용합니다. 이 함수는 지정된 정규식이 발생하는 값을 선택합니다.
Google Analytics의 소스 목록에서 이름을 가져오는 것이 좋습니다. 다음은 요청 본문에 이러한 조건을 추가하는 방법의 예입니다.
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201` 표준 SQL로 전환하는 방법
아직 표준 SQL로 전환하지 않았다면 언제든지 전환할 수 있습니다. 가장 중요한 것은 하나의 요청에서 방언을 혼합하는 것을 피하는 것입니다.
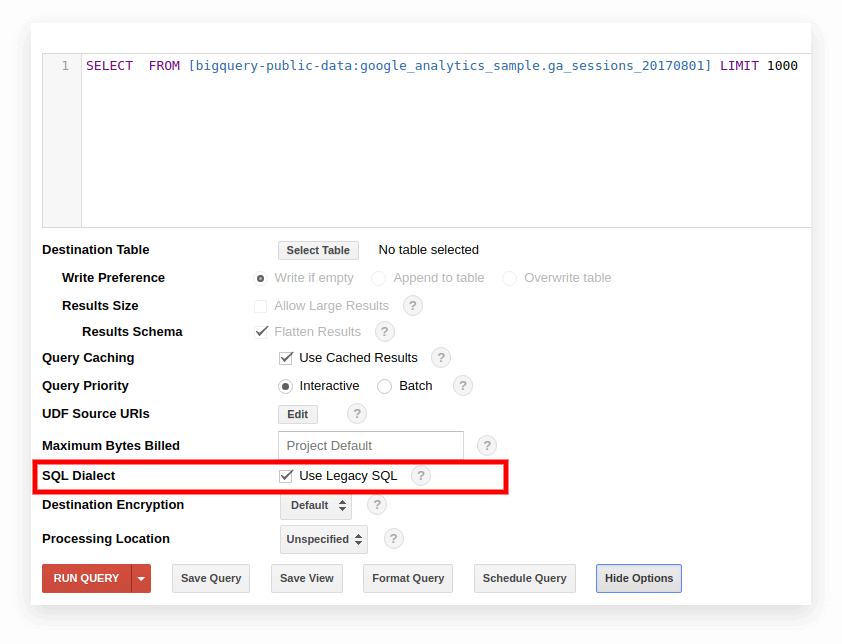
옵션 1. Google BigQuery 인터페이스에서 전환
Legacy SQL은 이전 BigQuery 인터페이스에서 기본적으로 사용됩니다. 방언 사이를 전환하려면 쿼리 입력 필드에서 옵션 표시 를 클릭하고 SQL 방언 옆에 있는 레거시 SQL 사용 상자를 선택 취소합니다.
새 인터페이스는 기본적으로 표준 SQL을 사용합니다. 여기에서 방언을 전환하려면 자세히 탭으로 이동해야 합니다.
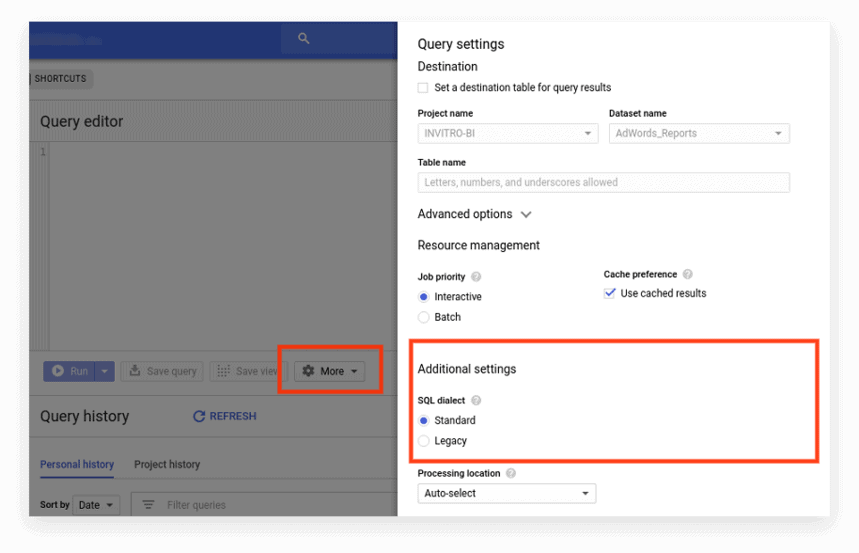
옵션 2. 요청 시작 부분에 접두사 쓰기
요청 설정을 선택하지 않은 경우 원하는 접두사(#standardSQL 또는 #legacySQL)로 시작할 수 있습니다.
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10;
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10; 이 경우 Google BigQuery는 인터페이스의 설정을 무시하고 접두사에 지정된 언어를 사용하여 쿼리를 실행합니다.
Apps Script를 사용하여 일정에 따라 실행되는 보기 또는 저장된 쿼리가 있는 경우 스크립트에서 useLegacySql 값을 false로 변경하는 것을 잊지 마십시오.
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }옵션 3. 보기에 대해 표준 SQL로 전환
테이블이 아닌 보기로 Google BigQuery로 작업하는 경우 표준 SQL 언어로 해당 보기에 액세스할 수 없습니다. 즉, 프레젠테이션이 Legacy SQL로 작성된 경우 표준 SQL로 해당 프레젠테이션에 대한 요청을 작성할 수 없습니다.
보기를 표준 SQL로 전송하려면 생성된 쿼리를 수동으로 다시 작성해야 합니다. 이를 수행하는 가장 쉬운 방법은 BigQuery 인터페이스를 사용하는 것입니다.
1. 보기를 엽니다.
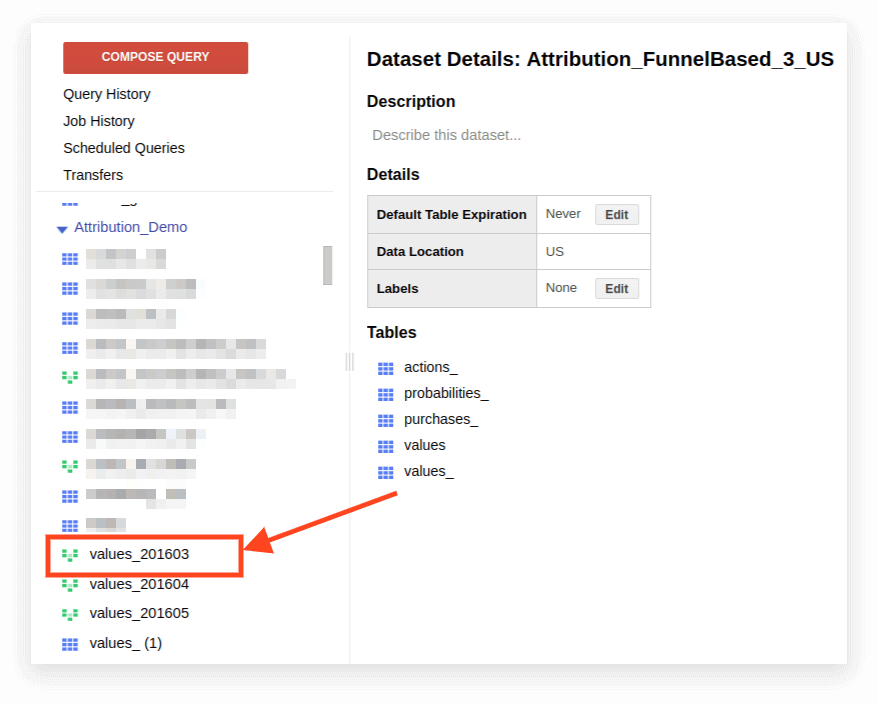
2. 세부 정보를 클릭합니다. 쿼리 텍스트가 열리고 쿼리 편집 버튼이 아래에 나타납니다.
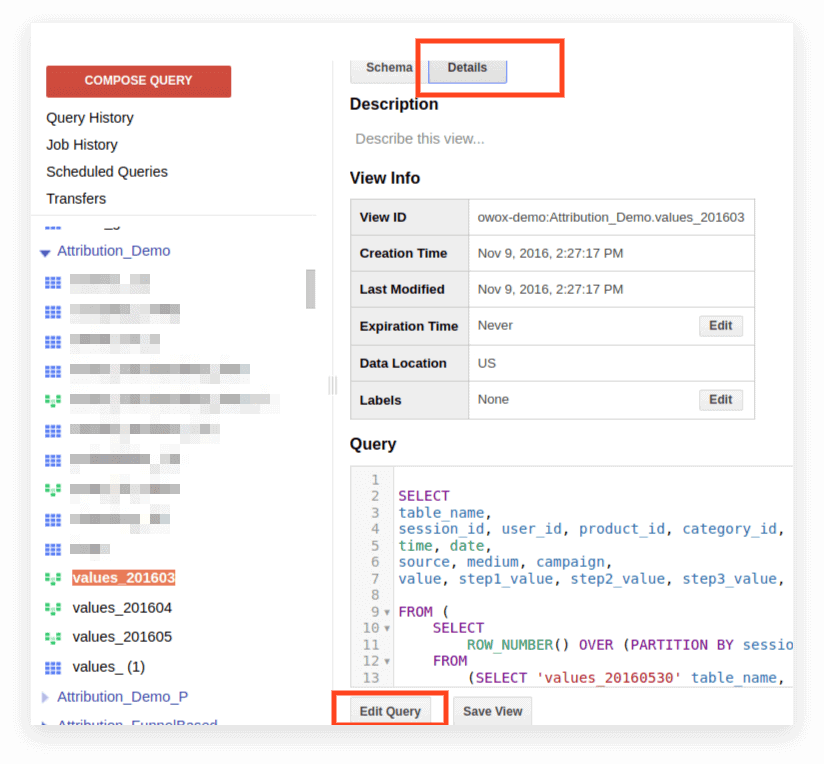
이제 표준 SQL의 규칙에 따라 요청을 편집할 수 있습니다.
요청을 프레젠테이션으로 계속 사용하려면 편집을 마친 후 보기 저장을 클릭하세요.
호환성, 구문 기능, 연산자, 기능
호환성
표준 SQL 구현 덕분에 BigQuery에서 직접 다른 서비스에 저장된 데이터에 직접 액세스할 수 있습니다.
- Google Cloud Storage 로그 파일
- Google Bigtable의 거래 기록
- 다른 출처의 데이터
이를 통해 머신 러닝 알고리즘을 기반으로 하는 예측 및 처방 분석을 비롯한 모든 분석 작업에 Google Cloud Platform 제품을 사용할 수 있습니다.
쿼리 구문
표준 언어의 쿼리 구조는 레거시와 거의 동일합니다.
테이블과 뷰의 이름은 마침표(마침표)로 구분되며 전체 쿼리는 악센트 부호로 묶입니다. `project_name.data_name_name.table_name``bigquery-public-data.samples.natality`
각 연산자에 포함될 수 있는 항목에 대한 설명과 함께 쿼리의 전체 구문은 BigQuery 문서에서 스키마로 컴파일됩니다.
표준 SQL 구문의 기능:
- SELECT 문의 필드를 나열하려면 쉼표가 필요합니다.
- FROM 다음에 UNNEST 연산자를 사용하는 경우 UNNEST 앞에 쉼표 또는 JOIN이 배치됩니다.
- FROM 앞에 쉼표를 넣을 수 없습니다.
- 두 쿼리 사이의 쉼표는 CROSS JOIN과 같으므로 주의해야 합니다.
- JOIN은 열이나 등식뿐만 아니라 임의의 표현식과 부등식으로도 수행할 수 있습니다.
- SQL 표현식의 모든 부분(SELECT, FROM, WHERE 등)에 복잡한 하위 쿼리를 작성할 수 있습니다. 실제로 다른 데이터베이스에서와 같이 WHERE column_name IN (SELECT ...)과 같은 표현식을 사용하는 것은 아직 불가능합니다.
연산자
표준 SQL에서 연산자는 데이터 유형을 정의합니다. 예를 들어 배열은 항상 대괄호 [] 안에 기록됩니다. 연산자는 비교, 논리 표현식(NOT, OR, AND) 일치 및 산술 계산에 사용됩니다.
기능
표준 SQL은 Legacy보다 더 많은 기능을 지원합니다. 기존 집계(합계, 숫자, 최소값, 최대값); 수학, 문자열 및 통계 함수; HyperLogLog ++와 같은 희귀 형식.
표준 방언에는 날짜 및 TIMESTAMP 작업을 위한 더 많은 기능이 있습니다. 전체 기능 목록은 Google 문서에 나와 있습니다. 가장 일반적으로 사용되는 함수는 날짜, 문자열, 집계 및 창 작업에 사용됩니다.
1. 집계 기능
COUNT(DISTINCT column_name)는 열의 고유 값 수를 계산합니다. 예를 들어 2019년 3월 1일에 모바일 장치의 세션 수를 계산해야 한다고 가정합니다. 세션 번호는 다른 행에서 반복될 수 있으므로 고유한 세션 번호 값만 계산하려고 합니다.
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile' SUM(column_name) — 열에 있는 값의 합계
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile' MIN(열 이름) | MAX(column_name) — 열의 최소값과 최대값. 이러한 함수는 테이블의 데이터 확산을 확인하는 데 편리합니다.
2. 창(분석) 기능
분석 함수는 전체 테이블이 아니라 특정 창, 즉 관심 있는 행 집합에 대한 값을 고려합니다. 즉, 테이블 내에서 세그먼트를 정의할 수 있습니다. 예를 들어, 모든 라인이 아니라 도시, 장치 범주 등에 대한 SUM(수익)을 계산할 수 있습니다. OVER 조건(PARTITION BY column_name)을 추가하여 분석 함수 SUM, COUNT 및 AVG와 기타 집계 함수를 전환할 수 있습니다.
예를 들어 트래픽 소스, 채널, 캠페인, 도시 및 장치 범주별로 세션 수를 계산해야 합니다. 이 경우 다음 표현식을 사용할 수 있습니다.
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t OVER는 계산이 수행될 창을 결정합니다. PARTITION BY는 계산을 위해 그룹화해야 하는 행을 나타냅니다. 일부 기능에서는 ORDER BY로 그룹화 순서를 지정해야 합니다.
창 함수의 전체 목록은 BigQuery 문서를 참조하세요.
3. 문자열 함수
이것은 텍스트를 변경하거나 텍스트의 서식을 지정하거나 열 값을 붙일 때 유용합니다. 예를 들어 표준 Google 애널리틱스 360 내보내기 데이터에서 고유한 세션 식별자를 생성하려는 경우 문자열 함수가 유용합니다. 가장 많이 사용되는 문자열 함수를 살펴보겠습니다.
SUBSTR은 문자열의 일부를 자릅니다. 요청에서 이 함수는 SUBSTR(string_name, 0.4)로 작성됩니다. 첫 번째 숫자는 줄의 시작 부분에서 건너뛸 문자 수를 나타내고 두 번째 숫자는 잘라낼 자릿수를 나타냅니다. 예를 들어 STRING 형식의 날짜가 포함된 날짜 열이 있다고 가정합니다. 이 경우 날짜는 20190103과 같습니다. 이 줄에서 연도를 추출하려면 SUBSTR이 도움이 될 것입니다.
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301` CONCAT(column_name 등)은 값을 붙입니다. 이전 예의 날짜 열을 사용하겠습니다. 모든 날짜가 2019-03-01과 같이 기록되기를 원한다고 가정합니다. 날짜를 현재 형식에서 이 형식으로 변환하려면 두 가지 문자열 함수를 사용할 수 있습니다. 먼저 SUBSTR을 사용하여 문자열의 필요한 부분을 자른 다음 하이픈으로 붙입니다.
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301` REGEXP_CONTAINS는 정규식이 발생하는 열의 값을 반환합니다.
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301` 이 함수는 SELECT와 WHERE에서 모두 사용할 수 있습니다. 예를 들어 WHERE에서 특정 페이지를 선택할 수 있습니다.
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order')
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order') 4. 날짜 기능
종종 테이블의 날짜는 STRING 형식으로 기록됩니다. Google 데이터 스튜디오에서 결과를 시각화하려는 경우 PARSE_DATE 함수를 사용하여 테이블의 날짜를 DATE 형식으로 변환해야 합니다.
PARSE_DATE는 1900-01-01 형식의 STRING을 DATE 형식으로 변환합니다.
테이블의 날짜가 다르게 보이면(예: 19000101 또는 01_01_1900) 먼저 지정된 형식으로 변환해야 합니다.
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301` DATE_DIFF는 일, 주, 월 또는 연 단위로 두 날짜 사이에 경과된 시간을 계산합니다. 사용자가 광고를 본 시점과 주문한 시점 사이의 간격을 결정해야 하는 경우에 유용합니다. 다음은 요청에서 함수가 표시되는 방식입니다.
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301` 나열된 기능에 대해 자세히 알아보려면 BigQuery Google 기능 — 상세 검토를 읽어보세요.
마케팅 보고서에 대한 SQL 쿼리
표준 SQL 언어를 사용하면 기업이 심층 세분화, 기술 감사, 마케팅 KPI 분석 및 CPA 네트워크의 불공정 계약자 식별을 통해 데이터에서 최대한의 정보를 추출할 수 있습니다. 다음은 Google BigQuery에서 수집된 데이터에 대한 SQL 쿼리가 도움이 될 비즈니스 문제의 예입니다.
1. ROPO 분석: 오프라인 판매에 대한 온라인 캠페인의 기여도를 평가합니다. ROPO 분석을 수행하려면 온라인 사용자 행동에 대한 데이터를 CRM, 통화 추적 시스템 및 모바일 애플리케이션의 데이터와 결합해야 합니다.
각 사용자에 대해 고유한 공통 매개변수(예: 사용자 ID)인 키가 1루와 2루에 있는 경우 다음을 추적할 수 있습니다.
매장에서 상품을 구매하기 전에 사이트를 방문한 사용자
사용자가 사이트에서 행동하는 방식
사용자가 구매 결정을 내리는 데 걸린 시간
오프라인 구매가 가장 많이 증가한 캠페인
2. 사이트에서의 행동(방문한 페이지, 본 제품, 구매 전 사이트 방문 횟수)에서 포인트 카드 번호 및 구매 항목에 이르기까지 매개변수의 조합에 따라 고객을 분류합니다.
3. 어떤 CPA 파트너가 악의적으로 일하고 UTM 태그를 교체하는지 알아보세요.
4. 판매 깔때기를 통해 사용자의 진행 상황을 분석합니다.
표준 SQL 방언으로 쿼리 선택을 준비했습니다. 사이트, 광고 소스 및 Google BigQuery의 CRM 시스템에서 이미 데이터를 수집하고 있다면 이 템플릿을 사용하여 비즈니스 문제를 해결할 수 있습니다. BigQuery의 프로젝트 이름, 데이터세트, 테이블을 자신의 것으로 바꾸기만 하면 됩니다. 컬렉션에서 11개의 SQL 쿼리를 받게 됩니다.
Google Analytics 360에서 Google BigQuery로의 표준 내보내기를 사용하여 수집된 데이터의 경우:
- 모든 매개변수의 컨텍스트에서 사용자 작업
- 주요 사용자 활동에 대한 통계
- 특정 제품 페이지를 본 사용자
- 특정 제품을 구매한 사용자의 행동
- 필요한 단계에 따라 깔때기 설정
- 내부 검색 사이트의 효율성
OWOX BI를 사용하여 Google BigQuery에서 수집된 데이터의 경우:
- 소스 및 채널별 기여 소비
- 방문자를 유치하는 도시별 평균 비용
- 소스 및 채널별 총 이익에 대한 ROAS
- 결제수단 및 배송수단별 CRM 내 주문건수
- 도시별 평균 배송 시간
이 문서에서 답을 찾지 못한 Google BigQuery 데이터 쿼리에 대한 질문이 있는 경우 댓글로 질문하세요. 도와드리겠습니다.