
Google BigQueryの標準SQL:マーケティングでの利点と使用例
公開: 2022-04-122016年、GoogleBigQueryはテーブルと通信するための新しい方法である標準SQLを導入しました。 それまで、BigQueryにはBigQuery SQL(現在はLegacy SQLと呼ばれています)と呼ばれる独自の構造化クエリ言語がありました。
一見したところ、レガシーSQLと標準SQLの間に大きな違いはありません。テーブルの名前は少し異なって書かれています。 Standardには、わずかに厳しい文法要件(たとえば、FROMの前にコンマを置くことはできません)とより多くのデータ型があります。 しかし、よく見ると、マーケターに多くの利点を与えるいくつかのマイナーな構文変更があります。
この記事では、次の質問に対する回答が得られます。
- レガシーSQLに対する標準SQLの利点は何ですか?
- 標準SQLの機能とその使用方法を教えてください。
- レガシーSQLから標準SQLに移行するにはどうすればよいですか?
- 標準SQLと互換性のある他のサービス、構文機能、演算子、および関数は何ですか?
- マーケティングレポートにSQLクエリを使用するにはどうすればよいですか?
レガシーSQLに対する標準SQLの利点は何ですか?
新しいデータ型:配列とネストされたフィールド
標準SQLは、新しいデータ型であるARRAYおよびSTRUCT(配列およびネストされたフィールド)をサポートします。 これは、BigQueryでは、マルチレベルの添付ファイルが含まれることが多いJSON/Avroファイルから読み込まれたテーブルの操作が簡単になったことを意味します。
ネストされたフィールドは、大きなフィールド内のミニテーブルです。
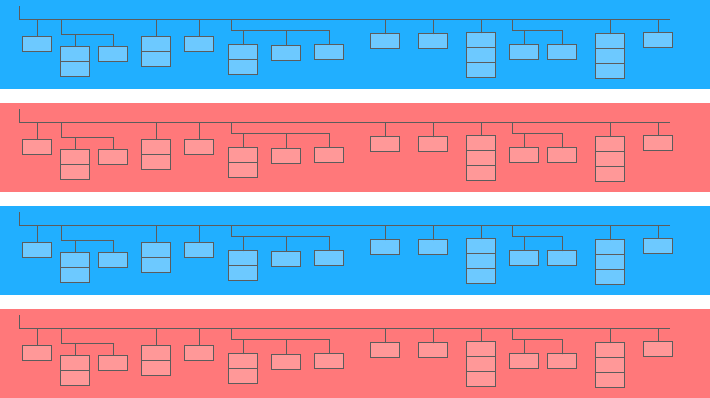
上の図で、青と黄色のバーはミニテーブルが埋め込まれている線です。 各行は1つのセッションです。 セッションには、日付、ID番号、ユーザーデバイスカテゴリ、ブラウザ、オペレーティングシステムなどの共通パラメータがあります。各セッションの一般的なパラメータに加えて、ヒットテーブルが行に添付されます。

ヒットテーブルには、サイトでのユーザーアクションに関する情報が含まれています。 たとえば、ユーザーがバナーをクリックしたり、カタログをめくったり、商品ページを開いたり、商品をバスケットに入れたり、注文したりすると、これらのアクションはヒットテーブルに記録されます。
ユーザーがサイトで注文すると、注文に関する情報もヒットテーブルに入力されます。
- transactionId(トランザクションを識別する番号)
- transactionRevenue(注文の合計値)
- transactionShipping(送料)
OWOXBIを使用して収集されたセッションデータテーブルも同様の構造です。
過去1か月間のニューヨーク市のユーザーからの注文数を知りたいとします。 調べるには、ヒットテーブルを参照して、一意のトランザクションIDの数を数える必要があります。 このようなテーブルからデータを抽出するために、標準SQLにはUNNEST関数があります。
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City 注文情報がネストされたテーブルではなく別のテーブルに記録されている場合、どのセッションで注文が行われたかを確認するには、JOINを使用してテーブルと注文情報およびテーブルとセッションデータを組み合わせる必要があります。
その他のサブクエリオプション
マルチレベルのネストされたフィールドからデータを抽出する必要がある場合は、SELECTとWHEREを使用してサブクエリを追加できます。 たとえば、OWOX BIセッションストリーミングテーブルでは、別のサブテーブルである製品がヒットサブテーブルに書き込まれます。 製品サブテーブルは、拡張eコマース配列で送信される製品データを収集します。 サイトに拡張eコマースが設定されていて、ユーザーが商品ページを閲覧した場合、この商品の特性が商品サブテーブルに記録されます。
これらの製品特性を取得するには、メインクエリ内にサブクエリが必要です。 製品特性ごとに、個別のSELECTサブクエリが括弧内に作成されます。
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD`
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` 標準SQLの機能のおかげで、クエリロジックの構築とコードの記述が簡単になります。 比較のために、レガシーSQLでは、次のタイプのラダーを作成する必要があります。
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )外部ソースへのリクエスト
標準SQLを使用すると、Google Bigtable、Google Cloud Storage、Googleドライブ、Googleスプレッドシートから直接BigQueryテーブルにアクセスできます。
つまり、テーブル全体をBigQueryに読み込む代わりに、1つのクエリでデータを削除し、必要なパラメータを選択して、クラウドストレージにアップロードできます。
その他のユーザー機能(UDF)
文書化されていない式を使用する必要がある場合は、ユーザー定義関数(UDF)が役立ちます。 標準SQLのドキュメントはデジタル分析のほとんどすべてのタスクをカバーしているため、私たちの実践では、これが発生することはめったにありません。
標準SQLでは、ユーザー定義関数はSQLまたはJavaScriptで記述できます。 レガシーSQLはJavaScriptのみをサポートします。 これらの関数の引数は列であり、それらが取る値は列を操作した結果です。 標準SQLでは、関数はクエリと同じウィンドウで記述できます。
その他の参加条件
レガシーSQLでは、JOIN条件は等価または列名に基づくことができます。 これらのオプションに加えて、標準SQLダイアレクトは、不等式および任意の式によるJOINをサポートします。
たとえば、不公平なCPAパートナーを特定するために、トランザクションから60秒以内にソースが置き換えられたセッションを選択できます。 標準SQLでこれを行うには、JOIN条件に不等式を追加します。
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime JOINに関する標準SQLの唯一の制限は、WHERE列IN(SELECT ...)の形式のサブクエリとの半結合を許可しないことです。
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESC
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESC間違いの可能性が少ない
条件が正しくない場合、レガシーSQLの一部の関数はNULLを返します。 たとえば、ゼロによる除算が計算に組み込まれている場合、クエリが実行され、テーブルの結果の行にNULLエントリが表示されます。 これにより、クエリまたはデータの問題がマスクされる可能性があります。
標準SQLのロジックはより単純です。 条件または入力データが正しくない場合、クエリは「ゼロ除算」などのエラーを生成するため、クエリをすばやく修正できます。 次のチェックが標準SQLに組み込まれています。
- +、-、×、SUM、AVG、STDEVの有効な値
- ゼロ除算
リクエストはより速く実行されます
標準SQLで記述されたJOINクエリは、受信データの予備フィルタリングのおかげで、レガシーSQLで記述されたクエリよりも高速です。 最初に、クエリはJOIN条件に一致する行を選択し、次にそれらを処理します。
将来的には、GoogleBigQueryは標準SQLのクエリの速度とパフォーマンスの向上に取り組みます。
テーブルは編集できます:行の挿入と削除、更新
データ操作言語(DML)関数は、標準SQLで使用できます。 これは、クエリを作成するのと同じウィンドウを使用して、テーブルを更新し、テーブルに行を追加または削除できることを意味します。 たとえば、DMLを使用すると、2つのテーブルのデータを1つに結合できます。
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)コードは読みやすく、編集しやすい
標準SQLを使用すると、複雑なクエリをSELECTだけでなくWITHでも開始できるため、コードの読み取り、コメント、および理解が容易になります。 これはまた、自分自身を防ぎ、他人の間違いを修正する方が簡単であることを意味します。
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2 複数の段階で計算を行う場合は、WITH演算子を使用すると便利です。 まず、サブクエリで中間メトリックを収集してから、最終的な計算を行うことができます。
BigQueryを含むGoogleCloudPlatform(GCP)は、データウェアハウスやデータクラウドの整理から、科学実験や予測分析や処方分析の実行まで、ビッグデータを処理するためのフルサイクルプラットフォームです。 標準SQLの導入により、BigQueryは対象者を拡大しています。 GCPの使用は、マーケティングアナリスト、製品アナリスト、データサイエンティスト、その他のスペシャリストのチームにとってますます興味深いものになっています。
標準SQLの機能とユースケースの例
OWOX BIでは、GoogleBigQueryまたはOWOXBIパイプラインへの標準のGoogleAnalytics360エクスポートを使用してコンパイルされたテーブルを使用することがよくあります。 以下の例では、そのようなデータに対するSQLクエリの詳細を見ていきます。
BigQueryでサイトからデータをまだ収集していない場合は、OWOXBIの試用版を使用して無料で収集を試すことができます。
1.時間間隔のデータを選択します
Google BigQueryでは、サイトのユーザー行動データはワイルドカードテーブル(アスタリスク付きのテーブル)に保存されます。 毎日別のテーブルが作成されます。 これらのテーブルの名前は同じです。接尾辞のみが異なります。 接尾辞は、YYYYMMDD形式の日付です。 たとえば、テーブルowoxbi_sessions_20190301には、2019年3月1日のセッションに関するデータが含まれています。
たとえば、2019年2月1日から2月28日までのデータを取得するために、1つのリクエストでこのようなテーブルのグループを直接参照できます。これを行うには、FROMおよびWHEREでYYYYMMDDを*に置き換える必要があります。時間間隔の開始と終了のテーブルサフィックスを指定する必要があります。
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �'
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �' 私たちがデータを収集したい特定の日付は、私たちに常に知られているわけではありません。 たとえば、毎週、過去3か月のデータを分析する必要がある場合があります。 これを行うには、FORMAT_DATE関数を使用できます。
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) BETWEENの後、最初のテーブルのサフィックスを記録します。 CURRENT_DATE()、INTERVAL 3 MONTHSというフレーズは、「現在の日付から過去3か月のデータを選択する」ことを意味します。 2番目のテーブルサフィックスはANDの後にフォーマットされます。 間隔の終わりを昨日としてマークする必要があります:CURRENT_DATE()、INTERVAL1DAY。
2.ユーザーパラメータとインジケーターを取得します
Google Analyticsエクスポートテーブルのユーザーパラメータと指標は、ネストされたヒットテーブルとcustomDimensionsおよびcustomMetricsサブテーブルに書き込まれます。 すべてのカスタムディメンションは2つの列に記録されます。1つはサイトで収集されたパラメーターの数、もう1つはそれらの値です。 1回のヒットで送信されるすべてのパラメータは次のようになります。
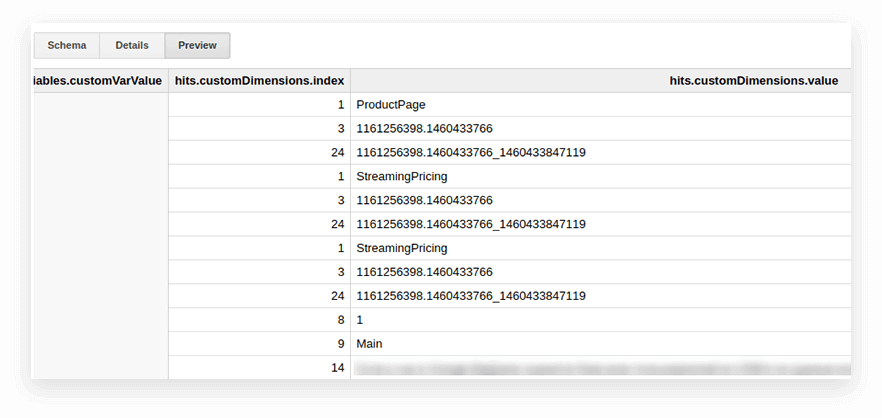
それらを解凍し、必要なパラメーターを別々の列に書き込むために、次のSQLクエリを使用します。
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 リクエストの内容は次のとおりです。
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201` 以下のスクリーンショットでは、GoogleBigQueryのGoogleAnalytics 360デモデータからパラメーター1と2を選択し、それらをpage_typeとclient_idと呼んでいます。 各パラメーターは、個別の列に記録されます。

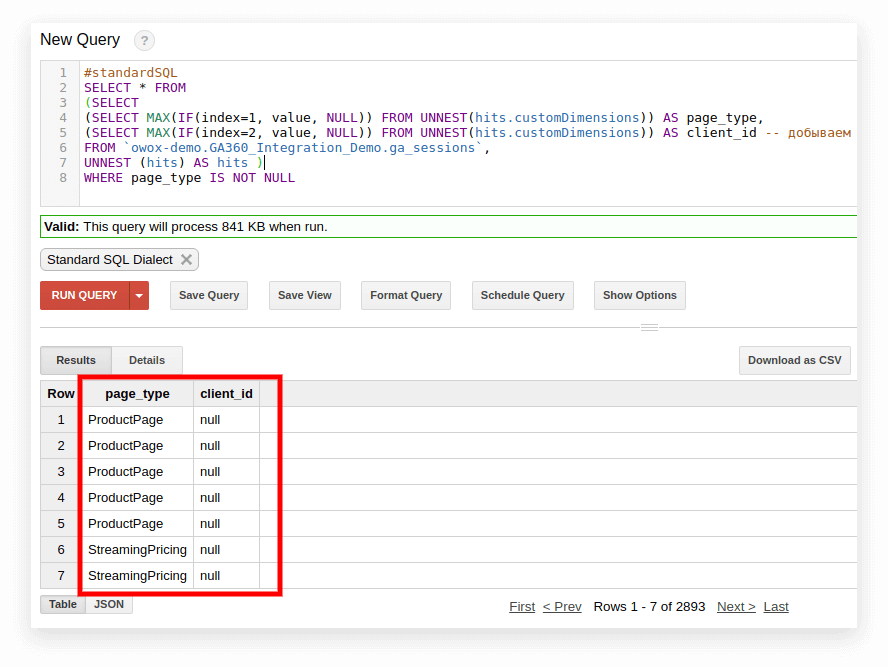
3.トラフィックソース、チャネル、キャンペーン、都市、およびデバイスカテゴリごとにセッション数を計算します
このような計算は、Google Data Studioでデータを視覚化し、都市とデバイスのカテゴリでフィルタリングする場合に役立ちます。 これは、COUNTウィンドウ関数を使用して簡単に実行できます。
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`4.複数のテーブルからの同じデータを結合します
完了した注文に関するデータを複数のBigQueryテーブルに収集するとします。1つはストアAからすべての注文を収集し、もう1つはストアBから注文を収集します。これらを次の列を持つ1つのテーブルに結合します。
- client_id —一意の購入者を識別する番号
- transaction_created —TIMESTAMP形式の注文作成時間
- transaction_id —注文番号
- is_authorized —注文が確認されたかどうか
- transaction_revenue —注文金額
この例では、2018年1月1日から昨日までの注文がテーブルに含まれている必要があります。 これを行うには、テーブルの各グループから適切な列を選択し、それらに同じ名前を割り当て、結果をUNIONALLと組み合わせます。
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC5.トラフィックチャネルグループの辞書を作成します
データがGoogleAnalyticsに入力されると、システムは特定のトランジションが属するグループ(直接、オーガニック検索、有料検索など)を自動的に判別します。 チャネルのグループを識別するために、Google Analyticsは遷移のUTMタグ、つまりutm_sourceとutm_mediumを調べます。 チャネルグループと定義ルールの詳細については、Googleアナリティクスヘルプをご覧ください。
OWOX BIクライアントがチャネルのグループに独自の名前を割り当てたい場合は、特定のチャネルに属する遷移である辞書を作成します。 これを行うには、条件付きCASE演算子とREGEXP_CONTAINS関数を使用します。 この関数は、指定された正規表現が発生する値を選択します。
GoogleAnalyticsのソースのリストから名前を取得することをお勧めします。 このような条件をリクエスト本文に追加する方法の例を次に示します。
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201` 標準SQLに切り替える方法
まだ標準SQLに切り替えていない場合は、いつでも切り替えることができます。 主なことは、1つのリクエストで方言を混在させないようにすることです。
オプション1.GoogleBigQueryインターフェースに切り替えます
古いBigQueryインターフェースでは、デフォルトでレガシーSQLが使用されます。 方言を切り替えるには、クエリ入力フィールドの下にある[オプションの表示]をクリックし、[SQL方言]の横にある[レガシーSQLを使用する]チェックボックスをオフにします。
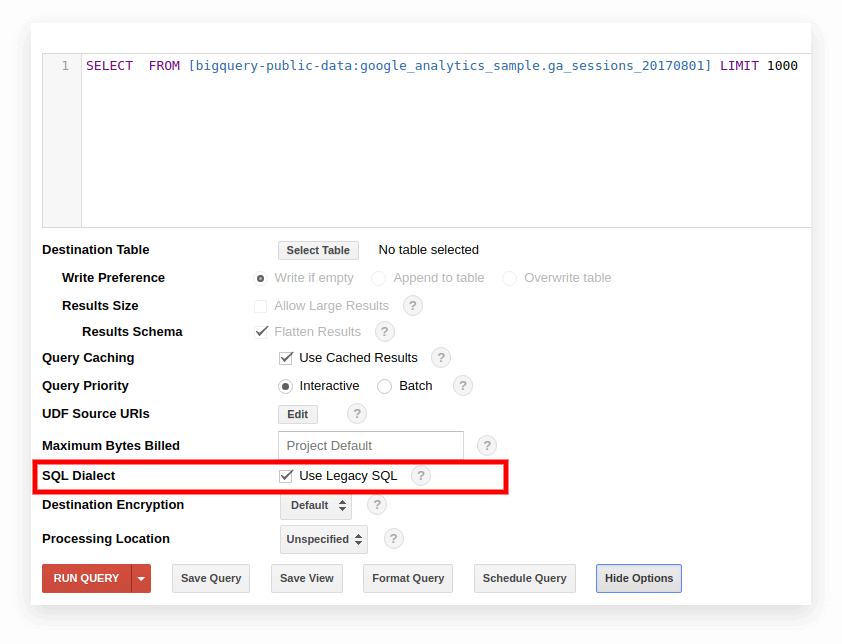
新しいインターフェイスは、デフォルトで標準SQLを使用します。 ここで、方言を切り替えるには、[その他]タブに移動する必要があります。
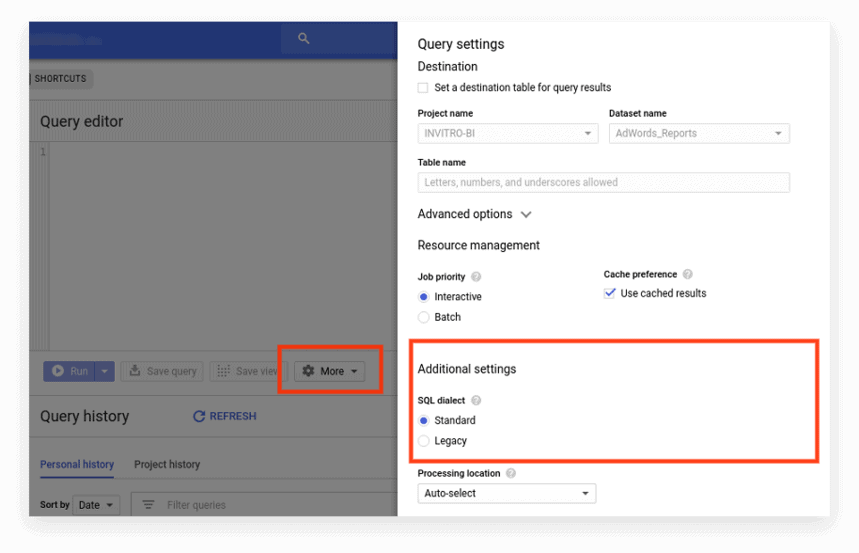
オプション2.リクエストの先頭にプレフィックスを書き込みます
リクエスト設定にチェックマークを付けていない場合は、目的のプレフィックス(#standardSQLまたは#legacySQL)から始めることができます。
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10;
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10; この場合、Google BigQueryはインターフェースの設定を無視し、プレフィックスで指定された方言を使用してクエリを実行します。
Apps Scriptを使用してスケジュールに従って起動されるビューまたは保存されたクエリがある場合は、スクリプトでuseLegacySqlの値をfalseに変更することを忘れないでください。
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }オプション3.ビューの標準SQLへの移行
テーブルではなくビューを使用してGoogleBigQueryを使用している場合、これらのビューには標準SQLダイアレクトではアクセスできません。 つまり、プレゼンテーションがレガシーSQLで記述されている場合、標準SQLでプレゼンテーションに要求を書き込むことはできません。
ビューを標準SQLに転送するには、ビューが作成されたクエリを手動で書き直す必要があります。 これを行う最も簡単な方法は、BigQueryインターフェースを使用することです。
1.ビューを開きます。
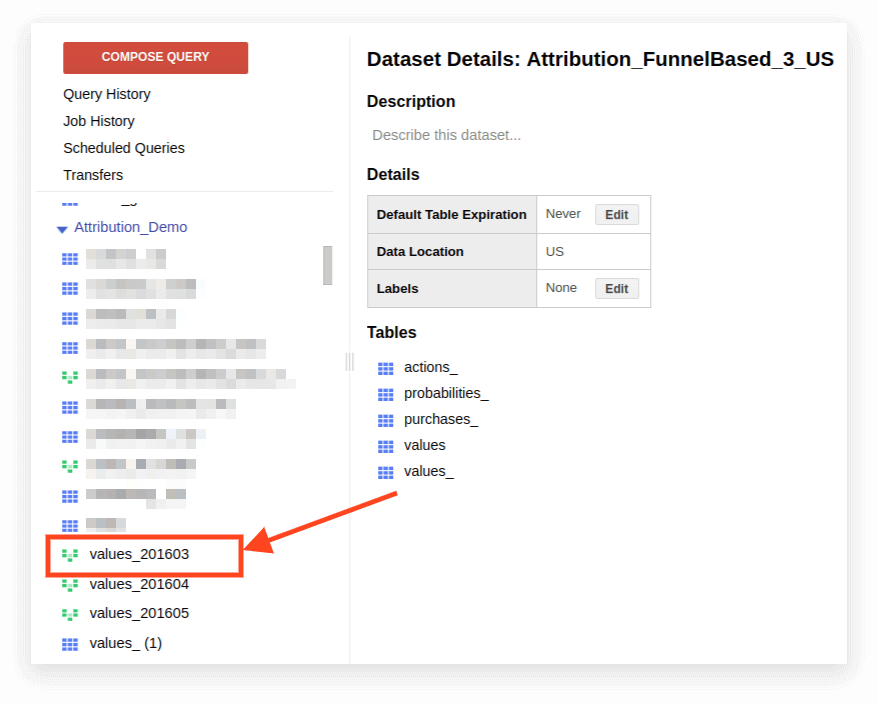
2.[詳細]をクリックします。 クエリテキストが開き、[クエリの編集]ボタンが下に表示されます。
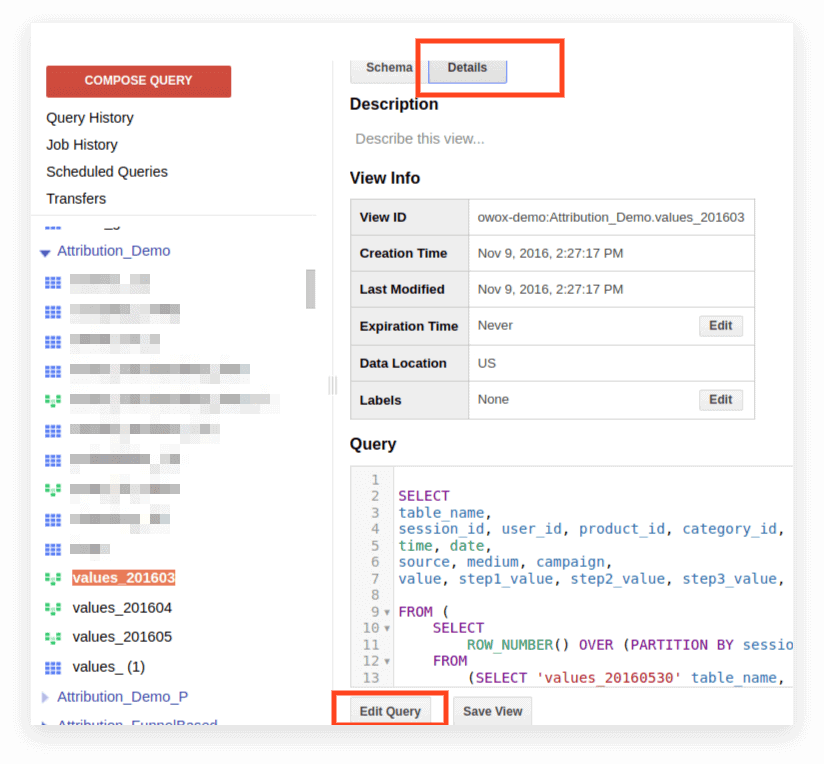
これで、標準SQLのルールに従ってリクエストを編集できます。
リクエストをプレゼンテーションとして引き続き使用する場合は、編集が終了したら[ビューを保存]をクリックします。
互換性、構文機能、演算子、関数
互換性
標準SQLの実装のおかげで、BigQueryから直接他のサービスに保存されているデータに直接アクセスできます。
- GoogleCloudStorageのログファイル
- GoogleBigtableのトランザクションレコード
- 他のソースからのデータ
これにより、機械学習アルゴリズムに基づく予測分析や処方分析など、あらゆる分析タスクにGoogleCloudPlatform製品を使用できます。
クエリ構文
標準方言のクエリ構造は、レガシーのクエリ構造とほぼ同じです。
テーブルとビューの名前はピリオド(ピリオド)で区切られ、クエリ全体がアクサングラーブで囲まれます: `project_name.data_name_name.table_name``bigquery-public-data.samples.natality`
各演算子に含めることができるものの説明を含むクエリの完全な構文は、BigQueryドキュメントのスキーマとしてコンパイルされます。
標準SQL構文の機能:
- SELECTステートメントのフィールドをリストするには、コンマが必要です。
- FROMの後にUNNEST演算子を使用すると、UNNESTの前にコンマまたはJOINが配置されます。
- FROMの前にコンマを置くことはできません。
- 2つのクエリ間のコンマはCROSSJOINに等しいので、注意してください。
- JOINは、列や等式だけでなく、任意の式や不等式によっても実行できます。
- SQL式の任意の部分(SELECT、FROM、WHEREなど)に複雑なサブクエリを書き込むことができます。 実際には、他のデータベースのようにWHERE column_name IN(SELECT ...)のような式を使用することはまだできません。
演算子
標準SQLでは、演算子はデータのタイプを定義します。 たとえば、配列は常に角かっこ[]で記述されます。 演算子は、比較、論理式(NOT、OR、AND)の照合、および算術計算に使用されます。
関数
標準SQLは、レガシーよりも多くの機能をサポートしています。従来の集計(合計、数、最小、最大)。 数学関数、文字列関数、および統計関数。 HyperLogLog++などのまれな形式。
標準方言には、日付とタイムスタンプを操作するためのより多くの関数があります。 機能の完全なリストは、Googleのドキュメントに記載されています。 最も一般的に使用される関数は、日付、文字列、集計、およびウィンドウを操作するためのものです。
1.集計関数
COUNT(DISTINCT column_name)は、列内の一意の値の数をカウントします。 たとえば、2019年3月1日のモバイルデバイスからのセッション数をカウントする必要があるとします。セッション番号は異なる行で繰り返すことができるため、一意のセッション番号の値のみをカウントする必要があります。
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile' SUM(column_name)—列の値の合計
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile' MIN(column_name)| MAX(column_name)—列の最小値と最大値。 これらの関数は、テーブル内のデータの広がりをチェックするのに便利です。
2.ウィンドウ(分析)関数
分析関数は、テーブル全体ではなく、特定のウィンドウ(関心のある行のセット)の値を考慮します。つまり、テーブル内のセグメントを定義できます。 たとえば、すべての回線ではなく、都市、デバイスカテゴリなどのSUM(収益)を計算できます。 分析関数SUM、COUNT、AVG、およびその他の集計関数にOVER条件(PARTITION BY column_name)を追加することにより、それらを有効にすることができます。
たとえば、トラフィックソース、チャネル、キャンペーン、都市、およびデバイスカテゴリごとにセッション数をカウントする必要があります。 この場合、次の式を使用できます。
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t OVERは、計算が行われるウィンドウを決定します。 PARTITION BYは、計算のためにグループ化する必要がある行を示します。 一部の関数では、ORDERBYを使用してグループ化の順序を指定する必要があります。
ウィンドウ関数の完全なリストについては、BigQueryのドキュメントをご覧ください。
3.文字列関数
これらは、テキストを変更したり、テキストを1行でフォーマットしたり、列の値を接着したりする必要がある場合に役立ちます。 たとえば、文字列関数は、標準のGoogleAnalytics360エクスポートデータから一意のセッション識別子を生成する場合に最適です。 最も人気のある文字列関数について考えてみましょう。
SUBSTRは文字列の一部をカットします。 リクエストでは、この関数はSUBSTR(string_name、0.4)として記述されています。 最初の数字は行頭からスキップする文字数を示し、2番目の数字はカットする桁数を示します。 たとえば、STRING形式の日付を含む日付列があるとします。 この場合、日付は20190103のようになります。この行から年を抽出する場合は、SUBSTRが役立ちます。
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301` CONCAT(column_nameなど)は値を接着します。 前の例の日付列を使用してみましょう。 2019-03-01のようにすべての日付を記録するとします。 日付を現在の形式からこの形式に変換するには、2つの文字列関数を使用できます。最初に、文字列の必要な部分をSUBSTRで切り取り、次にハイフンで接着します。
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301` REGEXP_CONTAINSは、正規表現が発生する列の値を返します。
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301` この関数は、SELECTとWHEREの両方で使用できます。 たとえば、WHEREでは、特定のページを選択できます。
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order')
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order') 4.日付関数
多くの場合、テーブルの日付はSTRING形式で記録されます。 Google Data Studioで結果を視覚化する場合は、PARSE_DATE関数を使用してテーブルの日付をDATE形式に変換する必要があります。
PARSE_DATEは、1900-01-01形式のSTRINGをDATE形式に変換します。
テーブルの日付が異なって見える場合(たとえば、19000101または01_01_1900)、最初にそれらを指定された形式に変換する必要があります。
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301` DATE_DIFFは、2つの日付の間の経過時間を、日、週、月、または年で計算します。 ユーザーが広告を見て注文するまでの間隔を決定する必要がある場合に便利です。 リクエストで関数がどのように表示されるかを次に示します。
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301` リストされている機能について詳しく知りたい場合は、BigQueryのGoogle機能—詳細レビューをご覧ください。
マーケティングレポートのSQLクエリ
標準SQL方言を使用すると、企業は、詳細なセグメンテーション、技術監査、マーケティングKPI分析、およびCPAネットワーク内の不公正な請負業者の特定により、データから最大限の情報を抽出できます。 GoogleBigQueryで収集されたデータに対するSQLクエリが役立つビジネス上の問題の例を次に示します。
1. ROPO分析:オフライン販売へのオンラインキャンペーンの貢献度を評価します。 ROPO分析を実行するには、オンラインユーザーの行動に関するデータを、CRM、通話追跡システム、およびモバイルアプリケーションからのデータと組み合わせる必要があります。
1つ目と2つ目のベースにキーがある場合(ユーザーごとに一意の共通パラメーター(ユーザーIDなど))、次のことを追跡できます。
ストアで商品を購入する前にサイトにアクセスしたユーザー
ユーザーがサイトでどのように行動したか
ユーザーが購入を決定するのにかかった時間
オフライン購入で最も増加したキャンペーンはどれか。
2.サイトでの行動(訪問したページ、表示した製品、購入前のサイトへの訪問数)からポイントカード番号や購入したアイテムまで、パラメーターの任意の組み合わせで顧客をセグメント化します。
3.どのCPAパートナーが悪意を持って働いており、UTMタグを置き換えているかを調べます。
4.セールスファネルを通じてユーザーの進捗状況を分析します。
標準SQL方言で選択したクエリを用意しました。 サイト、広告ソース、Google BigQueryのCRMシステムからすでにデータを収集している場合は、これらのテンプレートを使用してビジネス上の問題を解決できます。 BigQueryのプロジェクト名、データセット、テーブルを独自のものに置き換えるだけです。 コレクションには、11個のSQLクエリが含まれています。
Google Analytics360からGoogleBigQueryへの標準エクスポートを使用して収集されたデータの場合:
- パラメータのコンテキストでのユーザーアクション
- 主要なユーザーアクションに関する統計
- 特定の製品ページを閲覧したユーザー
- 特定の製品を購入したユーザーのアクション
- 必要な手順で目標到達プロセスを設定します
- 内部検索サイトの有効性
OWOXBIを使用してGoogleBigQueryで収集されたデータの場合:
- ソースおよびチャネルによる消費に起因する
- 都市ごとに訪問者を引き付けるための平均コスト
- ソースおよびチャネル別の粗利益のROAS
- 支払い方法と配送方法によるCRMの注文数
- 都市別の平均配達時間
この記事で回答が見つからなかったGoogleBigQueryデータのクエリについて質問がある場合は、コメントで質問してください。 私たちはあなたを助けようとします。