
Google BigQuery'de Standart SQL: Pazarlamada Avantajlar ve Kullanım Örnekleri
Yayınlanan: 2022-04-122016'da Google BigQuery, tablolarla iletişim kurmanın yeni bir yolunu tanıttı: Standart SQL. O zamana kadar BigQuery, BigQuery SQL (şimdi Eski SQL olarak anılıyor) adlı kendi yapılandırılmış sorgu diline sahipti.
İlk bakışta Legacy ve Standard SQL arasında pek bir fark yoktur: tablo isimleri biraz farklı yazılmıştır; Standard'ın biraz daha katı dil bilgisi gereksinimleri (örneğin, FROM'dan önce virgül koyamazsınız) ve daha fazla veri türü vardır. Ancak yakından bakarsanız, pazarlamacılara birçok avantaj sağlayan bazı küçük sözdizimi değişiklikleri var.
Bu makalede, aşağıdaki soruların yanıtlarını alacaksınız:
- Standart SQL'in Eski SQL'e göre avantajları nelerdir?
- Standart SQL'in yetenekleri nelerdir ve nasıl kullanılır?
- Legacy'den Standard SQL'e nasıl geçebilirim?
- Standard SQL, başka hangi hizmetler, sözdizimi özellikleri, operatörler ve işlevlerle uyumludur?
- Pazarlama raporları için SQL sorgularını nasıl kullanabilirim?
Standart SQL'in Eski SQL'e göre avantajları nelerdir?
Yeni veri türleri: diziler ve iç içe alanlar
Standart SQL, yeni veri türlerini destekler: ARRAY ve STRUCT (diziler ve iç içe alanlar). Bu, BigQuery'de, genellikle çok düzeyli ekler içeren JSON/Avro dosyalarından yüklenen tablolarla çalışmanın daha kolay hale geldiği anlamına gelir.
İç içe alan, daha büyük olanın içindeki mini bir masadır:
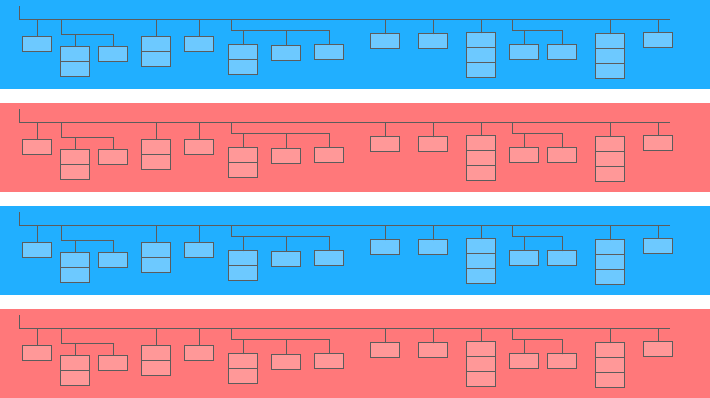
Yukarıdaki şemada mavi ve sarı çubuklar mini tabloların gömülü olduğu çizgilerdir. Her satır bir seanstır. Oturumların ortak parametreleri vardır: tarih, kimlik numarası, kullanıcı cihaz kategorisi, tarayıcı, işletim sistemi vb. Her oturum için genel parametrelere ek olarak, isabet tablosu satıra eklenir.

İsabet tablosu, sitedeki kullanıcı eylemleri hakkında bilgi içerir. Örneğin, bir kullanıcı bir banner'a tıklarsa, katalogda gezinirse, bir ürün sayfası açarsa, bir ürünü sepete koyarsa veya bir sipariş verirse, bu eylemler isabet tablosuna kaydedilecektir.
Bir kullanıcı siteye sipariş verirse, siparişle ilgili bilgiler de isabet tablosuna girilecektir:
- işlem kimliği (işlemi tanımlayan sayı)
- işlem Geliri (siparişin toplam değeri)
- işlemNakliye (nakliye maliyetleri)
OWOX BI kullanılarak toplanan oturum veri tabloları benzer bir yapıya sahiptir.
Geçen ay New York City'deki kullanıcılardan gelen siparişlerin sayısını öğrenmek istediğinizi varsayalım. Bulmak için, isabet tablosuna bakmanız ve benzersiz işlem kimliklerinin sayısını saymanız gerekir. Bu tür tablolardan veri çıkarmak için Standart SQL'in bir UNNEST işlevi vardır:
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City Sipariş bilgileri yuvalanmış bir tabloda değil de ayrı bir tabloda kaydedilmişse, hangi oturumlarda siparişlerin verildiğini bulmak için tabloyu sipariş bilgileriyle ve tabloyu oturum verileriyle birleştirmek için JOIN kullanmanız gerekir.
Daha fazla alt sorgu seçeneği
Çok düzeyli iç içe alanlardan veri çıkarmanız gerekiyorsa, SELECT ve WHERE ile alt sorgular ekleyebilirsiniz. Örneğin, OWOX BI oturum akış tablolarında, isabet alt tablosuna başka bir alt tablo olan ürün yazılır. Ürün alt tablosu, Gelişmiş E-ticaret dizisiyle iletilen ürün verilerini toplar. Sitede gelişmiş e-ticaret kurulursa ve bir kullanıcı bir ürün sayfasına bakarsa, bu ürünün özellikleri ürün alt tablosuna kaydedilir.
Bu ürün özelliklerini elde etmek için ana sorgunun içinde bir alt sorguya ihtiyacınız olacak. Her ürün özelliği için parantez içinde ayrı bir SELECT alt sorgusu oluşturulur:
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD`
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` Standart SQL'in yetenekleri sayesinde sorgu mantığı oluşturmak ve kod yazmak daha kolaydır. Karşılaştırma için, Legacy SQL'de bu tür bir merdiven yazmanız gerekir:
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )Dış kaynaklara yapılan istekler
Standart SQL'i kullanarak BigQuery tablolarına doğrudan Google Bigtable, Google Cloud Storage, Google Drive ve Google Sheets'ten erişebilirsiniz.
Yani tüm tabloyu BigQuery'ye yüklemek yerine tek bir sorgu ile verileri silebilir, ihtiyacınız olan parametreleri seçip bulut depolamaya yükleyebilirsiniz.
Daha fazla kullanıcı işlevi (UDF)
Belgelenmemiş bir formül kullanmanız gerekiyorsa, Kullanıcı Tanımlı İşlevler (UDF) size yardımcı olacaktır. Uygulamamızda, bu nadiren olur, çünkü Standart SQL belgeleri neredeyse tüm dijital analitik görevlerini kapsar.
Standart SQL'de, kullanıcı tanımlı fonksiyonlar SQL veya JavaScript ile yazılabilir; Eski SQL yalnızca JavaScript'i destekler. Bu işlevlerin argümanları sütunlardır ve aldıkları değerler sütunları manipüle etmenin sonucudur. Standart SQL'de fonksiyonlar, sorgularla aynı pencerede yazılabilir.
Diğer KATIL koşulları
Eski SQL'de, JOIN koşulları eşitlik veya sütun adlarına dayalı olabilir. Bu seçeneklere ek olarak, Standart SQL diyalekti eşitsizliğe ve keyfi ifadeye göre JOIN'i destekler.
Örneğin, haksız EBM ortaklarını belirlemek için, işlemin ardından 60 saniye içinde kaynağın değiştirildiği oturumları seçebiliriz. Bunu Standart SQL'de yapmak için JOIN koşuluna bir eşitsizlik ekleyebiliriz:
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime Standart SQL'in JOIN ile ilgili tek sınırlaması, WHERE sütunu IN (SELECT ...) formunun alt sorgularıyla yarı birleştirmeye izin vermemesidir:
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESC
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESCDaha az hata olasılığı
Koşul yanlışsa, Eski SQL'deki bazı işlevler NULL döndürür. Örneğin, hesaplamalarınıza sıfıra bölme işlemi eklendiyse, sorgu yürütülür ve tablonun sonuçtaki satırlarında NULL girişleri görünür. Bu, sorgudaki veya verilerdeki sorunları maskeleyebilir.
Standart SQL'in mantığı daha basittir. Bir koşul veya giriş verileri yanlışsa, sorgu bir hata oluşturur, örneğin "sıfıra bölme", böylece sorguyu hızla düzeltebilirsiniz. Aşağıdaki kontroller Standart SQL'de gömülüdür:
- +, -, ×, SUM, AVG, STDEV için geçerli değerler
- Sıfıra bölüm
İstekler daha hızlı çalışır
Standart SQL'de yazılan JOIN sorguları, gelen verilerin ön filtrelemesi sayesinde Eski SQL'de yazılanlardan daha hızlıdır. İlk olarak sorgu, JOIN koşullarıyla eşleşen satırları seçer, ardından bunları işler.
Gelecekte Google BigQuery, yalnızca Standart SQL için sorguların hızını ve performansını iyileştirmeye çalışacak.
Tablolar düzenlenebilir: satır ekleme ve silme, güncelleme
Veri İşleme Dili (DML) işlevleri Standart SQL'de mevcuttur. Bu, sorgu yazdığınız pencereden tabloları güncelleyebileceğiniz ve bunlara satır ekleyip kaldırabileceğiniz anlamına gelir. Örneğin, DML kullanarak iki tablodaki verileri tek bir tabloda birleştirebilirsiniz:
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)Kodun okunması ve düzenlenmesi daha kolaydır
Standart SQL ile karmaşık sorgular yalnızca SELECT ile değil, aynı zamanda WITH ile de başlatılabilir, bu da kodun okunmasını, yorumlanmasını ve anlaşılmasını kolaylaştırır. Bu aynı zamanda kendinizinkini önlemenin ve başkalarının hatalarını düzeltmenin daha kolay olduğu anlamına gelir.
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2 Birkaç aşamada yapılan hesaplamalarınız varsa, WITH operatörüyle çalışmak uygundur. Önce alt sorgularda ara metrikleri toplayabilir, ardından son hesaplamaları yapabilirsiniz.
BigQuery'yi içeren Google Cloud Platform (GCP), bir veri ambarı veya veri bulutu düzenlemekten bilimsel deneyler ve tahmine dayalı ve kuralcı analitik çalıştırmaya kadar büyük verilerle çalışmak için tam döngülü bir platformdur. Standart SQL'in kullanıma sunulmasıyla BigQuery, hedef kitlesini genişletiyor. GCP ile çalışmak, pazarlama analistleri, ürün analistleri, veri bilimcileri ve diğer uzmanlardan oluşan ekipler için daha ilgi çekici hale geliyor.
Standart SQL'in yetenekleri ve kullanım örnekleri
OWOX BI'da, genellikle Google BigQuery'ye veya OWOX BI Pipeline'a standart Google Analytics 360 dışa aktarımı kullanılarak derlenen tablolarla çalışırız. Aşağıdaki örneklerde, bu tür veriler için SQL sorgularının özelliklerine bakacağız.
BigQuery'de sitenizden henüz veri toplamıyorsanız, bunu OWOX BI'ın deneme sürümüyle ücretsiz olarak deneyebilirsiniz.
1. Bir zaman aralığı için veri seçin
Google BigQuery'de sitenize ilişkin kullanıcı davranışı verileri joker karakter tablolarında (yıldızlı tablolar) depolanır; her gün için ayrı bir tablo oluşturulur. Bu tablolar aynı ada sahiptir: sadece son ek farklıdır. Son ek, YYYYMMDD biçimindeki tarihtir. Örneğin, owoxbi_sessions_20190301 tablosu, 1 Mart 2019 için oturumlarla ilgili verileri içerir.
Örneğin 1 Şubat ile 28 Şubat 2019 arasında veri elde etmek için bir istekte bu tür tabloların bir grubuna doğrudan başvurabiliriz. Bunu yapmak için YYYYMMDD'yi FROM ve WHERE'de * ile değiştirmemiz gerekir. zaman aralığının başlangıcı ve bitişi için tablo eklerini belirtmemiz gerekiyor:
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �'
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �' Veri toplamak istediğimiz belirli tarihler her zaman tarafımızca bilinmez. Örneğin, her hafta son üç aya ait verileri analiz etmemiz gerekebilir. Bunu yapmak için FORMAT_DATE işlevini kullanabiliriz:
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) BETWEEN'den sonra ilk tablonun son ekini kaydediyoruz. CURRENT_DATE (), INTERVAL 3 AY ifadesi, «geçerli tarihten itibaren son 3 aya ait verileri seçin» anlamına gelir. İkinci tablo soneki, AND'den sonra biçimlendirilir. Aralığın sonunu dün olarak işaretlemek gerekiyor: CURRENT_DATE (), INTERVAL 1 DAY.
2. Kullanıcı parametrelerini ve göstergelerini alın
Google Analytics Dışa Aktarma tablolarındaki kullanıcı parametreleri ve metrikleri, iç içe isabetler tablosuna ve customDimensions ve customMetrics alt tablolarına yazılır. Tüm özel boyutlar iki sütuna kaydedilir: biri sitede toplanan parametre sayısı için, ikincisi değerleri için. Tek vuruşla iletilen tüm parametreler şöyle görünür:
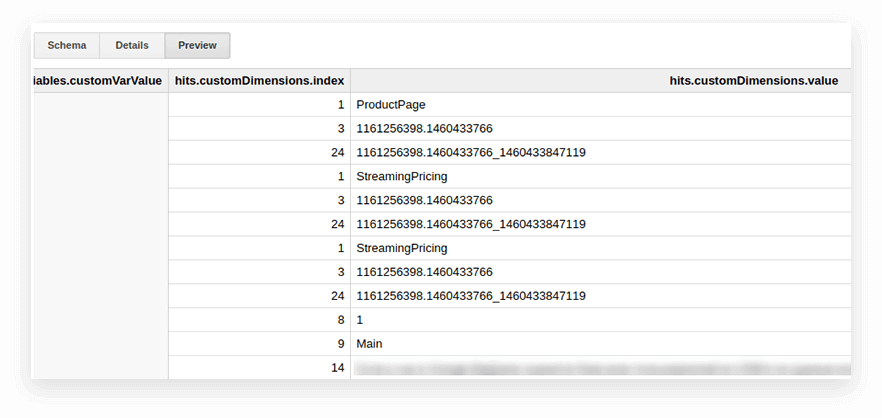
Bunları açmak ve gerekli parametreleri ayrı sütunlara yazmak için aşağıdaki SQL sorgusunu kullanıyoruz:
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 İşte istekte nasıl göründüğü:
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201` Aşağıdaki ekran görüntüsünde, Google BigQuery'deki Google Analytics 360 demo verilerinden 1. ve 2. parametreleri seçtik ve bunlara page_type ve client_id adını verdik. Her parametre ayrı bir sütuna kaydedilir:

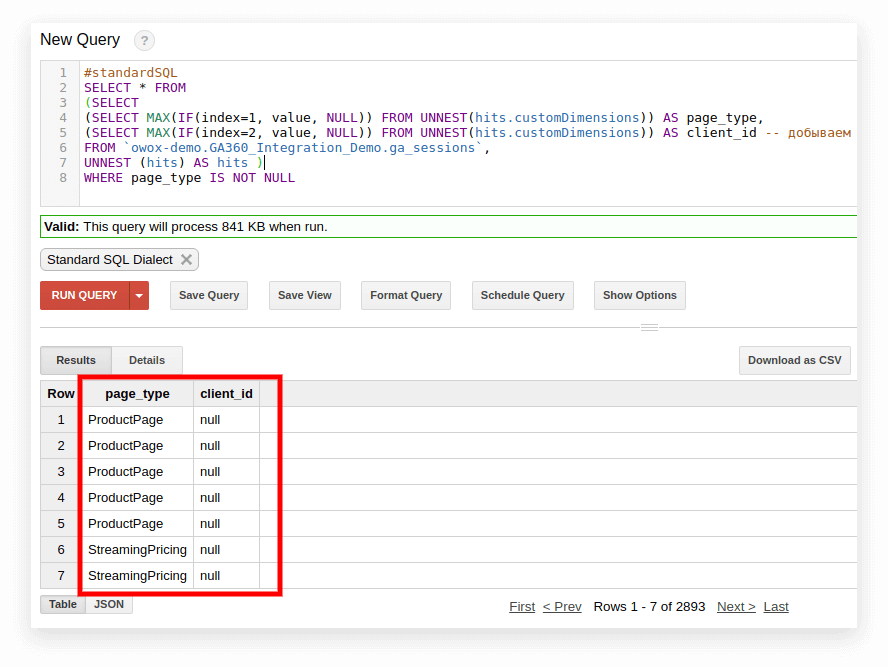
3. Trafik kaynağı, kanal, kampanya, şehir ve cihaz kategorisine göre oturum sayısını hesaplayın
Bu tür hesaplamalar, verileri Google Data Studio'da görselleştirmeyi ve şehir ve cihaz kategorisine göre filtrelemeyi planlıyorsanız kullanışlıdır. COUNT pencere işleviyle bunu yapmak kolaydır:
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`4. Aynı verileri birkaç tablodan birleştirin
Birkaç BigQuery tablosunda tamamlanan siparişlerle ilgili veri topladığınızı varsayalım: biri A Mağazasından tüm siparişleri, diğeri B Mağazasından siparişleri toplar. Bunları şu sütunlarla tek bir tabloda birleştirmek istiyorsunuz:
- client_id — benzersiz bir alıcıyı tanımlayan bir sayı
- transaction_created — TIMESTAMP formatında sipariş oluşturma zamanı
- işlem_kimliği - sipariş numarası
- is_approved — siparişin onaylanıp onaylanmadığı
- işlem_revenue — sipariş tutarı
Örneğimizde 1 Ocak 2018 tarihinden düne kadar olan siparişler mutlaka tabloda yer almalıdır. Bunu yapmak için, her tablo grubundan uygun sütunları seçin, onlara aynı adı atayın ve sonuçları UNION ALL ile birleştirin:
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC5. Trafik kanalı grupları sözlüğü oluşturun
Veriler Google Analytics'e girdiğinde, sistem belirli bir geçişin ait olduğu grubu otomatik olarak belirler: Doğrudan, Organik Arama, Ücretli Arama vb. Google Analytics, bir kanal grubunu belirlemek için UTM geçiş etiketlerine, yani utm_source ve utm_medium'a bakar. Google Analytics Yardım'da kanal grupları ve tanım kuralları hakkında daha fazla bilgi edinebilirsiniz.
OWOX BI istemcileri kanal gruplarına kendi adlarını atamak isterse, geçişin belirli bir kanala ait olduğu bir sözlük oluştururuz. Bunu yapmak için koşullu CASE operatörünü ve REGEXP_CONTAINS işlevini kullanırız. Bu işlev, belirtilen normal ifadenin gerçekleştiği değerleri seçer.
Adları Google Analytics'teki kaynak listenizden almanızı öneririz. Bu tür koşulların istek gövdesine nasıl ekleneceğine ilişkin bir örnek:
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201` Standart SQL'e nasıl geçilir
Henüz Standart SQL'e geçmediyseniz, bunu istediğiniz zaman yapabilirsiniz. Ana şey, lehçeleri tek bir istekte karıştırmaktan kaçınmaktır.
1. Seçenek Google BigQuery arayüzünü açın
Eski BigQuery arayüzünde varsayılan olarak eski SQL kullanılır. Lehçeler arasında geçiş yapmak için, sorgu giriş alanı altındaki Seçenekleri Göster'e tıklayın ve SQL Lehçesi'nin yanındaki Eski SQL Kullan kutusunun işaretini kaldırın.
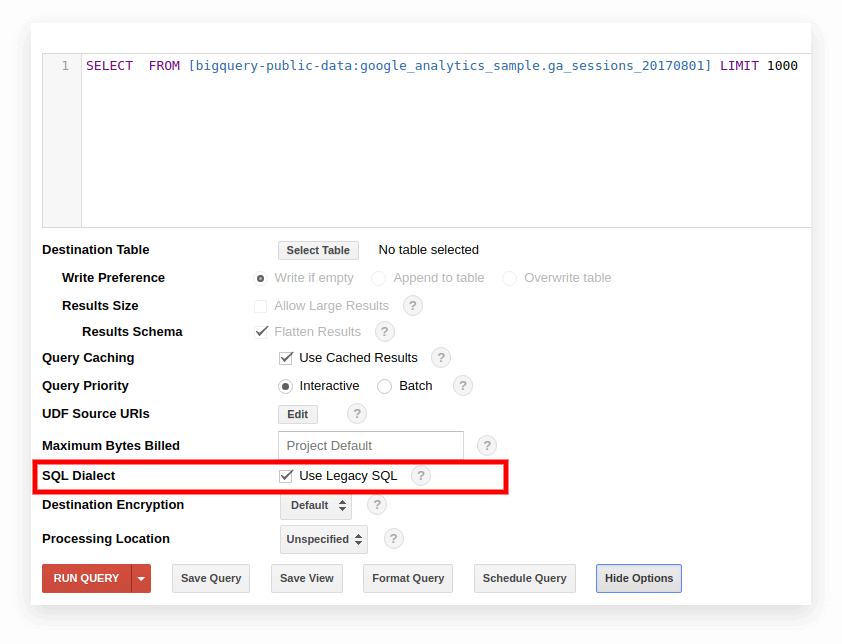
Yeni arayüz, varsayılan olarak Standart SQL'i kullanır. Burada, lehçeleri değiştirmek için Daha Fazla sekmesine gitmeniz gerekir:
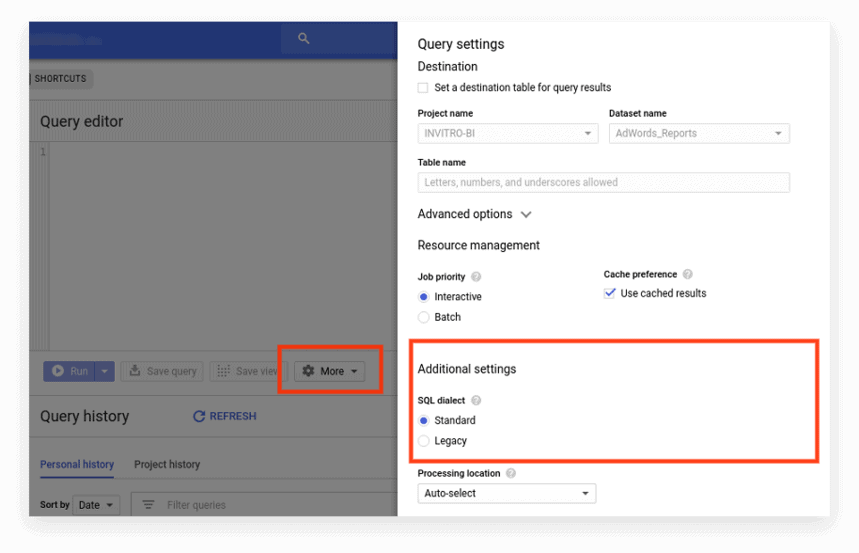
Seçenek 2. Ön eki isteğin başına yazın
İstek ayarlarını işaretlemediyseniz, istediğiniz önekle (#standardSQL veya #legacySQL) başlayabilirsiniz:
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10;
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10; Bu durumda Google BigQuery, arayüzdeki ayarları yok sayar ve ön ekte belirtilen lehçeyi kullanarak sorguyu çalıştırır.
Apps Komut Dosyası kullanılarak bir zamanlamaya göre başlatılan görünümleriniz veya kayıtlı sorgularınız varsa, komut dosyasında useLegacySql değerini false olarak değiştirmeyi unutmayın:
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }Seçenek 3. Görünümler için Standart SQL'e Geçiş
Google BigQuery ile tablolarla değil görünümlerle çalışıyorsanız, bu görünümlere Standart SQL lehçesinde erişilemez. Yani sununuz Eski SQL'de yazılmışsa, Standart SQL'de ona istek yazamazsınız.
Bir görünümü standart SQL'e aktarmak için, oluşturulduğu sorguyu manuel olarak yeniden yazmanız gerekir. Bunu yapmanın en kolay yolu BigQuery arayüzünden geçer.
1. Görünümü açın:
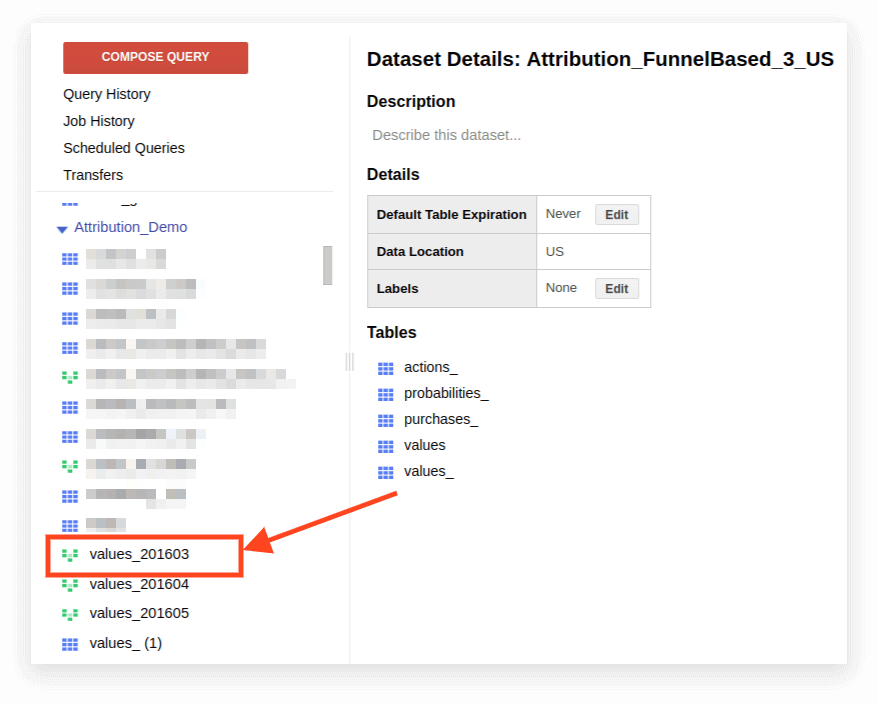
2. Ayrıntılar'ı tıklayın. Sorgu metni açılmalı ve Sorguyu Düzenle düğmesi aşağıda görünecektir:
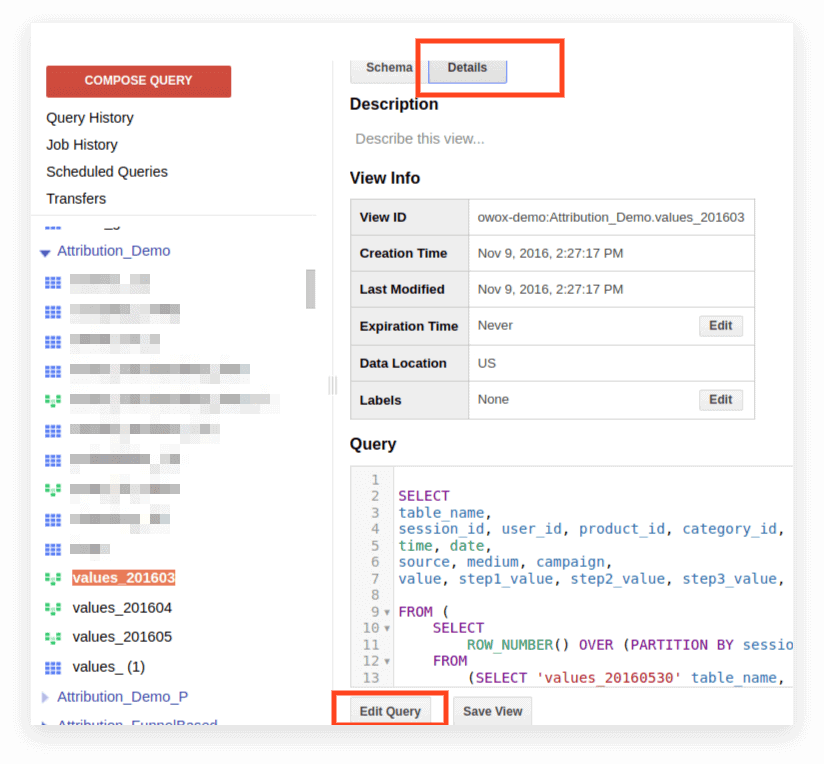
Artık isteğinizi Standart SQL kurallarına göre düzenleyebilirsiniz.
İsteği sunum olarak kullanmaya devam etmeyi planlıyorsanız, düzenlemeyi bitirdikten sonra Görünümü Kaydet'e tıklayın.
Uyumluluk, sözdizimi özellikleri, işleçler, işlevler
uyumluluk
Standart SQL uygulaması sayesinde, diğer hizmetlerde depolanan verilere doğrudan BigQuery'den erişebilirsiniz:
- Google Bulut Depolama günlük dosyaları
- Google Bigtable'daki işlem kayıtları
- Diğer kaynaklardan gelen veriler
Bu, makine öğrenimi algoritmalarına dayalı tahmine dayalı ve kuralcı analizler de dahil olmak üzere her türlü analitik görev için Google Cloud Platform ürünlerini kullanmanıza olanak tanır.
Sorgu sözdizimi
Standart lehçedeki sorgu yapısı, Legacy'deki ile hemen hemen aynıdır:
Tabloların ve görünümün adları bir nokta (nokta) ile ayrılır ve tüm sorgu ciddi vurgular içine alınır: `project_name.data_name_name.table_name``bigquery-public-data.samples.natality`
Her operatöre nelerin eklenebileceğinin açıklamalarıyla birlikte sorgunun tam sözdizimi, BigQuery belgelerinde bir şema olarak derlenmiştir.
Standart SQL sözdiziminin özellikleri:
- SELECT ifadesindeki alanları listelemek için virgül gerekir.
- UNNEST operatörünü FROM'dan sonra kullanırsanız, UNNEST'ten önce bir virgül veya JOIN konur.
- FROM'dan önce virgül koyamazsınız.
- İki sorgu arasındaki virgül, CROSS JOIN'e eşittir, bu yüzden dikkatli olun.
- JOIN, yalnızca sütun veya eşitlikle değil, keyfi ifadeler ve eşitsizlikle de yapılabilir.
- SQL ifadesinin herhangi bir bölümüne (SELECT, FROM, WHERE, vb.) karmaşık alt sorgular yazmak mümkündür. Pratikte WHERE column_name IN (SELECT ...) gibi ifadeleri diğer veritabanlarında olduğu gibi kullanmak henüz mümkün değil.
operatörler
Standart SQL'de operatörler veri türünü tanımlar. Örneğin, bir dizi her zaman parantez [] içinde yazılır. Operatörler karşılaştırma yapmak, mantıksal ifadeyi (NOT, OR, AND) eşleştirmek ve aritmetik hesaplamalarda kullanılır.
Fonksiyonlar
Standart SQL, Legacy'den daha fazla özelliği destekler: geleneksel toplama (toplam, sayı, minimum, maksimum); matematiksel, string ve istatistiksel fonksiyonlar; ve HyperLogLog ++ gibi nadir biçimler.
Standart lehçede, tarihler ve TIMESTAMP ile çalışmak için daha fazla işlev vardır. Google'ın belgelerinde özelliklerin tam listesi sağlanır. En sık kullanılan işlevler tarihler, dizeler, toplama ve pencere ile çalışmak içindir.
1. Toplama işlevleri
COUNT (DISTINCT sütun_adı), bir sütundaki benzersiz değerlerin sayısını sayar. Örneğin 1 Mart 2019'da mobil cihazlardan oturum sayısını saymamız gerektiğini varsayalım. Bir oturum numarası farklı satırlarda tekrar edilebileceğinden, yalnızca benzersiz oturum sayısı değerlerini saymak istiyoruz:
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile' SUM (sütun_adı) — sütundaki değerlerin toplamı
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile' MIN (sütun_adı) | MAX (sütun_adı) — sütundaki minimum ve maksimum değer. Bu işlevler, bir tablodaki verilerin yayılmasını kontrol etmek için uygundur.
2. Pencere (analitik) işlevleri
Analitik işlevler, değerleri tüm tablo için değil, belirli bir pencere - ilgilendiğiniz bir dizi satır için dikkate alır. Yani, bir tablo içindeki segmentleri tanımlayabilirsiniz. Örneğin, SUM'u (gelir) tüm hatlar için değil, şehirler, cihaz kategorileri vb. için hesaplayabilirsiniz. SUM, COUNT ve AVG analitik işlevlerini ve bunlara OVER koşulunu (PARTITION BY sütun_adı) ekleyerek diğer toplama işlevlerini dönüştürebilirsiniz.
Örneğin, trafik kaynağına, kanala, kampanyaya, şehre ve cihaz kategorisine göre oturum sayısını saymanız gerekir. Bu durumda aşağıdaki ifadeyi kullanabiliriz:
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t OVER, hesaplamaların yapılacağı pencereyi belirler. PARTITION BY, hesaplama için hangi satırların gruplandırılması gerektiğini belirtir. Bazı fonksiyonlarda gruplama sırasını ORDER BY ile belirtmek gerekir.
Pencere işlevlerinin tam listesi için BigQuery belgelerine bakın.
3. Dize işlevleri
Bunlar, metni değiştirmeniz, metni bir satırda biçimlendirmeniz veya sütun değerlerini yapıştırmanız gerektiğinde kullanışlıdır. Örneğin, standart Google Analytics 360 dışa aktarma verilerinden benzersiz bir oturum tanımlayıcısı oluşturmak istiyorsanız dize işlevleri harikadır. En popüler string fonksiyonlarını ele alalım.
SUBSTR, dizenin bir kısmını keser. İstekte bu fonksiyon SUBSTR (string_name, 0.4) olarak yazılır. İlk sayı satırın başından itibaren kaç karakter atlanacağını, ikinci sayı ise kaç basamak kesileceğini belirtir. Örneğin, STRING biçiminde tarihler içeren bir tarih sütununuz olduğunu varsayalım. Bu durumda tarihler şöyle görünür: 20190103. Bu satırdan bir yıl çıkarmak isterseniz SUBSTR size yardımcı olacaktır:
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301` CONCAT (sütun_adı, vb.) değerleri yapıştırır. Önceki örnekteki tarih sütununu kullanalım. Tüm tarihlerin şu şekilde kaydedilmesini istediğinizi varsayalım: 2019-03-01. Tarihleri mevcut biçimlerinden bu biçime dönüştürmek için iki dize işlevi kullanılabilir: önce dizenin gerekli parçalarını SUBSTR ile kesin, ardından bunları kısa çizgi ile yapıştırın:
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301` REGEXP_CONTAINS, normal ifadenin gerçekleştiği sütunların değerlerini döndürür:
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301` Bu fonksiyon hem SELECT hem de WHERE içinde kullanılabilir. Örneğin, NEREDE, onunla belirli sayfaları seçebilirsiniz:
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order')
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order') 4. Tarih fonksiyonları
Genellikle tablolardaki tarihler STRING biçiminde kaydedilir. Sonuçları Google Data Studio'da görselleştirmeyi planlıyorsanız, tablodaki tarihlerin PARSE_DATE işlevi kullanılarak DATE biçimine dönüştürülmesi gerekir.
PARSE_DATE, 1900-01-01 biçimindeki bir STRING öğesini DATE biçimine dönüştürür.
Tablolarınızdaki tarihler farklı görünüyorsa (örneğin, 19000101 veya 01_01_1900), önce bunları belirtilen biçime dönüştürmeniz gerekir.
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301` DATE_DIFF, iki tarih arasında gün, hafta, ay veya yıl olarak ne kadar zaman geçtiğini hesaplar. Bir kullanıcının reklamı gördüğü ve sipariş verdiği zaman arasındaki aralığı belirlemeniz gerekiyorsa bu kullanışlıdır. İşlev bir istekte şöyle görünür:
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301` Listelenen işlevler hakkında daha fazla bilgi edinmek istiyorsanız, BigQuery Google Özellikleri — Ayrıntılı İnceleme bölümünü okuyun.
Pazarlama raporları için SQL sorguları
Standart SQL diyalekti, işletmelerin derin segmentasyon, teknik denetimler, pazarlama KPI analizi ve CPA ağlarındaki haksız yüklenicilerin belirlenmesi ile verilerden maksimum bilgi elde etmesine olanak tanır. Burada, Google BigQuery'de toplanan verilerle ilgili SQL sorgularının size yardımcı olacağı iş sorunlarına ilişkin örnekler verilmiştir.
1. ROPO analizi: çevrimiçi kampanyaların çevrimdışı satışlara katkısını değerlendirin. ROPO analizini gerçekleştirmek için çevrimiçi kullanıcı davranışına ilişkin verileri CRM, çağrı izleme sistemi ve mobil uygulamanızdan gelen verilerle birleştirmeniz gerekir.
Bir ve ikinci tabanda bir anahtar varsa - her kullanıcı için benzersiz olan ortak bir parametre (örneğin, Kullanıcı Kimliği) - şunları izleyebilirsiniz:
hangi kullanıcıların mağazadan mal satın almadan önce siteyi ziyaret ettiği
kullanıcıların sitede nasıl davrandığı
kullanıcıların satın alma kararı vermesi ne kadar sürdü
Çevrimdışı satın almalarda en büyük artışı hangi kampanyalar sağladı.
2. Müşterileri, sitedeki davranıştan (ziyaret edilen sayfalar, görüntülenen ürünler, satın almadan önce siteye yapılan ziyaret sayısı) sadakat kartı numarasına ve satın alınan ürünlere kadar herhangi bir parametre kombinasyonuna göre segmentlere ayırın.
3. Hangi CPA iş ortaklarının kötü niyetle çalıştığını ve UTM etiketlerini değiştirdiğini öğrenin.
4. Satış hunisi aracılığıyla kullanıcıların ilerlemesini analiz edin.
Standart SQL lehçesinde bir dizi sorgu hazırladık. Halihazırda sitenizden, reklam kaynaklarından ve Google BigQuery'deki CRM sisteminizden veri topluyorsanız, iş sorunlarınızı çözmek için bu şablonları kullanabilirsiniz. BigQuery'deki proje adını, veri kümesini ve tabloyu kendinizle değiştirin. Koleksiyonda 11 SQL sorgusu alacaksınız.
Google Analytics 360'tan Google BigQuery'ye standart dışa aktarma kullanılarak toplanan veriler için:
- Herhangi bir parametre bağlamında kullanıcı eylemleri
- Anahtar kullanıcı eylemlerine ilişkin istatistikler
- Belirli ürün sayfalarını görüntüleyen kullanıcılar
- Belirli bir ürünü satın alan kullanıcıların eylemleri
- Gerekli tüm adımlarla huniyi kurun
- Dahili arama sitesinin etkinliği
OWOX BI kullanılarak Google BigQuery'de toplanan veriler için:
- Kaynak ve kanala göre atfedilen tüketim
- Bir ziyaretçiyi şehre çekmenin ortalama maliyeti
- Kaynağa ve kanala göre brüt kâr için ROAS
- Ödeme yöntemine ve teslimat yöntemine göre CRM'deki sipariş sayısı
- Şehre göre ortalama teslimat süresi
Bu makalede yanıtını bulamadığınız Google BigQuery verilerini sorgulama hakkında sorularınız varsa yorumlarda sorun. Size yardımcı olmaya çalışacağız.