
SQL standard dans Google BigQuery : avantages et exemples d'utilisation en marketing
Publié: 2022-04-12En 2016, Google BigQuery a introduit une nouvelle façon de communiquer avec les tables : le SQL standard. Jusque-là, BigQuery avait son propre langage de requête structuré appelé BigQuery SQL (maintenant appelé Legacy SQL).
À première vue, il n'y a pas beaucoup de différence entre Legacy et Standard SQL : les noms des tables sont écrits un peu différemment ; Standard a des exigences grammaticales légèrement plus strictes (par exemple, vous ne pouvez pas mettre de virgule avant FROM) et davantage de types de données. Mais si vous regardez attentivement, il y a quelques modifications mineures de la syntaxe qui offrent de nombreux avantages aux spécialistes du marketing.
Dans cet article, vous obtiendrez des réponses aux questions suivantes :
- Quels sont les avantages du SQL standard par rapport au SQL hérité ?
- Quelles sont les fonctionnalités de Standard SQL et comment est-il utilisé ?
- Comment puis-je passer de Legacy à Standard SQL ?
- Avec quels autres services, caractéristiques de syntaxe, opérateurs et fonctions le SQL standard est-il compatible ?
- Comment puis-je utiliser des requêtes SQL pour les rapports marketing ?
Quels sont les avantages du SQL standard par rapport au SQL hérité ?
Nouveaux types de données : tableaux et champs imbriqués
Le SQL standard prend en charge de nouveaux types de données : ARRAY et STRUCT (tableaux et champs imbriqués). Cela signifie que dans BigQuery, il est devenu plus facile de travailler avec des tables chargées à partir de fichiers JSON/Avro, qui contiennent souvent des pièces jointes à plusieurs niveaux.
Un champ imbriqué est une mini table à l'intérieur d'une plus grande :
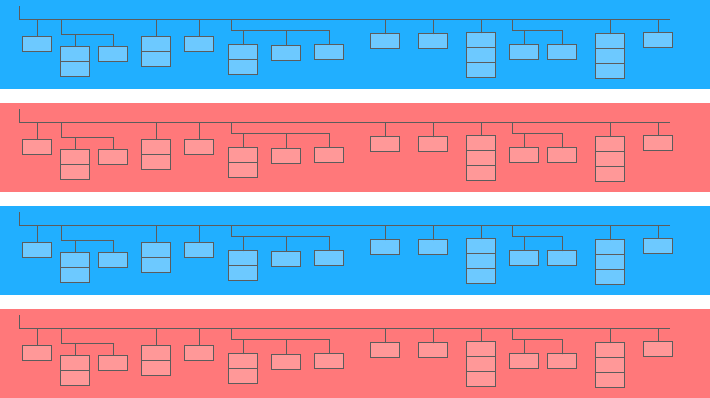
Dans le diagramme ci-dessus, les barres bleues et jaunes sont les lignes dans lesquelles les mini-tableaux sont intégrés. Chaque ligne est une session. Les sessions ont des paramètres communs : date, numéro d'identification, catégorie d'appareil utilisateur, navigateur, système d'exploitation, etc. En plus des paramètres généraux pour chaque session, le tableau des hits est attaché à la ligne.

Le tableau des hits contient des informations sur les actions des utilisateurs sur le site. Par exemple, si un utilisateur clique sur une bannière, feuillette le catalogue, ouvre une page produit, met un produit dans le panier ou passe une commande, ces actions seront enregistrées dans le tableau des visites.
Si un utilisateur passe une commande sur le site, des informations sur la commande seront également saisies dans le tableau des visites :
- transactionId (numéro identifiant la transaction)
- transactionRevenue (valeur totale de la commande)
- transactionShipping (frais de port)
Les tables de données de session collectées à l'aide d'OWOX BI ont une structure similaire.
Supposons que vous souhaitiez connaître le nombre de commandes passées par des utilisateurs à New York au cours du mois dernier. Pour le savoir, vous devez vous référer au tableau des résultats et compter le nombre d'identifiants de transaction uniques. Pour extraire des données de ces tables, le SQL standard dispose d'une fonction UNNEST :
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City Si les informations de commande ont été enregistrées dans une table séparée et non dans une table imbriquée, vous devrez utiliser JOIN pour combiner la table avec les informations de commande et la table avec les données de session afin de savoir dans quelles sessions les commandes ont été passées.
Plus d'options de sous-requête
Si vous avez besoin d'extraire des données de champs imbriqués à plusieurs niveaux, vous pouvez ajouter des sous-requêtes avec SELECT et WHERE. Par exemple, dans les tables de streaming de session OWOX BI, une autre sous-table, product, est écrite dans la sous-table hits. La sous-table de produit collecte les données de produit qui sont transmises avec un tableau Enhanced Ecommerce. Si un e-commerce enrichi est mis en place sur le site et qu'un utilisateur a consulté une page produit, les caractéristiques de ce produit seront enregistrées dans la sous-table produit.
Pour obtenir ces caractéristiques de produit, vous aurez besoin d'une sous-requête dans la requête principale. Pour chaque caractéristique de produit, une sous-requête SELECT distincte est créée entre parenthèses :
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD`
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` Grâce aux fonctionnalités du SQL standard, il est plus facile de créer une logique de requête et d'écrire du code. À titre de comparaison, dans Legacy SQL, vous auriez besoin d'écrire ce type d'échelle :
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )Demandes à des sources externes
À l'aide de SQL standard, vous pouvez accéder aux tables BigQuery directement depuis Google Bigtable, Google Cloud Storage, Google Drive et Google Sheets.
Autrement dit, au lieu de charger l'intégralité de la table dans BigQuery, vous pouvez supprimer les données avec une seule requête, sélectionner les paramètres dont vous avez besoin et les importer dans le stockage cloud.
Plus de fonctions utilisateur (UDF)
Si vous avez besoin d'utiliser une formule qui n'est pas documentée, les fonctions définies par l'utilisateur (UDF) vous aideront. Dans notre pratique, cela se produit rarement, car la documentation SQL standard couvre presque toutes les tâches d'analyse numérique.
En SQL standard, les fonctions définies par l'utilisateur peuvent être écrites en SQL ou JavaScript ; L'ancien SQL ne prend en charge que JavaScript. Les arguments de ces fonctions sont des colonnes, et les valeurs qu'elles prennent sont le résultat de la manipulation des colonnes. En SQL standard, les fonctions peuvent être écrites dans la même fenêtre que les requêtes.
Plus de conditions de JOIN
Dans Legacy SQL, les conditions JOIN peuvent être basées sur l'égalité ou les noms de colonne. En plus de ces options, le dialecte SQL Standard supporte les JOIN par inégalité et par expression arbitraire.
Par exemple, pour identifier les partenaires CPA injustes, nous pouvons sélectionner des sessions dans lesquelles la source a été remplacée dans les 60 secondes suivant la transaction. Pour ce faire, en SQL standard, nous pouvons ajouter une inégalité à la condition JOIN :
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime La seule limitation du SQL standard par rapport à JOIN est qu'il n'autorise pas la semi-jointure avec des sous-requêtes de la forme WHERE colonne IN (SELECT ...) :
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESC
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESCMoins de risques d'erreurs
Certaines fonctions de Legacy SQL renvoient NULL si la condition est incorrecte. Par exemple, si la division par zéro s'est glissée dans vos calculs, la requête sera exécutée et des entrées NULL apparaîtront dans les lignes résultantes de la table. Cela peut masquer des problèmes dans la requête ou dans les données.
La logique du SQL standard est plus simple. Si une condition ou une donnée d'entrée est incorrecte, la requête générera une erreur, par exemple « division par zéro », afin que vous puissiez rapidement corriger la requête. Les vérifications suivantes sont intégrées dans le SQL standard :
- Valeurs valides pour +, -, ×, SUM, AVG, STDEV
- Division par zéro
Les requêtes s'exécutent plus rapidement
Les requêtes JOIN écrites en SQL Standard sont plus rapides que celles écrites en Legacy SQL grâce au filtrage préalable des données entrantes. Tout d'abord, la requête sélectionne les lignes qui correspondent aux conditions JOIN, puis les traite.
À l'avenir, Google BigQuery s'efforcera d'améliorer la vitesse et les performances des requêtes uniquement pour le SQL standard.
Les tableaux peuvent être modifiés : insérer et supprimer des lignes, mettre à jour
Les fonctions DML (Data Manipulation Language) sont disponibles en SQL standard. Cela signifie que vous pouvez mettre à jour des tables et y ajouter ou en supprimer des lignes via la même fenêtre dans laquelle vous écrivez des requêtes. Par exemple, en utilisant DML, vous pouvez combiner les données de deux tables en une seule :
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)Le code est plus facile à lire et à modifier
Avec le SQL standard, les requêtes complexes peuvent être lancées non seulement avec SELECT mais aussi avec WITH, ce qui rend le code plus facile à lire, à commenter et à comprendre. Cela signifie également qu'il est plus facile d'éviter les siennes et de corriger les erreurs des autres.
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2 Il est pratique de travailler avec l'opérateur AVEC si vous avez des calculs qui se font en plusieurs étapes. Tout d'abord, vous pouvez collecter des métriques intermédiaires dans des sous-requêtes, puis effectuer les calculs finaux.
La Google Cloud Platform (GCP), qui inclut BigQuery, est une plate-forme à cycle complet pour travailler avec le Big Data, de l'organisation d'un entrepôt de données ou d'un cloud de données à l'exécution d'expériences scientifiques et d'analyses prédictives et prescriptives. Avec l'introduction du SQL standard, BigQuery élargit son audience. Travailler avec GCP devient de plus en plus intéressant pour les analystes marketing, les analystes de produits, les data scientists et les équipes d'autres spécialistes.
Fonctionnalités du SQL standard et exemples de cas d'utilisation
Chez OWOX BI, nous travaillons souvent avec des tableaux compilés à l'aide de l'exportation standard de Google Analytics 360 vers Google BigQuery ou le pipeline OWOX BI. Dans les exemples ci-dessous, nous examinerons les spécificités des requêtes SQL pour de telles données.
Si vous ne collectez pas encore de données à partir de votre site dans BigQuery, vous pouvez essayer de le faire gratuitement avec la version d'essai d'OWOX BI.
1. Sélectionnez des données pour un intervalle de temps
Dans Google BigQuery, les données de comportement des utilisateurs de votre site sont stockées dans des tableaux génériques (tableaux avec un astérisque) ; un tableau séparé est formé pour chaque jour. Ces tables ont le même nom : seul le suffixe est différent. Le suffixe est la date au format AAAAMMJJ. Par exemple, la table owoxbi_sessions_20190301 contient des données sur les sessions du 1er mars 2019.
Nous pouvons faire référence directement à un groupe de ces tables dans une seule requête afin d'obtenir des données, par exemple, du 1er février au 28 février 2019. Pour ce faire, nous devons remplacer AAAAMMJJ par un * dans FROM, et dans WHERE, nous devons spécifier les suffixes de table pour le début et la fin de l'intervalle de temps :
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �'
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �' Les dates précises pour lesquelles nous souhaitons collecter des données ne nous sont pas toujours connues. Par exemple, chaque semaine, nous pourrions avoir besoin d'analyser les données des trois derniers mois. Pour cela, nous pouvons utiliser la fonction FORMAT_DATE :
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) Après BETWEEN, nous enregistrons le suffixe du premier tableau. L'expression CURRENT_DATE (), INTERVAL 3 MONTHS signifie "sélectionner les données des 3 derniers mois à partir de la date actuelle". Le deuxième suffixe de table est formaté après ET. Il est nécessaire de marquer la fin de l'intervalle comme hier : CURRENT_DATE (), INTERVAL 1 DAY.
2. Récupérer les paramètres utilisateur et les indicateurs
Les paramètres utilisateur et les métriques des tables d'exportation Google Analytics sont écrits dans la table des accès imbriqués et dans les sous-tables customDimensions et customMetrics. Toutes les dimensions personnalisées sont enregistrées dans deux colonnes : une pour le nombre de paramètres collectés sur le site, la seconde pour leurs valeurs. Voici à quoi ressemblent tous les paramètres transmis d'un seul coup :
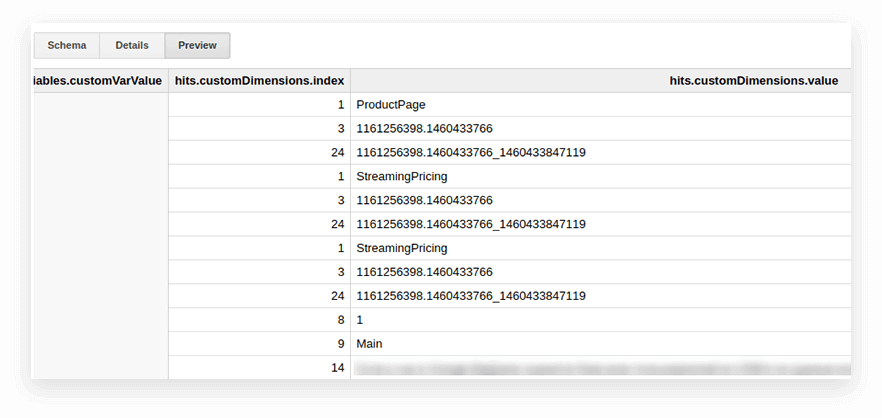
Afin de les décompresser et d'écrire les paramètres nécessaires dans des colonnes séparées, nous utilisons la requête SQL suivante :
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 Voici à quoi cela ressemble dans la requête :
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201` Dans la capture d'écran ci-dessous, nous avons sélectionné les paramètres 1 et 2 des données de démonstration de Google Analytics 360 dans Google BigQuery et les avons appelés page_type et client_id. Chaque paramètre est enregistré dans une colonne distincte :

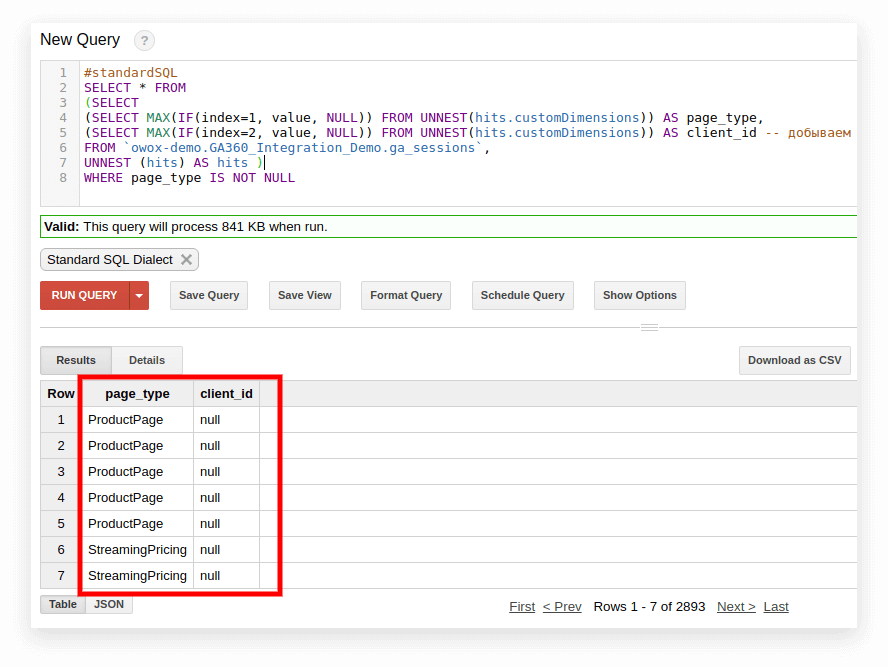
3. Calculez le nombre de sessions par source de trafic, canal, campagne, ville et catégorie d'appareil
Ces calculs sont utiles si vous prévoyez de visualiser les données dans Google Data Studio et de filtrer par ville et catégorie d'appareil. C'est facile à faire avec la fonction de fenêtre COUNT :
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`4. Combinez les mêmes données de plusieurs tables
Supposons que vous collectiez des données sur les commandes terminées dans plusieurs tables BigQuery : l'une collecte toutes les commandes du magasin A, l'autre collecte les commandes du magasin B. Vous souhaitez les combiner dans une table avec ces colonnes :
- client_id — un numéro qui identifie un acheteur unique
- transaction_created — heure de création de la commande au format TIMESTAMP
- transaction_id — numéro de commande
- is_approved — si la commande a été confirmée
- transaction_revenu — montant de la commande
Dans notre exemple, les commandes du 1er janvier 2018 à hier doivent figurer dans le tableau. Pour ce faire, sélectionnez les colonnes appropriées dans chaque groupe de tables, attribuez-leur le même nom et combinez les résultats avec UNION ALL :
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC5. Créer un dictionnaire des groupes de canaux de trafic
Lorsque les données entrent dans Google Analytics, le système détermine automatiquement le groupe auquel appartient une transition particulière : recherche directe, recherche organique, recherche payante, etc. Pour identifier un groupe de canaux, Google Analytics regarde les balises UTM des transitions, à savoir utm_source et utm_medium. Vous pouvez en savoir plus sur les groupes de canaux et les règles de définition dans l'aide de Google Analytics.
Si les clients OWOX BI souhaitent attribuer leurs propres noms à des groupes de canaux, nous créons un dictionnaire, dont la transition appartient à un canal spécifique. Pour ce faire, nous utilisons l'opérateur conditionnel CASE et la fonction REGEXP_CONTAINS. Cette fonction sélectionne les valeurs dans lesquelles l'expression régulière spécifiée se produit.
Nous vous recommandons de prendre les noms de votre liste de sources dans Google Analytics. Voici un exemple de la façon d'ajouter de telles conditions au corps de la requête :
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201` Comment passer au SQL standard
Si vous n'êtes pas encore passé au SQL standard, vous pouvez le faire à tout moment. L'essentiel est d'éviter de mélanger les dialectes dans une même requête.
Option 1. Basculer dans l'interface Google BigQuery
L'ancien SQL est utilisé par défaut dans l'ancienne interface BigQuery. Pour basculer entre les dialectes, cliquez sur Afficher les options sous le champ de saisie de la requête et décochez la case Utiliser le SQL hérité en regard de Dialecte SQL.
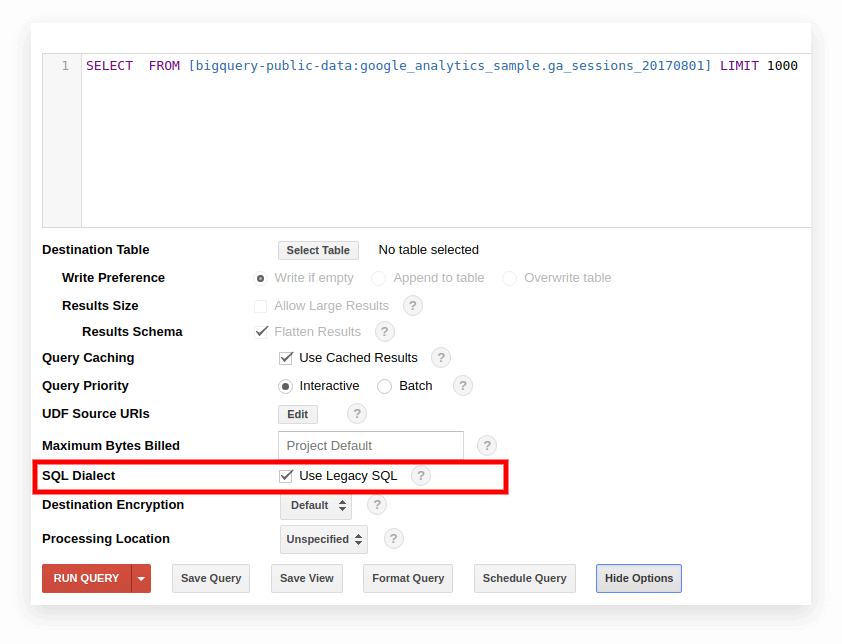
La nouvelle interface utilise le SQL standard par défaut. Ici, vous devez aller dans l'onglet Plus pour changer de dialecte :
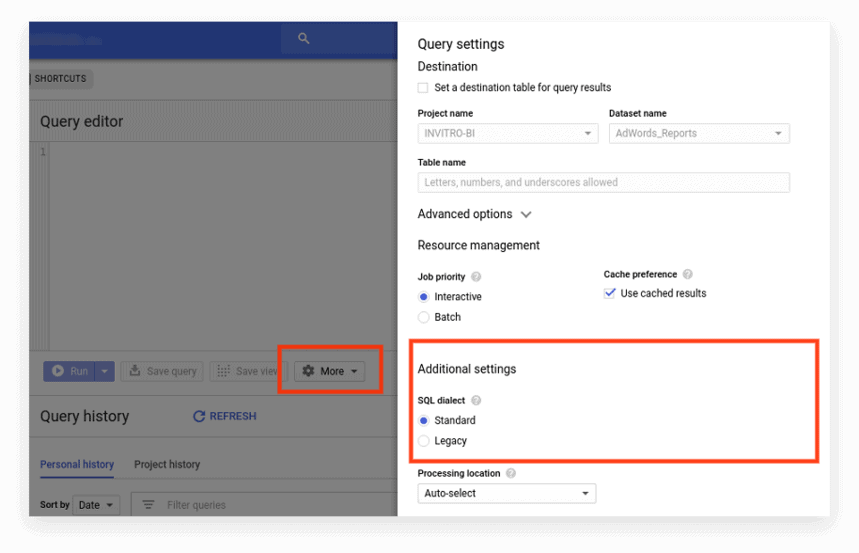
Option 2. Écrivez le préfixe au début de la requête
Si vous n'avez pas coché les paramètres de la requête, vous pouvez commencer par le préfixe souhaité (#standardSQL ou #legacySQL) :
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10;
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10; Dans ce cas, Google BigQuery ignorera les paramètres de l'interface et exécutera la requête en utilisant le dialecte spécifié dans le préfixe.
Si vous avez des vues ou des requêtes enregistrées qui sont lancées selon un calendrier à l'aide d'Apps Script, n'oubliez pas de modifier la valeur de useLegacySql sur false dans le script :
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }Option 3. Transition vers SQL standard pour les vues
Si vous travaillez avec Google BigQuery non pas avec des tables mais avec des vues, ces vues ne sont pas accessibles dans le dialecte SQL standard. Autrement dit, si votre présentation est écrite en SQL hérité, vous ne pouvez pas y écrire de requêtes en SQL standard.
Pour transférer une vue en SQL standard, vous devez réécrire manuellement la requête par laquelle elle a été créée. Pour ce faire, le moyen le plus simple consiste à utiliser l'interface BigQuery.
1. Ouvrez la vue :
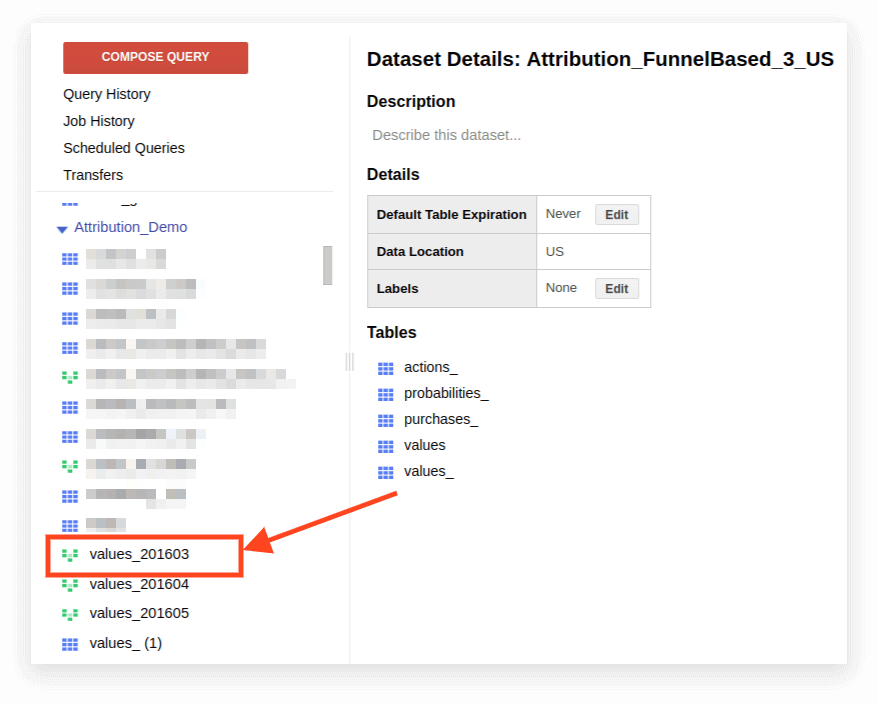
2. Cliquez sur Détails. Le texte de la requête devrait s'ouvrir et le bouton Modifier la requête apparaîtra ci-dessous :
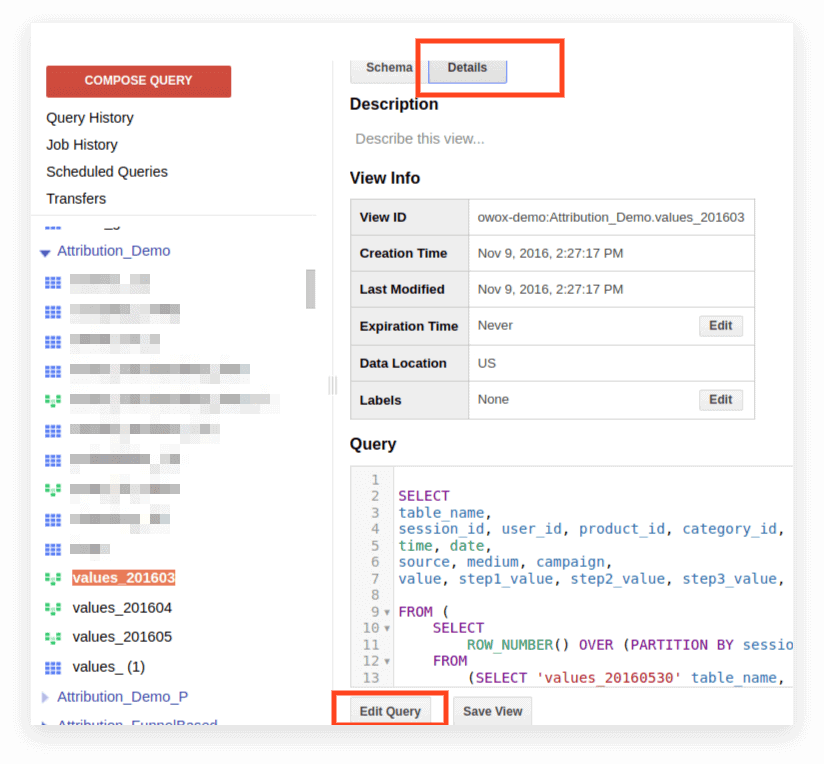
Vous pouvez maintenant modifier la requête selon les règles du SQL standard.
Si vous prévoyez de continuer à utiliser la demande en tant que présentation, cliquez sur Enregistrer la vue après avoir terminé la modification.
Compatibilité, caractéristiques de syntaxe, opérateurs, fonctions
Compatibilité
Grâce à la mise en œuvre de Standard SQL, vous pouvez accéder directement aux données stockées dans d'autres services directement depuis BigQuery :
- Fichiers journaux de Google Cloud Storage
- Enregistrements transactionnels dans Google Bigtable
- Données provenant d'autres sources
Cela vous permet d'utiliser les produits Google Cloud Platform pour toutes les tâches analytiques, y compris les analyses prédictives et prescriptives basées sur des algorithmes d'apprentissage automatique.
Syntaxe de la requête
La structure de la requête dans le dialecte Standard est presque la même que dans Legacy :
Les noms des tables et de la vue sont séparés par un point (point) et toute la requête est entourée d'accents graves : `project_name.data_name_name.table_name``bigquery-public-data.samples.natality`
La syntaxe complète de la requête, avec des explications sur ce qui peut être inclus dans chaque opérateur, est compilée sous forme de schéma dans la documentation BigQuery.
Fonctionnalités de la syntaxe SQL standard :
- Des virgules sont nécessaires pour répertorier les champs dans l'instruction SELECT.
- Si vous utilisez l'opérateur UNNEST après FROM , une virgule ou JOIN est placée avant UNNEST.
- Vous ne pouvez pas mettre une virgule avant FROM.
- Une virgule entre deux requêtes équivaut à un CROSS JOIN, alors faites attention.
- JOIN peut être fait non seulement par colonne ou égalité, mais par expressions arbitraires et inégalité.
- Il est possible d'écrire des sous-requêtes complexes dans n'importe quelle partie de l'expression SQL (dans SELECT, FROM, WHERE, etc.). En pratique, il n'est pas encore possible d'utiliser des expressions telles que WHERE nom_colonne IN (SELECT ...) comme vous pouvez le faire dans d'autres bases de données.
Les opérateurs
En SQL standard, les opérateurs définissent le type de données. Par exemple, un tableau est toujours écrit entre crochets []. Les opérateurs sont utilisés pour la comparaison, correspondant à l'expression logique (NOT, OR, AND) et dans les calculs arithmétiques.
Les fonctions
SQL standard prend en charge plus de fonctionnalités que Legacy : agrégation traditionnelle (somme, nombre, minimum, maximum) ; fonctions mathématiques, de chaîne et statistiques ; et des formats rares comme HyperLogLog++.
Dans le dialecte Standard, il y a plus de fonctions pour travailler avec les dates et TIMESTAMP. Une liste complète des fonctionnalités est fournie dans la documentation de Google. Les fonctions les plus couramment utilisées concernent les dates, les chaînes, l'agrégation et la fenêtre.
1. Fonctions d'agrégation
COUNT (DISTINCT nom_colonne) compte le nombre de valeurs uniques dans une colonne. Par exemple, supposons que nous devions compter le nombre de sessions à partir d'appareils mobiles le 1er mars 2019. Étant donné qu'un numéro de session peut être répété sur différentes lignes, nous voulons compter uniquement les valeurs uniques du numéro de session :
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile' SUM (column_name) — la somme des valeurs de la colonne
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile' MIN (nom_colonne) | MAX (column_name) — la valeur minimum et maximum dans la colonne. Ces fonctions sont pratiques pour vérifier la répartition des données dans une table.
2. Fonctions de fenêtre (analytiques)
Les fonctions analytiques considèrent les valeurs non pas pour l'ensemble du tableau mais pour une certaine fenêtre - un ensemble de lignes qui vous intéressent. Autrement dit, vous pouvez définir des segments dans un tableau. Par exemple, vous pouvez calculer SUM (revenu) non pas pour toutes les lignes mais pour les villes, les catégories d'appareils, etc. Vous pouvez transformer les fonctions analytiques SUM, COUNT et AVG ainsi que d'autres fonctions d'agrégation en leur ajoutant la condition OVER (PARTITION BY nom_colonne).
Par exemple, vous devez compter le nombre de sessions par source de trafic, canal, campagne, ville et catégorie d'appareil. Dans ce cas, nous pouvons utiliser l'expression suivante :
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t OVER détermine la fenêtre pour laquelle les calculs seront effectués. PARTITION BY indique quelles lignes doivent être regroupées pour le calcul. Dans certaines fonctions, il est nécessaire de spécifier l'ordre de regroupement avec ORDER BY.
Pour obtenir la liste complète des fonctions de fenêtre, consultez la documentation BigQuery.
3. Fonctions de chaîne
Celles-ci sont utiles lorsque vous devez modifier du texte, formater le texte sur une ligne ou coller les valeurs des colonnes. Par exemple, les fonctions de chaîne sont idéales si vous souhaitez générer un identifiant de session unique à partir des données d'exportation standard de Google Analytics 360. Considérons les fonctions de chaîne les plus populaires.
SUBSTR coupe une partie de la chaîne. Dans la requête, cette fonction est écrite sous la forme SUBSTR (string_name, 0.4). Le premier nombre indique le nombre de caractères à sauter depuis le début de la ligne et le second nombre indique le nombre de chiffres à couper. Par exemple, supposons que vous ayez une colonne de date contenant des dates au format STRING. Dans ce cas, les dates ressemblent à ceci : 20190103. Si vous souhaitez extraire une année de cette ligne, SUBSTR vous aidera :
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301` CONCAT (nom_colonne, etc.) colle les valeurs. Utilisons la colonne de date de l'exemple précédent. Supposons que vous vouliez que toutes les dates soient enregistrées comme ceci : 2019-03-01. Pour convertir les dates de leur format actuel vers ce format, deux fonctions de chaîne peuvent être utilisées : d'abord, coupez les morceaux nécessaires de la chaîne avec SUBSTR, puis collez-les à travers le trait d'union :
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301` REGEXP_CONTAINS renvoie les valeurs des colonnes dans lesquelles l'expression régulière apparaît :
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301` Cette fonction peut être utilisée à la fois dans SELECT et WHERE. Par exemple, dans WHERE, vous pouvez sélectionner des pages spécifiques avec :
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order')
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order') 4. Fonctions de date
Souvent, les dates dans les tables sont enregistrées au format STRING. Si vous prévoyez de visualiser les résultats dans Google Data Studio, les dates du tableau doivent être converties au format DATE à l'aide de la fonction PARSE_DATE.
PARSE_DATE convertit une CHAÎNE au format 1900-01-01 au format DATE.
Si les dates de vos tables semblent différentes (par exemple, 19000101 ou 01_01_1900), vous devez d'abord les convertir au format spécifié.
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301` DATE_DIFF calcule le temps écoulé entre deux dates en jours, semaines, mois ou années. C'est utile si vous avez besoin de déterminer l'intervalle entre le moment où un utilisateur a vu une publicité et passé une commande. Voici à quoi ressemble la fonction dans une requête :
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301` Si vous souhaitez en savoir plus sur les fonctions répertoriées, lisez BigQuery Google Features — A Detailed Review.
Requêtes SQL pour les rapports marketing
Le dialecte SQL standard permet aux entreprises d'extraire un maximum d'informations des données avec une segmentation approfondie, des audits techniques, une analyse des KPI marketing et l'identification des sous-traitants déloyaux dans les réseaux CPA. Voici des exemples de problèmes métier dans lesquels les requêtes SQL sur les données collectées dans Google BigQuery vous aideront.
1. Analyse ROPO : évaluez la contribution des campagnes en ligne aux ventes hors ligne. Pour effectuer une analyse ROPO, vous devez combiner les données sur le comportement des utilisateurs en ligne avec les données de votre CRM, de votre système de suivi des appels et de votre application mobile.
S'il existe une clé dans l'une et la deuxième base (un paramètre commun unique pour chaque utilisateur (par exemple, l'ID utilisateur)), vous pouvez suivre :
quels utilisateurs ont visité le site avant d'acheter des produits dans le magasin
comment les utilisateurs se sont comportés sur le site
combien de temps les utilisateurs ont pris pour prendre une décision d'achat
quelles campagnes ont enregistré la plus forte augmentation des achats hors ligne.
2. Segmenter les clients par toute combinaison de paramètres, du comportement sur le site (pages visitées, produits consultés, nombre de visites sur le site avant achat) au numéro de carte de fidélité et aux articles achetés.
3. Découvrez quels partenaires CPA travaillent de mauvaise foi et remplacent les balises UTM.
4. Analysez la progression des utilisateurs dans l'entonnoir de vente.
Nous avons préparé une sélection de requêtes en dialecte SQL standard. Si vous collectez déjà des données à partir de votre site, de sources publicitaires et de votre système CRM dans Google BigQuery, vous pouvez utiliser ces modèles pour résoudre vos problèmes commerciaux. Remplacez simplement le nom du projet, l'ensemble de données et la table dans BigQuery par les vôtres. Dans la collection, vous recevrez 11 requêtes SQL.
Pour les données collectées à l'aide de l'exportation standard de Google Analytics 360 vers Google BigQuery :
- Actions de l'utilisateur dans le contexte de tous les paramètres
- Statistiques sur les actions des utilisateurs clés
- Utilisateurs ayant consulté des pages de produits spécifiques
- Actions des utilisateurs qui ont acheté un produit particulier
- Configurez l'entonnoir avec toutes les étapes nécessaires
- Efficacité du site de recherche interne
Pour les données collectées dans Google BigQuery à l'aide d'OWOX BI :
- Consommation attribuée par source et canal
- Coût moyen pour attirer un visiteur par ville
- ROAS pour la marge brute par source et canal
- Nombre de commandes dans le CRM par mode de paiement et mode de livraison
- Délai de livraison moyen par ville
Si vous avez des questions sur l'interrogation des données Google BigQuery auxquelles vous n'avez pas trouvé de réponses dans cet article, posez-les dans les commentaires. Nous essaierons de vous aider.