
Google BigQuery 中的标准 SQL:营销中使用的优势和示例
已发表: 2022-04-122016 年,Google BigQuery 引入了一种与表通信的新方式:标准 SQL。 在那之前,BigQuery 拥有自己的结构化查询语言,称为 BigQuery SQL(现在称为 Legacy SQL)。
乍一看,Legacy SQL 和 Standard SQL 并没有太大区别:表名的写法略有不同; 标准有稍微严格的语法要求(例如,您不能在 FROM 之前放置逗号)和更多的数据类型。 但是,如果您仔细观察,就会发现一些细微的语法变化给营销人员带来了许多优势。
在本文中,您将获得以下问题的答案:
- 与传统 SQL 相比,标准 SQL 有哪些优势?
- 标准 SQL 有哪些功能以及如何使用它?
- 如何从旧版 SQL 迁移到标准 SQL?
- 标准 SQL 还兼容哪些其他服务、语法特性、运算符和函数?
- 如何将 SQL 查询用于营销报告?
与传统 SQL 相比,标准 SQL 有哪些优势?
新数据类型:数组和嵌套字段
标准 SQL 支持新的数据类型:ARRAY 和 STRUCT(数组和嵌套字段)。 这意味着在 BigQuery 中,处理从 JSON/Avro 文件加载的表变得更加容易,这些文件通常包含多级附件。
嵌套字段是一个更大的表中的一个迷你表:
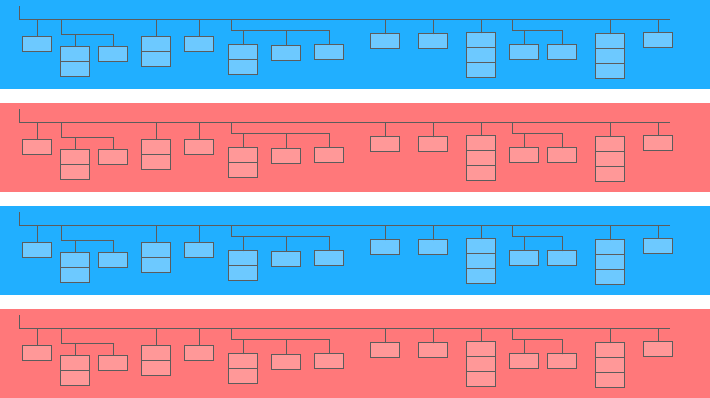
在上图中,蓝色和黄色条是嵌入迷你表格的线条。 每行是一个会话。 会话具有通用参数:日期、ID 号、用户设备类别、浏览器、操作系统等。除了每个会话的通用参数外,还附有命中表。

hits 表包含有关用户在站点上的操作的信息。 例如,如果用户点击横幅、翻阅目录、打开产品页面、将产品放入购物篮或下订单,这些操作将记录在命中表中。
如果用户在网站上下订单,订单的相关信息也将输入到命中表中:
- transactionId(标识交易的编号)
- transactionRevenue(订单总价值)
- transactionShipping(运费)
使用 OWOX BI 收集的会话数据表具有类似的结构。
假设您想知道过去一个月纽约市用户的订单数量。 要找出答案,您需要参考 hits 表并计算唯一事务 ID 的数量。 为了从这些表中提取数据,标准 SQL 有一个 UNNEST 函数:
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City 如果订单信息记录在单独的表中而不是嵌套表中,则必须使用 JOIN 将包含订单信息的表和包含会话数据的表结合起来,以便找出在哪些会话中下订单。
更多子查询选项
如果需要从多级嵌套字段中提取数据,可以使用 SELECT 和 WHERE 添加子查询。 例如,在 OWOX BI 会话流表中,另一个子表 product 被写入 hits 子表。 产品子表收集通过增强型电子商务数组传输的产品数据。 如果在网站上设置了增强型电子商务,并且用户查看了产品页面,则该产品的特征将记录在产品子表中。
要获得这些产品特征,您需要在主查询中添加一个子查询。 对于每个产品特性,在括号中创建一个单独的 SELECT 子查询:
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD`
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` 由于标准 SQL 的功能,构建查询逻辑和编写代码变得更加容易。 作为比较,在 Legacy SQL 中,您需要编写这种类型的阶梯:
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )对外部资源的请求
使用标准 SQL,您可以直接从 Google Bigtable、Google Cloud Storage、Google Drive 和 Google Sheets 访问 BigQuery 表。
也就是说,无需将整个表加载到 BigQuery 中,您可以通过一次查询删除数据,选择您需要的参数,然后将它们上传到云存储。
更多用户功能 (UDF)
如果您需要使用未记录的公式,用户定义函数 (UDF) 将为您提供帮助。 在我们的实践中,这种情况很少发生,因为标准 SQL 文档几乎涵盖了数字分析的所有任务。
在标准 SQL 中,用户定义的函数可以用 SQL 或 JavaScript 编写; 旧版 SQL 仅支持 JavaScript。 这些函数的参数是列,它们取的值是操作列的结果。 在标准 SQL 中,可以在与查询相同的窗口中编写函数。
更多JOIN条件
在旧版 SQL 中,JOIN 条件可以基于相等或列名。 除了这些选项之外,标准 SQL 方言还支持通过不等式和任意表达式进行 JOIN。
例如,为了识别不公平的 CPA 合作伙伴,我们可以选择在交易后 60 秒内更换来源的会话。 要在标准 SQL 中做到这一点,我们可以在 JOIN 条件中添加一个不等式:
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime 标准 SQL 关于 JOIN 的唯一限制是它不允许半连接形式为 WHERE column IN (SELECT ...) 的子查询:
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESC
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESC犯错的机会更小
如果条件不正确,旧版 SQL 中的某些函数会返回 NULL。 例如,如果除以零已经悄悄进入您的计算,则将执行查询,并且 NULL 条目将出现在表的结果行中。 这可能会掩盖查询或数据中的问题。
标准 SQL 的逻辑更直接。 如果条件或输入数据不正确,查询将生成错误,例如“除以零”,因此您可以快速更正查询。 标准 SQL 中嵌入了以下检查:
- +、-、×、SUM、AVG、STDEV 的有效值
- 被零除
请求运行得更快
由于对传入数据进行了初步过滤,用标准 SQL 编写的 JOIN 查询比用传统 SQL 编写的查询要快。 首先,查询选择匹配 JOIN 条件的行,然后处理它们。
将来,Google BigQuery 将致力于提高仅针对标准 SQL 的查询的速度和性能。
可以编辑表格:插入和删除行、更新
标准 SQL 中提供了数据操作语言 (DML) 函数。 这意味着您可以通过编写查询的同一窗口更新表并在其中添加或删除行。 例如,使用 DML,您可以将两个表中的数据合并为一个:
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)代码更易于阅读和编辑
使用标准 SQL,不仅可以使用 SELECT 还可以使用 WITH 启动复杂的查询,从而使代码更易于阅读、注释和理解。 这也意味着更容易防止自己的错误和纠正他人的错误。
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2 如果您的计算是分几个阶段完成的,那么使用 WITH 运算符会很方便。 首先,您可以在子查询中收集中间指标,然后进行最终计算。
包含 BigQuery 的 Google Cloud Platform (GCP) 是一个用于处理大数据的全周期平台,从组织数据仓库或数据云到运行科学实验以及预测性和规范性分析。 随着标准 SQL 的推出,BigQuery 正在扩大其受众。 对于营销分析师、产品分析师、数据科学家和其他专家团队来说,与 GCP 合作变得越来越有趣。
标准 SQL 的功能和用例示例
在 OWOX BI,我们经常处理使用标准 Google Analytics 360 导出到 Google BigQuery 或 OWOX BI Pipeline 编译的表。 在下面的示例中,我们将查看针对此类数据的 SQL 查询的细节。
如果您还没有在 BigQuery 中从您的站点收集数据,您可以尝试使用 OWOX BI 的试用版免费这样做。
1.选择时间间隔的数据
在 Google BigQuery 中,您网站的用户行为数据存储在通配符表(带有星号的表)中; 每天形成一个单独的表格。 这些表具有相同的名称:仅后缀不同。 后缀是格式为 YYYYMMDD 的日期。 例如,表 owoxbi_sessions_20190301 包含 2019 年 3 月 1 日的会话数据。
我们可以在一个请求中直接引用一组这样的表来获取数据,例如从 2019 年 2 月 1 日到 2 月 28 日。为此,我们需要在 FROM 中将 YYYYMMDD 替换为 *,在 WHERE 中,我们需要为时间间隔的开始和结束指定表后缀:
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �'
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �' 我们并不总是知道我们想要收集数据的具体日期。 例如,我们可能每周都需要分析过去三个月的数据。 为此,我们可以使用 FORMAT_DATE 函数:
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) 在 BETWEEN 之后,我们记录第一个表的后缀。 CURRENT_DATE (), INTERVAL 3 MONTHS 表示«选择从当前日期开始的最后 3 个月的数据。» 第二个表后缀在 AND 之后格式化。 需要将间隔结束标记为昨天:CURRENT_DATE (), INTERVAL 1 DAY。
2.检索用户参数和指标
Google Analytics(分析)导出表中的用户参数和指标被写入嵌套匹配表以及 customDimensions 和 customMetrics 子表。 所有自定义维度都记录在两列中:一列是网站上收集的参数数量,第二列是它们的值。 这是一击传输的所有参数的样子:
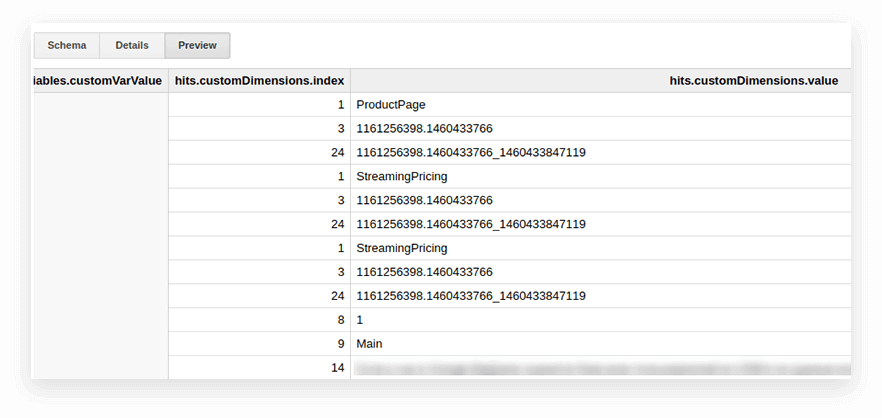
为了解压它们并将必要的参数写入单独的列,我们使用以下 SQL 查询:
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 这是请求中的样子:
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201`
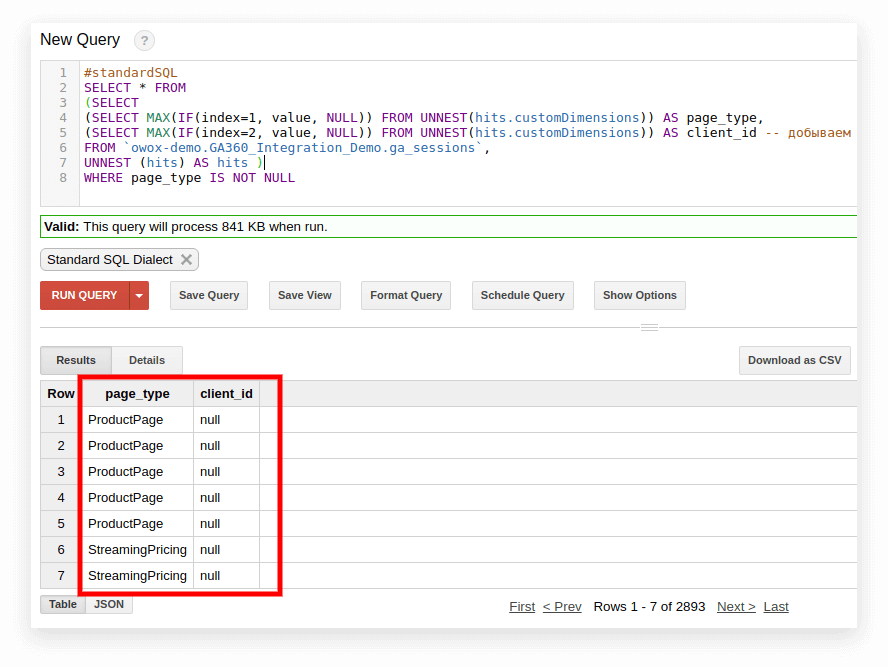
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201` 在下面的屏幕截图中,我们从 Google BigQuery 中的 Google Analytics 360 演示数据中选择了参数 1 和 2,并将它们命名为 page_type 和 client_id。 每个参数都记录在单独的列中:

3. 按流量来源、渠道、活动、城市、设备类别计算会话数
如果您计划在 Google Data Studio 中可视化数据并按城市和设备类别进行过滤,此类计算非常有用。 使用 COUNT 窗口函数很容易做到这一点:
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`4. 合并多张表的相同数据
假设您在多个 BigQuery 表中收集已完成订单的数据:一个收集来自商店 A 的所有订单,另一个收集来自商店 B 的订单。您希望将它们合并到一个包含以下列的表中:
- client_id — 标识唯一买家的数字
- transaction_created — TIMESTAMP 格式的订单创建时间
- transaction_id — 订单号
- is_approved — 订单是否被确认
- transaction_revenue — 订单金额
在我们的示例中,从 2018 年 1 月 1 日到昨天的订单必须在表中。 为此,请从每组表中选择适当的列,为它们分配相同的名称,然后将结果与 UNION ALL 结合起来:
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC5.创建流量渠道组字典
当数据进入 Google Analytics 时,系统会自动确定特定转换所属的组:直接、自然搜索、付费搜索等。 为了识别一组渠道,Google Analytics 会查看转换的 UTM 标签,即 utm_source 和 utm_medium。 您可以在 Google Analytics(分析)帮助中阅读有关渠道组和定义规则的更多信息。
如果 OWOX BI 客户端想要将自己的名称分配给通道组,我们创建一个字典,该转换属于特定通道。 为此,我们使用条件 CASE 运算符和 REGEXP_CONTAINS 函数。 该函数选择出现指定正则表达式的值。
我们建议您从 Google Analytics 中的来源列表中获取名称。 以下是如何将此类条件添加到请求正文的示例:
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201` 如何切换到标准 SQL
如果您还没有切换到标准 SQL,您可以随时切换。 主要是避免在一个请求中混合方言。
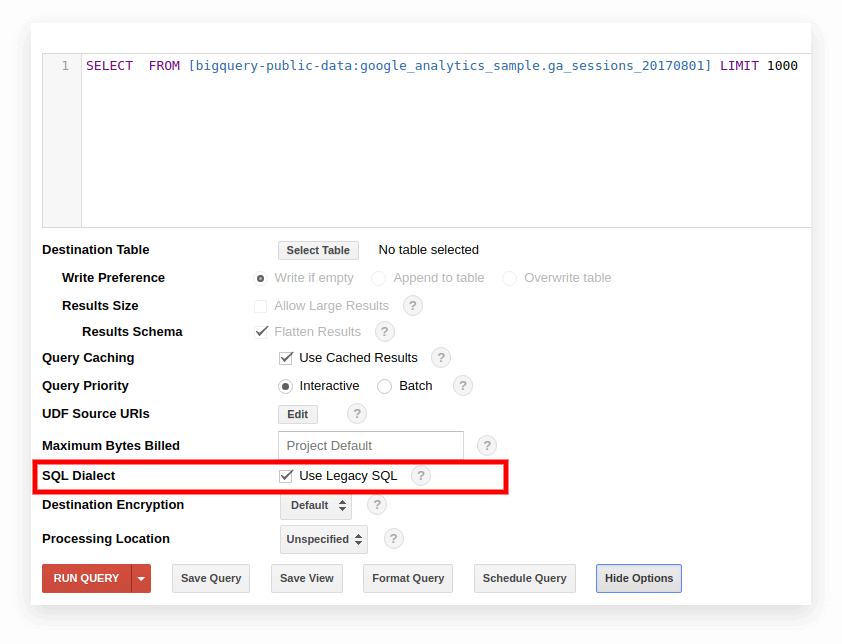
选项 1. 切换到 Google BigQuery 界面
旧版 BigQuery 界面默认使用旧版 SQL。 要在方言之间切换,请单击查询输入字段下的Show Options并取消选中 SQL Dialect 旁边的Use Legacy SQL框。
新接口默认使用标准 SQL。 在这里,您需要转到更多选项卡来切换方言:
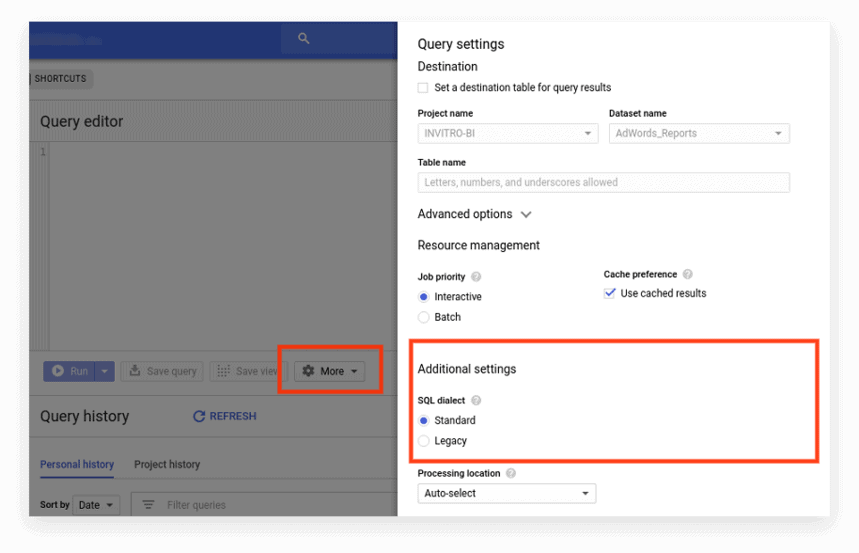
选项 2. 在请求的开头写前缀
如果您没有勾选请求设置,您可以从所需的前缀(#standardSQL 或 #legacySQL)开始:
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10;
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10; 在这种情况下,Google BigQuery 将忽略界面中的设置,并使用前缀中指定的方言运行查询。
如果您有使用 Apps 脚本按计划启动的视图或保存的查询,请不要忘记在脚本中将 useLegacySql 的值更改为 false:
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }选项 3. 转换为视图的标准 SQL
如果您使用 Google BigQuery 而不是表而是视图,则无法在标准 SQL 方言中访问这些视图。 也就是说,如果您的演示文稿是用 Legacy SQL 编写的,那么您就不能在 Standard SQL 中向它编写请求。
要将视图传输到标准 SQL,您需要手动重写创建它的查询。 最简单的方法是通过 BigQuery 界面。
1. 打开视图:
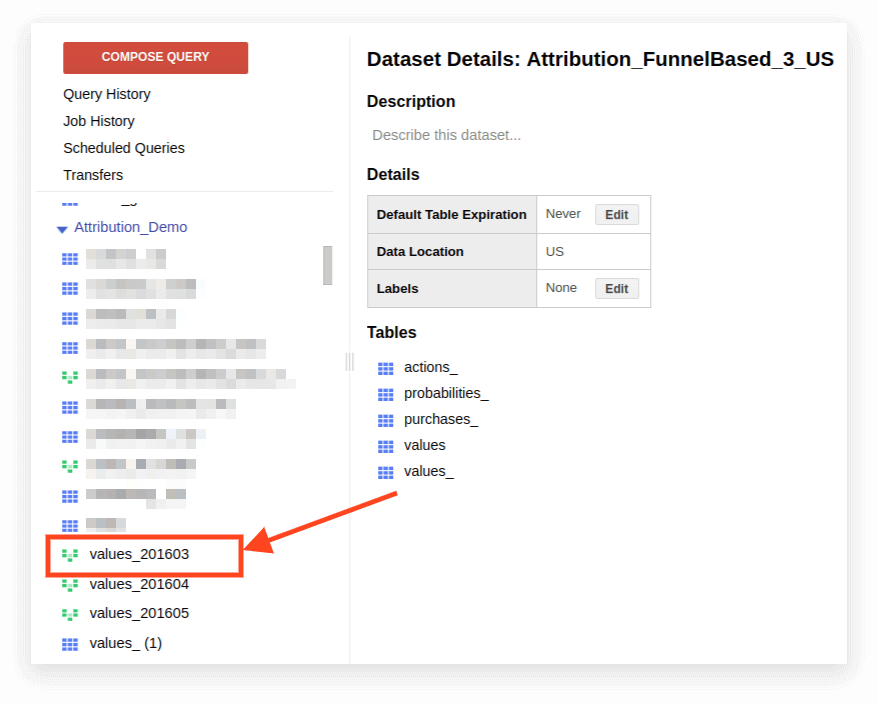
2. 单击详细信息。 查询文本应打开,编辑查询按钮将出现在下方:
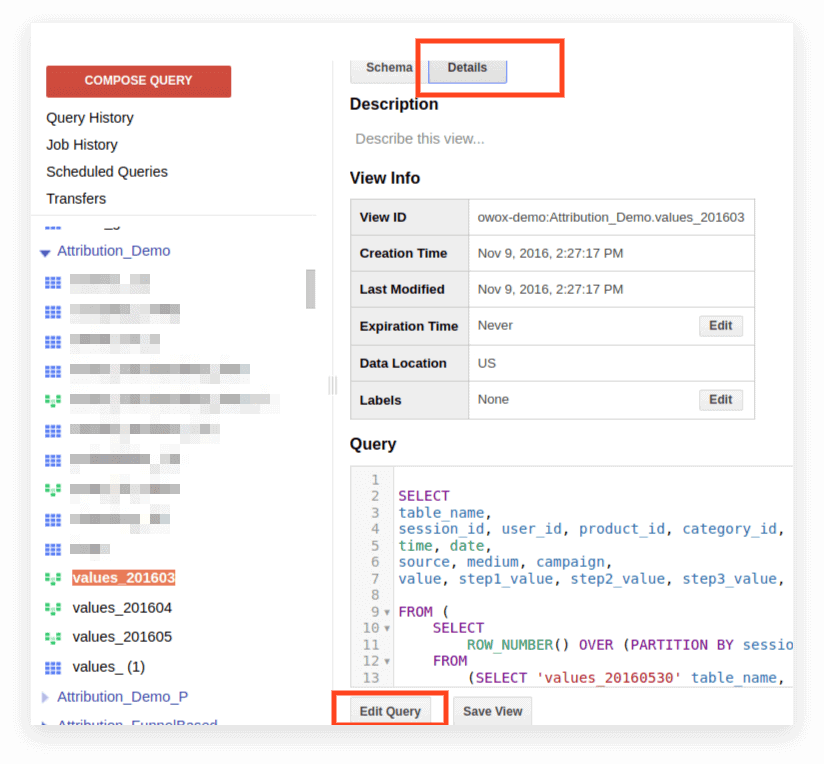
现在您可以根据标准 SQL 的规则编辑请求。
如果您打算继续将请求用作演示文稿,请在完成编辑后单击保存视图。
兼容性、语法特性、运算符、函数
兼容性
由于标准 SQL 的实施,您可以直接从 BigQuery 直接访问存储在其他服务中的数据:
- 谷歌云存储日志文件
- Google Bigtable 中的交易记录
- 其他来源的数据
这使您可以将 Google Cloud Platform 产品用于任何分析任务,包括基于机器学习算法的预测性和规范性分析。
查询语法
Standard 方言中的查询结构与 Legacy 中的几乎相同:
表和视图的名称用句点(句号)分隔,整个查询用重音括起来:`project_name.data_name_name.table_name``bigquery-public-data.samples.natality`
查询的完整语法以及每个运算符中可以包含的内容的说明在 BigQuery 文档中编译为架构。
标准 SQL 语法的特点:
- 需要逗号来列出 SELECT 语句中的字段。
- 如果在 FROM 之后使用 UNNEST 运算符,则在 UNNEST 之前放置一个逗号或 JOIN。
- FROM 前不能加逗号。
- 两个查询之间的逗号等于 CROSS JOIN,所以要小心。
- JOIN 不仅可以通过列或相等来完成,还可以通过任意表达式和不等式来完成。
- 可以在 SQL 表达式的任何部分(在 SELECT、FROM、WHERE 等中)编写复杂的子查询。 实际上,还不能像在其他数据库中那样使用 WHERE column_name IN (SELECT ...) 这样的表达式。
运营商
在标准 SQL 中,运算符定义数据的类型。 例如,数组总是写在方括号 [] 中。 运算符用于比较、匹配逻辑表达式(NOT、OR、AND)和算术计算。
职能
标准 SQL 支持比 Legacy 更多的特性:传统聚合(sum、number、minimum、maximum); 数学、字符串和统计函数; 以及 HyperLogLog ++ 等稀有格式。
在标准方言中,有更多用于处理日期和 TIMESTAMP 的功能。 Google 的文档中提供了完整的功能列表。 最常用的函数用于处理日期、字符串、聚合和窗口。
1.聚合函数
COUNT (DISTINCT column_name) 计算列中唯一值的数量。 例如,假设我们需要计算 2019 年 3 月 1 日来自移动设备的会话数。由于会话编号可以在不同的行上重复,我们只想计算唯一的会话编号值:
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile' SUM (column_name) — 列中值的总和
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile' 最小(列名)| MAX (column_name) — 列中的最小值和最大值。 这些函数便于检查表中数据的分布情况。
2.窗口(分析)功能
分析函数考虑的不是整个表的值,而是某个窗口的值——您感兴趣的一组行。也就是说,您可以在表中定义段。 例如,您可以计算 SUM(收入),而不是针对所有线路,而是针对城市、设备类别等。 您可以通过向分析函数 SUM、COUNT 和 AVG 以及其他聚合函数添加 OVER 条件 (PARTITION BY column_name) 来对其进行转换。
例如,您需要按流量来源、渠道、活动、城市和设备类别统计会话数。 在这种情况下,我们可以使用以下表达式:
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t OVER 确定将进行计算的窗口。 PARTITION BY 指示应将哪些行分组以进行计算。 在某些函数中,需要用 ORDER BY 指定分组的顺序。
有关窗口函数的完整列表,请参阅 BigQuery 文档。
3.字符串函数
当您需要更改文本、格式化一行文本或粘合列的值时,这些非常有用。 例如,如果您想从标准的 Google Analytics 360 导出数据中生成唯一的会话标识符,则字符串函数非常有用。 让我们考虑最流行的字符串函数。
SUBSTR 剪切部分字符串。 在请求中,这个函数写为 SUBSTR (string_name, 0.4)。 第一个数字表示从行首跳过多少个字符,第二个数字表示要剪切多少位。 例如,假设您有一个包含 STRING 格式日期的日期列。 在这种情况下,日期如下所示:20190103。如果您想从该行中提取年份,SUBSTR 将帮助您:
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301` CONCAT(column_name 等)粘合值。 让我们使用上一个示例中的日期列。 假设您希望像这样记录所有日期:2019-03-01。 要将日期从当前格式转换为这种格式,可以使用两个字符串函数:首先,使用 SUBSTR 剪切字符串的必要部分,然后通过连字符将它们粘合:
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301` REGEXP_CONTAINS 返回出现正则表达式的列的值:
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301` 此函数可用于 SELECT 和 WHERE。 例如,在 WHERE 中,您可以使用它选择特定页面:
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order')
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order') 4.日期功能
通常,表格中的日期以 STRING 格式记录。 如果您计划在 Google Data Studio 中可视化结果,则需要使用 PARSE_DATE 函数将表中的日期转换为 DATE 格式。
PARSE_DATE 将 1900-01-01 格式的 STRING 转换为 DATE 格式。
如果表中的日期看起来不同(例如,19000101 或 01_01_1900),则必须首先将它们转换为指定的格式。
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301` DATE_DIFF 以天、周、月或年计算两个日期之间经过的时间。 如果您需要确定用户看到广告和下订单之间的时间间隔,这很有用。 下面是函数在请求中的样子:
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301` 如果您想了解有关所列功能的更多信息,请阅读 BigQuery Google 功能 - 详细回顾。
营销报告的 SQL 查询
标准 SQL 方言允许企业通过深度细分、技术审计、营销 KPI 分析和识别 CPA 网络中的不公平承包商从数据中提取最大信息。 以下是一些业务问题示例,在这些问题中,对 Google BigQuery 中收集的数据的 SQL 查询将对您有所帮助。
1. ROPO分析:评估线上活动对线下销售的贡献。 要执行 ROPO 分析,您需要将在线用户行为数据与来自 CRM、呼叫跟踪系统和移动应用程序的数据相结合。
如果在一个和第二个碱基中有一个键——对于每个用户来说都是唯一的公共参数(例如,用户 ID)——你可以跟踪:
哪些用户在商店购买商品之前访问了该网站
用户在网站上的行为方式
用户做出购买决定需要多长时间
哪些广告系列在线下购买方面的增幅最大。
2. 通过任何参数组合对客户进行细分,从网站上的行为(访问的页面、查看的产品、购买前访问网站的次数)到会员卡号和购买的商品。
3. 找出哪些 CPA 合作伙伴在恶意工作并替换 UTM 标签。
4、通过销售漏斗分析用户的进度。
我们准备了一系列标准 SQL 方言的查询。 如果您已经从您的网站、广告来源和 Google BigQuery 中的 CRM 系统收集数据,则可以使用这些模板来解决您的业务问题。 只需将 BigQuery 中的项目名称、数据集和表替换为您自己的。 在集合中,您将收到 11 个 SQL 查询。
对于使用从 Google Analytics 360 到 Google BigQuery 的标准导出收集的数据:
- 任何参数上下文中的用户操作
- 关键用户操作统计
- 查看特定产品页面的用户
- 购买特定产品的用户的操作
- 使用任何必要的步骤设置漏斗
- 内部搜索网站的有效性
对于使用 OWOX BI 在 Google BigQuery 中收集的数据:
- 按来源和渠道划分的消费
- 城市吸引游客的平均成本
- ROAS 按来源和渠道划分的毛利润
- 按付款方式和交付方式在 CRM 中的订单数量
- 各城市的平均交货时间
如果您有关于查询 Google BigQuery 数据的问题,但在本文中没有找到答案,请在评论中提问。 我们会尽力帮助您。