
SQL padrão no Google BigQuery: vantagens e exemplos de uso em marketing
Publicados: 2022-04-12Em 2016, o Google BigQuery introduziu uma nova maneira de se comunicar com tabelas: SQL padrão. Até então, o BigQuery tinha sua própria linguagem de consulta estruturada chamada BigQuery SQL (agora chamada Legacy SQL).
À primeira vista, não há muita diferença entre Legacy e SQL padrão: os nomes das tabelas são escritos de forma um pouco diferente; O padrão tem requisitos gramaticais um pouco mais rígidos (por exemplo, você não pode colocar uma vírgula antes de FROM) e mais tipos de dados. Mas se você olhar de perto, há algumas pequenas mudanças de sintaxe que dão muitas vantagens aos profissionais de marketing.
Neste artigo, você obterá respostas para as seguintes perguntas:
- Quais são as vantagens do SQL padrão sobre o SQL legado?
- Quais são os recursos do SQL padrão e como ele é usado?
- Como posso migrar do Legacy para o SQL padrão?
- Com quais outros serviços, recursos de sintaxe, operadores e funções o SQL padrão é compatível?
- Como posso usar consultas SQL para relatórios de marketing?
Quais são as vantagens do SQL padrão sobre o SQL legado?
Novos tipos de dados: arrays e campos aninhados
O SQL padrão suporta novos tipos de dados: ARRAY e STRUCT (arrays e campos aninhados). Isso significa que, no BigQuery, ficou mais fácil trabalhar com tabelas carregadas de arquivos JSON/Avro, que geralmente contêm anexos de vários níveis.
Um campo aninhado é uma minitabela dentro de uma maior:
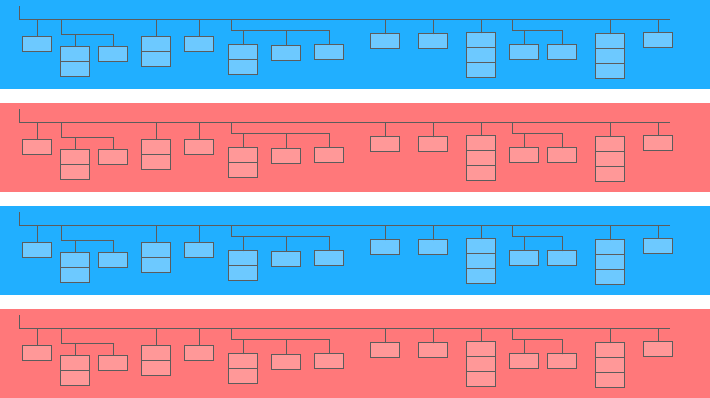
No diagrama acima, as barras azul e amarela são as linhas nas quais as mini-tabelas estão incorporadas. Cada linha é uma sessão. As sessões têm parâmetros comuns: data, número de ID, categoria do dispositivo do usuário, navegador, sistema operacional etc. Além dos parâmetros gerais para cada sessão, a tabela de acessos é anexada à linha.

A tabela de hits contém informações sobre as ações do usuário no site. Por exemplo, se um usuário clicar em um banner, folhear o catálogo, abrir uma página de produto, colocar um produto na cesta ou fazer um pedido, essas ações serão registradas na tabela de acessos.
Se um usuário fizer um pedido no site, as informações sobre o pedido também serão inseridas na tabela de acertos:
- transactionId (número que identifica a transação)
- transaçãoRevenue (valor total do pedido)
- transaçãoEnvio (custos de envio)
As tabelas de dados de sessão coletadas usando OWOX BI têm uma estrutura semelhante.
Suponha que você queira saber o número de pedidos de usuários na cidade de Nova York no último mês. Para descobrir, você precisa consultar a tabela de hits e contar o número de IDs de transação exclusivos. Para extrair dados dessas tabelas, o SQL padrão possui uma função UNNEST:
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City
#standardSQL SELECT COUNT (DISTINCT hits.transaction.transactionId) -- count the number of unique order numbers; DISTINCT helps to avoid duplication FROM `project_name.dataset_name.owoxbi_sessions_*` -- refer to the table group (wildcard tables) WHERE ( _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTHS)) -- if we don't know which dates we need, it's better to use the function FORMAT_DATE INTERVAL AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) AND geoNetwork.city = 'New York' -- choose orders made in New York City Se as informações do pedido foram registradas em uma tabela separada e não em uma tabela aninhada, você teria que usar JOIN para combinar a tabela com as informações do pedido e a tabela com os dados da sessão para descobrir em quais sessões os pedidos foram feitos.
Mais opções de subconsulta
Se você precisar extrair dados de campos aninhados de vários níveis, poderá adicionar subconsultas com SELECT e WHERE. Por exemplo, nas tabelas de streaming de sessão do OWOX BI, outra subtabela, produto, é gravada na subtabela hits. A subtabela do produto coleta dados do produto que são transmitidos com uma matriz de comércio eletrônico avançado. Se o e-commerce avançado estiver configurado no site e um usuário tiver visto a página de um produto, as características desse produto serão registradas na subtabela do produto.
Para obter essas características do produto, você precisará de uma subconsulta dentro da consulta principal. Para cada característica do produto, uma subconsulta SELECT separada é criada entre parênteses:
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD`
SELECT column_name1, -- list the other columns you want to receive column_name2, (SELECT productBrand FROM UNNEST(hits.product)) AS hits_product_productBrand, (SELECT productRevenue FROM UNNEST(hits.product)) AS hits_product_productRevenue, -- list product features (SELECT localProductRevenue FROM UNNEST(hits.product)) AS hits_product_localProductRevenue, (SELECT productPrice FROM UNNEST(hits.product)) AS hits_product_productPrice, FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` Graças aos recursos do SQL padrão, é mais fácil criar lógica de consulta e escrever código. Para comparação, no Legacy SQL, você precisaria escrever este tipo de escada:
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )
SELECT column_name1, column_name2, column_name3 FROM ( SELECT table_name.some_column AS column1… FROM table_name )Solicitações a fontes externas
Usando o SQL padrão, você pode acessar as tabelas do BigQuery diretamente do Google Bigtable, Google Cloud Storage, Google Drive e Planilhas Google.
Ou seja, em vez de carregar a tabela inteira no BigQuery, você pode excluir os dados com uma única consulta, selecionar os parâmetros necessários e enviá-los para o armazenamento em nuvem.
Mais funções do usuário (UDF)
Se você precisar usar uma fórmula que não está documentada, as Funções Definidas pelo Usuário (UDF) o ajudarão. Em nossa prática, isso raramente acontece, pois a documentação do SQL padrão abrange quase todas as tarefas de análise digital.
No SQL padrão, as funções definidas pelo usuário podem ser escritas em SQL ou JavaScript; O SQL legado suporta apenas JavaScript. Os argumentos dessas funções são colunas, e os valores que elas assumem são o resultado da manipulação de colunas. No SQL padrão, as funções podem ser escritas na mesma janela das consultas.
Mais condições de JOIN
No Legacy SQL, as condições JOIN podem ser baseadas em igualdade ou nomes de coluna. Além dessas opções, o dialeto SQL padrão suporta JOIN por desigualdade e por expressão arbitrária.
Por exemplo, para identificar parceiros de CPA injustos, podemos selecionar sessões nas quais a origem foi substituída em até 60 segundos após a transação. Para fazer isso no SQL padrão, podemos adicionar uma desigualdade à condição JOIN:
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime
#standardSQL SELECT * FROM ( SELECT traff.clientId AS clientId, traff.page_path AS pagePath, traff.traffic_source AS startSource, traff.traffic_medium AS startMedium, traff.time AS startTime, aff.evAction AS evAction, aff.evSource AS finishSource, aff.evMedium AS finishMedium, aff.evCampaign AS finishCampaign, aff.time AS finishTime, aff.isTransaction AS isTransaction, aff.pagePath AS link, traff.time-aff.time AS diff FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, trafficSource.source AS traffic_source, trafficSource.medium AS traffic_medium, trafficSource.campaign AS traffic_campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST (hits) AS h WHERE trafficSource.medium != 'cpa' ) AS traff JOIN ( SELECT total.date date, total.time time, total.clientId AS clientId, total.eventAction AS evAction, total.source AS evSource, total.medium AS evMedium, total.campaign AS evCampaign, tr.eventAction AS isTransaction, total.page_path AS pagePath FROM ( SELECT fullVisitorID AS clientId, h.page.pagePath AS page_path, h.eventInfo.eventAction AS eventAction, trafficSource.source AS source, trafficSource.medium AS medium, trafficSource.campaign AS campaign, date, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE trafficSource.medium ='cpa' ) AS total LEFT JOIN ( SELECT fullVisitorID AS clientId, date, h.eventInfo.eventAction AS eventAction, h.page.pagePath pagePath, SAFE_CAST(visitStartTime+h.time/1000 AS INT64) AS time FROM `demoproject.google_analytics_sample.ga_sessions_20190301`, UNNEST(hits) AS h WHERE h.eventInfo.eventAction = 'typ_page' AND h.type = 'EVENT' GROUP BY 1, 2, 3, 4, 5 ) AS tr ON total.clientId=tr.clientId AND total.date=tr.date AND tr.time>total.time -- JOIN tables by inequality. Pass the additional WHERE clause that was needed in Legacy SQL WHERE tr.eventAction = 'typ_page' ) AS aff ON traff.clientId = aff.clientId ) WHERE diff> -60 AND diff<0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 ORDER BY clientId, finishTime A única limitação do SQL padrão em relação ao JOIN é que ele não permite semi-junção com subconsultas da forma WHERE column IN (SELECT ...):
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESC
#legacySQL SELECT mother_age, COUNT(mother_age) total FROM [bigquery-public-data:samples.natality] WHERE -- such a construction cannot be used in Standard SQL state IN (SELECT state FROM (SELECT state, COUNT(state) total FROM [bigquery-public-data:samples.natality] GROUP BY state ORDER BY total DESC LIMIT 10)) AND mother_age > 50 GROUP BY mother_age ORDER BY mother_age DESCMenos chance de erros
Algumas funções no Legacy SQL retornam NULL se a condição estiver incorreta. Por exemplo, se a divisão por zero entrou em seus cálculos, a consulta será executada e as entradas NULL aparecerão nas linhas resultantes da tabela. Isso pode mascarar problemas na consulta ou nos dados.
A lógica do SQL padrão é mais direta. Se uma condição ou dados de entrada estiverem incorretos, a consulta gerará um erro, por exemplo, «divisão por zero», para que você possa corrigir a consulta rapidamente. As seguintes verificações estão incorporadas no SQL padrão:
- Valores válidos para +, -, ×, SUM, AVG, STDEV
- Divisão por zero
As solicitações são executadas mais rapidamente
As consultas JOIN escritas em SQL padrão são mais rápidas do que aquelas escritas em Legacy SQL graças à filtragem preliminar dos dados de entrada. Primeiro, a consulta seleciona as linhas que correspondem às condições JOIN e as processa.
No futuro, o Google BigQuery trabalhará para melhorar a velocidade e o desempenho das consultas apenas para SQL padrão.
As tabelas podem ser editadas: inserir e excluir linhas, atualizar
As funções da linguagem de manipulação de dados (DML) estão disponíveis no SQL padrão. Isso significa que você pode atualizar tabelas e adicionar ou remover linhas delas por meio da mesma janela em que escreve as consultas. Por exemplo, usando DML, você pode combinar dados de duas tabelas em uma:
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)
#standardSQL MERGE dataset.Inventory AS T USING dataset.NewArrivals AS S ON T.ProductID = S.ProductID WHEN MATCHED THEN UPDATE SET quantity = T.quantity + S.quantity WHEN NOT MATCHED THEN INSERT (ProductID, quantity) VALUES (ProductID, quantity)O código é mais fácil de ler e editar
Com o SQL padrão, consultas complexas podem ser iniciadas não apenas com SELECT, mas também com WITH, tornando o código mais fácil de ler, comentar e entender. Isso também significa que é mais fácil prevenir seus próprios erros e corrigir os erros dos outros.
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2
#standardSQL WITH total_1 AS ( -- the first subquery in which the intermediate indicator will be calculated SELECT id, metric1, SUM(metric2) AS total_sum1 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ), total_2 AS ( -- the second subquery SELECT id, metric1, SUM(metric2) AS total_sum2 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric1 ), total_3 AS ( -- the third subquery SELECT id, metric, SUM(metric2) AS total_sum3 FROM `project_name.dataset_name.owoxbi_sessions_YYYYMMDD` GROUP BY id, metric ) SELECT *, ROUND(100*( total_2.total_sum2 - total_3.total_sum3) / total_3.total_sum3, 3) AS difference -- get the difference index: subtract the value of the second subquery from the value of the third; divide by the value of the third FROM total_1 ORDER BY 1, 2 É conveniente trabalhar com o operador WITH se você tiver cálculos feitos em várias etapas. Primeiro, você pode coletar métricas intermediárias em subconsultas e, em seguida, fazer os cálculos finais.
O Google Cloud Platform (GCP), que inclui o BigQuery, é uma plataforma de ciclo completo para trabalhar com big data, desde a organização de um data warehouse ou nuvem de dados até a execução de experimentos científicos e análises preditivas e prescritivas. Com a introdução do SQL padrão, o BigQuery está expandindo seu público. Trabalhar com o GCP está se tornando mais interessante para analistas de marketing, analistas de produtos, cientistas de dados e equipes de outros especialistas.
Recursos do SQL padrão e exemplos de casos de uso
Na OWOX BI, geralmente trabalhamos com tabelas compiladas usando a exportação padrão do Google Analytics 360 para o Google BigQuery ou o OWOX BI Pipeline. Nos exemplos abaixo, veremos as especificidades das consultas SQL para esses dados.
Se você ainda não estiver coletando dados do seu site no BigQuery, experimente fazê-lo gratuitamente com a versão de avaliação do OWOX BI.
1. Selecione dados para um intervalo de tempo
No Google BigQuery, os dados de comportamento do usuário do seu site são armazenados em tabelas curinga (tabelas com um asterisco); uma tabela separada é formada para cada dia. Essas tabelas têm o mesmo nome: apenas o sufixo é diferente. O sufixo é a data no formato AAAAMMDD. Por exemplo, a tabela owoxbi_sessions_20190301 contém dados sobre sessões de 1º de março de 2019.
Podemos nos referir diretamente a um grupo dessas tabelas em uma solicitação para obter dados, por exemplo, de 1º de fevereiro a 28 de fevereiro de 2019. Para fazer isso, precisamos substituir YYYYMMDD por um * em FROM e em WHERE, precisamos especificar os sufixos da tabela para o início e o fim do intervalo de tempo:
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �'
#standardSQL SELECT sessionId, FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN �' AND �' As datas específicas para as quais queremos coletar dados nem sempre são conhecidas por nós. Por exemplo, toda semana podemos precisar analisar dados dos últimos três meses. Para fazer isso, podemos usar a função FORMAT_DATE:
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
#standardSQL SELECT <enumerate field names> FROM `project_name.dataset_name.owoxbi_sessions_*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTHS)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) Após BETWEEN, gravamos o sufixo da primeira tabela. A frase CURRENT_DATE(), INTERVAL 3 MONTHS significa «selecionar dados dos últimos 3 meses a partir da data atual.» O segundo sufixo da tabela é formatado após AND. É necessário marcar o fim do intervalo como ontem: CURRENT_DATE(), INTERVAL 1 DAY.
2. Recupere os parâmetros e indicadores do usuário
Os parâmetros e métricas do usuário nas tabelas de exportação do Google Analytics são gravados na tabela de hits aninhados e nas subtabelas customDimensions e customMetrics. Todas as dimensões personalizadas são registradas em duas colunas: uma para o número de parâmetros coletados no site, a segunda para seus valores. Veja como são todos os parâmetros transmitidos com um hit:
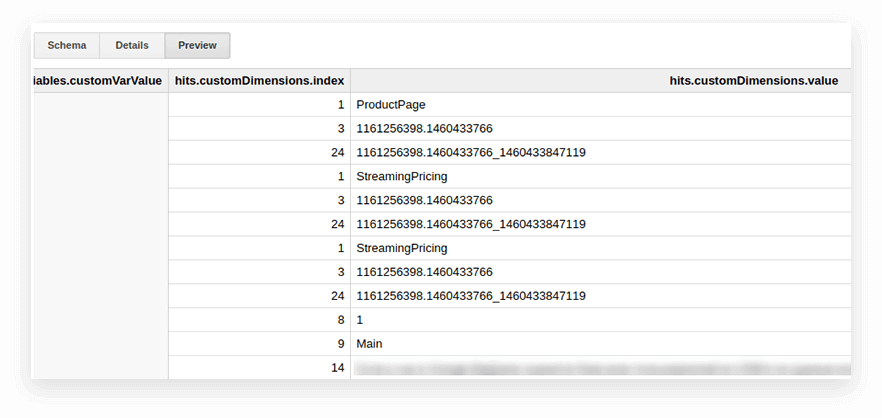
Para descompactá-los e escrever os parâmetros necessários em colunas separadas, usamos a seguinte consulta SQL:
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1
-- Custom Dimensions (in the line below index - the number of the user variable, which is set in the Google Analytics interface; dimension1 is the name of the custom parameter, which you can change as you like. For each subsequent parameter, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS dimension1, -- Custom Metrics: the index below is the number of the user metric specified in the Google Analytics interface; metric1 is the name of the metric, which you can change as you like. For each of the following metrics, you need to write the same line: (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 Veja como está na solicitação:
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column name1>, <column_name2>, -- list column names (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customDimensions)) AS page_type, (SELECT MAX(IF(index=2, value, NULL)) FROM UNNEST(hits.customDimensions)) AS visitor_type, -- produce the necessary custom dimensions (SELECT MAX(IF(index=1, value, NULL)) FROM UNNEST(hits.customMetrics)) AS metric1 -- produce the necessary custom metrics <column_name3> -- if you need more columns, continue to list FROM `project_name.dataset_name.owoxbi_sessions_20190201` Na captura de tela abaixo, selecionamos os parâmetros 1 e 2 dos dados de demonstração do Google Analytics 360 no Google BigQuery e os chamamos de page_type e client_id. Cada parâmetro é registrado em uma coluna separada:

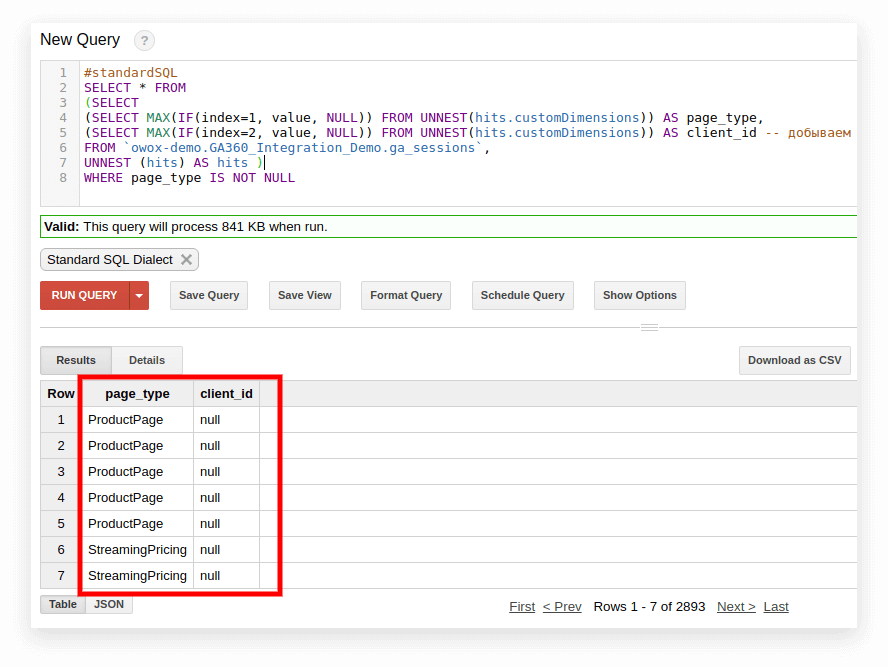
3. Calcule o número de sessões por origem de tráfego, canal, campanha, cidade e categoria de dispositivo
Esses cálculos são úteis se você planeja visualizar dados no Google Data Studio e filtrar por cidade e categoria de dispositivo. Isso é fácil de fazer com a função de janela COUNT:
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT <column_name 1>, -- choose any columns COUNT (DISTINCT sessionId) AS total_sessions, -- summarize the session IDs to find the total number of sessions COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS part_sessions -- summarize the number of sessions by campaign, channel, traffic source, city, and device category FROM `project_name.dataset_name.owoxbi_sessions_20190201`4. Combine os mesmos dados de várias tabelas
Suponha que você colete dados sobre pedidos concluídos em várias tabelas do BigQuery: uma coleta todos os pedidos da loja A, a outra coleta os pedidos da loja B. Você quer combiná-los em uma tabela com estas colunas:
- client_id — um número que identifica um comprador único
- transaction_created — hora de criação do pedido no formato TIMESTAMP
- transaction_id — número do pedido
- is_approved — se o pedido foi confirmado
- transaction_revenue — valor do pedido
Em nosso exemplo, os pedidos de 1º de janeiro de 2018 até ontem devem estar na tabela. Para fazer isso, selecione as colunas apropriadas de cada grupo de tabelas, atribua a elas o mesmo nome e combine os resultados com UNION ALL:
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC
#standardSQL SELECT cid AS client_id, order_time AS transaction_created, order_status AS is_approved, order_number AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) UNION ALL SELECT userId AS client_id, created_timestamp AS transaction_created, operator_mark AS is_approved, transactionId AS transaction_id FROM `project_name.dataset_name.table1_*` WHERE ( _TABLE_SUFFIX BETWEEN �' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) ) ORDER BY transaction_created DESC5. Crie um dicionário de grupos de canais de tráfego
Quando os dados entram no Google Analytics, o sistema determina automaticamente o grupo ao qual uma determinada transição pertence: pesquisa direta, orgânica, pesquisa paga e assim por diante. Para identificar um grupo de canais, o Google Analytics analisa as tags UTM de transições, ou seja, utm_source e utm_medium. Você pode ler mais sobre grupos de canais e regras de definição na Ajuda do Google Analytics.
Se os clientes OWOX BI quiserem atribuir seus próprios nomes a grupos de canais, criamos um dicionário, cuja transição pertence a um canal específico. Para fazer isso, usamos o operador CASE condicional e a função REGEXP_CONTAINS. Esta função seleciona os valores em que ocorre a expressão regular especificada.
Recomendamos pegar nomes de sua lista de fontes no Google Analytics. Veja um exemplo de como adicionar essas condições ao corpo da solicitação:
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201`
#standardSQL SELECT CASE WHEN (REGEXP_CONTAINS (source, 'yandex') AND medium = 'referral' THEN 'Organic Search' WHEN (REGEXP_CONTAINS (source, 'yandex.market')) AND medium = 'referral' THEN 'Referral' WHEN (REGEXP_CONTAINS (source, '^(go.mail.ru|google.com)$') AND medium = 'referral') THEN 'Organic Search' WHEN medium = 'organic' THEN 'Organic Search' WHEN (medium = 'cpc') THEN 'Paid Search' WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' WHEN medium = 'social' THEN 'Social' WHEN source = '(direct)' THEN 'Direct' WHEN REGEXP_CONTAINS (medium, 'banner|cpm') THEN 'Display' ELSE 'Other' END channel_group -- the name of the column in which the channel groups are written FROM `project_name.dataset_name.owoxbi_sessions_20190201` Como mudar para o SQL padrão
Se você ainda não mudou para o SQL padrão, pode fazê-lo a qualquer momento. O principal é evitar misturar dialetos em uma solicitação.
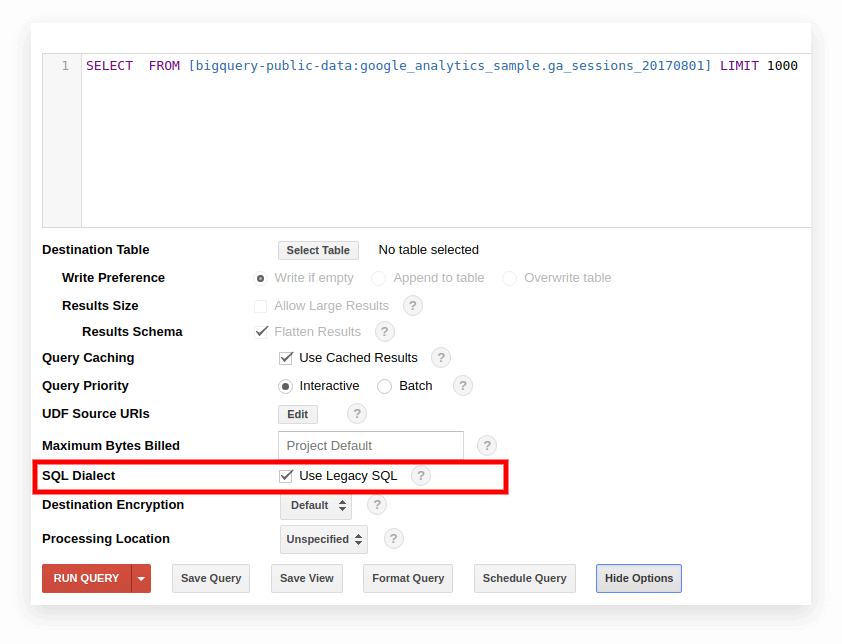
Opção 1. Alterne na interface do Google BigQuery
O SQL legado é usado por padrão na interface antiga do BigQuery. Para alternar entre dialetos, clique em Mostrar opções no campo de entrada da consulta e desmarque a caixa Usar SQL legado ao lado de Dialeto SQL.
A nova interface usa o SQL padrão por padrão. Aqui, você precisa ir para a guia Mais para alternar dialetos:
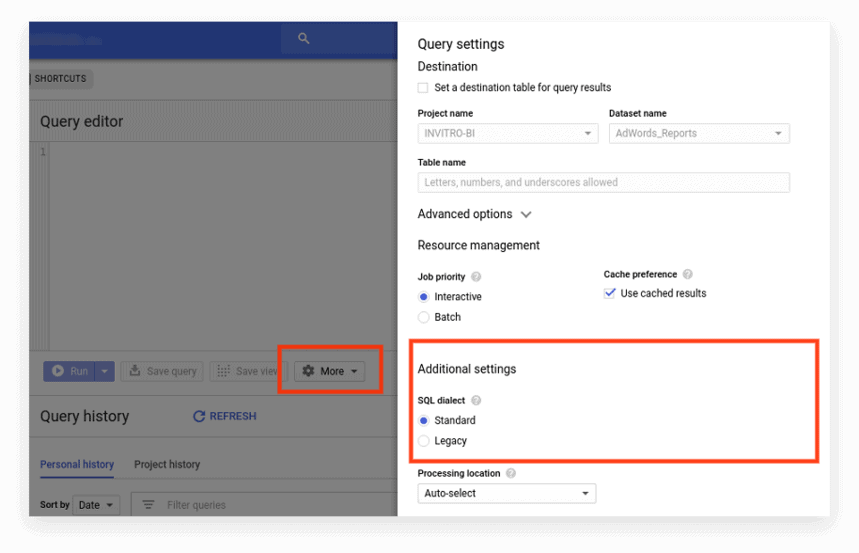
Opção 2. Escreva o prefixo no início da solicitação
Se você não marcou as configurações de solicitação, pode começar com o prefixo desejado (#standardSQL ou #legacySQL):
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10;
#standardSQL SELECT weight_pounds, state, year, gestation_weeks FROM `bigquery-public-data.samples.natality` ORDER BY weight_pounds DESC LIMIT 10; Nesse caso, o Google BigQuery ignorará as configurações na interface e executará a consulta usando o dialeto especificado no prefixo.
Se você tiver visualizações ou consultas salvas que são iniciadas em uma programação usando o Apps Script, não se esqueça de alterar o valor de useLegacySql para false no script:
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }
var job = { configuration: { query: { query: 'INSERT INTO MyDataSet.MyFooBarTable (Id, Foo, Date) VALUES (1, \'bar\', current_Date);', useLegacySql: false }Opção 3. Transição para SQL padrão para visualizações
Se você trabalha com o Google BigQuery não com tabelas, mas com visualizações, essas visualizações não podem ser acessadas no dialeto SQL padrão. Ou seja, se sua apresentação for escrita em Legacy SQL, você não poderá escrever solicitações para ela em Standard SQL.
Para transferir uma visualização para o SQL padrão, você precisa reescrever manualmente a consulta pela qual ela foi criada. A maneira mais fácil de fazer isso é por meio da interface do BigQuery.
1. Abra a visualização:
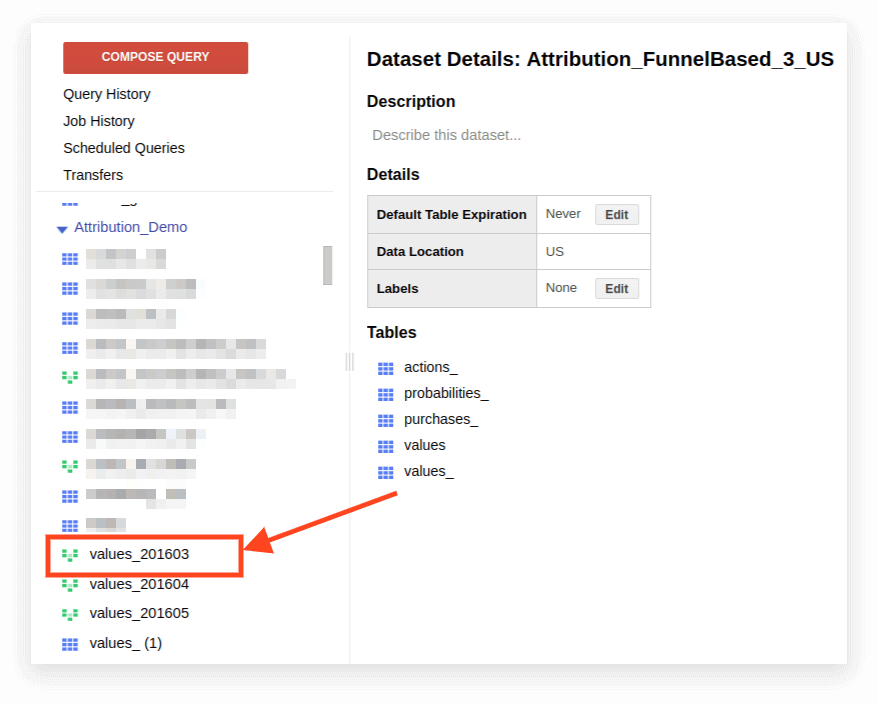
2. Clique em Detalhes. O texto da consulta deve abrir e o botão Editar consulta aparecerá abaixo:
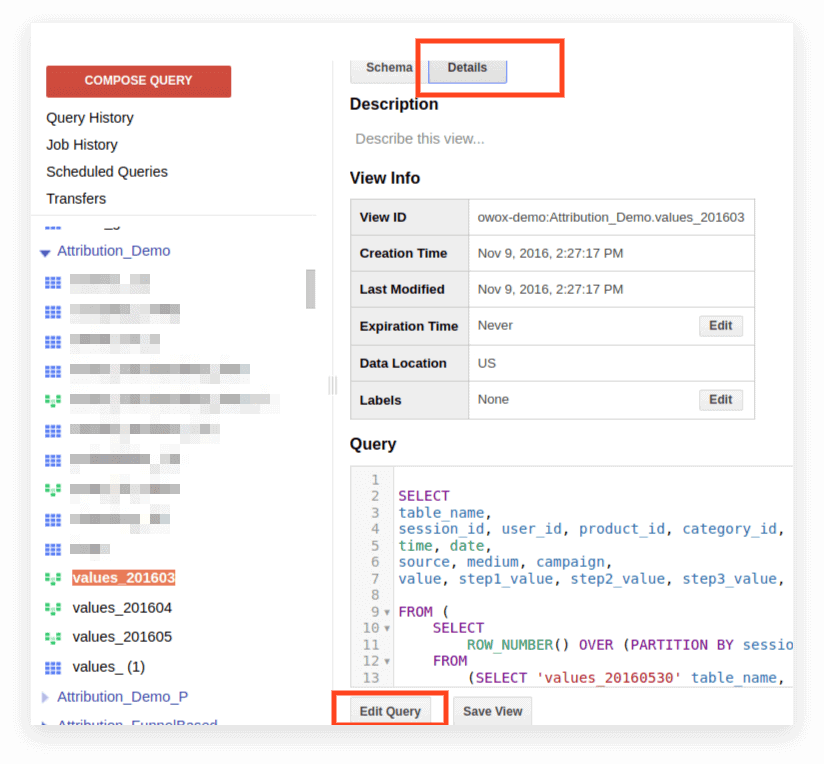
Agora você pode editar a solicitação de acordo com as regras do SQL padrão.
Se você planeja continuar usando a solicitação como uma apresentação, clique em Salvar exibição após terminar de editar.
Compatibilidade, recursos de sintaxe, operadores, funções
Compatibilidade
Graças à implementação do SQL padrão, você pode acessar diretamente os dados armazenados em outros serviços diretamente do BigQuery:
- Arquivos de registro do Google Cloud Storage
- Registros transacionais no Google Bigtable
- Dados de outras fontes
Isso permite que você use os produtos do Google Cloud Platform para qualquer tarefa analítica, incluindo análises preditivas e prescritivas com base em algoritmos de aprendizado de máquina.
Sintaxe da consulta
A estrutura de consulta no dialeto padrão é quase a mesma do Legado:
Os nomes das tabelas e da visualização são separados por um ponto (ponto final), e toda a consulta é colocada entre acentos graves: `project_name.data_name_name.table_name``bigquery-public-data.samples.natality`
A sintaxe completa da consulta, com explicações sobre o que pode ser incluído em cada operador, é compilada como um esquema na documentação do BigQuery.
Recursos da sintaxe SQL padrão:
- São necessárias vírgulas para listar campos na instrução SELECT.
- Se você usar o operador UNNEST após FROM , uma vírgula ou JOIN será colocada antes de UNNEST.
- Você não pode colocar uma vírgula antes de FROM.
- Uma vírgula entre duas consultas é igual a um CROSS JOIN, então tenha cuidado com isso.
- JOIN pode ser feito não apenas por coluna ou igualdade, mas por expressões arbitrárias e desigualdade.
- É possível escrever subconsultas complexas em qualquer parte da expressão SQL (em SELECT, FROM, WHERE, etc.). Na prática, ainda não é possível usar expressões como WHERE column_name IN (SELECT ...) como em outros bancos de dados.
Operadores
No SQL padrão, os operadores definem o tipo de dados. Por exemplo, um array é sempre escrito entre colchetes []. Os operadores são usados para comparação, correspondendo à expressão lógica (NOT, OR, AND) e em cálculos aritméticos.
Funções
O SQL padrão suporta mais recursos do que o Legacy: agregação tradicional (soma, número, mínimo, máximo); funções matemáticas, de string e estatísticas; e formatos raros como HyperLogLog ++.
No dialeto padrão, há mais funções para trabalhar com datas e TIMESTAMP. Uma lista completa de recursos é fornecida na documentação do Google. As funções mais usadas são para trabalhar com datas, strings, agregação e janela.
1. Funções de agregação
COUNT (DISTINCT column_name) conta o número de valores exclusivos em uma coluna. Por exemplo, digamos que precisamos contar o número de sessões de dispositivos móveis em 1º de março de 2019. Como um número de sessão pode ser repetido em linhas diferentes, queremos contar apenas os valores exclusivos de número de sessão:
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT COUNT (DISTINCT sessionId) AS sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` WHERE device.deviceCategory = 'mobile' SUM (column_name) — a soma dos valores na coluna
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile'
#standardSQL SELECT SUM (hits.transaction.transactionRevenue) AS revenue FROM `project_name.dataset_name.owoxbi_sessions_20190301`, UNNEST (hits) AS hits -- unpacking the nested field hits WHERE device.deviceCategory = 'mobile' MIN (nome_coluna) | MAX (column_name) — o valor mínimo e máximo na coluna. Essas funções são convenientes para verificar a distribuição de dados em uma tabela.
2. Funções de janela (analíticas)
As funções analíticas consideram valores não para a tabela inteira, mas para uma determinada janela — um conjunto de linhas que você está interessado. Ou seja, você pode definir segmentos dentro de uma tabela. Por exemplo, você pode calcular SUM (receita) não para todas as linhas, mas para cidades, categorias de dispositivos e assim por diante. Você pode ativar as funções analíticas SUM, COUNT e AVG, bem como outras funções de agregação, adicionando a condição OVER (PARTITION BY column_name) a elas.
Por exemplo, você precisa contar o número de sessões por origem de tráfego, canal, campanha, cidade e categoria de dispositivo. Neste caso, podemos usar a seguinte expressão:
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t
SELECT date, geoNetwork.city, t.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign, COUNT(DISTINCT sessionId) OVER(PARTITION BY date, geoNetwork.city, session.device.deviceCategory, trafficSource.source, trafficSource.medium, trafficSource.campaign) AS segmented_sessions FROM `project_name.dataset_name.owoxbi_sessions_20190301` t OVER determina a janela para a qual os cálculos serão feitos. PARTITION BY indica quais linhas devem ser agrupadas para cálculo. Em algumas funções é necessário especificar a ordem de agrupamento com ORDER BY.
Para obter uma lista completa de funções de janela, consulte a documentação do BigQuery.
3. Funções de string
Eles são úteis quando você precisa alterar o texto, formatar o texto em uma linha ou colar os valores das colunas. Por exemplo, as funções de string são ótimas se você quiser gerar um identificador de sessão exclusivo dos dados de exportação padrão do Google Analytics 360. Vamos considerar as funções de string mais populares.
SUBSTR corta parte da string. Na solicitação, esta função é escrita como SUBSTR (string_name, 0.4). O primeiro número indica quantos caracteres devem ser ignorados desde o início da linha e o segundo número indica quantos dígitos devem ser cortados. Por exemplo, digamos que você tenha uma coluna de data que contém datas no formato STRING. Nesse caso, as datas ficam assim: 20190103. Se você deseja extrair um ano dessa linha, o SUBSTR o ajudará:
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT SUBSTR(date,0,4) AS year FROM `project_name.dataset_name.owoxbi_sessions_20190301` CONCAT (column_name, etc.) cola valores. Vamos usar a coluna de data do exemplo anterior. Suponha que você queira que todas as datas sejam registradas assim: 2019-03-01. Para converter datas de seu formato atual para este formato, duas funções de string podem ser usadas: primeiro, corte as partes necessárias da string com SUBSTR, depois cole-as através do hífen:
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CONCAT(SUBSTR(date,0,4),"-",SUBSTR(date,5,2),"-",SUBSTR(date,7,2)) AS date FROM `project_name.dataset_name.owoxbi_sessions_20190301` REGEXP_CONTAINS retorna os valores das colunas nas quais ocorre a expressão regular:
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT CASE WHEN REGEXP_CONTAINS (medium, '^(sending|email|mail)$') THEN 'Email' WHEN REGEXP_CONTAINS (source, '(mail|email|Mail)') THEN 'Email' WHEN REGEXP_CONTAINS (medium, '^(cpa)$') THEN 'Affiliate' ELSE 'Other' END Channel_groups FROM `project_name.dataset_name.owoxbi_sessions_20190301` Esta função pode ser usada em SELECT e WHERE. Por exemplo, em WHERE, você pode selecionar páginas específicas com ele:
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order')
WHERE REGEXP_CONTAINS(hits.page.pagePath, 'land[123]/|/product-order') 4. Funções de data
Muitas vezes, as datas nas tabelas são registradas no formato STRING. Se você planeja visualizar os resultados no Google Data Studio, as datas na tabela precisam ser convertidas para o formato DATE usando a função PARSE_DATE.
PARSE_DATE converte uma STRING do formato 1900-01-01 para o formato DATE.
Se as datas em suas tabelas parecerem diferentes (por exemplo, 19000101 ou 01_01_1900), você deve primeiro convertê-las para o formato especificado.
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT PARSE_DATE('%Y-%m-%d', date) AS date_new FROM `project_name.dataset_name.owoxbi_sessions_20190301` DATE_DIFF calcula quanto tempo se passou entre duas datas em dias, semanas, meses ou anos. É útil se você precisar determinar o intervalo entre o momento em que um usuário viu a publicidade e fez um pedido. Veja como a função fica em uma solicitação:
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301`
#standardSQL SELECT DATE_DIFF( PARSE_DATE('%Y%m%d', date1), PARSE_DATE('%Y%m%d', date2), DAY ) days -- convert the date1 and date2 lines to the DATE format; choose units to show the difference (DAY, WEEK, MONTH, etc.) FROM `project_name.dataset_name.owoxbi_sessions_20190301` Se você quiser saber mais sobre as funções listadas, leia BigQuery Google Features — A Detailed Review.
Consultas SQL para relatórios de marketing
O dialeto SQL padrão permite que as empresas extraiam o máximo de informações de dados com segmentação profunda, auditorias técnicas, análise de KPI de marketing e identificação de contratados injustos em redes CPA. Veja alguns exemplos de problemas de negócios nos quais as consultas SQL nos dados coletados no Google BigQuery ajudarão você.
1. Análise de ROPO: avaliar a contribuição das campanhas online para as vendas offline. Para realizar a análise de ROPO, você precisa combinar dados sobre o comportamento do usuário online com dados do seu CRM, sistema de rastreamento de chamadas e aplicativo móvel.
Se houver uma chave em uma e na segunda base — um parâmetro comum que é exclusivo para cada usuário (por exemplo, ID do usuário) — você poderá acompanhar:
quais usuários visitaram o site antes de comprar mercadorias na loja
como os usuários se comportaram no site
quanto tempo os usuários levaram para tomar uma decisão de compra
quais campanhas tiveram o maior aumento nas compras offline.
2. Segmente os clientes por qualquer combinação de parâmetros, desde o comportamento no site (páginas visitadas, produtos visualizados, número de visitas ao site antes de comprar) até o número do cartão fidelidade e itens comprados.
3. Descubra quais parceiros CPA estão trabalhando de má fé e substituindo as tags UTM.
4. Analise o progresso dos usuários pelo funil de vendas.
Preparamos uma seleção de consultas no dialeto SQL padrão. Se você já coleta dados de seu site, de fontes de publicidade e de seu sistema de CRM no Google BigQuery, pode usar esses modelos para resolver seus problemas de negócios. Basta substituir o nome do projeto, o conjunto de dados e a tabela no BigQuery pelos seus. Na coleção, você receberá 11 consultas SQL.
Para dados coletados usando a exportação padrão do Google Analytics 360 para o Google BigQuery:
- Ações do usuário no contexto de quaisquer parâmetros
- Estatísticas sobre as principais ações do usuário
- Usuários que visualizaram páginas de produtos específicos
- Ações de usuários que compraram um determinado produto
- Configure o funil com todas as etapas necessárias
- Eficácia do site de busca interno
Para dados coletados no Google BigQuery usando OWOX BI:
- Consumo atribuído por fonte e canal
- Custo médio de atrair um visitante por cidade
- ROAS para lucro bruto por fonte e canal
- Número de pedidos no CRM por forma de pagamento e forma de entrega
- Tempo médio de entrega por cidade
Se você tiver dúvidas sobre como consultar dados do Google BigQuery para as quais não encontrou respostas neste artigo, pergunte nos comentários. Tentaremos ajudá-lo.