
Przetwarzanie dokumentów przy użyciu ustrukturyzowanych par klucz-wartość
Opublikowany: 2022-03-31Dlaczego pary klucz-wartość w tym systemie przetwarzania dokumentów?
Napisanie tego posta przypomniało mi post z 2007 roku, który napisałem o wyszukiwaniu lokalnym i danych strukturalnych, w którym pary klucz-wartość były ważnym aspektem tego patentu z 2007 roku. Post był:
Informacje strukturalne w wyszukiwarce lokalnej Google.
Wydało mi się interesujące, gdy Google pisał o wstawianiu par klucz-wartość w systemie przetwarzania dokumentów, takim jak ten tutaj, z podejściem uczenia maszynowego w sercu, przechodząc do technicznego SEO.
Wykorzystanie par klucz-wartość jest nadal ważne po 15 latach.
Przetwarzanie dokumentów w Google
Zrozumienie przetwarzania dokumentów (np. faktur, odcinków wypłat, paragonów sprzedaży itp.) jest kluczową potrzebą biznesową. Duża część (np. 90% lub więcej) danych przedsiębiorstwa jest przechowywana i reprezentowana w nieustrukturyzowanych dokumentach. Wyodrębnianie uporządkowanych danych z rekordów może być kosztowne, czasochłonne i podatne na błędy.
Ten patent opisuje system analizujący przetwarzanie dokumentów i metodę zaimplementowaną jako programy komputerowe na komputerach w lokalizacjach, które konwertują nieustrukturyzowane dokumenty na ustrukturyzowane pary klucz-wartość.
System parsowania zostaje skonfigurowany do przetwarzania dokumentów w celu identyfikacji „kluczowych” danych tekstowych i odpowiadających im danych tekstowych „wartości” w dokumencie. Klucz definiuje etykietę, która charakteryzuje (tzn. opisuje) odpowiednią wartość.
Na przykład klucz „Data” może odpowiadać wartości „2-23-2019”.
Istnieje metoda wykonywana przez urządzenie do przetwarzania danych, która dostarcza obraz dokumentu do modelu wykrywania, w którym: model wykrywania jest konfigurowany do przetwarzania obrazu przez wartości wielu parametrów modelu wykrywania w celu wygenerowania danych wyjściowych definiujących ramki ograniczające wygenerowane dla pomysłu.
Przewiduje się, że każda ramka ograniczająca wygenerowana dla obrazu zawiera parę klucz-wartość zawierającą krytyczne dane tekstowe i dane tekstowe wartości, przy czym niezbędne dane tekstowe definiują etykietę, która charakteryzuje dane wartości tekstowej.
Każda z ramek granicznych wygenerowanych dla obrazu: identyfikuje informacje tekstowe zawarte w ramce granicznej przy użyciu techniki optycznego rozpoznawania znaków; określanie, czy dane tekstowe przechowywane przez ramkę ograniczającą definiują parę klucz-wartość; oraz w odpowiedzi na ustalenie, że dane tekstowe zawarte w ramce ograniczającej reprezentują parę klucz-wartość, dostarczając parę klucz-wartość do użycia w charakteryzowaniu dokumentu.
Model detekcji to model sieci neuronowej.
Model sieci neuronowej obejmuje splotową sieć neuronową.
Model sieci neuronowej jest szkolony na zestawie przykładów szkoleniowych. Każdy przykład treningowy zawiera wejście treningowe i wyjście docelowe; wejście treningowe zawiera obraz treningowy dokumentu treningowego. Docelowe dane wyjściowe zawierają dane definiujące ramki ograniczające w obrazie treningowym, obejmujące odpowiednią parę klucz-wartość.
Dokumentem jest faktura.

Dostarczenie obrazu dokumentu do modelu wykrywania obejmuje: identyfikację określonej klasy papieru; i dostarczenie idei dokumentu do modelu wykrywania, który jest szkolony do przetwarzania kopii określonego typu.
- Ustalenie, czy dane tekstowe zawarte w ramce ograniczającej definiują parę klucz-wartość, obejmuje:
- Podejmowanie decyzji, że informacje tekstowe posiadane przez ramkę ograniczającą obejmują klucz z wcześniej określonego zestawu prawidłowych kluczy;
- Znalezienie typu części danych tekstowych przechowywanych przez obwiednię, która nie ma klucza; określenie lokalizacji odpowiednich odmian dla wartości odpowiadających kluczowi
- Wybranie, że styl części danych tekstowych ujętej w ramkę ograniczającą, która nie zawiera klucza, zostanie uwzględniony w zestawie prawidłowych typów dla wartości odpowiadających kluczowi.
- Uczenie się, że zbiór prawidłowych typów dla wartości odpowiadających kluczowi obejmuje: mapowanie klucza do kolekcji odpowiednich rodzajów dla wartości odpowiadających kluczowi przy użyciu z góry określonego mapowania.
Zestaw ważnych kluczy i mapowanie kluczy do odpowiednich lokalizacji odpowiednich typów dla wartości odpowiadających kluczom dostarczonych przez użytkownika.
Ramki ograniczające mają kształt prostokąta.
Sposób obejmuje ponadto: odbieranie dokumentu od użytkownika; oraz przekształcenie papieru w obraz, przy czym rysunek przedstawia dokument.
Metoda wykonywana przez system przetwarzania dokumentów, metoda obejmująca:
- Dostarczanie obrazu dokumentu do modelu wykrywania skonfigurowanego do przetwarzania obrazu w celu zidentyfikowania w ramkach granicznych obrazu, które przewidują, że zawierają parę klucz-wartość zawierającą krytyczne dane tekstowe i dane tekstowe wartości, przy czym klucz definiuje etykietę, która charakteryzuje odpowiadającą wartość do klucza; dla każdego z obwiedni wygenerowanych dla obrazu,
- Identyfikowanie danych tekstowych zawartych w ramce ograniczającej przy użyciu techniki optycznego rozpoznawania znaków i określanie, czy informacje tekstowe przechowywane przez ramkę ograniczającą definiują parę klucz-wartość
- Wyprowadzenie zespołu klucz-wartość do wykorzystania przy charakterystyce dokumentu.
Model wykrywania to model uczenia maszynowego z parametrami, które można trenować w zestawie danych szkoleniowych.
Model uczenia maszynowego obejmuje model sieci neuronowej, w szczególności splotowej sieci neuronowej.
Model uczenia maszynowego jest szkolony na zestawie przykładów szkoleniowych, a każdy przykład szkolenia ma dane wejściowe szkolenia i dane wyjściowe.
Wejście szkoleniowe zawiera obraz szkoleniowy dokumentu szkoleniowego. Docelowe dane wyjściowe obejmują ramki ograniczające definiujące dane w obrazie szkoleniowym, z których każdy zawiera odpowiednią parę klucz-wartość.
Dokumentem jest faktura.
Dostarczenie obrazu dokumentu do modelu wykrywania obejmuje: identyfikację określonej klasy papieru; i dostarczenie idei dokumentu do modelu wykrywania, który jest szkolony do przetwarzania dokumentów określonego typu.
Czy to para klucz-wartość?
Ustalenie, czy dane tekstowe zawarte w ramce ograniczającej definiują parę klucz-wartość oznacza:
- Podejmowanie decyzji, że informacje tekstowe posiadane przez ramkę ograniczającą zawierają klucz z wcześniej określonego zestawu prawidłowych kluczy
- Znajdowanie typu części danych tekstowych przechowywanych przez obwiednię, która nie ma klucza
- Zanotowanie lokalizacji odpowiednich odmian dla wartości odpowiadających kluczowi
- Wybranie, że styl części danych tekstowych ujętej w ramkę ograniczającą, która nie zawiera klucza, zostanie uwzględniony w zestawie prawidłowych typów dla wartości odpowiadających kluczowi.
Identyfikowanie zestawu prawidłowych typów dla wartości odpowiadających kluczowi obejmuje: mapowanie klucza do kolekcji właściwych rodzajów dla wartości odpowiadających kluczowi przy użyciu z góry określonego mapowania.
Zestaw ważnych kluczy i mapowanie kluczy do odpowiednich lokalizacji odpowiednich typów dla wartości odpowiadających kluczom dostarczonych przez użytkownika.
Ramki ograniczające mają kształt prostokąta.
Sposób obejmuje ponadto: odbieranie dokumentu od użytkownika; oraz przekształcenie papieru w obraz, przy czym rysunek przedstawia dokument.
Według innego aspektu istnieje system zawierający: komputery; oraz urządzenia pamięciowe połączone z komputerami, przy czym urządzenia pamięciowe przechowują instrukcje, które po wykonaniu przez komputery powodują, że komputery wykonują operacje obejmujące operacje opisanego wcześniej sposobu.
Zalety tego podejścia do przetwarzania dokumentów
System opisany w tej specyfikacji może zostać wykorzystany do konwersji dużej liczby nieustrukturyzowanych dokumentów na ustrukturyzowane pary klucz-wartość. W ten sposób system eliminuje potrzebę wyodrębniania ustrukturyzowanych danych z nieustrukturyzowanych dokumentów, co może być kosztowne, czasochłonne i podatne na błędy.
System opisany w tej specyfikacji może identyfikować pary klucz-wartość w dokumentach o wysokim poziomie dokładności (np. dla niektórych typów dokumentów z dokładnością większą niż 99%). Dzięki temu system może nadawać się do wdrożenia w aplikacjach (np. przetwarzających dokumenty finansowe), które wymagają wysokiego poziomu dokładności.
System opisany w tej specyfikacji może uogólniać lepiej niż niektóre konwencjonalne systemy, tj. ma ulepszone możliwości uogólniania w porównaniu z niektórymi tradycyjnymi sposobami.
W szczególności, wykorzystując model wykrywania uczący się maszynowo, wyszkolony do rozpoznawania sygnałów wizualnych, które rozróżniają pary klucz-wartość w dokumentach, system może zidentyfikować pary klucz-wartość w określonym stylu, strukturze lub treści dokumentów.
Identyfikacja par klucz-wartość w patencie na przetwarzanie dokumentów
Identyfikowanie par klucz-wartość w dokumentach
Wynalazcy: Yang Xu, Jiang Wang i Shengyang Dai
Pełnomocnik: Google LLC
Patent USA: 11 288 719
Przyznano: 29 marca 2022
Złożono: 27 lutego 2020 r.
Abstrakcyjny
Metody, systemy i aparatura, w tym programy komputerowe zakodowane na komputerowym nośniku pamięci, do konwertowania nieustrukturyzowanych dokumentów na ustrukturyzowane pary klucz-wartość.
W jednym aspekcie sposób obejmuje: dostarczenie obrazu dokumentu do modelu wykrywania, przy czym: model wykrywania zostaje skonfigurowany do przetwarzania obrazu w celu wygenerowania danych wyjściowych, które określają ramki ograniczające generowane dla obrazu; i przewiduje się, że każda ramka ograniczająca wygenerowana dla obrazu będzie zawierać parę klucz-wartość zawierającą kluczowe dane tekstowe i dane tekstowe wartości, przy czym kluczowe dane tekstowe definiują etykietę, która charakteryzuje dane tekstowe wartości, oraz dla każdego z ramek ograniczających wygenerowanych dla obraz: identyfikacja danych tekstowych zawartych w ramce ograniczającej przy użyciu techniki optycznego rozpoznawania znaków i określanie, czy dane tekstowe zawarte w ramce ograniczającej definiują parę klucz-wartość.
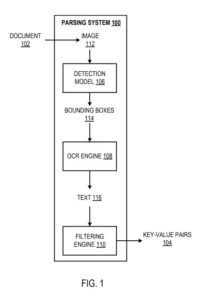
Przykładowy system analizowania
System parsowania jest przykładem metody zaimplementowanej jako programy komputerowe na komputerach w lokalizacjach, w których wdrażane są opisane poniżej systemy, komponenty i techniki.
System parsowania zostaje skonfigurowany do przetwarzania dokumentu (np. faktury, odcinka wypłaty lub paragonu sprzedaży) w celu identyfikacji par klucz-wartość w dokumencie. „Para klucz-wartość” odnosi się do klucza i odpowiadającej mu wartości, zazwyczaj danych tekstowych. Przez „dane tekstowe” należy rozumieć co najmniej: znaki alfabetyczne, cyfry i symbole specjalne. Jak opisano wcześniej, klucz definiuje etykietę, która charakteryzuje odpowiednią wartość.
System może odbierać dokument na różne sposoby.
Na przykład, system może odbierać papier jako przesłanie od zdalnego użytkownika systemu przez sieć transmisji danych (np. przy użyciu interfejsu programowania aplikacji (API) udostępnionego przez system). Dokument może zostać przedstawiony w dowolnym odpowiednim formacie danych nieustrukturyzowanych, na przykład jako dokument w formacie Portable Document Format (PDF) lub jako dokument graficzny (np. dokument Portable Network Graphics (PNG) lub Joint Photographic Experts Group (JPEG)).
Zidentyfikuj pary klucz-wartość w przetwarzaniu dokumentów
System wykorzystuje model wykrywania, mechanizm optycznego rozpoznawania znaków (OCR) oraz mechanizm filtrowania do identyfikacji par klucz-wartość w przetwarzaniu dokumentów.
Model wykrywania zostaje skonfigurowany do przetwarzania obrazu dokumentu w celu wygenerowania danych wyjściowych definiujących ramki ograniczające na obrazie. Przewiduje się, że każdy z nich będzie zawierał dane tekstowe reprezentujące odpowiednią parę klucz-wartość. Oznacza to, że oczekuje się, że każda ramka ograniczająca będzie zawierać informacje tekstowe, które określają:
(i) klucz, oraz
(ii) wartość odpowiadającą kluczowi. Na przykład ramka ograniczająca może zawierać dane tekstowe „Nazwisko: Jan Kowalski”, które określają klucz „Nazwisko” i odpowiadającą mu wartość „Jan Kowalski”. Model wykrywania może być skonfigurowany do generowania ramek ograniczających, które obejmują pojedynczą parę klucz-wartość (tj. zamiast wielu par klucz-wartość).
Obraz dokumentu to uporządkowany zbiór wartości liczbowych, które reprezentują wizualny wygląd papieru. Obraz może być czarno-białym obrazem dokumentu. W tym przykładzie obraz można opisać jako dwuwymiarową tablicę liczbowych wartości intensywności. Jako inny przykład, obraz może być kolorowym obrazem dokumentu. W tym przykładzie obraz może zostać przedstawiony jako obraz wielokanałowy. Każdy kanał odpowiada odpowiedniemu kolorowi (np. czerwonemu, zielonemu lub niebieskiemu) i jest definiowany jako dwuwymiarowa tablica liczbowych wartości intensywności.
Ramki ograniczające mogą być prostokątnymi ramkami ograniczającymi. Prostokątna ramka ograniczająca może być reprezentowana przez współrzędne określonego narożnika ramki ograniczającej oraz odpowiednią szerokość i wysokość kontenera ograniczającego. Mówiąc ogólniej, możliwe są inne kształty obwiedni i inne sposoby przedstawiania obwiedni.
Chociaż model wykrywania może rozpoznawać i wykorzystywać dowolne ramki lub granice obecne w dokumencie jako sygnały wizualne, ramki ograniczające nie są ograniczone do wyrównania (tj. pokrywania się) z istniejącymi strukturami granic obecnymi w dokumencie. Ponadto system może generować ramki ograniczające bez wyświetlania ramek granicznych na obrazie dokumentu.
Oznacza to, że system może generować dane definiujące pakiety ograniczające bez podawania użytkownikowi systemu wizualnego znaku położenia ramek ograniczających.
Model wykrywania jest ogólnie modelem uczenia maszynowego, czyli modelem posiadającym zestaw parametrów, które można przeszkolić na zestawie danych szkoleniowych. Dane treningowe zawierają wiele przykładów treningowych, z których każdy zawiera:
(i) obraz szkoleniowy przedstawiający dokument szkoleniowy oraz
(ii) docelowy wynik, który definiuje ramki ograniczające, zawiera odpowiednią parę klucz-wartość w obrazie szkoleniowym.
Dane uczące mogą być generowane przez ręczne adnotacje, to znaczy przez osobę identyfikującą ramki ograniczające wokół par klucz-wartość w dokumencie uczącym (np. przy użyciu odpowiedniego oprogramowania do adnotacji).
Uczenie modelu wykrywania przy użyciu technik uczenia maszynowego na zbiorze danych uczących umożliwia rozpoznawanie sygnałów wizualnych, które pozwolą mu identyfikować pary klucz-wartość w dokumentach. Na przykład, model wykrywania może być wyszkolony do rozpoznawania sygnałów lokalnych (np. style tekstu i względne przestrzenne położenia słów) i sygnałów globalnych (np. obecność granic w dokumencie) w celu identyfikacji par klucz-wartość.

Wizualne wskazówki, które umożliwiają modelowi wykrywania zapamiętanie zespołów klucz-wartość w rekordach, na ogół nie obejmują sygnałów reprezentujących wyraźne znaczenie słów w dokumencie.
Sygnały wizualne rozróżniające pary klucz-wartość
Uczenie modelu wykrywania w celu rozpoznawania sygnałów wizualnych, które rozróżniają pary klucz-wartość w dokumentach, umożliwia modelowi wykrywania „uogólnienie” poza danymi uczącymi używanymi do przygotowania modelu wykrywania. Wyszkolony model wykrywania może przetwarzać obraz przedstawiający dokument w celu wygenerowania ramek ograniczających zawierających pary klucz-wartość w dokumencie, nawet jeśli kopia nie została uwzględniona w danych szkoleniowych używanych do trenowania modelu wykrywania.
W jednym przykładzie model wykrywania może być modelem wykrywania obiektów sieci neuronowej (np. obejmującym splotowe sieci neuronowe), gdzie „obiekty” odpowiadają parom klucz-wartość w dokumencie. Możliwe do trenowania parametry modelu sieci neuronowej obejmują wagi modelu sieci neuronowej, na przykład wagi definiujące filtry splotowe w modelu sieci neuronowej.
Model sieci neuronowej może zostać przeszkolony na zbiorze danych uczących przy użyciu odpowiedniej procedury uczenia maszynowego, na przykład stochastycznego opadania gradientu. W szczególności, w każdej iteracji uczącej, model sieci neuronowej może przetwarzać obrazy uczące z „partii” (tj. zestawu) przykładów uczących w celu wygenerowania ramek ograniczających, zgodnie z przewidywaniami obejmującymi odpowiednie pary klucz-wartość w obrazach uczących. System może testować funkcję celu, która charakteryzuje miarę podobieństwa między prostokątami granicznymi generowanymi przez model sieci neuronowej i prostokątami granicznymi określonymi przez odpowiednie docelowe wyniki przykładów uczących.
Miarą podobieństwa dwóch ramek granicznych może być na przykład suma kwadratów odległości między odpowiednimi wierzchołkami ramek granicznych. System może wyznaczyć gradienty funkcji celu zdobytych wartości parametrów sieci neuronowej (np. za pomocą wstecznej propagacji błędów), a następnie wykorzystać nachylenie do dostosowania bieżących wartości parametrów sieci neuronowej.
W szczególności system może wykorzystać regułę aktualizacji parametrów z dowolnego odpowiedniego algorytmu optymalizacji zniżania gradientu (np. Adama lub RMSprop) w celu dostosowania bieżących wartości parametrów sieci neuronowej przy użyciu gradientów. System trenuje model sieci neuronowej aż do spełnienia kryterium zakończenia treningu (np. dopóki nie zostanie wykonana z góry określona liczba iteracji uczenia lub zmiana wartości funkcji celu między iteracjami uczenia spadnie poniżej z góry określonego progu).
Przed zastosowaniem modelu wykrywania system może zidentyfikować „klasę” dokumentu (np. faktura, odcinek wypłaty, paragon). Użytkownik systemu może zidentyfikować klasę rekordu po dostarczeniu dokumentu do systemu. Metoda może wykorzystywać klasyfikacyjną sieć neuronową do klasyfikacji klasy artykułu. System może wykorzystywać techniki OCR do identyfikacji tekstu w dokumencie, a następnie umieścić styl dokumentu na podstawie tekstu w dokumencie. W konkretnym przykładzie, w odpowiedzi na określenie frazy „Wypłata netto”, system może zidentyfikować klasę papieru jako „odcinek wypłaty”.
W innym konkretnym przykładzie, w odpowiedzi na zidentyfikowanie wyrażenia „podatek od sprzedaży”, system może zidentyfikować klasę dokumentu jako „faktura”. Po zidentyfikowaniu określonej klasy rekordu system może użyć modelu wykrywania, który jest szkolony do przetwarzania kopii określonej klasy. Metoda może używać modelu wykrywania, który został przeszkolony na danych uczących, które zawierały tylko dokumenty tej samej określonej klasy co dokument.
Korzystanie z modelu wykrywania, który jest wyszkolony do przetwarzania dokumentów tej samej klasy co dokument, może poprawić wydajność modelu wykrywania (np. poprzez umożliwienie modelowi wykrywania generowania ramek ograniczających wokół par klucz-wartość z większą dokładnością).
Dla każdego obwiedni system przetwarza część obrazu ujętą w obwiednię przy użyciu mechanizmu OCR w celu zidentyfikowania danych tekstowych (tj. tekstu) przechowywanych przez obwiednię. W szczególności aparat OCR identyfikuje tekst zawarty w ramce ograniczającej, identyfikując każdy znak alfabetyczny, numeryczny lub unikalny zawarty w ramce ograniczającej. Mechanizm OCR może użyć dowolnej odpowiedniej techniki do identyfikacji tekstu otoczonego ramką ograniczającą.
Aparat filtrujący określa, czy tekst zawarty w ramce ograniczającej reprezentuje parę klucz-wartość. Aparat filtrujący może zdecydować, czy tekst otaczający obwiednię odpowiednio reprezentuje parę klucz-wartość. Na przykład aparat filtrowania może określić, czy tekst zawarty w obwiedni zawiera poprawny klucz z wcześniej określonego zestawu prawych kluczy dla danego obwiedni. Na przykład zbiór prawidłowych kluczy może składać się z: „Data”, „Godzina”, „Nr faktury”, „Kwota należna” i tym podobne.
Porównując różne części tekstu w celu ustalenia, czy tekst zawarty w ramce ograniczającej zawiera prawidłowy klucz, aparat filtrujący może określić, że dwa fragmenty tekstu są „pasujące”, nawet jeśli nie są identyczne. Na przykład aparat filtrowania może określić, że dwie części czytnika pasują do siebie, nawet jeśli zawierają różne wielkości liter lub znaki interpunkcyjne (np. system filtrowania może określić, że „Data”, „Data:” „data” i „data:” wszystkie pasują).
W odpowiedzi na stwierdzenie, że tekst otoczony ramką ograniczającą nie zawiera prawidłowego klucza z prawych kluczy, aparat filtrowania określa, że tekst otoczony ramką ograniczającą nie reprezentuje pary klucz-wartość.
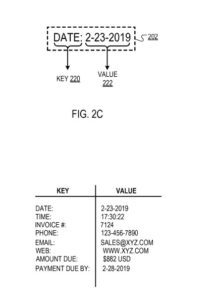
W odpowiedzi na ustalenie, że tekst zawarty w ramce ograniczającej zawiera prawidłowy klucz, mechanizm filtrowania identyfikuje „typ” (np. alfabetyczny, numeryczny, czasowy) części tekstu zawartej w ramce ograniczającej, która nie została zidentyfikowana jako klucz ( tj. tekst „niekluczowy”). Na przykład dla ramki ograniczającej, która ma tekst: „Data: 2-23-2019”, gdzie mechanizm filtrujący identyfikuje „Data:” jako klucz (jak opisano wcześniej), mechanizm filtrujący może zidentyfikować typ - tekst klucza „2-23-2019” jako „czasowy”.
Oprócz identyfikacji typu tekstu niebędącego kluczem aparat filtrowania identyfikuje zestaw prawidłowych typów dla wartości odpowiadających kluczowi. W szczególności silnik filtrujący może mapować klucz do grupy pomocnych typów danych dla wartości odpowiadających kluczowi przez z góry określone mapowanie. Na przykład aparat filtrujący może mapować klucz „Nazwa” do odpowiedniego typu danych wartości „alfabetycznie”, wskazując, że wartość odpowiadająca kluczowi powinna mieć alfabetyczny typ danych (np. „Jan Kowalski”).
Jako inny przykład, aparat filtrujący może mapować klucz „Date” do odpowiedniego typu danych wartości „temporal”, wskazując, że wartość odpowiadająca kluczowi powinna mieć czasowy typ danych (np. „2-23-2019” lub „ 17:30:22”).
Aparat filtrowania określa, czy typ tekstu niebędącego kluczem zostanie uwzględniony w zestawie prawidłowych rodzajów wartości odpowiadających kluczowi. W odpowiedzi na ustalenie, że styl tekstu niebędącego kluczem zostanie uwzględniony w kolekcji odpowiednich typów dla wartości odpowiadających legendzie, aparat filtrowania określa, że tekst ujęty w ramkę ograniczającą reprezentuje parę klucz-wartość. W szczególności aparat filtrujący identyfikuje tekst niebędący kluczem jako wartość odpowiadającą kluczowi. W przeciwnym razie aparat filtrowania określa, że tekst ujęty w obwiednię nie reprezentuje pary klucz-wartość.
Zestaw ważnych kluczy i mapowanie z właściwych kluczy do lokalizacji pomocnych typów danych dla wartości odpowiadających ważnym kluczom może zostać dostarczony przez użytkownika systemu (np. poprzez API udostępnione przez system).
Po zidentyfikowaniu par klucz-wartość z tekstu zawartego w odpowiednich ramkach ograniczających za pomocą mechanizmu filtrowania system wyprowadza zidentyfikowane pary klucz-wartość. Na przykład, system może dostarczyć zespoły klucz-wartość do zdalnego użytkownika systemu przez sieć teleinformatyczną (np. za pomocą API udostępnionego przez system). Jako inny przykład, system może przechowywać dane definiujące zidentyfikowane pary klucz-wartość w bazie danych (lub innej strukturze danych) dostępnej dla użytkownika systemu.
W niektórych przypadkach użytkownik systemu może zażądać, aby system zidentyfikował wartość odpowiadającą danemu kluczowi w dokumencie (np. „Faktura nr”). W takich przypadkach zamiast identyfikować i dostarczać każdą parę klucz-wartość w rekordzie, system może przetwarzać tekst umieszczony w odpowiednich ramkach ograniczających, dopóki żądany zespół nie rozpozna i nie wykona zamówionej pary klucz-wartość.
Jak opisano powyżej, model wykrywania może zostać przeszkolony do generowania ramek ograniczających, z których każdy zawiera odpowiednią parę klucz-wartość. Lub zamiast używać jednego modelu wykrywania, system może obejmować:
(i) „model wykrywania kluczy”, który jest szkolony do generowania ramek ograniczających, które zawierają odpowiednie klucze, oraz
(ii) „model wykrywania wartości”, który jest szkolony do generowania ramek ograniczających, które zawierają odpowiednie wartości.
System może odpowiednio zidentyfikować pary klucz-wartość z ramek granicznych klucza i ramek granicznych wartości. Na przykład dla każdego zespołu ramek ograniczających, który zawiera kluczową ramkę graniczną i ramkę graniczną wartości, system może wygenerować „wynik dopasowania” na podstawie:
(i) przestrzenna bliskość ramek ograniczających,
(ii) czy ramka ograniczająca klucz zawiera poprawny klucz oraz
(iii) czy typ wartości zawartej w polu ograniczającym wartość zostanie uwzględniony w zestawie poprawnych typów dla wartości odpowiadających kluczowi.
System może zidentyfikować klucz zawarty w ramce ograniczającej klucz i wartość otoczoną ramką ograniczającą wartość jako parę klucz-wartość, jeśli wynik dopasowania między ramką ograniczającą klucz a ramką ograniczającą wartość przekracza próg.
Przykład dokumentu faktury
Użytkownik systemu przetwarzania dokumentów może dostarczyć fakturę (np. jako zeskanowany obraz lub plik PDF) do systemu parsowania.
Ramki ograniczające są generowane przez model wykrywania systemu parsowania. Przewiduje się, że każda ramka ograniczająca zawiera dane tekstowe definiujące parę klucz-wartość. Model wykrywania nie generuje ramki ograniczającej z tekstem (np. „Dziękujemy za Twoją firmę!”), ponieważ ten tekst nie reprezentuje pary klucz-wartość.
System analizowania wykorzystuje techniki OCR do identyfikacji tekstu wewnątrz każdej ramki ograniczającej, a następnie identyfikuje dobre pary klucz-wartość zawarte w ramkach ograniczających.
Klucz (tj. „Data:”) i wartość (tj. „2-23-2019”) ujęte w ramce ograniczającej.
Pary klucz-wartość i przetwarzanie dokumentów
System analizujący zaprogramowany przez tę specyfikację może wykonywać przetwarzanie dokumentów.
System odbiera dokument jako upload od zdalnego użytkownika systemu przez sieć teleinformatyczną (np. za pomocą API udostępnionego przez system). Dokument może być reprezentowany w dowolnym odpowiednim formacie danych nieustrukturyzowanych, takim jak dokument PDF lub dokument obrazu (np. dokument PNG lub JPEG).
System konwertuje dokument na obraz, czyli uporządkowany zbiór wartości liczbowych, który reprezentuje wizualny wygląd papieru. Na przykład obraz może być czarno-białym obrazem dokumentu, który jest opisywany jako dwuwymiarowa tablica liczbowych wartości intensywności.
Przez zestaw parametrów modelu wykrywania do generowania danych wyjściowych, które definiują ramki ograniczające w obrazie dokumentu. Przewiduje się, że każda ramka ograniczająca będzie zawierać parę klucz-wartość, w tym krytyczne dane tekstowe i dane tekstowe wartości, gdzie klucz definiuje etykietę charakteryzującą wartość.
Model wykrywania może być modelem wykrywania obiektów, który obejmuje splotowe sieci neuronowe.
Przeszukaj wiadomości prosto do skrzynki odbiorczej
*Wymagany