
Обработка документов с использованием структурированных пар ключ-значение
Опубликовано: 2022-03-31Почему пары ключ-значение в этой системе обработки документов?
Написание этого поста напомнило мне о посте 2007 года, который я написал о локальном поиске и структурированных данных, где пары ключ-значение были важным аспектом этого патента 2007 года. Пост был:
Структурированная информация в локальном поиске Google.
Мне показалось интересным увидеть, как Google пишет о вставке пар ключ-значение в систему обработки документов, подобную той, что здесь, с подходом машинного обучения в основе, проникая в техническое SEO.
Использование пар ключ-значение по-прежнему важно сейчас, спустя 15 лет.
Обработка документов в Google
Понимание обработки документов (например, счетов-фактур, платежных квитанций, товарных чеков и т.п.) является важнейшей потребностью бизнеса. Большая часть (например, 90 % и более) корпоративных данных хранится и представляется в неструктурированных документах. Извлечение структурированных данных из записей может быть дорогостоящим, трудоемким и подверженным ошибкам.
В этом патенте описывается система синтаксического анализа обработки документов и метод, реализованный в виде компьютерных программ на компьютерах в местах, которые преобразуют неструктурированные документы в структурированные пары ключ-значение.
Система синтаксического анализа настраивается на обработку документов для идентификации «ключевых» текстовых данных и соответствующих «ценных» текстовых данных в документе. Ключ определяет метку, которая характеризует (т. е. описывает) соответствующее значение.
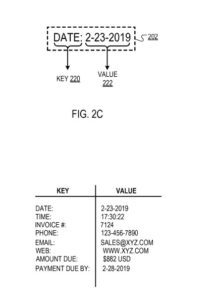
Например, ключу «Дата» может соответствовать значение «23-23-2019».
Существует способ, выполняемый устройством обработки данных, которое обеспечивает изображение документа для модели обнаружения, в котором: модель обнаружения настраивается для обработки изображения значениями множества параметров модели обнаружения для создания выходных данных, которые определяют ограничивающие рамки создан для идеи.
Прогнозируется, что каждая ограничивающая рамка, сгенерированная для изображения, заключает в себе пару ключ-значение, содержащую важные текстовые данные и текстовые данные значения, при этом необходимые текстовые данные определяют метку, которая характеризует данные текстового значения.
Каждая из ограничивающих рамок, созданных для изображения: идентифицирует текстовую информацию, заключенную в ограничивающую рамку, с использованием метода оптического распознавания символов; определяют, определяют ли текстовые данные, содержащиеся в ограничивающей рамке, пару ключ-значение; и в ответ на определение того, что текстовые данные, заключенные в ограничительную рамку, представляют собой пару ключ-значение, предоставление пары ключ-значение для использования в характеристике документа.
Модель обнаружения представляет собой модель нейронной сети.
Модель нейронной сети содержит сверточную нейронную сеть.
Модель нейронной сети обучается на наборе обучающих примеров. Каждый обучающий пример содержит обучающий ввод и целевой вывод; обучающий ввод включает в себя обучающее изображение обучающего документа. Целевой вывод содержит данные, определяющие ограничивающие рамки в тренировочном изображении, заключающие в себе соответствующую пару ключ-значение.
Документ представляет собой счет-фактуру.

Предоставление изображения документа модели обнаружения включает в себя: идентификацию конкретного класса бумаги; и предоставление идеи документа модели обнаружения, которая обучается обрабатывать копии определенного типа.
- Определение того, определяют ли текстовые данные, заключенные в ограничительную рамку, пару ключ-значение, включает:
- Принятие решения о том, что текстовая информация, которой обладает ограничительная рамка, включает в себя ключ из заданного набора действительных ключей;
- Нахождение типа части текстовых данных, содержащейся в ограничивающей рамке, не имеющей ключа; определение местоположения подходящих разновидностей для значений, соответствующих ключу
- Выбор того, что стиль части текстовых данных, заключенной в ограничительную рамку, которая не включает ключ, включается в набор допустимых типов для значений, соответствующих ключу.
- Изучение того, что набор допустимых типов для значений, соответствующих ключу, включает в себя: сопоставление ключа с набором подходящих типов для значений, соответствующих ключу, с использованием заранее определенного сопоставления.
Набор действительных ключей и сопоставление ключей с соответствующими местоположениями подходящих типов для значений, соответствующих ключам, предоставляются пользователем.
Ограничительные рамки имеют прямоугольную форму.
Способ дополнительно включает: прием документа от пользователя; и преобразование бумаги в изображение, при этом рисунок изображает документ.
Способ, выполняемый системой обработки документов, включающий:
- Предоставление изображения документа модели обнаружения, сконфигурированной для обработки изображения для идентификации в ограничивающих прямоугольниках изображения, которые, согласно прогнозам, заключают в себе пару ключ-значение, содержащую критические текстовые данные и текстовые данные значения, где ключ определяет метку, которая характеризует значение, соответствующее к ключу; для каждой из ограничивающих рамок, созданных для изображения,
- Идентификация текстовых данных, заключенных в ограничивающую рамку, с использованием метода оптического распознавания символов и определение того, определяет ли текстовая информация, содержащаяся в ограничивающей рамке, пару ключ-значение.
- Вывод пары "ключ-значение" для использования в характеристике документа.
Модель обнаружения — это модель машинного обучения с параметрами, которые можно обучить на обучающем наборе данных.
Модель машинного обучения содержит модель нейронной сети, в частности сверточной нейронной сети.
Модель машинного обучения обучается на наборе обучающих примеров, и каждый обучающий пример имеет обучающий вход и целевой результат.
Обучающий вход содержит обучающее изображение обучающего документа. Целевой вывод включает в себя определяющие данные ограничивающие прямоугольники в обучающем изображении, каждый из которых заключает в себе соответствующую пару ключ-значение.
Документ представляет собой счет-фактуру.
Предоставление изображения документа модели обнаружения включает в себя: идентификацию конкретного класса бумаги; и предоставление идеи документа модели обнаружения, которая обучается обрабатывать документы определенного типа.
Это пара ключ-значение?
Определение того, определяют ли текстовые данные, заключенные в ограничительную рамку, пару ключ-значение, означает:
- Принятие решения о том, что текстовая информация, содержащаяся в ограничивающей рамке, включает в себя ключ из заранее определенного набора действительных ключей.
- Поиск типа части текстовых данных, содержащейся в ограничивающей рамке, которая не имеет ключа
- Отмечая расположение подходящих разновидностей для значений, соответствующих ключу
- Выбор того, что стиль части текстовых данных, заключенной в ограничительную рамку, которая не включает ключ, включается в набор допустимых типов для значений, соответствующих ключу.
Идентификация набора допустимых типов для значений, соответствующих ключу, включает в себя: сопоставление ключа с набором надлежащих типов для значений, соответствующих ключу, с использованием заранее определенного отображения.
Набор действительных ключей и сопоставление ключей с соответствующими местоположениями подходящих типов для значений, соответствующих ключам, предоставляются пользователем.
Ограничительные рамки имеют прямоугольную форму.
Способ дополнительно включает: прием документа от пользователя; и преобразование бумаги в изображение, при этом рисунок изображает документ.
Согласно другому аспекту имеется система, содержащая: компьютеры; и запоминающие устройства, соединенные с компьютерами, при этом запоминающие устройства хранят инструкции, которые при выполнении компьютерами заставляют компьютеры выполнять операции, включающие операции ранее описанного способа.
Преимущества этого подхода к обработке документов
Система, описанная в этой спецификации, может использоваться для преобразования большого количества неструктурированных документов в структурированные пары ключ-значение. Таким образом, система устраняет необходимость извлечения структурированных данных из неструктурированных документов, что может быть дорогостоящим, трудоемким и подверженным ошибкам.
Система, описанная в этой спецификации, может идентифицировать пары ключ-значение в документах с высоким уровнем точности (например, для некоторых типов документов с точностью более 99%). Таким образом, система может быть пригодна для развертывания в приложениях (например, для обработки финансовых документов), которым требуется высокий уровень точности.
Система, описанная в этой спецификации, может обобщать лучше, чем некоторые традиционные системы, т. е. она обладает улучшенными возможностями обобщения по сравнению с некоторыми традиционными методами.
В частности, используя модель обнаружения с машинным обучением, обученную распознавать визуальные сигналы, которые различают пары ключ-значение в документах, система может идентифицировать пары ключ-значение определенного стиля, структуры или содержания документов.
Идентификация пар ключ-значение в патенте на обработку документов
Идентификация пар ключ-значение в документах
Изобретатели: Ян Сюй, Цзян Ван и Шэнъян Дай.
Правопреемник: Google LLC
Патент США: 11 288 719
Выдано: 29 марта 2022 г.
Подано: 27 февраля 2020 г.
Абстрактный
Способы, системы и устройства, включая компьютерные программы, закодированные на компьютерном носителе данных, для преобразования неструктурированных документов в структурированные пары ключ-значение.
В одном аспекте способ включает в себя: предоставление изображения документа модели обнаружения, при этом: модель обнаружения конфигурируется для обработки изображения для создания выходных данных, определяющих ограничивающие рамки, сгенерированные для изображения; и прогнозируется, что каждая ограничивающая рамка, сгенерированная для изображения, заключает в себе пару ключ-значение, содержащую ключевые текстовые данные и текстовые данные значения, где ключевые текстовые данные определяют метку, характеризующую текстовые данные значения, и для каждой из ограничивающих рамок, сгенерированных для изображение: идентификация текстовых данных, заключенных в ограничивающую рамку, с использованием метода оптического распознавания символов и определение того, определяют ли текстовые данные, заключенные в ограничивающую рамку, пару ключ-значение.
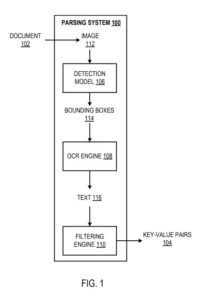
Пример системы синтаксического анализа
Система синтаксического анализа является примером метода, реализованного в виде компьютерных программ на компьютерах в местах, где реализуются системы, компоненты и методы, описанные ниже.
Система синтаксического анализа настраивается для обработки документа (например, счета-фактуры, платежной квитанции или квитанции о продаже) для идентификации пар ключ-значение в документе. «Пара ключ-значение» относится к ключу и соответствующему значению, обычно текстовым данным. Под «текстовыми данными» следует понимать как минимум: буквы алфавита, цифры и специальные символы. Как описано ранее, ключ определяет метку, характеризующую соответствующее значение.
Система может получить документ различными способами.
Например, система может принимать документ в виде загрузки от пользователя удаленной системы по сети передачи данных (например, с использованием интерфейса прикладного программирования (API), предоставляемого системой). Документ может быть представлен в любом соответствующем формате неструктурированных данных, например, в виде документа в формате Portable Document Format (PDF) или в виде документа с изображением (например, в формате Portable Network Graphics (PNG) или документа Объединенной группы экспертов по фотографии (JPEG)).
Определение пар ключ-значение в обработке документов
Система использует модель обнаружения, механизм оптического распознавания символов (OCR) и механизм фильтрации для идентификации пар ключ-значение при обработке документов.
Модель обнаружения настраивается для обработки изображения документа для создания выходных данных, определяющих ограничивающие рамки на изображении. Каждый из них содержит текстовые данные, представляющие соответствующую пару ключ-значение. То есть ожидается, что каждая ограничивающая рамка будет иметь текстовую информацию, которая определяет:
(i) ключ, и
(ii) значение, соответствующее ключу. Например, ограничивающая рамка может содержать текстовые данные «Имя: Джон Смит», которые определяют ключ «Имя» и соответствующее значение «Джон Смит». Модель обнаружения может быть сконфигурирована для создания ограничивающих рамок, которые заключают в себе одну пару ключ-значение (то есть, а не множество пар ключ-значение).
Изображение документа представляет собой упорядоченный набор числовых значений, представляющих внешний вид бумаги. Изображение может быть черно-белым изображением документа. В этом примере изображение может быть описано как двумерный массив числовых значений интенсивности. В качестве другого примера изображение может быть цветным изображением документа. В этом примере изображение может быть представлено как многоканальное изображение. Каждый канал соответствует соответствующему цвету (например, красному, зеленому или синему) и определяется как двумерный массив числовых значений интенсивности.
Ограничивающие рамки могут быть прямоугольными ограничивающими рамками. Прямоугольная ограничивающая рамка может быть представлена координатами определенного угла ограничивающей рамки и соответствующей шириной и высотой ограничивающего контейнера. В более общем плане возможны другие формы ограничивающей рамки и другие способы представления ограничивающих рамок.
В то время как модель обнаружения может распознавать и использовать любые кадры или границы, присутствующие в документе, в качестве визуальных сигналов, ограничивающие прямоугольники не обязаны выравниваться (т. е. совпадать) с какими-либо существующими структурами границ, текущими в документе. Кроме того, система может генерировать ограничивающие рамки без отображения ограничивающих рамок на изображении документа.
То есть система может генерировать данные, определяющие ограничивающие пакеты, не давая визуального знака положения ограничивающих рамок пользователю системы.
Модель обнаружения обычно представляет собой модель машинного обучения, то есть модель, имеющую набор параметров, которые можно обучить на наборе обучающих данных. Обучающие данные включают в себя множество обучающих примеров, каждый из которых включает:
(i) обучающее изображение, которое изображает обучающий документ, и
(ii) целевой вывод, который определяет ограничивающие рамки, заключающие в себе соответствующую пару ключ-значение в обучающем изображении.
Обучающие данные могут быть сгенерированы путем аннотирования вручную, то есть человеком, идентифицирующим ограничивающие рамки вокруг пар ключ-значение в обучающем документе (например, с использованием соответствующего программного обеспечения для аннотирования).
Обучение модели обнаружения с использованием методов машинного обучения на наборе обучающих данных позволяет ей распознавать визуальные сигналы, которые позволяют идентифицировать пары ключ-значение в документах. Например, модель обнаружения может быть обучена распознавать локальные сигналы (например, стили текста и относительное пространственное положение слов) и глобальные сигналы (например, наличие границ в документе) для идентификации пар ключ-значение.

Визуальные подсказки, которые позволяют модели обнаружения запоминать пары «ключ-значение» в записях, обычно не включают в себя сигналы, представляющие явное значение слов в документе.
Визуальные сигналы, которые различают пары ключ-значение
Обучение модели обнаружения распознаванию визуальных сигналов, которые различают пары ключ-значение в документах, позволяет модели обнаружения «обобщать» за пределы обучающих данных, используемых для подготовки модели обнаружения. Обученная модель обнаружения может обрабатывать изображение, изображающее документ, для создания ограничивающих рамок, заключающих пары ключ-значение в документе, даже если копия не была включена в обучающие данные, используемые для обучения модели обнаружения.
В одном примере модель обнаружения может быть моделью обнаружения объектов нейронной сети (например, включая сверточные нейронные сети), где «объекты» соответствуют парам ключ-значение в документе. Обучаемые параметры модели нейронной сети включают в себя веса модели нейронной сети, например, веса, которые определяют сверточные фильтры в модели нейронной сети.
Модель нейронной сети может обучаться на обучающем наборе данных с использованием соответствующей процедуры обучения машинного обучения, например стохастического градиентного спуска. В частности, на каждой обучающей итерации модель нейронной сети может обрабатывать обучающие изображения из «пакета» (т. е. набора) обучающих примеров для создания ограничивающих рамок, которые, по прогнозам, заключают в себе соответствующие пары «ключ-значение» в обучающих изображениях. Система может тестировать целевую функцию, которая характеризует меру сходства между ограничивающими прямоугольниками, сгенерированными моделью нейронной сети, и ограничивающими прямоугольниками, заданными соответствующими целевыми выходными данными обучающих примеров.
Мерой подобия между двумя ограничивающими рамками может быть, например, сумма квадратов расстояний между соответствующими вершинами ограничивающих рамок. Система может определять градиенты целевой функции от значений параметров нейронной сети (например, с помощью обратного распространения ошибки) и после этого использовать наклоны для корректировки текущих значений параметров нейронной сети.
В частности, система может использовать правило обновления параметров из любого подходящего алгоритма оптимизации градиентного спуска (например, Adam или RMSprop) для настройки текущих значений параметров нейронной сети с использованием градиентов. Система обучает модель нейронной сети до тех пор, пока не будет выполнен критерий окончания обучения (например, пока не будет выполнено заданное количество итераций обучения или пока изменение значения целевой функции объекта между итерациями обучения не упадет ниже заданного порога).
Перед использованием модели обнаружения система может идентифицировать «класс» документа (например, счет-фактура, платежная квитанция или товарный чек). Пользователь системы может идентифицировать класс записи при предоставлении документа в систему. Метод может использовать классификационную нейронную сеть для классификации класса бумаги. Система может использовать методы OCR для идентификации текста в документе и после этого размещать стиль документа на основе текста в документе. В конкретном примере в ответ на определение фразы «Чистая оплата» система может идентифицировать класс бумаги как «платежный корешок».
В другом конкретном примере в ответ на определение фразы «Налог с продаж» система может определить класс документа как «счет-фактура». После определения определенного класса записи система может использовать модель обнаружения, которая обучается обрабатывать копии определенного класса. Метод может использовать модель обнаружения, обученную на обучающих данных, которые включают только документы того же конкретного класса, что и документ.
Использование модели обнаружения, которая обучается обрабатывать документы того же класса, что и документ, может повысить производительность модели обнаружения (например, позволяя модели обнаружения генерировать ограничивающие рамки вокруг пар ключ-значение с большей точностью).
Для каждой ограничивающей рамки система обрабатывает часть изображения, заключенную в ограничивающую рамку, с помощью механизма OCR для идентификации текстовых данных (т. е. текста), содержащихся в ограничивающей рамке. В частности, механизм OCR идентифицирует текст, заключенный в ограничивающую рамку, идентифицируя каждый буквенный, числовой или уникальный символ, заключенный в ограничивающую рамку. Механизм OCR может использовать любой подходящий метод для идентификации текста, заключенного в ограничительную рамку.
Механизм фильтрации определяет, представляет ли текст, заключенный в ограничительную рамку, пару ключ-значение. Механизм фильтрации может решить, правильно ли текст, окружающий ограничивающую рамку, представляет пару ключ-значение. Например, механизм фильтрации может определить, включает ли текст, заключенный в ограничительную рамку, действительный ключ из предопределенного набора правильных ключей для данной ограничивающей рамки. Например, набор действительных ключей может состоять из: «Дата», «Время», «Счет №», «Сумма к оплате» и т.п.
При сравнении различных частей текста, чтобы определить, содержит ли текст, заключенный в ограничительную рамку, действительный ключ, механизм фильтрации может определить, что два фрагмента текста «совпадают», даже если они не идентичны. Например, механизм фильтрации может определить, что две части считывающего устройства совпадают, даже если они содержат разные заглавные буквы или знаки препинания (например, система фильтрации может определить, что «Дата», «Дата:», «дата» и «дата:» все совпадают).
В ответ на определение того, что текст, заключенный в ограничительную рамку, не включает допустимый ключ из правильных ключей, механизм фильтрации определяет, что текст, заключенный в ограничивающую рамку, не представляет пару ключ-значение.
В ответ на определение того, что текст, заключенный в ограничительную рамку, включает действительный ключ, механизм фильтрации идентифицирует «тип» (например, алфавитный, числовой, временной) части текста, заключенной в ограничительную рамку, не идентифицированной как ключ ( т. е. «неключевой» текст). Например, для ограничительной рамки с текстом «Дата: 23-23-2019», где механизм фильтрации идентифицирует «Дата:» в качестве ключа (как описано ранее), механизм фильтрации может определить тип не -ключевой текст «23-23-2019» как «временной».
Помимо определения типа неключевого текста, механизм фильтрации определяет набор допустимых типов для значений, соответствующих ключу. В частности, механизм фильтрации может отображать ключ на группу полезных типов данных для значений, соответствующих ключу, посредством заранее определенного отображения. Например, механизм фильтрации может отображать ключ «Имя» в соответствующий тип данных значения «алфавитный», указывая, что значение, соответствующее ключу, должно иметь алфавитный тип данных (например, «Джон Смит»).
В качестве другого примера механизм фильтрации может сопоставить ключ «Дата» с соответствующим типом данных значения «temporal», указывая, что значение, соответствующее ключу, должно иметь временный тип данных (например, «23-2019» или « 17:30:22").
Механизм фильтрации определяет, включается ли тип неключевого текста в набор допустимых типов для значений, соответствующих ключу. В ответ на определение того, что стиль неключевого текста включается в набор подходящих типов для значений, соответствующих легенде, механизм фильтрации определяет, что текст, заключенный в ограничительную рамку, представляет пару ключ-значение. В частности, механизм фильтрации идентифицирует неключевой текст как значение, соответствующее ключу. В противном случае механизм фильтрации определяет, что текст, заключенный в ограничительную рамку, не представляет пару ключ-значение.
Набор действительных ключей и сопоставление правильных ключей с местоположениями полезных типов данных для значений, соответствующих действительным ключам, могут быть предоставлены пользователем системы (например, через API, предоставляемый системой).
После определения пар ключ-значение из текста, заключенного в соответствующие ограничивающие рамки, с помощью механизма фильтрации система выводит идентифицированные пары ключ-значение. Например, система может предоставлять команды "ключ-значение" удаленному пользователю системы по сети передачи данных (например, с использованием API, предоставляемого системой). В качестве другого примера система может хранить данные, определяющие идентифицированные пары ключ-значение, в базе данных (или другой структуре данных), доступной для пользователя системы.
В некоторых случаях пользователь системы может запросить, чтобы система идентифицировала значение, соответствующее конкретному ключу в документе (например, «Счет №»). В этих случаях вместо того, чтобы идентифицировать и предоставлять каждую пару ключ-значение в записи, система может обрабатывать текст, помещенный в соответствующие ограничивающие рамки, до тех пор, пока запрошенная команда ключ-значение не распознает и не выполнит упорядоченную пару ключ-значение.
Как описано выше, модель обнаружения можно обучить генерировать ограничивающие прямоугольники, каждый из которых заключает в себе соответствующую пару ключ-значение. Или, вместо использования одной модели обнаружения, система может включать:
(i) «модель обнаружения ключей», которая обучается генерировать ограничивающие рамки, в которых заключены соответствующие ключи, и
(ii) «модель обнаружения значений», которая обучается генерировать ограничивающие прямоугольники, заключающие в себе соответствующие значения.
Система может соответствующим образом идентифицировать пары ключ-значение из ограничивающих рамок ключей и ограничивающих рамок значений. Например, для каждой группы ограничивающих рамок, которая включает в себя ограничивающую рамку ключа и ограничивающую рамку значения, система может генерировать «оценку совпадения» на основе:
(i) пространственная близость ограничивающих рамок,
(ii) заключает ли ограничивающая рамка ключа действительный ключ, и
(iii) включается ли тип значения, заключенного в ограничивающую рамку значения, в набор допустимых типов для значений, соответствующих ключу.
Система может идентифицировать ключ, заключенный в ограничивающую рамку ключа, и значение, заключенное в ограничивающую рамку значения, как пару ключ-значение, если оценка совпадения между ограничивающей рамкой ключа и ограничивающей рамкой значения превышает пороговое значение.
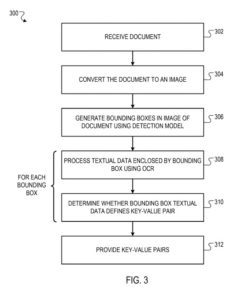
Пример счета-фактуры
Пользователь системы обработки документов может предоставить счет-фактуру (например, в виде отсканированного изображения или файла PDF) в систему анализа.
Ограничивающие рамки генерируются моделью обнаружения системы синтаксического анализа. Прогнозируется, что каждая ограничивающая рамка будет заключать в себе текстовые данные, определяющие пару ключ-значение. Модель обнаружения не создает ограничивающую рамку с текстом (например, «Спасибо за ваше сотрудничество!»), поскольку этот текст не представляет пару «ключ-значение».
Система синтаксического анализа использует методы OCR для идентификации текста внутри каждой ограничивающей рамки, а затем идентифицирует хорошие пары ключ-значение, заключенные в ограничивающие рамки.
Ключ (например, «Дата:») и значение (например, «23-23-2019»), заключенные в ограничивающую рамку.
Пары ключ-значение и обработка документов
Система синтаксического анализа, запрограммированная в соответствии с этой спецификацией, может выполнять обработку документов.
Система получает документ в виде загрузки от пользователя удаленной системы по сети передачи данных (например, с использованием API, предоставляемого системой). Документ может быть представлен в любом соответствующем формате неструктурированных данных, таком как документ PDF или документ изображения (например, документ PNG или JPEG).
Система преобразует документ в изображение, то есть в упорядоченный набор числовых значений, представляющих внешний вид бумаги. Например, изображение может быть черно-белым изображением документа, которое описывается как двумерный массив числовых значений интенсивности.
С помощью набора параметров модели обнаружения для создания выходных данных, определяющих ограничивающие рамки на изображении документа. Прогнозируется, что каждая ограничивающая рамка заключает в себе пару ключ-значение, включая критические текстовые данные и текстовые данные значения, где ключ определяет метку, характеризующую значение.
Модель обнаружения может быть моделью обнаружения объектов, которая включает в себя сверточные нейронные сети.
Поиск новостей прямо в папку «Входящие»
*Необходимый