
Elaborazione dei documenti utilizzando coppie chiave-valore strutturate
Pubblicato: 2022-03-31Perché le coppie chiave-valore in questo sistema di elaborazione dei documenti?
Scrivere questo post mi ha ricordato un post del 2007 che ho scritto sulla ricerca locale e sui dati strutturati in cui le coppie chiave-valore erano un aspetto importante di quel brevetto del 2007. Il post era:
Informazioni strutturate nella ricerca locale di Google.
Mi è sembrato interessante vedere Google scrivere sull'inserimento di coppie chiave-valore in un sistema di elaborazione dei documenti come quello qui, con un approccio di machine learning al centro, entrare nella SEO tecnica.
Gli utilizzi delle Ppair chiave-valore sono ancora importanti dopo 15 anni.
Elaborazione dei documenti su Google
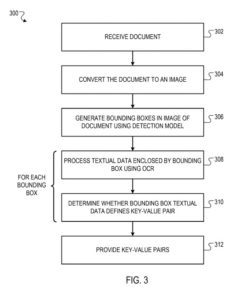
Comprendere l'elaborazione dei documenti (ad es. fatture, buste paga, ricevute di vendita e simili) è un'esigenza aziendale cruciale. Una grande frazione (ad esempio, il 90% o più) dei dati aziendali viene archiviata e rappresentata in documenti non strutturati. L'estrazione di dati strutturati dai record può essere costosa, dispendiosa in termini di tempo e soggetta a errori.
Questo brevetto descrive un sistema di analisi di elaborazione dei documenti e un metodo implementato come programmi per computer su computer in posizioni che convertono documenti non strutturati in coppie chiave-valore strutturate.
Il sistema di analisi viene configurato per documentare l'elaborazione per identificare i dati testuali "chiave" e i corrispondenti dati testuali "di valore" nel documento. La chiave definisce un'etichetta che caratterizza (cioè è descrittiva di) un valore corrispondente.
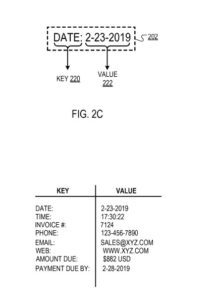
Ad esempio, la chiave “Data” può corrispondere al valore “23-2-2019”.
Esiste un metodo eseguito da un apparato di elaborazione dati, che fornisce un'immagine di un documento a un modello di rilevamento, in cui: il modello di rilevamento viene configurato per elaborare l'immagine in base ai valori di una pluralità di parametri del modello di rilevamento per generare un output che definisce riquadri di delimitazione generato per l'idea.
Ogni riquadro di delimitazione generato per l'immagine viene previsto per racchiudere una coppia chiave-valore comprendente dati testuali critici e dati testuali di valore, in cui i dati testuali necessari definiscono un'etichetta che caratterizza i dati di valore testuale.
Ciascuno dei riquadri di delimitazione generati per l'immagine: identifica le informazioni testuali racchiuse dal riquadro di delimitazione utilizzando una tecnica di riconoscimento ottico dei caratteri; determinare se i dati testuali contenuti nel riquadro di delimitazione definiscono una coppia chiave-valore; e in risposta alla determinazione che i dati testuali racchiusi dal riquadro di delimitazione rappresentano una coppia chiave-valore, fornendo la coppia chiave-valore da utilizzare nella caratterizzazione del documento.
Il modello di rilevamento è un modello di rete neurale.
Il modello di rete neurale comprende una rete neurale convoluzionale.
Il modello di rete neurale viene addestrato su una serie di esempi di addestramento. Ogni esempio di formazione comprende un input di formazione e un output di destinazione; l'input di formazione include un'immagine di formazione di un documento di formazione. L'output di destinazione contiene i dati che definiscono i riquadri di delimitazione nell'immagine di addestramento che racchiudono una rispettiva coppia chiave-valore.
Il documento è una fattura.

Fornire un'immagine di un documento a un modello di rilevamento comprende: identificare una classe particolare della carta; e fornire l'idea del documento a un modello di rilevamento che viene addestrato per elaborare copie del tipo specifico.
- Determinare se i dati testuali racchiusi dal riquadro di delimitazione definiscono una coppia chiave-valore comprende:
- Decidere che le informazioni testuali possedute dal riquadro di delimitazione includono una chiave da un insieme predeterminato di chiavi valide;
- Trovare un tipo di una parte di dati testuali detenuti dal riquadro di delimitazione che non ha la chiave; identificare una posizione di varietà idonee per i valori corrispondenti alla chiave
- Scegliendo che lo stile della parte dei dati testuali racchiusa dal riquadro di delimitazione che non include la chiave venga incluso nell'insieme dei tipi validi per i valori corrispondenti alla chiave.
- Apprendere che un insieme di tipi validi per valori corrispondenti alla chiave comprende: mappare la chiave alla raccolta di tipi adatti per valori corrispondenti alla chiave utilizzando una mappatura predeterminata.
L'insieme di chiavi valide e la mappatura dalle chiavi alle posizioni corrispondenti di tipi adatti per i valori corrispondenti alle chiavi vengono forniti da un utente.
I riquadri di delimitazione hanno una forma rettangolare.
Il metodo comprende inoltre: ricevere il documento da un utente; e convertire la carta in un'immagine, in cui il dipinto raffigura il documento.
Un metodo eseguito dal sistema di elaborazione dei documenti, il metodo comprendente:
- Fornitura di un'immagine di un documento a un modello di rilevamento configurato per elaborare l'immagine da identificare nei riquadri di delimitazione dell'immagine previsti per racchiudere una coppia chiave-valore comprendente dati testuali critici e dati testuali di valore, in cui la chiave definisce un'etichetta che caratterizza un valore corrispondente alla chiave; per ciascuno dei riquadri di delimitazione generati per l'immagine,
- Identificare i dati testuali racchiusi dal rettangolo di selezione utilizzando una tecnica di riconoscimento ottico dei caratteri e determinare se le informazioni testuali contenute nel rettangolo di selezione definiscono una coppia chiave-valore
- Output del team chiave-valore da utilizzare nella caratterizzazione del documento.
Il modello di rilevamento è un modello di apprendimento automatico con parametri che possono essere addestrati su un set di dati di addestramento.
Il modello di apprendimento automatico comprende un modello di rete neurale, in particolare una rete neurale convoluzionale.
Il modello di apprendimento automatico viene addestrato su una serie di esempi di formazione e ogni esempio di formazione ha un input di formazione e un output di destinazione.
L'input di formazione comprende un'immagine di formazione di un documento di formazione. L'output di destinazione include riquadri di delimitazione per la definizione dei dati nell'immagine di addestramento, ciascuno dei quali racchiude una rispettiva coppia chiave-valore.
Il documento è una fattura.
Fornire un'immagine di un documento a un modello di rilevamento comprende: identificare una classe particolare della carta; e fornire l'idea del documento a un modello di rilevamento che viene addestrato per elaborare documenti del tipo specifico.
È una coppia chiave-valore?
Determinare se i dati testuali racchiusi dal riquadro di delimitazione definiscono una coppia chiave-valore significa:
- Decidere che le informazioni testuali possedute dal riquadro di delimitazione includono una chiave da un insieme predeterminato di chiavi valide
- Trovare un tipo di una parte di dati testuali detenuti dal riquadro di delimitazione che non ha la chiave
- Notare una posizione di varietà adatte per i valori corrispondenti alla chiave
- Scegliendo che lo stile della parte dei dati testuali racchiusa dal riquadro di delimitazione che non include la chiave venga incluso nell'insieme di tipi validi per i valori corrispondenti alla chiave.
L'identificazione di un insieme di tipi validi per i valori corrispondenti alla chiave comprende: mappare la chiave alla raccolta di tipi propri per i valori corrispondenti alla chiave utilizzando una mappatura predeterminata.
L'insieme di chiavi valide e la mappatura dalle chiavi alle posizioni corrispondenti di tipi adatti per i valori corrispondenti alle chiavi vengono forniti da un utente.
I riquadri di delimitazione hanno una forma rettangolare.
Il metodo comprende inoltre: ricevere il documento da un utente; e convertire la carta in un'immagine, in cui il dipinto raffigura il documento.
Secondo un altro aspetto, esiste un sistema composto da: computer; e dispositivi di memorizzazione accoppiati a computer, in cui i dispositivi di memorizzazione memorizzano istruzioni che, quando eseguite da computer, fanno sì che i computer eseguano operazioni comprendenti le operazioni del metodo precedentemente descritto.
Vantaggi di questo approccio all'elaborazione dei documenti
Il sistema descritto in questa specifica può essere utilizzato per convertire un gran numero di documenti non strutturati in coppie chiave-valore strutturate. Pertanto, il sistema elimina la necessità di estrarre dati strutturati da documenti non strutturati, che possono essere costosi, dispendiosi in termini di tempo e soggetti a errori.
Il sistema descritto in questa specifica è in grado di identificare coppie chiave-valore in documenti con un elevato livello di accuratezza (ad esempio, per alcuni tipi di documenti, con una precisione superiore al 99%). Pertanto, il sistema può essere adatto per l'implementazione in applicazioni (ad es. elaborazione di documenti finanziari) che richiedono un elevato livello di accuratezza.
Il sistema descritto in questa descrizione può generalizzare meglio di alcuni sistemi convenzionali, cioè ha capacità di generalizzazione migliorate rispetto ad alcuni metodi tradizionali.
In particolare, sfruttando un modello di rilevamento appreso dalla macchina addestrato a riconoscere i segnali visivi che distinguono le coppie chiave-valore nei documenti, il sistema può identificare le coppie chiave-valore dello stile, della struttura o del contenuto specifico dei documenti.
L'identificazione delle coppie chiave-valore nel brevetto per l'elaborazione dei documenti
Identificazione delle coppie chiave-valore nei documenti
Inventori: Yang Xu, Jiang Wang e Shengyang Dai
Assegnatario: Google LLC
Brevetto USA: 11.288.719
Concesso: 29 marzo 2022
Archiviato: 27 febbraio 2020
Astratto
Metodi, sistemi e apparati, compresi programmi per computer codificati su un supporto di memorizzazione per computer, per convertire documenti non strutturati in coppie chiave-valore strutturate.
In un aspetto, un metodo comprende: fornire un'immagine di un documento a un modello di rilevamento, in cui: il modello di rilevamento viene configurato per elaborare l'immagine per generare un output che definisce i riquadri di delimitazione generati per l'immagine; e ogni riquadro di delimitazione generato per l'immagine viene previsto per racchiudere una coppia chiave-valore comprendente dati testuali chiave e dati testuali di valore, in cui i dati testuali chiave definiscono un'etichetta che caratterizza i dati testuali di valore e per ciascuno dei riquadri di delimitazione generati per l'immagine: identificare i dati testuali racchiusi dal riquadro di delimitazione utilizzando una tecnica di riconoscimento ottico dei caratteri e determinare se i dati testuali racchiusi dal riquadro di delimitazione definiscono una coppia chiave-valore.
Un esempio di sistema di analisi
Il sistema di analisi è un esempio di metodo implementato come programmi per computer su computer in posizioni in cui vengono implementati i sistemi, i componenti e le tecniche descritti di seguito.
Il sistema di analisi viene configurato per elaborare un documento (ad esempio una fattura, una busta paga o una ricevuta di vendita) per identificare le coppie chiave-valore nel documento. Una "coppia chiave-valore" si riferisce a una chiave e un valore corrispondente, generalmente dati testuali. I "dati testuali" dovrebbero essere intesi come riferiti almeno a: caratteri alfabetici, numeri e simboli speciali. Come descritto in precedenza, una chiave definisce un'etichetta che caratterizza un valore corrispondente.
Il sistema può ricevere il documento in vari modi.
Ad esempio, il sistema può ricevere il documento come caricamento da un utente del sistema remoto su una rete di comunicazione dati (ad esempio, utilizzando un'interfaccia di programmazione dell'applicazione (API) messa a disposizione dal sistema). Il documento può essere rappresentato in qualsiasi formato di dati non strutturato appropriato, ad esempio come documento PDF (Portable Document Format) o come documento immagine (ad esempio, un documento Portable Network Graphics (PNG) o Joint Photographic Experts Group (JPEG).
Identificare le coppie chiave-valore nell'elaborazione dei documenti
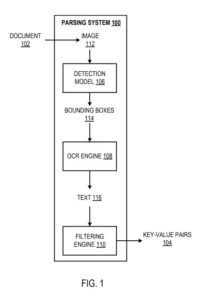
Il sistema utilizza un modello di rilevamento, un motore di riconoscimento ottico dei caratteri (OCR) e un motore di filtraggio per identificare le coppie chiave-valore nell'elaborazione dei documenti.
Il modello di rilevamento viene configurato per elaborare un'immagine del documento per generare un output che definisce i riquadri di delimitazione nell'immagine. Ciascuno viene previsto per racchiudere dati testuali che rappresentano una rispettiva coppia chiave-valore. Cioè, ogni riquadro di delimitazione dovrebbe avere informazioni testuali che definiscono:
(i) una chiave, e
(ii) un valore corrispondente alla chiave. Ad esempio, un riquadro di delimitazione può racchiudere i dati testuali "Nome: John Smith", che definisce la chiave "Nome" e il valore corrispondente "John Smith". Il modello di rilevamento può essere configurato per generare riquadri di delimitazione che racchiudono una singola coppia chiave-valore (cioè, anziché molte coppie chiave-valore).
L'immagine del documento è una raccolta ordinata di valori numerici che rappresentano l'aspetto visivo della carta. L'immagine può essere un'immagine in bianco e nero del documento. In questo esempio, l'immagine può essere descritta come una matrice bidimensionale di valori numerici di intensità. Come altro esempio, l'immagine può essere un'immagine a colori del documento. In questo esempio, l'immagine può essere rappresentata come un'immagine multicanale. Ciascun canale corrisponde a un rispettivo colore (ad es. rosso, verde o blu) e viene definito come una matrice bidimensionale di valori numerici di intensità.
I riquadri di delimitazione possono essere riquadri di delimitazione rettangolari. Un rettangolo di delimitazione rettangolare può essere rappresentato dalle coordinate di un particolare angolo del rettangolo di delimitazione e dalla larghezza e dall'altezza corrispondenti del contenitore di delimitazione. Più in generale, sono possibili altre forme di riquadro di delimitazione e altri modi di rappresentare i riquadri di delimitazione.
Sebbene il modello di rilevamento possa riconoscere e utilizzare qualsiasi cornice o bordo presente nel documento come segnali visivi, i riquadri di delimitazione non sono vincolati ad allinearsi (ossia essere coincidenti) con le strutture esistenti di confini presenti nella carta. Inoltre, il sistema può generare i riquadri di delimitazione senza visualizzare i riquadri di delimitazione nell'immagine del documento.
Cioè, il sistema può generare dati che definiscono i pacchetti di delimitazione senza dare un segno visivo della posizione dei riquadri di delimitazione a un utente del sistema.
Il modello di rilevamento è generalmente un modello di apprendimento automatico, ovvero un modello con un insieme di parametri che possono essere addestrati su un insieme di dati di addestramento. I dati di formazione includono molti esempi di formazione, ognuno dei quali include:
(i) un'immagine di formazione che rappresenti un documento di formazione e
(ii) un output di destinazione che definisce dei riquadri di delimitazione racchiude una rispettiva coppia chiave-valore nell'immagine di addestramento.
I dati di addestramento possono essere generati mediante annotazione manuale, ovvero da una persona che identifica i riquadri di delimitazione attorno alle coppie chiave-valore nel documento di addestramento (ad esempio, utilizzando un software di annotazione appropriato).
L'addestramento del modello di rilevamento mediante tecniche di apprendimento automatico su una serie di dati di addestramento gli consente di riconoscere segnali visivi che gli consentiranno di identificare le coppie chiave-valore nei documenti. Ad esempio, il modello di rilevamento può essere addestrato a riconoscere segnali locali (ad esempio, stili di testo e posizioni spaziali relative delle parole) e segnali globali (ad esempio, la presenza di bordi nel documento) per identificare coppie chiave-valore.

I segnali visivi che consentono al modello di rilevamento di ricordare i team di valori chiave nei record generalmente non includono segnali che rappresentano il significato esplicito delle parole nel documento.
Segnali visivi che distinguono le coppie chiave-valore
L'addestramento del modello di rilevamento per riconoscere i segnali visivi che distinguono le coppie chiave-valore nei documenti consente al modello di rilevamento di "generalizzare" oltre i dati di addestramento utilizzati per preparare il modello di rilevamento. Il modello di rilevamento addestrato potrebbe elaborare un'immagine raffigurante un documento per generare riquadri di delimitazione che racchiudono coppie chiave-valore nel documento anche se la copia non è stata inclusa nei dati di addestramento utilizzati per addestrare il modello di rilevamento.
In un esempio, il modello di rilevamento può essere un modello di rilevamento di oggetti di rete neurale (ad esempio, comprese le reti neurali convoluzionali), in cui gli "oggetti" corrispondono a coppie chiave-valore nel documento. I parametri addestrabili del modello di rete neurale includono i pesi del modello di rete neurale, ad esempio i pesi che definiscono i filtri convoluzionali nel modello di rete neurale.
Il modello di rete neurale può essere addestrato sul set di dati di addestramento utilizzando una procedura di addestramento di apprendimento automatico appropriata, ad esempio la discesa del gradiente stocastico. In particolare, ad ogni iterazione di addestramento, il modello di rete neurale può elaborare immagini di addestramento da un "batch" (cioè un insieme) di esempi di addestramento per generare riquadri di delimitazione previsti per racchiudere le rispettive coppie chiave-valore nelle immagini di addestramento. Il sistema può testare una funzione obiettivo che caratterizza una misura di somiglianza tra i bounding box generati dal modello di rete neurale e i bounding box specificati dai corrispondenti output target degli esempi di addestramento.
La misura della somiglianza tra due riquadri di delimitazione può essere, ad esempio, una somma di distanze al quadrato tra i rispettivi vertici dei riquadri di delimitazione. Il sistema può determinare i gradienti della funzione di mira che ha ottenuto i valori dei parametri della rete neurale (ad esempio, utilizzando la backpropagation) e quindi utilizzare le pendenze per regolare i valori dei parametri della rete neurale correnti.
In particolare, il sistema può utilizzare la regola di aggiornamento dei parametri da qualsiasi algoritmo di ottimizzazione della discesa del gradiente appropriato (ad es. Adam o RMSprop) per regolare i valori dei parametri della rete neurale correnti utilizzando i gradienti. Il sistema addestra il modello di rete neurale fino a quando non viene soddisfatto un criterio di terminazione dell'addestramento (ad esempio, fino a quando non è stato eseguito un numero predeterminato di iterazioni di addestramento o una modifica del valore della funzione obiettivo dell'oggetto tra le iterazioni di addestramento non scende al di sotto di una soglia predeterminata).
Prima di utilizzare il modello di rilevamento, il sistema può identificare una "classe" del documento (ad es. fattura, busta paga o ricevuta di vendita). Un utente del sistema può identificare la classe del record fornendo il documento al sistema. Il metodo può utilizzare una rete neurale di classificazione per classificare la classe della carta. Il sistema può utilizzare tecniche OCR per identificare il testo nel documento e, successivamente, posizionare lo stile del documento in base al testo nel documento. In un esempio particolare, in risposta alla determinazione della frase "Pagamento netto", il sistema può identificare la classe cartacea come "busta paga".
In un altro esempio particolare, in risposta all'identificazione della frase "imposta sulle vendite", il sistema può identificare la classe del documento come "fattura". Dopo aver identificato la classe particolare del record, il sistema può utilizzare un modello di rilevamento che viene addestrato per elaborare copie della classe specifica. Il metodo può utilizzare un modello di rilevamento che è stato addestrato sui dati di addestramento che includevano solo documenti della stessa classe particolare del documento.
L'utilizzo di un modello di rilevamento che viene addestrato per elaborare documenti della stessa classe del documento può migliorare le prestazioni del modello di rilevamento (ad esempio, consentendo al modello di rilevamento di generare riquadri di delimitazione attorno a coppie chiave-valore con maggiore precisione).
Per ogni riquadro di delimitazione, il sistema elabora la parte dell'immagine racchiusa dal riquadro di delimitazione utilizzando il motore OCR per identificare i dati testuali (cioè il testo) detenuti dal riquadro di delimitazione. In particolare, il motore OCR identifica il testo racchiuso da un riquadro di delimitazione identificando ogni carattere alfabetico, numerico o univoco racchiuso dal riquadro di delimitazione. Il motore OCR può utilizzare qualsiasi tecnica appropriata per identificare il testo circondato da un riquadro di delimitazione.
Il motore di filtraggio determina se il testo racchiuso da un riquadro di delimitazione rappresenta una coppia chiave-valore. Il motore di filtraggio può decidere se il testo che circonda il riquadro di delimitazione rappresenta una coppia chiave-valore in modo appropriato. Ad esempio, il motore di filtraggio può determinare se il testo racchiuso dal riquadro di delimitazione include una chiave valida da un insieme predeterminato di chiavi giuste per un dato riquadro di delimitazione. Ad esempio, la raccolta di chiavi valide può essere composta da: "Data", "Ora", "Fattura n.", "Importo dovuto" e simili.
Confrontando diverse porzioni di testo per determinare se il testo racchiuso dal riquadro di delimitazione include una chiave valida, il motore di filtraggio può determinare che due porzioni di testo "corrispondono" anche se non sono identiche. Ad esempio, il motore di filtraggio può determinare che due parti del lettore corrispondono anche se includono lettere maiuscole o punteggiatura diverse (ad esempio, il sistema di filtraggio può determinare che "Data", "Data:" "data" e "data:" sono tutti corrispondenti).
In risposta alla determinazione che il testo racchiuso dal riquadro di delimitazione non include una chiave valida dalle chiavi giuste, il motore di filtraggio determina che il testo racchiuso dal riquadro di delimitazione non rappresenta una coppia chiave-valore.
In risposta alla determinazione che il testo racchiuso dal riquadro di delimitazione contenga una chiave valida, il motore di filtraggio identifica un “tipo” (es. alfabetico, numerico, temporale) della parte di testo racchiusa dal riquadro di delimitazione non identificata come chiave ( cioè il testo “non chiave”). Ad esempio, per un riquadro di delimitazione che ha il testo: "Data: 23-02-2019", dove il motore di filtraggio identifica "Data:" come chiave (come descritto in precedenza), il motore di filtraggio può identificare il tipo di non -testo chiave "23-2-2019" come "temporale".
Oltre a identificare il tipo del testo non chiave, il motore di filtraggio identifica un insieme di tipi validi per i valori corrispondenti alla chiave. In particolare, il motore di filtraggio può mappare la chiave su un gruppo di tipi di dati utili per i valori corrispondenti alla chiave mediante una mappatura predeterminata. Ad esempio, il motore di filtraggio può mappare la chiave "Nome" al tipo di dati del valore corrispondente "alfabetico", indicando che il valore corrispondente alla chiave deve avere un tipo di dati alfabetico (ad esempio, "John Smith").
Come altro esempio, il motore di filtraggio può mappare la chiave "Date" sul tipo di dati del valore corrispondente "temporale", indicando che il valore corrispondente alla chiave deve avere un tipo di dati temporale (ad es. "23-2-2019" o " 17:30:22”).
Il motore di filtraggio determina se il tipo di testo non chiave viene incluso nell'insieme di tipi validi per i valori corrispondenti alla chiave. In risposta alla determinazione che lo stile del testo non chiave viene incluso nella raccolta di tipi adatti per i valori corrispondenti alla legenda, il motore di filtraggio determina che il testo racchiuso dal riquadro di delimitazione rappresenta una coppia chiave-valore. In particolare, il motore di filtraggio identifica il testo non chiave come il valore corrispondente alla chiave. In caso contrario, il motore di filtraggio determina che il testo racchiuso dal riquadro di delimitazione non rappresenta una coppia chiave-valore.
L'insieme di chiavi valide e la mappatura dalle chiavi giuste alle posizioni dei tipi di dati utili per i valori corrispondenti alle chiavi valide possono essere forniti da un utente del sistema (ad esempio, tramite un'API resa disponibile dal sistema).
Dopo aver identificato le coppie chiave-valore dal testo racchiuso dai rispettivi riquadri di delimitazione utilizzando il motore di filtraggio, il sistema emette le coppie chiave-valore identificate. Ad esempio, il sistema può fornire i team chiave-valore a un utente remoto del sistema su una rete di comunicazione dati (ad esempio, utilizzando un'API resa disponibile dal sistema). Come altro esempio, il sistema può memorizzare dati che definiscono le coppie chiave-valore identificate in un database (o altra struttura dati) accessibile all'utente del sistema.
In alcuni casi, un utente del sistema può richiedere che il sistema identifichi il valore corrispondente alla chiave particolare nel documento (ad esempio, “Fattura #”). In questi casi, anziché identificare e fornire ogni coppia chiave-valore nel record, il sistema può elaborare il testo inserito nei rispettivi riquadri di delimitazione fino a quando il team chiave-valore richiesto riconosce ed esegue la coppia chiave-valore ordinata.
Come descritto sopra, il modello di rilevamento può essere addestrato per generare riquadri di delimitazione che racchiudono ciascuno una rispettiva coppia chiave-valore. Oppure, anziché utilizzare un unico modello di rilevamento, il sistema può includere:
(i) un "modello di rilevamento delle chiavi" che viene addestrato a generare riquadri di delimitazione che racchiudono le rispettive chiavi, e
(ii) un "modello di rilevamento del valore" che viene addestrato a generare riquadri di delimitazione che racchiudono i rispettivi valori.
Il sistema è in grado di identificare le coppie chiave-valore dai riquadri di delimitazione delle chiavi e dai riquadri di delimitazione del valore in modo appropriato. Ad esempio, per ogni squadra di riquadri di delimitazione che include un riquadro di delimitazione delle chiavi e un riquadro di delimitazione dei valori, il sistema può generare un "punteggio partita" basato su:
(i) la vicinanza spaziale dei riquadri di delimitazione,
(ii) se il riquadro di delimitazione della chiave racchiude una chiave valida, e
(iii) se il tipo del valore racchiuso dal riquadro di delimitazione del valore viene incluso in un insieme di tipi validi per i valori corrispondenti alla chiave.
Il sistema può identificare la chiave racchiusa da un riquadro di delimitazione della chiave e il valore racchiuso da un riquadro di delimitazione del valore come coppia chiave-valore se il punteggio di corrispondenza tra il riquadro di delimitazione della chiave e il riquadro di delimitazione del valore supera una soglia.
Un esempio di documento di fattura
Un utente del sistema di elaborazione dei documenti può fornire la fattura (ad esempio, come immagine digitalizzata o file PDF) al sistema di analisi.
I riquadri di delimitazione sono generati dal modello di rilevamento del sistema di analisi. Si prevede che ogni riquadro di delimitazione racchiuda dati testuali che definiscono una coppia chiave-valore. Il modello di rilevamento non genera un riquadro di delimitazione contenente del testo (ad es. "Grazie per la tua attività!") poiché questo testo non rappresenta una coppia chiave-valore.
Il sistema di analisi utilizza tecniche OCR per identificare il testo all'interno di ogni riquadro di delimitazione e successivamente identifica buone coppie chiave-valore racchiuse dai riquadri di delimitazione.
La chiave (ad es. "Data:") e il valore (ad es. "23-2-2019") racchiusi dal riquadro di delimitazione.
Coppie chiave-valore ed elaborazione dei documenti
Un sistema di analisi programmato da questa specifica può eseguire l'elaborazione dei documenti.
Il sistema riceve un documento come caricamento da un utente del sistema remoto su una rete di comunicazione dati (ad esempio, utilizzando un'API messa a disposizione dal sistema). Il documento può essere rappresentato in qualsiasi formato di dati non strutturato appropriato, come un documento PDF o un documento immagine (ad esempio, un documento PNG o JPEG).
Il sistema converte il documento in un'immagine, ovvero una raccolta ordinata di valori numerici che rappresenta l'aspetto visivo della carta. Ad esempio, l'immagine può essere un'immagine in bianco e nero del documento che viene descritta come una matrice bidimensionale di valori di intensità numerica.
Da un insieme di parametri del modello di rilevamento per generare un output che definisce i riquadri di delimitazione nell'immagine del documento. Ogni riquadro di delimitazione viene previsto per racchiudere una coppia chiave-valore che include dati testuali critici e dati testuali di valore, in cui la chiave definisce un'etichetta che caratterizza il valore.
Il modello di rilevamento può essere un modello di rilevamento di oggetti che include reti neurali convoluzionali.
Cerca notizie direttamente nella tua casella di posta
*Necessario