
Traitement de documents à l'aide de paires clé-valeur structurées
Publié: 2022-03-31Pourquoi des paires clé-valeur dans ce système de traitement de documents ?
La rédaction de cet article m'a rappelé un article de 2007 que j'avais écrit sur la recherche locale et les données structurées où les paires clé-valeur étaient un aspect important de ce brevet de 2007. Le poste était :
Informations structurées dans la recherche locale de Google.
Il m'a semblé intéressant de voir Google écrire sur l'insertion de paires clé-valeur dans un système de traitement de documents comme celui-ci, avec une approche d'apprentissage automatique en son cœur, entrant dans le référencement technique.
Les usages des paires clé-valeur sont toujours importants après 15 ans.
Traitement des documents chez Google
Comprendre le traitement des documents (par exemple, les factures, les fiches de paie, les reçus de vente, etc.) est un besoin commercial crucial. Une grande partie (par exemple, 90 % ou plus) des données d'entreprise est stockée et représentée dans des documents non structurés. L'extraction de données structurées à partir d'enregistrements peut être coûteuse, chronophage et source d'erreurs.
Ce brevet décrit un système d'analyse de traitement de documents et un procédé mis en œuvre sous forme de programmes informatiques sur des ordinateurs dans des emplacements qui convertissent des documents non structurés en paires clé-valeur structurées.
Le système d'analyse est configuré pour documenter le traitement afin d'identifier les données textuelles « clés » et les données textuelles « de valeur » correspondantes dans le document. La clé définit une étiquette qui caractérise (c'est-à-dire décrit) une valeur correspondante.
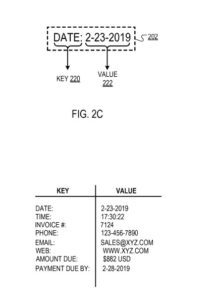
Par exemple, la clé "Date" peut correspondre à la valeur "2-23-2019".
Il existe un procédé exécuté par un appareil de traitement de données, qui fournit une image d'un document à un modèle de détection, dans lequel : le modèle de détection est configuré pour traiter l'image par des valeurs d'une pluralité de paramètres de modèle de détection pour générer une sortie qui définit des cadres de délimitation généré pour l'idée.
Chaque cadre de délimitation généré pour l'image est prédit pour contenir une paire clé-valeur comprenant des données textuelles critiques et des données textuelles de valeur, les données textuelles nécessaires définissant une étiquette qui caractérise les données de valeur textuelle.
Chacun des cadres de délimitation générés pour l'image : identifie les informations textuelles contenues dans le cadre de délimitation à l'aide d'une technique de reconnaissance optique de caractères ; déterminer si les données textuelles détenues par la boîte englobante définissent une paire clé-valeur ; et en réponse à la détermination que les données textuelles entourées par le cadre de délimitation représentent une paire clé-valeur, fournir le couple clé-valeur à utiliser pour caractériser le document.
Le modèle de détection est un modèle de réseau neuronal.
Le modèle de réseau neuronal comprend un réseau neuronal convolutionnel.
Le modèle de réseau neuronal est formé sur un ensemble d'exemples de formation. Chaque exemple d'apprentissage comprend une entrée d'apprentissage et une sortie cible ; l'entrée d'apprentissage comprend une image d'apprentissage d'un document d'apprentissage. La sortie cible contient des données définissant des cadres de délimitation dans l'image d'apprentissage renfermant une paire clé-valeur respective.
Le document est une facture.

La fourniture d'une image d'un document à un modèle de détection comprend : l'identification d'une classe particulière du papier ; et fournir l'idée du document à un modèle de détection qui est formé pour traiter des copies du type spécifique.
- Déterminer si les données textuelles comprises dans le cadre de délimitation définissent une paire clé-valeur comprend :
- décider que les informations textuelles possédées par la boîte englobante comprennent une clé parmi un ensemble prédéterminé de clés valides ;
- Trouver un type d'une partie de données textuelles détenues par la boîte englobante qui n'a pas la clé ; identifier un emplacement de variétés appropriées pour les valeurs correspondant à la clé
- Choisir que le style de la partie des données textuelles entourée par la boîte englobante qui n'inclut pas la clé soit inclus dans l'ensemble des types valides pour les valeurs correspondant à la clé.
- L'apprentissage qu'un ensemble de types valides pour les valeurs correspondant à la clé comprend : le mappage de la clé à la collection de types appropriés pour les valeurs correspondant à la clé à l'aide d'un mappage prédéterminé.
L'ensemble de clés valides et le mappage des clés aux emplacements correspondants de types appropriés pour les valeurs correspondant aux clés sont fournis par un utilisateur.
Les boîtes englobantes ont une forme rectangulaire.
Le procédé comprend en outre : la réception du document d'un utilisateur ; et convertir le papier en une image, la peinture représentant le document.
Procédé exécuté par le système de traitement de documents, le procédé comprenant :
- Fournir une image d'un document à un modèle de détection configuré pour traiter l'image afin d'identifier dans les cadres de délimitation d'image prévus pour contenir une paire clé-valeur comprenant des données textuelles critiques et des données textuelles de valeur, la clé définissant une étiquette qui caractérise une valeur correspondant à la clé ; pour chacun des rectangles englobants générés pour l'image,
- Identification des données textuelles contenues dans la boîte englobante à l'aide d'une technique de reconnaissance optique de caractères et détermination si les informations textuelles détenues par la boîte englobante définissent une paire clé-valeur
- Sortie de l'équipe clé-valeur à utiliser pour caractériser le document.
Le modèle de détection est un modèle d'apprentissage automatique avec des paramètres qui peuvent être entraînés sur un ensemble de données d'entraînement.
Le modèle d'apprentissage automatique comprend un modèle de réseau neuronal, en particulier un réseau neuronal convolutionnel.
Le modèle d'apprentissage automatique est formé sur un ensemble d'exemples de formation, et chaque exemple de formation a une entrée de formation et une sortie cible.
L'entrée d'apprentissage comprend une image d'apprentissage d'un document d'apprentissage. La sortie cible comprend des cadres de délimitation définissant les données dans l'image d'apprentissage qui renferment chacun une paire clé-valeur respective.
Le document est une facture.
La fourniture d'une image d'un document à un modèle de détection comprend : l'identification d'une classe particulière du papier ; et fournir l'idée du document à un modèle de détection qui est formé pour traiter des documents du type spécifique.
Est-ce une paire clé-valeur ?
Déterminer si les données textuelles comprises dans le cadre de délimitation définissent une paire clé-valeur signifie :
- Décider que les informations textuelles possédées par la boîte englobante comprennent une clé parmi un ensemble prédéterminé de clés valides
- Trouver un type d'une partie de données textuelles détenues par la boîte englobante qui n'a pas la clé
- Noter un emplacement des variétés appropriées pour les valeurs correspondant à la clé
- Choisir que le style de la partie des données textuelles entourée par la boîte englobante qui n'inclut pas la clé soit inclus dans l'ensemble des types valides pour les valeurs correspondant à la clé.
L'identification d'un ensemble de types valides pour les valeurs correspondant à la clé comprend : le mappage de la clé à la collection de types appropriés pour les valeurs correspondant à la clé à l'aide d'un mappage prédéterminé.
L'ensemble de clés valides et le mappage des clés aux emplacements correspondants de types appropriés pour les valeurs correspondant aux clés sont fournis par un utilisateur.
Les boîtes englobantes ont une forme rectangulaire.
Le procédé comprend en outre : la réception du document d'un utilisateur ; et convertir le papier en une image, la peinture représentant le document.
Selon un autre aspect, il existe un système comprenant : des ordinateurs ; et des dispositifs de stockage couplés à des ordinateurs, les dispositifs de stockage stockant des instructions qui, lorsqu'elles sont exécutées par des ordinateurs, amènent les ordinateurs à exécuter des opérations comprenant les opérations du procédé décrit précédemment.
Avantages de cette approche de traitement de documents
Le système décrit dans cette spécification peut être utilisé pour convertir un grand nombre de documents non structurés en paires clé-valeur structurées. Ainsi, le système évite d'avoir à extraire des données structurées à partir de documents non structurés, ce qui peut être coûteux, long et sujet aux erreurs.
Le système décrit dans cette spécification peut identifier des paires clé-valeur dans des documents avec un haut niveau de précision (par exemple, pour certains types de documents, avec une précision supérieure à 99 %). Ainsi, le système peut convenir à un déploiement dans des applications (par exemple, le traitement de documents financiers) qui nécessitent un haut niveau de précision.
Le système décrit dans cette spécification peut mieux généraliser que certains systèmes conventionnels, c'est-à-dire qu'il a des capacités de généralisation améliorées par rapport à certains procédés traditionnels.
En particulier, en tirant parti d'un modèle de détection appris par machine formé pour reconnaître les signaux visuels qui distinguent les paires clé-valeur dans les documents, le système peut identifier les paires clé-valeur du style, de la structure ou du contenu spécifique des articles.
Le brevet d'identification des paires clé-valeur dans le traitement de documents
Identification des paires clé-valeur dans les documents
Inventeurs : Yang Xu, Jiang Wang et Shengyang Dai
Cessionnaire : Google LLC
Brevet américain : 11 288 719
Attribué : 29 mars 2022
Date de dépôt : 27 février 2020
Abstrait
L'invention concerne des procédés, des systèmes et un appareil, comprenant des programmes informatiques codés sur un support de stockage informatique, pour convertir des documents non structurés en paires clé-valeur structurées.
Dans un aspect, un procédé comprend : la fourniture d'une image d'un document à un modèle de détection, dans lequel : le modèle de détection est configuré pour traiter l'image afin de générer une sortie qui définit des cadres de délimitation générés pour l'image ; et chaque boîte englobante générée pour l'image est prédite pour contenir une paire clé-valeur comprenant des données textuelles clés et des données textuelles de valeur, dans laquelle les données textuelles clés définissent une étiquette qui caractérise les données textuelles de valeur, et pour chacune des boîtes englobantes générées pour l'image : identification des données textuelles incluses dans la boîte englobante à l'aide d'une technique de reconnaissance optique de caractères, et détermination si les données textuelles incluses dans la boîte englobante définissent une paire clé-valeur.
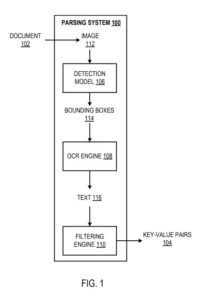
Un exemple de système d'analyse
Le système d'analyse est un exemple d'une méthode mise en œuvre sous forme de programmes informatiques sur des ordinateurs dans des emplacements où les systèmes, composants et techniques décrits ci-dessous sont mis en œuvre.
Le système d'analyse est configuré pour traiter un document (par exemple, une facture, un talon de paie ou un reçu de vente) afin d'identifier les paires clé-valeur dans le papier. Une « paire clé-valeur » fait référence à une clé et à une valeur correspondante, généralement des données textuelles. Les « données textuelles » doivent être comprises comme faisant référence au moins : aux caractères alphabétiques, aux chiffres et aux symboles spéciaux. Comme décrit précédemment, une clé définit une étiquette qui caractérise une valeur correspondante.
Le système peut recevoir le document de diverses manières.
Par exemple, le système peut recevoir le papier sous forme de téléchargement d'un utilisateur du système distant sur un réseau de communication de données (par exemple, en utilisant une interface de programmation d'application (API) rendue disponible par le système). Le document peut être représenté dans n'importe quel format de données non structuré approprié, par exemple, en tant que document PDF (Portable Document Format) ou en tant que document image (par exemple, un document Portable Network Graphics (PNG) ou Joint Photographic Experts Group (JPEG)).
Identifier les paires clé-valeur dans le traitement des documents
Le système utilise un modèle de détection, un moteur de reconnaissance optique de caractères (OCR) et un moteur de filtrage pour identifier les paires clé-valeur dans le traitement des documents.
Le modèle de détection est configuré pour traiter une image du document afin de générer une sortie qui définit les cadres de délimitation dans l'image. Chacun est prédit pour contenir des données textuelles représentant une paire clé-valeur respective. C'est-à-dire que chaque boîte englobante doit contenir des informations textuelles qui définissent :
(i) une clé, et
(ii) une valeur correspondant à la clé. Par exemple, une zone de délimitation peut contenir les données textuelles "Name : John Smith", qui définissent la clé "Name" et la valeur correspondante "John Smith". Le modèle de détection peut être configuré pour générer des boîtes englobantes qui renferment une seule paire clé-valeur (c'est-à-dire plutôt que de nombreux couples clé-valeur).
L'image du document est une collection ordonnée de valeurs numériques qui représentent l'aspect visuel du papier. L'image peut être une image en noir et blanc du document. Dans cet exemple, l'image peut être décrite comme un tableau bidimensionnel de valeurs d'intensité numériques. Comme autre exemple, l'image peut être une image couleur du document. Dans cet exemple, l'image peut être représentée comme une image multicanal. Chaque canal correspond à une couleur respective (par exemple, rouge, vert ou bleu) et est défini comme un tableau bidimensionnel de valeurs d'intensité numériques.
Les boîtes englobantes peuvent être des boîtes englobantes rectangulaires. Une boîte englobante rectangulaire peut être représentée par les coordonnées d'un coin particulier de la boîte englobante et la largeur et la hauteur correspondantes du conteneur englobant. Plus généralement, d'autres formes de boîtes englobantes et d'autres manières de représenter les boîtes englobantes sont possibles.
Alors que le modèle de détection peut reconnaître et utiliser tous les cadres ou bordures présents dans le document comme signaux visuels, les cadres de délimitation ne sont pas contraints de s'aligner (c'est-à-dire de coïncider) avec les structures de bordures existantes présentes dans le papier. De plus, le système peut générer les cadres de délimitation sans afficher les cadres de délimitation dans l'image du document.
C'est-à-dire que le système peut générer des données définissant les ensembles de délimitation sans donner de signe visuel de la position des boîtes de délimitation à un utilisateur du système.
Le modèle de détection est généralement un modèle d'apprentissage automatique, c'est-à-dire un modèle ayant un ensemble de paramètres pouvant être entraînés sur un ensemble de données d'apprentissage. Les données de formation comprennent de nombreux exemples de formation, dont chacun comprend :
(i) une image de formation qui représente un document de formation, et
(ii) une sortie cible qui définit des cadres de délimitation enferme une paire clé-valeur respective dans l'image d'apprentissage.
Les données d'apprentissage peuvent être générées par annotation manuelle, c'est-à-dire par une personne identifiant des cadres de délimitation autour de paires clé-valeur dans le document d'apprentissage (par exemple, à l'aide d'un logiciel d'annotation approprié).
Entraîner le modèle de détection à l'aide de techniques d'apprentissage automatique sur un ensemble de données d'apprentissage lui permet de reconnaître des signaux visuels qui lui permettront d'identifier des paires clé-valeur dans des documents. Par exemple, le modèle de détection peut être formé pour reconnaître les signaux locaux (par exemple, les styles de texte et les positions spatiales relatives des mots) et les signaux globaux (par exemple, la présence de bordures dans le document) pour identifier les paires clé-valeur.

Les repères visuels qui permettent au modèle de détection de mémoriser les équipes de valeurs-clés dans les enregistrements n'incluent généralement pas de signaux représentant la signification explicite des mots dans le document.
Signaux visuels qui distinguent les paires clé-valeur
La formation du modèle de détection pour reconnaître les signaux visuels qui distinguent les paires clé-valeur dans les documents permet au modèle de détection de « généraliser » au-delà des données de formation utilisées pour préparer le modèle de détection. Le modèle de détection formé peut traiter une image représentant un document pour générer des cadres de délimitation contenant des paires clé-valeur dans le document même si la copie n'a pas été incluse dans les données de formation utilisées pour former le modèle de détection.
Dans un exemple, le modèle de détection peut être un modèle de détection d'objets de réseau neuronal (par exemple, comprenant des réseaux neuronaux convolutifs), où les "objets" correspondent à des paires clé-valeur dans le document. Les paramètres pouvant être entraînés du modèle de réseau neuronal comprennent les poids du modèle de réseau neuronal, par exemple, des poids qui définissent des filtres convolutionnels dans le modèle de réseau neuronal.
Le modèle de réseau neuronal peut être formé sur l'ensemble de données de formation à l'aide d'une procédure de formation d'apprentissage automatique appropriée, par exemple, une descente de gradient stochastique. En particulier, à chaque itération d'apprentissage, le modèle de réseau neuronal peut traiter des images d'apprentissage à partir d'un "lot" (c'est-à-dire un ensemble) d'exemples d'apprentissage pour générer des cadres de délimitation prévus pour enfermer des paires clé-valeur respectives dans les images d'apprentissage. Le système peut tester une fonction cible qui caractérise une mesure de similarité entre les cadres de délimitation générés par le modèle de réseau neuronal et les cadres de délimitation spécifiés par les sorties cibles correspondantes des exemples d'apprentissage.
La mesure de similarité entre deux boîtes englobantes peut être, par exemple, une somme des distances au carré entre les sommets respectifs des boîtes englobantes. Le système peut déterminer les gradients de la fonction de visée par rapport aux valeurs des paramètres du réseau neuronal (par exemple, en utilisant la rétropropagation) et ensuite utiliser les pentes pour ajuster les valeurs actuelles des paramètres du réseau neuronal.
En particulier, le système peut utiliser la règle de mise à jour des paramètres de tout algorithme d'optimisation de descente de gradient approprié (par exemple, Adam ou RMSprop) pour ajuster les valeurs actuelles des paramètres du réseau neuronal à l'aide des gradients. Le système entraîne le modèle de réseau neuronal jusqu'à ce qu'un critère de fin d'apprentissage soit satisfait (par exemple, jusqu'à ce qu'un nombre prédéterminé d'itérations d'apprentissage ait été effectué ou qu'un changement de la valeur de la fonction de visée d'objet entre les itérations d'apprentissage tombe en dessous d'un seuil prédéterminé).
Avant d'utiliser le modèle de détection, le système peut identifier une « classe » du document (par exemple, facture, talon de paie ou ticket de caisse). Un utilisateur du système peut identifier la classe de l'enregistrement lors de la fourniture du document au système. Le procédé peut utiliser un réseau neuronal de classification pour classer la classe de l'article. Le système peut utiliser des techniques OCR pour identifier le texte dans le document et, après cela, placer le style du document sur la base du texte dans le document. Dans un exemple particulier, en réponse à la détermination de l'expression "Paiement net", le système peut identifier la classe de papier comme un "talon de paie".
Dans un autre exemple particulier, en réponse à l'identification de l'expression "Taxe de vente", le système peut identifier la classe du document comme "facture". Après avoir identifié la classe particulière de l'enregistrement, le système peut utiliser un modèle de détection qui est formé pour traiter des copies de la classe spécifique. Le procédé peut utiliser un modèle de détection qui a été formé sur des données de formation qui ne comprenaient que des documents de la même classe particulière que le document.
L'utilisation d'un modèle de détection entraîné à traiter des documents de la même classe que le document peut améliorer les performances du modèle de détection (par exemple, en permettant au modèle de détection de générer des cadres de délimitation autour de paires clé-valeur avec une plus grande précision).
Pour chaque boîte englobante, le système traite la partie de l'image entourée par la boîte englobante à l'aide du moteur OCR pour identifier les données textuelles (c'est-à-dire le texte) détenues par la boîte englobante. En particulier, le moteur OCR identifie le texte entouré d'un cadre de délimitation en identifiant chaque caractère alphabétique, numérique ou unique contenu dans le cadre de délimitation. Le moteur OCR peut utiliser n'importe quelle technique appropriée pour identifier le texte entouré d'une boîte englobante.
Le moteur de filtrage détermine si le texte entouré d'un cadre de délimitation représente une paire clé-valeur. Le moteur de filtrage peut décider si le texte entourant le cadre de délimitation représente une paire clé-valeur de manière appropriée. Par exemple, le moteur de filtrage peut déterminer si le texte entouré par la boîte englobante comprend une clé valide à partir d'un ensemble prédéterminé de clés droites pour une boîte englobante donnée. Par exemple, la collection de clés valides peut consister en : "Date", "Heure", "Numéro de facture", "Montant dû", etc.
En comparant différentes parties de texte pour déterminer si le texte entouré par la boîte englobante comprend une clé valide, le moteur de filtrage peut déterminer que deux morceaux de texte « correspondent » même s'ils ne sont pas identiques. Par exemple, le moteur de filtrage peut déterminer que deux parties du lecteur correspondent même si elles incluent des majuscules ou des signes de ponctuation différents (par exemple, le système de filtrage peut déterminer que « Date », « Date : », « date » et « date : » correspondent tous).
En réponse à la détermination que le texte entouré par la boîte englobante n'inclut pas une clé valide parmi les bonnes clés, le moteur de filtrage détermine que le texte entouré par la boîte englobante ne représente pas une paire clé-valeur.
En réponse à la détermination que le texte entouré par la boîte englobante comprend une clé valide, le moteur de filtrage identifie un "type" (par exemple, alphabétique, numérique, temporel) de la partie de texte entourée par la boîte englobante non identifiée comme la clé ( c'est-à-dire le texte "non clé"). Par exemple, pour un cadre englobant contenant le texte : "Date : 23/02/2019", où le moteur de filtrage identifie "Date :" comme clé (comme décrit précédemment), le moteur de filtrage peut identifier le type de non -texte clé « 23-02-2019 » comme étant « temporel ».
Outre l'identification du type du texte non clé, le moteur de filtrage identifie un ensemble de types valides pour les valeurs correspondant à la clé. En particulier, le moteur de filtrage peut mapper la clé à un groupe de types de données utiles pour des valeurs correspondant à la clé par un mappage prédéterminé. Par exemple, le moteur de filtrage peut mapper la clé "Nom" au type de données de valeur correspondant "alphabétique", indiquant que la valeur correspondant à la clé doit avoir un type de données alphabétique (par exemple, "John Smith").
Comme autre exemple, le moteur de filtrage peut mapper la clé "Date" au type de données de valeur correspondant "temporel", indiquant que la valeur correspondant à la clé doit avoir un type de données temporel (par exemple, "2-23-2019" ou " 17:30:22").
Le moteur de filtrage détermine si le type du texte non clé est inclus dans l'ensemble des types valides pour les valeurs correspondant à la clé. En réponse à la détermination que le style du texte non clé est inclus dans la collection de types appropriés pour les valeurs correspondant à la légende, le moteur de filtrage détermine que le texte entouré par la boîte englobante représente une paire clé-valeur. En particulier, le moteur de filtrage identifie le texte non clé comme la valeur correspondant à la clé. Sinon, le moteur de filtrage détermine que le texte entouré par le cadre de délimitation ne représente pas une paire clé-valeur.
L'ensemble de clés valides et le mappage des bonnes clés aux emplacements des types de données utiles pour les valeurs correspondant aux clés valides peuvent être fournis par un utilisateur du système (par exemple, via une API mise à disposition par le système).
Après avoir identifié les paires clé-valeur à partir du texte entouré par les cadres de délimitation respectifs à l'aide du moteur de filtrage, le système génère les paires clé-valeur identifiées. Par exemple, le système peut fournir les équipes clé-valeur à un utilisateur distant du système sur un réseau de communication de données (par exemple, en utilisant une API mise à disposition par le système). Comme autre exemple, le système peut stocker des données définissant les paires clé-valeur identifiées dans une base de données (ou une autre structure de données) accessible à l'utilisateur du système.
Dans certains cas, un utilisateur du système peut demander que le système identifie la valeur correspondant à la clé particulière dans le document (par exemple, "N° de facture"). Dans ces cas, plutôt que d'identifier et de fournir chaque paire clé-valeur dans l'enregistrement, le système peut traiter le texte placé dans les cadres de délimitation respectifs jusqu'à ce que l'équipe clé-valeur demandée reconnaisse et exécute la paire clé-valeur commandée.
Comme décrit ci-dessus, le modèle de détection peut être formé pour générer des cadres de délimitation qui renferment chacun une paire clé-valeur respective. Ou, plutôt que d'utiliser un seul modèle de détection, le système peut inclure :
(i) un "modèle de détection de clé" qui est formé pour générer des boîtes englobantes qui contiennent des clés respectives, et
(ii) un « modèle de détection de valeur » qui est formé pour générer des boîtes englobantes qui contiennent des valeurs respectives.
Le système peut identifier les paires clé-valeur à partir des cadres de délimitation de clé et des cadres de délimitation de valeur de manière appropriée. Par exemple, pour chaque équipe de cadres de délimitation qui comprend un cadre de délimitation de clé et un cadre de délimitation de valeur, le système peut générer un « score de correspondance » basé sur :
(i) la proximité spatiale des boîtes englobantes,
(ii) si la boîte englobante de clé contient une clé valide, et
(iii) si le type de la valeur entourée par la boîte englobante de la valeur est inclus dans un ensemble de types valides pour les valeurs correspondant à la clé.
Le système peut identifier la clé entourée par un cadre de délimitation de clé et la valeur entourée par un cadre de délimitation de valeur en tant que paire clé-valeur si le score de correspondance entre le cadre de délimitation de clé et le cadre de délimitation de valeur dépasse un seuil.
Un exemple de document de facturation
Un utilisateur du système de traitement de documents peut fournir la facture (par exemple, sous la forme d'une image numérisée ou d'un fichier PDF) au système d'analyse syntaxique.
Les boîtes englobantes sont générées par le modèle de détection du système d'analyse syntaxique. Chaque boîte englobante est censée contenir des données textuelles qui définissent une paire clé-valeur. Le modèle de détection ne génère pas de cadre de délimitation contenant du texte (c'est-à-dire « Merci pour votre entreprise ! ») puisque ce texte ne représente pas une paire clé-valeur.
Le système d'analyse utilise des techniques OCR pour identifier le texte à l'intérieur de chaque boîte englobante et identifie ensuite les bonnes paires clé-valeur entourées par les boîtes englobantes.
La clé (c'est-à-dire « Date : ») et la valeur (c'est-à-dire « 23/02/2019 ») sont entourées par la boîte englobante.
Paires clé-valeur et traitement de documents
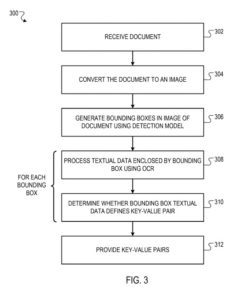
Un système d'analyse syntaxique programmé par cette spécification peut effectuer un traitement de document.
Le système reçoit un document sous la forme d'un téléchargement d'un utilisateur du système à distance sur un réseau de communication de données (par exemple, à l'aide d'une API mise à disposition par le système). Le document peut être représenté dans n'importe quel format de données non structuré approprié, tel qu'un document PDF ou un document image (par exemple, un document PNG ou JPEG).
Le système convertit le document en une image, c'est-à-dire une collection ordonnée de valeurs numériques qui représente l'apparence visuelle du papier. Par exemple, l'image peut être une image en noir et blanc du document qui est décrite comme un tableau bidimensionnel de valeurs d'intensité numériques.
Par un ensemble de paramètres de modèle de détection pour générer une sortie qui définit les cadres de délimitation dans l'image du document. Chaque boîte englobante est prédite pour contenir une paire clé-valeur comprenant des données textuelles critiques et des données textuelles de valeur, où la clé définit une étiquette qui caractérise la valeur.
Le modèle de détection peut être un modèle de détection d'objet qui comprend des réseaux neuronaux convolutifs.
Rechercher des actualités directement dans votre boîte de réception
*Obligatoire