
Processamento de documentos usando pares de valores-chave estruturados
Publicados: 2022-03-31Por que pares de valores-chave neste sistema de processamento de documentos?
Escrever este post me lembrou de um post de 2007 que escrevi sobre pesquisa local e dados estruturados, onde os pares de valores-chave eram um aspecto importante dessa patente de 2007. A postagem foi:
Informações Estruturadas na Pesquisa Local do Google.
Achei interessante ver o Google escrevendo sobre a inserção de pares de valores-chave em um sistema de processamento de documentos como este aqui, com uma abordagem de aprendizado de máquina em sua essência, entrando em SEO técnico.
Os usos de Ppairs de valor-chave ainda são importantes agora, após 15 anos.
Processamento de documentos no Google
Compreender o processamento de documentos (por exemplo, faturas, recibos de pagamento, recibos de vendas e similares) é uma necessidade empresarial crucial. Uma grande fração (por exemplo, 90% ou mais) dos dados corporativos é armazenada e representada em documentos não estruturados. Extrair dados estruturados de registros pode ser caro, demorado e propenso a erros.
Esta patente descreve um sistema de análise de processamento de documentos e um método implementado como programas de computador em computadores em locais que convertem documentos não estruturados em pares de valores-chave estruturados.
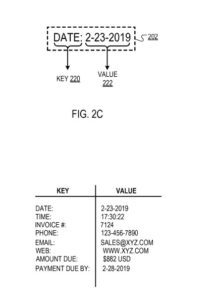
O sistema de análise é configurado para documentar o processamento para identificar dados textuais “chave” e dados textuais de “valor” correspondentes no papel. A chave define um rótulo que caracteriza (ou seja, é descritivo de) um valor correspondente.
Por exemplo, a chave “Data” pode corresponder ao valor “23-23-2019”.
Existe um método realizado pelo aparelho de processamento de dados, que fornece uma imagem de um documento para um modelo de detecção, em que: o modelo de detecção é configurado para processar a imagem por valores de uma pluralidade de parâmetros do modelo de detecção para gerar uma saída que define caixas delimitadoras gerado para a ideia.
Cada caixa delimitadora gerada para a imagem é prevista para incluir um par chave-valor que compreende dados textuais críticos e dados textuais de valor, em que os dados textuais necessários definem um rótulo que caracteriza os dados textuais de valor.
Cada uma das caixas delimitadoras geradas para a imagem: identifica as informações textuais contidas na caixa delimitadora usando uma técnica de reconhecimento óptico de caracteres; determinar se os dados textuais mantidos pela caixa delimitadora definem um par chave-valor; e em resposta à determinação de que os dados textuais incluídos na caixa delimitadora representam um par chave-valor, fornecendo o par chave-valor para uso na caracterização do documento.
O modelo de detecção é um modelo de rede neural.
O modelo de rede neural compreende uma rede neural convolucional.
O modelo de rede neural é treinado em um conjunto de exemplos de treinamento. Cada exemplo de treinamento compreende uma entrada de treinamento e uma saída de destino; a entrada de treinamento inclui uma imagem de treinamento de um documento de treinamento. A saída de destino contém dados que definem caixas delimitadoras na imagem de treinamento que inclui um respectivo par de valores-chave.
O documento é uma fatura.

Fornecer uma imagem de um documento para um modelo de detecção compreende: identificar uma classe particular do papel; e fornecer a ideia do documento a um modelo de detecção que é treinado para processar cópias do tipo específico.
- Determinar se os dados textuais delimitados pela caixa delimitadora definem um par chave-valor compreende:
- Decidir que a informação textual possuída pela caixa delimitadora inclui uma chave de um conjunto predeterminado de chaves válidas;
- Encontrar um tipo de parte de dados textuais mantidos pela caixa delimitadora que não possui a chave; identificar uma localização de variedades adequadas para valores correspondentes à chave
- Escolhendo que o estilo da parte dos dados textuais delimitada pela caixa delimitadora que não inclui a chave seja incluída no conjunto de tipos válidos para valores correspondentes à chave.
- Aprender que um conjunto de tipos válidos para valores correspondentes à chave compreende: mapear a chave para a coleção de tipos adequados para valores correspondentes à chave usando um mapeamento predeterminado.
O conjunto de chaves válidas e o mapeamento de chaves para locais correspondentes de tipos adequados para valores correspondentes às chaves são fornecidos por um usuário.
As caixas delimitadoras têm uma forma retangular.
O método compreende ainda: receber o documento de um usuário; e converter o papel em uma imagem, em que a pintura retrata o documento.
Um método realizado pelo sistema de processamento de documentos, o método compreendendo:
- Fornecer uma imagem de um documento para um modelo de detecção configurado para processar a imagem para identificar nas caixas delimitadoras de imagem previstas para incluir um par de valor-chave compreendendo dados textuais críticos e dados textuais de valor, em que a chave define um rótulo que caracteriza um valor correspondente para a chave; para cada uma das caixas delimitadoras geradas para a imagem,
- Identificando dados textuais contidos pela caixa delimitadora usando uma técnica de reconhecimento óptico de caracteres e determinando se as informações textuais mantidas pela caixa delimitadora definem um par chave-valor
- Saída da equipe de valor-chave para uso na caracterização do documento.
O modelo de detecção é um modelo de aprendizado de máquina com parâmetros que podem ser treinados em um conjunto de dados de treinamento.
O modelo de aprendizado de máquina compreende um modelo de rede neural, particularmente uma rede neural convolucional.
O modelo de aprendizado de máquina é treinado em um conjunto de exemplos de treinamento e cada exemplo de treinamento tem uma entrada de treinamento e uma saída de destino.
A entrada de treinamento compreende uma imagem de treinamento de um documento de treinamento. A saída de destino inclui caixas delimitadoras de definição de dados na imagem de treinamento, cada uma contendo um respectivo par chave-valor.
O documento é uma fatura.
Fornecer uma imagem de um documento para um modelo de detecção compreende: identificar uma classe particular do papel; e fornecer a ideia do documento a um modelo de detecção que é treinado para processar documentos do tipo específico.
É um par chave-valor?
Determinar se os dados textuais delimitados pela caixa delimitadora definem um par chave-valor significa:
- Decidir que a informação textual possuída pela caixa delimitadora inclui uma chave de um conjunto predeterminado de chaves válidas
- Encontrar um tipo de parte de dados textuais mantidos pela caixa delimitadora que não possui a chave
- Observando uma localização de variedades adequadas para valores correspondentes à chave
- Escolher que o estilo da parte dos dados textuais entre a caixa delimitadora que não inclui a chave seja incluído no conjunto de tipos válidos para valores correspondentes à chave.
A identificação de um conjunto de tipos válidos para valores correspondentes à chave compreende: mapear a chave para a coleção de tipos apropriados para valores correspondentes à chave usando um mapeamento predeterminado.
O conjunto de chaves válidas e o mapeamento de chaves para locais correspondentes de tipos adequados para valores correspondentes às chaves são fornecidos por um usuário.
As caixas delimitadoras têm uma forma retangular.
O método compreende ainda: receber o documento de um usuário; e converter o papel em uma imagem, em que a pintura retrata o documento.
De acordo com outro aspecto, existe um sistema composto por: computadores; e dispositivos de armazenamento acoplados a computadores, em que os dispositivos de armazenamento armazenam instruções que, quando executadas por computadores, fazem com que os computadores executem operações compreendendo as operações do método descrito anteriormente.
Vantagens desta abordagem de processamento de documentos
O sistema descrito nesta especificação pode ser usado para converter um grande número de documentos não estruturados em pares de valores-chave estruturados. Assim, o sistema evita a necessidade de extrair dados estruturados de documentos não estruturados, que podem ser caros, demorados e propensos a erros.
O sistema descrito nesta especificação pode identificar pares de valores-chave em documentos com alto nível de precisão (por exemplo, para alguns tipos de documentos, com precisão superior a 99%). Assim, o sistema pode ser adequado para implantação em aplicativos (por exemplo, processamento de documentos financeiros) que precisam de um alto nível de precisão.
O sistema descrito nesta especificação pode generalizar melhor do que alguns sistemas convencionais, ou seja, possui capacidades de generalização aprimoradas em comparação com alguns métodos tradicionais.
Em particular, aproveitando um modelo de detecção aprendido por máquina treinado para reconhecer sinais visuais que distinguem pares de valores-chave em documentos, o sistema pode identificar pares de valores-chave do estilo, estrutura ou conteúdo específico dos documentos.
A identificação de pares de valores-chave na patente de processamento de documentos
Identificando pares de valores-chave em documentos
Inventores: Yang Xu, Jiang Wang e Shengyang Dai
Responsável: Google LLC
Patente dos EUA: 11.288.719
Concedido: 29 de março de 2022
Arquivado: 27 de fevereiro de 2020
Resumo
Métodos, sistemas e aparelhos, incluindo programas de computador codificados em um meio de armazenamento de computador, para converter documentos não estruturados em pares de valores-chave estruturados.
Em um aspecto, um método compreende: fornecer uma imagem de um documento para um modelo de detecção, em que: o modelo de detecção é configurado para processar a imagem para gerar uma saída que define caixas delimitadoras geradas para a imagem; e cada caixa delimitadora gerada para a imagem é prevista para incluir um par de valores-chave compreendendo dados textuais-chave e dados textuais de valor, em que os dados textuais-chave definem um rótulo que caracteriza os dados textuais de valor e para cada uma das caixas delimitadoras geradas para a imagem: identificar dados textuais incluídos pela caixa delimitadora usando uma técnica de reconhecimento óptico de caracteres e determinar se os dados textuais delimitados pela caixa delimitadora definem um par chave-valor.
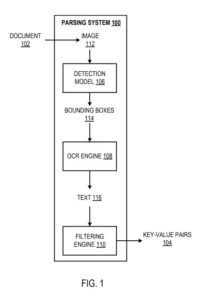
Um exemplo de sistema de análise
O sistema de análise sintática é um exemplo de um método implementado como programas de computador em computadores em locais onde os sistemas, componentes e técnicas descritos abaixo são implementados.
O sistema de análise é configurado para processar um documento (por exemplo, uma fatura, recibo de pagamento ou recibo de venda) para identificar pares de valores-chave no papel. Um “par chave-valor” refere-se a uma chave e um valor correspondente, geralmente dados textuais. “Dados textuais” devem ser entendidos como se referindo a pelo menos: caracteres alfabéticos, números e símbolos especiais. Conforme descrito anteriormente, uma chave define um rótulo que caracteriza um valor correspondente.
O sistema pode receber o documento de várias maneiras.
Por exemplo, o sistema pode receber o papel como um upload de um usuário remoto do sistema através de uma rede de comunicação de dados (por exemplo, usando uma interface de programação de aplicativos (API) disponibilizada pelo sistema). O documento pode ser representado em qualquer formato de dados não estruturado apropriado, por exemplo, como um documento Portable Document Format (PDF) ou como um documento de imagem (por exemplo, um documento Portable Network Graphics (PNG) ou Joint Photographic Experts Group (JPEG)).
Identificar pares de valores-chave no processamento de documentos
O sistema usa um modelo de detecção, um mecanismo de reconhecimento óptico de caracteres (OCR) e um mecanismo de filtragem para identificar pares de valores-chave no processamento de documentos.
O modelo de detecção é configurado para processar uma imagem do documento para gerar uma saída que define caixas delimitadoras na imagem. Cada um é previsto para incluir dados textuais que representam um respectivo par de valores-chave. Ou seja, espera-se que cada caixa delimitadora tenha informações textuais que definem:
(i) uma chave, e
(ii) um valor correspondente à chave. Por exemplo, uma caixa delimitadora pode incluir os dados textuais “Nome: João Silva”, que define a chave “Nome” e o valor correspondente “João Silva”. O modelo de detecção pode ser configurado para gerar caixas delimitadoras que encerram um único par chave-valor (ou seja, em vez de muitos pares chave-valor).
A imagem do documento é uma coleção ordenada de valores numéricos que representam a aparência visual do papel. A imagem pode ser uma imagem em preto e branco do documento. Neste exemplo, a imagem pode ser descrita como uma matriz bidimensional de valores numéricos de intensidade. Como outro exemplo, a imagem pode ser uma imagem colorida do documento. Neste exemplo, a imagem pode ser representada como uma imagem multicanal. Cada canal corresponde a uma cor respectiva (por exemplo, vermelho, verde ou azul) e é definido como uma matriz bidimensional de valores numéricos de intensidade.
As caixas delimitadoras podem ser caixas delimitadoras retangulares. Uma caixa delimitadora retangular pode ser representada pelas coordenadas de um canto específico da caixa delimitadora e pela largura e altura correspondentes do contêiner delimitador. Mais geralmente, outras formas de caixa delimitadora e outras formas de representar as caixas delimitadoras são possíveis.
Embora o modelo de detecção possa reconhecer e usar quaisquer molduras ou bordas presentes no documento como sinais visuais, as caixas delimitadoras não são restringidas para alinhar (ou seja, ser coincidentes) com quaisquer estruturas de fronteiras existentes no papel. Além disso, o sistema pode gerar as caixas delimitadoras sem exibir as caixas delimitadoras na imagem do documento.
Ou seja, o sistema pode gerar dados definindo os pacotes delimitadores sem dar um sinal visual da posição das caixas delimitadoras para um usuário do sistema.
O modelo de detecção geralmente é um modelo de aprendizado de máquina, ou seja, um modelo com um conjunto de parâmetros que podem ser treinados em um conjunto de dados de treinamento. Os dados de treinamento incluem muitos exemplos de treinamento, cada um dos quais inclui:
(i) uma imagem de treinamento que retrata um documento de treinamento, e
(ii) uma saída de destino que define caixas delimitadoras inclui um respectivo par chave-valor na imagem de treinamento.
Os dados de treinamento podem ser gerados por anotação manual, ou seja, por uma pessoa identificando caixas delimitadoras em torno de pares de valores-chave no documento de treinamento (por exemplo, usando um software de anotação apropriado).
Treinar o modelo de detecção usando técnicas de aprendizado de máquina em um conjunto de dados de treinamento permite que ele reconheça sinais visuais que permitirão identificar pares de valores-chave em documentos. Por exemplo, o modelo de detecção pode ser treinado para reconhecer sinais locais (por exemplo, estilos de texto e as posições espaciais relativas das palavras) e sinais globais (por exemplo, a presença de bordas no documento) para identificar pares de valores-chave.

As dicas visuais que permitem que o modelo de detecção lembre as equipes de valores-chave nos registros geralmente não incluem sinais que representam o significado explícito das palavras no documento.
Sinais visuais que distinguem pares de valores-chave
Treinar o modelo de detecção para reconhecer sinais visuais que distinguem pares de valores-chave em documentos permite que o modelo de detecção "generalize" além dos dados de treinamento usados para preparar o modelo de detecção. O modelo de detecção treinado pode processar uma imagem que descreve um documento para gerar caixas delimitadoras envolvendo pares de valores-chave no papel, mesmo que a cópia não tenha sido incluída nos dados de treinamento usados para treinar o modelo de detecção.
Em um exemplo, o modelo de detecção pode ser um modelo de detecção de objeto de rede neural (por exemplo, incluindo redes neurais convolucionais), em que os "objetos" correspondem a pares chave-valor no documento. Os parâmetros treináveis do modelo de rede neural incluem os pesos do modelo de rede neural, por exemplo, pesos que definem filtros convolucionais no modelo de rede neural.
O modelo de rede neural pode ser treinado no conjunto de dados de treinamento usando um procedimento de treinamento de aprendizado de máquina apropriado, por exemplo, descida de gradiente estocástica. Em particular, em cada iteração de treinamento, o modelo de rede neural pode processar imagens de treinamento de um "lote" (ou seja, um conjunto) de exemplos de treinamento para gerar caixas delimitadoras previstas para incluir os respectivos pares de valores-chave nas imagens de treinamento. O sistema pode testar uma função objetivo que caracteriza uma medida de similaridade entre as caixas delimitadoras geradas pelo modelo de rede neural e as caixas delimitadoras especificadas pelas saídas alvo correspondentes dos exemplos de treinamento.
A medida de similaridade entre duas caixas delimitadoras pode ser, por exemplo, uma soma das distâncias quadradas entre os respectivos vértices das caixas delimitadoras. O sistema pode determinar os gradientes da função objetivo ganhou os valores dos parâmetros da rede neural (por exemplo, usando backpropagation) e depois disso usar as inclinações para ajustar os valores atuais dos parâmetros da rede neural.
Em particular, o sistema pode usar a regra de atualização de parâmetro de qualquer algoritmo de otimização de descida de gradiente apropriado (por exemplo, Adam ou RMSprop) para ajustar os valores atuais dos parâmetros da rede neural usando os gradientes. O sistema treina o modelo de rede neural até que um critério de término de treinamento seja atendido (por exemplo, até que um número predeterminado de iterações de treinamento tenha sido realizado ou uma mudança no valor da função objetivo do objeto entre as iterações de treinamento caia abaixo de um limite predeterminado).
Antes de usar o modelo de detecção, o sistema pode identificar uma “classe” do documento (por exemplo, fatura, recibo de pagamento ou recibo de venda). Um usuário do sistema pode identificar a classe do registro ao fornecer o documento ao sistema. O método pode usar uma rede neural de classificação para classificar a classe do papel. O sistema pode utilizar técnicas de OCR para identificar o texto no documento e, em seguida, colocar o estilo do documento com base no texto do documento. Em um exemplo específico, em resposta à determinação da frase "Pagamento Líquido", o sistema pode identificar a classe de papel como um "contrato de pagamento".
Em outro exemplo específico, em resposta à identificação da frase “imposto sobre vendas”, o sistema pode identificar a classe do documento como “fatura”. Depois de identificar a classe específica do registro, o sistema pode usar um modelo de detecção que é treinado para processar cópias da classe específica. O método pode usar um modelo de detecção que foi treinado em dados de treinamento que incluíam apenas documentos da mesma classe específica do documento.
O uso de um modelo de detecção treinado para processar documentos da mesma classe que o documento pode melhorar o desempenho do modelo de detecção (por exemplo, permitindo que o modelo de detecção gere caixas delimitadoras em torno de pares chave-valor com maior precisão).
Para cada caixa delimitadora, o sistema processa a parte da imagem delimitada pela caixa delimitadora usando o mecanismo de OCR para identificar os dados textuais (ou seja, o texto) contidos pela caixa delimitadora. Em particular, o mecanismo de OCR identifica o texto delimitado por uma caixa delimitadora, identificando cada caractere alfabético, numérico ou exclusivo delimitado pela caixa delimitadora. O mecanismo de OCR pode usar qualquer técnica apropriada para identificar o texto cercado por uma caixa delimitadora.
O mecanismo de filtragem determina se o texto entre uma caixa delimitadora representa um par chave-valor. O mecanismo de filtragem pode decidir se o texto ao redor da caixa delimitadora representa um par chave-valor adequadamente. Por exemplo, o mecanismo de filtragem pode determinar se o texto delimitado pela caixa delimitadora inclui uma chave válida de um conjunto predeterminado de chaves certas para uma determinada caixa delimitadora. Por exemplo, a coleção de chaves válidas pode consistir em: “Data”, “Hora”, “Nº da fatura”, “Valor devido” e similares.
Ao comparar diferentes partes do texto para determinar se o texto incluído na caixa delimitadora inclui uma chave válida, o mecanismo de filtragem pode determinar que duas partes do texto são "correspondentes", mesmo que não sejam idênticas. Por exemplo, o mecanismo de filtragem pode determinar que duas partes do leitor são correspondentes, mesmo que incluam letras maiúsculas ou pontuação diferentes (por exemplo, o sistema de filtragem pode determinar que "Data", "Data:" "data" e "data:" são todos correspondentes).
Em resposta à determinação de que o texto delimitado pela caixa delimitadora não inclui uma chave válida das chaves corretas, o mecanismo de filtragem determina que o texto delimitado pela caixa delimitadora não representa um par chave-valor.
Em resposta à determinação de que o texto delimitado pela caixa delimitadora inclui uma chave válida, o mecanismo de filtragem identifica um "tipo" (por exemplo, alfabético, numérico, temporal) da parte do texto delimitada pela caixa delimitadora não identificada como a chave ( ou seja, o texto “não-chave”). Por exemplo, para uma caixa delimitadora que tenha o texto: “Data: 23-2-2019”, onde o mecanismo de filtragem identifica “Data:” como a chave (conforme descrito anteriormente), o mecanismo de filtragem pode identificar o tipo de não -key text “2-23-2019” como sendo “temporal”.
Além de identificar o tipo do texto não-chave, o mecanismo de filtragem identifica um conjunto de tipos válidos para os valores correspondentes à chave. Em particular, o mecanismo de filtragem pode mapear a chave para um grupo de tipos de dados úteis para valores correspondentes à chave por um mapeamento predeterminado. Por exemplo, o mecanismo de filtragem pode mapear a chave “Nome” para o tipo de dados de valor correspondente “alfabético”, indicando que o valor correspondente à chave deve ter um tipo de dados alfabético (por exemplo, “John Smith”).
Como outro exemplo, o mecanismo de filtragem pode mapear a chave "Data" para o tipo de dados de valor correspondente "temporal", indicando que o valor correspondente à chave deve ter um tipo de dados temporal (por exemplo, "23-23-2019" ou " 17:30:22”).
O mecanismo de filtragem determina se o tipo de texto não chave é incluído no conjunto de tipos válidos para valores correspondentes à chave. Em resposta à determinação de que o estilo do texto não-chave seja incluído na coleção de tipos adequados para valores correspondentes à legenda, o mecanismo de filtragem determina que o texto entre a caixa delimitadora representa um par chave-valor. Em particular, o mecanismo de filtragem identifica o texto sem chave como o valor correspondente à chave. Caso contrário, o mecanismo de filtragem determina que o texto entre a caixa delimitadora não representa um par chave-valor.
O conjunto de chaves válidas e o mapeamento das chaves corretas para locais de tipos de dados úteis para valores correspondentes às chaves válidas podem ser fornecidos por um usuário do sistema (por exemplo, por meio de uma API disponibilizada pelo sistema).
Depois de identificar os pares de valores-chave do texto entre as respectivas caixas delimitadoras usando o mecanismo de filtragem, o sistema gera os pares de valores-chave identificados. Por exemplo, o sistema pode fornecer as equipes de valores-chave para um usuário remoto do sistema por meio de uma rede de comunicação de dados (por exemplo, usando uma API disponibilizada pelo sistema). Como outro exemplo, o sistema pode armazenar dados que definem os pares chave-valor identificados em um banco de dados (ou outra estrutura de dados) acessível ao usuário do sistema.
Em alguns casos, um usuário do sistema pode solicitar que o sistema identifique o valor correspondente à chave específica no documento (por exemplo, “Nº da fatura”). Nesses casos, em vez de identificar e fornecer cada par de chave-valor no registro, o sistema pode processar o texto colocado nas respectivas caixas delimitadoras até que a equipe de chave-valor solicitada reconheça e execute o par de chave-valor ordenado.
Conforme descrito acima, o modelo de detecção pode ser treinado para gerar caixas delimitadoras, cada uma com um respectivo par chave-valor. Ou, em vez de usar um único modelo de detecção, o sistema pode incluir:
(i) um “modelo de detecção de chave” que é treinado para gerar caixas delimitadoras que incluem as respectivas chaves, e
(ii) um “modelo de detecção de valor” que é treinado para gerar caixas delimitadoras que incluem os respectivos valores.
O sistema pode identificar os pares chave-valor das caixas delimitadoras de chave e das caixas delimitadoras de valor apropriadamente. Por exemplo, para cada equipe de caixas delimitadoras que inclui uma caixa delimitadora de chave e uma caixa delimitadora de valor, o sistema pode gerar uma “pontuação de correspondência” com base em:
(i) a proximidade espacial das caixas delimitadoras,
(ii) se a caixa delimitadora de chave inclui uma chave válida e
(iii) se o tipo do valor delimitado pela caixa delimitadora de valor é incluído em um conjunto de tipos válidos para valores correspondentes à chave.
O sistema pode identificar a chave delimitada por uma caixa delimitadora de chave e o valor delimitado por uma caixa delimitadora de valor como um par chave-valor se a pontuação de correspondência entre a caixa delimitadora de chave e a caixa delimitadora de valor exceder um limite.
Um exemplo de um documento de fatura
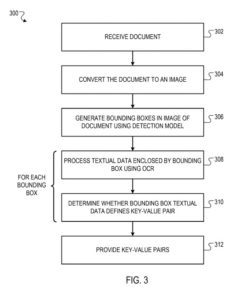
Um usuário do sistema de processamento de documentos pode fornecer a fatura (por exemplo, como uma imagem digitalizada ou um arquivo PDF) ao sistema de análise.
As caixas delimitadoras são geradas pelo modelo de detecção do sistema de análise sintática. Prevê-se que cada caixa delimitadora inclua dados textuais que definem um par de valores-chave. O modelo de detecção não gera uma caixa delimitadora com texto (ou seja, “Obrigado por sua empresa!”), pois esse texto não representa um par de valores-chave.
O sistema de análise usa técnicas de OCR para identificar o texto dentro de cada caixa delimitadora e, a partir daí, identifica bons pares de valores-chave entre as caixas delimitadoras.
A chave (ou seja, "Data:") e o valor (ou seja, "23-2-2019") dentro da caixa delimitadora.
Pares de valores-chave e processamento de documentos
Um sistema de análise programado por esta especificação pode realizar o processamento de documentos.
O sistema recebe um documento como upload de um usuário remoto do sistema através de uma rede de comunicação de dados (por exemplo, usando uma API disponibilizada pelo sistema). O documento pode ser representado em qualquer formato de dados não estruturado apropriado, como um documento PDF ou um documento de imagem (por exemplo, um documento PNG ou JPEG).
O sistema converte o documento em uma imagem, ou seja, uma coleção ordenada de valores numéricos que representam a aparência visual do papel. Por exemplo, a imagem pode ser uma imagem em preto e branco do documento que é descrita como uma matriz bidimensional de valores numéricos de intensidade.
Por um conjunto de parâmetros do modelo de detecção para gerar uma saída que define caixas delimitadoras na imagem do documento. Cada caixa delimitadora é prevista para incluir um par chave-valor, incluindo dados textuais críticos e dados textuais de valor, em que a chave define um rótulo que caracteriza o valor.
O modelo de detecção pode ser um modelo de detecção de objeto que inclui redes neurais convolucionais.
Pesquisar notícias diretamente na sua caixa de entrada
*Requerido