
Dokumentenverarbeitung mit strukturierten Schlüssel-Wert-Paaren
Veröffentlicht: 2022-03-31Warum Schlüssel-Wert-Paare in diesem Dokumentenverarbeitungssystem?
Das Schreiben dieses Beitrags erinnerte mich an einen Beitrag aus dem Jahr 2007, den ich über lokale Suche und strukturierte Daten schrieb, wo Schlüssel-Wert-Paare ein wichtiger Aspekt dieses Patents von 2007 waren. Der Beitrag war:
Strukturierte Informationen in der lokalen Suche von Google.
Ich fand es interessant zu sehen, wie Google über das Einfügen von Schlüssel-Wert-Paaren in ein Dokumentenverarbeitungssystem wie das hier geschriebene schreibt, mit einem maschinellen Lernansatz im Mittelpunkt, der in die technische SEO einsteigt.
Die Verwendung von Schlüsselwertpaaren ist nach 15 Jahren immer noch wichtig.
Dokumentenverarbeitung bei Google
Das Verstehen der Dokumentenverarbeitung (z. B. Rechnungen, Gehaltsabrechnungen, Verkaufsbelege und dergleichen) ist eine entscheidende Geschäftsanforderung. Ein großer Teil (z. B. 90 % oder mehr) der Unternehmensdaten wird in unstrukturierten Dokumenten gespeichert und dargestellt. Das Extrahieren strukturierter Daten aus Datensätzen kann teuer, zeitaufwändig und fehleranfällig sein.
Dieses Patent beschreibt ein Dokumentenverarbeitungs-Parsing-System und ein Verfahren, das als Computerprogramme auf Computern an Orten implementiert ist, die unstrukturierte Dokumente in strukturierte Schlüssel-Wert-Paare umwandeln.
Das Parsing-System wird so konfiguriert, dass es die Verarbeitung dokumentiert, um „Schlüssel“-Textdaten und entsprechende „Wert“-Textdaten im Papier zu identifizieren. Der Schlüssel definiert eine Bezeichnung, die einen entsprechenden Wert charakterisiert (dh beschreibt).
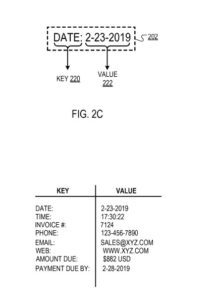
Beispielsweise kann der Schlüssel „Datum“ dem Wert „23.2.2019“ entsprechen.
Es gibt ein von einer Datenverarbeitungsvorrichtung durchgeführtes Verfahren, das einem Erkennungsmodell ein Bild eines Dokuments bereitstellt, wobei: das Erkennungsmodell so konfiguriert wird, dass es das Bild durch Werte mehrerer Erkennungsmodellparameter verarbeitet, um eine Ausgabe zu erzeugen, die Begrenzungsrahmen definiert für die Idee generiert.
Jede für das Bild erzeugte Begrenzungsbox wird vorhergesagt, ein Schlüssel-Wert-Paar einzuschließen, das kritische Textdaten und Wert-Textdaten umfasst, wobei die notwendigen Textdaten ein Etikett definieren, das die Textwertdaten charakterisiert.
Jeder der für das Bild erzeugten Begrenzungsrahmen: identifiziert Textinformationen, die von dem Begrenzungsrahmen eingeschlossen sind, unter Verwendung einer optischen Zeichenerkennungstechnik; Bestimmen, ob die von dem Begrenzungsrahmen gehaltenen Textdaten ein Schlüssel-Wert-Paar definieren; und als Reaktion auf die Feststellung, dass die von der Begrenzungsbox eingeschlossenen Textdaten ein Schlüssel-Wert-Paar darstellen, Bereitstellen des Schlüssel-Wert-Paares zur Verwendung bei der Charakterisierung des Dokuments.
Das Erkennungsmodell ist ein neuronales Netzwerkmodell.
Das neurale Netzwerkmodell umfasst ein konvolutionelles neurales Netzwerk.
Das neuronale Netzwerkmodell wird anhand einer Reihe von Trainingsbeispielen trainiert. Jedes Trainingsbeispiel umfasst eine Trainingseingabe und eine Zielausgabe; die Trainingseingabe umfasst ein Trainingsbild eines Trainingsdokuments. Die Zielausgabe enthält Daten, die Begrenzungsrahmen im Trainingsbild definieren, die ein jeweiliges Schlüssel-Wert-Paar einschließen.
Das Dokument ist eine Rechnung.

Das Bereitstellen eines Bildes eines Dokuments für ein Erkennungsmodell umfasst: Identifizieren einer bestimmten Klasse des Papiers; und Bereitstellen der Idee des Dokuments für ein Erkennungsmodell, das darauf trainiert wird, Kopien des spezifischen Typs zu verarbeiten.
- Die Bestimmung, ob die vom Begrenzungsrahmen eingeschlossenen Textdaten ein Schlüssel-Wert-Paar definieren, umfasst Folgendes:
- Entscheiden, dass die Textinformationen, die der Begrenzungsrahmen besitzt, einen Schlüssel aus einem vorbestimmten Satz gültiger Schlüssel enthalten;
- Finden eines Typs eines Teils von Textdaten, die von der Begrenzungsbox gehalten werden, die den Schlüssel nicht hat; Identifizieren eines Standorts geeigneter Sorten für Werte, die dem Schlüssel entsprechen
- Auswählen, dass der Stil des Teils der Textdaten, der von der Begrenzungsbox eingeschlossen ist, der den Schlüssel nicht enthält, in den Satz gültiger Typen für Werte aufgenommen wird, die dem Schlüssel entsprechen.
- Lernen, dass ein Satz gültiger Typen für Werte, die dem Schlüssel entsprechen, Folgendes umfasst: Abbilden des Schlüssels auf die Sammlung geeigneter Typen für Werte, die dem Schlüssel entsprechen, unter Verwendung einer vorbestimmten Abbildung.
Der Satz gültiger Schlüssel und die Zuordnung von Schlüsseln zu entsprechenden Orten geeigneter Typen für Werte, die den Schlüsseln entsprechen, werden von einem Benutzer bereitgestellt.
Die Begrenzungsboxen haben eine rechteckige Form.
Das Verfahren umfasst ferner: Empfangen des Dokuments von einem Benutzer; und Umwandeln des Papiers in ein Bild, wobei das Gemälde das Dokument darstellt.
Verfahren, das von dem Dokumentenverarbeitungssystem durchgeführt wird, wobei das Verfahren Folgendes umfasst:
- Bereitstellen eines Bildes eines Dokuments für ein Detektionsmodell, das konfiguriert ist, um das Bild zu verarbeiten, um in den Bildbegrenzungsboxen zu identifizieren, von denen vorhergesagt wird, dass sie ein Schlüssel-Wert-Paar einschließen, das kritische Textdaten und Werttextdaten umfasst, wobei der Schlüssel eine Bezeichnung definiert, die einen entsprechenden Wert charakterisiert zum Schlüssel; für jeden der für das Bild generierten Begrenzungsrahmen,
- Identifizieren von Textdaten, die von dem Begrenzungsrahmen eingeschlossen sind, unter Verwendung einer optischen Zeichenerkennungstechnik und Bestimmen, ob die von dem Begrenzungsrahmen gehaltenen Textinformationen ein Schlüssel-Wert-Paar definieren
- Ausgabe des Schlüssel-Wert-Teams zur Verwendung bei der Charakterisierung des Dokuments.
Das Erkennungsmodell ist ein maschinelles Lernmodell mit Parametern, die auf einem Trainingsdatensatz trainiert werden können.
Das maschinelle Lernmodell umfasst ein neurales Netzwerkmodell, insbesondere ein konvolutionelles neurales Netzwerk.
Das maschinelle Lernmodell wird mit einer Reihe von Trainingsbeispielen trainiert, und jedes Trainingsbeispiel hat eine Trainingseingabe und eine Zielausgabe.
Die Trainingseingabe umfasst ein Trainingsbild eines Trainingsdokuments. Die Zielausgabe umfasst datendefinierende Begrenzungsrahmen im Trainingsbild, die jeweils ein entsprechendes Schlüssel-Wert-Paar einschließen.
Das Dokument ist eine Rechnung.
Das Bereitstellen eines Bildes eines Dokuments für ein Erkennungsmodell umfasst: Identifizieren einer bestimmten Klasse des Papiers; und Bereitstellen der Idee des Dokuments für ein Erkennungsmodell, das darauf trainiert wird, Dokumente des spezifischen Typs zu verarbeiten.
Handelt es sich um ein Schlüssel-Wert-Paar?
Zu bestimmen, ob die vom Begrenzungsrahmen eingeschlossenen Textdaten ein Schlüssel-Wert-Paar definieren, bedeutet Folgendes:
- Entscheiden, dass die Textinformationen, die der Begrenzungsrahmen besitzt, einen Schlüssel aus einem vorbestimmten Satz gültiger Schlüssel enthalten
- Finden eines Typs eines Teils von Textdaten, die von dem Begrenzungsrahmen gehalten werden, der keinen Schlüssel hat
- Notieren eines Standorts geeigneter Sorten für Werte, die dem Schlüssel entsprechen
- Auswählen, dass der Stil des Teils der Textdaten, der von dem Begrenzungsrahmen eingeschlossen ist, der den Schlüssel nicht enthält, in den Satz gültiger Typen für Werte aufgenommen wird, die dem Schlüssel entsprechen.
Das Identifizieren eines Satzes gültiger Typen für Werte, die dem Schlüssel entsprechen, umfasst: Abbilden des Schlüssels auf die Sammlung geeigneter Typen für Werte, die dem Schlüssel entsprechen, unter Verwendung einer vorbestimmten Abbildung.
Der Satz gültiger Schlüssel und die Zuordnung von Schlüsseln zu entsprechenden Orten geeigneter Typen für Werte, die den Schlüsseln entsprechen, werden von einem Benutzer bereitgestellt.
Die Begrenzungsboxen haben eine rechteckige Form.
Das Verfahren umfasst ferner: Empfangen des Dokuments von einem Benutzer; und Umwandeln des Papiers in ein Bild, wobei das Gemälde das Dokument darstellt.
Gemäß einem anderen Aspekt gibt es ein System, umfassend: Computer; und Speichervorrichtungen, die mit Computern gekoppelt sind, wobei die Speichervorrichtungen Anweisungen speichern, die, wenn sie von Computern ausgeführt werden, Computer veranlassen, Operationen durchzuführen, die die Operationen des zuvor beschriebenen Verfahrens umfassen.
Vorteile dieses Dokumentenverarbeitungsansatzes
Das in dieser Spezifikation beschriebene System kann verwendet werden, um eine große Anzahl unstrukturierter Dokumente in strukturierte Schlüssel-Wert-Paare umzuwandeln. Somit vermeidet das System die Notwendigkeit, strukturierte Daten aus unstrukturierten Dokumenten zu extrahieren, was teuer, zeitaufwändig und fehleranfällig sein kann.
Das in dieser Spezifikation beschriebene System kann Schlüssel-Wert-Paare in Dokumenten mit einem hohen Maß an Genauigkeit identifizieren (z. B. für einige Arten von Dokumenten mit einer Genauigkeit von mehr als 99 %). Somit kann das System für den Einsatz in Anwendungen (z. B. Verarbeitung von Finanzdokumenten) geeignet sein, die ein hohes Maß an Genauigkeit erfordern.
Das in dieser Beschreibung beschriebene System kann besser verallgemeinern als einige herkömmliche Systeme, dh es hat im Vergleich zu einigen herkömmlichen Verfahren verbesserte Verallgemeinerungsfähigkeiten.
Insbesondere durch die Nutzung eines maschinell erlernten Erkennungsmodells, das darauf trainiert ist, visuelle Signale zu erkennen, die Schlüssel-Wert-Paare in Dokumenten unterscheiden, kann das System Schlüssel-Wert-Paare des spezifischen Stils, der Struktur oder des Inhalts der Papiere identifizieren.
Patent zur Identifizierung von Schlüssel-Wert-Paaren in der Dokumentenverarbeitung
Identifizieren von Schlüssel-Wert-Paaren in Dokumenten
Erfinder: Yang Xu, Jiang Wang und Shengyang Dai
Zessionar: Google LLC
US-Patent: 11.288.719
Gewährt: 29. März 2022
Eingereicht: 27. Februar 2020
Abstrakt
Verfahren, Systeme und Apparate, einschließlich auf einem Computerspeichermedium codierte Computerprogramme zum Konvertieren unstrukturierter Dokumente in strukturierte Schlüssel-Wert-Paare.
In einem Aspekt umfasst ein Verfahren: Bereitstellen eines Bildes eines Dokuments für ein Erkennungsmodell, wobei: das Erkennungsmodell konfiguriert wird, das Bild zu verarbeiten, um eine Ausgabe zu erzeugen, die Begrenzungsrahmen definiert, die für das Bild erzeugt werden; und jeder für das Bild erzeugte Begrenzungsrahmen vorhergesagt wird, ein Schlüssel-Wert-Paar einzuschließen, das Schlüsseltextdaten und Werttextdaten umfasst, wobei die Schlüsseltextdaten ein Etikett definieren, das die Werttextdaten charakterisiert, und für jeden der erzeugten Begrenzungsrahmen das Bild: Identifizieren von durch den Begrenzungsrahmen eingeschlossenen Textdaten unter Verwendung einer optischen Zeichenerkennungstechnik und Bestimmen, ob die durch den Begrenzungsrahmen eingeschlossenen Textdaten ein Schlüssel-Wert-Paar definieren.
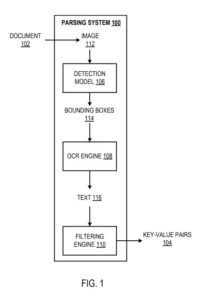
Ein beispielhaftes Parsing-System
Das Analysesystem ist ein Beispiel für ein Verfahren, das als Computerprogramme auf Computern an Orten implementiert wird, an denen die unten beschriebenen Systeme, Komponenten und Techniken implementiert werden.
Das Parsing-System wird so konfiguriert, dass es ein Dokument verarbeitet (z. B. eine Rechnung, eine Gehaltsabrechnung oder einen Verkaufsbeleg), um Schlüssel-Wert-Paare in dem Papier zu identifizieren. Ein „Schlüssel-Wert-Paar“ bezieht sich auf einen Schlüssel und einen entsprechenden Wert, im Allgemeinen Textdaten. Unter „Textdaten“ sind mindestens zu verstehen: Buchstaben, Zahlen und Sonderzeichen. Wie zuvor beschrieben, definiert ein Schlüssel eine Bezeichnung, die einen entsprechenden Wert charakterisiert.
Das System kann das Dokument auf verschiedene Arten empfangen.
Zum Beispiel kann das System das Papier als Upload von einem entfernten Systembenutzer über ein Datenkommunikationsnetzwerk empfangen (z. B. unter Verwendung einer Anwendungsprogrammierschnittstelle (API), die durch das System verfügbar gemacht wird). Das Dokument kann in jedem geeigneten unstrukturierten Datenformat dargestellt werden, zum Beispiel als ein PDF-Dokument (Portable Document Format) oder als ein Bilddokument (z. B. ein PNG- (Portable Network Graphics) oder JPEG-Dokument (Joint Photographic Experts Group)).
Identifizieren Sie Schlüssel-Wert-Paare in der Dokumentenverarbeitung
Das System verwendet ein Erkennungsmodell, eine OCR-Engine (Optical Character Recognition) und eine Filter-Engine, um Schlüssel-Wert-Paare bei der Dokumentenverarbeitung zu identifizieren.
Das Erkennungsmodell wird so konfiguriert, dass es ein Bild des Dokuments verarbeitet, um eine Ausgabe zu generieren, die Begrenzungsrahmen im Bild definiert. Jedes wird vorhergesagt, um Textdaten einzuschließen, die ein jeweiliges Schlüssel-Wert-Paar darstellen. Das heißt, von jedem Begrenzungsrahmen wird erwartet, dass er Textinformationen enthält, die Folgendes definieren:
(i) ein Schlüssel, und
(ii) einen Wert, der dem Schlüssel entspricht. Beispielsweise kann ein Begrenzungsrahmen die Textdaten „Name: John Smith“ einschließen, die den Schlüssel „Name“ und den entsprechenden Wert „John Smith“ definieren. Das Erkennungsmodell kann konfiguriert werden, um Begrenzungsrahmen zu erzeugen, die ein einzelnes Schlüssel-Wert-Paar einschließen (dh eher als viele Schlüssel-Wert-Paare).
Das Bild des Dokuments ist eine geordnete Sammlung numerischer Werte, die das visuelle Erscheinungsbild des Papiers darstellen. Das Bild kann ein Schwarz-Weiß-Bild des Dokuments sein. In diesem Beispiel kann das Bild als ein zweidimensionales Array aus numerischen Intensitätswerten beschrieben werden. Als weiteres Beispiel kann das Bild ein Farbbild des Dokuments sein. In diesem Beispiel kann das Bild als Mehrkanalbild dargestellt werden. Jeder Kanal entspricht einer jeweiligen Farbe (z. B. Rot, Grün oder Blau) und wird als zweidimensionales Array aus numerischen Intensitätswerten definiert.
Die Begrenzungsboxen können rechteckige Begrenzungsboxen sein. Ein rechteckiger Begrenzungsrahmen kann durch die Koordinaten einer bestimmten Ecke des Begrenzungsrahmens und die entsprechende Breite und Höhe des Begrenzungscontainers dargestellt werden. Allgemeiner sind andere Begrenzungskastenformen und andere Möglichkeiten zur Darstellung der Begrenzungskästen möglich.
Während das Detektionsmodell alle in dem Dokument vorhandenen Rahmen oder Grenzen als visuelle Signale erkennen und verwenden kann, sind die Begrenzungsboxen nicht gezwungen, sich mit irgendwelchen existierenden Strukturen von Grenzen, die in dem Papier aktuell sind, auszurichten (dh zusammenfallend zu sein). Darüber hinaus kann das System die Begrenzungsrahmen erzeugen, ohne die Begrenzungsrahmen im Bild des Dokuments anzuzeigen.
Das heißt, das System kann Daten erzeugen, die die Begrenzungspakete definieren, ohne einem Benutzer des Systems ein visuelles Zeichen der Position der Begrenzungsboxen zu geben.
Das Erkennungsmodell ist im Allgemeinen ein maschinelles Lernmodell, d. h. ein Modell mit einem Satz von Parametern, die anhand eines Satzes von Trainingsdaten trainiert werden können. Die Trainingsdaten enthalten viele Trainingsbeispiele, von denen jedes Folgendes umfasst:
(i) ein Trainingsbild, das ein Trainingsdokument darstellt, und
(ii) eine Zielausgabe, die Begrenzungsrahmen definiert, die ein entsprechendes Schlüssel-Wert-Paar in dem Trainingsbild umschließen.
Die Trainingsdaten können durch manuelle Annotation generiert werden, dh durch eine Person, die Begrenzungsrahmen um Schlüssel-Wert-Paare in dem Trainingsdokument identifiziert (z. B. unter Verwendung einer geeigneten Annotationssoftware).
Durch das Trainieren des Erkennungsmodells mithilfe von maschinellen Lerntechniken anhand einer Reihe von Trainingsdaten kann es visuelle Signale erkennen, die es ihm ermöglichen, Schlüssel-Wert-Paare in Dokumenten zu identifizieren. Beispielsweise kann das Erkennungsmodell darauf trainiert werden, lokale Signale (z. B. Textstile und die relativen räumlichen Positionen von Wörtern) und globale Signale (z. B. das Vorhandensein von Rändern in dem Dokument) zu erkennen, um Schlüssel-Wert-Paare zu identifizieren.

Die visuellen Hinweise, die es dem Erkennungsmodell ermöglichen, sich an Schlüsselwertteams in Datensätzen zu erinnern, enthalten im Allgemeinen keine Signale, die die explizite Bedeutung der Wörter im Dokument darstellen.
Visuelle Signale, die Schlüssel-Wert-Paare unterscheiden
Durch das Trainieren des Erkennungsmodells zum Erkennen visueller Signale, die Schlüssel-Wert-Paare in Dokumenten unterscheiden, kann das Erkennungsmodell über die Trainingsdaten hinaus „verallgemeinern“, die zum Erstellen des Erkennungsmodells verwendet wurden. Das trainierte Erkennungsmodell könnte ein Bild verarbeiten, das ein Dokument darstellt, um Begrenzungsrahmen zu erzeugen, die Schlüssel-Wert-Paare in dem Papier einschließen, selbst wenn die Kopie nicht in den Trainingsdaten enthalten war, die zum Trainieren des Erkennungsmodells verwendet wurden.
In einem Beispiel kann das Erkennungsmodell ein Objekterkennungsmodell eines neuronalen Netzes sein (z. B. einschließlich neuronaler Faltungsnetze), wobei die "Objekte" Schlüssel-Wert-Paaren in dem Dokument entsprechen. Die trainierbaren Parameter des neuronalen Netzwerkmodells umfassen die Gewichtungen des neuronalen Netzwerkmodells, beispielsweise Gewichtungen, die Faltungsfilter in dem neuronalen Netzwerkmodell definieren.
Das neuronale Netzwerkmodell kann mit dem Trainingsdatensatz trainiert werden, indem ein geeignetes Trainingsverfahren für maschinelles Lernen verwendet wird, beispielsweise stochastischer Gradientenabstieg. Insbesondere kann das neuronale Netzwerkmodell bei jeder Trainingsiteration Trainingsbilder aus einem „Batch“ (dh einem Satz) von Trainingsbeispielen verarbeiten, um Begrenzungsrahmen zu erzeugen, von denen vorhergesagt wird, dass sie entsprechende Schlüssel-Wert-Paare in den Trainingsbildern einschließen. Das System kann eine Zielfunktion testen, die ein Ähnlichkeitsmaß zwischen den durch das neuronale Netzwerkmodell erzeugten Begrenzungsboxen und den durch die entsprechenden Zielausgaben der Trainingsbeispiele spezifizierten Begrenzungsboxen charakterisiert.
Das Ähnlichkeitsmaß zwischen zwei Begrenzungsboxen kann beispielsweise eine Summe quadrierter Abstände zwischen den jeweiligen Eckpunkten der Begrenzungsboxen sein. Das System kann Gradienten der Zielfunktion bestimmen, die aus den Parameterwerten des neuronalen Netzwerks gewonnen werden (z. B. unter Verwendung von Backpropagation) und danach die Steigungen verwenden, um die aktuellen Parameterwerte des neuronalen Netzwerks anzupassen.
Insbesondere kann das System die Parameteraktualisierungsregel von jedem geeigneten Gradientenabfall-Optimierungsalgorithmus (z. B. Adam oder RMSprop) verwenden, um die aktuellen neuronalen Netzwerkparameterwerte unter Verwendung der Gradienten anzupassen. Das System trainiert das neuronale Netzwerkmodell, bis ein Trainingsbeendigungskriterium erfüllt ist (z. B. bis eine vorbestimmte Anzahl von Trainingsiterationen durchgeführt wurden oder eine Änderung des Werts der Objektzielfunktion zwischen Trainingsiterationen unter einen vorbestimmten Schwellenwert fällt).
Vor der Verwendung des Erkennungsmodells kann das System eine "Klasse" des Dokuments (z. B. Rechnung, Gehaltsabrechnung oder Kaufbeleg) identifizieren. Ein Benutzer des Systems kann die Klasse des Datensatzes beim Bereitstellen des Dokuments an das System identifizieren. Das Verfahren kann ein neuronales Klassifizierungsnetzwerk verwenden, um die Klasse des Papiers zu klassifizieren. Das System kann OCR-Techniken verwenden, um den Text in dem Dokument zu identifizieren und danach den Stil des Dokuments basierend auf dem Text in dem Dokument zu platzieren. In einem bestimmten Beispiel kann das System als Reaktion auf die Bestimmung des Ausdrucks „Nettogehalt“ die Papierklasse als „Gehaltsabrechnung“ identifizieren.
In einem weiteren bestimmten Beispiel kann das System als Reaktion auf das Identifizieren des Ausdrucks „Umsatzsteuer“ die Klasse des Dokuments als „Rechnung“ identifizieren. Nach dem Identifizieren der bestimmten Klasse des Datensatzes kann das System ein Erkennungsmodell verwenden, das darauf trainiert wird, Kopien der bestimmten Klasse zu verarbeiten. Das Verfahren kann ein Erkennungsmodell verwenden, das mit Trainingsdaten trainiert wurde, die nur Dokumente derselben bestimmten Klasse wie das Dokument enthielten.
Die Verwendung eines Erkennungsmodells, das darauf trainiert wird, Dokumente derselben Klasse wie das Dokument zu verarbeiten, kann die Leistung des Erkennungsmodells verbessern (z. B. indem es dem Erkennungsmodell ermöglicht wird, Begrenzungsrahmen um Schlüssel-Wert-Paare mit größerer Genauigkeit zu erzeugen).
Für jeden Begrenzungsrahmen verarbeitet das System den Teil des Bildes, der von dem Begrenzungsrahmen umschlossen ist, unter Verwendung der OCR-Maschine, um die Textdaten (dh den Text) zu identifizieren, die von dem Begrenzungsrahmen gehalten werden. Insbesondere identifiziert die OCR-Maschine den von einem Begrenzungsrahmen eingeschlossenen Text durch Identifizieren jedes alphabetischen, numerischen oder eindeutigen Zeichens, das von dem Begrenzungsrahmen eingeschlossen ist. Die OCR-Engine kann jede geeignete Technik verwenden, um den von einem Begrenzungsrahmen umgebenen Text zu identifizieren.
Die Filter-Engine bestimmt, ob der von einem Begrenzungsrahmen eingeschlossene Text ein Schlüssel-Wert-Paar darstellt. Die Filter-Engine kann entscheiden, ob der Text, der den Begrenzungsrahmen umgibt, ein Schlüssel-Wert-Paar angemessen darstellt. Beispielsweise kann die Filtermaschine bestimmen, ob der von der Begrenzungsbox eingeschlossene Text einen gültigen Schlüssel aus einem vorbestimmten Satz von rechten Schlüsseln für eine gegebene Begrenzungsbox enthält. Beispielsweise kann die Sammlung gültiger Schlüssel bestehen aus: „Datum“, „Uhrzeit“, „Rechnungsnummer“, „fälliger Betrag“ und dergleichen.
Beim Vergleichen verschiedener Textteile, um zu bestimmen, ob der von der Begrenzungsbox eingeschlossene Text einen gültigen Schlüssel enthält, kann die Filtermaschine bestimmen, dass zwei Textteile „übereinstimmen“, selbst wenn sie nicht identisch sind. Beispielsweise kann die Filter-Engine bestimmen, dass zwei Teile des Lesegeräts übereinstimmen, selbst wenn sie unterschiedliche Großschreibung oder Interpunktion enthalten (z. B. kann das Filtersystem bestimmen, dass „Datum“, „Datum:“, „Datum“ und „Datum:“ passen alle zusammen).
Als Reaktion auf die Bestimmung, dass der von der Begrenzungsbox eingeschlossene Text keinen gültigen Schlüssel aus den richtigen Schlüsseln enthält, bestimmt die Filtermaschine, dass der von der Begrenzungsbox umgebene Text kein Schlüssel-Wert-Paar darstellt.
Als Reaktion auf die Feststellung, dass der vom Begrenzungsrahmen eingeschlossene Text einen gültigen Schlüssel enthält, identifiziert die Filter-Engine einen „Typ“ (z. B. alphabetisch, numerisch, zeitlich) des vom Begrenzungsrahmen eingeschlossenen Textteils, der nicht als Schlüssel identifiziert wurde ( dh der „Nicht-Schlüssel“-Text). Beispielsweise kann für einen Begrenzungsrahmen mit dem Text: „Datum: 23.02.2019“, bei dem die Filtermaschine „Datum:“ als Schlüssel identifiziert (wie zuvor beschrieben), die Filtermaschine den Typ des Nichts identifizieren -Schlüsseltext „23.2.2019“ als „zeitlich“.
Neben der Identifizierung des Typs des Nicht-Schlüsseltexts identifiziert die Filtermaschine einen Satz gültiger Typen für Werte, die dem Schlüssel entsprechen. Insbesondere kann die Filter-Engine den Schlüssel durch eine vorbestimmte Abbildung auf eine Gruppe von hilfreichen Datentypen für Werte abbilden, die dem Schlüssel entsprechen. Beispielsweise kann die Filter-Engine den Schlüssel „Name“ dem entsprechenden Wertdatentyp „alphabetisch“ zuordnen, was anzeigt, dass der dem Schlüssel entsprechende Wert einen alphabetischen Datentyp haben sollte (z. B. „John Smith“).
Als weiteres Beispiel kann die Filter-Engine den Schlüssel „Datum“ dem entsprechenden Wertdatentyp „zeitlich“ zuordnen, was angibt, dass der dem Schlüssel entsprechende Wert einen zeitlichen Datentyp haben sollte (z. B. „23.2.2019“ oder „ 17:30:22“).
Die Filter-Engine bestimmt, ob der Typ des Nicht-Schlüssel-Textes in den Satz gültiger Typen für Werte aufgenommen wird, die dem Schlüssel entsprechen. Als Reaktion auf die Bestimmung, dass der Stil des Nicht-Schlüssel-Textes in die Sammlung geeigneter Typen für Werte aufgenommen wird, die der Legende entsprechen, bestimmt die Filter-Engine, dass der von der Begrenzungsbox eingeschlossene Text ein Schlüssel-Wert-Paar darstellt. Insbesondere identifiziert die Filtermaschine den Nichtschlüsseltext als den Wert, der dem Schlüssel entspricht. Andernfalls stellt das Filtermodul fest, dass der vom Begrenzungsrahmen eingeschlossene Text kein Schlüssel/Wert-Paar darstellt.
Der Satz gültiger Schlüssel und die Zuordnung von richtigen Schlüsseln zu Orten hilfreicher Datentypen für Werte, die den gültigen Schlüsseln entsprechen, können von einem Systembenutzer bereitgestellt werden (z. B. durch eine vom System bereitgestellte API).
Nach dem Identifizieren von Schlüssel-Wert-Paaren aus dem Text, der von jeweiligen Begrenzungsrahmen eingeschlossen ist, unter Verwendung der Filtermaschine, gibt das System die identifizierten Schlüssel-Wert-Paare aus. Beispielsweise kann das System die Schlüssel-Wert-Teams einem entfernten Benutzer des Systems über ein Datenkommunikationsnetz bereitstellen (z. B. unter Verwendung einer vom System bereitgestellten API). Als weiteres Beispiel kann das System Daten speichern, die die identifizierten Schlüssel-Wert-Paare in einer Datenbank (oder anderen Datenstruktur) definieren, auf die der Benutzer des Systems zugreifen kann.
In einigen Fällen kann ein Systembenutzer verlangen, dass das System den Wert identifiziert, der dem bestimmten Schlüssel in dem Dokument entspricht (z. B. "Rechnungsnummer"). In diesen Fällen kann das System, anstatt jedes Schlüssel-Wert-Paar im Datensatz zu identifizieren und bereitzustellen, den Text verarbeiten, der in den jeweiligen Begrenzungsrahmen platziert ist, bis das angeforderte Schlüssel-Wert-Team das geordnete Schlüssel-Wert-Paar erkennt und ausführt.
Wie oben beschrieben, kann das Erkennungsmodell darauf trainiert werden, Begrenzungsrahmen zu erzeugen, die jeweils ein jeweiliges Schlüssel-Wert-Paar einschließen. Oder anstatt ein einzelnes Erkennungsmodell zu verwenden, kann das System Folgendes umfassen:
(i) ein „Schlüsselerkennungsmodell“, das darauf trainiert wird, Begrenzungsrahmen zu erzeugen, die jeweilige Schlüssel einschließen, und
(ii) ein „Werterkennungsmodell“, das darauf trainiert wird, Begrenzungsrahmen zu erzeugen, die entsprechende Werte einschließen.
Das System kann Schlüssel-Wert-Paare aus den Schlüssel-Begrenzungsboxen und den Wert-Begrenzungsboxen in geeigneter Weise identifizieren. Beispielsweise kann das System für jedes Team von Begrenzungsrahmen, das einen Schlüssel-Begrenzungsrahmen und einen Werte-Begrenzungsrahmen enthält, eine „Match-Punktzahl“ basierend auf Folgendem generieren:
(i) die räumliche Nähe der Begrenzungsboxen,
(ii) ob die Schlüsselbegrenzungsbox einen gültigen Schlüssel einschließt, und
(iii) ob der Typ des Werts, der von der Wertbegrenzungsbox eingeschlossen ist, in einen Satz gültiger Typen für Werte aufgenommen wird, die dem Schlüssel entsprechen.
Das System kann den von einem Schlüsselbegrenzungsrahmen eingeschlossenen Schlüssel und den von einem Wertebegrenzungsrahmen umgebenen Wert als ein Schlüssel-Wert-Paar identifizieren, wenn die Übereinstimmungspunktzahl zwischen dem Schlüsselbegrenzungsrahmen und dem Wertebegrenzungsrahmen einen Schwellenwert überschreitet.
Ein Beispiel für ein Rechnungsdokument
Ein Benutzer des Dokumentenverarbeitungssystems kann die Rechnung (z. B. als gescanntes Bild oder als PDF-Datei) an das Parsing-System liefern.
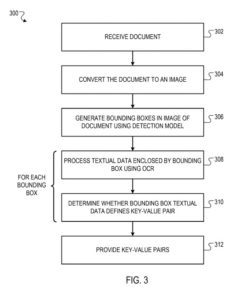
Begrenzungsrahmen werden durch das Erkennungsmodell des Parsing-Systems generiert. Es wird vorhergesagt, dass jeder Begrenzungsrahmen Textdaten einschließt, die ein Schlüssel-Wert-Paar definieren. Das Erkennungsmodell generiert keinen Begrenzungsrahmen mit Text (z. B. „Danke für Ihr Geschäft!“), da dieser Text kein Schlüssel-Wert-Paar darstellt.
Das Parsing-System verwendet OCR-Techniken, um den Text innerhalb jedes Begrenzungsrahmens zu identifizieren, und identifiziert danach gute Schlüssel-Wert-Paare, die von den Begrenzungsrahmen eingeschlossen sind.
Der Schlüssel (z. B. „Datum:“) und der Wert (z. B. „23.2.2019“), die vom Begrenzungsrahmen eingeschlossen sind.
Schlüssel-Wert-Paare und Dokumentenverarbeitung
Ein nach dieser Spezifikation programmiertes Analysesystem kann eine Dokumentenverarbeitung durchführen.
Das System empfängt ein Dokument als Upload von einem entfernten Systembenutzer über ein Datenkommunikationsnetzwerk (z. B. unter Verwendung einer vom System bereitgestellten API). Das Dokument kann in jedem geeigneten unstrukturierten Datenformat dargestellt werden, wie etwa einem PDF-Dokument oder einem Bilddokument (z. B. einem PNG- oder JPEG-Dokument).
Das System wandelt das Dokument in ein Bild um, d. h. eine geordnete Sammlung numerischer Werte, die das visuelle Erscheinungsbild des Papiers darstellen. Beispielsweise kann das Bild ein Schwarz-Weiß-Bild des Dokuments sein, das als zweidimensionales Array aus numerischen Intensitätswerten beschrieben wird.
Durch einen Satz von Erkennungsmodellparametern zum Generieren einer Ausgabe, die Begrenzungsrahmen im Bild des Dokuments definiert. Jeder Begrenzungsrahmen wird prognostiziert, um ein Schlüssel-Wert-Paar mit kritischen Textdaten und Werttextdaten einzuschließen, wobei der Schlüssel eine Bezeichnung definiert, die den Wert charakterisiert.
Das Erkennungsmodell kann ein Objekterkennungsmodell sein, das Faltungsneuronale Netze enthält.
Suchen Sie Nachrichten direkt in Ihren Posteingang
*Erforderlich