
構造化されたキーと値のペアを使用したドキュメント処理
公開: 2022-03-31このドキュメント処理システムでキーと値のペアが使用されるのはなぜですか?
この投稿を書くと、ローカル検索と構造化データについて書いた2007年の投稿を思い出しました。ここで、キーと値のペアは、その2007年の特許の重要な側面でした。 投稿は次のとおりです。
Googleのローカル検索における構造化された情報。
ここにあるようなドキュメント処理システムにキーと値のペアを挿入することについてGoogleが書いているのを見て、私は興味深く感じました。機械学習アプローチを中心に、技術的なSEOに取り組んでいます。
Key-Value Ppairの使用法は、15年経った今でも重要です。
Googleでのドキュメント処理
文書処理(請求書、給与明細書、領収書など)を理解することは、重要なビジネスニーズです。 エンタープライズデータの大部分(たとえば、90%以上)は、非構造化ドキュメントに保存および表示されます。 レコードから構造化データを抽出すると、費用と時間がかかり、エラーが発生しやすくなります。
この特許は、文書処理解析システムと、非構造化文書を構造化キーと値のペアに変換する場所にあるコンピューター上のコンピュータープログラムとして実装される方法について説明しています。
解析システムは、紙の「重要な」テキストデータと対応する「価値のある」テキストデータを識別するための文書処理を行うように構成されます。 キーは、対応する値を特徴付ける(つまり、説明する)ラベルを定義します。
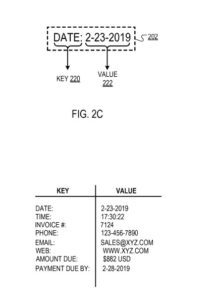
たとえば、キー「Date」は値「2-23-2019」に対応する場合があります。
文書の画像を検出モデルに提供するデータ処理装置によって実行される方法があり、ここで、検出モデルは、複数の検出モデルパラメータの値によって画像を処理して、境界ボックスを定義する出力を生成するように構成される。アイデアのために生成されます。
画像用に生成された各バウンディングボックスは、重要なテキストデータと値のテキストデータで構成されるキーと値のペアを囲むと予測されます。必要なテキストデータは、テキスト値データを特徴付けるラベルを定義します。
画像用に生成された各バウンディングボックス:光学式文字認識技術を使用して、バウンディングボックスで囲まれたテキスト情報を識別します。 バウンディングボックスによって保持されているテキストデータがキーと値のペアを定義しているかどうかを判断します。 また、バウンディングボックスで囲まれたテキストデータがキーと値のペアを表していると判断した場合は、ドキュメントの特性評価に使用するキーと値のペアを提供します。
検出モデルはニューラルネットワークモデルです。
ニューラルネットワークモデルは、畳み込みニューラルネットワークで構成されます。
ニューラルネットワークモデルは、一連のトレーニング例でトレーニングされます。 各トレーニング例は、トレーニング入力とターゲット出力で構成されます。 トレーニング入力には、トレーニングドキュメントのトレーニング画像が含まれます。 ターゲット出力には、それぞれのキーと値のペアを囲むトレーニング画像の境界ボックスを定義するデータが含まれています。
ドキュメントは請求書です。

文書の画像を検出モデルに提供することは、以下を含む。紙の特定のクラスを識別する。 特定のタイプのコピーを処理するようにトレーニングされる検出モデルにドキュメントのアイデアを提供します。
- バウンディングボックスで囲まれたテキストデータがキーと値のペアを定義するかどうかを判断するには、次の要素が含まれます。
- バウンディングボックスが所有するテキスト情報に、事前に定義された有効なキーのセットからのキーが含まれていることを決定します。
- キーを持たないバウンディングボックスによって保持されているテキストデータの一部のタイプを検索します。 キーに対応する値に適した品種の場所を特定する
- キーを含まないバウンディングボックスで囲まれたテキストデータの部分のスタイルが、キーに対応する値の有効なタイプのセットに含まれるように選択します。
- キーに対応する値の有効なタイプのセットが含まれることを学習する:所定のマッピングを使用して、キーをキーに対応する値の適切な種類のコレクションにマッピングする。
有効なキーのセットと、キーからキーに対応する値に適したタイプの対応する場所へのマッピングは、ユーザーによって提供されます。
バウンディングボックスは長方形です。
この方法はさらに、以下を含む。ユーザから文書を受信する。 そして、紙を画像に変換し、絵画は文書を描写します。
文書処理システムによって実行される方法であって、以下を含む方法。
- 重要なテキストデータと値のテキストデータを含むキーと値のペアを囲むと予測される画像境界ボックスで識別するために画像を処理するように構成された検出モデルにドキュメントの画像を提供します。キーは、対応する値を特徴付けるラベルを定義しますキーに; 画像用に生成されたバウンディングボックスごとに、
- 光学式文字認識技術を使用してバウンディングボックスで囲まれたテキストデータを識別し、バウンディングボックスで保持されているテキスト情報がキーと値のペアを定義しているかどうかを判断します
- ドキュメントの特性評価に使用するためのキーバリューチームの出力。
検出モデルは、トレーニングデータセットでトレーニングできるパラメーターを備えた機械学習モデルです。
機械学習モデルは、ニューラルネットワークモデル、特に畳み込みニューラルネットワークで構成されます。
機械学習モデルは一連のトレーニング例でトレーニングされ、各トレーニング例にはトレーニング入力とターゲット出力があります。
トレーニング入力は、トレーニングドキュメントのトレーニング画像で構成されます。 ターゲット出力には、トレーニングイメージ内のデータ定義バウンディングボックスが含まれ、それぞれがそれぞれのキーと値のペアを囲みます。
ドキュメントは請求書です。
文書の画像を検出モデルに提供することは、以下を含む。紙の特定のクラスを識別する。 特定のタイプのドキュメントを処理するようにトレーニングされる検出モデルにドキュメントのアイデアを提供します。
それはキーと値のペアですか?
バウンディングボックスで囲まれたテキストデータがキーと値のペアを定義するかどうかを判断することは、次のことを意味します。
- バウンディングボックスが所有するテキスト情報に、事前に定義された有効なキーのセットからのキーが含まれていることを決定する
- キーを持たないバウンディングボックスによって保持されているテキストデータの一部のタイプを検索する
- キーに対応する値に適した品種の場所に注意する
- キーを含まないバウンディングボックスで囲まれたテキストデータの部分のスタイルが、キーに対応する値の有効なタイプのセットに含まれることを選択します。
キーに対応する値の有効なタイプのセットを識別するには、次のことが含まれます。所定のマッピングを使用して、キーをキーに対応する値の適切な種類のコレクションにマッピングします。
有効なキーのセットと、キーからキーに対応する値に適したタイプの対応する場所へのマッピングは、ユーザーによって提供されます。
バウンディングボックスは長方形です。
この方法はさらに、以下を含む。ユーザから文書を受信する。 そして、紙を画像に変換し、絵画は文書を描写します。
別の態様によれば、以下を含むシステムが存在する。 コンピュータに結合された記憶装置であって、記憶装置は、コンピュータによって実行されると、コンピュータに前述の方法の操作を含む操作を実行させる命令を格納する。
このドキュメント処理アプローチの利点
この仕様で説明されているシステムは、多数の非構造化ドキュメントを構造化キーと値のペアに変換するために使用できます。 したがって、システムは、非構造化ドキュメントから構造化データを抽出する必要をなくします。これは、費用がかかり、時間がかかり、エラーが発生しやすい可能性があります。
この仕様で説明されているシステムは、ドキュメント内のキーと値のペアを高レベルの精度で識別できます(たとえば、一部のタイプのドキュメントでは、99%を超える精度で)。 したがって、このシステムは、高レベルの精度を必要とするアプリケーション(たとえば、財務書類の処理)での展開に適している場合があります。
この仕様で説明されているシステムは、一部の従来のシステムよりも一般化が優れています。つまり、一部の従来の方法と比較して一般化機能が向上しています。
特に、ドキュメント内のキーと値のペアを区別する視覚信号を認識するようにトレーニングされた機械学習の検出モデルを活用することで、システムは特定のスタイル、構造、または論文の内容のキーと値のペアを識別できます。
文書処理特許におけるキーと値のペアの識別
ドキュメント内のキーと値のペアの識別
発明者:Yang Xu、Jiang Wang、Shengyang Dai
譲受人:Google LLC
米国特許:11,288,719
付与:2022年3月29日
提出日:2020年2月27日
概要
非構造化文書を構造化キーと値のペアに変換するための、コンピューター記憶媒体上にエンコードされたコンピュータープログラムを含む方法、システム、および装置。
一態様では、方法は、以下を含む。検出モデルに文書の画像を提供する。ここで、検出モデルは、画像を処理して、画像に対して生成される境界ボックスを定義する出力を生成するように構成される。 画像に対して生成された各バウンディングボックスは、キーテキストデータと値テキストデータを含むキーと値のペアを囲むと予測されます。ここで、キーテキストデータは、値テキストデータを特徴付けるラベルを定義します。画像:光学式文字認識技術を使用してバウンディングボックスで囲まれたテキストデータを識別し、バウンディングボックスで囲まれたテキストデータがキーと値のペアを定義するかどうかを判断します。
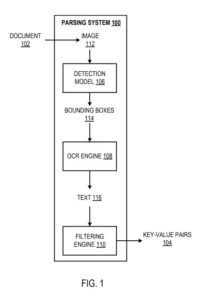
構文解析システムの例
構文解析システムは、以下に説明するシステム、コンポーネント、および技法が実装される場所にあるコンピューター上にコンピュータープログラムとして実装される方法の例です。
解析システムは、ドキュメント(請求書、給与明細書、領収書など)を処理して、紙のキーと値のペアを識別するように構成されます。 「キーと値のペア」とは、キーと対応する値、通常はテキストデータを指します。 「テキストデータ」は、少なくともアルファベット文字、数字、特殊記号を指すと理解する必要があります。 前に説明したように、キーは対応する値を特徴付けるラベルを定義します。
システムは、さまざまな方法でドキュメントを受信できます。
例えば、システムは、データ通信ネットワークを介して(例えば、システムによって利用可能にされたアプリケーションプログラミングインターフェース(API)を使用して)リモートシステムユーザーからのアップロードとして紙を受け取ることができる。 ドキュメントは、任意の適切な非構造化データ形式で表すことができます。たとえば、Portable Document Format(PDF)ドキュメントまたはイメージドキュメント(たとえば、Portable Network Graphics(PNG)またはJoint Photographic Experts Group(JPEG)ドキュメント)として表すことができます。
ドキュメント処理でキーと値のペアを特定する
このシステムは、検出モデル、光学式文字認識(OCR)エンジン、およびフィルタリングエンジンを使用して、ドキュメント処理でキーと値のペアを識別します。
検出モデルは、ドキュメントの画像を処理して、画像の境界ボックスを定義する出力を生成するように構成されます。 それぞれが、それぞれのキーと値のペアを表すテキストデータを囲むと予測されます。 つまり、各バウンディングボックスには、次のことを定義するテキスト情報が含まれていることが期待されます。
(i)キー、および
(ii)キーに対応する値。 たとえば、バウンディングボックスは、キー「Name」と対応する値「JohnSmith」を定義するテキストデータ「Name:JohnSmith」を囲む場合があります。 検出モデルは、単一のキーと値のペア(つまり、多くのキーと値のペアではなく)を囲む境界ボックスを生成するように構成できます。
ドキュメントの画像は、紙の外観を表す数値の順序付けられたコレクションです。 画像は、ドキュメントの白黒画像である可能性があります。 この例では、画像は数値強度値の2次元配列として記述される場合があります。 別の例として、画像は、文書のカラー画像であり得る。 この例では、画像はマルチチャネル画像として表される場合があります。 各チャネルはそれぞれの色(たとえば、赤、緑、または青)に対応し、数値強度値の2次元配列として定義されます。
バウンディングボックスは、長方形のバウンディングボックスであってもよい。 長方形のバウンディングボックスは、バウンディングボックスの特定のコーナーの座標と、それに対応するバウンディングコンテナの幅と高さで表すことができます。 より一般的には、他のバウンディングボックスの形状およびバウンディングボックスを表す他の方法が可能である。
検出モデルは、ドキュメントに存在するフレームまたは境界線を視覚信号として認識して使用できますが、境界ボックスは、紙に現在存在する境界線の既存の構造と整列するように制約されません(つまり、一致します)。 さらに、システムは、ドキュメントの画像にバウンディングボックスを表示せずにバウンディングボックスを生成する場合があります。
すなわち、システムは、システムのユーザにバウンディングボックスの位置の視覚的なサインを与えることなく、バウンディングパッケージを定義するデータを生成することができる。
検出モデルは通常、機械学習モデルです。つまり、一連のトレーニングデータでトレーニングを受けることができる一連のパラメーターを持つモデルです。 トレーニングデータには多くのトレーニング例が含まれており、それぞれに次のものが含まれています。
(i)トレーニングドキュメントを表すトレーニング画像、および
(ii)境界ボックスを定義するターゲット出力は、トレーニング画像のそれぞれのキーと値のペアを囲みます。
トレーニングデータは、手動の注釈によって、つまり、トレーニングドキュメント内のキーと値のペアの周囲の境界ボックスを識別する人によって(たとえば、適切な注釈ソフトウェアを使用して)生成される場合があります。
一連のトレーニングデータで機械学習技術を使用して検出モデルをトレーニングすると、視覚的な信号を認識して、ドキュメント内のキーと値のペアを識別できるようになります。 たとえば、検出モデルは、ローカル信号(たとえば、テキストスタイルと単語の相対的な空間位置)とグローバル信号(たとえば、ドキュメント内の境界線の存在)を認識して、キーと値のペアを識別するようにトレーニングできます。
検出モデルがレコード内のキー値チームを記憶できるようにする視覚的な手がかりには、通常、ドキュメント内の単語の明示的な意味を表す信号は含まれていません。
キーと値のペアを区別する視覚信号
ドキュメント内のキーと値のペアを区別する視覚信号を認識するように検出モデルをトレーニングすると、検出モデルは、検出モデルの準備に使用されるトレーニングデータを超えて「一般化」できます。 トレーニングされた検出モデルは、ドキュメントを表す画像を処理して、検出モデルのトレーニングに使用されるトレーニングデータにコピーが含まれていなくても、紙のキーと値のペアを囲む境界ボックスを生成する場合があります。
一例では、検出モデルは、ニューラルネットワークオブジェクト検出モデル(例えば、畳み込みニューラルネットワークを含む)であり得る。ここで、「オブジェクト」は、文書内のキーと値のペアに対応する。 ニューラルネットワークモデルのトレーニング可能なパラメーターには、ニューラルネットワークモデルの重みが含まれます。たとえば、ニューラルネットワークモデルの畳み込みフィルターを定義する重みが含まれます。
ニューラルネットワークモデルは、確率的勾配降下法などの適切な機械学習トレーニング手順を使用して、トレーニングデータセットでトレーニングを受けることができます。 特に、各トレーニング反復で、ニューラルネットワークモデルは、トレーニング例の「バッチ」(つまり、セット)からのトレーニング画像を処理して、トレーニング画像内のそれぞれのキーと値のペアを囲むと予測される境界ボックスを生成する場合があります。 システムは、ニューラルネットワークモデルによって生成されたバウンディングボックスと、トレーニング例の対応するターゲット出力によって指定されたバウンディングボックスとの間の類似性の尺度を特徴付ける照準関数をテストすることができます。

2つの境界ボックス間の類似性の尺度は、例えば、境界ボックスのそれぞれの頂点間の距離の二乗の合計であり得る。 システムは、ニューラルネットワークパラメータ値を獲得した照準関数の勾配を決定し(たとえば、バックプロパゲーションを使用)、その後、勾配を使用して現在のニューラルネットワークパラメータ値を調整できます。
特に、システムは、任意の適切な勾配降下最適化アルゴリズム(AdamやRMSpropなど)のパラメーター更新ルールを使用して、勾配を使用して現在のニューラルネットワークパラメーター値を調整できます。 システムは、トレーニング終了基準が満たされるまで(たとえば、所定の数のトレーニング反復が実行されるか、トレーニング反復間のオブジェクト照準関数の値の変化が所定のしきい値を下回るまで)ニューラルネットワークモデルをトレーニングします。
検出モデルを使用する前に、システムはドキュメントの「クラス」(請求書、給与明細書、領収書など)を識別する場合があります。 システムのユーザーは、ドキュメントをシステムに提供するときに、レコードのクラスを識別できます。 この方法は、分類ニューラルネットワークを使用して、論文のクラスを分類することができる。 システムは、OCR技術を使用してドキュメント内のテキストを識別し、その後、ドキュメント内のテキストに基づいてドキュメントのスタイルを配置する場合があります。 特定の例では、「ネットペイ」というフレーズを決定することに応答して、システムは、紙のクラスを「給与明細書」として識別することができる。
別の特定の例では、「消費税」という句を識別することに応答して、システムは、文書のクラスを「請求書」として識別することができる。 レコードの特定のクラスを識別した後、システムは、特定のクラスのコピーを処理するようにトレーニングされる検出モデルを使用する場合があります。 このメソッドは、ドキュメントと同じ特定のクラスのドキュメントのみを含むトレーニングデータでトレーニングされた検出モデルを使用する場合があります。
ドキュメントと同じクラスのドキュメントを処理するようにトレーニングされた検出モデルを使用すると、検出モデルのパフォーマンスが向上する場合があります(たとえば、検出モデルがキーと値のペアの周囲に境界ボックスをより正確に生成できるようにすることによって)。
バウンディングボックスごとに、システムはOCRエンジンを使用して、バウンディングボックスで囲まれた画像の一部を処理し、バウンディングボックスによって保持されているテキストデータ(つまり、テキスト)を識別します。 特に、OCRエンジンは、バウンディングボックスで囲まれたアルファベット、数字、または一意の各文字を識別することにより、バウンディングボックスで囲まれたテキストを識別します。 OCRエンジンは、適切な手法を使用して、境界ボックスで囲まれたテキストを識別できます。
フィルタリングエンジンは、境界ボックスで囲まれたテキストがキーと値のペアを表すかどうかを判断します。 フィルタリングエンジンは、バウンディングボックスを囲むテキストがキーと値のペアを適切に表すかどうかを判断できます。 例えば、フィルタリングエンジンは、バウンディングボックスによって囲まれたテキストが、所与のバウンディングボックスの所定の右キーのセットからの有効なキーを含むかどうかを決定することができる。 たとえば、有効なキーのコレクションは、「日付」、「時刻」、「請求書番号」、「未払い額」などで構成されます。
テキストのさまざまな部分を比較して、バウンディングボックスで囲まれたテキストに有効なキーが含まれているかどうかを判断する場合、フィルタリングエンジンは、2つのテキストが同一でなくても「一致」していると判断する場合があります。 たとえば、フィルタリングエンジンは、異なる大文字と句読点が含まれている場合でも、リーダーの2つの部分が一致していると判断する場合があります(たとえば、フィルタリングシステムは、「日付」、「日付:」、「日付」、「日付:」と判断する場合があります。すべて一致しています)。
バウンディングボックスで囲まれたテキストに正しいキーからの有効なキーが含まれていないと判断した場合、フィルタリングエンジンは、バウンディングボックスで囲まれたテキストがキーと値のペアを表していないと判断します。
バウンディングボックスで囲まれたテキストに有効なキーが含まれていると判断した場合、フィルタリングエンジンは、キーとして識別されていないバウンディングボックスで囲まれたテキストの部分の「タイプ」(アルファベット、数字、時間など)を識別します(つまり、「非キー」テキスト)。 たとえば、「Date:2-23-2019」というテキストが含まれるバウンディングボックスの場合、フィルタリングエンジンは「Date:」をキーとして識別します(前述のとおり)。フィルタリングエンジンは、非のタイプを識別します。 -キーテキスト「2-23-2019」は「一時的」です。
非キーテキストのタイプを識別することに加えて、フィルタリングエンジンは、キーに対応する値の有効なタイプのセットを識別します。 特に、フィルタリングエンジンは、所定のマッピングによって、キーに対応する値の有用なデータ型のグループにキーをマッピングすることができる。 たとえば、フィルタリングエンジンは、キー「Name」を対応する値のデータ型「alphabetical」にマップできます。これは、キーに対応する値がアルファベット順のデータ型(たとえば、「JohnSmith」)であることを示します。
別の例として、フィルタリングエンジンは、キー「日付」を対応する値データ型「時間的」にマッピングし、キーに対応する値が時間的データ型(例えば、「2-23-2019」または「 17:30:22」)。
フィルタリングエンジンは、キー以外のテキストのタイプが、キーに対応する値の有効な種類のセットに含まれるかどうかを判断します。 非キーテキストのスタイルが凡例に対応する値の適切なタイプのコレクションに含まれると判断した場合、フィルタリングエンジンは、境界ボックスで囲まれたテキストがキーと値のペアを表すと判断します。 特に、フィルタリングエンジンは、キー以外のテキストをキーに対応する値として識別します。 それ以外の場合、フィルタリングエンジンは、バウンディングボックスで囲まれたテキストがキーと値のペアを表していないと判断します。
有効なキーのセットと、正しいキーから有効なキーに対応する値の有用なデータ型の場所へのマッピングは、システムユーザーによって提供される場合があります(たとえば、システムによって利用可能になるAPIを介して)。
フィルタリングエンジンを使用して、それぞれの境界ボックスで囲まれたテキストからキーと値のペアを識別した後、システムは識別されたキーと値のペアを出力します。 たとえば、システムは、データ通信ネットワークを介して(たとえば、システムによって利用可能になったAPIを使用して)システムのリモートユーザーにキーバリューチームを提供できます。 別の例として、システムは、識別されたキーと値のペアを定義するデータを、システムのユーザーがアクセスできるデータベース(または他のデータ構造)に格納できます。
場合によっては、システムユーザーは、システムがドキュメント内の特定のキーに対応する値(「請求書番号」など)を識別するように要求することがあります。 このような場合、システムは、レコード内のすべてのキーと値のペアを識別して提供するのではなく、要求されたキーと値のチームが順序付けられたキーと値のペアを認識して実行するまで、それぞれの境界ボックスに配置されたテキストを処理します。
上記のように、検出モデルは、それぞれがそれぞれのキーと値のペアを囲む境界ボックスを生成するようにトレーニングできます。 または、単一の検出モデルを使用するのではなく、システムに次のものが含まれる場合があります。
(i)それぞれのキーを囲むバウンディングボックスを生成するようにトレーニングされる「キー検出モデル」、および
(ii)それぞれの値を囲む境界ボックスを生成するようにトレーニングされる「値検出モデル」。
システムは、キー境界ボックスと値境界ボックスからキーと値のペアを適切に識別できます。 たとえば、キーバウンディングボックスと値バウンディングボックスを含むバウンディングボックスの各チームについて、システムは以下に基づいて「一致スコア」を生成できます。
(i)バウンディングボックスの空間的近接性、
(ii)キーバウンディングボックスが有効なキーを囲んでいるかどうか、および
(iii)値の境界ボックスで囲まれた値のタイプが、キーに対応する値の有効なタイプのセットに含まれるかどうか。
キー境界ボックスと値境界ボックスの間の一致スコアがしきい値を超えた場合、システムは、キー境界ボックスで囲まれたキーと値境界ボックスで囲まれた値をキーと値のペアとして識別することができます。
請求書の例
文書処理システムのユーザーは、請求書を(例えば、スキャンされた画像またはPDFファイルとして)解析システムに提供することができる。
バウンディングボックスは、解析システムの検出モデルによって生成されます。 各境界ボックスは、キーと値のペアを定義するテキストデータを囲むと予測されます。 このテキストはキーと値のペアを表していないため、検出モデルはテキスト(つまり、「ビジネスに感謝します!」)を含む境界ボックスを生成しません。
解析システムは、OCR技術を使用して、各バウンディングボックス内のテキストを識別し、その後、バウンディングボックスで囲まれた適切なキーと値のペアを識別します。
境界ボックスで囲まれたキー(つまり、「日付:」)と値(つまり、「2-23-2019」)。
キーと値のペアとドキュメント処理
この仕様でプログラムされた解析システムは、文書処理を実行できます。
システムは、データ通信ネットワークを介して(たとえば、システムによって利用可能にされたAPIを使用して)リモートシステムユーザーからアップロードとしてドキュメントを受信します。 ドキュメントは、PDFドキュメントや画像ドキュメント(PNGやJPEGドキュメントなど)など、適切な非構造化データ形式で表すことができます。
システムは、ドキュメントを画像、つまり、紙の外観を表す順序付けられた数値のコレクションに変換します。 たとえば、画像は、数値強度値の2次元配列として記述されるドキュメントの白黒画像である場合があります。
ドキュメントの画像内の境界ボックスを定義する出力を生成するための一連の検出モデルパラメータ。 各境界ボックスは、重要なテキストデータと値のテキストデータを含むキーと値のペアを囲むと予測されます。ここで、キーは値を特徴付けるラベルを定義します。
検出モデルは、畳み込みニューラルネットワークを含むオブジェクト検出モデルである場合があります。
受信トレイに直接ニュースを検索
*必須