
使用结构化键值对的文档处理
已发表: 2022-03-31为什么在这个文档处理系统中使用键值对?
写这篇文章让我想起了我在 2007 年写的一篇关于本地搜索和结构化数据的文章,其中键值对是 2007 年专利的一个重要方面。 帖子是:
Google 本地搜索中的结构化信息。
看到谷歌写的关于在像这里这样的文档处理系统中插入键值对的文章让我感到很有趣,其核心是机器学习方法,进入技术 SEO。
15 年后,key-value Ppairs 的使用仍然很重要。
Google 的文档处理
了解文档处理(例如,发票、付款存根、销售收据等)是一项重要的业务需求。 企业数据的很大一部分(例如,90% 或更多)在非结构化文档中存储和表示。 从记录中提取结构化数据可能是昂贵、耗时且容易出错的。
该专利描述了一种文档处理解析系统和一种方法,该方法在将非结构化文档转换为结构化键值对的位置的计算机上实现为计算机程序。
解析系统被配置为文档处理,以识别论文中的“关键”文本数据和相应的“价值”文本数据。 键定义了表征(即,描述)相应值的标签。
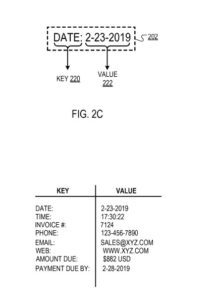
例如,键“日期”可以对应于值“2-23-2019”。
有一种由数据处理装置执行的方法,其将文档的图像提供给检测模型,其中:检测模型被配置为通过多个检测模型参数的值来处理图像以生成定义边界框的输出为这个想法而生成。
为图像生成的每个边界框都被预测为包含一个键值对,该键值对包括关键文本数据和值文本数据,其中必要的文本数据定义了表征文本值数据的标签。
为图像生成的每个边界框: 使用光学字符识别技术识别边界框包围的文本信息; 判断边界框保存的文本数据是否定义了键值对; 并且响应于确定由边界框包围的文本数据表示键值对,提供键值对以用于表征文档。
检测模型是神经网络模型。
神经网络模型包括卷积神经网络。
神经网络模型在一组训练示例上进行训练。 每个训练样例包括一个训练输入和一个目标输出; 训练输入包括训练文档的训练图像。 目标输出包含定义训练图像中的边界框的数据,其中包含相应的键值对。
该文件是发票。

将文档的图像提供给检测模型包括:识别特定类别的纸张; 并将文档的想法提供给经过训练以处理特定类型副本的检测模型。
- 判断边界框包围的文本数据是否定义键值对包括:
- 确定边界框所拥有的文本信息包括来自预定的一组有效键的键;
- 查找边界框所持有的文本数据中没有key的部分类型; 识别与键对应的值的合适品种的位置
- 选择由边界框包围的不包含键的文本数据部分的样式将包含在与键对应的值的有效类型集中。
- 获知键对应的值的有效类型集合包括:使用预定映射将键映射到键对应的值的合适类型集合。
有效键的集合以及从键到对应于键的值的合适类型的对应位置的映射由用户提供。
边界框具有矩形形状。
该方法还包括:接收来自用户的文档; 并将纸张转换为图像,其中绘画描绘了文件。
一种由文档处理系统执行的方法,该方法包括:
- 将文档的图像提供给检测模型,该检测模型被配置为处理图像以在图像边界框中进行识别,该图像边界框被预测为包围包括关键文本数据和值文本数据的键值对,其中键定义了表征对应值的标签到钥匙; 对于为图像生成的每个边界框,
- 使用光学字符识别技术识别边界框包围的文本数据,并确定边界框持有的文本信息是否定义了键值对
- 输出用于表征文档的键值团队。
检测模型是一种机器学习模型,其参数可以在训练数据集上进行训练。
机器学习模型包括神经网络模型,特别是卷积神经网络。
机器学习模型在一组训练示例上进行训练,每个训练示例都有一个训练输入和一个目标输出。
训练输入包括训练文档的训练图像。 目标输出包括训练图像中定义数据的边界框,每个边界框都包含相应的键值对。
该文件是发票。
将文档的图像提供给检测模型包括:识别特定类别的纸张; 并将文档的想法提供给经过训练以处理特定类型文档的检测模型。
是键值对吗?
判断边界框包围的文本数据是否定义了键值对意味着:
- 确定边界框拥有的文本信息包括来自预定的一组有效键的键
- 查找边界框所持有的文本数据的一部分的类型,它没有键
- 记下与键对应的值的合适品种的位置
- 选择由边界框包围的不包含键的文本数据部分的样式将包含在与键对应的值的有效类型集中。
识别与键对应的值的一组有效类型包括:使用预定映射将键映射到与键对应的值的适当种类的集合。
有效键的集合以及从键到对应于键的值的合适类型的对应位置的映射由用户提供。
边界框具有矩形形状。
该方法还包括:接收来自用户的文档; 并将纸张转换为图像,其中绘画描绘了文件。
根据另一方面,存在一种系统,包括:计算机; 以及耦合到计算机的存储设备,其中存储设备存储指令,当由计算机执行时,使计算机执行包括前述方法的操作的操作。
这种文档处理方法的优点
本规范中描述的系统可以用来将大量的非结构化文档转换为结构化的键值对。 因此,该系统消除了从非结构化文档中提取结构化数据的需要,这可能是昂贵、耗时且容易出错的。
本规范中描述的系统能够以较高的准确度识别文档中的键值对(例如,对于某些类型的文档,准确度大于 99%)。 因此,该系统可能适合部署在需要高度准确性的应用程序(例如,处理财务文件)中。
本规范所描述的系统比一些传统系统具有更好的泛化能力,即与一些传统方法相比,它具有改进的泛化能力。
特别是,通过利用经过训练以识别区分文档中键值对的视觉信号的机器学习检测模型,系统可以识别论文的特定样式、结构或内容的键值对。
文档处理专利中的键值对识别
识别文档中的键值对
发明人:杨旭、姜王、戴盛阳
受让人:谷歌有限责任公司
美国专利:11,288,719
授予:2022 年 3 月 29 日
提交日期:2020 年 2 月 27 日
抽象的
用于将非结构化文档转换为结构化键值对的方法、系统和设备,包括在计算机存储介质上编码的计算机程序。
在一个方面,一种方法包括: 将文档的图像提供给检测模型,其中: 检测模型被配置为处理图像以生成定义为图像生成的边界框的输出; 并且为图像生成的每个边界框被预测为包含一个键值对,该键值对包括键文本数据和值文本数据,其中键文本数据定义了表征值文本数据的标签,并且为每个生成的边界框图像:利用光学字符识别技术识别包围盒包围的文本数据,并确定包围盒包围的文本数据是否定义键值对。
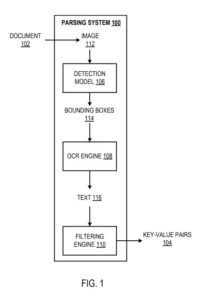
一个示例解析系统
解析系统是在以下描述的系统、组件和技术被实现的位置的计算机上实现为计算机程序的方法的示例。
解析系统被配置为处理文档(例如,发票、付款存根或销售收据)以识别论文中的键值对。 “键值对”是指一个键和一个对应的值,通常是文本数据。 “文本数据”应该被理解为至少是指:字母字符、数字和特殊符号。 如前所述,键定义了表征相应值的标签。
系统可以以多种方式接收文档。
例如,系统可以通过数据通信网络(例如,使用系统提供的应用程序编程接口(API))从远程系统用户接收作为上传的论文。 该文档可以以任何适当的非结构化数据格式表示,例如,作为可移植文档格式(PDF)文档或作为图像文档(例如,可移植网络图形(PNG)或联合图像专家组(JPEG)文档)。
识别文档处理中的键值对
该系统使用检测模型、光学字符识别 (OCR) 引擎和过滤引擎来识别文档处理中的键值对。
检测模型被配置为处理文档的图像以生成定义图片中边界框的输出。 每个都被预测为包含表示相应键值对的文本数据。 也就是说,每个边界框都应该有文本信息来定义:
(i) 一把钥匙,和
(ii) 对应于键的值。 例如,边界框可能包含文本数据“姓名:约翰·史密斯”,它定义了“姓名”键和相应的值“约翰·史密斯”。 检测模型可以被配置为生成包围单个键值对(即,而不是许多键值对)的边界框。
文档的图像是代表纸张视觉外观的有序数值集合。 该图像可以是文档的黑白图像。 在这个例子中,图片可以被描述为数值强度值的二维数组。 作为另一示例,图像可以是文档的彩色图像。 在此示例中,图片可以表示为多通道图像。 每个通道对应于相应的颜色(例如,红色、绿色或蓝色),并被定义为数值强度值的二维数组。
边界框可以是矩形边界框。 矩形边界框可以由边界框的特定角的坐标和边界容器的相应宽度和高度来表示。 更一般地,其他边界框形状和其他表示边界框的方式是可能的。
虽然检测模型可以识别和使用文档中存在的任何框架或边界作为视觉信号,但边界框不限于与论文中当前的任何现有边界结构对齐(即,重合)。 此外,系统可以生成边界框而不在文档的图像中显示边界框。
即,系统可以生成定义边界包的数据,而不向系统的用户给出边界框位置的视觉标志。
检测模型一般是机器学习模型,即具有一组参数的模型,可以在一组训练数据上得到训练。 训练数据包括许多训练样例,每个训练样例包括:
(i) 描述训练文档的训练图像,以及
(ii) 定义边界框的目标输出在训练图像中包含相应的键值对。
训练数据可以通过手动注释生成,即,由人识别训练文档中键值对周围的边界框(例如,使用适当的注释软件)。
在一组训练数据上使用机器学习技术训练检测模型,使其能够识别视觉信号,从而识别文档中的键值对。 例如,检测模型可以被训练以识别局部信号(例如,文本样式和单词的相对空间位置)和全局信号(例如,文档中边界的存在)以识别键值对。
使检测模型能够记住记录中的键值团队的视觉提示通常不包括表示文档中单词的明确含义的信号。
区分键值对的视觉信号
训练检测模型以识别区分文档中键值对的视觉信号,使检测模型能够“泛化”超出用于准备检测模型的训练数据。 经过训练的检测模型可能会处理描述文档的图像,以生成包含论文中键值对的边界框,即使副本未包含在用于训练检测模型的训练数据中。
在一个示例中,检测模型可以是神经网络对象检测模型(例如,包括卷积神经网络),其中“对象”对应于文档中的键值对。 神经网络模型的可训练参数包括神经网络模型的权重,例如定义神经网络模型中卷积滤波器的权重。
神经网络模型可以使用适当的机器学习训练程序在训练数据集上进行训练,例如随机梯度下降。 特别地,在每次训练迭代中,神经网络模型可以处理来自“批次”(即,一组)训练示例的训练图像,以生成预测为包围训练图像中的各个键值对的边界框。 该系统可以测试目标函数,该目标函数表征由神经网络模型生成的边界框和由训练示例的对应目标输出指定的边界框之间的相似性度量。
例如,两个边界框之间的相似性度量可以是边界框的各个顶点之间的距离平方和。 系统可以确定目标函数的梯度,获得神经网络参数值(例如,使用反向传播),然后使用斜率调整当前神经网络参数值。
特别地,系统可以使用来自任何适当的梯度下降优化算法(例如,Adam 或 RMSprop)的参数更新规则来使用梯度调整当前神经网络参数值。 系统训练神经网络模型直到满足训练终止标准(例如,直到已经执行了预定数量的训练迭代或者训练迭代之间的目标目标函数的值的变化低于预定阈值)。
在使用检测模型之前,系统可以识别文档的“类别”(例如,发票、付款存根或销售收据)。 系统的用户可以在将文档提供给系统时识别记录的类别。 该方法可以使用分类神经网络对论文的类别进行分类。 系统可以使用 OCR 技术来识别文档中的文本,然后根据文档中的文本放置文档的样式。 在特定示例中,响应于确定短语“Net Pay”,系统可以将纸张类别识别为“pay stub”。

在另一个特定示例中,响应于识别短语“销售税”,系统可以将文档的类别识别为“发票”。 在识别记录的特定类别后,系统可以使用经过训练的检测模型来处理特定类别的副本。 该方法可以使用在仅包括与文档相同特定类别的文档的训练数据上得到训练的检测模型。
使用经过训练来处理与文档相同类别的文档的检测模型可以提高检测模型的性能(例如,通过使检测模型能够以更高的准确度围绕键值对生成边界框)。
对于每个边界框,系统使用OCR引擎处理被边界框包围的图像部分,以识别边界框持有的文本数据(即文本)。 具体而言,OCR 引擎通过识别由边界框包围的每个字母、数字或唯一字符来识别由边界框包围的文本。 OCR 引擎可以使用任何适当的技术来识别由边界框包围的文本。
过滤引擎确定边界框包围的文本是否代表键值对。 过滤引擎可以决定边界框周围的文本是否适当地表示键值对。 例如,过滤引擎可以确定由边界框包围的文本是否包括来自给定边界框的预定右键集合中的有效键。 例如,有效密钥的集合可以包括:“日期”、“时间”、“发票#”、“到期金额”等。
在比较文本的不同部分以确定边界框包围的文本是否包括有效键时,过滤引擎可以确定两段文本“匹配”,即使它们不相同。 例如,过滤引擎可以确定阅读器的两个部分是匹配的,即使它们包括不同的大写或标点符号(例如,过滤系统可以确定“日期”、“日期:”、“日期”和“日期:”都是匹配的)。
响应于确定边界框包围的文本不包括来自正确键的有效键,过滤引擎确定边界框包围的文本不代表键值对。
响应于确定由边界框包围的文本包括有效键,过滤引擎识别未被识别为键的边界框包围的文本部分的“类型”(例如,字母、数字、时间)(即“非关键”文本)。 例如,对于具有文本:“日期:2-23-2019”的边界框,其中过滤引擎将“日期:”标识为键(如前所述),过滤引擎可以识别非- 关键文本“2-23-2019”是“时间的”。
除了识别非键文本的类型外,过滤引擎还为键对应的值识别一组有效类型。 特别地,过滤引擎可以通过预定映射将关键字映射到一组有用的数据类型,用于对应于关键字的值。 例如,过滤引擎可以将键“Name”映射到对应的值数据类型“字母”,指示对应于键的值应该具有字母数据类型(例如,“John Smith”)。
作为另一个例子,过滤引擎可以将键“Date”映射到对应的值数据类型“temporal”,指示对应于键的值应该具有时间数据类型(例如,“2-23-2019”或“ 17:30:22”)。
过滤引擎确定非键文本的类型是否包含在与键对应的值的有效种类集中。 响应于确定非键文本的样式被包括在与图例对应的值的合适类型的集合中,过滤引擎确定由边界框包围的文本表示键值对。 具体来说,过滤引擎将非关键字文本识别为关键字对应的值。 否则,过滤引擎确定边界框包围的文本不代表键值对。
对于对应于有效键的值,有效键的集合和从右键到有用数据类型的位置的映射可以由系统用户提供(例如,通过系统提供的API)。
在使用过滤引擎从各个边界框包围的文本中识别出键值对后,系统输出识别出的键值对。 例如,系统可以通过数据通信网络(例如,使用系统提供的API)向系统的远程用户提供键值组。 作为另一个示例,系统可以将定义所识别的键值对的数据存储在系统用户可访问的数据库(或其他数据结构)中。
在某些情况下,系统用户可以请求系统识别与文档中的特定键对应的值(例如,“发票#”)。 在这些情况下,系统可能会处理放置在相应边界框中的文本,而不是识别和提供记录中的每个键值对,直到被请求的键值团队识别并执行有序的键值对。
如上所述,可以训练检测模型以生成边界框,每个边界框都包含相应的键值对。 或者,系统可能包括:
(i) 一个“键检测模型”,经过训练可以生成包围各个键的边界框,以及
(ii) 一个“值检测模型”,经过训练可以生成包含相应值的边界框。
系统可以从键边界框和值边界框中适当地识别键值对。 例如,对于包含一个键边界框和一个值边界框的每组边界框,系统可以根据以下内容生成“匹配分数”:
(i) 边界框的空间接近度,
(ii) 密钥边界框是否包含有效密钥,以及
(iii) 值边界框所包围的值的类型是否包含在与键对应的值的一组有效类型中。
如果键边界框和值边界框之间的匹配分数超过阈值,则系统可以将键边界框包围的键和值边界框包围的值识别为键值对。
发票文件示例
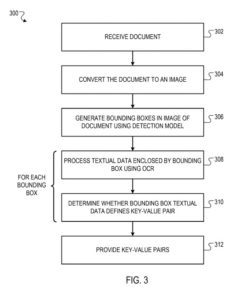
文档处理系统的用户可以将发票(例如,作为扫描图像或PDF文件)提供给解析系统。
边界框由解析系统的检测模型生成。 每个边界框都被预测为包含定义键值对的文本数据。 检测模型不会生成包含文本的边界框(即“感谢您的支持!”),因为该文本不代表键值对。
解析系统使用 OCR 技术来识别每个边界框内的文本,然后识别边界框包围的良好键值对。
由边界框包围的键(即“日期:”)和值(即“2-23-2019”)。
键值对和文档处理
由本规范编程的解析系统可以执行文档处理。
系统通过数据通信网络(例如,使用系统提供的API)从远程系统用户接收作为上传的文档。 文档可以以任何适当的非结构化数据格式表示,例如PDF文档或图像文档(例如PNG或JPEG文档)。
系统将文档转换为图像,即表示纸张视觉外观的有序数值集合。 例如,图像可能是文档的黑白图像,它被描述为数值强度值的二维数组。
通过一组检测模型参数生成一个输出,该输出定义了文档图像中的边界框。 每个边界框都被预测为包含一个键值对,包括关键文本数据和值文本数据,其中键定义了一个表征值的标签。
检测模型可以是包括卷积神经网络的对象检测模型。
直接在您的收件箱中搜索新闻
*必需的