
Procesarea documentelor folosind perechi cheie-valoare structurate
Publicat: 2022-03-31De ce perechi cheie-valoare în acest sistem de procesare a documentelor?
Scrierea acestei postări mi-a amintit de o postare din 2007 pe care am scris-o despre căutarea locală și datele structurate în care perechile cheie-valoare erau un aspect important al acelui brevet din 2007. Postarea a fost:
Informații structurate în Căutarea locală Google.
Nu mi s-a părut interesant să văd Google scriind despre inserarea perechilor cheie-valoare într-un sistem de procesare a documentelor ca cel de aici, cu o abordare de învățare automată în centrul ei, intrând în SEO tehnic.
Utilizările perechilor cheie-valoare sunt încă importante acum, după 15 ani.
Procesarea documentelor la Google
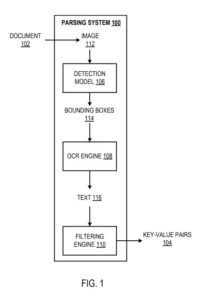
Înțelegerea procesării documentelor (de exemplu, facturi, talonoane de plată, chitanțe de vânzare și altele asemenea) este o nevoie esențială a afacerii. O parte mare (de exemplu, 90% sau mai mult) din datele întreprinderii este stocată și reprezentată în documente nestructurate. Extragerea datelor structurate din înregistrări poate fi costisitoare, consumatoare de timp și predispusă la erori.
Acest brevet descrie un sistem de procesare a documentelor de analiză și o metodă implementată ca programe de calculator pe computere în locații care convertesc documente nestructurate în perechi cheie-valoare structurate.
Sistemul de analiză este configurat pentru procesarea documentelor pentru a identifica datele textuale „cheie” și datele textuale „valorice” corespunzătoare în lucrare. Cheia definește o etichetă care caracterizează (adică este descriptivă) o valoare corespunzătoare.
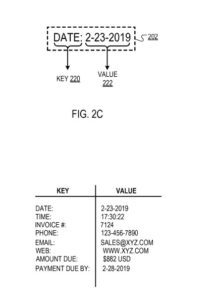
De exemplu, cheia „Data” poate corespunde valorii „23-2-2019”.
Există o metodă realizată de un aparat de procesare a datelor, care furnizează o imagine a unui document unui model de detectare, în care: modelul de detectare este configurat să proceseze imaginea prin valorile unei multitudini de parametri ai modelului de detectare pentru a genera o ieșire care definește casetele de delimitare generat pentru idee.
Fiecare casetă de delimitare generată pentru imagine este prevăzută pentru a include o pereche cheie-valoare care cuprinde date textuale critice și date textuale de valoare, în care datele textuale necesare definesc o etichetă care caracterizează datele textuale de valoare.
Fiecare dintre casetele de delimitare generate pentru imagine: identifică informațiile textuale incluse în caseta de delimitare folosind o tehnică de recunoaștere optică a caracterelor; determinarea dacă datele textuale deținute de caseta de delimitare definesc o pereche cheie-valoare; și ca răspuns la determinarea faptului că datele textuale incluse în caseta de delimitare reprezintă o pereche cheie-valoare, furnizând cuplul cheie-valoare pentru utilizare în caracterizarea documentului.
Modelul de detectare este un model de rețea neuronală.
Modelul rețelei neuronale cuprinde o rețea neuronală convoluțională.
Modelul rețelei neuronale este antrenat pe un set de exemple de antrenament. Fiecare exemplu de instruire cuprinde o intrare de antrenament și o ieșire țintă; intrarea de instruire include o imagine de instruire a unui document de instruire. Ieșirea țintă conține date care definesc casete de delimitare în imaginea de antrenament care includ o pereche cheie-valoare respectivă.
Documentul este o factură.

Furnizarea unei imagini a unui document unui model de detectare cuprinde: identificarea unei clase particulare de hârtie; și oferind ideea documentului unui model de detectare care este instruit să proceseze copii de tipul specific.
- Determinarea dacă datele textuale incluse în caseta de delimitare definesc o pereche cheie-valoare cuprinde:
- Decizia că informațiile textuale deținute de caseta de delimitare includ o cheie dintr-un set predeterminat de chei valide;
- Găsirea unui tip de parte a datelor textuale deținute de caseta de delimitare care nu are cheia; identificarea unei locații a soiurilor potrivite pentru valorile corespunzătoare cheii
- Alegerea ca stilul părții de date textuale închise de căsuța de delimitare care nu include cheia să fie inclus în setul de tipuri valide pentru valorile corespunzătoare cheii.
- Învățarea că un set de tipuri valide pentru valorile corespunzătoare cheii cuprinde: maparea cheii la colecția de tipuri adecvate pentru valorile corespunzătoare cheii folosind o mapare predeterminată.
Setul de chei valide și maparea de la chei la locațiile corespunzătoare de tipuri adecvate pentru valorile corespunzătoare cheilor sunt furnizate de un utilizator.
Cutiile de delimitare au o formă dreptunghiulară.
Metoda mai cuprinde: primirea documentului de la un utilizator; și conversia hârtiei într-o imagine, în care pictura ilustrează documentul.
O metodă realizată de sistemul de procesare a documentelor, metoda cuprinzând:
- Furnizarea unei imagini a unui document unui model de detectare configurat pentru a procesa imaginea pentru a fi identificată în casetele de delimitare a imaginii prevăzute pentru a include o pereche cheie-valoare care cuprinde date textuale critice și date textuale de valoare, în care cheia definește o etichetă care caracterizează o valoare corespunzătoare la cheie; pentru fiecare dintre casetele de delimitare generate pentru imagine,
- Identificarea datelor textuale incluse în caseta de delimitare folosind o tehnică de recunoaștere optică a caracterelor și determinarea dacă informațiile textuale deținute de caseta de delimitare definesc o pereche cheie-valoare
- Producerea echipei cheie-valoare pentru a fi utilizată în caracterizarea documentului.
Modelul de detectare este un model de învățare automată cu parametri care pot fi antrenați pe un set de date de antrenament.
Modelul de învățare automată cuprinde un model de rețea neuronală, în special o rețea neuronală convoluțională.
Modelul de învățare automată este antrenat pe un set de exemple de antrenament, iar fiecare exemplu de antrenament are o intrare de antrenament și o ieșire țintă.
Intrarea de instruire cuprinde o imagine de instruire a unui document de instruire. Ieșirea țintă include casete de delimitare care definesc datele în imaginea de antrenament, fiecare înglobând o pereche cheie-valoare respectivă.
Documentul este o factură.
Furnizarea unei imagini a unui document unui model de detectare cuprinde: identificarea unei clase particulare de hârtie; și oferirea ideii de document unui model de detectare care este instruit să proceseze documente de tipul specific.
Este o pereche cheie-valoare?
Determinarea dacă datele textuale incluse în caseta de delimitare definesc o pereche cheie-valoare înseamnă:
- Decizia că informațiile textuale deținute de caseta de delimitare includ o cheie dintr-un set predeterminat de chei valide
- Găsirea unui tip de parte a datelor textuale deținute de caseta de delimitare care nu are cheia
- Notarea unei locații a soiurilor potrivite pentru valorile corespunzătoare cheii
- Alegerea stilului părții de date textuale incluse în caseta de delimitare care nu include cheia este inclusă în setul de tipuri valide pentru valorile corespunzătoare cheii.
Identificarea unui set de tipuri valide pentru valorile corespunzătoare cheii cuprinde: maparea cheii la colecția de tipuri adecvate pentru valorile corespunzătoare cheii folosind o mapare predeterminată.
Setul de chei valide și maparea de la chei la locațiile corespunzătoare de tipuri adecvate pentru valorile corespunzătoare cheilor sunt furnizate de un utilizator.
Cutiile de delimitare au o formă dreptunghiulară.
Metoda mai cuprinde: primirea documentului de la un utilizator; și conversia hârtiei într-o imagine, în care pictura ilustrează documentul.
Conform unui alt aspect, există un sistem care cuprinde: calculatoare; şi dispozitive de stocare cuplate la computere, în care dispozitivele de stocare stochează instrucţiuni care, atunci când sunt executate de computere, determină computerele să efectueze operaţii cuprinzând operaţiile metodei descrise mai devreme.
Avantajele acestei abordări de procesare a documentelor
Sistemul descris în această specificație poate fi folosit pentru a converti un număr mare de documente nestructurate în perechi cheie-valoare structurate. Astfel, sistemul evită necesitatea extragerii datelor structurate din documente nestructurate, care pot fi costisitoare, consumatoare de timp și predispuse la erori.
Sistemul descris în această specificație poate identifica perechi cheie-valoare în documente cu un nivel ridicat de acuratețe (de exemplu, pentru unele tipuri de documente, cu o acuratețe mai mare de 99%). Astfel, sistemul poate fi potrivit pentru implementare în aplicații (de exemplu, procesarea documentelor financiare) care necesită un nivel ridicat de acuratețe.
Sistemul descris în această specificație se poate generaliza mai bine decât unele sisteme convenționale, adică are capacități de generalizare îmbunătățite în comparație cu unele metode tradiționale.
În special, utilizând un model de detectare învățat de mașină, antrenat să recunoască semnalele vizuale care disting perechile cheie-valoare din documente, sistemul poate identifica perechi cheie-valoare ale stilului, structurii sau conținutului specific al lucrărilor.
Identificarea perechilor cheie-valoare în brevetul de procesare a documentelor
Identificarea perechilor cheie-valoare în documente
Inventatori: Yang Xu, Jiang Wang și Shengyang Dai
Cesionar: Google LLC
Brevet SUA: 11.288.719
Acordat: 29 martie 2022
Depus: 27 februarie 2020
Abstract
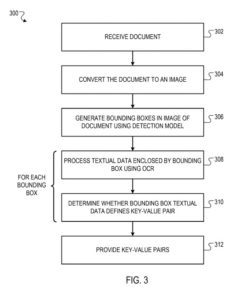
Metode, sisteme și aparate, inclusiv programe de calculator codificate pe un mediu de stocare computerizat, pentru conversia documentelor nestructurate în perechi cheie-valoare structurate.
Într-un aspect, o metodă cuprinde: furnizarea unei imagini a unui document unui model de detectare, în care: modelul de detectare este configurat să proceseze imaginea pentru a genera o ieșire care definește casetele de delimitare generate pentru imagine; și fiecare casetă de delimitare generată pentru imagine este prevăzută pentru a include o pereche cheie-valoare cuprinzând date textuale cheie și date textuale valori, în care datele textuale cheie definesc o etichetă care caracterizează datele textuale ale valorii și pentru fiecare dintre casetele de delimitare generate pentru imaginea: identificarea datelor textuale incluse în caseta de delimitare folosind o tehnică de recunoaștere optică a caracterelor și determinarea dacă datele textuale incluse în caseta de delimitare definesc o pereche cheie-valoare.
Un exemplu de sistem de analiză
Sistemul de analiză este un exemplu de metodă implementată ca programe de calculator pe computere în locații în care sunt implementate sistemele, componentele și tehnicile descrise mai jos.
Sistemul de analiză este configurat să proceseze un document (de exemplu, o factură, un bon de plată sau o chitanță de vânzare) pentru a identifica perechile cheie-valoare din hârtie. O „pereche cheie-valoare” se referă la o cheie și o valoare corespunzătoare, în general date textuale. „Datele textuale” ar trebui să fie înțelese ca referindu-se cel puțin la: caractere alfabetice, numere și simboluri speciale. După cum s-a descris mai devreme, o cheie definește o etichetă care caracterizează o valoare corespunzătoare.
Sistemul poate primi documentul într-o varietate de moduri.
De exemplu, sistemul poate primi hârtia ca încărcare de la un utilizator de sistem la distanță printr-o rețea de comunicații de date (de exemplu, folosind o interfață de programare a aplicației (API) pusă la dispoziție de sistem). Documentul poate fi reprezentat în orice format adecvat de date nestructurate, de exemplu, ca document Portable Document Format (PDF) sau ca document imagine (de exemplu, un document Portable Network Graphics (PNG) sau Joint Photographic Experts Group (JPEG)).
Identificați perechi cheie-valoare în procesarea documentelor
Sistemul folosește un model de detectare, un motor de recunoaștere optică a caracterelor (OCR) și un motor de filtrare pentru a identifica perechile cheie-valoare în procesarea documentelor.
Modelul de detectare este configurat pentru a procesa o imagine a documentului pentru a genera o ieșire care definește casetele de delimitare în imagine. Fiecare este prezis să includă date textuale reprezentând o pereche cheie-valoare respectivă. Adică, fiecare casetă de delimitare trebuie să aibă informații textuale care definesc:
(i) o cheie și
(ii) o valoare corespunzătoare cheii. De exemplu, o casetă de delimitare poate include datele textuale „Nume: John Smith”, care definește cheia „Nume” și valoarea corespunzătoare „John Smith”. Modelul de detectare poate fi configurat pentru a genera casete de delimitare care includ o singură pereche cheie-valoare (adică, mai degrabă decât multe cupluri cheie-valoare).
Imaginea documentului este o colecție ordonată de valori numerice care reprezintă aspectul vizual al hârtiei. Imaginea poate fi o imagine alb-negru a documentului. În acest exemplu, imaginea poate fi descrisă ca o matrice bidimensională de valori numerice de intensitate. Ca un alt exemplu, imaginea poate fi o imagine color a documentului. În acest exemplu, imaginea poate fi reprezentată ca o imagine cu mai multe canale. Fiecare canal corespunde unei culori respective (de exemplu, roșu, verde sau albastru) și este definit ca o matrice bidimensională de valori numerice de intensitate.
Casetele de delimitare pot fi casete de delimitare dreptunghiulare. O casetă de delimitare dreptunghiulară poate fi reprezentată de coordonatele unui anumit colț al casetei de delimitare și de lățimea și înălțimea corespunzătoare a containerului de delimitare. Mai general, sunt posibile alte forme de cutie de delimitare și alte moduri de reprezentare a casetelor de delimitare.
În timp ce modelul de detectare poate recunoaște și utiliza orice cadre sau margini prezente în document ca semnale vizuale, casetele de delimitare nu sunt constrânse să se alinieze (adică să coincidă) cu orice structuri existente ale limitelor curente în lucrare. Mai mult, sistemul poate genera casetele de delimitare fără a afișa casetele de delimitare în imaginea documentului.
Adică, sistemul poate genera date care definesc pachetele de delimitare fără a oferi un semn vizual al poziției casetelor de delimitare unui utilizator al sistemului.
Modelul de detectare este, în general, un model de învățare automată, adică un model având un set de parametri care pot fi instruiți pe un set de date de antrenament. Datele de instruire includ multe exemple de antrenament, fiecare dintre ele include:
(i) o imagine de formare care descrie un document de formare și
(ii) o ieșire țintă care definește casetele de delimitare care include o pereche cheie-valoare respectivă în imaginea de antrenament.
Datele de antrenament pot fi generate prin adnotare manuală, adică de către o persoană care identifică casete de delimitare în jurul perechilor cheie-valoare din documentul de instruire (de exemplu, folosind un software de adnotare adecvat).
Antrenarea modelului de detectare folosind tehnici de învățare automată pe un set de date de antrenament îi permite să recunoască semnale vizuale care îi vor permite să identifice perechile cheie-valoare în documente. De exemplu, modelul de detectare poate fi antrenat să recunoască semnale locale (de exemplu, stiluri de text și pozițiile spațiale relative ale cuvintelor) și semnale globale (de exemplu, prezența marginilor în document) pentru a identifica perechile cheie-valoare.

Indiciile vizuale care permit modelului de detectare să rețină echipele cheie-valoare în înregistrări, în general, nu includ semnale care reprezintă semnificația explicită a cuvintelor din document.
Semnale vizuale care disting perechile cheie-valoare
Antrenarea modelului de detectare pentru a recunoaște semnalele vizuale care disting perechile cheie-valoare din documente permite modelului de detectare să „generalice” dincolo de datele de antrenament utilizate pentru pregătirea modelului de detectare. Modelul de detectare antrenat poate procesa o imagine care ilustrează un document pentru a genera casete de delimitare care includ perechi cheie-valoare în hârtie, chiar dacă copia nu a fost inclusă în datele de antrenament utilizate pentru a antrena modelul de detectare.
Într-un exemplu, modelul de detectare poate fi un model de detectare a obiectului rețelei neuronale (de exemplu, inclusiv rețelele neuronale convoluționale), unde „obiectele” corespund perechilor cheie-valoare din document. Parametrii antrenabili ai modelului rețelei neuronale includ ponderile modelului rețelei neuronale, de exemplu, ponderi care definesc filtrele convoluționale în modelul rețelei neuronale.
Modelul rețelei neuronale poate fi instruit pe setul de date de antrenament utilizând o procedură de antrenament de învățare automată adecvată, de exemplu, coborârea gradientului stocastic. În special, la fiecare iterație de antrenament, modelul de rețea neuronală poate procesa imagini de antrenament dintr-un „lot” (adică, un set) de exemple de antrenament pentru a genera casete de delimitare prevăzute pentru a include perechile cheie-valoare respective în imaginile de antrenament. Sistemul poate testa o funcție de delimitare care caracterizează o măsură de similitudine între cutiile de delimitare generate de modelul rețelei neuronale și cutiile de delimitare specificate de rezultatele țintă corespunzătoare ale exemplelor de antrenament.
Măsura asemănării dintre două casete de delimitare poate fi, de exemplu, o sumă a distanțelor pătrate dintre vârfurile respective ale casetelor de delimitare. Sistemul poate determina gradienții funcției de țintire a câștigat valorile parametrilor rețelei neuronale (de exemplu, utilizând propagarea inversă) și apoi să folosească pantele pentru a ajusta valorile actuale ale parametrilor rețelei neuronale.
În special, sistemul poate folosi regula de actualizare a parametrilor de la orice algoritm adecvat de optimizare a coborârii gradientului (de exemplu, Adam sau RMSprop) pentru a ajusta valorile actuale ale parametrilor rețelei neuronale folosind gradienții. Sistemul antrenează modelul rețelei neuronale până când este îndeplinit un criteriu de terminare a antrenamentului (de exemplu, până când a fost efectuat un număr predeterminat de iterații de antrenament sau o schimbare a valorii funcției de obiectiv al obiectului între iterațiile de antrenament scade sub un prag predeterminat).
Înainte de a utiliza modelul de detectare, sistemul poate identifica o „clasă” a documentului (de exemplu, factură, bon de plată sau chitanță de vânzare). Un utilizator al sistemului poate identifica clasa înregistrării la furnizarea documentului către sistem. Metoda poate utiliza o rețea neuronală de clasificare pentru a clasifica clasa lucrării. Sistemul poate utiliza tehnici OCR pentru a identifica textul din document și, după aceea, pentru a plasa stilul documentului pe baza textului din document. Într-un exemplu special, ca răspuns la determinarea expresiei „Plată netă”, sistemul poate identifica clasa de hârtie ca „bon de plată”.
Într-un alt exemplu special, ca răspuns la identificarea expresiei „Taxa pe vânzări”, sistemul poate identifica clasa documentului drept „factură”. După identificarea clasei particulare a înregistrării, sistemul poate utiliza un model de detectare care este instruit să proceseze copii ale clasei specifice. Metoda poate utiliza un model de detectare care a fost instruit pe date de antrenament care au inclus doar documente din aceeași clasă particulară ca documentul.
Utilizarea unui model de detectare care este instruit să proceseze documente din aceeași clasă ca documentul poate îmbunătăți performanța modelului de detectare (de exemplu, permițând modelului de detectare să genereze cutii de delimitare în jurul perechilor cheie-valoare cu o mai mare acuratețe).
Pentru fiecare casetă de delimitare, sistemul prelucrează partea din imagine închisă de caseta de delimitare folosind motorul OCR pentru a identifica datele textuale (adică textul) deținute de caseta de delimitare. În special, motorul OCR identifică textul cuprins de o casetă de delimitare prin identificarea fiecărui caracter alfabetic, numeric sau unic cuprins de caseta de delimitare. Motorul OCR poate folosi orice tehnică adecvată pentru a identifica textul înconjurat de o casetă de delimitare.
Motorul de filtrare determină dacă textul încadrat de o casetă de delimitare reprezintă o pereche cheie-valoare. Motorul de filtrare poate decide dacă textul din jurul casetei de delimitare reprezintă o pereche cheie-valoare în mod corespunzător. De exemplu, motorul de filtrare poate determina dacă textul inclus în caseta de delimitare include o cheie validă dintr-un set predeterminat de chei drepte pentru o casetă de delimitare dată. De exemplu, colecția de chei valide poate consta în: „Data”, „Ora”, „Nr. factură”, „Suma datorată” și altele asemenea.
În compararea diferitelor porțiuni de text pentru a determina dacă textul inclus în caseta de delimitare include o cheie validă, motorul de filtrare poate determina că două bucăți de text „se potrivesc”, chiar dacă nu sunt identice. De exemplu, motorul de filtrare poate determina că două părți ale cititorului se potrivesc chiar dacă includ majuscule sau semne de punctuație diferite (de exemplu, sistemul de filtrare poate determina că „Data”, „Data:” „data” și „data:” toate se potrivesc).
Ca răspuns la determinarea faptului că textul cuprins de caseta de delimitare nu include o cheie validă din cheile din dreapta, motorul de filtrare determină că textul înconjurat de caseta de delimitare nu reprezintă o pereche cheie-valoare.
Ca răspuns la determinarea faptului că textul inclus în caseta de delimitare include o cheie validă, motorul de filtrare identifică un „tip” (de exemplu, alfabetic, numeric, temporal) al părții de text închisă de caseta de delimitare neidentificată ca cheie ( adică textul „non-cheie”). De exemplu, pentru o casetă de delimitare care are textul: „Data: 23-2-2019”, unde motorul de filtrare identifică „Data:” ca cheie (așa cum s-a descris mai devreme), motorul de filtrare poate identifica tipul de -textul cheie „23-2-2019” ca fiind „temporal”.
Pe lângă identificarea tipului textului non-cheie, motorul de filtrare identifică un set de tipuri valide pentru valorile corespunzătoare cheii. în particular, motorul de filtrare poate mapa cheia la un grup de tipuri de date utile pentru valorile corespunzătoare cheii printr-o mapare predeterminată. De exemplu, motorul de filtrare poate mapa cheia „Nume” cu tipul de date valorii corespunzător „alfabetic”, indicând faptul că valoarea corespunzătoare cheii ar trebui să aibă un tip de date alfabetic (de exemplu, „John Smith”).
Ca un alt exemplu, motorul de filtrare poate mapa cheia „Data” cu tipul de date corespunzător valorii „temporal”, indicând faptul că valoarea corespunzătoare cheii ar trebui să aibă un tip de date temporal (de exemplu, „23-2-2019” sau „ 17:30:22”).
Motorul de filtrare determină dacă tipul de text non-cheie este inclus în setul de tipuri valide pentru valorile corespunzătoare cheii. Ca răspuns la stabilirea faptului că stilul textului non-cheie este inclus în colecția de tipuri adecvate pentru valorile corespunzătoare legendei, motorul de filtrare determină că textul inclus în caseta de delimitare reprezintă o pereche cheie-valoare. În special, motorul de filtrare identifică textul non-cheie ca valoare corespunzătoare cheii. În caz contrar, motorul de filtrare determină că textul inclus în caseta de delimitare nu reprezintă o pereche cheie-valoare.
Setul de chei valide și maparea de la cheile drepte la locații ale tipurilor de date utile pentru valorile corespunzătoare cheilor valide pot fi furnizate de un utilizator de sistem (de exemplu, printr-un API pus la dispoziție de sistem).
După identificarea perechilor cheie-valoare din textul închis de casetele de delimitare respective utilizând motorul de filtrare, sistemul scoate perechile cheie-valoare identificate. De exemplu, sistemul poate furniza echipele cheie-valoare unui utilizator de la distanță al sistemului printr-o rețea de comunicații de date (de exemplu, folosind un API pus la dispoziție de sistem). Ca un alt exemplu, sistemul poate stoca date care definesc perechile cheie-valoare identificate într-o bază de date (sau altă structură de date) accesibilă utilizatorului sistemului.
În unele cazuri, un utilizator de sistem poate solicita sistemului să identifice valoarea corespunzătoare cheii specifice din document (de exemplu, „Nr. factură”). În aceste cazuri, în loc să identifice și să furnizeze fiecare pereche cheie-valoare din înregistrare, sistemul poate procesa textul plasat în casetele de delimitare respective până când echipa cheie-valoare solicitată recunoaște și execută perechea cheie-valoare comandată.
Așa cum este descris mai sus, modelul de detectare poate fi antrenat pentru a genera casete de delimitare care includ fiecare o pereche cheie-valoare respectivă. Sau, în loc să utilizeze un singur model de detectare, sistemul poate include:
(i) un „model de detectare a cheilor” care este instruit pentru a genera casete de delimitare care includ cheile respective și
(ii) un „model de detectare a valorii” care este antrenat pentru a genera casete de delimitare care includ valorile respective.
Sistemul poate identifica perechile cheie-valoare din casetele de delimitare cheie și casetele de delimitare valori în mod corespunzător. De exemplu, pentru fiecare echipă de casete de delimitare care include o casetă de delimitare cheie și o casetă de delimitare a valorii, sistemul poate genera un „scor de potrivire” bazat pe:
(i) proximitatea spațială a casetelor de delimitare,
(ii) dacă caseta de delimitare a cheii include o cheie validă și
(iii) dacă tipul valorii incluse în caseta de delimitare a valorii este inclus într-un set de tipuri valide pentru valorile corespunzătoare cheii.
Sistemul poate identifica cheia închisă de o casetă de delimitare a cheii și valoarea înconjurată de o casetă de delimitare a valorii ca o pereche cheie-valoare dacă scorul de potrivire dintre caseta de delimitare a cheii și caseta de delimitare a valorii depășește un prag.
Un exemplu de document de factură
Un utilizator al sistemului de procesare a documentelor poate furniza factura (de exemplu, ca o imagine scanată sau un fișier PDF) sistemului de analiză.
Cutiile de delimitare sunt generate de modelul de detectare al sistemului de analiză. Fiecare casetă de delimitare este prevăzută pentru a include date textuale care definesc o pereche cheie-valoare. Modelul de detectare nu generează o casetă de delimitare care conține text (adică „Mulțumesc pentru afacerea dvs.!”), deoarece acest text nu reprezintă o pereche cheie-valoare.
Sistemul de analizare folosește tehnici OCR pentru a identifica textul din interiorul fiecărei casete de delimitare și apoi identifică perechi cheie-valoare bune, închise de casetele de delimitare.
Cheia (adică, „Data:”) și valoarea (adică, „23-2-2019”) incluse în caseta de delimitare.
Perechi cheie-valoare și procesare a documentelor
Un sistem de analiză programat prin această specificație poate efectua procesarea documentelor.
Sistemul primește un document ca încărcare de la un utilizator de sistem la distanță printr-o rețea de comunicații de date (de exemplu, folosind un API pus la dispoziție de sistem). Documentul poate fi reprezentat în orice format adecvat de date nestructurate, cum ar fi un document PDF sau un document imagine (de exemplu, un document PNG sau JPEG).
Sistemul convertește documentul într-o imagine, adică o colecție ordonată de valori numerice care reprezintă aspectul vizual al hârtiei. De exemplu, imaginea poate fi o imagine alb-negru a documentului care este descrisă ca o matrice bidimensională de valori numerice de intensitate.
Printr-un set de parametri ai modelului de detectare pentru a genera o ieșire care definește casete de delimitare în imaginea documentului. Fiecare casetă de delimitare este prevăzută pentru a include o pereche cheie-valoare care include date textuale critice și date textuale de valoare, unde cheia definește o etichetă care caracterizează valoarea.
Modelul de detectare poate fi un model de detectare a obiectelor care include rețele neuronale convoluționale.
Căutați știri direct în căsuța dvs. de e-mail
*Necesar