
使用結構化鍵值對的文檔處理
已發表: 2022-03-31為什麼在這個文檔處理系統中使用鍵值對?
寫這篇文章讓我想起了我在 2007 年寫的一篇關於本地搜索和結構化數據的文章,其中鍵值對是 2007 年專利的一個重要方面。 帖子是:
Google 本地搜索中的結構化信息。
看到谷歌寫的關於在像這裡這樣的文檔處理系統中插入鍵值對的文章讓我感到很有趣,其核心是機器學習方法,進入技術 SEO。
15 年後,key-value Ppairs 的使用仍然很重要。
Google 的文檔處理
了解文檔處理(例如,發票、付款存根、銷售收據等)是一項重要的業務需求。 企業數據的很大一部分(例如,90% 或更多)在非結構化文檔中存儲和表示。 從記錄中提取結構化數據可能是昂貴、耗時且容易出錯的。
該專利描述了一種文檔處理解析系統和一種方法,該方法在將非結構化文檔轉換為結構化鍵值對的位置的計算機上實現為計算機程序。
解析系統被配置為文檔處理,以識別論文中的“關鍵”文本數據和相應的“價值”文本數據。 鍵定義了表徵(即,描述)相應值的標籤。
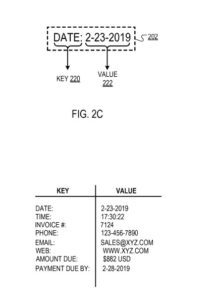
例如,鍵“日期”可以對應於值“2-23-2019”。
有一種由數據處理裝置執行的方法,其將文檔的圖像提供給檢測模型,其中:檢測模型被配置為通過多個檢測模型參數的值來處理圖像以生成定義邊界框的輸出為這個想法而生成。
為圖像生成的每個邊界框都被預測為包含一個鍵值對,該鍵值對包括關鍵文本數據和值文本數據,其中必要的文本數據定義了表徵文本值數據的標籤。
為圖像生成的每個邊界框: 使用光學字符識別技術識別邊界框包圍的文本信息; 判斷邊界框保存的文本數據是否定義了鍵值對; 並且響應於確定由邊界框包圍的文本數據表示鍵值對,提供鍵值對以用於表徵文檔。
檢測模型是神經網絡模型。
神經網絡模型包括卷積神經網絡。
神經網絡模型在一組訓練示例上進行訓練。 每個訓練樣例包括一個訓練輸入和一個目標輸出; 訓練輸入包括訓練文檔的訓練圖像。 目標輸出包含定義訓練圖像中的邊界框的數據,其中包含相應的鍵值對。
該文件是發票。

將文檔的圖像提供給檢測模型包括:識別特定類別的紙張; 並將文檔的想法提供給經過訓練以處理特定類型副本的檢測模型。
- 判斷邊界框包圍的文本數據是否定義鍵值對包括:
- 確定邊界框所擁有的文本信息包括來自預定的一組有效鍵的鍵;
- 查找邊界框所持有的文本數據中沒有key的部分類型; 識別與鍵對應的值的合適品種的位置
- 選擇由邊界框包圍的不包含鍵的文本數據部分的樣式將包含在與鍵對應的值的有效類型集中。
- 獲知鍵對應的值的有效類型集合包括:使用預定映射將鍵映射到鍵對應的值的合適類型集合。
有效鍵的集合以及從鍵到對應於鍵的值的合適類型的對應位置的映射由用戶提供。
邊界框具有矩形形狀。
該方法還包括:接收來自用戶的文檔; 並將紙張轉換為圖像,其中繪畫描繪了文件。
一種由文檔處理系統執行的方法,該方法包括:
- 將文檔的圖像提供給檢測模型,該檢測模型被配置為處理圖像以在圖像邊界框中進行識別,該圖像邊界框被預測為包圍包括關鍵文本數據和值文本數據的鍵值對,其中鍵定義了表徵對應值的標籤到鑰匙; 對於為圖像生成的每個邊界框,
- 使用光學字符識別技術識別邊界框包圍的文本數據,並確定邊界框持有的文本信息是否定義了鍵值對
- 輸出用於表徵文檔的鍵值團隊。
檢測模型是一種機器學習模型,其參數可以在訓練數據集上進行訓練。
機器學習模型包括神經網絡模型,特別是卷積神經網絡。
機器學習模型在一組訓練示例上進行訓練,每個訓練示例都有一個訓練輸入和一個目標輸出。
訓練輸入包括訓練文檔的訓練圖像。 目標輸出包括訓練圖像中定義數據的邊界框,每個邊界框都包含相應的鍵值對。
該文件是發票。
將文檔的圖像提供給檢測模型包括:識別特定類別的紙張; 並將文檔的想法提供給經過訓練以處理特定類型文檔的檢測模型。
是鍵值對嗎?
判斷邊界框包圍的文本數據是否定義了鍵值對意味著:
- 確定邊界框擁有的文本信息包括來自預定的一組有效鍵的鍵
- 查找邊界框所持有的文本數據的一部分的類型,它沒有鍵
- 記下與鍵對應的值的合適品種的位置
- 選擇由邊界框包圍的不包含鍵的文本數據部分的樣式將包含在與鍵對應的值的有效類型集中。
識別與鍵對應的值的一組有效類型包括:使用預定映射將鍵映射到與鍵對應的值的適當種類的集合。
有效鍵的集合以及從鍵到對應於鍵的值的合適類型的對應位置的映射由用戶提供。
邊界框具有矩形形狀。
該方法還包括:接收來自用戶的文檔; 並將紙張轉換為圖像,其中繪畫描繪了文件。
根據另一方面,存在一種系統,包括:計算機; 以及耦合到計算機的存儲設備,其中存儲設備存儲指令,當由計算機執行時,使計算機執行包括前述方法的操作的操作。
這種文檔處理方法的優點
本規範中描述的系統可以用來將大量的非結構化文檔轉換為結構化的鍵值對。 因此,該系統消除了從非結構化文檔中提取結構化數據的需要,這可能是昂貴、耗時且容易出錯的。
本規範中描述的系統能夠以較高的準確度識別文檔中的鍵值對(例如,對於某些類型的文檔,準確度大於 99%)。 因此,該系統可能適合部署在需要高度準確性的應用程序(例如,處理財務文件)中。
本規範所描述的系統比一些傳統系統具有更好的泛化能力,即與一些傳統方法相比,它具有改進的泛化能力。
特別是,通過利用機器學習的檢測模型訓練來識別區分文檔中鍵值對的視覺信號,系統可以識別論文的特定樣式、結構或內容的鍵值對。
文檔處理專利中的鍵值對識別
識別文檔中的鍵值對
發明人:楊旭、姜王、戴盛陽
受讓人:谷歌有限責任公司
美國專利:11,288,719
授予:2022 年 3 月 29 日
提交日期:2020 年 2 月 27 日
抽象的
用於將非結構化文檔轉換為結構化鍵值對的方法、系統和設備,包括在計算機存儲介質上編碼的計算機程序。
在一個方面,一種方法包括: 將文檔的圖像提供給檢測模型,其中: 檢測模型被配置為處理圖像以生成定義為圖像生成的邊界框的輸出; 並且為圖像生成的每個邊界框被預測為包含一個鍵值對,該鍵值對包括鍵文本數據和值文本數據,其中鍵文本數據定義了表徵值文本數據的標籤,並且為每個生成的邊界框圖像:利用光學字符識別技術識別包圍盒包圍的文本數據,並確定包圍盒包圍的文本數據是否定義鍵值對。
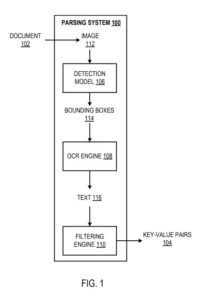
一個示例解析系統
解析系統是在以下描述的系統、組件和技術被實現的位置的計算機上實現為計算機程序的方法的示例。
解析系統被配置為處理文檔(例如,發票、付款存根或銷售收據)以識別論文中的鍵值對。 “鍵值對”是指一個鍵和一個對應的值,通常是文本數據。 “文本數據”應該被理解為至少是指:字母字符、數字和特殊符號。 如前所述,鍵定義了表徵相應值的標籤。
系統可以以多種方式接收文檔。
例如,系統可以通過數據通信網絡(例如,使用系統提供的應用程序編程接口(API))從遠程系統用戶接收作為上傳的論文。 該文檔可以以任何適當的非結構化數據格式表示,例如,作為可移植文檔格式(PDF)文檔或作為圖像文檔(例如,可移植網絡圖形(PNG)或聯合圖像專家組(JPEG)文檔)。
識別文檔處理中的鍵值對
該系統使用檢測模型、光學字符識別 (OCR) 引擎和過濾引擎來識別文檔處理中的鍵值對。
檢測模型被配置為處理文檔的圖像以生成定義圖片中邊界框的輸出。 每個都被預測為包含表示相應鍵值對的文本數據。 也就是說,每個邊界框都應該有文本信息來定義:
(i) 一把鑰匙,和
(ii) 對應於鍵的值。 例如,邊界框可能包含文本數據“姓名:約翰·史密斯”,它定義了“姓名”鍵和相應的值“約翰·史密斯”。 檢測模型可以被配置為生成包圍單個鍵值對(即,而不是許多鍵值對)的邊界框。
文檔的圖像是代表紙張視覺外觀的有序數值集合。 該圖像可以是文檔的黑白圖像。 在這個例子中,圖片可以被描述為數值強度值的二維數組。 作為另一示例,圖像可以是文檔的彩色圖像。 在此示例中,圖片可以表示為多通道圖像。 每個通道對應於相應的顏色(例如,紅色、綠色或藍色),並被定義為數值強度值的二維數組。
邊界框可以是矩形邊界框。 矩形邊界框可以由邊界框的特定角的坐標和邊界容器的相應寬度和高度來表示。 更一般地,其他邊界框形狀和其他表示邊界框的方式是可能的。
雖然檢測模型可以識別和使用文檔中存在的任何框架或邊界作為視覺信號,但邊界框不限於與論文中當前的任何現有邊界結構對齊(即,重合)。 此外,系統可以生成邊界框而不在文檔的圖像中顯示邊界框。
即,系統可以生成定義邊界包的數據,而不向系統的用戶給出邊界框位置的視覺標誌。
檢測模型一般是機器學習模型,即具有一組參數的模型,可以在一組訓練數據上得到訓練。 訓練數據包括許多訓練樣例,每個訓練樣例包括:
(i) 描述訓練文檔的訓練圖像,以及
(ii) 定義邊界框的目標輸出在訓練圖像中包含相應的鍵值對。
訓練數據可以通過手動註釋生成,即,由人識別訓練文檔中鍵值對周圍的邊界框(例如,使用適當的註釋軟件)。
在一組訓練數據上使用機器學習技術訓練檢測模型,使其能夠識別視覺信號,從而識別文檔中的鍵值對。 例如,檢測模型可以被訓練以識別局部信號(例如,文本樣式和單詞的相對空間位置)和全局信號(例如,文檔中邊界的存在)以識別鍵值對。
使檢測模型能夠記住記錄中的鍵值團隊的視覺提示通常不包括表示文檔中單詞的明確含義的信號。
區分鍵值對的視覺信號
訓練檢測模型以識別區分文檔中鍵值對的視覺信號,使檢測模型能夠“泛化”超出用於準備檢測模型的訓練數據。 經過訓練的檢測模型可能會處理描述文檔的圖像,以生成包含論文中鍵值對的邊界框,即使副本未包含在用於訓練檢測模型的訓練數據中。
在一個示例中,檢測模型可以是神經網絡對象檢測模型(例如,包括卷積神經網絡),其中“對象”對應於文檔中的鍵值對。 神經網絡模型的可訓練參數包括神經網絡模型的權重,例如定義神經網絡模型中卷積濾波器的權重。
神經網絡模型可以使用適當的機器學習訓練程序在訓練數據集上進行訓練,例如隨機梯度下降。 特別地,在每次訓練迭代中,神經網絡模型可以處理來自“批次”(即,一組)訓練示例的訓練圖像,以生成預測為包圍訓練圖像中的各個鍵值對的邊界框。 該系統可以測試目標函數,該目標函數表徵由神經網絡模型生成的邊界框和由訓練示例的對應目標輸出指定的邊界框之間的相似性度量。
例如,兩個邊界框之間的相似性度量可以是邊界框的各個頂點之間的距離平方和。 系統可以確定目標函數的梯度,獲得神經網絡參數值(例如,使用反向傳播),然後使用斜率調整當前神經網絡參數值。
特別地,系統可以使用來自任何適當的梯度下降優化算法(例如,Adam 或 RMSprop)的參數更新規則來使用梯度調整當前神經網絡參數值。 系統訓練神經網絡模型直到滿足訓練終止標準(例如,直到已經執行了預定數量的訓練迭代或者訓練迭代之間的目標目標函數的值的變化低於預定閾值)。
在使用檢測模型之前,系統可以識別文檔的“類別”(例如,發票、付款存根或銷售收據)。 系統的用戶可以在將文檔提供給系統時識別記錄的類別。 該方法可以使用分類神經網絡對論文的類別進行分類。 系統可以使用 OCR 技術來識別文檔中的文本,然後根據文檔中的文本放置文檔的樣式。 在特定示例中,響應於確定短語“Net Pay”,系統可以將紙張類別識別為“pay stub”。

在另一個特定示例中,響應於識別短語“銷售稅”,系統可以將文檔的類別識別為“發票”。 在識別記錄的特定類別後,系統可以使用經過訓練的檢測模型來處理特定類別的副本。 該方法可以使用在僅包括與文檔相同特定類別的文檔的訓練數據上得到訓練的檢測模型。
使用經過訓練來處理與文檔相同類別的文檔的檢測模型可以提高檢測模型的性能(例如,通過使檢測模型能夠以更高的準確度圍繞鍵值對生成邊界框)。
對於每個邊界框,系統使用OCR引擎處理被邊界框包圍的圖像部分,以識別邊界框持有的文本數據(即文本)。 具體而言,OCR 引擎通過識別由邊界框包圍的每個字母、數字或唯一字符來識別由邊界框包圍的文本。 OCR 引擎可以使用任何適當的技術來識別由邊界框包圍的文本。
過濾引擎確定邊界框包圍的文本是否代表鍵值對。 過濾引擎可以決定邊界框周圍的文本是否適當地表示鍵值對。 例如,過濾引擎可以確定由邊界框包圍的文本是否包括來自給定邊界框的預定右鍵集合中的有效鍵。 例如,有效密鑰的集合可以包括:“日期”、“時間”、“發票#”、“到期金額”等。
在比較文本的不同部分以確定邊界框包圍的文本是否包括有效鍵時,過濾引擎可以確定兩段文本“匹配”,即使它們不相同。 例如,過濾引擎可以確定閱讀器的兩個部分是匹配的,即使它們包括不同的大寫或標點符號(例如,過濾系統可以確定“日期”、“日期:”、“日期”和“日期:”都是匹配的)。
響應於確定邊界框包圍的文本不包括來自正確鍵的有效鍵,過濾引擎確定邊界框包圍的文本不代表鍵值對。
響應於確定由邊界框包圍的文本包括有效鍵,過濾引擎識別未被識別為鍵的邊界框包圍的文本部分的“類型”(例如,字母、數字、時間)(即“非關鍵”文本)。 例如,對於具有文本:“日期:2-23-2019”的邊界框,其中過濾引擎將“日期:”標識為鍵(如前所述),過濾引擎可以識別非- 關鍵文本“2-23-2019”是“時間的”。
除了識別非鍵文本的類型外,過濾引擎還為鍵對應的值識別一組有效類型。 特別地,過濾引擎可以通過預定映射將關鍵字映射到一組有用的數據類型,用於對應於關鍵字的值。 例如,過濾引擎可以將鍵“Name”映射到對應的值數據類型“字母”,指示對應於鍵的值應該具有字母數據類型(例如,“John Smith”)。
作為另一個例子,過濾引擎可以將鍵“Date”映射到對應的值數據類型“temporal”,指示對應於鍵的值應該具有時間數據類型(例如,“2-23-2019”或“ 17:30:22”)。
過濾引擎確定非鍵文本的類型是否包含在與鍵對應的值的有效種類集中。 響應於確定非鍵文本的樣式被包括在與圖例對應的值的合適類型的集合中,過濾引擎確定由邊界框包圍的文本表示鍵值對。 具體來說,過濾引擎將非關鍵字文本識別為關鍵字對應的值。 否則,過濾引擎確定邊界框包圍的文本不代表鍵值對。
對於對應於有效鍵的值,有效鍵的集合和從右鍵到有用數據類型的位置的映射可以由系統用戶提供(例如,通過系統提供的API)。
在使用過濾引擎從各個邊界框包圍的文本中識別出鍵值對後,系統輸出識別出的鍵值對。 例如,系統可以通過數據通信網絡(例如,使用系統提供的API)向系統的遠程用戶提供鍵值組。 作為另一個示例,系統可以將定義所識別的鍵值對的數據存儲在系統用戶可訪問的數據庫(或其他數據結構)中。
在某些情況下,系統用戶可以請求系統識別與文檔中的特定鍵對應的值(例如,“發票#”)。 在這些情況下,系統可能會處理放置在相應邊界框中的文本,而不是識別和提供記錄中的每個鍵值對,直到被請求的鍵值團隊識別並執行有序的鍵值對。
如上所述,可以訓練檢測模型以生成邊界框,每個邊界框都包含相應的鍵值對。 或者,系統可能包括:
(i) 一個“鍵檢測模型”,經過訓練可以生成包圍各個鍵的邊界框,以及
(ii) 一個“值檢測模型”,經過訓練可以生成包含相應值的邊界框。
系統可以從鍵邊界框和值邊界框中適當地識別鍵值對。 例如,對於包含一個鍵邊界框和一個值邊界框的每組邊界框,系統可以根據以下內容生成“匹配分數”:
(i) 邊界框的空間接近度,
(ii) 密鑰邊界框是否包含有效密鑰,以及
(iii) 值邊界框所包圍的值的類型是否包含在與鍵對應的值的一組有效類型中。
如果鍵邊界框和值邊界框之間的匹配分數超過閾值,則係統可以將鍵邊界框包圍的鍵和值邊界框包圍的值識別為鍵值對。
發票文件示例
文檔處理系統的用戶可以將發票(例如,作為掃描圖像或PDF文件)提供給解析系統。
邊界框由解析系統的檢測模型生成。 每個邊界框都被預測為包含定義鍵值對的文本數據。 檢測模型不會生成包含文本的邊界框(即“感謝您的支持!”),因為該文本不代表鍵值對。
解析系統使用 OCR 技術來識別每個邊界框內的文本,然後識別邊界框包圍的良好鍵值對。
由邊界框包圍的鍵(即“日期:”)和值(即“2-23-2019”)。
鍵值對和文檔處理
由本規範編程的解析系統可以執行文檔處理。
系統通過數據通信網絡(例如,使用系統提供的API)從遠程系統用戶接收作為上傳的文檔。 文檔可以以任何適當的非結構化數據格式表示,例如PDF文檔或圖像文檔(例如PNG或JPEG文檔)。
系統將文檔轉換為圖像,即表示紙張視覺外觀的有序數值集合。 例如,圖像可能是文檔的黑白圖像,它被描述為數值強度值的二維數組。
通過一組檢測模型參數生成一個輸出,該輸出定義了文檔圖像中的邊界框。 每個邊界框都被預測為包含一個鍵值對,包括關鍵文本數據和值文本數據,其中鍵定義了一個表徵值的標籤。
檢測模型可以是包括卷積神經網絡的對象檢測模型。
直接在您的收件箱中搜索新聞
*必需的