
Googleがウェブサイトをランク付けする方法
公開: 2022-07-21
今日の非常に競争の激しいオンライン環境では、Googleで上位に表示される企業やウェブサイトは、間違いなく潜在的な顧客や読者から最も注目を集めるでしょう。 最終的に、誰もがその切望されたナンバーワンのランキングスペースに到達しようとしています。 500万を超えるGoogle検索結果を分析した後、その理由は簡単にわかります。
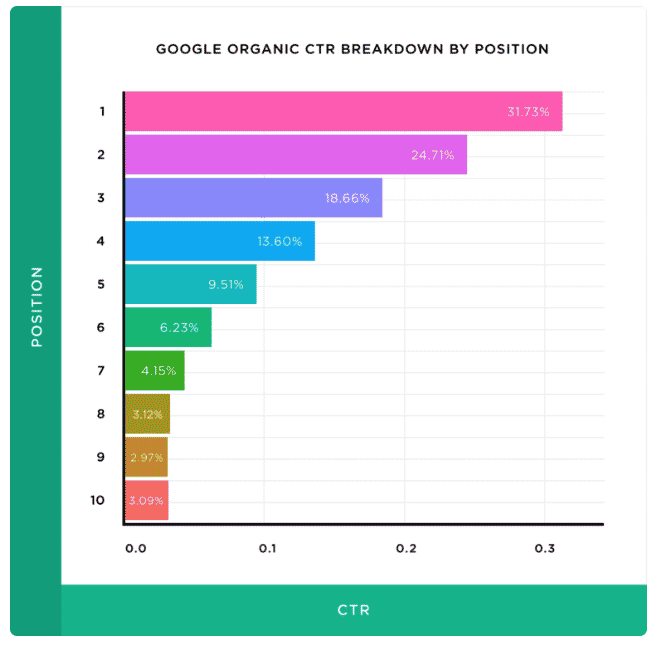
- #1の検索結果は(平均で)31.7%のクリック率を持ち、#10のスポットと比較してクリックを獲得する可能性が10倍高くなっています。
- #2の検索結果のクリック率は24.71%です
- #3の結果のクリック率は18.66%です
- 検索者の0.78%だけが2ページ目で何かをクリックしました
 出典:Backlinko
出典:Backlinko
Googleの最初の3つの位置が総クリック数の約75%を獲得しているという事実は、それほど驚くべきことではありません。 最後に何かをグーグルで検索したときのことを思い出してください。 特定のWebサイトを探しているのでない限り、おそらく最初の3つのオプションだけを見て、最初の結果をクリックしただけだと考えるのが安全です。
Google検索はどのように機能しますか?
Googleの主な目的は常に同じです。つまり、ユーザーがインターネット上で欲しいものを見つけられるようにすることです。
彼らは、最も関連性の高いWebサイトが最初に表示されるランキングシステムの形式で、特定のクエリに対して可能な限り最良の結果を提供することによってこれを実現します。 Googleが実際に結果をランク付けする方法を調べる前に、Google内で何かを検索したときに正確に何が起こるかを理解することが重要です。
一般的な仮定は、検索エンジンの結果ページ(SERP)に表示される結果はライブのウェブサイトであり、結果は「現時点で」提供されるというものです。 ただし、そうではありません。 グーグルによると、その検索は単純な3ステップの方法を使用して機能します:
- クロール: Googleがウェブサイトをランク付けするには、コンテンツをGoogleサーバーに直接ダウンロードする必要があります。 これは、Googlebotsと呼ばれるWebクローラーのシステムで実現されます。 Googlebotは、ウェブサイトを効果的にスキャンし、コンテンツをサーバーにダウンロードします。 クローラーは、デスクトップ検索とモバイル検索の両方をシミュレートできます。 これらのスキャンは、任意の間隔で定期的に実行されます。
- インデックス作成: Googleがすべてのコンテンツを取得すると、サイトのコンテンツを分析します。 ウェブサイトが安全で関連性があると見なされた場合、ウェブサイトのコンテンツはGoogleのインデックスデータベースに保存され、検索結果でユーザーに提供されるのを待ちます。
- 結果の表示:誰かがGoogleで検索すると、Googleのアルゴリズムがその検索を取得し、クエリに一致するすべての関連WebサイトのGoogleインデックスをふるいにかけます。 次に、アルゴリズムから判断された関連性と重要性の順にサイトを表示します。
Google SERP内に表示される結果は、実際には、インデックス作成時に表示されたWebサイトの単なるコピーです。 インデックスに登録された結果がライブサイトを反映していない場合があります。 結果をクリックして404エラーを受け取ったことがある場合は、これが理由です。
Google検索がどのように機能するかについてもっと知りたいですか? ソースから直接この5分間のビデオをチェックしてください。
Googleアルゴリズムはどのように機能しますか?
あなたがデジタルマーケターと一緒に時間を過ごしたことがあるなら、あなたは間違いなくグーグルのアルゴリズムについて聞いたことがあるでしょう。 アルゴリズムは、デジタルマーケティングの専門家やウェブサイトの所有者が理解する必要がある最も重要なことの1つです。
ユーザーが検索を入力すると、アルゴリズムは200を超えるさまざまな要因に基づいて、インデックス内の何兆ものWebサイトを瞬時にスキャンして分析します。 これらの要因のいくつかは次のとおりです。
- ドメイン要因(年齢、登録期間、ドメイン内のキーワードの一致など)
- ページレベルの要素(タイトルタグ、H1タグ、コンテンツの長さと有用性、LSIキーワード、内部リンク、ページの読み込み速度、スキーマデータなど)
- サイトレベルの要素(連絡先情報、ドメイン権限、サイトマップ、サイトアーキテクチャ、SSL証明書、モバイル対応、EATなど)
- 被リンク要因(被リンクの数、被リンクの品質)
- ユーザーインタラクション(クリックスルー率、バウンス率など)
- オフページ要因(引用、NAPの一貫性など)
Googleが200以上の異なる要因に対してすべてのウェブサイトを分析すると、ユーザーが探しているものと理想的に一致する結果が返されます。 これらはすべて、ほんの一瞬で起こります。

SERPの結果は、インデックス作成時に取得されたWebサイトのクローンにすぎないことはわかっていますが、これらの結果がユーザーにどのように正確に表示され、200のランキング要素がどのように使用されるかについては、水が少し濁っています。 グーグルはそのアルゴリズムがどのように機能するかの正確な詳細を隠すことで悪名高いので、成功のためにウェブサイトをセットアップしようとすると、猫とネズミのゲームのように感じることがよくあります。
Googleはどのようにウェブサイトをランク付けしますか?
グーグルはその秘密のアルゴリズム式の詳細を隠しているにもかかわらず、ランキング結果がどのように機能するかに影響を与えるトップランクの要因については確かに秘密ではありませんでした。
コンテンツの関連性
Googleで検索を入力すると、Google AIがクエリを受け取り、検索の背後にある適切な意味を判断します。 これは単純な概念のように聞こえますが、その背後にある科学はこの記事の範囲を超えています。 以下のサンプルのように、Googleにはいくつかの簡単な単語で検索を行い、その背後にある意味と意図を推定する機能があることだけを知っておく必要があります。
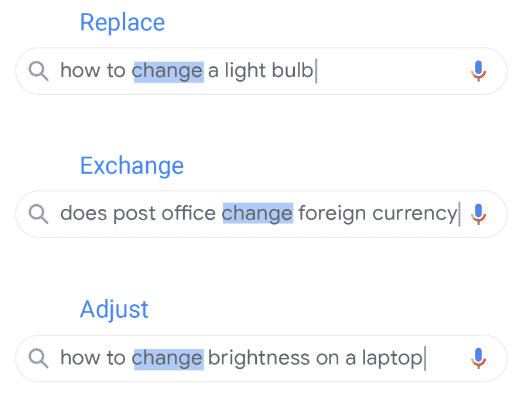
そこから、Googleは最初に検索に関連すると見なされた結果を表示します。
関連性は、クエリに一致するショートテールとロングテールの両方のキーワードとフレーズのページ上のコンテンツを分析することによって決定されます。 これはおそらく、コンテンツの関連性の最も基本的なシグナルであり、最も理解しやすいものです。 たとえば、「フェニックスのAC修理」を検索する場合、ページには「フェニックスのAC修理」またはその派生物が含まれているのが理想的です。
コンテンツの品質
キーワードに基づいてコンテンツの関連性のみを見ると、「フェニックスでのAC修理」をノンストップで提供する空白のウェブサイトは、有益なコンテンツを含む実際のページよりも上位にランク付けされます。 これを回避するために、Googleはコンテンツの全体的な品質を決定します。
コンテンツ品質のランク付けにはさまざまな要素がありますが、基本的な考え方は、専門知識、信頼性、信頼性(EAT)を示すWebサイトは、そうでないWebサイトよりもコンテンツ品質が高いと見なされるということです。
さらに、バックリンクを参照する強力なシステムを備えたWebサイトは、より高品質であると見なされます。 あなたのコンテンツを参照する信頼できるサイトが多いほど、あなたのサイトはより信頼できるように見えます。
ページの使いやすさ
すべてを考慮すると、見つけやすく、操作しやすいコンテンツの方がパフォーマンスが優れていることがよくあります。 たとえば、モバイルデバイス用に最適化されていないWebサイトは、携帯電話やタブレット用に効果的に最適化されているサイトよりもランク付けするのが困難になります。
ここで関係するもう1つの要素は、ページのアーキテクチャとデザインです。 コンテンツをヘッダー/画像のあるセクションに分割し、情報の全体的な階層を整理すると、ノンストップテキストを備えたページよりもはるかにアクセスしやすくなります。
ページ速度もここで考慮されます。 ページが特定の時間枠内にロードを拒否した場合、アクセシビリティが損なわれます。 一例として、ある調査によると、読み込みに3秒以上かかると、53%の人がモバイルページを離れます。
環境
Googleがページをランク付けする最後の方法は、全体的なコンテキストと関係があります。
検索履歴、設定、および場所に含まれる情報はすべて、表示される内容に影響します。
地元企業にとって、これを理解することは重要です。 配管工を探しているユーザーは、自分の地理的領域から結果が表示される可能性が高くなります。 地理的キーワードがコンテンツまたはメタデータ内に存在する場合、GoogleはWebサイトから地理的領域を判別できます。
ランキングを決定する要因はありません
グーグルがウェブサイトをランク付けする方法は比較的理解しやすいですが、それは非常に重要です。 前に述べたように、Googleがウェブサイトをランク付けするために使用する200以上の異なるシグナルがあるため、特効薬である1つまたは2つの主要なランク付け要因を決定することは不可能です。
さまざまなキーワードで常に上位3位にランクされているウェブサイトは、コンテンツ、サイトテクニカル、オフページの最適化に絶えず取り組んでおり、これらの高いランキングを達成していることを覚えておくことが重要です。
このビジネスでは、それはトップへの競争ですが、多くの場合、すべての異なるランキング要素で雑草に迷うのは簡単です。
結局のところ、コンテンツの関連性とコンテンツの品質、ページのアクセシビリティ、およびコンテキストの理解に焦点を当てることで、ランキングの目標を一貫して達成できるはずです。