
Guida introduttiva all'API Page Speed di Google
Pubblicato: 2019-03-11La velocità della pagina è uno dei più grandi indicatori di quanto tempo qualcuno trascorrerà sul tuo sito. Il caricamento lento delle pagine può portare a frequenze di rimbalzo più elevate, tassi di conversione inferiori e, di conseguenza, entrate inferiori.
Per avere un'idea del fatto che i tempi di caricamento possano influenzare la fidelizzazione e la conversione del tuo pubblico, lo strumento Page Speed Insights di Google è un ottimo punto di partenza. L'API Page Speed di Google è il modo in cui puoi collegare questi dati e incorporare approfondimenti nel tuo stack di dati. Lo abbiamo utilizzato per creare il nostro tracker di analisi Page Speed per monitorare le metriche chiave dell'esperienza utente per i nostri clienti.
Cosa c'è di così eccezionale nell'API Page Speed Insights?
Con questo strumento, puoi inserire un URL e ricevere un riepilogo delle sue prestazioni. Questo è ottimo per campionare una manciata di URL, ma cosa succede se si dispone di un sito Web di grandi dimensioni e si desidera visualizzare una panoramica completa delle prestazioni su più sezioni e tipi di pagina?
È qui che entra in gioco l'API. L'API Page Speed Insights di Google ci offre l'opportunità di analizzare le prestazioni di molte pagine e registrare i risultati, senza dover richiedere esplicitamente gli URL uno alla volta e interpretare i risultati manualmente.
Con questo in mente, abbiamo messo insieme una semplice guida che ti consentirà di iniziare a utilizzare l'API per il tuo sito web. Dopo aver familiarizzato con il processo descritto di seguito, vedrai come può essere utilizzato per analizzare la velocità del tuo sito su larga scala, tenere traccia di come cambia nel tempo o persino impostare strumenti di monitoraggio.
Questa guida presuppone una certa familiarità con gli script. Qui usiamo Python per interfacciarci con l'API e analizzare i risultati.
Obiettivi
In questo post imparerai come:
- Crea una query dell'API di Google Page Speed Insights
- Effettua richieste API per una tabella di URL
- Estrarre le informazioni di base dalla risposta dell'API
- Esegui lo script di esempio fornito in Python
Prepararsi
Ci sono alcuni passaggi che dovrai seguire prima di interrogare l'API Page Speed Insights con Python.
- Configurazione dell'API: molte API di Google richiedono chiavi API, password e altre misure di autenticazione. Tuttavia, non è necessario nulla di tutto ciò per iniziare con l'API di Google Page Speeds!
- Installazione di Python 3: se non hai mai utilizzato python prima, ti consigliamo di iniziare con la distribuzione Anaconda (versione Python 3.x), che installa python insieme a librerie di analisi dei dati popolari come Pandas.
Fare le richieste
Fondamenti di una richiesta
L'API può essere interrogata su questo endpoint utilizzando le richieste GET:
GET https://www.googleapis.com/pagespeedonline/v5/runPagespeedAggiungiamo quindi parametri aggiuntivi per specificare l'URL di cui vogliamo trovare la velocità della pagina e il tipo di dispositivo da utilizzare, come mostrato di seguito:
https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={url}&strategy={device_type} Quando effettui richieste, devi sostituire {url} con l'URL della pagina con codifica URL del tuo sito web e {device_type} con con mobile o desktop, per specificare il tipo di dispositivo.
Pacchetti Python
Per effettuare richieste, inserirle e quindi scrivere i risultati nelle tabelle, utilizzeremo alcune librerie Python:
- urllib : per effettuare le richieste HTTP.
- json : per analizzare e leggere gli oggetti di risposta.
- panda : per salvare i risultati in formato CSV.
Costruire la query
Per effettuare una richiesta API utilizzando Python, possiamo utilizzare il metodo urllib.request.urlopen :
import urllib.request import urllib.parse url = 'http://www.example.com' escaped_url = urllib.parse.quote(url) device_type = 'mobile' # Construct request url contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(escaped_url, device_type) ).read().decode('UTF-8')Questa richiesta dovrebbe restituire una risposta JSON (sorprendentemente grande). Ne discuteremo in modo più dettagliato a breve.
Fare più query
Uno dei principali punti di forza di questa API è che ci consente di estrarre velocità di pagina per batch di URL. Diamo un'occhiata a come questo può essere fatto con Python.
Un'opzione è archiviare i parametri della richiesta ( url e device_type ) in un CSV, che possiamo caricare in un Pandas DataFrame su cui ripetere l'iterazione. Nota di seguito che ogni richiesta o coppia url univoca + device_type ha una propria riga.
Archivia i dati in CSV
URL, device_type 0, https://www.example.com, desktop 1, https://www.example.com, mobile 2, https://www.example.com/blog, desktop 3, https://www.example.com/blog, mobileCarica il CSV
import pandas as pd df = pd.read_csvimport pandas as pd df = pd.read_csv(file_url)
Una volta che abbiamo un set di dati con tutti gli URL da richiedere, possiamo scorrere attraverso di essi ed effettuare una richiesta API per ogni riga. Questo è mostrato di seguito:
import time # This is where the responses will be stored response_object = {} # Iterating through df for i in range(0, len(df)): # Error handling try: print('Requesting row #:', i) # Define the request parameters url = df.iloc[i]['URL'] device_type = df.iloc[i]['device_type'] # Making request contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(url, device_type) ).read().decode('UTF-8') # Converts to json format contents_json = json.loads(contents) # Insert returned json response into response_object response_object[device_type][url] = contents_json print('Sleeping for 20 seconds between responses.') time.sleep(20) except Exception as e: print('Error:', e) print('Returning empty response for url:', url) response_object[device_type][url] = {}Leggendo la risposta
Prima di applicare qualsiasi filtro o formattazione ai dati, possiamo prima archiviare le risposte complete per un uso futuro in questo modo:
import json from datetime import datetime f_name ='data/{}-response.json'.format(datetime.now().strftime("%Y-%m-%d_%H:%M:%S")) with open(f_name, 'w') as outfile: json.dump(response_object, outfile, indent=4)Come accennato in precedenza, ogni risposta restituisce un oggetto JSON. Hanno molte proprietà diverse relative all'URL specificato e sono troppo grandi per essere decifrati senza filtri e formattazioni.

Per fare ciò, utilizzeremo la libreria Pandas, che semplifica l'estrazione dei dati desiderati in formato tabella ed esportati in CSV.
Questa è la struttura generale della risposta. I dati sui tempi di caricamento sono stati ridotti al minimo a causa delle sue dimensioni.
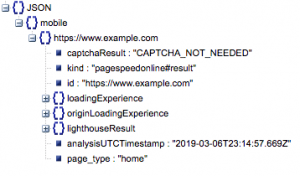
Struttura generale della risposta
Tra le altre informazioni, ci sono due principali fonti di dati sulla velocità della pagina inclusi nella risposta: i dati del laboratorio, archiviati in "lighthouseResult" e i dati del campo, archiviati in "loadingExperience". In questo post, ci concentreremo solo sui dati Field, che sono crowdsourcing in base agli utenti del mondo reale sul browser Chrome.
In particolare, estrarremo le seguenti metriche:
- URL richiesto e URL finale
- Abbiamo bisogno sia dell'URL richiesto che dell'URL risolto finale che è stato controllato per assicurarci che siano gli stessi. Questo ci aiuterà a identificare che il risultato proveniva dall'URL previsto anziché da un reindirizzamento.
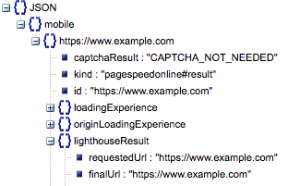
Possiamo vedere che entrambi gli URL sono gli stessi in "lighthouseResult" sopra.
- Primo dipinto ricco di contenuti (ms)
- Questo è il tempo che intercorre tra la prima navigazione dell'utente nella pagina e il momento in cui il browser esegue il rendering per la prima volta di un contenuto, informando l'utente che la pagina è in fase di caricamento.
- Questa metrica è misurata in millisecondi.
- First Contentful Paint (proporzioni di lento, medio, veloce)
- Questo mostra la percentuale di pagine che hanno tempi di caricamento lenti, medi e veloci di First Contentful Paint.
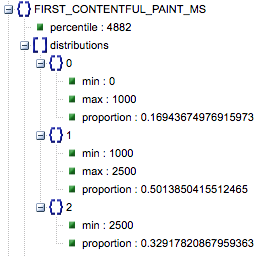
Tempo di caricamento del primo Contentful Paint in millisecondi, etichettato come "percentile" e proporzione di lento, medio e veloce.
Tutti questi risultati possono essere estratti per uno o entrambi i dati mobili e desktop.
Se chiamiamo il nostro dataframe Pandas df_field_responses, ecco come estrarremmo queste proprietà:
import pandas as pd # Specify the device_type (mobile or desktop) device_type = 'mobile' # Create dataframe to store responses df_field_responses = pd.DataFrame( columns=['requested_url', 'final_url', 'FCM_ms', 'FCP_category', 'FCP_fast', 'FCP_avg', 'FCP_slow' ] ) for (url, i) in zip( response_object[device_type].keys(), range(0, len(df_field_responses)) ): try: print('Trying to insert response for url:', url) # We reuse this below when selecting data from the response fcp_loading = response_object[device_type][url] ['loadingExperience']['metrics']['FIRST_CONTENTFUL_PAINT_MS'] # URLs df_field_responses.loc[i, 'requested_url'] = response_object[device_type][url]['lighthouseResult']['requestedUrl'] df_field_responses.loc[i, 'final_url'] = response_object[device_type][url]['lighthouseResult']['finalUrl'] # Loading experience: First Contentful Paint (ms) df_field_responses.loc[i, 'FCP_ms'] = fcp_loading['percentile'] df_field_responses.loc[i, 'FCP_category'] = fcp_loading['category'] # Proportions: First Contentful Paint df_field_responses.loc[i, 'FCP_fast'] = fcp_loading['distributions'][0]['proportion'] df_field_responses.loc[i, 'FCP_avg'] = fcp_loading['distributions'][1]['proportion'] df_field_responses.loc[i, 'FCP_slow'] = fcp_loading['distributions'][2]['proportion'] print('Inserted for row {}: {}'.format(i, df_field_responses.loc[i])) except Exception as e: print('Error:', e) print('Filling row with Error for row: {}; url: {}'.format(i, url)) # Fill in 'Error' for row if a field couldn't be found df_field_responses.loc[i] = ['Error' for i in range(0, len(df_field_responses.columns))]Quindi per memorizzare il dataframe, df_field_responses, in un CSV:
df_field_responses.to_csv('page_speeds_filtered_responses.csv', index=False)Esecuzione degli script su GitHub
Il repository su GitHub contiene istruzioni su come eseguire i file, ma ecco una rapida ripartizione.
- Prima di eseguire gli script di esempio su GitHub, dovrai clonare il repository utilizzando
-
git clone https://github.com/Ayima/page-speed-blog-post.git
-
- Quindi crea un file CSV con gli URL da interrogare.
- Compila il file di configurazione con il nome del file URL.
- Comando per eseguire gli script:
python main.py --config-file config.jsonQualcosa da tenere a mente:
L'API ha un limite al numero di richieste che puoi effettuare al giorno e al secondo.
Esistono diversi modi per prepararsi a questo, tra cui:
- Gestione degli errori: ripetere le richieste che restituiscono un errore
- Throttling: nel tuo script per limitare il numero di richieste inviate al secondo e richiedere nuovamente se un URL non riesce.
- Ottieni una chiave API se necessario (di solito se stai facendo più di una query al secondo).
Si spera che dopo aver letto questa guida tu sia in grado di iniziare a utilizzare alcune query di base dell'API di Google Page Speed Insights. Sentiti libero di contattarci su Twitter @ayima per qualsiasi domanda o se riscontri problemi!
Come utilizziamo l'API Page Speeds di Ayima
Qui ad Ayima raccogliamo e immagazziniamo continuamente le velocità delle pagine per i clienti. Questo ci aiuta a tenere d'occhio lo stato di salute dei loro siti Web e a identificare tendenze negative o positive. Monitorando le velocità per una varietà di pagine, siamo in grado di visualizzare le prestazioni per sezione del sito o tipo di pagina (ad es. pagine di prodotto e pagine di categoria per siti Web di e-commerce).
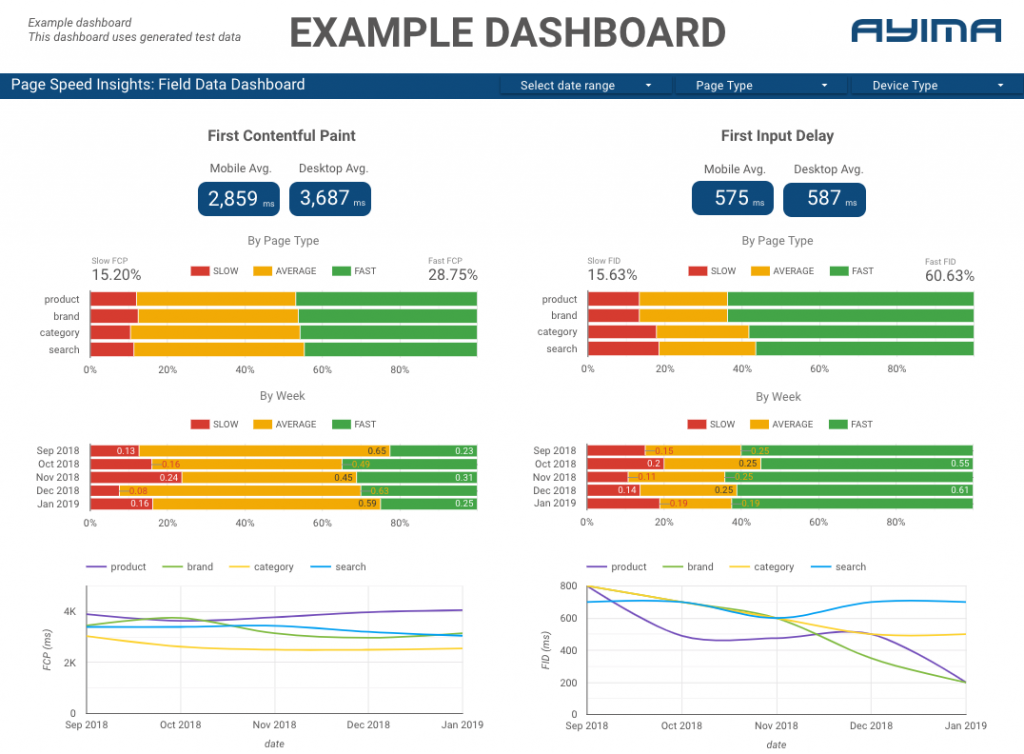
Tracciamo anche altre metriche interessanti fornite dall'API, inclusi i dati di Google Lab, e presentiamo tutto in una dashboard interattiva. Per ulteriori informazioni su questo non esitate a contattarci, ci piacerebbe chattare con voi!
Codice sorgente: puoi trovare il progetto GitHub con uno script di esempio da eseguire qui.