
Pierwsze kroki z interfejsem Google Page Speed API
Opublikowany: 2019-03-11Szybkość strony to jeden z najważniejszych wskaźników tego, jak długo ktoś spędzi w Twojej witrynie. Wolne ładowanie stron może prowadzić do wyższych współczynników odrzuceń, niższych współczynników konwersji, a tym samym niższych przychodów.
Aby dowiedzieć się, czy czasy wczytywania mogą mieć wpływ na utrzymanie odbiorców i konwersję, warto zacząć od narzędzia Google Page Speed Insights. Interfejs Google Page Speed API to sposób, w jaki możesz podłączyć się do tych danych i uwzględnić statystyki w swoim stosie danych. Wykorzystaliśmy go do zbudowania naszego własnego narzędzia analitycznego Page Speed do monitorowania kluczowych wskaźników doświadczenia użytkownika dla naszych klientów.
Co jest takiego wspaniałego w interfejsie Page Speed Insights API?
Za pomocą tego narzędzia możesz podłączyć adres URL i otrzymać podsumowanie jego działania. Świetnie nadaje się do próbkowania kilku adresów URL, ale co zrobić, jeśli masz dużą witrynę i chcesz zobaczyć kompleksowy przegląd skuteczności w wielu sekcjach i typach stron?
W tym miejscu wkracza interfejs API. Interfejs Google Page Speed Insights API daje nam możliwość analizowania wydajności wielu stron i rejestrowania wyników bez konieczności wyraźnego żądania adresów URL pojedynczo i ręcznej interpretacji wyników.
Mając to na uwadze, przygotowaliśmy prosty przewodnik, który pomoże Ci rozpocząć korzystanie z interfejsu API we własnej witrynie internetowej. Po zapoznaniu się z opisanym poniżej procesem zobaczysz, jak można go wykorzystać do analizy szybkości witryny na dużą skalę, śledzenia jej zmian w czasie, a nawet konfigurowania narzędzi do monitorowania.
Ten przewodnik zakłada pewną znajomość skryptów. Tutaj używamy Pythona do łączenia się z API i analizowania wyników.
Cele
W tym poście dowiesz się, jak:
- Utwórz zapytanie Google Page Speed Insights API
- Wysyłaj żądania API dla tabeli adresów URL
- Wydobądź podstawowe informacje z odpowiedzi API
- Uruchom podany przykładowy skrypt w Pythonie
Przygotowanie
Przed wysłaniem zapytania do interfejsu Page Speed Insights API za pomocą Pythona musisz wykonać kilka czynności.
- Konfiguracja interfejsu API: wiele interfejsów API Google wymaga kluczy API, haseł i innych środków uwierzytelniania. Jednak nie jest to wymagane, aby rozpocząć korzystanie z interfejsu Google Page Speeds API!
- Instalacja Pythona 3: Jeśli nigdy wcześniej nie korzystałeś z Pythona, zalecamy rozpoczęcie pracy z dystrybucją Anaconda (wersja Python 3.x), która instaluje Pythona wraz z popularnymi bibliotekami do analizy danych, takimi jak Pandas.
Składanie próśb
Podstawy wniosku
Zapytanie do interfejsu API można uzyskać w tym punkcie końcowym za pomocą żądań GET:
GET https://www.googleapis.com/pagespeedonline/v5/runPagespeedNastępnie dodajemy dodatkowe parametry, aby określić adres URL, dla którego chcemy znaleźć szybkość strony i typ używanego urządzenia, jak pokazano poniżej:
https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={url}&strategy={device_type} Wysyłając żądania, zamień {url} na zakodowany URL strony z Twojej witryny, a {device_type} na komórkę lub komputer, aby określić typ urządzenia.
Pakiety Pythona
Aby wysyłać żądania, przetwarzać je, a następnie zapisywać wyniki w tabelach, użyjemy kilku bibliotek Pythona:
- urllib : Aby wykonać żądania HTTP.
- json : Przetwarzanie i odczytywanie obiektów odpowiedzi.
- pandy : Aby zapisać wyniki w formacie CSV.
Konstruowanie zapytania
Aby wykonać żądanie API za pomocą Pythona, możemy użyć metody urllib.request.urlopen :
import urllib.request import urllib.parse url = 'http://www.example.com' escaped_url = urllib.parse.quote(url) device_type = 'mobile' # Construct request url contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(escaped_url, device_type) ).read().decode('UTF-8')To żądanie powinno zwrócić (zaskakująco dużą) odpowiedź JSON. Omówimy to bardziej szczegółowo wkrótce.
Robienie wielu zapytań
Główną zaletą tego interfejsu API jest to, że umożliwia nam zwiększenie szybkości stron dla partii adresów URL. Przyjrzyjmy się, jak można to zrobić w Pythonie.
Jedną z opcji jest przechowywanie parametrów żądania ( url i device_type ) w pliku CSV, który możemy załadować do Pandas DataFrame w celu iteracji. Zwróć uwagę poniżej, że każde żądanie lub unikalna para url + device_type ma swój własny wiersz.
Przechowuj dane w CSV
URL, device_type 0, https://www.example.com, desktop 1, https://www.example.com, mobile 2, https://www.example.com/blog, desktop 3, https://www.example.com/blog, mobileZaładuj plik CSV
import pandas as pd df = pd.read_csvimport pandas as pd df = pd.read_csv(plik_url)
Gdy mamy już zbiór danych ze wszystkimi adresami URL, których należy zażądać, możemy je przejrzeć i wykonać żądanie API dla każdego wiersza. Jest to pokazane poniżej:
import time # This is where the responses will be stored response_object = {} # Iterating through df for i in range(0, len(df)): # Error handling try: print('Requesting row #:', i) # Define the request parameters url = df.iloc[i]['URL'] device_type = df.iloc[i]['device_type'] # Making request contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(url, device_type) ).read().decode('UTF-8') # Converts to json format contents_json = json.loads(contents) # Insert returned json response into response_object response_object[device_type][url] = contents_json print('Sleeping for 20 seconds between responses.') time.sleep(20) except Exception as e: print('Error:', e) print('Returning empty response for url:', url) response_object[device_type][url] = {}Czytanie odpowiedzi
Przed zastosowaniem jakichkolwiek filtrów lub formatowania danych, możemy najpierw przechowywać pełne odpowiedzi do wykorzystania w przyszłości w następujący sposób:
import json from datetime import datetime f_name ='data/{}-response.json'.format(datetime.now().strftime("%Y-%m-%d_%H:%M:%S")) with open(f_name, 'w') as outfile: json.dump(response_object, outfile, indent=4)Jak wspomniano powyżej, każda odpowiedź zwraca obiekt JSON. Mają wiele różnych właściwości związanych z danym adresem URL i są zbyt duże, aby można je było rozszyfrować bez filtrowania i formatowania.

Aby to zrobić, użyjemy biblioteki Pandas, która ułatwia wyodrębnianie żądanych danych w formacie tabeli i eksportowanie do CSV.
To jest ogólna struktura odpowiedzi. Dane dotyczące czasów ładowania zostały zminimalizowane ze względu na jego rozmiar.
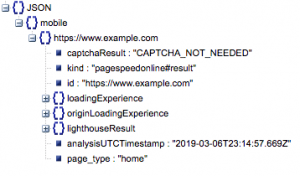
Ogólna struktura odpowiedzi
Wśród innych informacji w odpowiedzi znajdują się dwa główne źródła danych o szybkości strony: dane laboratoryjne, przechowywane w „lighthouseResult” i dane terenowe, przechowywane w „loadingExperience”. W tym poście skupimy się tylko na danych Field, które są pozyskiwane z tłumu na podstawie rzeczywistych użytkowników przeglądarki Chrome.
W szczególności wydobędziemy następujące metryki:
- Żądany adres URL i końcowy adres URL
- Potrzebujemy zarówno żądanego, jak i końcowego rozwiązania URL, które zostały poddane kontroli, aby upewnić się, że są takie same. Pomoże nam to stwierdzić, że wynik pochodzi z zamierzonego adresu URL, a nie z przekierowania.
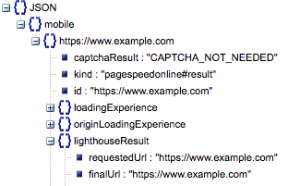
Widzimy, że oba adresy URL są takie same w „lighthouseResult” powyżej.
- Pierwsze wyrenderowanie treści (ms)
- Jest to czas między pierwszą nawigacją użytkownika na stronę a momentem, w którym przeglądarka po raz pierwszy renderuje fragment treści, informując użytkownika, że strona się ładuje.
- Ta metryka jest mierzona w milisekundach.
- First Contentful Paint (proporcje wolne, średnie, szybkie)
- Pokazuje procent stron, które mają wolne, średnie i szybkie czasy ładowania pierwszego wyrenderowania treści.
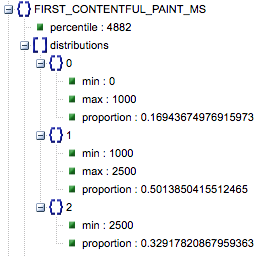
Czas wczytywania pierwszego wyrenderowania treści w milisekundach, oznaczony jako „percentyl” i proporcja wolnego, średniego i szybkiego.
Wszystkie te wyniki można wyodrębnić dla jednego lub obu danych mobilnych i stacjonarnych.
Jeśli nazwiemy naszą ramkę danych Pandy df_field_responses, oto jak wyodrębnimy te właściwości:
import pandas as pd # Specify the device_type (mobile or desktop) device_type = 'mobile' # Create dataframe to store responses df_field_responses = pd.DataFrame( columns=['requested_url', 'final_url', 'FCM_ms', 'FCP_category', 'FCP_fast', 'FCP_avg', 'FCP_slow' ] ) for (url, i) in zip( response_object[device_type].keys(), range(0, len(df_field_responses)) ): try: print('Trying to insert response for url:', url) # We reuse this below when selecting data from the response fcp_loading = response_object[device_type][url] ['loadingExperience']['metrics']['FIRST_CONTENTFUL_PAINT_MS'] # URLs df_field_responses.loc[i, 'requested_url'] = response_object[device_type][url]['lighthouseResult']['requestedUrl'] df_field_responses.loc[i, 'final_url'] = response_object[device_type][url]['lighthouseResult']['finalUrl'] # Loading experience: First Contentful Paint (ms) df_field_responses.loc[i, 'FCP_ms'] = fcp_loading['percentile'] df_field_responses.loc[i, 'FCP_category'] = fcp_loading['category'] # Proportions: First Contentful Paint df_field_responses.loc[i, 'FCP_fast'] = fcp_loading['distributions'][0]['proportion'] df_field_responses.loc[i, 'FCP_avg'] = fcp_loading['distributions'][1]['proportion'] df_field_responses.loc[i, 'FCP_slow'] = fcp_loading['distributions'][2]['proportion'] print('Inserted for row {}: {}'.format(i, df_field_responses.loc[i])) except Exception as e: print('Error:', e) print('Filling row with Error for row: {}; url: {}'.format(i, url)) # Fill in 'Error' for row if a field couldn't be found df_field_responses.loc[i] = ['Error' for i in range(0, len(df_field_responses.columns))]Następnie, aby zapisać ramkę danych, df_field_responses, w pliku CSV:
df_field_responses.to_csv('page_speeds_filtered_responses.csv', index=False)Uruchamianie skryptów na GitHub
Repozytorium na GitHub zawiera instrukcje dotyczące uruchamiania plików, ale tutaj jest szybki podział.
- Przed uruchomieniem przykładowych skryptów na GitHubie będziesz musiał sklonować repozytorium za pomocą
-
git clone https://github.com/Ayima/page-speed-blog-post.git
-
- Następnie utwórz plik CSV z adresami URL do zapytania.
- Wypełnij plik konfiguracyjny nazwą pliku URL.
- Polecenie do uruchomienia skryptów:
python main.py --config-file config.jsonCoś, o czym należy pamiętać:
Interfejs API ma limit liczby żądań, które możesz wykonać dziennie i na sekundę.
Istnieje kilka sposobów na przygotowanie się do tego, w tym:
- Obsługa błędów: powtarzanie żądań, które zwracają błąd
- Ograniczanie: w twoim skrypcie, aby ograniczyć liczbę żądań wysyłanych na sekundę i ponowne żądanie, jeśli URL się nie powiedzie.
- W razie potrzeby uzyskaj klucz API (zwykle jeśli wykonujesz więcej niż jedno zapytanie na sekundę).
Mamy nadzieję, że po przeczytaniu tego przewodnika będziesz w stanie rozpocząć korzystanie z podstawowych zapytań do interfejsu Google Page Speed Insights API. Jeśli masz jakiekolwiek pytania lub napotkasz problemy, skontaktuj się z nami na Twitterze @ayima!
Jak korzystamy z API Page Speeds w Ayima
W Ayima stale zbieramy i magazynujemy prędkości stron dla klientów. Pomaga nam to monitorować stan ich witryn i identyfikować negatywne lub pozytywne trendy. Monitorując prędkości dla różnych stron, jesteśmy w stanie wizualizować wydajność według sekcji witryny lub typu strony (np. strony produktów VS strony kategorii dla witryn e-commerce).
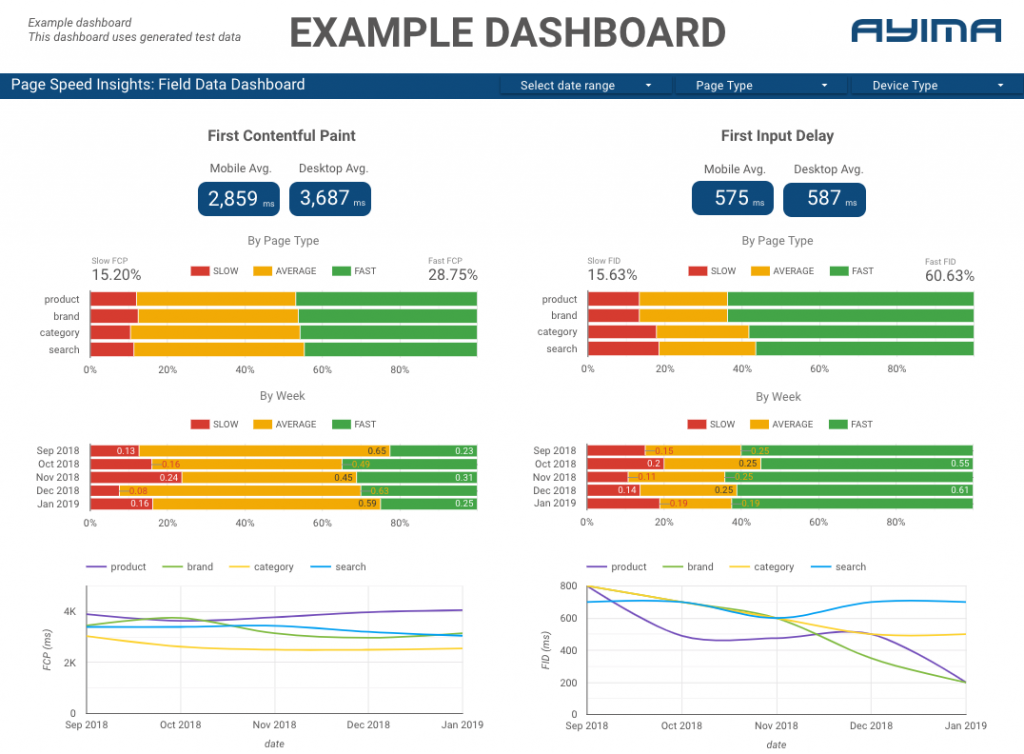
Śledzimy również inne interesujące metryki dostarczane przez API, w tym dane z laboratorium Google, i przedstawiamy wszystko na interaktywnym pulpicie nawigacyjnym. Aby uzyskać więcej informacji na ten temat, skontaktuj się z nami, chętnie z Tobą porozmawiamy!
Kod źródłowy: możesz znaleźć projekt GitHub z przykładowym skryptem do uruchomienia tutaj.