
Erste Schritte mit der Page Speed API von Google
Veröffentlicht: 2019-03-11Die Seitengeschwindigkeit ist einer der größten Indikatoren dafür, wie lange jemand auf Ihrer Website verbringt. Langsam ladende Seiten können zu höheren Absprungraten, niedrigeren Konversionsraten und damit zu niedrigeren Einnahmen führen.
Um einen Einblick zu erhalten, ob sich Ladezeiten auf Ihre Zuschauerbindung und -konvertierung auswirken können, ist das Page Speed Insights-Tool von Google ein guter Ausgangspunkt. Mit der Page Speed API von Google können Sie diese Daten einbinden und Erkenntnisse in Ihren Datenstapel integrieren. Wir haben es verwendet, um unseren eigenen Page Speed Analytics Tracker zu erstellen, um wichtige Metriken zur Benutzererfahrung für unsere Kunden zu überwachen.
Was ist so toll an der Page Speed Insights API?
Mit diesem Tool können Sie eine URL einfügen und erhalten eine Zusammenfassung ihrer Leistung. Dies ist großartig, um eine Handvoll URLs zu testen, aber was ist, wenn Sie eine große Website haben und einen umfassenden Überblick über die Leistung über mehrere Abschnitte und Seitentypen hinweg sehen möchten?
Hier kommt die API ins Spiel. Die Page Speed Insights-API von Google gibt uns die Möglichkeit, die Leistung für viele Seiten zu analysieren und die Ergebnisse zu protokollieren, ohne explizit URLs einzeln anfordern und die Ergebnisse manuell interpretieren zu müssen.
Vor diesem Hintergrund haben wir eine einfache Anleitung zusammengestellt, die Ihnen den Einstieg in die Verwendung der API für Ihre eigene Website erleichtert. Sobald Sie sich mit dem unten beschriebenen Prozess vertraut gemacht haben, werden Sie sehen, wie er verwendet werden kann, um die Geschwindigkeit Ihrer Website in großem Maßstab zu analysieren, zu verfolgen, wie sie sich im Laufe der Zeit ändert, oder sogar Überwachungstools einzurichten.
Dieses Handbuch setzt eine gewisse Vertrautheit mit der Skripterstellung voraus. Hier verwenden wir Python, um mit der API zu kommunizieren und die Ergebnisse zu parsen.
Ziele
In diesem Beitrag erfahren Sie, wie Sie:
- Erstellen Sie eine Google Page Speed Insights-API-Abfrage
- Stellen Sie API-Anforderungen für eine URL-Tabelle
- Extrahieren Sie grundlegende Informationen aus der API-Antwort
- Führen Sie das angegebene Beispielskript in Python aus
Einrichten
Es gibt einige Schritte, die Sie befolgen müssen, bevor Sie die Page Speed Insights-API mit Python abfragen.
- API-Setup: Viele Google-APIs erfordern API-Schlüssel, Passwörter und andere Authentifizierungsmaßnahmen. Sie benötigen jedoch nichts davon, um mit der Google Page Speeds API zu beginnen!
- Installation von Python 3: Wenn Sie Python noch nie verwendet haben, empfehlen wir, mit der Anaconda-Distribution (Python 3.x-Version) zu beginnen, die Python zusammen mit beliebten Datenanalysebibliotheken wie Pandas installiert.
Die Anträge stellen
Grundlagen einer Anfrage
Die API kann an diesem Endpunkt mit GET-Anfragen abgefragt werden:
GET https://www.googleapis.com/pagespeedonline/v5/runPagespeedWir fügen dann zusätzliche Parameter hinzu, um die URL anzugeben, von der wir die Seitengeschwindigkeit und den zu verwendenden Gerätetyp finden möchten, wie unten gezeigt:
https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={url}&strategy={device_type} Wenn Sie Anfragen stellen, sollten Sie {url} durch die URL-codierte Seiten-URL Ihrer Website und {device_type} durch Mobile oder Desktop ersetzen, um den Gerätetyp anzugeben.
Python-Pakete
Um Anfragen zu stellen, sie aufzunehmen und die Ergebnisse dann in Tabellen zu schreiben, verwenden wir einige Python-Bibliotheken:
- urllib : Um die HTTP-Anforderungen zu stellen.
- json : Zum Analysieren und Lesen der Antwortobjekte.
- pandas : Um die Ergebnisse im CSV-Format zu speichern.
Erstellen der Abfrage
Um eine API-Anfrage mit Python zu stellen, können wir die Methode urllib.request.urlopen verwenden:
import urllib.request import urllib.parse url = 'http://www.example.com' escaped_url = urllib.parse.quote(url) device_type = 'mobile' # Construct request url contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(escaped_url, device_type) ).read().decode('UTF-8')Diese Anfrage sollte eine (überraschend große) JSON-Antwort zurückgeben. Wir werden dies in Kürze ausführlicher besprechen.
Mehrere Anfragen stellen
Ein wichtiges Verkaufsargument dieser API ist, dass sie es uns ermöglicht, Seitengeschwindigkeiten für Chargen von URLs zu ziehen. Lassen Sie uns einen Blick darauf werfen, wie dies mit Python erreicht werden kann.
Eine Option besteht darin, die Anforderungsparameter ( url und device_type ) in einer CSV-Datei zu speichern, die wir in einen Pandas DataFrame laden können, um sie zu durchlaufen. Beachten Sie unten, dass jede Anfrage oder jedes eindeutige Paar aus url und device_type eine eigene Zeile hat.
Speichern Sie Daten in CSV
URL, device_type 0, https://www.example.com, desktop 1, https://www.example.com, mobile 2, https://www.example.com/blog, desktop 3, https://www.example.com/blog, mobileLaden Sie die CSV-Datei
import pandas as pd df = pd.read_csvimport pandas as pd df = pd.read_csv(url_file)
Sobald wir einen Datensatz mit allen anzufordernden URLs haben, können wir sie durchlaufen und für jede Zeile eine API-Anfrage stellen. Dies ist unten dargestellt:
import time # This is where the responses will be stored response_object = {} # Iterating through df for i in range(0, len(df)): # Error handling try: print('Requesting row #:', i) # Define the request parameters url = df.iloc[i]['URL'] device_type = df.iloc[i]['device_type'] # Making request contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(url, device_type) ).read().decode('UTF-8') # Converts to json format contents_json = json.loads(contents) # Insert returned json response into response_object response_object[device_type][url] = contents_json print('Sleeping for 20 seconds between responses.') time.sleep(20) except Exception as e: print('Error:', e) print('Returning empty response for url:', url) response_object[device_type][url] = {}Lesen der Antwort
Bevor wir Filter oder Formatierungen auf die Daten anwenden, können wir zunächst die vollständigen Antworten für die zukünftige Verwendung wie folgt speichern:
import json from datetime import datetime f_name ='data/{}-response.json'.format(datetime.now().strftime("%Y-%m-%d_%H:%M:%S")) with open(f_name, 'w') as outfile: json.dump(response_object, outfile, indent=4)Wie oben erwähnt, gibt jede Antwort ein JSON-Objekt zurück. Sie haben viele verschiedene Eigenschaften in Bezug auf die angegebene URL und sind viel zu groß, um sie ohne Filterung und Formatierung zu entschlüsseln.

Dazu verwenden wir die Pandas-Bibliothek, die es einfach macht, die gewünschten Daten im Tabellenformat zu extrahieren und in CSV zu exportieren.
Dies ist die allgemeine Struktur der Antwort. Die Angaben zu Ladezeiten wurden aufgrund ihrer Größe minimiert.
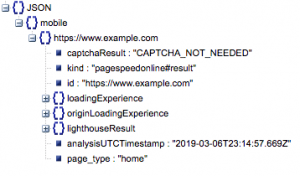
Allgemeine Antwortstruktur
Neben anderen Informationen enthält die Antwort zwei Hauptquellen für Seitengeschwindigkeitsdaten: Labordaten, die in „lighthouseResult“ gespeichert sind, und Felddaten, die in „loadingExperience“ gespeichert sind. In diesem Beitrag konzentrieren wir uns nur auf Felddaten, die auf der Grundlage von realen Benutzern im Chrome-Browser gesammelt werden.
Insbesondere werden wir die folgenden Metriken extrahieren:
- Angeforderte URL und finale URL
- Wir benötigen sowohl die angeforderte als auch die endgültig aufgelöste URL, die geprüft wurden, um sicherzustellen, dass sie identisch sind. Dies hilft uns zu erkennen, dass das Ergebnis von der beabsichtigten URL und nicht von einer Weiterleitung stammt.
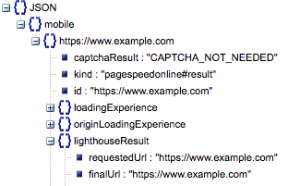
Wir können sehen, dass beide URLs in „lighthouseResult“ oben gleich sind.
- Erste zufriedene Farbe (ms)
- Dies ist die Zeit zwischen der ersten Navigation des Benutzers auf der Seite und dem Zeitpunkt, an dem der Browser zum ersten Mal einen Inhalt rendert und dem Benutzer mitteilt, dass die Seite geladen wird.
- Diese Metrik wird in Millisekunden gemessen.
- First Contentful Paint (Anteile von langsam, durchschnittlich, schnell)
- Dies zeigt den Prozentsatz der Seiten mit langsamen, durchschnittlichen und schnellen Ladezeiten von First Contentful Paint.
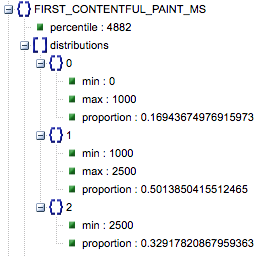
Ladezeit von First Contentful Paint in Millisekunden, als „Perzentil“ bezeichnet, und Anteil von langsam, durchschnittlich und schnell.
Alle diese Ergebnisse können entweder für die Mobil- und Desktop-Daten oder für beide extrahiert werden.
Wenn wir unseren Pandas-Datenrahmen df_field_responses nennen, würden wir diese Eigenschaften folgendermaßen extrahieren:
import pandas as pd # Specify the device_type (mobile or desktop) device_type = 'mobile' # Create dataframe to store responses df_field_responses = pd.DataFrame( columns=['requested_url', 'final_url', 'FCM_ms', 'FCP_category', 'FCP_fast', 'FCP_avg', 'FCP_slow' ] ) for (url, i) in zip( response_object[device_type].keys(), range(0, len(df_field_responses)) ): try: print('Trying to insert response for url:', url) # We reuse this below when selecting data from the response fcp_loading = response_object[device_type][url] ['loadingExperience']['metrics']['FIRST_CONTENTFUL_PAINT_MS'] # URLs df_field_responses.loc[i, 'requested_url'] = response_object[device_type][url]['lighthouseResult']['requestedUrl'] df_field_responses.loc[i, 'final_url'] = response_object[device_type][url]['lighthouseResult']['finalUrl'] # Loading experience: First Contentful Paint (ms) df_field_responses.loc[i, 'FCP_ms'] = fcp_loading['percentile'] df_field_responses.loc[i, 'FCP_category'] = fcp_loading['category'] # Proportions: First Contentful Paint df_field_responses.loc[i, 'FCP_fast'] = fcp_loading['distributions'][0]['proportion'] df_field_responses.loc[i, 'FCP_avg'] = fcp_loading['distributions'][1]['proportion'] df_field_responses.loc[i, 'FCP_slow'] = fcp_loading['distributions'][2]['proportion'] print('Inserted for row {}: {}'.format(i, df_field_responses.loc[i])) except Exception as e: print('Error:', e) print('Filling row with Error for row: {}; url: {}'.format(i, url)) # Fill in 'Error' for row if a field couldn't be found df_field_responses.loc[i] = ['Error' for i in range(0, len(df_field_responses.columns))]Speichern Sie dann den Datenrahmen df_field_responses in einer CSV-Datei:
df_field_responses.to_csv('page_speeds_filtered_responses.csv', index=False)Ausführen der Skripte auf GitHub
Das Repository auf GitHub enthält Anweisungen zum Ausführen der Dateien, aber hier ist eine kurze Aufschlüsselung.
- Bevor Sie die Beispielskripts auf GitHub ausführen, müssen Sie das Repository mit klonen
-
git clone https://github.com/Ayima/page-speed-blog-post.git
-
- Erstellen Sie dann eine CSV-Datei mit den abzufragenden URLs.
- Füllen Sie die Konfigurationsdatei mit dem URL-Dateinamen aus.
- Befehl zum Ausführen der Skripte:
python main.py --config-file config.jsonEtwas zu beachten:
Die API hat ein Limit, wie viele Anfragen Sie pro Tag und pro Sekunde stellen können.
Es gibt mehrere Möglichkeiten, sich darauf vorzubereiten, darunter:
- Fehlerbehandlung : Wiederholen Sie Anfragen, die einen Fehler zurückgeben
- Drosselung: in Ihrem Skript, um die Anzahl der pro Sekunde gesendeten Anfragen zu begrenzen, und erneute Anfrage, wenn eine URL fehlschlägt.
- Holen Sie sich bei Bedarf einen API-Schlüssel (normalerweise, wenn Sie mehr als eine Abfrage pro Sekunde durchführen).
Hoffentlich sind Sie nach dem Lesen dieses Leitfadens in der Lage, mit einigen grundlegenden Abfragen der Google Page Speed Insights-API loszulegen. Fühlen Sie sich frei, uns auf Twitter @ayima zu erreichen, wenn Sie Fragen haben oder auf Probleme stoßen!
Wie wir die Page Speeds API bei Ayima verwenden
Hier bei Ayima erfassen und speichern wir kontinuierlich Seitengeschwindigkeiten für Kunden. Dies hilft uns, den Zustand ihrer Websites im Auge zu behalten und negative oder positive Trends zu erkennen. Durch die Überwachung der Geschwindigkeiten für eine Vielzahl von Seiten sind wir in der Lage, die Leistung nach Websiteabschnitt oder Seitentyp zu visualisieren (z. B. Produktseiten vs. Kategorieseiten für E-Commerce-Websites).
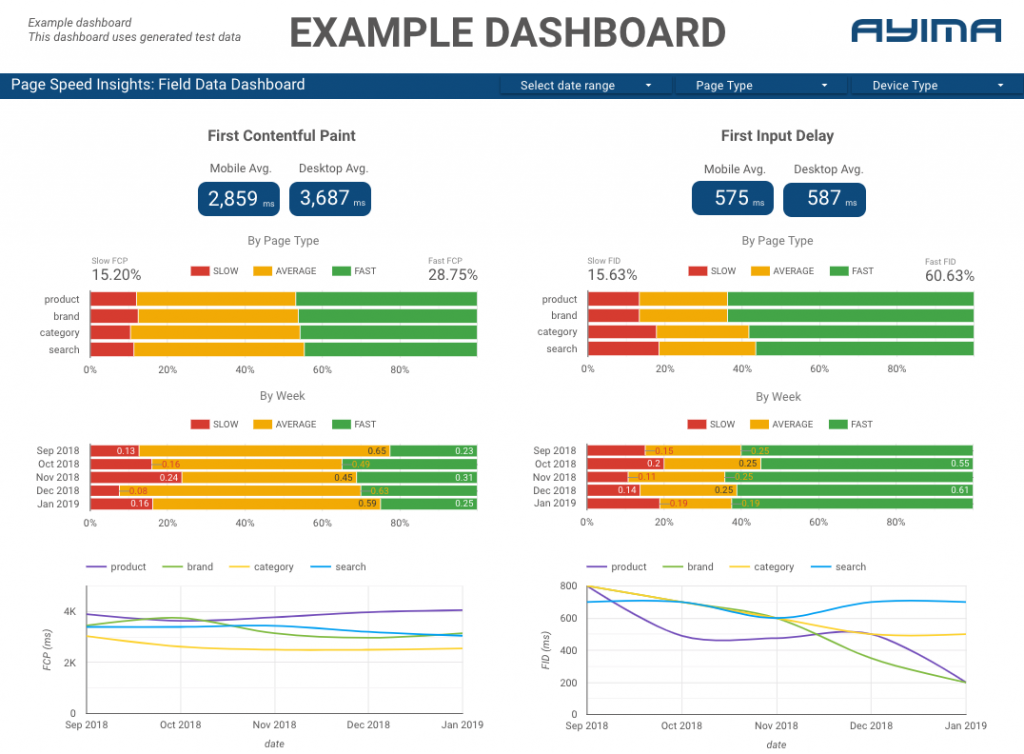
Wir verfolgen auch andere interessante Metriken, die von der API bereitgestellt werden, einschließlich Googles Lab-Daten, und präsentieren alles in einem interaktiven Dashboard. Für weitere Informationen kontaktieren Sie uns bitte, wir würden uns freuen, mit Ihnen zu chatten!
Quellcode: Das GitHub-Projekt mit einem auszuführenden Beispielskript finden Sie hier.