
Google의 Page Speed API 시작하기
게시 됨: 2019-03-11페이지 속도는 누군가가 귀하의 사이트에 머무는 시간을 나타내는 가장 큰 지표 중 하나입니다. 페이지 로딩 속도가 느리면 이탈률이 높아지고 전환율이 낮아져 수익이 감소할 수 있습니다.
로드 시간이 잠재고객 보유 및 전환에 영향을 미칠 수 있는지 여부에 대한 통찰력을 얻으려면 Google의 Page Speed Insights 도구를 시작하는 것이 좋습니다. Google의 Page Speed API는 이 데이터에 연결하고 데이터 스택 내에서 통찰력을 통합하는 방법입니다. 우리는 이를 사용하여 고객의 주요 사용자 경험 메트릭을 모니터링하는 자체 Page Speed 분석 추적기를 구축했습니다.
Page Speed Insights API의 장점은 무엇입니까?
이 도구를 사용하면 URL을 연결하고 성능 요약을 받을 수 있습니다. 이는 소수의 URL을 샘플링하는 데 유용하지만 웹사이트가 크고 여러 섹션 및 페이지 유형에 대한 종합적인 성능 개요를 보려면 어떻게 해야 합니까?
여기에서 API가 필요합니다. Google의 Page Speed Insights API는 URL을 한 번에 하나씩 명시적으로 요청하고 결과를 수동으로 해석할 필요 없이 여러 페이지의 성능을 분석하고 결과를 기록할 수 있는 기회를 제공합니다.
이를 염두에 두고 귀하의 웹사이트에 API 사용을 시작하는 데 도움이 되는 간단한 가이드를 마련했습니다. 아래에 설명된 프로세스에 익숙해지면 규모에 따라 사이트 속도를 분석하고 시간이 지남에 따라 어떻게 변하는지 추적하거나 모니터링 도구를 설정하는 데 이 프로세스를 사용할 수 있습니다.
이 가이드는 스크립팅에 어느 정도 익숙하다고 가정합니다. 여기에서 Python을 사용하여 API와 인터페이스하고 결과를 구문 분석합니다.
목표
이 게시물에서는 다음 방법을 배웁니다.
- Google Page Speed Insights API 쿼리 구성
- URL 테이블에 대한 API 요청 만들기
- API 응답에서 기본 정보 추출
- Python에서 주어진 예제 스크립트 실행
설정하기
Python으로 Page Speed Insights API를 쿼리하기 전에 따라야 할 몇 가지 단계가 있습니다.
- API 설정: 많은 Google API에는 API 키, 비밀번호 및 기타 인증 수단이 필요합니다. 그러나 Google Page Speeds API를 시작하기 위해 이 중 어느 것도 필요하지 않습니다!
- Python 3 설치: 이전에 Python을 사용한 적이 없다면 Pandas와 같은 인기 있는 데이터 분석 라이브러리와 함께 Python을 설치하는 Anaconda 배포판(Python 3.x 버전)으로 시작하는 것이 좋습니다.
요청하기
요청의 기본 사항
API는 GET 요청을 사용하여 이 끝점에서 쿼리할 수 있습니다.
GET https://www.googleapis.com/pagespeedonline/v5/runPagespeed그런 다음 아래와 같이 페이지 속도와 사용할 장치 유형을 찾으려는 URL을 지정하기 위해 추가 매개변수를 추가합니다.
https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={url}&strategy={device_type} 요청할 때 {url} 을 웹사이트의 URL로 인코딩된 페이지 URL로 바꾸고 {device_type} 을 모바일 또는 데스크톱으로 바꿔서 기기 유형을 지정해야 합니다.
파이썬 패키지
요청을 하고 수집한 다음 결과를 테이블에 쓰기 위해 몇 가지 파이썬 라이브러리를 사용할 것입니다.
- urllib : HTTP 요청을 합니다.
- json : 응답 객체를 파싱하고 읽는다.
- pandas : 결과를 CSV 형식으로 저장합니다.
쿼리 구성
Python을 사용하여 API 요청을 하려면 urllib.request.urlopen 메서드를 사용할 수 있습니다.
import urllib.request import urllib.parse url = 'http://www.example.com' escaped_url = urllib.parse.quote(url) device_type = 'mobile' # Construct request url contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(escaped_url, device_type) ).read().decode('UTF-8')이 요청은 (놀랍게도 큰) JSON 응답을 반환해야 합니다. 이에 대해서는 곧 더 자세히 논의할 것입니다.
여러 쿼리 만들기
이 API의 주요 판매 포인트는 일괄 URL에 대한 페이지 속도를 가져올 수 있다는 것입니다. 파이썬으로 이것을 어떻게 할 수 있는지 살펴봅시다.
한 가지 옵션은 요청 매개변수( url 및 device_type )를 CSV에 저장하는 것입니다. 이 CSV를 Pandas DataFrame에 로드하여 반복할 수 있습니다. 아래에서 각 요청 또는 고유한 url + device_type 쌍에는 자체 행이 있습니다.
CSV에 데이터 저장
URL, device_type 0, https://www.example.com, desktop 1, https://www.example.com, mobile 2, https://www.example.com/blog, desktop 3, https://www.example.com/blog, mobileCSV 로드
import pandas as pd df = pd.read_csvimport pandas as pd df = pd.read_csv(url_file)
요청할 모든 URL이 포함된 데이터 세트가 있으면 이를 반복하고 각 행에 대해 API 요청을 수행할 수 있습니다. 이것은 아래와 같습니다.
import time # This is where the responses will be stored response_object = {} # Iterating through df for i in range(0, len(df)): # Error handling try: print('Requesting row #:', i) # Define the request parameters url = df.iloc[i]['URL'] device_type = df.iloc[i]['device_type'] # Making request contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(url, device_type) ).read().decode('UTF-8') # Converts to json format contents_json = json.loads(contents) # Insert returned json response into response_object response_object[device_type][url] = contents_json print('Sleeping for 20 seconds between responses.') time.sleep(20) except Exception as e: print('Error:', e) print('Returning empty response for url:', url) response_object[device_type][url] = {}응답 읽기
데이터에 필터나 서식을 적용하기 전에 먼저 다음과 같이 나중에 사용할 수 있도록 전체 응답을 저장할 수 있습니다.
import json from datetime import datetime f_name ='data/{}-response.json'.format(datetime.now().strftime("%Y-%m-%d_%H:%M:%S")) with open(f_name, 'w') as outfile: json.dump(response_object, outfile, indent=4)위에서 언급했듯이 각 응답은 JSON 객체를 반환합니다. 그들은 주어진 URL과 관련된 많은 다른 속성을 가지고 있으며 필터링 및 형식 지정 없이 해독하기에는 너무 큽니다.
이를 위해 Pandas 라이브러리를 사용하여 원하는 데이터를 테이블 형식으로 쉽게 추출하고 CSV로 내보낼 수 있습니다.
이것이 응답의 일반적인 구조입니다. 로드 시간에 대한 데이터는 크기로 인해 최소화되었습니다.

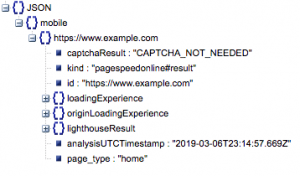
일반 응답 구조
다른 정보 중에서 응답에 포함된 페이지 속도 데이터의 두 가지 주요 소스는 'lighthouseResult'에 저장된 실험실 데이터와 'loadingExperience'에 저장된 필드 데이터입니다. 이 게시물에서는 Chrome 브라우저의 실제 사용자를 기반으로 하는 크라우드 소싱인 필드 데이터에만 초점을 맞출 것입니다.
특히 다음 메트릭을 추출할 것입니다.
- 요청된 URL 및 최종 도착 URL
- 동일한지 확인하기 위해 감사된 요청된 URL과 최종 확인된 URL이 모두 필요합니다. 이렇게 하면 리디렉션이 아닌 의도한 URL에서 결과가 나왔다는 것을 식별하는 데 도움이 됩니다.
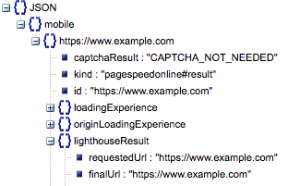
위의 'lighthouseResult'에서 두 URL이 동일한 것을 확인할 수 있습니다.
- 첫 번째 콘텐츠가 포함된 페인트 (ms)
- 이것은 사용자가 페이지를 처음 탐색한 후 브라우저가 처음으로 콘텐츠를 렌더링하여 사용자에게 페이지가 로드 중임을 알리는 시간입니다.
- 이 측정항목은 밀리초 단위로 측정됩니다.
- 첫 번째 콘텐츠가 포함된 페인트 (느림, 평균, 빠름 비율)
- 이것은 First Contentful Paint의 느린, 평균 및 빠른 로드 시간을 가진 페이지의 비율을 보여줍니다.
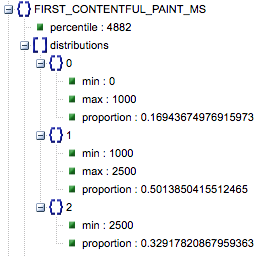
첫 번째 Contentful Paint 로드 시간(밀리초), 레이블이 '백분위수', 느린 비율, 평균 비율, 빠름 비율.
이러한 모든 결과는 모바일 및 데스크톱 데이터 중 하나 또는 둘 다에 대해 추출할 수 있습니다.
Pandas 데이터 프레임을 df_field_responses라고 하는 경우 이러한 속성을 추출하는 방법은 다음과 같습니다.
import pandas as pd # Specify the device_type (mobile or desktop) device_type = 'mobile' # Create dataframe to store responses df_field_responses = pd.DataFrame( columns=['requested_url', 'final_url', 'FCM_ms', 'FCP_category', 'FCP_fast', 'FCP_avg', 'FCP_slow' ] ) for (url, i) in zip( response_object[device_type].keys(), range(0, len(df_field_responses)) ): try: print('Trying to insert response for url:', url) # We reuse this below when selecting data from the response fcp_loading = response_object[device_type][url] ['loadingExperience']['metrics']['FIRST_CONTENTFUL_PAINT_MS'] # URLs df_field_responses.loc[i, 'requested_url'] = response_object[device_type][url]['lighthouseResult']['requestedUrl'] df_field_responses.loc[i, 'final_url'] = response_object[device_type][url]['lighthouseResult']['finalUrl'] # Loading experience: First Contentful Paint (ms) df_field_responses.loc[i, 'FCP_ms'] = fcp_loading['percentile'] df_field_responses.loc[i, 'FCP_category'] = fcp_loading['category'] # Proportions: First Contentful Paint df_field_responses.loc[i, 'FCP_fast'] = fcp_loading['distributions'][0]['proportion'] df_field_responses.loc[i, 'FCP_avg'] = fcp_loading['distributions'][1]['proportion'] df_field_responses.loc[i, 'FCP_slow'] = fcp_loading['distributions'][2]['proportion'] print('Inserted for row {}: {}'.format(i, df_field_responses.loc[i])) except Exception as e: print('Error:', e) print('Filling row with Error for row: {}; url: {}'.format(i, url)) # Fill in 'Error' for row if a field couldn't be found df_field_responses.loc[i] = ['Error' for i in range(0, len(df_field_responses.columns))]그런 다음 데이터 프레임 df_field_responses를 CSV에 저장하려면 다음을 수행합니다.
df_field_responses.to_csv('page_speeds_filtered_responses.csv', index=False)GitHub에서 스크립트 실행
GitHub의 리포지토리에는 파일을 실행하는 방법에 대한 지침이 포함되어 있지만 여기에 간단한 분석이 있습니다.
- GitHub에서 예제 스크립트를 실행하기 전에 다음을 사용하여 리포지토리를 복제해야 합니다.
-
git clone https://github.com/Ayima/page-speed-blog-post.git
-
- 그런 다음 쿼리할 URL이 포함된 CSV 파일을 만듭니다.
- 구성 파일에 URL 파일 이름을 입력합니다.
- 스크립트를 실행하는 명령:
python main.py --config-file config.json명심해야 할 사항:
API에는 하루 및 초당 요청할 수 있는 요청 수에 대한 제한이 있습니다.
다음을 포함하여 이를 준비하는 몇 가지 방법이 있습니다.
- 오류 처리: 오류 를 반환하는 반복 요청
- 조절: 스크립트에서 초당 전송되는 요청 수를 제한하고 URL이 실패하면 다시 요청합니다.
- 필요한 경우 API 키를 가져옵니다(일반적으로 초당 두 개 이상의 쿼리를 만드는 경우).
이 가이드를 읽은 후 Google Page Speed Insights API의 몇 가지 기본 쿼리를 시작하고 실행할 수 있기를 바랍니다. 질문이 있거나 문제가 발생하면 트위터 @ayima로 언제든지 연락해 주세요!
Ayima에서 Page Speeds API를 사용하는 방법
여기 Ayima에서 우리는 클라이언트를 위해 지속적으로 페이지 속도를 수집하고 보관합니다. 이것은 우리가 그들의 웹사이트의 상태를 주시하고 부정적이거나 긍정적인 경향을 식별하는 데 도움이 됩니다. 다양한 페이지의 속도를 모니터링하여 사이트 섹션 또는 페이지 유형(예: 전자 상거래 웹사이트의 경우 제품 페이지 VS 카테고리 페이지)별로 성능을 시각화할 수 있습니다.
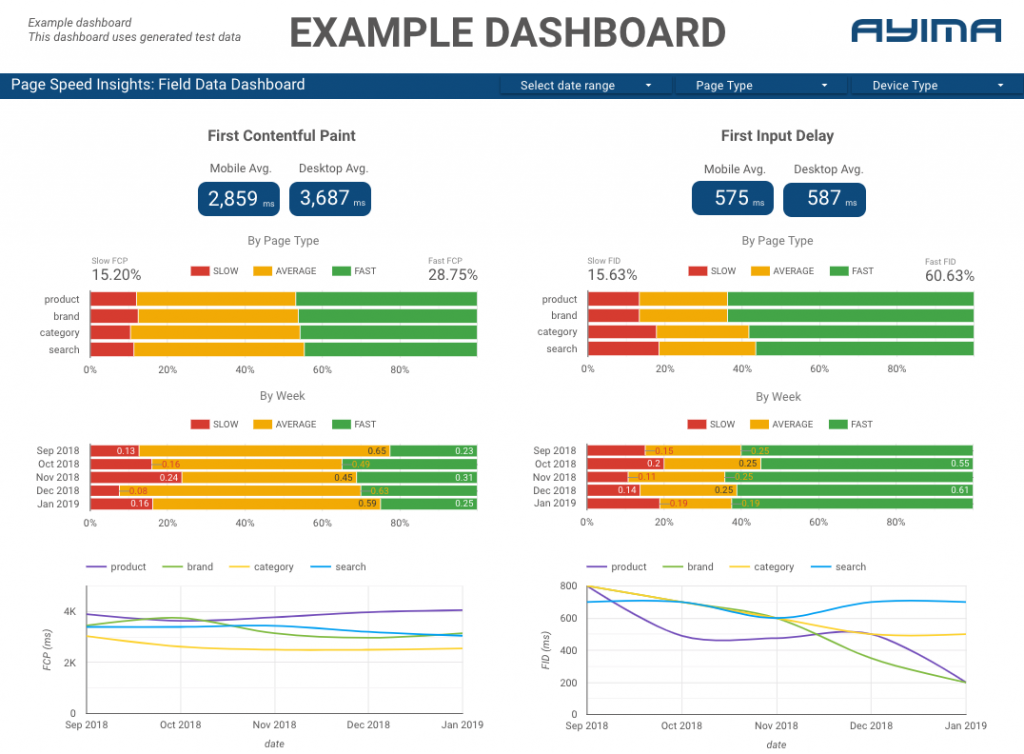
또한 Google의 실험실 데이터를 포함하여 API에서 제공하는 다른 흥미로운 측정항목을 추적하고 모든 것을 대화형 대시보드에 표시합니다. 이에 대한 자세한 정보를 원하시면 연락해 주십시오. 채팅을 하고 싶습니다!
소스 코드: 여기에서 실행할 예제 스크립트가 있는 GitHub 프로젝트를 찾을 수 있습니다.