
เริ่มต้นใช้งาน Page Speed API ของ Google
เผยแพร่แล้ว: 2019-03-11ความเร็วของหน้าเป็นตัวบ่งชี้ที่ใหญ่ที่สุดตัวหนึ่งว่าผู้ใช้จะใช้เวลาบนไซต์ของคุณนานแค่ไหน หน้าที่โหลดช้าสามารถนำไปสู่อัตราตีกลับที่สูงขึ้น อัตราการแปลงที่ต่ำลง และทำให้รายได้ลดลง
เพื่อให้ได้ข้อมูลเชิงลึกว่าเวลาในการโหลดอาจส่งผลต่อการรักษาผู้ชมและ Conversion ของคุณหรือไม่ เครื่องมือ Page Speed Insights ของ Google จึงเป็นจุดเริ่มต้นที่ดี Page Speed API ของ Google คือวิธีที่คุณสามารถเสียบเข้ากับข้อมูลนี้และรวมข้อมูลเชิงลึกไว้ในกองข้อมูลของคุณ เราใช้มันเพื่อสร้างตัวติดตามการวิเคราะห์ Page Speed ของเราเองเพื่อตรวจสอบตัวชี้วัดประสบการณ์ผู้ใช้ที่สำคัญสำหรับลูกค้าของเรา
อะไรที่ยอดเยี่ยมมากเกี่ยวกับ Page Speed Insights API
ด้วยเครื่องมือนี้ คุณสามารถเสียบ URL และรับข้อมูลสรุปประสิทธิภาพได้ วิธีนี้เหมาะสำหรับการสุ่มตัวอย่าง URL จำนวนหนึ่ง แต่จะเป็นอย่างไรถ้าคุณมีเว็บไซต์ขนาดใหญ่และต้องการดูภาพรวมที่ครอบคลุมของประสิทธิภาพในส่วนต่างๆ และประเภทหน้าเว็บต่างๆ
นี่คือที่มาของ API Google Page Speed Insights API ของ Google เปิดโอกาสให้เราวิเคราะห์ประสิทธิภาพสำหรับหลาย ๆ หน้าและบันทึกผลลัพธ์ โดยไม่จำเป็นต้องขอ URL ทีละรายการอย่างชัดแจ้งและตีความผลลัพธ์ด้วยตนเอง
ด้วยเหตุนี้ เราจึงได้รวบรวมคำแนะนำง่ายๆ ที่จะช่วยให้คุณเริ่มต้นใช้งาน API สำหรับเว็บไซต์ของคุณเองได้ เมื่อคุณทำความคุ้นเคยกับกระบวนการที่อธิบายไว้ด้านล่างแล้ว คุณจะเห็นว่าสามารถใช้เพื่อวิเคราะห์ความเร็วไซต์ของคุณในวงกว้าง ติดตามว่ามีการเปลี่ยนแปลงอย่างไรเมื่อเวลาผ่านไป หรือแม้แต่ตั้งค่าเครื่องมือตรวจสอบ
คู่มือนี้จะถือว่ามีความคุ้นเคยกับการเขียนสคริปต์อยู่บ้าง ที่นี่เราใช้ Python เพื่อเชื่อมต่อกับ API และแยกวิเคราะห์ผลลัพธ์
วัตถุประสงค์
ในโพสต์นี้ คุณจะได้เรียนรู้วิธี:
- สร้างแบบสอบถาม Google Page Speed Insights API
- สร้างคำขอ API สำหรับตาราง URL
- ดึงข้อมูลพื้นฐานจากการตอบกลับ API
- รันสคริปต์ตัวอย่างที่กำหนดใน Python
กำลังตั้งค่า
คุณต้องปฏิบัติตามสองสามขั้นตอนก่อนที่จะสืบค้น Page Speed Insights API ด้วย Python
- การตั้งค่า API: Google API จำนวนมากต้องการคีย์ API รหัสผ่าน และมาตรการตรวจสอบสิทธิ์อื่นๆ อย่างไรก็ตาม คุณไม่จำเป็นต้องดำเนินการใดๆ เพื่อเริ่มต้นกับ Google Page Speeds API!
- การติดตั้ง Python 3: หากคุณไม่เคยใช้ python มาก่อน เราขอแนะนำให้เริ่มต้นด้วยการแจกจ่าย Anaconda (เวอร์ชัน Python 3.x) ซึ่งติดตั้ง python พร้อมกับไลบรารีการวิเคราะห์ข้อมูลยอดนิยม เช่น Pandas
การทำตามคำขอ
พื้นฐานของการร้องขอ
สามารถสอบถาม API ได้ที่จุดสิ้นสุดนี้โดยใช้คำขอ GET:
GET https://www.googleapis.com/pagespeedonline/v5/runPagespeedจากนั้นเราเพิ่มพารามิเตอร์เพิ่มเติมเพื่อระบุ URL ที่เราต้องการค้นหาความเร็วหน้าเว็บและประเภทอุปกรณ์ที่จะใช้ดังที่แสดงด้านล่าง:
https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={url}&strategy={device_type} เมื่อส่งคำขอ คุณควรแทนที่ {url} ด้วย URL ของหน้าที่เข้ารหัส URL จากเว็บไซต์ของคุณ และ {device_type} ด้วยมือถือหรือเดสก์ท็อป เพื่อระบุประเภทอุปกรณ์
แพ็คเกจ Python
ในการส่งคำขอ นำเข้าข้อมูลแล้วเขียนผลลัพธ์ลงในตาราง เราจะใช้ไลบรารีหลามสองสามตัว:
- urllib : เพื่อสร้างคำขอ HTTP
- json : เพื่อแยกวิเคราะห์และอ่านวัตถุตอบกลับ
- pandas : เพื่อบันทึกผลลัพธ์ในรูปแบบ CSV
การสร้างแบบสอบถาม
ในการสร้างคำขอ API โดยใช้ Python เราสามารถใช้เมธอด urllib.request.urlopen :
import urllib.request import urllib.parse url = 'http://www.example.com' escaped_url = urllib.parse.quote(url) device_type = 'mobile' # Construct request url contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(escaped_url, device_type) ).read().decode('UTF-8')คำขอนี้ควรส่งคืนการตอบกลับ JSON (ขนาดใหญ่อย่างน่าประหลาดใจ) เราจะพูดถึงรายละเอียดเพิ่มเติมในไม่ช้านี้
ทำการสอบถามหลายรายการ
จุดขายที่สำคัญของ API นี้คือช่วยให้เราสามารถดึงความเร็วของหน้าสำหรับกลุ่มของ URL มาดูกันว่าสิ่งนี้สามารถทำได้ด้วย Python อย่างไร
ทางเลือกหนึ่งคือการจัดเก็บพารามิเตอร์คำขอ ( url และ device_type ) ใน CSV ซึ่งเราสามารถโหลดลงใน Pandas DataFrame เพื่อทำซ้ำได้ โปรดสังเกตว่าแต่ละคำขอหรือคู่ url + device_type ที่ไม่ซ้ำกันมีแถวของตัวเอง
จัดเก็บข้อมูลใน CSV
URL, device_type 0, https://www.example.com, desktop 1, https://www.example.com, mobile 2, https://www.example.com/blog, desktop 3, https://www.example.com/blog, mobileโหลด CSV
import pandas as pd df = pd.read_csvimport pandas as pd df = pd.read_csv(url_file)
เมื่อเรามีชุดข้อมูลที่มี URL ทั้งหมดที่จะขอแล้ว เราสามารถทำซ้ำผ่านพวกมันและสร้างคำขอ API สำหรับแต่ละแถวได้ นี้แสดงไว้ด้านล่าง:
import time # This is where the responses will be stored response_object = {} # Iterating through df for i in range(0, len(df)): # Error handling try: print('Requesting row #:', i) # Define the request parameters url = df.iloc[i]['URL'] device_type = df.iloc[i]['device_type'] # Making request contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(url, device_type) ).read().decode('UTF-8') # Converts to json format contents_json = json.loads(contents) # Insert returned json response into response_object response_object[device_type][url] = contents_json print('Sleeping for 20 seconds between responses.') time.sleep(20) except Exception as e: print('Error:', e) print('Returning empty response for url:', url) response_object[device_type][url] = {}การอ่านคำตอบ
ก่อนที่จะใช้ตัวกรองหรือการจัดรูปแบบใดๆ กับข้อมูล อันดับแรก เราสามารถเก็บคำตอบทั้งหมดไว้ใช้ในอนาคตได้ดังนี้:
import json from datetime import datetime f_name ='data/{}-response.json'.format(datetime.now().strftime("%Y-%m-%d_%H:%M:%S")) with open(f_name, 'w') as outfile: json.dump(response_object, outfile, indent=4)ตามที่กล่าวไว้ข้างต้น การตอบกลับแต่ละครั้งจะส่งคืนอ็อบเจ็กต์ JSON พวกเขามีคุณสมบัติที่แตกต่างกันมากมายที่เกี่ยวข้องกับ URL ที่กำหนด และมีขนาดใหญ่เกินกว่าจะถอดรหัสโดยไม่ต้องกรองและจัดรูปแบบ

ในการทำเช่นนี้ เราจะใช้ไลบรารี Pandas ซึ่งทำให้ง่ายต่อการดึงข้อมูลที่เราต้องการในรูปแบบตารางและส่งออกเป็น CSV
นี่คือโครงสร้างทั่วไปของการตอบสนอง ข้อมูลเวลาในการโหลดลดลงเนื่องจากขนาด
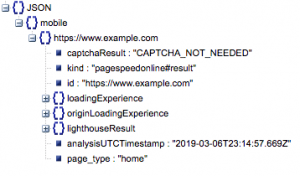
โครงสร้างการตอบสนองทั่วไป
ท่ามกลางข้อมูลอื่นๆ มีแหล่งข้อมูลหลักสองแห่งของข้อมูลความเร็วหน้าเว็บที่รวมอยู่ในการตอบสนอง: ข้อมูลแล็บ ที่จัดเก็บไว้ใน 'lighthouseResult' และข้อมูลฟิลด์ เก็บไว้ใน 'loadingExperience' ในโพสต์นี้ เราจะเน้นเฉพาะข้อมูลภาคสนาม ซึ่งรวบรวมมาจากผู้ใช้จริงบนเบราว์เซอร์ Chrome
โดยเฉพาะอย่างยิ่ง เราจะแยกเมตริกต่อไปนี้:
- URL ที่ขอและ URL สุดท้าย
- เราต้องการทั้ง URL ที่ร้องขอและสุดท้ายที่แก้ไขแล้วซึ่งได้รับการตรวจสอบเพื่อให้แน่ใจว่าเป็น URL เดียวกัน ซึ่งจะช่วยให้เราระบุได้ว่าผลลัพธ์นั้นมาจาก URL ที่ต้องการแทนการเปลี่ยนเส้นทาง
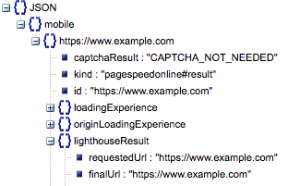
เราจะเห็นว่า URL ทั้งสองเหมือนกันใน 'lighthouseResult' ด้านบน
- First Contentful Paint (มิลลิวินาที)
- นี่คือเวลาระหว่างการนำทางครั้งแรกของผู้ใช้ไปยังหน้าเว็บและเมื่อเบราว์เซอร์แสดงเนื้อหาเป็นครั้งแรก โดยบอกผู้ใช้ว่าหน้าเว็บกำลังโหลด
- เมตริกนี้วัดเป็นมิลลิวินาที
- First Contentful Paint (สัดส่วนของช้า เฉลี่ย เร็ว)
- นี่แสดงเปอร์เซ็นต์ของหน้าที่มีความเร็วในการโหลด First Contentful Paint ช้า เฉลี่ย และเร็ว
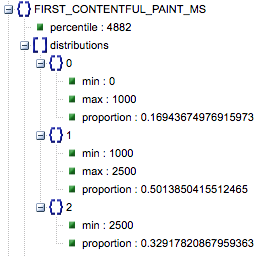
เวลาในการโหลด Contentful Paint ครั้งแรกในหน่วยมิลลิวินาที มีป้ายกำกับ 'percentile' และสัดส่วนของช้า เฉลี่ย และเร็ว
ผลลัพธ์ทั้งหมดเหล่านี้สามารถดึงออกมาสำหรับข้อมูลมือถือและเดสก์ท็อปอย่างใดอย่างหนึ่งหรือทั้งสองอย่าง
หากเราเรียกดาต้าเฟรมของ Pandas df_field_responses นี่คือวิธีที่เราจะแยกคุณสมบัติเหล่านี้:
import pandas as pd # Specify the device_type (mobile or desktop) device_type = 'mobile' # Create dataframe to store responses df_field_responses = pd.DataFrame( columns=['requested_url', 'final_url', 'FCM_ms', 'FCP_category', 'FCP_fast', 'FCP_avg', 'FCP_slow' ] ) for (url, i) in zip( response_object[device_type].keys(), range(0, len(df_field_responses)) ): try: print('Trying to insert response for url:', url) # We reuse this below when selecting data from the response fcp_loading = response_object[device_type][url] ['loadingExperience']['metrics']['FIRST_CONTENTFUL_PAINT_MS'] # URLs df_field_responses.loc[i, 'requested_url'] = response_object[device_type][url]['lighthouseResult']['requestedUrl'] df_field_responses.loc[i, 'final_url'] = response_object[device_type][url]['lighthouseResult']['finalUrl'] # Loading experience: First Contentful Paint (ms) df_field_responses.loc[i, 'FCP_ms'] = fcp_loading['percentile'] df_field_responses.loc[i, 'FCP_category'] = fcp_loading['category'] # Proportions: First Contentful Paint df_field_responses.loc[i, 'FCP_fast'] = fcp_loading['distributions'][0]['proportion'] df_field_responses.loc[i, 'FCP_avg'] = fcp_loading['distributions'][1]['proportion'] df_field_responses.loc[i, 'FCP_slow'] = fcp_loading['distributions'][2]['proportion'] print('Inserted for row {}: {}'.format(i, df_field_responses.loc[i])) except Exception as e: print('Error:', e) print('Filling row with Error for row: {}; url: {}'.format(i, url)) # Fill in 'Error' for row if a field couldn't be found df_field_responses.loc[i] = ['Error' for i in range(0, len(df_field_responses.columns))]จากนั้นในการจัดเก็บดาต้าเฟรม df_field_responses ใน CSV:
df_field_responses.to_csv('page_speeds_filtered_responses.csv', index=False)การรันสคริปต์บน GitHub
ที่เก็บข้อมูลบน GitHub มีคำแนะนำเกี่ยวกับวิธีการเรียกใช้ไฟล์ แต่นี่คือรายละเอียดด่วน
- ก่อนรันสคริปต์ตัวอย่างบน GitHub คุณจะต้องโคลนที่เก็บโดยใช้
-
git clone https://github.com/Ayima/page-speed-blog-post.git
-
- จากนั้นสร้างไฟล์ CSV ที่มี URL ที่จะสืบค้น
- กรอกไฟล์ปรับแต่งด้วยชื่อไฟล์ URL
- คำสั่งเพื่อเรียกใช้สคริปต์:
python main.py --config-file config.jsonสิ่งที่ควรทราบ:
API มีการจำกัดจำนวนคำขอที่คุณสามารถทำได้ต่อวันและต่อวินาที
มีหลายวิธีในการเตรียมตัวสำหรับสิ่งนี้ ได้แก่:
- การจัดการข้อผิดพลาด: ทำซ้ำคำขอที่ส่งคืนข้อผิดพลาด
- การ ควบคุมปริมาณ: ในสคริปต์ของคุณเพื่อจำกัดจำนวนคำขอที่ส่งต่อวินาที และขออีกครั้งหาก URL ล้มเหลว
- รับคีย์ API หากจำเป็น (โดยปกติหากคุณทำการสืบค้นมากกว่าหนึ่งรายการต่อวินาที)
หวังว่าหลังจากอ่านคู่มือนี้แล้ว คุณจะสามารถเริ่มต้นใช้งานด้วยการสืบค้นข้อมูลพื้นฐานของ Google Page Speed Insights API ได้ อย่าลังเลที่จะติดต่อเราได้ที่ twitter @ayima หากมีคำถามหรือหากคุณประสบปัญหาใด ๆ !
วิธีที่เราใช้ Page Speeds API ที่ Ayima
ที่ Ayima เรารวบรวมและเร่งความเร็วหน้าคลังสินค้าให้กับลูกค้าอย่างต่อเนื่อง ข้อมูลนี้ช่วยให้เราติดตามความสมบูรณ์ของเว็บไซต์ของตนและระบุแนวโน้มด้านลบหรือด้านบวก ด้วยการตรวจสอบความเร็วสำหรับหน้าต่างๆ หลายๆ หน้า เราจึงสามารถแสดงภาพประสิทธิภาพตามส่วนของไซต์หรือประเภทหน้าเว็บ (เช่น หน้าผลิตภัณฑ์ VS หน้าหมวดหมู่สำหรับเว็บไซต์อีคอมเมิร์ซ)
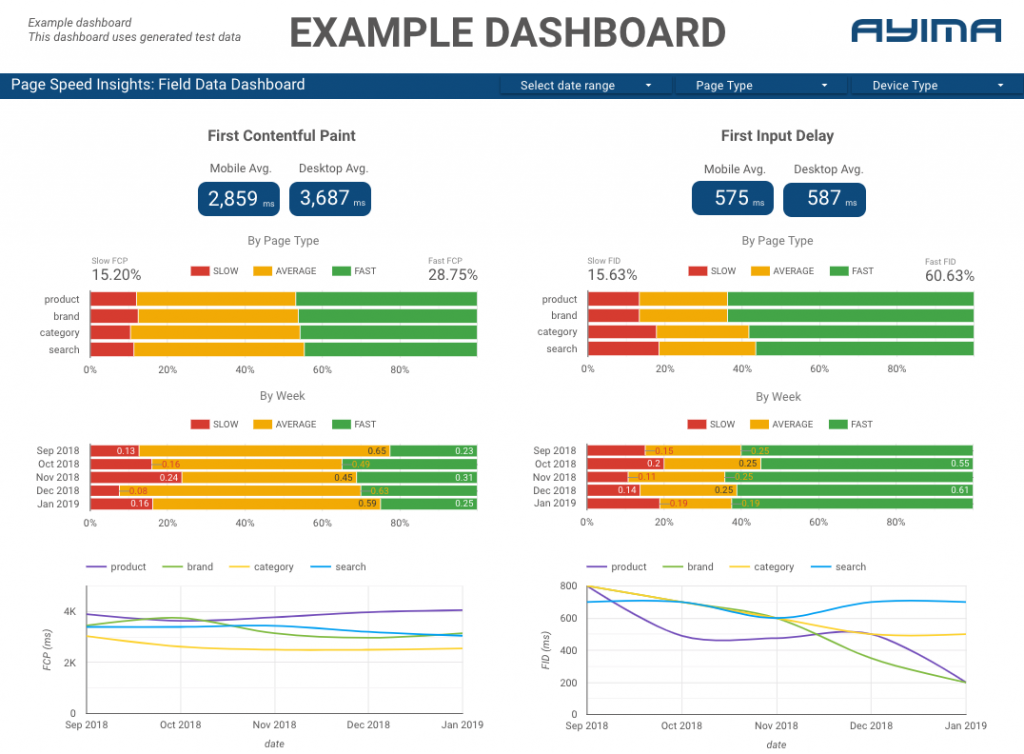
เรายังติดตามตัวชี้วัดที่น่าสนใจอื่นๆ ที่ API จัดหาให้ รวมถึงข้อมูล Lab ของ Google และนำเสนอทุกอย่างในแดชบอร์ดเชิงโต้ตอบ สำหรับข้อมูลเพิ่มเติมเกี่ยวกับเรื่องนี้ โปรดติดต่อ เรายินดีที่จะพูดคุยกับคุณ!
ซอร์สโค้ด: คุณสามารถค้นหาโปรเจ็กต์ GitHub พร้อมสคริปต์ตัวอย่างเพื่อเรียกใช้ที่นี่