
Primeros pasos con la API de velocidad de página de Google
Publicado: 2019-03-11La velocidad de la página es uno de los mayores indicadores de cuánto tiempo pasará alguien en tu sitio. Las páginas de carga lenta pueden generar tasas de rebote más altas, tasas de conversión más bajas y, por lo tanto, menores ingresos.
Para obtener una idea de si los tiempos de carga pueden estar afectando la retención y la conversión de su audiencia, la herramienta Page Speed Insights de Google es un excelente lugar para comenzar. La API de velocidad de la página de Google es la forma en que puede conectarse a estos datos e incorporar conocimientos dentro de su pila de datos. Lo hemos usado para construir nuestro propio rastreador de análisis de Page Speed para monitorear las métricas clave de la experiencia del usuario para nuestros clientes.
¿Qué tiene de bueno la API de Page Speed Insights?
Con esta herramienta, puede conectar una URL y recibir un resumen de su rendimiento. Esto es excelente para probar un puñado de URL, pero ¿qué sucede si tiene un sitio web grande y desea ver una descripción general completa del rendimiento en varias secciones y tipos de página?
Aquí es donde entra en juego la API. La API de Page Speed Insights de Google nos brinda la oportunidad de analizar el rendimiento de muchas páginas y registrar los resultados, sin necesidad de solicitar explícitamente las URL de una en una e interpretar los resultados manualmente.
Con esto en mente, hemos elaborado una guía simple que lo ayudará a comenzar a usar la API para su propio sitio web. Una vez que se haya familiarizado con el proceso descrito a continuación, verá cómo se puede utilizar para analizar la velocidad de su sitio a escala, hacer un seguimiento de cómo cambia con el tiempo o incluso configurar herramientas de supervisión.
Esta guía asume cierta familiaridad con las secuencias de comandos. Aquí usamos Python para interactuar con la API y analizar los resultados.
Objetivos
En este post aprenderás a:
- Construya una consulta API de Google Page Speed Insights
- Hacer solicitudes de API para una tabla de URL
- Extraer información básica de la respuesta de la API
- Ejecute el script de ejemplo dado en Python
preparándose
Hay algunos pasos que deberá seguir antes de consultar la API de Page Speed Insights con Python.
- Configuración de API: muchas API de Google requieren claves de API, contraseñas y otras medidas de autenticación. Sin embargo, ¡no necesita nada de esto para comenzar con la API de velocidades de página de Google!
- Instalación de Python 3: si nunca ha usado python antes, le recomendamos que comience con la distribución Anaconda (versión de Python 3.x), que instala python junto con bibliotecas de análisis de datos populares como Pandas.
Hacer las solicitudes
Conceptos básicos de una solicitud
La API se puede consultar en este punto final mediante solicitudes GET:
GET https://www.googleapis.com/pagespeedonline/v5/runPagespeedLuego agregamos parámetros adicionales para especificar la URL de la que queremos encontrar la velocidad de la página y el tipo de dispositivo a usar, como se muestra a continuación:
https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={url}&strategy={device_type} Al realizar solicitudes, debe reemplazar {url} con la URL de la página codificada en URL de su sitio web y {device_type} con móvil o computadora de escritorio, para especificar el tipo de dispositivo.
Paquetes de Python
Para realizar solicitudes, ingerirlas y luego escribir los resultados en tablas, usaremos algunas bibliotecas de Python:
- urllib : Para realizar las solicitudes HTTP.
- json : para analizar y leer los objetos de respuesta.
- pandas : Para guardar los resultados en formato CSV.
Construyendo la consulta
Para realizar una solicitud de API usando Python, podemos usar el método urllib.request.urlopen :
import urllib.request import urllib.parse url = 'http://www.example.com' escaped_url = urllib.parse.quote(url) device_type = 'mobile' # Construct request url contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(escaped_url, device_type) ).read().decode('UTF-8')Esta solicitud debería devolver una respuesta JSON (sorprendentemente grande). Discutiremos esto con más detalle en breve.
Haciendo varias consultas
Un importante punto de venta de esta API es que nos permite obtener velocidades de página para lotes de URL. Echemos un vistazo a cómo se puede hacer esto con Python.
Una opción es almacenar los parámetros de solicitud ( url y device_type ) en un CSV, que podemos cargar en un Pandas DataFrame para iterar. Observe a continuación que cada solicitud o par único de url + device_type tiene su propia fila.
Almacenar datos en CSV
URL, device_type 0, https://www.example.com, desktop 1, https://www.example.com, mobile 2, https://www.example.com/blog, desktop 3, https://www.example.com/blog, mobileCargue el CSV
import pandas as pd df = pd.read_csvimport pandas as pd df = pd.read_csv(archivo_url)
Una vez que tenemos un conjunto de datos con todas las URL para solicitar, podemos recorrerlas y realizar una solicitud de API para cada fila. Esto se muestra a continuación:
import time # This is where the responses will be stored response_object = {} # Iterating through df for i in range(0, len(df)): # Error handling try: print('Requesting row #:', i) # Define the request parameters url = df.iloc[i]['URL'] device_type = df.iloc[i]['device_type'] # Making request contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(url, device_type) ).read().decode('UTF-8') # Converts to json format contents_json = json.loads(contents) # Insert returned json response into response_object response_object[device_type][url] = contents_json print('Sleeping for 20 seconds between responses.') time.sleep(20) except Exception as e: print('Error:', e) print('Returning empty response for url:', url) response_object[device_type][url] = {}leyendo la respuesta
Antes de aplicar filtros o formatear los datos, primero podemos almacenar las respuestas completas para uso futuro de esta manera:
import json from datetime import datetime f_name ='data/{}-response.json'.format(datetime.now().strftime("%Y-%m-%d_%H:%M:%S")) with open(f_name, 'w') as outfile: json.dump(response_object, outfile, indent=4)Como se mencionó anteriormente, cada respuesta devuelve un objeto JSON. Tienen muchas propiedades diferentes relacionadas con la URL dada y son demasiado grandes para descifrarlos sin filtrarlos y formatearlos.

Para hacer esto, usaremos la biblioteca Pandas, que facilita la extracción de los datos que queremos en formato de tabla y la exportación a CSV.
Esta es la estructura general de la respuesta. Los datos de tiempos de carga se han minimizado debido a su tamaño.
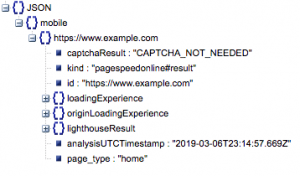
Estructura general de respuesta
Entre otra información, hay dos fuentes principales de datos de velocidad de página incluidos en la respuesta: datos de laboratorio, almacenados en 'lighthouseResult' y datos de campo, almacenados en 'loadingExperience'. En esta publicación, nos centraremos solo en los datos de campo, que se obtienen de forma colectiva en función de los usuarios del mundo real en el navegador Chrome.
En concreto, vamos a extraer las siguientes métricas:
- URL solicitada y URL final
- Necesitamos la URL resuelta final y solicitada que se auditó para asegurarnos de que sean iguales. Esto nos ayudará a identificar que el resultado provino de la URL deseada en lugar de una redirección.
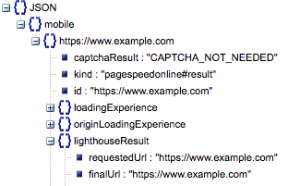
Podemos ver que ambas URL son iguales en 'lighthouseResult' arriba.
- Primera pintura con contenido (ms)
- Este es el tiempo entre la primera navegación del usuario a la página y cuando el navegador muestra por primera vez un contenido, diciéndole al usuario que la página se está cargando.
- Esta métrica se mide en milisegundos.
- Primera pintura con contenido (proporciones de lento, medio, rápido)
- Esto muestra el porcentaje de páginas que tienen tiempos de carga lentos, promedio y rápidos de First Contentful Paint.
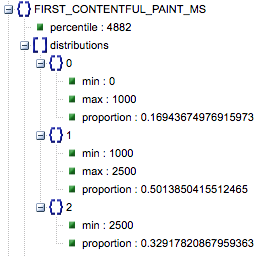
Tiempo de carga de First Contentful Paint en milisegundos, etiquetado como 'percentil' y proporción de lento, promedio y rápido.
Todos estos resultados se pueden extraer para los datos móviles y de escritorio, o para ambos.
Si llamamos a nuestro marco de datos de Pandas df_field_responses, así es como extraeríamos estas propiedades:
import pandas as pd # Specify the device_type (mobile or desktop) device_type = 'mobile' # Create dataframe to store responses df_field_responses = pd.DataFrame( columns=['requested_url', 'final_url', 'FCM_ms', 'FCP_category', 'FCP_fast', 'FCP_avg', 'FCP_slow' ] ) for (url, i) in zip( response_object[device_type].keys(), range(0, len(df_field_responses)) ): try: print('Trying to insert response for url:', url) # We reuse this below when selecting data from the response fcp_loading = response_object[device_type][url] ['loadingExperience']['metrics']['FIRST_CONTENTFUL_PAINT_MS'] # URLs df_field_responses.loc[i, 'requested_url'] = response_object[device_type][url]['lighthouseResult']['requestedUrl'] df_field_responses.loc[i, 'final_url'] = response_object[device_type][url]['lighthouseResult']['finalUrl'] # Loading experience: First Contentful Paint (ms) df_field_responses.loc[i, 'FCP_ms'] = fcp_loading['percentile'] df_field_responses.loc[i, 'FCP_category'] = fcp_loading['category'] # Proportions: First Contentful Paint df_field_responses.loc[i, 'FCP_fast'] = fcp_loading['distributions'][0]['proportion'] df_field_responses.loc[i, 'FCP_avg'] = fcp_loading['distributions'][1]['proportion'] df_field_responses.loc[i, 'FCP_slow'] = fcp_loading['distributions'][2]['proportion'] print('Inserted for row {}: {}'.format(i, df_field_responses.loc[i])) except Exception as e: print('Error:', e) print('Filling row with Error for row: {}; url: {}'.format(i, url)) # Fill in 'Error' for row if a field couldn't be found df_field_responses.loc[i] = ['Error' for i in range(0, len(df_field_responses.columns))]Luego, para almacenar el marco de datos, df_field_responses, en un CSV:
df_field_responses.to_csv('page_speeds_filtered_responses.csv', index=False)Ejecutar los scripts en GitHub
El repositorio en GitHub contiene instrucciones sobre cómo ejecutar los archivos, pero aquí hay un desglose rápido.
- Antes de ejecutar los scripts de ejemplo en GitHub, deberá clonar el repositorio usando
-
git clone https://github.com/Ayima/page-speed-blog-post.git
-
- Luego cree un archivo CSV con las URL para consultar.
- Rellene el archivo de configuración con el nombre del archivo URL.
- Comando para ejecutar los scripts:
python main.py --config-file config.jsonAlgo para tener en cuenta:
La API tiene un límite en cuanto a la cantidad de solicitudes que puede realizar por día y por segundo.
Hay varias maneras de prepararse para esto, incluyendo:
- Manejo de errores: repetir solicitudes que devuelven un error
- Limitación: en su secuencia de comandos para limitar la cantidad de solicitudes enviadas por segundo y volver a solicitar si falla una URL.
- Obtenga una clave API si es necesario (generalmente si realiza más de una consulta por segundo).
Con suerte, después de leer esta guía, podrá ponerse en marcha con algunas consultas básicas de la API de Google Page Speed Insights. ¡No dude en comunicarse con nosotros en twitter @ayima con cualquier pregunta o si tiene algún problema!
Cómo usamos la API Page Speeds en Ayima
Aquí en Ayima, recopilamos y almacenamos continuamente las velocidades de página para los clientes. Esto nos ayuda a vigilar la salud de sus sitios web e identificar tendencias negativas o positivas. Al monitorear las velocidades para una variedad de páginas, podemos visualizar el rendimiento por sección del sitio o tipo de página (por ejemplo, páginas de productos VS páginas de categorías para sitios web de comercio electrónico).
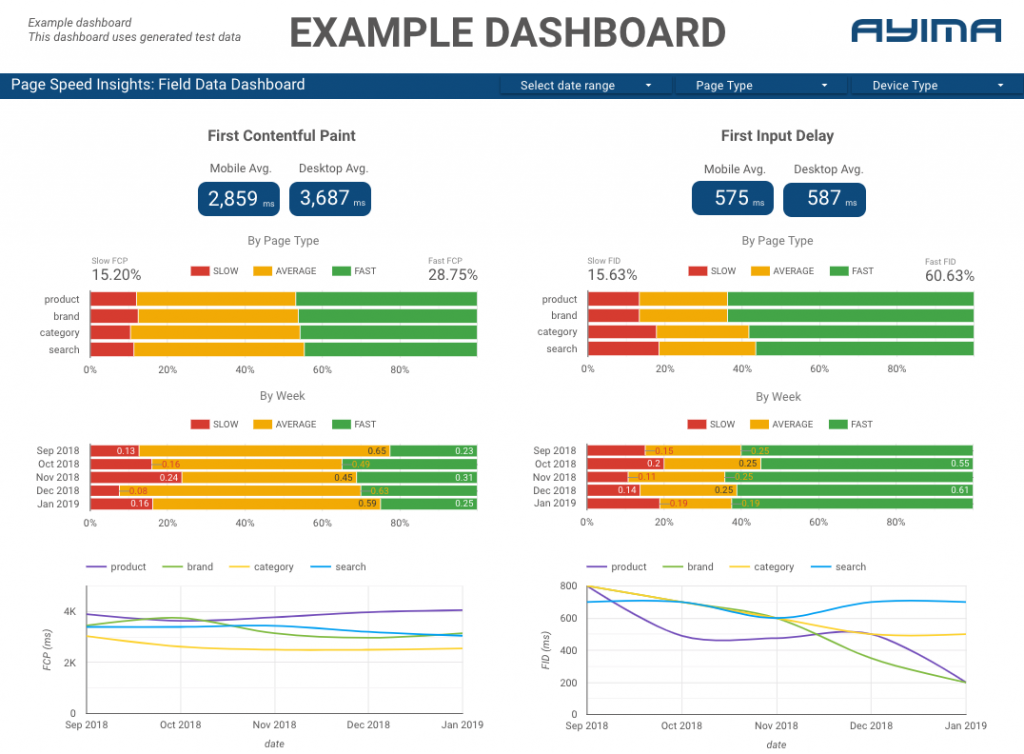
También rastreamos otras métricas interesantes proporcionadas por la API, incluidos los datos del laboratorio de Google, y presentamos todo en un tablero interactivo. Para obtener más información al respecto, comuníquese con nosotros, ¡nos encantaría conversar con usted!
Código fuente: puede encontrar el proyecto de GitHub con un script de ejemplo para ejecutar aquí.