
開始使用 Google 的 Page Speed API
已發表: 2019-03-11頁面速度是衡量某人將在您的網站上花費多長時間的最大指標之一。 緩慢加載頁面會導致更高的跳出率、更低的轉化率,從而降低收入。
要深入了解加載時間是否會影響您的受眾保留和轉化,Google 的 Page Speed Insights 工具是一個很好的起點。 Google 的 Page Speed API 是您可以插入這些數據並在您的數據堆棧中整合洞察力的方式。 我們已經使用它來構建我們自己的 Page Speed 分析跟踪器,以監控我們客戶的關鍵用戶體驗指標。
Page Speed Insights API 有什麼了不起的?
使用此工具,您可以插入 URL 並接收其性能摘要。 這非常適合對少數 URL 進行採樣,但如果您有一個大型網站並希望查看跨多個部分和頁麵類型的性能的全面概述,該怎麼辦?
這就是 API 的用武之地。Google 的 Page Speed Insights API 讓我們有機會分析許多頁面的性能並記錄結果,而無需一次明確地請求一個 URL 並手動解釋結果。
考慮到這一點,我們整理了一份簡單的指南,幫助您開始為自己的網站使用 API。 一旦您熟悉了下面概述的過程,您將了解如何使用它來大規模分析您的站點速度,跟踪它如何隨時間變化,甚至設置監控工具。
本指南假定您對腳本有一定的了解。 這裡我們使用 Python 與 API 交互並解析結果。
目標
在這篇文章中,您將學習如何:
- 構建 Google Page Speed Insights API 查詢
- 對 URL 表發出 API 請求
- 從 API 響應中提取基本信息
- 在 Python 中運行給定的示例腳本
設置
在使用 Python 查詢 Page Speed Insights API 之前,您需要執行幾個步驟。
- API 設置:許多 Google API 需要 API 密鑰、密碼和其他身份驗證措施。 但是,您不需要任何這些即可開始使用 Google Page Speeds API!
- Python 3 安裝:如果您以前從未使用過 python,我們建議您開始使用 Anaconda 發行版(Python 3.x 版本),它安裝了 python 以及 Pandas 等流行的數據分析庫。
提出請求
請求的基礎
可以使用 GET 請求在此端點查詢 API:
GET https://www.googleapis.com/pagespeedonline/v5/runPagespeed然後我們添加額外的參數來指定我們想要查找頁面速度的 URL 和要使用的設備類型,如下所示:
https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={url}&strategy={device_type} 發出請求時,您應將{url}替換為您網站中的 URL 編碼頁面 URL,並將{device_type}替換為移動設備或桌面設備,以指定設備類型。
Python 包
為了發出請求,攝取它們,然後將結果寫入表,我們將使用一些 python 庫:
- urllib :發出 HTTP 請求。
- json :解析和讀取響應對象。
- pandas :以 CSV 格式保存結果。
構造查詢
要使用 Python 發出 API 請求,我們可以使用urllib.request.urlopen方法:
import urllib.request import urllib.parse url = 'http://www.example.com' escaped_url = urllib.parse.quote(url) device_type = 'mobile' # Construct request url contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(escaped_url, device_type) ).read().decode('UTF-8')這個請求應該返回一個(非常大的)JSON 響應。 我們將在稍後更詳細地討論這個問題。
進行多個查詢
這個 API 的一個主要賣點是它使我們能夠為批量 URL 拉取頁面速度。 讓我們看一下如何使用 Python 完成此操作。
一種選擇是將請求參數( url和device_type )存儲在 CSV 中,我們可以將其加載到 Pandas DataFrame 中進行迭代。 請注意,每個請求或唯一的url + device_type對都有自己的行。
以 CSV 格式存儲數據
URL, device_type 0, https://www.example.com, desktop 1, https://www.example.com, mobile 2, https://www.example.com/blog, desktop 3, https://www.example.com/blog, mobile加載 CSV
import pandas as pd df = pd.read_csvimport pandas as pd df = pd.read_csv(url_file)
一旦我們有了一個包含所有要請求的 URL 的數據集,我們就可以遍歷它們並為每一行發出 API 請求。 如下所示:
import time # This is where the responses will be stored response_object = {} # Iterating through df for i in range(0, len(df)): # Error handling try: print('Requesting row #:', i) # Define the request parameters url = df.iloc[i]['URL'] device_type = df.iloc[i]['device_type'] # Making request contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(url, device_type) ).read().decode('UTF-8') # Converts to json format contents_json = json.loads(contents) # Insert returned json response into response_object response_object[device_type][url] = contents_json print('Sleeping for 20 seconds between responses.') time.sleep(20) except Exception as e: print('Error:', e) print('Returning empty response for url:', url) response_object[device_type][url] = {}閱讀回复
在對數據應用任何過濾器或格式化之前,我們可以首先存儲完整的響應以供將來使用,如下所示:
import json from datetime import datetime f_name ='data/{}-response.json'.format(datetime.now().strftime("%Y-%m-%d_%H:%M:%S")) with open(f_name, 'w') as outfile: json.dump(response_object, outfile, indent=4)如上所述,每個響應都返回一個 JSON 對象。 它們具有與給定 URL 相關的許多不同屬性,並且在不過濾和格式化的情況下太大而無法破譯。
為此,我們將使用 Pandas 庫,它可以輕鬆地以表格格式提取我們想要的數據並導出為 CSV。
這是響應的一般結構。 由於其大小,有關加載時間的數據已被最小化。

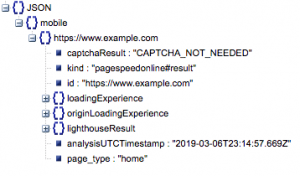
一般響應結構
除其他信息外,響應中包含兩個主要的頁面速度數據來源:實驗室數據,存儲在“lighthouseResult”中;字段數據,存儲在“loadingExperience”中。 在這篇文章中,我們將只關注 Field 數據,這些數據是根據 Chrome 瀏覽器上的真實用戶眾包獲取的。
特別是,我們將提取以下指標:
- 請求的 URL 和最終 URL
- 我們需要經過審核的請求 URL 和最終解析 URL,以確保它們相同。 這將幫助我們確定結果來自預期的 URL 而不是重定向。
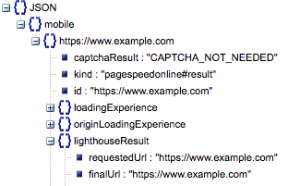
我們可以在上面的“lighthouseResult”中看到兩個 URL 是相同的。
- 首次內容繪製(毫秒)
- 這是用戶第一次導航到頁面和瀏覽器第一次呈現一段內容之間的時間,告訴用戶頁面正在加載。
- 該指標以毫秒為單位。
- First Contentful Paint (慢、平均、快的比例)
- 這顯示了 First Contentful Paint 加載時間緩慢、平均和快速的頁面百分比。
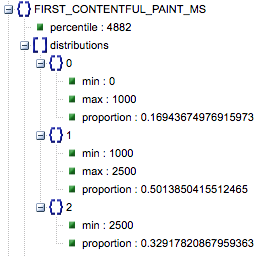
第一個 Contentful Paint 加載時間(以毫秒為單位),標記為“百分比”,以及慢速、平均和快速的比例。
所有這些結果都可以為移動和桌面數據中的一個或兩個提取。
如果我們將 Pandas 數據框稱為 df_field_responses,我們將通過以下方式提取這些屬性:
import pandas as pd # Specify the device_type (mobile or desktop) device_type = 'mobile' # Create dataframe to store responses df_field_responses = pd.DataFrame( columns=['requested_url', 'final_url', 'FCM_ms', 'FCP_category', 'FCP_fast', 'FCP_avg', 'FCP_slow' ] ) for (url, i) in zip( response_object[device_type].keys(), range(0, len(df_field_responses)) ): try: print('Trying to insert response for url:', url) # We reuse this below when selecting data from the response fcp_loading = response_object[device_type][url] ['loadingExperience']['metrics']['FIRST_CONTENTFUL_PAINT_MS'] # URLs df_field_responses.loc[i, 'requested_url'] = response_object[device_type][url]['lighthouseResult']['requestedUrl'] df_field_responses.loc[i, 'final_url'] = response_object[device_type][url]['lighthouseResult']['finalUrl'] # Loading experience: First Contentful Paint (ms) df_field_responses.loc[i, 'FCP_ms'] = fcp_loading['percentile'] df_field_responses.loc[i, 'FCP_category'] = fcp_loading['category'] # Proportions: First Contentful Paint df_field_responses.loc[i, 'FCP_fast'] = fcp_loading['distributions'][0]['proportion'] df_field_responses.loc[i, 'FCP_avg'] = fcp_loading['distributions'][1]['proportion'] df_field_responses.loc[i, 'FCP_slow'] = fcp_loading['distributions'][2]['proportion'] print('Inserted for row {}: {}'.format(i, df_field_responses.loc[i])) except Exception as e: print('Error:', e) print('Filling row with Error for row: {}; url: {}'.format(i, url)) # Fill in 'Error' for row if a field couldn't be found df_field_responses.loc[i] = ['Error' for i in range(0, len(df_field_responses.columns))]然後將數據幀 df_field_responses 存儲在 CSV 中:
df_field_responses.to_csv('page_speeds_filtered_responses.csv', index=False)在 GitHub 上運行腳本
GitHub 上的存儲庫包含有關如何運行文件的說明,但這裡有一個快速細分。
- 在 GitHub 上運行示例腳本之前,您需要使用克隆存儲庫
git clone https://github.com/Ayima/page-speed-blog-post.git
- 然後創建一個包含要查詢的 URL 的 CSV 文件。
- 使用 URL 文件名填寫配置文件。
- 運行腳本的命令:
python main.py --config-file config.json要記住的事情:
API 對您每天和每秒可以發出的請求數有限制。
有幾種方法可以為此做好準備,包括:
- 錯誤處理:重複請求返回錯誤
- 限制:在您的腳本中限制每秒發送的請求數,並在 URL 失敗時重新請求。
- 如有必要,獲取 API 密鑰(通常是在您每秒進行一次以上查詢的情況下)。
希望在閱讀完本指南後,您能夠開始使用 Google Page Speed Insights API 的一些基本查詢。 如有任何問題或遇到任何問題,請隨時通過推特@ayima 聯繫我們!
我們如何在 Ayima 使用 Page Speeds API
在 Ayima,我們不斷為客戶收集和存儲頁面速度。 這有助於我們密切關注他們網站的健康狀況並識別負面或正面趨勢。 通過監控各種頁面的速度,我們能夠按站點部分或頁麵類型(例如電子商務網站的產品頁面 VS 類別頁面)可視化性能。
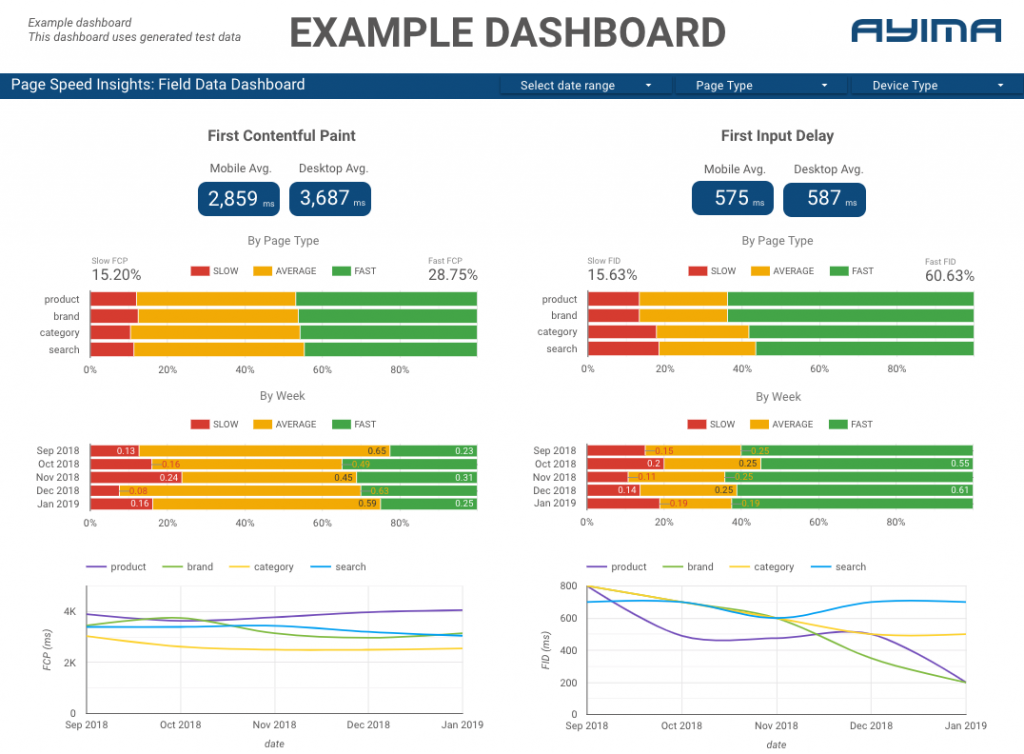
我們還跟踪 API 提供的其他有趣指標,包括 Google 的實驗室數據,並在交互式儀表板中顯示所有內容。 有關這方面的更多信息,請與我們聯繫,我們很樂意與您聊天!
源代碼:您可以在此處找到帶有示例腳本的 GitHub 項目以運行。