
GoogleのPageSpeedAPI入門
公開: 2019-03-11ページ速度は、誰かがあなたのサイトに費やす時間の最大の指標の1つです。 ページの読み込みが遅いと、バウンス率が高くなり、コンバージョン率が低くなるため、収益が低下する可能性があります。
読み込み時間がオーディエンスの維持とコンバージョンに影響を与えているかどうかを把握するには、GoogleのPageSpeedInsightsツールから始めるのが最適です。 GoogleのPageSpeedAPIは、このデータにプラグインして、データスタック内に洞察を組み込む方法です。 これを使用して、クライアントの主要なユーザーエクスペリエンスメトリックを監視する独自のPageSpeed分析トラッカーを構築しました。
Page Speed Insights APIの何がそんなに素晴らしいのですか?
このツールを使用すると、URLをプラグインして、そのパフォーマンスの概要を受け取ることができます。 これは、少数のURLをサンプリングするのに最適ですが、大規模なWebサイトがあり、複数のセクションとページタイプにわたるパフォーマンスの包括的な概要を確認したい場合はどうでしょうか。
そこでAPIが登場します。GoogleのPageSpeedInsights APIを使用すると、一度に1つずつ明示的にURLをリクエストして結果を手動で解釈しなくても、多くのページのパフォーマンスを分析して結果をログに記録できます。
これを念頭に置いて、独自のWebサイトでAPIの使用を開始するための簡単なガイドをまとめました。 以下に概説するプロセスに慣れると、サイトの速度を大規模に分析したり、時間の経過とともにどのように変化したかを追跡したり、監視ツールを設定したりするためにどのように使用できるかがわかります。
このガイドは、スクリプトにある程度精通していることを前提としています。 ここでは、Pythonを使用してAPIとインターフェースし、結果を解析します。
目的
この投稿では、次の方法を学習します。
- Google Page SpeedInsightsAPIクエリを作成します
- URLのテーブルに対してAPIリクエストを作成します
- API応答から基本情報を抽出します
- 与えられたサンプルスクリプトをPythonで実行します
セットアップ
PythonでPageSpeedInsights APIをクエリする前に、従う必要のあるいくつかの手順があります。
- APIの設定:多くのGoogle APIには、APIキー、パスワード、その他の認証手段が必要です。 ただし、Google Page Speeds APIの使用を開始するために、これらのいずれも必要ありません。
- Python 3のインストール:これまでPythonを使用したことがない場合は、Pandasなどの一般的なデータ分析ライブラリとともにPythonをインストールするAnacondaディストリビューション(Python 3.xバージョン)の使用を開始することをお勧めします。
リクエストする
リクエストの基本
APIは、GETリクエストを使用してこのエンドポイントでクエリできます。
GET https://www.googleapis.com/pagespeedonline/v5/runPagespeed次に、以下に示すように、追加のパラメーターを追加して、ページ速度を検索するURLと使用するデバイスタイプを指定します。
https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={url}&strategy={device_type} リクエストを行うときは、 {url}をウェブサイトのURLエンコードされたページURLに置き換え、 {device_type}をモバイルまたはデスクトップに置き換えてデバイスタイプを指定する必要があります。
Pythonパッケージ
リクエストを作成し、それらを取り込み、結果をテーブルに書き込むために、いくつかのPythonライブラリを使用します。
- urllib :HTTPリクエストを作成します。
- json :応答オブジェクトを解析して読み取るため。
- pandas :結果をCSV形式で保存します。
クエリの作成
Pythonを使用してAPIリクエストを行うには、 urllib.request.urlopenメソッドを使用できます。
import urllib.request import urllib.parse url = 'http://www.example.com' escaped_url = urllib.parse.quote(url) device_type = 'mobile' # Construct request url contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(escaped_url, device_type) ).read().decode('UTF-8')このリクエストは、(驚くほど大きな)JSON応答を返す必要があります。 これについては、後ほど詳しく説明します。
複数のクエリを行う
このAPIの主なセールスポイントは、URLのバッチのページ速度を引き出すことができることです。 Pythonでこれを行う方法を見てみましょう。
1つのオプションは、リクエストパラメータ( urlとdevice_type )をCSVに保存することです。これを、PandasDataFrameに読み込んで繰り返すことができます。 以下で、各リクエスト、または一意のurl + device_typeのペアに独自の行があることに注意してください。
データをCSVで保存
URL, device_type 0, https://www.example.com, desktop 1, https://www.example.com, mobile 2, https://www.example.com/blog, desktop 3, https://www.example.com/blog, mobileCSVを読み込む
import pandas as pd df = pd.read_csvimport pandas as pd df = pd.read_csv(url_file)
リクエストするすべてのURLを含むデータセットを取得したら、それらを反復処理して、各行に対してAPIリクエストを作成できます。 これを以下に示します。
import time # This is where the responses will be stored response_object = {} # Iterating through df for i in range(0, len(df)): # Error handling try: print('Requesting row #:', i) # Define the request parameters url = df.iloc[i]['URL'] device_type = df.iloc[i]['device_type'] # Making request contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(url, device_type) ).read().decode('UTF-8') # Converts to json format contents_json = json.loads(contents) # Insert returned json response into response_object response_object[device_type][url] = contents_json print('Sleeping for 20 seconds between responses.') time.sleep(20) except Exception as e: print('Error:', e) print('Returning empty response for url:', url) response_object[device_type][url] = {}回答を読む
データにフィルターやフォーマットを適用する前に、次のように将来使用するために最初に完全な応答を保存できます。
import json from datetime import datetime f_name ='data/{}-response.json'.format(datetime.now().strftime("%Y-%m-%d_%H:%M:%S")) with open(f_name, 'w') as outfile: json.dump(response_object, outfile, indent=4)上記のように、各応答はJSONオブジェクトを返します。 それらは、指定されたURLに関連する多くの異なるプロパティを持っており、フィルタリングとフォーマットなしで解読するには大きすぎます。
これを行うには、Pandasライブラリを使用します。これにより、必要なデータをテーブル形式で簡単に抽出して、CSVにエクスポートできます。

これが応答の一般的な構造です。 読み込み時間のデータは、そのサイズのために最小化されています。
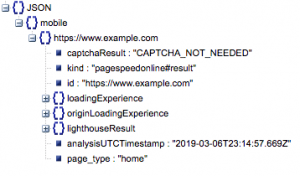
一般的な応答構造
他の情報の中でも、応答に含まれるページ速度データの2つの主要なソースがあります。「lighthouseResult」に保存されたラボデータと「loadingExperience」に保存されたフィールドデータです。 この投稿では、Chromeブラウザの実際のユーザーに基づいてクラウドソーシングされたフィールドデータのみに焦点を当てます。
特に、次のメトリックを抽出します。
- 要求されたURLと最終的なURL
- それらが同じであることを確認するために監査された要求されたURLと最終的に解決されたURLの両方が必要です。 これは、結果がリダイレクトではなく目的のURLからのものであることを識別するのに役立ちます。
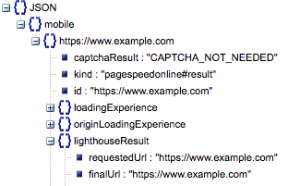
上記の「lighthouseResult」では、両方のURLが同じであることがわかります。
- 最初の満足のいくペイント(ms)
- これは、ユーザーが最初にページに移動してから、ブラウザーが最初にコンテンツをレンダリングして、ページが読み込まれていることをユーザーに通知するまでの時間です。
- このメトリックはミリ秒単位で測定されます。
- 最初の満足のいくペイント(遅い、平均、速いの割合)
- これは、First Contentful Paintの読み込み時間が遅い、平均的な、速いページの割合を示しています。
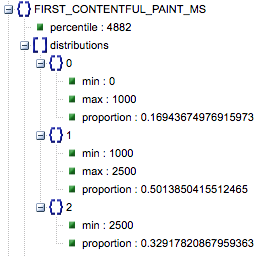
「パーセンタイル」とラベル付けされたミリ秒単位の最初のコンテンツフルペイントのロード時間、および低速、平均、高速の比率。
これらの結果はすべて、モバイルデータとデスクトップデータのいずれか、または両方について抽出できます。
Pandasデータフレームをdf_field_responsesと呼ぶ場合、これらのプロパティを抽出する方法は次のとおりです。
import pandas as pd # Specify the device_type (mobile or desktop) device_type = 'mobile' # Create dataframe to store responses df_field_responses = pd.DataFrame( columns=['requested_url', 'final_url', 'FCM_ms', 'FCP_category', 'FCP_fast', 'FCP_avg', 'FCP_slow' ] ) for (url, i) in zip( response_object[device_type].keys(), range(0, len(df_field_responses)) ): try: print('Trying to insert response for url:', url) # We reuse this below when selecting data from the response fcp_loading = response_object[device_type][url] ['loadingExperience']['metrics']['FIRST_CONTENTFUL_PAINT_MS'] # URLs df_field_responses.loc[i, 'requested_url'] = response_object[device_type][url]['lighthouseResult']['requestedUrl'] df_field_responses.loc[i, 'final_url'] = response_object[device_type][url]['lighthouseResult']['finalUrl'] # Loading experience: First Contentful Paint (ms) df_field_responses.loc[i, 'FCP_ms'] = fcp_loading['percentile'] df_field_responses.loc[i, 'FCP_category'] = fcp_loading['category'] # Proportions: First Contentful Paint df_field_responses.loc[i, 'FCP_fast'] = fcp_loading['distributions'][0]['proportion'] df_field_responses.loc[i, 'FCP_avg'] = fcp_loading['distributions'][1]['proportion'] df_field_responses.loc[i, 'FCP_slow'] = fcp_loading['distributions'][2]['proportion'] print('Inserted for row {}: {}'.format(i, df_field_responses.loc[i])) except Exception as e: print('Error:', e) print('Filling row with Error for row: {}; url: {}'.format(i, url)) # Fill in 'Error' for row if a field couldn't be found df_field_responses.loc[i] = ['Error' for i in range(0, len(df_field_responses.columns))]次に、データフレームdf_field_responsesをCSVに保存します。
df_field_responses.to_csv('page_speeds_filtered_responses.csv', index=False)GitHubでスクリプトを実行する
GitHubのリポジトリには、ファイルの実行方法に関する説明が含まれていますが、ここに簡単な内訳があります。
- GitHubでサンプルスクリプトを実行する前に、を使用してリポジトリのクローンを作成する必要があります。
-
git clone https://github.com/Ayima/page-speed-blog-post.git
-
- 次に、クエリするURLを含むCSVファイルを作成します。
- 構成ファイルにURLファイル名を入力します。
- スクリプトを実行するコマンド:
python main.py --config-file config.json覚えておくべきこと:
APIには、1日および1秒あたりに実行できるリクエストの数に制限があります。
これに備えるには、次のようないくつかの方法があります。
- エラー処理:エラーを返すリクエストを繰り返します
- スロットリング:スクリプトで、1秒あたりに送信されるリクエストの数を制限し、URLが失敗した場合に再リクエストします。
- 必要に応じてAPIキーを取得します(通常、1秒間に複数のクエリを実行する場合)。
このガイドを読んだ後、Google Page SpeedInsightsAPIの基本的なクエリを開始して実行できるようになることを願っています。 ご不明な点がある場合や問題が発生した場合は、Twitter@ayimaまでお気軽にお問い合わせください。
AyimaでのPageSpeedsAPIの使用方法
ここAyimaでは、クライアントのページ速度を継続的に収集して保管しています。 これは、Webサイトの状態を監視し、ネガティブまたはポジティブな傾向を特定するのに役立ちます。 さまざまなページの速度を監視することで、サイトセクションまたはページタイプ(eコマースWebサイトの製品ページとカテゴリページなど)ごとにパフォーマンスを視覚化できます。
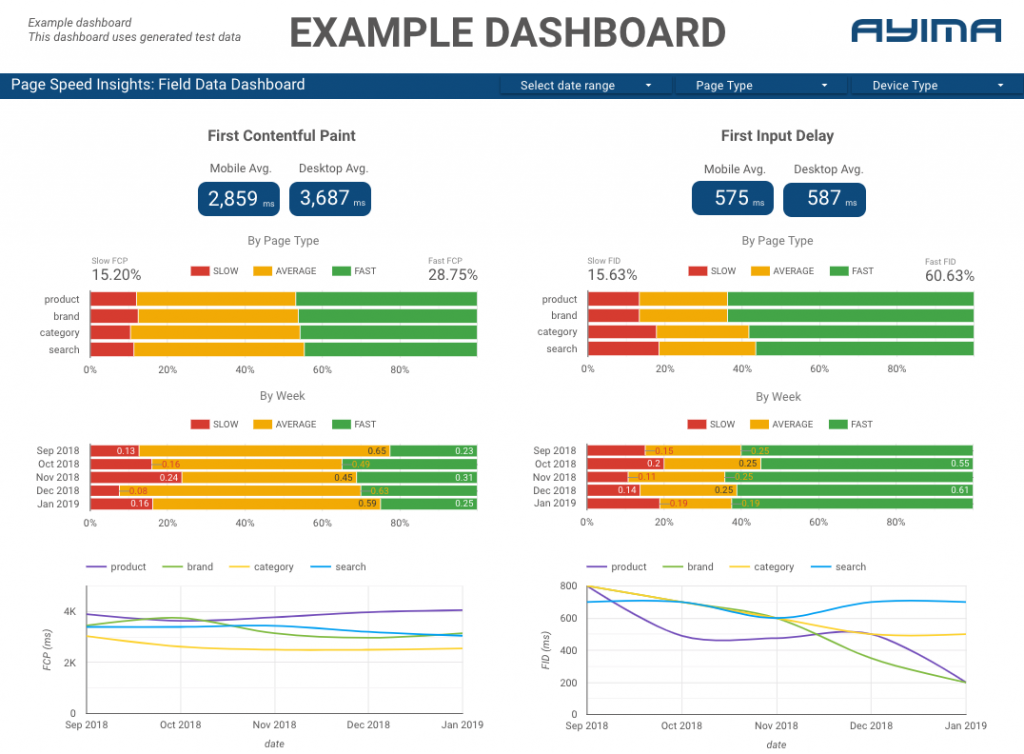
また、Googleのラボデータなど、APIによって提供されるその他の興味深い指標を追跡し、すべてをインタラクティブなダッシュボードに表示します。 詳細については、お問い合わせください。チャットさせていただきます。
ソースコード:ここで実行するサンプルスクリプトを含むGitHubプロジェクトを見つけることができます。