
الشروع في استخدام واجهة برمجة تطبيقات سرعة الصفحة من Google
نشرت: 2019-03-11تعد سرعة الصفحة واحدة من أكبر المؤشرات على المدة التي سيقضيها شخص ما على موقعك. يمكن أن تؤدي صفحات التحميل البطيء إلى معدلات ارتداد أعلى ، ومعدلات تحويل أقل ، وبالتالي انخفاض الإيرادات.
للحصول على نظرة ثاقبة حول ما إذا كانت أوقات التحميل قد تؤثر على الاحتفاظ بالجمهور والتحويل ، تعد أداة Page Speed Insights من Google مكانًا رائعًا للبدء. واجهة برمجة تطبيقات Page Speed من Google هي الطريقة التي يمكنك بها توصيل هذه البيانات ودمج الأفكار في مكدس البيانات الخاص بك. لقد استخدمناها لبناء أداة تعقب تحليلات سرعة الصفحة الخاصة بنا لمراقبة مقاييس تجربة المستخدم الرئيسية لعملائنا.
ما هو الشيء الرائع في Page Speed Insights API؟
باستخدام هذه الأداة ، يمكنك توصيل عنوان URL والحصول على ملخص لأدائه. يعد هذا أمرًا رائعًا لأخذ عينات من عدد قليل من عناوين URL ، ولكن ماذا لو كان لديك موقع ويب كبير وتريد رؤية نظرة عامة شاملة على الأداء عبر أقسام وأنواع صفحات متعددة؟
هذا هو المكان الذي تأتي فيه واجهة برمجة التطبيقات. تتيح لنا Page Speed Insights API من Google الفرصة لتحليل الأداء للعديد من الصفحات وتسجيل النتائج ، دون الحاجة إلى طلب عناوين URL صراحة واحدة تلو الأخرى وتفسير النتائج يدويًا.
مع وضع ذلك في الاعتبار ، قمنا بتجميع دليل بسيط سيساعدك على البدء في استخدام واجهة برمجة التطبيقات لموقعك على الويب. بمجرد أن تتعرف على العملية الموضحة أدناه ، سترى كيف يمكن استخدامها لتحليل سرعة موقعك على نطاق واسع ، وتتبع كيفية تغيرها بمرور الوقت أو حتى إعداد أدوات المراقبة.
يفترض هذا الدليل بعض الإلمام بالكتابة النصية. هنا نستخدم Python للتفاعل مع API وتحليل النتائج.
أهداف
ستتعلم في هذا المنشور كيفية:
- إنشاء استعلام Google Page Speed Insights API
- قم بعمل طلبات API لجدول عناوين URL
- استخراج المعلومات الأساسية من استجابة API
- قم بتشغيل المثال النصي المحدد في Python
جاري الإعداد
هناك بعض الخطوات التي ستحتاج إلى اتباعها قبل الاستعلام عن Page Speed Insights API مع Python.
- إعداد API: تتطلب العديد من واجهات برمجة تطبيقات Google مفاتيح API وكلمات المرور وإجراءات المصادقة الأخرى. ومع ذلك ، لا تحتاج إلى أي من هذا لبدء استخدام واجهة برمجة تطبيقات Google Page Speeds!
- تثبيت Python 3: إذا لم تستخدم Python من قبل ، فإننا نوصي بالبدء في توزيع Anaconda (إصدار Python 3.x) ، الذي يقوم بتثبيت Python جنبًا إلى جنب مع مكتبات تحليل البيانات الشائعة مثل Pandas.
تقديم الطلبات
أساسيات الطلب
يمكن الاستعلام عن واجهة برمجة التطبيقات في نقطة النهاية هذه باستخدام طلبات GET:
GET https://www.googleapis.com/pagespeedonline/v5/runPagespeedنضيف بعد ذلك معلمات إضافية لتحديد عنوان URL الذي نريد العثور على سرعة الصفحة ونوع الجهاز المراد استخدامه ، كما هو موضح أدناه:
https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={url}&strategy={device_type} عند إجراء الطلبات ، يجب استبدال {url} بعنوان URL للصفحة المشفرة بعنوان URL من موقعك على الويب ، {device_type} بالجوال أو سطح المكتب ، لتحديد نوع الجهاز.
حزم بايثون
من أجل تقديم الطلبات واستيعابها ثم كتابة النتائج في الجداول ، سنستخدم عددًا قليلاً من مكتبات python:
- urllib : لعمل طلبات HTTP.
- json : لتحليل كائنات الاستجابة وقراءتها.
- الباندا : لحفظ النتائج بتنسيق CSV.
بناء الاستعلام
لتقديم طلب API باستخدام Python ، يمكننا استخدام طريقة urllib.request.urlopen :
import urllib.request import urllib.parse url = 'http://www.example.com' escaped_url = urllib.parse.quote(url) device_type = 'mobile' # Construct request url contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(escaped_url, device_type) ).read().decode('UTF-8')يجب أن يعرض هذا الطلب استجابة JSON (كبيرة بشكل مدهش). سنناقش هذا بمزيد من التفصيل قريبا.
عمل استفسارات متعددة
تتمثل إحدى نقاط البيع الرئيسية لواجهة برمجة التطبيقات هذه في أنها تمكننا من سحب سرعات الصفحة لدُفعات من عناوين URL. دعونا نلقي نظرة على كيفية القيام بذلك باستخدام بايثون.
أحد الخيارات هو تخزين معلمات الطلب ( url و device_type ) في ملف CSV ، والذي يمكننا تحميله في Pandas DataFrame للتكرار. لاحظ أدناه أن كل طلب أو زوج فريد من نوع url + device_type له صف خاص به.
تخزين البيانات في CSV
URL, device_type 0, https://www.example.com, desktop 1, https://www.example.com, mobile 2, https://www.example.com/blog, desktop 3, https://www.example.com/blog, mobileقم بتحميل ملف CSV
import pandas as pd df = pd.read_csvimport pandas as pd df = pd.read_csv(url_file)
بمجرد أن يكون لدينا مجموعة بيانات بها جميع عناوين URL التي نطلبها ، يمكننا تكرارها وتقديم طلب واجهة برمجة تطبيقات لكل صف. هذا موضح أدناه:
import time # This is where the responses will be stored response_object = {} # Iterating through df for i in range(0, len(df)): # Error handling try: print('Requesting row #:', i) # Define the request parameters url = df.iloc[i]['URL'] device_type = df.iloc[i]['device_type'] # Making request contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(url, device_type) ).read().decode('UTF-8') # Converts to json format contents_json = json.loads(contents) # Insert returned json response into response_object response_object[device_type][url] = contents_json print('Sleeping for 20 seconds between responses.') time.sleep(20) except Exception as e: print('Error:', e) print('Returning empty response for url:', url) response_object[device_type][url] = {}قراءة الرد
قبل تطبيق أي عوامل تصفية أو تنسيق على البيانات ، يمكننا أولاً تخزين الردود الكاملة للاستخدام في المستقبل مثل هذا:
import json from datetime import datetime f_name ='data/{}-response.json'.format(datetime.now().strftime("%Y-%m-%d_%H:%M:%S")) with open(f_name, 'w') as outfile: json.dump(response_object, outfile, indent=4)كما ذكرنا أعلاه ، تقوم كل استجابة بإرجاع كائن JSON. لديهم العديد من الخصائص المختلفة المتعلقة بعنوان URL المحدد ، وهي كبيرة جدًا بحيث لا يمكن فك تشفيرها بدون تصفية وتنسيق.

للقيام بذلك ، سنستخدم مكتبة Pandas ، مما يجعل من السهل استخراج البيانات التي نريدها في تنسيق جدول وتصديرها إلى CSV.
هذا هو الهيكل العام للاستجابة. تم تصغير البيانات الخاصة بأوقات التحميل نظرًا لحجمها.
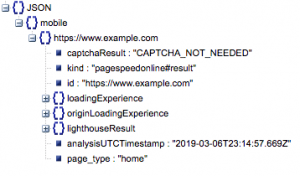
الهيكل العام للاستجابة
من بين المعلومات الأخرى ، هناك مصدران رئيسيان لبيانات سرعة الصفحة المضمنة في الاستجابة: بيانات المختبر ، المخزنة في "lighthouseResult" وبيانات الحقل ، المخزنة في "loadingExperience". في هذا المنشور ، سنركز على البيانات الميدانية فقط ، والتي يتم تجميعها بشكل جماعي بناءً على مستخدمي العالم الحقيقي على متصفح Chrome.
على وجه الخصوص ، سنقوم باستخراج المقاييس التالية:
- رابط URL المطلوب ورابط عنوان URL النهائي
- نحتاج إلى كل من عنوان URL المطلوب والحل النهائي الذي تم تدقيقه للتأكد من أنهما متماثلان. سيساعدنا هذا في تحديد أن النتيجة جاءت من عنوان URL المقصود بدلاً من إعادة التوجيه.
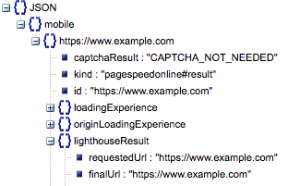
يمكننا أن نرى أن كلا عنواني URL متماثلان في "lighthouseResult" أعلاه.
- أول رسم مضمون (مللي ثانية)
- هذا هو الوقت بين تنقل المستخدم لأول مرة إلى الصفحة وعندما يعرض المتصفح جزءًا من المحتوى لأول مرة ، لإخبار المستخدم بأنه يتم تحميل الصفحة.
- يتم قياس هذا المقياس بالمللي ثانية.
- أول رسم مضمون (نسب بطيئة ومتوسطة وسريعة)
- يعرض هذا النسبة المئوية للصفحات ذات أوقات التحميل البطيئة والمتوسطة والسريعة لـ First Contentful Paint.
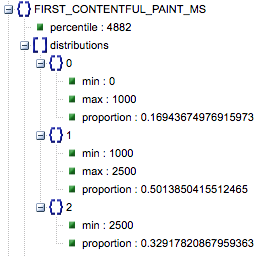
وقت تحميل First Contentful Paint بالمللي ثانية ، والمسمى "النسبة المئوية" ، ونسبة بطيئة ومتوسطة وسريعة.
يمكن استخراج كل هذه النتائج لأيٍّ من بيانات الهاتف وسطح المكتب أو كليهما.
إذا استدعينا Pandas dataframe df_field_responses ، فإليك كيفية استخراج هذه الخصائص:
import pandas as pd # Specify the device_type (mobile or desktop) device_type = 'mobile' # Create dataframe to store responses df_field_responses = pd.DataFrame( columns=['requested_url', 'final_url', 'FCM_ms', 'FCP_category', 'FCP_fast', 'FCP_avg', 'FCP_slow' ] ) for (url, i) in zip( response_object[device_type].keys(), range(0, len(df_field_responses)) ): try: print('Trying to insert response for url:', url) # We reuse this below when selecting data from the response fcp_loading = response_object[device_type][url] ['loadingExperience']['metrics']['FIRST_CONTENTFUL_PAINT_MS'] # URLs df_field_responses.loc[i, 'requested_url'] = response_object[device_type][url]['lighthouseResult']['requestedUrl'] df_field_responses.loc[i, 'final_url'] = response_object[device_type][url]['lighthouseResult']['finalUrl'] # Loading experience: First Contentful Paint (ms) df_field_responses.loc[i, 'FCP_ms'] = fcp_loading['percentile'] df_field_responses.loc[i, 'FCP_category'] = fcp_loading['category'] # Proportions: First Contentful Paint df_field_responses.loc[i, 'FCP_fast'] = fcp_loading['distributions'][0]['proportion'] df_field_responses.loc[i, 'FCP_avg'] = fcp_loading['distributions'][1]['proportion'] df_field_responses.loc[i, 'FCP_slow'] = fcp_loading['distributions'][2]['proportion'] print('Inserted for row {}: {}'.format(i, df_field_responses.loc[i])) except Exception as e: print('Error:', e) print('Filling row with Error for row: {}; url: {}'.format(i, url)) # Fill in 'Error' for row if a field couldn't be found df_field_responses.loc[i] = ['Error' for i in range(0, len(df_field_responses.columns))]ثم لتخزين إطار البيانات ، df_field_responses ، في ملف CSV:
df_field_responses.to_csv('page_speeds_filtered_responses.csv', index=False)تشغيل البرامج النصية على جيثب
يحتوي المستودع الموجود على GitHub على إرشادات حول كيفية تشغيل الملفات ، ولكن يوجد هنا تفصيل سريع.
- قبل تشغيل أمثلة البرامج النصية على GitHub ، ستحتاج إلى استنساخ المستودع باستخدام
-
git clone https://github.com/Ayima/page-speed-blog-post.git
-
- ثم قم بإنشاء ملف CSV مع عناوين URL للاستعلام عنها.
- املأ ملف التكوين باسم ملف URL.
- أمر لتشغيل البرامج النصية:
python main.py --config-file config.jsonشيء يجب مراعاته:
تحتوي واجهة برمجة التطبيقات على حد لعدد الطلبات التي يمكنك إجراؤها في اليوم والثانية.
هناك عدة طرق للاستعداد لذلك بما في ذلك:
- معالجة الأخطاء: كرر الطلبات التي ترجع خطأ
- الخنق: في البرنامج النصي الخاص بك للحد من عدد الطلبات المرسلة في الثانية ، وإعادة الطلب في حالة فشل عنوان URL.
- احصل على مفتاح API إذا لزم الأمر (عادةً إذا كنت تجري أكثر من استعلام واحد في الثانية).
نأمل بعد قراءة هذا الدليل أن تتمكن من بدء تشغيل بعض الاستعلامات الأساسية لواجهة برمجة تطبيقات Google Page Speed Insights. لا تتردد في التواصل معنا على twitterayima لطرح أي أسئلة أو إذا واجهت أي مشاكل!
كيف نستخدم Page Speeds API في Ayima
هنا في Ayima ، نقوم باستمرار بجمع وتخزين سرعات الصفحات للعملاء. يساعدنا ذلك في مراقبة صحة مواقعهم الإلكترونية وتحديد الاتجاهات السلبية أو الإيجابية. من خلال مراقبة السرعات لمجموعة متنوعة من الصفحات ، يمكننا تصور الأداء حسب قسم الموقع أو نوع الصفحة (على سبيل المثال ، صفحات المنتج مقابل صفحات فئة مواقع التجارة الإلكترونية).
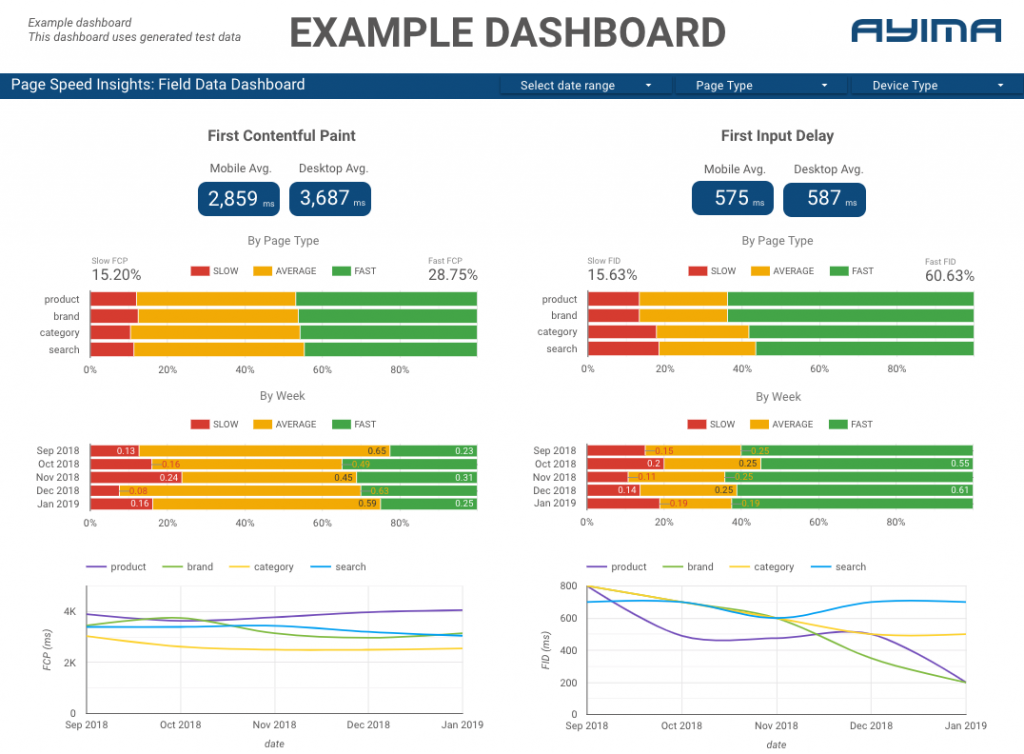
نتتبع أيضًا مقاييس أخرى مثيرة للاهتمام توفرها واجهة برمجة التطبيقات ، بما في ذلك بيانات مختبر Google ، ونقدم كل شيء في لوحة معلومات تفاعلية. لمزيد من المعلومات حول هذا يرجى الاتصال ، يسعدنا التحدث معك!
كود المصدر: يمكنك العثور على مشروع GitHub مع مثال على البرنامج النصي للتشغيل هنا.