
Hadoop ve Spark: Bire Bir Karşılaştırma
Yayınlanan: 2022-11-02Apache Software Foundation tarafından geliştirilen Hadoop ve Spark, büyük veri mimarileri için yaygın olarak kullanılan açık kaynaklı çerçevelerdir.
Şu anda Büyük Veri olgusunun gerçekten merkezindeyiz ve şirketler artık verilerin karar verme süreçleri üzerindeki etkisini görmezden gelemezler.
Bir hatırlatma olarak, Büyük Veri olarak kabul edilen veriler üç kriteri karşılar: hız, hız ve çeşitlilik. Ancak Büyük Veriyi geleneksel sistem ve teknolojilerle işleyemezsiniz.
Apache Software Foundation, bu sorunun üstesinden gelmek için en çok kullanılan çözümleri, yani Hadoop ve Spark'ı önermiştir.
Ancak, büyük veri işlemede yeni olan kişiler bu iki teknolojiyi anlamakta güçlük çekiyor. Tüm şüpheleri ortadan kaldırmak için bu makalede, Hadoop ve Spark arasındaki temel farkları ve ne zaman birini veya diğerini seçmeniz gerektiğini veya bunları birlikte kullanmanız gerektiğini öğrenin.
Hadoop
Hadoop, Büyük Veriyi işlemek için bir ekosistem oluşturan birkaç modülden oluşan bir yazılım aracıdır. Hadoop'un bu işleme için kullandığı ilke, verilerin paralel olarak işlenmesi için dağıtılmış dağıtımıdır.

Hadoop'un dağıtılmış depolama sistemi kurulumu, birkaç sıradan bilgisayardan oluşur ve böylece birkaç düğümden oluşan bir küme oluşturur. Bu sistemi benimsemek, Hadoop'un birden fazla görevi aynı anda, hızlı ve verimli bir şekilde gerçekleştirerek büyük miktardaki mevcut verileri verimli bir şekilde işlemesine olanak tanır.
Hadoop ile işlenen veriler birçok şekilde olabilir. Geleneksel bir VTYS'deki Excel tabloları veya tablolar gibi yapılandırılabilirler. Bu veriler, JSON veya XML dosyaları gibi yarı yapılandırılmış bir şekilde de sunulabilir. Hadoop ayrıca resimler, videolar veya ses dosyaları gibi yapılandırılmamış verileri de destekler.
Ana bileşenler
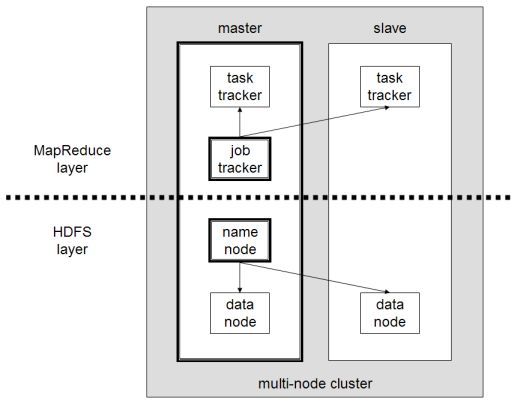
Hadoop'un ana bileşenleri şunlardır:
- HDFS veya Hadoop Dağıtılmış Dosya Sistemi, Hadoop tarafından dağıtılmış veri depolaması gerçekleştirmek için kullanılan sistemdir. Küme meta verilerini içeren bir ana düğümden ve verilerin kendisinin depolandığı birkaç bağımlı düğümden oluşur;
- MapReduce , bu dağıtılmış verileri işlemek için kullanılan algoritmik modeldir. Bu tasarım deseni Java, R, Scala, Go, JavaScript veya Python gibi çeşitli programlama dilleri kullanılarak uygulanabilir. Her düğüm içinde paralel olarak çalışır;
- Çeşitli yardımcı programların ve kitaplıkların diğer Hadoop bileşenlerini desteklediği Hadoop Common ;
- YARN , Hadoop kümesindeki kaynağı ve her düğüm tarafından gerçekleştirilen iş yükünü yönetmek için bir düzenleme aracıdır. Ayrıca bu çerçevenin 2.0 sürümünden beri MapReduce uygulamasını da destekler.
Apaçi Kıvılcımı

Apache Spark, başlangıçta bilgisayar bilimcisi Matei Zaharia tarafından 2009 yılında doktorasının bir parçası olarak oluşturulmuş açık kaynaklı bir çerçevedir. Daha sonra 2010 yılında Apache Yazılım Vakfı'na katıldı.
Spark, birkaç düğüm üzerinde dağıtılmış bir şekilde dağıtılmış bir hesaplama ve veri işleme motorudur. Spark'ın temel özelliği, bellek içi işleme gerçekleştirmesidir, yani kümede dağıtılan büyük verileri önbelleğe almak ve işlemek için RAM kullanır. Daha yüksek performans ve çok daha yüksek işlem hızı sağlar.

Spark, toplu işleme, gerçek akış işleme, makine öğrenimi ve grafik hesaplama dahil olmak üzere çeşitli görevleri destekler. HDFS, RDBMS ve hatta NoSQL veritabanları gibi çeşitli sistemlerden gelen verileri de işleyebiliriz. Spark'ın uygulaması Scala veya Python gibi çeşitli dillerle yapılabilir.
Ana bileşenler
Apache Spark'ın ana bileşenleri şunlardır:
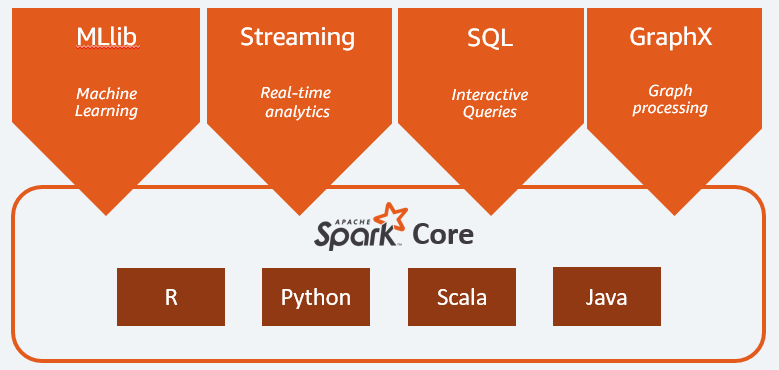
- Spark Core , tüm platformun genel motorudur. Görevlerin planlanması ve dağıtılmasından, girdi/çıktı operasyonlarının koordine edilmesinden veya herhangi bir arızanın giderilmesinden sorumludur;
- Spark SQL , yapılandırılmış ve yarı yapılandırılmış verileri destekleyen RDD şemasını sağlayan bileşendir. Özellikle, SQL'i yürüterek veya SQL motoruna erişim sağlayarak yapılandırılmış türdeki verilerin toplanmasını ve işlenmesini optimize etmeyi mümkün kılar;
- Akış veri analizine izin veren Spark Akışı . Spark Streaming, Flume, Kinesis veya Kafka gibi farklı kaynaklardan gelen verileri destekler;
- MLib , Apache Spark'ın makine öğrenimi için yerleşik kitaplığı. Birkaç makine öğrenimi algoritmasının yanı sıra makine öğrenimi ardışık düzenleri oluşturmak için çeşitli araçlar sağlar;
- GraphX , dağıtılmış bir mimari içinde modelleme, hesaplamalar ve grafik analizleri gerçekleştirmek için bir dizi API'yi birleştirir.
Hadoop ve Spark: Farklar

Spark, bir Büyük Veri hesaplama ve veri işleme motorudur. Yani teoride biraz Hadoop MapReduce'a benziyor, bu da In-Memory'de çalıştığı için çok daha hızlı. O halde Hadoop ve Spark'ı farklı kılan nedir? Bir bakalım:

- Hadoop gruplar halinde ilerlerken Spark, özellikle bellek içi işleme sayesinde çok daha verimlidir;
- Spark, performansını korumak için önemli miktarda RAM gerektirdiğinden maliyet açısından çok daha pahalıdır. Öte yandan Hadoop, veri işleme için yalnızca sıradan bir makineye güvenir;
- Hadoop toplu işleme için daha uygundur, Spark ise en çok akış verileri veya yapılandırılmamış veri akışları ile uğraşırken uygundur;
- Hadoop, verileri sürekli olarak çoğalttığı için hataya daha dayanıklıdır, Spark ise HDFS'ye dayanan esnek dağıtılmış veri kümesi (RDD) kullanır.
- Hadoop daha ölçeklenebilirdir, çünkü yalnızca mevcut makineler artık yeterli değilse başka bir makine eklemeniz gerekir. Spark, genişletmek için HDFS gibi diğer çerçevelerin sistemine güvenir.
| faktör | Hadoop | Kıvılcım |
| İşleme | Toplu İşleme | Bellek İçi İşleme |
| Dosya yönetimi | HDFS | Hadoop'un HDFS'sini kullanır |
| Hız | Hızlı | 10 ila 1000 kat daha hızlı |
| Dil desteği | Java, Python, Scala, R, Go ve JavaScript | Java, Python, Scala ve R |
| Hata Toleransı | Daha Hoşgörülü | Daha Az Toleranslı |
| Maliyet | Daha az pahalı | Daha pahalı |
| ölçeklenebilirlik | Daha Ölçeklenebilir | Daha Az Ölçeklenebilir |
Hadoop için iyidir
İşlem hızı kritik değilse Hadoop iyi bir çözümdür. Örneğin, veri işleme bir gecede yapılabiliyorsa, Hadoop'un MapReduce'unu kullanmayı düşünmek mantıklıdır.
Hadoop'un HDFS'si kuruluşlara verileri depolamak ve işlemek için daha iyi bir yol sağladığından, Hadoop, işlenmesinin nispeten zor olduğu veri ambarlarından büyük veri kümelerini boşaltmanıza olanak tanır.
Kıvılcım şunlar için iyidir:
Spark'ın esnek Dağıtılmış Veri Kümeleri (RDD'ler) birden fazla bellek içi harita işlemine izin verirken, Hadoop MapReduce'un ara sonuçları diske yazması gerekir, bu da gerçek zamanlı etkileşimli veri analizi yapmak istiyorsanız Spark'ı tercih edilen bir seçenek haline getirir.
Spark'ın bellek içi işlemesi ve Cassandra veya MongoDB gibi dağıtılmış veritabanları için desteği, veriler bir kaynak veritabanından alındığında ve başka bir hedef sisteme gönderildiğinde, veri geçişi ve ekleme için mükemmel bir çözümdür.
Hadoop ve Spark'ı Birlikte Kullanma

Genellikle Hadoop ve Spark arasında seçim yapmanız gerekir; bununla birlikte, çoğu durumda, bu iki çerçeve çok iyi bir şekilde bir arada bulunabileceği ve birlikte çalışabileceği için seçim yapmak gereksiz olabilir. Gerçekten de Spark'ı geliştirmenin arkasındaki ana neden, Hadoop'u değiştirmek yerine geliştirmekti.
Önceki bölümlerde gördüğümüz gibi Spark, HDFS depolama sistemini kullanarak Hadoop ile entegre edilebilir. Aslında her ikisi de dağıtılmış bir ortamda daha hızlı veri işleme gerçekleştirir. Benzer şekilde, verileri Hadoop'ta tahsis edebilir ve Spark kullanarak işleyebilir veya Hadoop MapReduce içinde işler çalıştırabilirsiniz.
Çözüm
Hadoop mu Kıvılcım mı? Çerçeveyi seçmeden önce, mimarinizi göz önünde bulundurmalısınız ve onu oluşturan teknolojiler, ulaşmak istediğiniz hedefle tutarlı olmalıdır. Ayrıca Spark, Hadoop ekosistemiyle tamamen uyumludur ve Hadoop Dağıtılmış Dosya Sistemi ve Apache Hive ile sorunsuz çalışır.
Ayrıca bazı büyük veri araçlarını da keşfedebilirsiniz.